利用DeepSeek R1和Ollama构建RAG系统:只需100行代码
有没有想过可以直接向 PDF 或技术手册提问?想象一下,你不再需要逐页翻阅那些枯燥的文档,而是像和一位知识渊博的朋友聊天一样,轻松获取信息。本指南将向你展示如何使用(一个开源推理工具)和(一个用于运行本地 AI 模型的轻量级框架)构建一个**检索增强生成(RAG)**系统。别担心,即使你不是技术大牛,跟着我一步步来,你也能搞定!
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
有没有想过可以直接向 PDF 或技术手册提问?想象一下,你不再需要逐页翻阅那些枯燥的文档,而是像和一位知识渊博的朋友聊天一样,轻松获取信息。本指南将向你展示如何使用 DeepSeek R1(一个开源推理工具)和 Ollama(一个用于运行本地 AI 模型的轻量级框架)构建一个**检索增强生成(RAG)**系统。别担心,即使你不是技术大牛,跟着我一步步来,你也能搞定!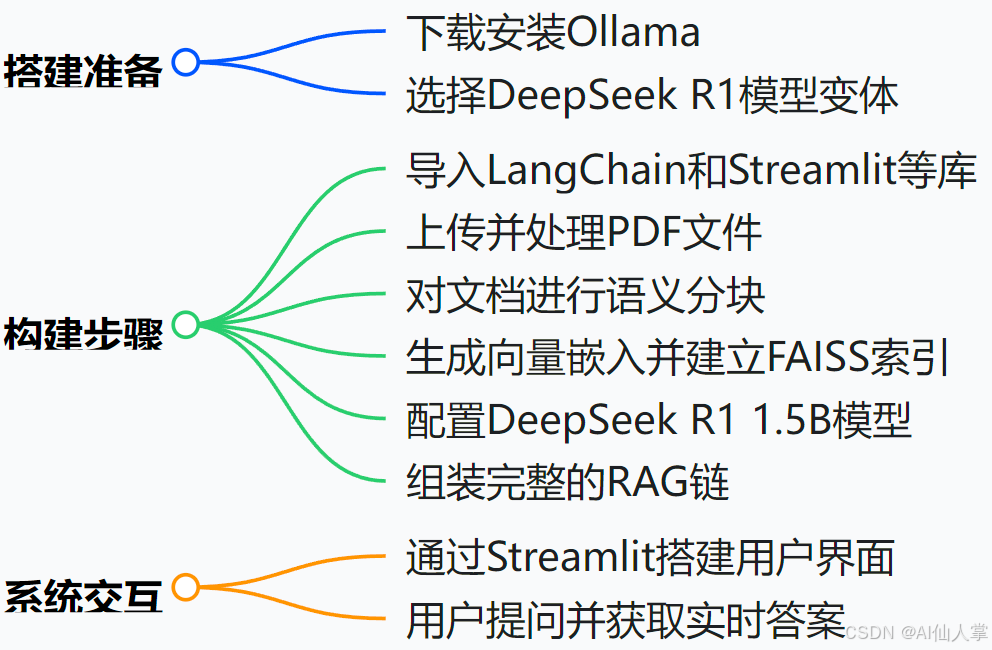
构建本地 RAG 系统所需的工具
Ollama 允许你在本地运行像 DeepSeek R1 这样的模型。你可以把它想象成一个“AI 模型管家”,帮你轻松管理各种模型。
- 下载: Ollama
- 安装: 通过终端安装并运行以下命令。
DeepSeek R1 的参数范围从 1.5B 到 671B。对于轻量级的 RAG 应用,可以从 1.5B 模型开始。毕竟,谁不想从小白变成大神呢?
ollama run deepseek-r1:1.5b
小贴士: 更大的模型(例如 70B)提供更好的推理能力,但需要更多的内存。如果你有一台性能强劲的电脑,不妨试试看!
安装工具库
pip install -U langchain langchain-community langchain_experimental
pip install streamlit
pip install pdfplumber
pip install semantic-chunkers
pip install open-text-embeddings
pip install ollama
pip install prompt-template
pip install sentence-transformers
pip install faiss
构建 RAG
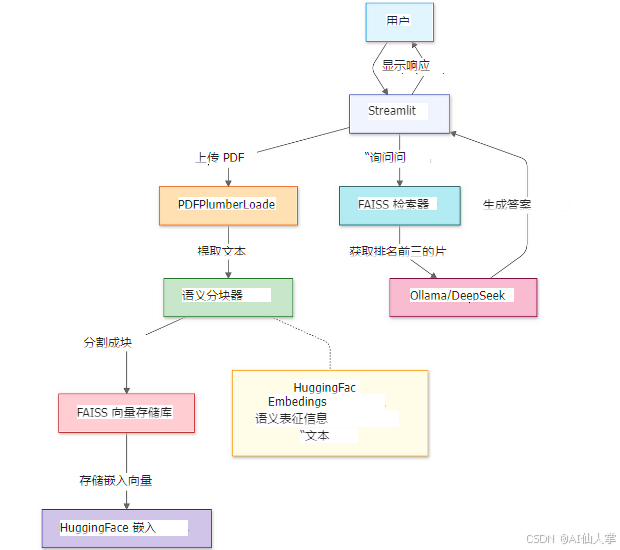
第一步:导入库
我们将使用:
- LangChain 用于文档处理和检索。它就像是一个“文档处理大师”,帮你把复杂的文档整理得井井有条。
- Streamlit 用于用户友好的 Web 界面。你可以把它想象成一个“网页魔术师”,轻松打造交互式界面。
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
第二步:上传并处理 PDF
利用 Streamlit 的文件上传器选择本地 PDF。使用 PDFPlumberLoader 高效提取文本,无需手动解析。就像你有一个“文档扫描仪”,瞬间把纸质文档变成电子版。
# Streamlit 文件上传器
uploaded_file = st.file_uploader("上传一个 PDF 文件", type="pdf") if uploaded_file:
# 临时保存 PDF
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue()) # 加载 PDF 文本
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
第三步:策略性地分块文档
利用 Streamlit 的文件上传器选择本地 PDF。使用 PDFPlumberLoader 高效提取文本,无需手动解析。这就像把一本厚厚的书拆分成一个个小章节,方便你快速找到所需信息。
# 将文本分割成语义块
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
第四步:创建可搜索的知识库
为分块生成向量嵌入并将其存储在 FAISS 索引中。这就像给你的文档加上了一个“智能搜索引擎”,快速找到相关内容。
- 嵌入允许快速、上下文相关的搜索。
# 生成嵌入
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings) # 连接检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 获取前 3 个分块
第五步:配置 DeepSeek R1
使用 DeepSeek R1 1.5B 模型设置 RetrievalQA 链。这就像给你的 AI 助手安装了一个“知识过滤器”,确保它只根据文档内容回答问题,而不是胡编乱造。
- 这确保了答案基于 PDF 内容,而不是依赖于模型的训练数据。
llm = Ollama(model="deepseek-r1:1.5b") # 我们的 1.5B 参数模型 # 创建提示模板
prompt = """
1. 仅使用以下上下文。
2. 如果不确定,请说“我不知道”。
3. 保持答案在 4 句话以内。 上下文: {context} 问题: {question} 答案:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
第六步:组装 RAG 链
将上传、分块和检索整合到一个连贯的管道中。这就像给你的 AI 系统装上了一台“流水线机器”,自动完成所有步骤。
- 这种方法为模型提供了经过验证的上下文,提高了准确性。
# 链 1: 生成答案
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT) # 链 2: 合并文档分块
document_prompt = PromptTemplate(
template="上下文:\n内容:{page_content}\n来源:{source}",
input_variables=["page_content", "source"]
) # 最终的 RAG 管道
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
第七步:启动 Web 界面
Streamlit 允许用户输入问题并即时获得答案。这就像给你的 AI 系统装上了一扇“对话窗口”,用户可以随时提问,随时获取答案。
- 查询检索匹配的分块,将其输入模型,并实时显示结果。
# Streamlit 用户界面
user_input = st.text_input("向你的 PDF 提问:") if user_input:
with st.spinner("思考中..."):
response = qa(user_input)["result"]
st.write(response)
完整代码:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
# color palette
primary_color = "#1E90FF"
secondary_color = "#FF6347"
background_color = "#F5F5F5"
text_color = "#4561e9"
# 自定义CSS
st.markdown(f"""
<style>
.stApp {{
background-color: {background_color};
color: {text_color};
}}
.stButton>button {{
background-color: {primary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
.stTextInput>div>div>input {{
border: 2px solid {primary_color};
border-radius: 5px;
padding: 10px;
font-size: 16px;
}}
.stFileUploader>div>div>div>button {{
background-color: {secondary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
</style>
""", unsafe_allow_html=True)
# Streamlit应用标题
st.title("使用DeepSeek R1和Ollama构建RAG系统")
# 加载PDF
uploaded_file = st.file_uploader("上传PDF文件", type="pdf")
if uploaded_file is not None:
# Save the uploaded file to a temporary location
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load the PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
# Split into chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
# Instantiate the embedding model
embedder = HuggingFaceEmbeddings()
# Create the vector store and fill it with embeddings
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Define llm
llm = Ollama(model="deepseek-r1")
# Define the prompt
prompt = """
1. 使用以下上下文内容回答最后的问题。
2. 如果不知道答案,只需说"我不知道",不要编造答案。
3. 保持回答简洁,控制在3-4句话内。
Context: {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(
llm=llm,
prompt=QA_CHAIN_PROMPT,
callbacks=None,
verbose=True)
document_prompt = PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\ncontent:{page_content}\nsource:{source}",
)
combine_documents_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
document_prompt=document_prompt,
callbacks=None)
qa = RetrievalQA(
combine_documents_chain=combine_documents_chain,
verbose=True,
retriever=retriever,
return_source_documents=True)
# 用户输入
user_input = st.text_input("输入与PDF相关的问题:")
# 处理用户输入
if user_input:
with st.spinner("处理中..."):
response = qa(user_input)["result"]
st.write("响应结果:")
st.write(response)
else:
st.write("请上传PDF文件以继续。")
DeepSeek 与 RAG 的未来
DeepSeek R1 只是一个开始。随着即将推出的自我验证和多跳推理等功能,未来的 RAG 系统可以自主辩论和优化其逻辑。想象一下,未来的 AI 不仅能回答问题,还能自我反思和修正,简直就像是科幻电影中的场景!
今天就构建你自己的 RAG 系统,释放基于文档的 AI 的全部潜力!别等了,赶紧动手吧,未来的你一定会感谢现在的自己!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)