DeepSeek-V3-0324 发布,本次 V3 版本有哪些改进?
新一周的第一天,北京时间 3 月 24 日晚,DeepSeek 「突然」发布了模型更新。但暂时还不是 DeepSeek V4 或 R2,而是 DeepSeek V3 模型的一次更新。大家对这次「小版本升级」的 DeepSeek V3 模型体验如何呢?一起来看大模型、Python 话题领域优秀答主、答主与答主的回答吧~推理能力增强基准测试提升显著Web前端开发能力优化中文写作能力升级风格与内容优化功
新一周的第一天,北京时间 3 月 24 日晚,DeepSeek 「突然」发布了模型更新。但暂时还不是 DeepSeek V4 或 R2,而是 DeepSeek V3 模型的一次更新。大家对这次「小版本升级」的 DeepSeek V3 模型体验如何呢?一起来看大模型、Python 话题领域优秀答主
@段小草、答主 @toyama nao与答主 @ Trisimo 崔思莫 的回答吧~
DeepSeek-V3-0324 发布,本次 V3 版本有哪些改进?
****|****** *答主:段小草*
Update:官网刚刚更新了版本说明,数学和编程提升幅度很大,推理能力增强,写作风格和 R1 对齐(倒也不是非得学 R1 那么癫):
Deepseek-chat 模型升级为 DeepSeek-V3-0324:
-
推理能力增强
-
-
基准测试提升显著
-
- MMLU-Pro: 75.9 → 81.2 (+5.3)
- GPQA: 59.1 → 68.4 (+9.3)
- AIME: 39.6 → 59.4 (+19.8)
- LiveCodeBench: 39.2 → 49.2 (+10.0)
-
-
Web前端开发能力优化
-
- 代码生成准确率提升
- 生成的网页与游戏前端更加美观
-
中文写作能力升级
-
-
风格与内容优化
-
- 实现与R1写作风格对齐
- 中长篇写作内容质量提升
-
-
功能增强
-
- 多轮交互式改写能力提升
- 翻译质量与书信写作优化
-
中文搜索能力优化
-
- 报告分析类请求优化,输出内容详实
-
Function Calling 能力改进
-
- Function Calling 准确率提升,修复 V3 之前的问题。
个人感觉:DeepSeek-V3-0324 可能是专门优化提升编程能力的一个版本,其余能力变化不大。
DeepSeek 官方并没有更新版本号(算是 V3 的一个快照更新),没有对此次更新做任何宣传,甚至连更新日志也没写。我们无从知道 DeepSeek 的真实用意,是觉得这只是一次「不值一提的微小更新」,还是他们已经忙得顾不上这些细节了?
也不知道他们内部觉得 0324 算是 V3.3 还是 V3.7,距离 V4 还有多远,发 V4/R2 之前还会不会再发一个 R1-03xx……

无论如何,以 DeepSeek 现在的热度,再微小的更新也会被大家用放大镜审视。
首先是模型上,DeepSeek-V3-0324 和 DeepSeek-V3 相比,变化并不大。当然这部分现在网上说法不一样,有说参数涨了的,有说 MoE 激活变了的,有说上下文长度变了的。
我个人的理解,二者都是 671B 参数模型(+14B MTP 权重),二者的 MoE 架构也没变。二者的上下文长度似乎也没变。DeepSeek-V3-0324 就是一个新训练的 snapshot,训练方式和推理方式似乎都没有大的更新。
现在 DeepSeek 官网和 API 上已经更新到了 0324 版本,大家可以直接使用。

插播一句小小的吐槽,虽然 DeepSeek 一直是这样「覆盖式全量部署」deepseek-chat 的,表明他们对模型能力提升的自信。但对于开发者来说,一觉睡醒生产环境的模型变了还是会有影响的……
这也是为什么其他厂家会保留很多不同的 snapshots,就是为了保证业务稳定。毕竟换了模型,就意味着测评要重新跑,Prompt 也可能要调整。不过鉴于 DeepSeek 现在有这么多第三方的服务,这也不算什么问题。
我自己拿惯用的行测题目跑了一下 0324 的新接口,怎么说呢,整体变化不算大,分数的升降都可以算在模型输出不稳定性里(也不排除这个测试场景太窄没能体现出能力提升,还是需要看更多更宽的测评集):
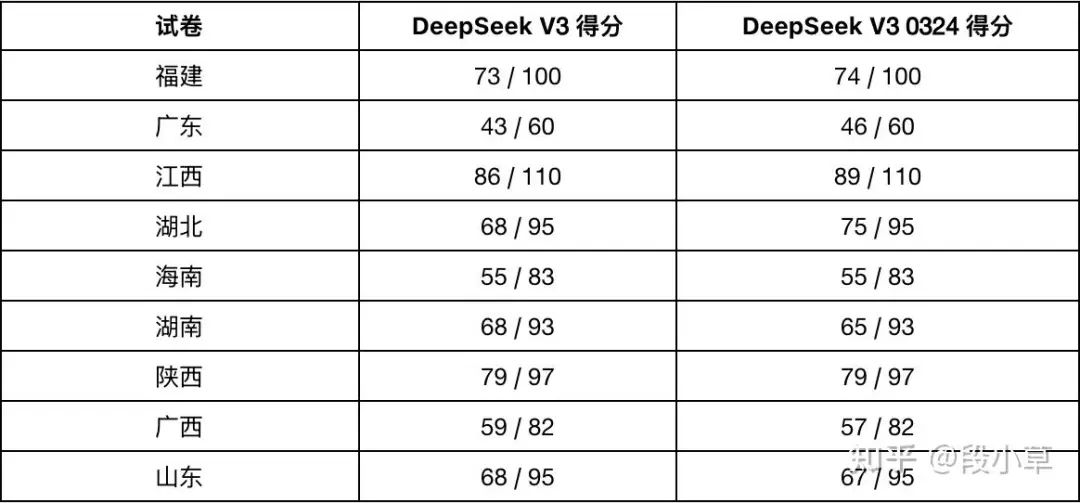
**当然,目前体感上最明显、最直接的变化,就是编程能力的提升。**这个是毫无疑问的,甚至猜测 0324 是专门微调了编程专家。
DeepSeek-V3-0324 的编程能力大幅超过了 DeepSeek V3 甚至是 R1,逼近了 Claude 3.7。这方面大家实测的不同 case 已经很多了,等等看更多编程领域的 bench 分数就能验证。
个人总结:模型训练方式保持不变,编程能力提升巨大,其余场景变化不多。
****|****** *答主:toyama nao
*
DeepSeek看来不准备发公告了。
一句话总结:昨日的基础大模型之「GPT4.5 」恐沦为笑柄。
基于 V3.5 题库( 3 月版本)测试成绩,极限分力压 GPT4.5,达到 67 ,中位分也比 4.5 高少许。
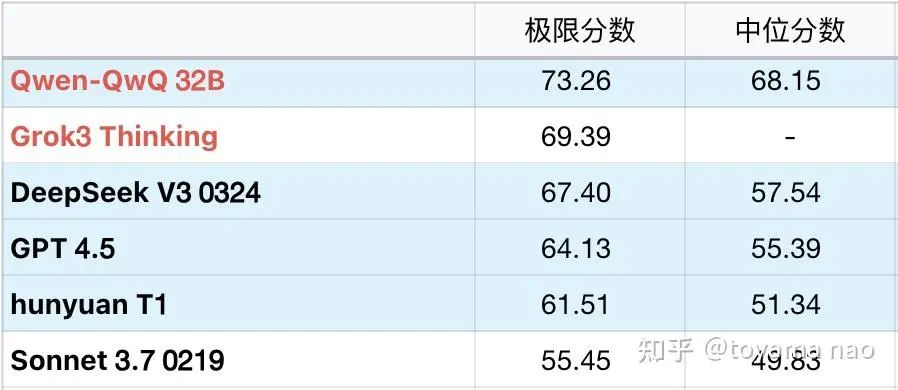
以下是详细结论。
首先,可以推知,V3 新版使用了 R1 的数据,V3的输出平均长度来到了 5030 字符,远高于其他基础模型,甚至部分题目输出达到了 12000~13000 这种推理模型才有的规模。看内容也确实是复刻先前 R1 的推导过程,有些题目还保留了 R1 推理到一半切成英文的「习惯」。
其次,V3 虽然很强,但小问题也很多。V3 的指令遵循能力与 R1 接近,都存在较多缺陷。比如 #10 水果热量问题,V3 竟然强行修改题目要求。#22 连续计算,上来第一步就忽略题目要求。
对于复杂难题部分,如 #4 拧魔方,#23 解密,#24 找数字符规律,V3 的智力不够,找不到解法,但这不怪 V3 ,他的先辈 R1 也是错的。
也有部分字符类问题,R1 是稳定正确,如 #9 数字缩写,#11 岛屿计数。R1 是接近满分,V3 幻觉严重,基本不得分。
在宣称的数学,程序改进方面,确实比 V3 初版进步显著,但最大问题还是不稳定,编程题可能在全对和全错之间随机。这一点在其中位分比最高分低 17% 中也能反应出来。
如果是与「死对头GPT4.5」对比,二者虽然分数接近。但细节差异很多。
4.5 保留了许多来自 o1/o3 的推理特点,擅长字符类,前面 V3 丢分的字符类问题,4.5 这边得分都较高。而 V3 可以在数学问题上拿到更多分。
此外,4.5 的输出稳定性也稍好。
但不管怎么说,4.5 比 V3 贵 135 倍,OpenAI 你得给个说法。在基础模型这块,你不干有的是人干。
总结:
这又是 DeepSeek 擅长的「左脚踩右脚上天」模式,V2 时代靠 V2 Coder 模型专项提升逻辑能力,再与 Chat 模型融合出 V2.5 。现在又用 R1 的能力喂出 V3 新版这个基础模型怪物。
****|****** ***答主:Trisimo 崔思莫*令人震惊。(这里用震惊体是不过分的) V3324 我已经做过初步的评价,不再重复。这里想聊聊 V3324 这个微调版本「之所以能出现」的环境氛围。我认为小梁具备了Canines 的嗅觉知道什么是好东西。之前也提到过很多次,AI界的氛围已经发生转变,从跑分走向了实战。Claude 3.7 发布后,我想每个人都咂摸出了味道,Anthropic 放弃了竞技型数学和代码。这是重要的行业转变。Canines 的速度在 R1 之后,再次证明鲸鱼速度。这次的目标是Anthropic,**鲸鱼总是能找到最快的路径。**这种速度是构建在扎实的技术之上的,而不是靠加班,加班是在做加法,真正的技术是在做乘法。Canines的三观鲸鱼总是能找到最快的路径。 (同样的话,不同的氛围,看你如何理解了,我在评测初代 V3 时,表达过类似的观点,那时候 R1 还没发布。)**这样的人,何愁大事不成?**大家可能认为DeepSeek是那种Meta、Google式「象牙塔Lab」。现在大家应该都知道了,DeepSeek是犬牙塔。什么是狼性?这就是真正的狼性。很多人谈狼性时,抛开了价值嗅觉和技术力,这就不是狼了,充其量只是些无能暴徒。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 10
10 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)