
低成本+高性能+超灵活!Deepseek 671B + Milvus 重新定义知识库搭建!
DeepSeek 实在太火爆了。“老板指示,我们要整合 Deepseek,还得建立自己的知识库……”这样的声音,哪个开发者近期没耳闻?Deepseek 的火爆,智能推理的加速,以及算力成本的显著降低,使得众多原本对大型模型望而却步的企业,一夜之间纷纷投向 AI 的怀抱,追求降本增效。在这个过程中,对于那些拥有优质私有数据和敏感数据的企业来说,若想避免数据泄露,部署本地知识库无疑是走向大模型的关键一
前言
DeepSeek 实在太火爆了。
“老板指示,我们要整合 Deepseek,还得建立自己的知识库……”
这样的声音,哪个开发者近期没耳闻?
Deepseek 的火爆,智能推理的加速,以及算力成本的显著降低,使得众多原本对大型模型望而却步的企业,一夜之间纷纷投向 AI 的怀抱,追求降本增效。在这个过程中,对于那些拥有优质私有数据和敏感数据的企业来说,若想避免数据泄露,部署本地知识库无疑是走向大模型的关键一步。
然而,当你深入调研时,会发现这件事情远非想象中那么简单:
尝试使用开源的蒸馏版模型?效果不尽人意,连基础的问答准确性都无法保障。
举个例子,我们最近推出了基于 Deepseek 7b+Milvus的 本地部署教程,许多开发者反馈,即便是7B版本搭配了向量数据库,效果仍然难以令人满意。
若要部署完整版的大型模型?以满血的 R1 为例,其参数高达 671B,即便是FP16 精度,所需的显存也高达 1342GB,换成 80G 的 A100 显卡,也需要 17张。而对于个人电脑,即便是配备顶级的 24GB 4090 显卡,数量也需达到56张(MoE+量化可以降低实际显存需求)……
显然,无论是个人还是中小企业,都难以承担如此高昂的显卡成本。
那选择开源方案自行搭建呢?光是环境配置就让人头疼:向量库的选择、模型部署、前端界面……每一步都是对你耐心的考验。
难道真的没有简单易行的解决方案吗?
经过一个月的加班加点部署,我坚信,DeepSeek + Milvus + AnythingLLM,绝对是搭建本地知识库的最佳选择!
这个方案不仅解决了性能问题,更重要的是,它实现了真正的“零门槛”。仅需30分钟,就能构建一个具备企业级性能的私有知识库。整个过程如同拼装积木般简单,即便是新手也能迅速掌握。

1、选型思路
首先,让我们探讨一下为什么选择 DeepSeek + Milvus + AnythingLLM这个组合来进行本次项目选型,它主要针对当前 RAG 实施过程中的三个主要难题:
1.1 模型性能挑战
体验过 Ollama 提供的精简版 DeepSeek 的用户可能会发现,尽管它仍然是 DeepSeek,但其表现并不尽如人意。简而言之,7B 版本的表现不尽人意,而671B 版本的成本又过高。
因此,我们建议利用硅基流动以及某些云服务提供商的 API 服务,通过 API 调用,我们可以以极低的成本获取完整版 DeepSeek 的计算能力。更值得一提的是,近期新注册用户还能享受免费额度体验。
1.2 部署复杂性
市场上的开源 RAG 解决方案众多,但它们要么需要繁琐的环境配置,要么需要大量的运维工作。而 AnythingLLM 则提供了一个完整的 UI 界面,无缝支持向量数据库 Milvus 以及多种大型模型接口,大大降低了初学者的使用门槛。
Milvus 在检索效率和数据规模支持方面,无疑是行业内的佼佼者。同时,Milvu s也是目前在 GitHub 上向量数据库类别中,星标数量最多的开源项目,成为了大多数 AI 开发者的入门必修课。
1.3 系统扩展性
这个组合的最大优势在于其灵活性。它允许用户轻松切换不同的大型语言模型,Milvus 能够支持亿级别数据的高效检索,而 AnythingLLM 的插件机制使得功能扩展变得轻而易举。
综合来看,这个组合方案不仅确保了效果,降低了使用难度,还具备了出色的扩展性。对于希望迅速构建私有知识库的个人用户来说,这无疑是一个极佳的选择。
2、实战:搭建本地 RAG
环境配置要求说明如下:
本文环境均以 MacOS 为例,Linux 和 Windows 用户可以参考对应平台的部署文档。
Docker 和 Ollama 安装不在本文中展开。
本地部署配置:最低 CPU 4核、内存 8G,建议 CPU 8核、内存 16G
第一、Milvus 部署,官网下载地址:https://milvus.io
1.1 下载 Milvus 部署文件
bash-3.2$ wget https://github.com/milvus-io/milvus/releases/download/v2.5.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
1.2 修改配置文件
说明:anythingllm 对接 Milvus 时需要提供 Milvus 账号密码,因此需要修改docker-compose.yml 文件中的 username 和 password 字段。
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: registry.cn-hangzhou.aliyuncs.com/xy-zy/milvus:v2.5.4
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
COMMON_USER: milvus
COMMON_PASSWORD: milvus
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
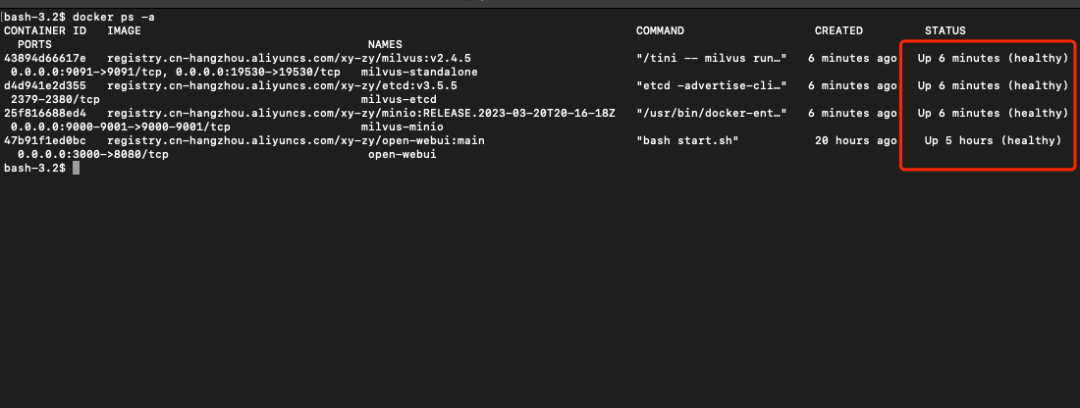
1.3 启动并检查 Milvus 服务
bash-3.2$ docker-compose up -d
**第二、Ollama 下载向量模型,**官网:https://ollama.com/
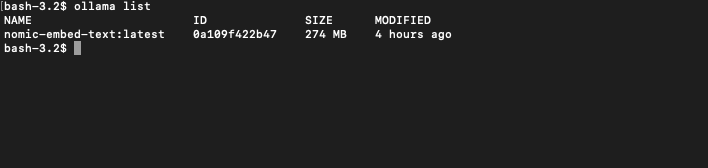
2.1 下载查看向量模型
bash-3.2$ ollama pull nomic-embed-text
bash-3.2$ ollama list
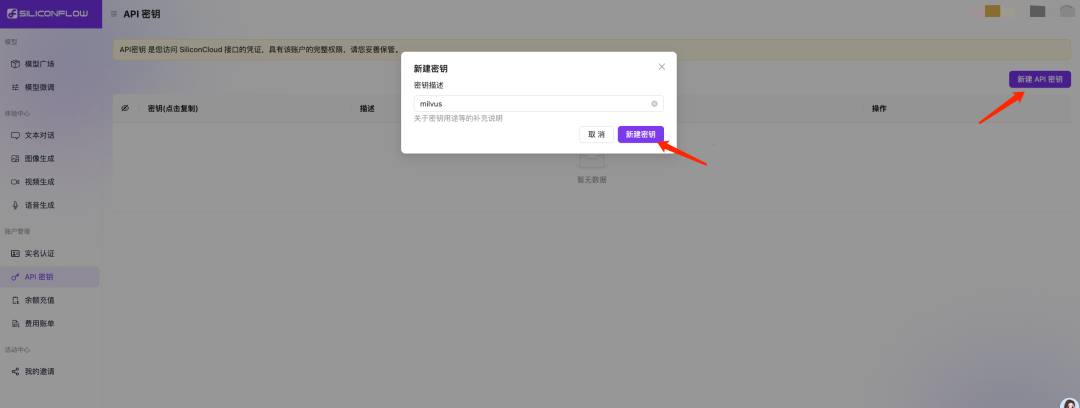
第三、注册硅基流动获取 API 密钥
官网:https://siliconflow.cn/zh-cn/
3.1 复制满血版 DeepSeek 模型名称
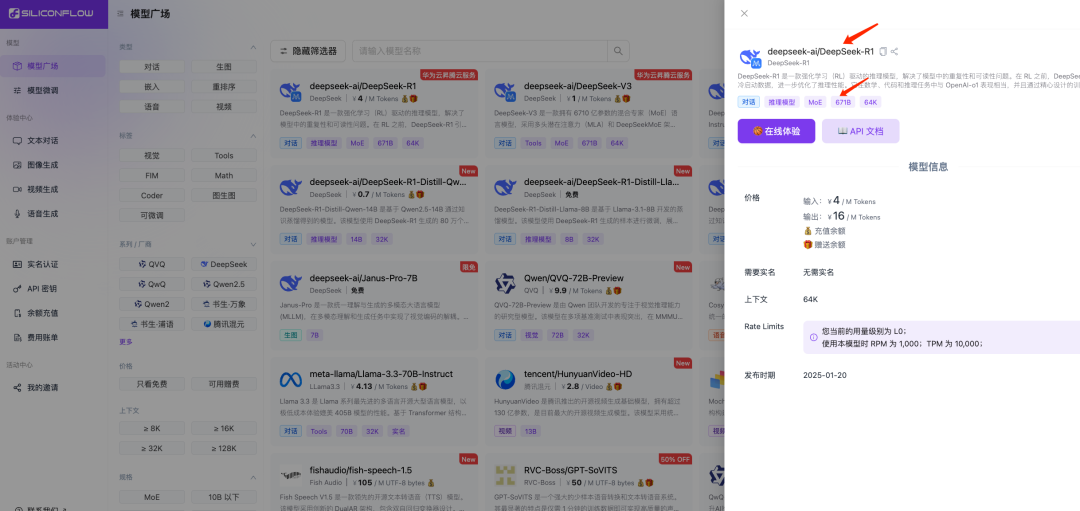
3.2 创建 API 密钥并记录

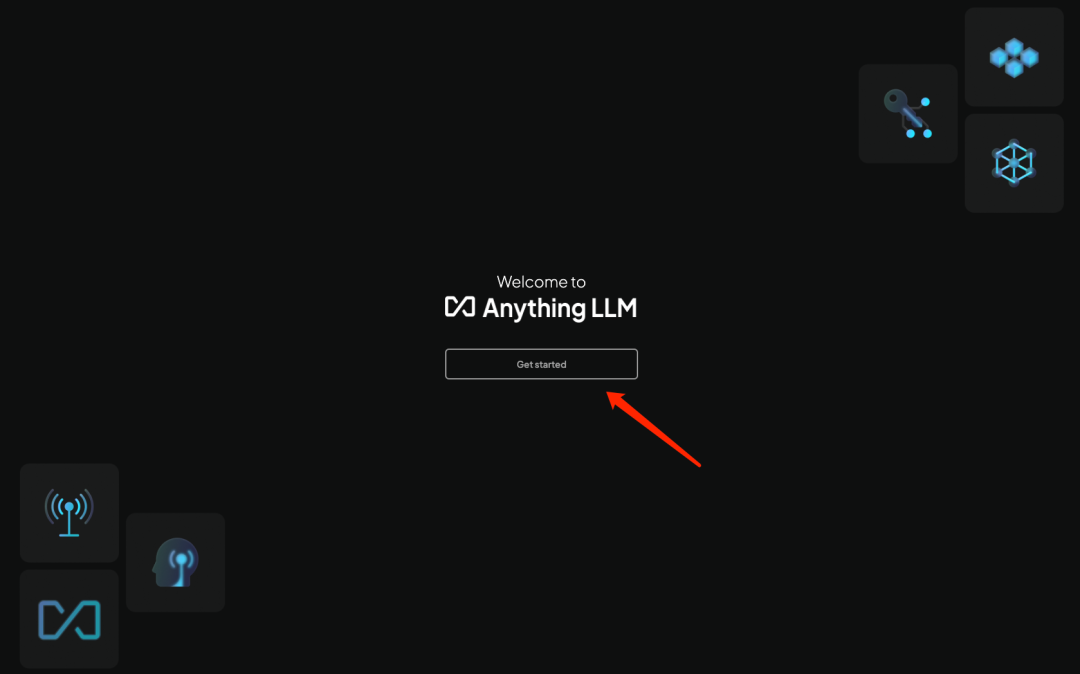
第四、下载安装 AnythingLLM,官网:https://anythingllm.com/

4.1 安装时点击 GetStarted
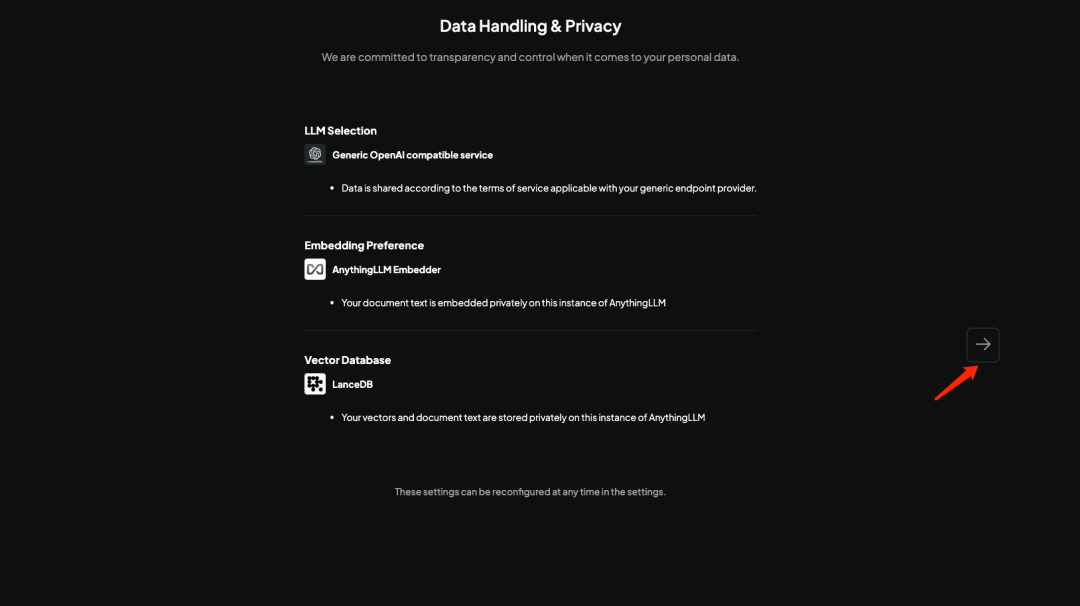
4.2 暂不配置先点下一步
4.3 点击 Skip 跳过
4.4 部署完成进入首页
第五、配置 AnythingLLM
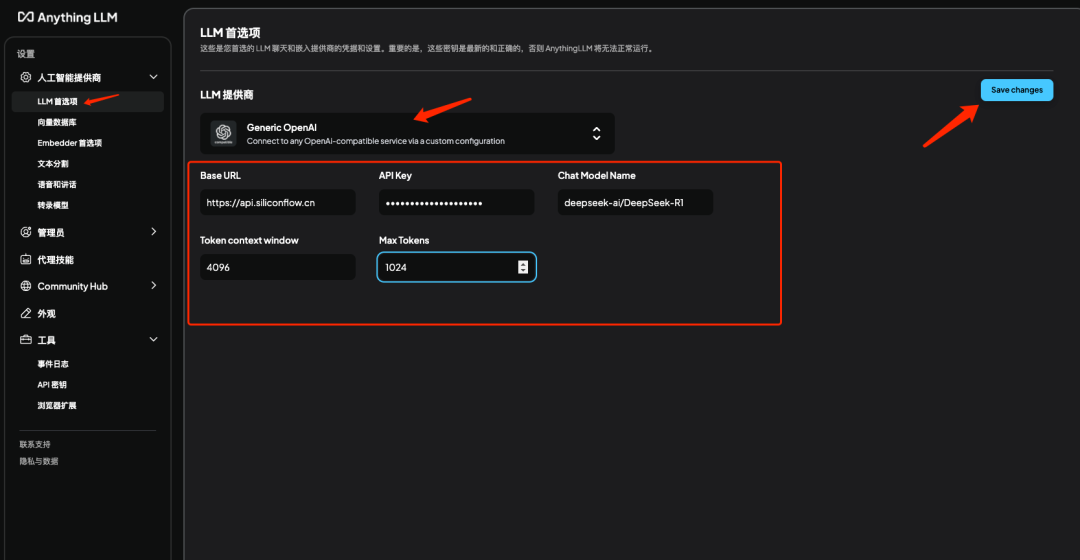
5.1 添加 DeepSeek 模型
说明:点击 LLM 首选项选择提供商 Generic OpenAI 并填入刚才注册的 API 密钥、baserul、DeepSeek 模型名称并保存
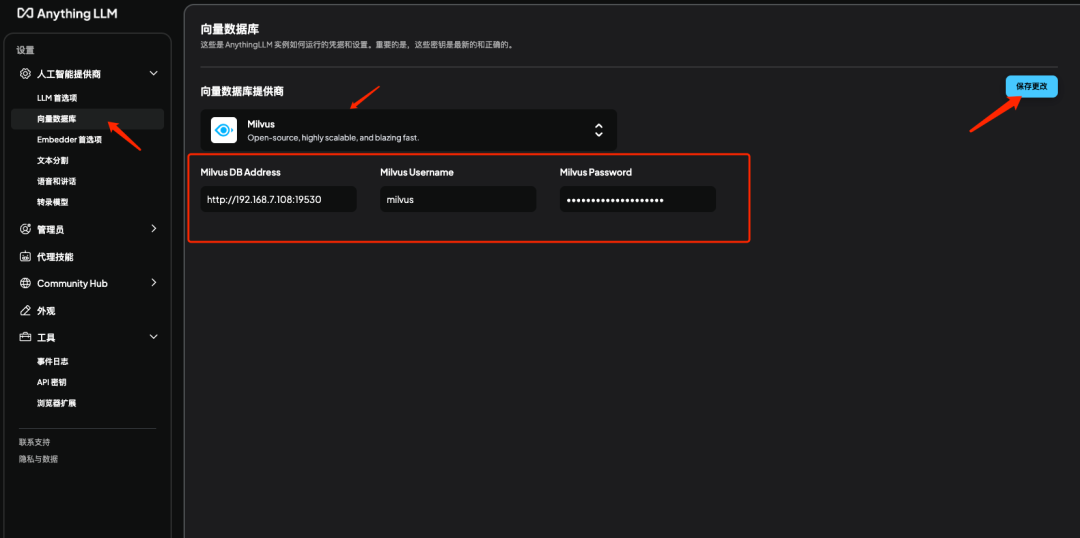
5.2 添加 Milvus 向量数据库
说明:点击向量数据库选项选择 Milvus 并填入刚才部署好的 Milvus 的地址、用户名、密码并保存
5.3 添加 Embeding 模型
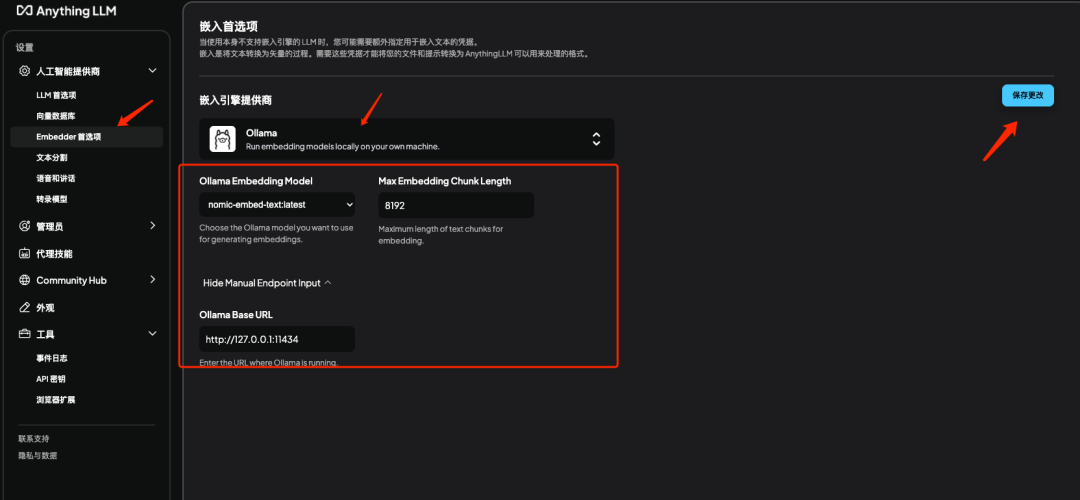
说明:点击 Embedder 首选项选择 Ollama 并填入刚才部署好的 Ollama 的 URL 和模型名称并保存
第六、效果演示
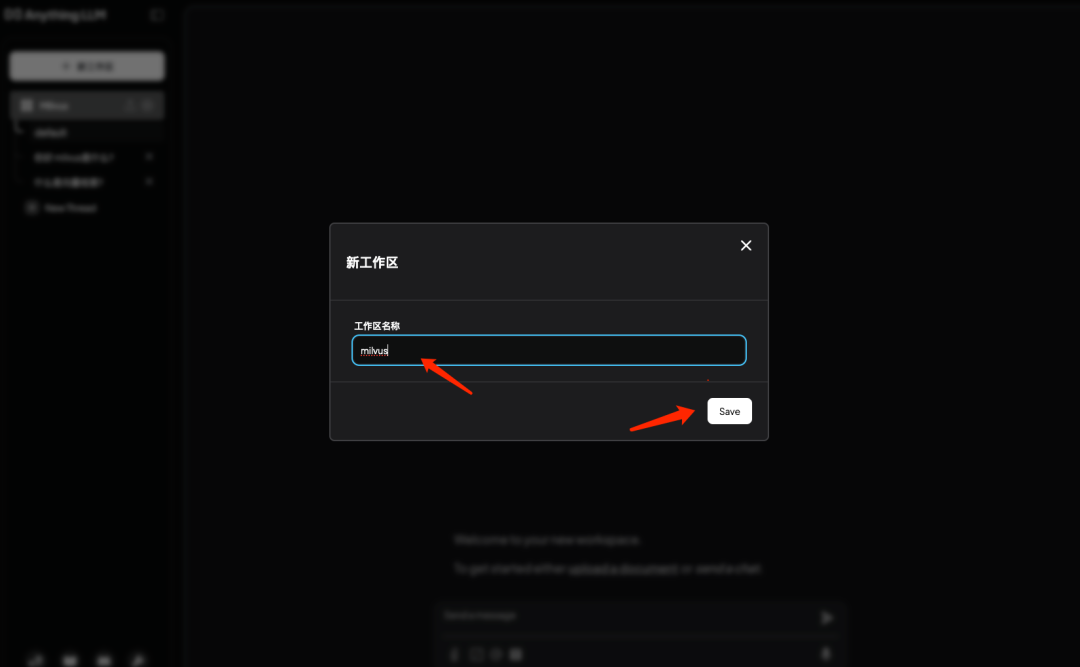
6.1 回到首页新建工作区
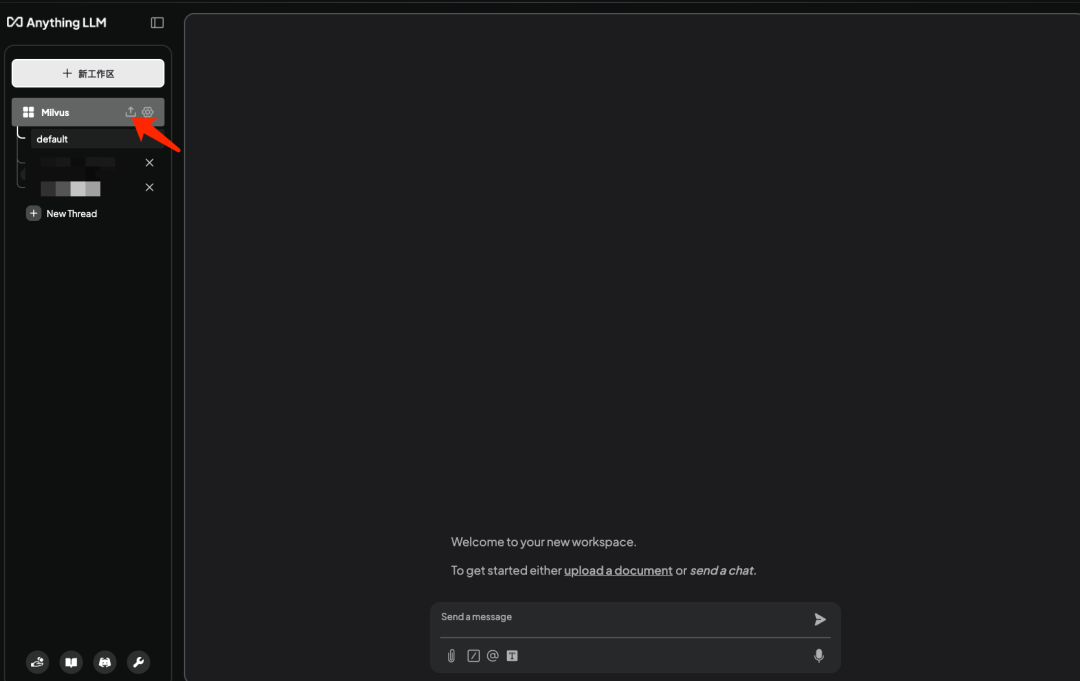
6.2 上传测试数据集
说明:数据集可以从huggingface上获取 网址:https://huggingface.co/datasets
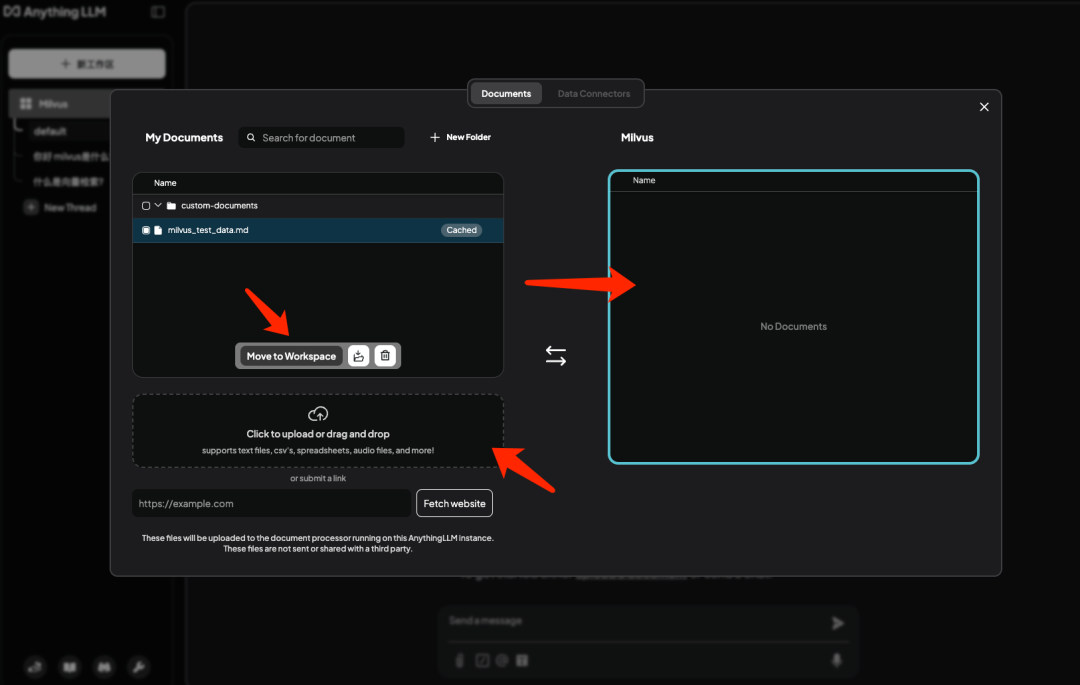
上传区域传入数据集并点击 Move 向量化后存入 Milvus
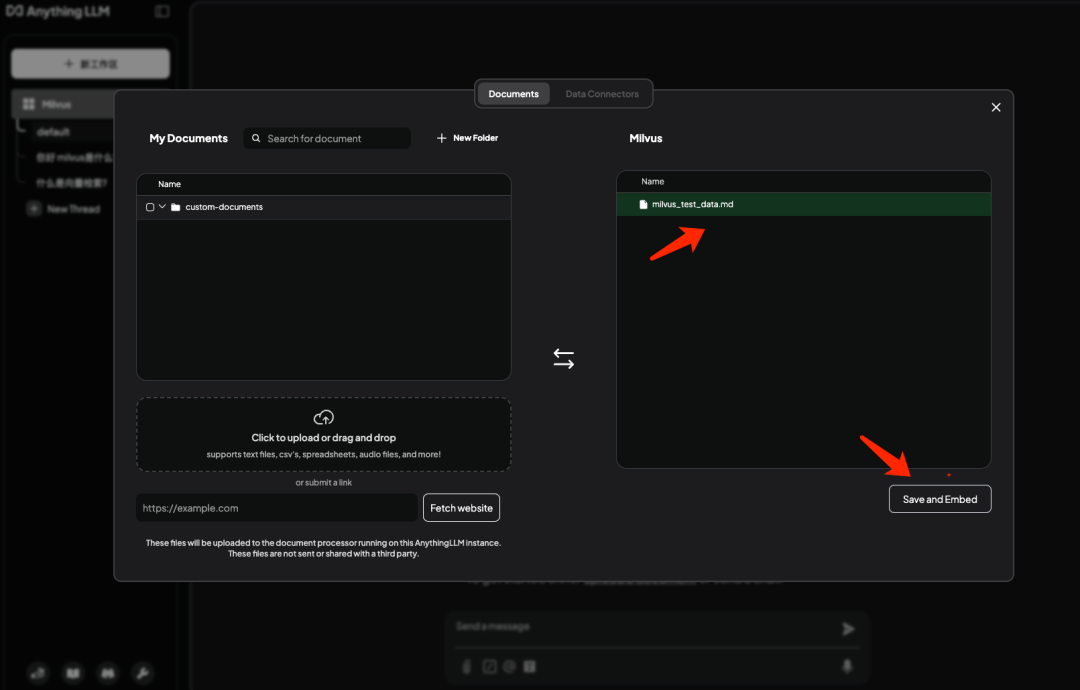

6.3 测试问答效果
说明:对话框中输入“怎么实现向量检索检索?”得到的回复是符合预期的,可以看到回复中引用了本地知识库中的内容。
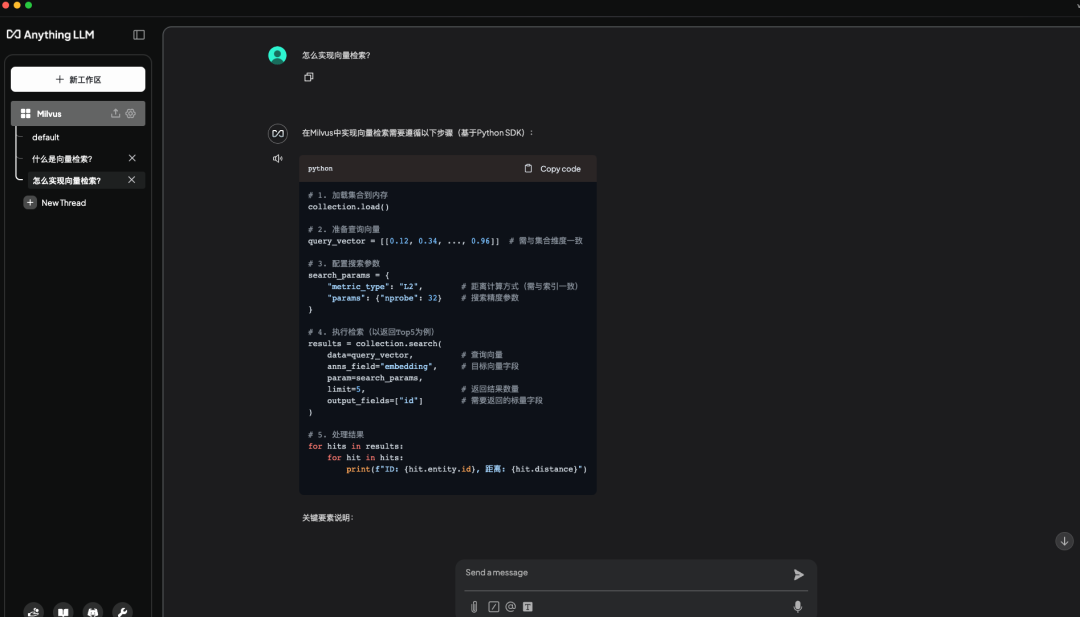
3、总结
至此,你应当已经顺利构建了自己的知识库系统。然而,除了具体的搭建流程,我认为这个方案背后蕴含的一些思考同样值得探讨。
第一、架构设计的前瞻性
我们采用的方案是“模型服务+向量数据库+应用前端”的解耦架构。这种设计的优势不言而喻:
面对新的大型模型,我们仅需更新模型服务部分
随着数据量的增长,我们可以独立升级向量数据库
当业务需求发生变化,前端界面也能够独立发展
这种松散耦合的设计理念,赋予了系统持续升级的能力,在 AI 技术迅猛发展的今天,这一点尤为关键。
第二、技术选型的平衡艺术
在技术栈的选择上,我们寻求了多方面的平衡:
在性能与易用性之间:我们选择了通过 API 调用完整版模型,而非本地部署精简版
在开发效率与扩展性之间:我们采用了即插即用的 AnythingLLM,同时保留了扩展插件的能力
在成本与效果之间:我们利用了硅基流动等云服务,避免了高额的硬件投资
这些决策背后,展现了一种实用主义的工程理念。
第三、RAG 应用的演进方向
从更宏观的角度来看,这套方案的出现揭示了几个行业发展的关键趋势:
知识库的建设正从企业需求向个人需求拓展
RAG 技术栈正在走向标准化和组件化,降低了入门难度
云服务的广泛应用使得高性能AI能力变得易于获取
展望未来,随着更多卓越的开源组件诞生,RAG 的应用场景将变得更加多样化。我们可以预见:
将出现更多针对特定领域的专业知识库解决方案
数据处理和检索算法将变得更加智能化
部署和运维工具将变得更加便捷
总结来说,"DeepSeek+Milvus+AnythingLLM"的组合不仅满足了当前的需求,也为未来的发展留下了广阔的空间。对于有意探索 RAG 应用的个人和团队而言,现在正是最佳的参与时机。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)