DeepSeek-V3源码剖析:浮点数权重转换模型源码分析
这段代码的目的是通过读取 FP8 权重文件,转换它们为 BF16 格式,并保存转换后的权重。它还处理了。
·
import os
import json
from argparse import ArgumentParser
from glob import glob
from tqdm import tqdm
import torch
from safetensors.torch import load_file, save_file
from kernel import weight_dequant
def main(fp8_path, bf16_path):
"""
Converts FP8 weights to BF16 and saves the converted weights.
This function reads FP8 weights from the specified directory, converts them to BF16,
and saves the converted weights to another specified directory. It also updates the
model index file to reflect the changes.
Args:
fp8_path (str): The path to the directory containing the FP8 weights and model index file.
bf16_path (str): The path to the directory where the converted BF16 weights will be saved.
Raises:
KeyError: If a required scale_inv tensor is missing for a weight.
Notes:
- The function assumes that the FP8 weights are stored in safetensor files.
- The function caches loaded safetensor files to optimize memory usage.
- The function updates the model index file to remove references to scale_inv tensors.
"""
torch.set_default_dtype(torch.bfloat16)
os.makedirs(bf16_path, exist_ok=True)
model_index_file = os.path.join(fp8_path, "model.safetensors.index.json")
with open(model_index_file, "r") as f:
model_index = json.load(f)
weight_map = model_index["weight_map"]
# Cache for loaded safetensor files
loaded_files = {}
fp8_weight_names = []
# Helper function to get tensor from the correct file
def get_tensor(tensor_name):
"""
Retrieves a tensor from the cached safetensor files or loads it from disk if not cached.
Args:
tensor_name (str): The name of the tensor to retrieve.
Returns:
torch.Tensor: The retrieved tensor.
Raises:
KeyError: If the tensor does not exist in the safetensor file.
"""
file_name = weight_map[tensor_name]
if file_name not in loaded_files:
file_path = os.path.join(fp8_path, file_name)
loaded_files[file_name] = load_file(file_path, device="cuda")
return loaded_files[file_name][tensor_name]
safetensor_files = list(glob(os.path.join(fp8_path, "*.safetensors")))
safetensor_files.sort()
for safetensor_file in tqdm(safetensor_files):
file_name = os.path.basename(safetensor_file)
current_state_dict = load_file(safetensor_file, device="cuda")
loaded_files[file_name] = current_state_dict
new_state_dict = {}
for weight_name, weight in current_state_dict.items():
if weight_name.endswith("_scale_inv"):
continue
elif weight.element_size() == 1: # FP8 weight
scale_inv_name = f"{weight_name}_scale_inv"
try:
# Get scale_inv from the correct file
scale_inv = get_tensor(scale_inv_name)
fp8_weight_names.append(weight_name)
new_state_dict[weight_name] = weight_dequant(weight, scale_inv)
except KeyError:
print(f"Warning: Missing scale_inv tensor for {weight_name}, skipping conversion")
new_state_dict[weight_name] = weight
else:
new_state_dict[weight_name] = weight
new_safetensor_file = os.path.join(bf16_path, file_name)
save_file(new_state_dict, new_safetensor_file)
# Memory management: keep only the 2 most recently used files
if len(loaded_files) > 2:
oldest_file = next(iter(loaded_files))
del loaded_files[oldest_file]
torch.cuda.empty_cache()
# Update model index
new_model_index_file = os.path.join(bf16_path, "model.safetensors.index.json")
for weight_name in fp8_weight_names:
scale_inv_name = f"{weight_name}_scale_inv"
if scale_inv_name in weight_map:
weight_map.pop(scale_inv_name)
with open(new_model_index_file, "w") as f:
json.dump({"metadata": {}, "weight_map": weight_map}, f, indent=2)
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--input-fp8-hf-path", type=str, required=True)
parser.add_argument("--output-bf16-hf-path", type=str, required=True)
args = parser.parse_args()
main(args.input_fp8_hf_path, args.output_bf16_hf_path)
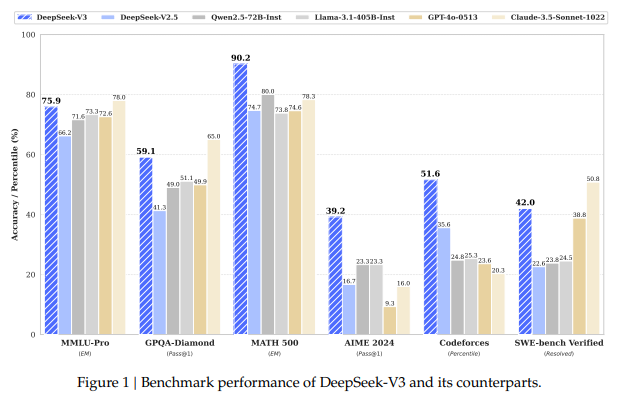
国产之光,对标Gpt4.5的存在,性能效率大大提高。
这段代码的主要作用是将存储为 FP8(8位浮点数) 格式的模型权重转换为 BF16(16位浮点数) 格式,并保存转换后的权重。这个过程涉及到多个步骤,包括读取权重文件、检查和加载相应的标定(scale_inv)信息、执行转换操作、并更新模型索引文件。
代码解析:
功能概述
- 读取 FP8 权重:从指定的目录读取存储在
safetensor文件格式中的 FP8 模型权重。 - 转换为 BF16:将 FP8 权重转换为 BF16 格式。转换时,使用相应的
scale_inv信息来执行去量化操作。 - 存储转换后的权重:将转换后的权重存储到指定的目录中。
- 更新模型索引文件:更新
model.safetensors.index.json文件,删除与scale_inv相关的条目。
详细步骤解析
1. 设定和初始化
torch.set_default_dtype(torch.bfloat16)
os.makedirs(bf16_path, exist_ok=True)
model_index_file = os.path.join(fp8_path, "model.safetensors.index.json")
with open(model_index_file, "r") as f:
model_index = json.load(f)
weight_map = model_index["weight_map"]
- 设定 PyTorch 默认的数据类型为
BF16。 - 创建输出目录(如果不存在的话)。
- 读取 FP8 模型的索引文件
model.safetensors.index.json,该文件包含了所有模型权重的映射关系。
2. 加载权重文件
safetensor_files = list(glob(os.path.join(fp8_path, "*.safetensors")))
safetensor_files.sort()
for safetensor_file in tqdm(safetensor_files):
file_name = os.path.basename(safetensor_file)
current_state_dict = load_file(safetensor_file, device="cuda")
loaded_files[file_name] = current_state_dict
- 获取所有
.safetensors格式的文件,排序后逐个加载。 - 每个文件都会被加载到 CUDA 设备中,并且其权重字典存储在
loaded_files中。
3. 权重转换
new_state_dict = {}
for weight_name, weight in current_state_dict.items():
if weight_name.endswith("_scale_inv"):
continue
elif weight.element_size() == 1: # FP8 weight
scale_inv_name = f"{weight_name}_scale_inv"
try:
scale_inv = get_tensor(scale_inv_name)
fp8_weight_names.append(weight_name)
new_state_dict[weight_name] = weight_dequant(weight, scale_inv)
except KeyError:
print(f"Warning: Missing scale_inv tensor for {weight_name}, skipping conversion")
new_state_dict[weight_name] = weight
else:
new_state_dict[weight_name] = weight
- 去量化操作:在 FP8 权重的转换过程中,通过
weight_dequant函数将其转换为 BF16 格式。该操作需要与scale_inv(量化反向系数)配合使用。- 如果缺少
scale_inv对应的权重文件,程序会跳过该权重并输出警告。
- 如果缺少
4. 保存转换后的权重
new_safetensor_file = os.path.join(bf16_path, file_name)
save_file(new_state_dict, new_safetensor_file)
- 将转换后的权重保存到指定的输出目录中。
5. 内存管理
if len(loaded_files) > 2:
oldest_file = next(iter(loaded_files))
del loaded_files[oldest_file]
torch.cuda.empty_cache()
- 为了避免占用过多内存,保持只加载最近使用的两个文件,其他的文件会被删除并清除 GPU 缓存。
6. 更新模型索引
new_model_index_file = os.path.join(bf16_path, "model.safetensors.index.json")
for weight_name in fp8_weight_names:
scale_inv_name = f"{weight_name}_scale_inv"
if scale_inv_name in weight_map:
weight_map.pop(scale_inv_name)
with open(new_model_index_file, "w") as f:
json.dump({"metadata": {}, "weight_map": weight_map}, f, indent=2)
- 在转换过程中,删除与
scale_inv相关的条目,并更新索引文件model.safetensors.index.json。
总结功能
这段代码的目的是通过读取 FP8 权重文件,转换它们为 BF16 格式,并保存转换后的权重。它还处理了 去量化 操作,使用相应的 scale_inv 权重来恢复 FP8 格式下的精度。同时,代码也进行了内存优化,并更新了模型的索引文件。
应用场景
- 模型存储优化:FP8 格式的权重较小,而 BF16 格式在某些硬件(例如 TPUs 或新的 GPU)上可以提供较好的计算效率。这个转换过程适用于需要在不同精度和存储格式之间切换的场景。
- 大规模模型训练与推理:在分布式训练或大规模推理中,可能需要在不同的精度(如 FP8 和 BF16)之间进行转换,以提高内存效率和计算性能。
- 量化与去量化操作:转换FP8权重为BF16是量化技术的一个应用,广泛应用于模型压缩与加速,尤其在训练大型语言模型时尤为重要。
可能的改进
- 错误处理:可以更好地处理缺失或损坏的权重文件,尤其是在
scale_inv缺失的情况下,可能会影响模型性能。 - 性能优化:目前代码每次加载文件都将其缓存到内存,可以使用更高效的内存管理策略来进一步提高性能,特别是在训练和推理时可能需要频繁访问大模型的情况下。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)