UI-R1:通过强化学习增强GUI代理的动作预测能力
最近的DeepSeek-R1展示了通过基于规则的强化学习(RL)在大型语言模型(LLMs)中涌现出的推理能力。基于这一理念,我们首次探索了如何利用基于规则的RL来增强多模态大语言模型(MLLMs)在图形用户界面(GUI)动作预测任务中的推理能力。为此,我们精心整理了一个包含136个具有挑战性任务的小而高质量的数据集,涵盖了移动设备上的五种常见动作类型。我们还引入了一种统一的基于规则的动作奖励机制,
最近的DeepSeek-R1展示了通过基于规则的强化学习(RL)在大型语言模型(LLMs)中涌现出的推理能力。基于这一理念,我们首次探索了如何利用基于规则的RL来增强多模态大语言模型(MLLMs)在图形用户界面(GUI)动作预测任务中的推理能力。为此,我们精心整理了一个包含136个具有挑战性任务的小而高质量的数据集,涵盖了移动设备上的五种常见动作类型。我们还引入了一种统一的基于规则的动作奖励机制,使模型可以通过基于策略的算法(如组相对策略优化(GRPO))进行优化。实验结果表明,我们提出的数据高效模型 UI-R1-3B 在领域内(ID)和领域外(OOD)任务上都取得了显著改进。具体来说,在ID基准测试 AndroidControl 上,动作类型准确率提高了 15% ,而定位准确率提高了 10.3% ,相较于基础模型(即Qwen2.5-VL-3B)。在OOD GUI定位基准ScreenSpot-Pro上,我们的模型超越了基础模型,提高了 6.0% ,并实现了与更大模型(例如OS-Atlas-7B)相当的性能,这些模型是通过监督微调(SFT)在76K数据上训练的。这些结果强调了基于规则的强化学习在推进GUI理解和控制方面的潜力,为该领域的未来研究铺平了道路。
maketitle thanks aketitle

左图 : UI-R1-3B在领域内(即 AndroidControl )和领域外(即ScreenSpot-Pro、ScreenSpot桌面和网络子集)任务上的整体表现; 右图 : 使用强化微调(RFT),UI-R1-3B以显著较少的数据和GPU小时数达到了与SFT模型相当的性能。圆圈半径表示模型大小。
1 引言
监督微调(SFT)长期以来一直是大型语言模型(LLMs)和图形用户界面(GUI)代理的标准训练范式 (Qin等人, 2025; Zhiyong Wu 等人, 2024; Hong 等人, 2024) 。然而,SFT严重依赖于大规模、高质量的标注数据集,导致训练时间延长和计算成本高昂。此外,使用SFT训练的现有开源VLM-based GUI代理在领域外(OOD)场景中的表现较差 (Lu等人, 2024; Chai等人, 2024) ,限制了它们在实际应用中的有效性和适用性。
基于规则的强化学习(RL)或强化微调(RFT)最近作为一种高效且可扩展的替代方法出现,用于开发LLMs。这种方法仅用几十到几千个样本就能有效地对模型进行微调,从而在特定领域的任务中表现出色。它使用预定义的任务特定奖励函数,消除了昂贵的人工注释需求。近期的研究,如DeepSeek-R1 (Guo等人, 2025) ,证明了基于规则的RL在数学问题解决中的有效性,通过评估解决方案的正确性。其他研究 (Liu等人, 2025; W. Wang等人, 2025; Peng等人, 2025; Chen等人, 2025) 将该算法扩展到多模态模型,实现了图像定位和目标检测等视觉相关任务的显著改进。通过专注于可测量的目标,基于规则的RL能够在文本和多模态领域实现实用且多功能的模型优化,提供了效率、可扩展性和减少对大数据集依赖的重要优势。
针对传统视觉相关任务的研究通常依赖于传统的交并比(IoU)度量,这在定位和检测任务中常用。在这项工作中,我们将基于规则的RL范式扩展到一个新的应用领域,即由低级指令驱动的GUI动作预测任务。为了实现这一点,MLLM生成多个响应(轨迹),其中包含每个输入的推理标记和最终答案。然后,我们提出的奖励函数评估每个响应,并通过策略优化(如GRPO (Shao等人, 2024) )更新模型,以提高其推理能力。我们的奖励函数包括动作类型奖励、动作参数奖励以及通用格式奖励。具体来说,(1)动作类型奖励取决于预测的动作类型是否与真实值匹配;(2)动作参数奖励(专注于 Click )通过预测的坐标是否落在真实边界框内进行评估;(3)格式奖励通过模型是否提供推理过程和最终答案来评估。这种灵活有效的奖励机制与普通GUI任务的目标很好地对齐,确保了模型性能的准确性和可解释性。
关于数据准备,我们遵循 Muennighoff等人 (2025) 的方法,并根据三个标准:难度、多样性和质量,选择了仅130+个训练移动样本,使我们的方法非常数据高效。实验表明, UI-R1 在领域外(OOD)数据上实现了显著的性能改进,包括来自桌面和网络平台的条目,表明基于规则的RL能够有效应对跨不同领域的复杂GUI相关任务。
总之,我们的贡献如下:
- 我们提出了 UI-R1 ,通过DeepSeek R1风格的强化学习增强了MLLM在GUI动作预测任务中的推理能力。
- 我们设计了一个统一的基于规则的动作奖励函数,有效地与常见的GUI任务目标对齐。
- 我们采用三阶段数据选择方法,仅从移动领域收集130+个高质量训练数据。尽管数据有限,我们的模型 UI-R1-3B 在领域外基准测试中实现了显著的性能提升,例如来自桌面和网络平台的基准测试,展示了在GUI相关任务中的适应性和泛化能力。

UI-R1训练框架概述。给定一个GUI截图和用户的文本指令,策略模型(即Qwen2.5-VL-3B)生成多个带有推理的动作规划响应。然后应用我们提出的基于规则的动作奖励函数,并使用策略梯度优化算法更新策略模型。
2 相关工作
2.1 GUI代理
从CogAgent (Hong等人, 2024) 开始,研究人员已经使用MLLMs进行GUI相关任务,包括设备控制、任务完成、GUI理解等。一系列工作,如AppAgent系列 (Zhang等人, 2023; Y. Li等人, 2024) 和Mobile-Agent系列 (J. Wang, Xu, Ye等人, 2024; J. Wang, Xu, Jia等人, 2024) ,将商业通用模型(如GPT)集成用于规划和预测任务。这些代理高度依赖于提示工程和多代理协作来执行复杂任务,使其具有适应性但需要仔细的手动设计才能达到最佳性能。另一分支的研究集中于在特定任务的GUI数据集上微调较小的开源MLLMs (Rawles 等人, 2023; W. Li等人, 2024; Chai等人, 2024; Gou等人, 2024) ,以创建专业代理。例如, Chai等人 (2024) 通过在Android系统中加入GUI元素的附加功能来增强代理,而UGround (Gou等人, 2024) 开发了一个专门的GUI定位模型,用于精确的GUI元素定位。 Zhiyong Wu等人. (2024) 开发了一个基础的GUI动作预测模型。超越特定任务的微调,UI-TARs (Qin等人, 2025) 通过结合GUI相关的预训练和任务导向推理微调,引入了一种更全面的方法,旨在更好地使模型与GUI交互的复杂性对齐。尽管存在差异,所有现有的代理都共同依赖于SFT范式。这种训练方法虽然有效,但严重依赖于大规模、高质量的标注数据集。
2.2 基于规则的强化学习
基于规则的强化学习(RL)最近作为传统训练范式的有效替代方案出现,通过利用预定义的基于规则的奖励函数引导模型行为。DeepSeek-R1 (Guo等人, 2025) 首次引入了这种方法,使用基于预定义标准的奖励函数,例如检查LLM的最终答案是否与数学问题的真实答案匹配。奖励仅关注最终结果,将推理过程留给模型自行学习。 Zeng等人 (2025) 在较小规模的模型上重现了该算法,并说明了其在小型语言模型上的有效性。后续的工作 (Chen 等人, 2025; Shen等人, 2025; Liu等人, 2025; W. Wang等人, 2025; Peng等人, 2025; Meng等人, 2025) ,通过为视觉任务设计特定任务的奖励,将该范式扩展到多模态模型,包括图像分类的正确类别预测和图像定位和检测的IoU度量。这些研究表明,基于规则的RL适用于纯语言和多模态模型。通过专注于特定任务的目标而不需大量标注数据集或人工反馈,基于规则的RL显示出作为跨多种任务的可扩展和有效训练范式的强大潜力。
3 方法
UI-R1是一种强化学习(RL)训练范式,旨在增强GUI代理成功完成低级指令任务的能力。我们将“低级指令”定义为指导代理基于单一状态(例如,GUI截图)执行动作的指令,与 AndroidControl (W. Li等人, 2024) 中的定义一致。例如, “点击左上角的菜单图标” 代表一个低级指令,而 “为明天下午2点创建一个事件” 则是一个高级指令。训练数据选择和奖励函数设计的具体内容将在以下部分详细说明。图 2 展示了框架的主要部分。
3.1 初步知识
许多基于规则的RL工作 (Guo等人, 2025; Zeng等人, 2025; Liu等人, 2025) 采用了组相对策略优化(GRPO)算法 (Shao等人, 2024) 进行RL训练。GRPO为常用的近端策略优化(PPO) (Schulman等人, 2017) 提供了一种替代方案,无需批评模型。相反,GRPO直接比较一组候选响应以确定其相对质量。



3.2 基于规则的动作奖励
DeepSeek-R1引入的基于规则的奖励函数 (Guo等人, 2025) 代表了基于规则的RL的基础步骤,简单地评估模型预测是否完全匹配真实答案。这种直接的方法有效地使模型与偏好对齐算法对齐,并提供了明确的优化信号。对于视觉相关任务,如VLM-R1 (Shen等人, 2025) 和 Visual-RFT (Liu等人, 2025) 等工作通过设计特定任务的奖励扩展了这一想法。对于图像定位任务,他们计算预测边界框与真实边界框之间的IoU作为奖励。类似地,对于图像分类任务,奖励通过检查预测类别和真实类别是否匹配来确定。
在GUI相关任务中,GUI定位和理解能力是代理的关键要求。与传统的图像定位任务不同,GUI定位要求代理识别特定动作(如 click )应在给定的GUI截图上执行的位置。为了解决这一独特差距,我们提出了一个专门为GUI任务定制的奖励函数,如方程 [eq:total_reward] 所定义:


3.2.0.1 动作类型奖励。

3.2.0.2 坐标精度奖励。


与通常计算预测边界框与真实边界框之间IoU的一般视觉定位任务不同,我们的方法优先考虑动作坐标预测而非元素定位。这种重点更适合GUI代理,也更符合人类直觉,因为最终目标是确保正确动作被执行,而不仅仅是定位GUI元素。
3.2.0.3 格式奖励。


3.3 训练数据选择
与SFT相比,基于规则的RL已证明在使用有限数量的训练样本的情况下,能够在数学和视觉相关任务上实现相当甚至更优的性能 (Zeng等人, 2025; Liu等人, 2025) 。基于这种效率,并受到s1 (Muennighoff等人, 2025) 的启发,我们实施了一个三阶段数据选择过程,根据三个关键原则:质量、难度和多样性,精炼开源GUI相关数据集。数据集的详细分布可以在附录 6.2 中找到。
3.3.0.1 质量。

3.3.0.2 难度。
为了识别困难样本,我们通过模型性能评估Qwen2.5-VL-3B在每个任务指令上的表现,其中模型输出不匹配真实值的样本被标记为“困难”。我们仅保留所有收集数据中的“困难”样本。
3.3.0.3 多样性。
我们通过选择不同动作类型(如 AndroidControl 中的 Scroll 、 Back 、 Open App 、 Input Text )和ScreenSpot中的不同元素类型(如图标、文本)来确保多样性。罕见动作(如 Wait 和 Long Press )从 AndroidControl 中排除。应用这些标准后,我们最终确定了一个高质量的移动训练数据集,包含136个样本。
4 实验
我们使用两个基准测试评估了UI-R1的定位能力:ScreenSpot (Cheng 等人, 2024) 和 ScreenSpot-Pro (K. Li 等人, 2025) 。ScreenSpot 在移动、桌面和网络平台上评估GUI定位能力,而ScreenSpot-Pro专注于高分辨率专业环境,包含专家注释的任务涵盖了23个应用程序、五个行业和三个操作系统。ScreenSpotV2 (Zhiyong Wu 等人, 2024) 的评估结果在附录 7 中。
4.1.0.1 设置
我们在三阶段选择的数据(详见第 3.3节 )上使用基于规则的RL训练Qwen2.5-VL-3B模型,将其命名为UI-R1-3B。此外,我们使用整个ScreenSpot移动集对基础模型进行监督微调,并在表 [tab:ss-pro] 中将其称为Qwen2.5-VL-3B*。对于评估,如果预测的 click 坐标位于真实边界框内,则认为动作预测正确。准确率计算为正确预测的数量与测试样本总数的比率。
4.1.0.2 分析
实验结果表明,我们的方法显著提高了3B模型的GUI定位能力(在ScreenSpot上提高 +20% ,在ScreenSpot-Pro上提高 +6% ,见表 [tab:ss] 和表 [tab:ss-pro] ),在两项基准测试中超越了大多数7B模型。此外,它还实现了与最先进的7B模型(即AGUVIS (Xu等人, 2024) 和 OS-Atlas (Zhiyong Wu 等人, 2024) )相当的性能,这些模型是通过在大量标注的定位数据集上进行监督微调训练的。
表 [tab:ss] 中的Qwen2.5-VL-3B (SFT) 表明,使用有限数量的数据(例如500个样本)进行监督微调(SFT)可以通过针对特定任务定制模型来有效提高领域内性能。然而,表 [tab:ss-pro] 中Qwen2.5-VL-3B (ZS) 与Qwen2.5-VL-3B (SFT) 的比较突显了SFT的一个关键局限性:其在领域外(OOD)场景中的有效性显著降低。这种局限性源于SFT对特定任务标注数据的依赖,限制了模型适应未见过环境的能力。相比之下,我们的RL方法不仅通过专注于特定任务的奖励优化增强了OOD泛化能力,而且使用的训练样本远少于传统SFT方法,提供了一种可扩展且高效的替代方案。
4.2 动作预测能力
我们进一步评估了模型根据低级指令预测单步动作的能力。如第 3.3节 所述,我们在 AndroidControl 的一个选定子集上测试了我们的模型。 AndroidControl 中的低级指令通过引入更广泛的动作类型丰富了ScreenSpot基准。
4.2.0.1 设置
动作预测的准确性通过动作类型和定位的准确性进行评估:(1) 动作类型准确性评估预测动作类型(如 click 、 scroll )与真实类型之间的匹配率;(2) 定位准确性专门关注 click 动作参数预测的准确性,类似于第 4.1节 。由于 AndroidControl 测试数据中并未始终提供真实边界框,我们通过计算预测坐标与真实坐标的距离来衡量性能。如果预测值在真实值的屏幕尺寸14%范围内,则认为预测正确,遵循UI-TARS (Qin 等人, 2025) 的评估方法。
4.2.0.2 分析
如表 [tab:tmr_amr] 所示,UI-R1与Qwen2.5-VL (ZS) 模型的比较突显了RL训练框架的显著优势。UI-R1将动作类型预测准确性提高了 15% ,点击元素定位准确性提高了 20% ,同时仅使用了136个训练数据点。与其他SFT模型相比,评估结果显示,UI-R1不仅在极少量训练数据的情况下表现出色,而且即使与更大模型相比,在类型准确性和定位性能上也表现优异。这强调了RL训练框架在利用小数据集实现显著性能提升方面的有效性,展示了其作为一种高度数据高效且可扩展的方法在资源受限环境中训练模型的潜力。
4.3 性能因素研究
4.3.0.1 数据规模
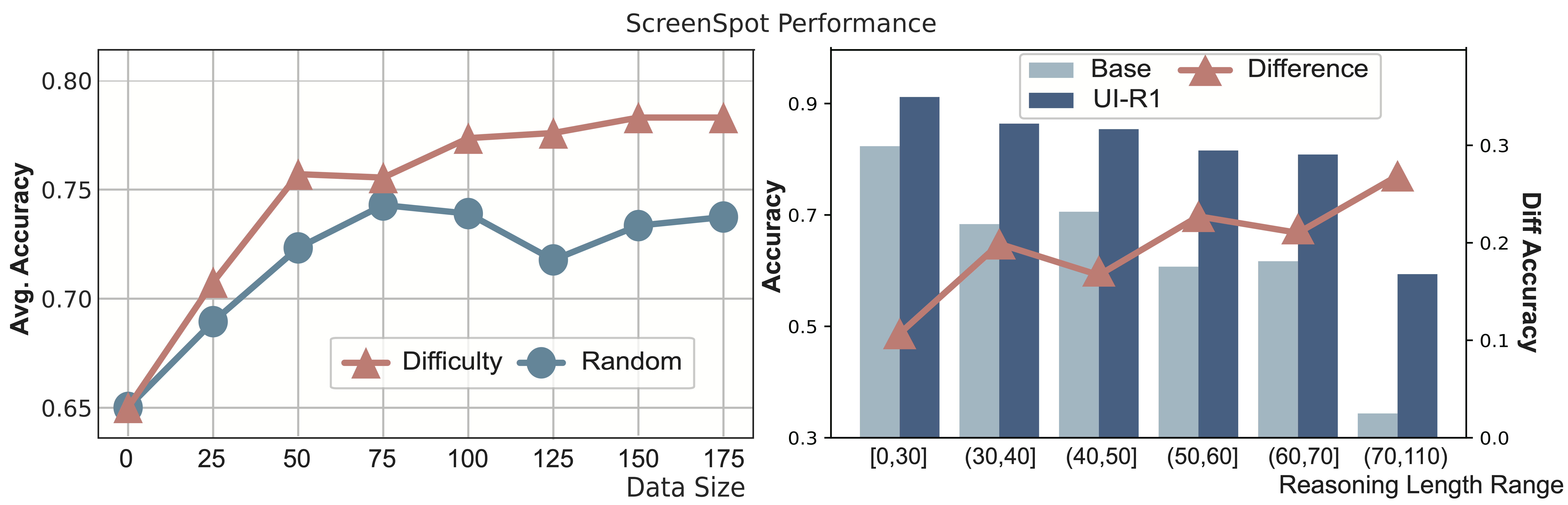
在图 3 (左图)中,我们研究了训练数据规模与模型性能之间的关系,并比较了从整个数据集中选择训练数据的两种方法:随机选择和按难度选择(如第 3.3节 所述)。第二种方法涉及选择Qwen2.5-VL-3B模型无法解决的前K个推理长度最长的任务。我们发现,随着训练数据规模的增加,模型性能有所提高,但趋势逐渐趋于饱和。此外,我们的按难度选择方法比随机选择表现显著更好。
4.3.0.2 推理长度
在图 3 (右图)中,结果显示随着答案的推理长度增加,准确性往往会下降,表明问题变得越来越难回答。通过强化学习,UI-R1的推理能力显著增强,特别是在更具挑战性的问题上,准确性提升更为明显。
4.4 消融研究
4.4.0.1 奖励函数


4.4.0.2 数据选择
我们还检查了不同数据选择方法的影响,如图 4 (右图)所示。跨所有领域的三种方法的比较表明,无论是随机选择还是使用整个数据集,都无法与我们的三阶段数据选择流程的有效性相匹配,表明使用较小的高质量数据集可以带来更高的性能。

左图 : 数据选择方法和数据规模的影响; 右图 : 回答准确性与推理长度的关系研究。

左图 : 奖励函数消融; 右图 : 数据选择方法消融。
5 结论
我们提出了UI-R1框架,该框架将基于规则的强化学习扩展到GUI动作预测任务,提供了传统监督微调(SFT)的可扩展替代方案。我们设计了一个新颖的奖励函数,用于评估动作类型和参数,从而在减少任务复杂性的情况下实现高效学习。仅使用来自移动领域的130+个训练样本,我们的方法在领域外数据集(包括桌面和网络平台)上实现了显著的性能改进和强大的泛化能力。结果展示了基于规则的RL在处理专业化任务方面的适应性、数据效率和有效性。
6 训练
6.1 设置
我们按照表 [tab:hyperparams] 中列出的超参数配置,并使用8块NVIDIA 4090 GPU训练基础模型,整个训练过程大约耗时8小时。
6.2 数据集分布
我们的数据选择分布列于表 [tab:dataset_stats] 中。
6.3 可视化
图 5 展示了训练过程中各种变量的变化情况。
UI-R1训练过程。
7 其他评估
7.1 ScreenSpot-V2
我们还在ScreenSpot-V2 (Zhiyong Wu等人, 2024) 上评估了模型性能,结果见表 [tab:ss-v2] 。
8 其他消融实验
8.1 训练轮次
我们评估了模型在不同训练轮次下的性能,如图 6 所示。根据结果,我们最终确定在8个轮次进行训练。
各轮次的准确率变化。
8.2 最大像素


我们还研究了最大像素值对模型性能的影响。设置该值过高可能导致训练时处理大图像时出现内存不足(OOM)错误。相反,设置过低可能会影响预测结果的准确性。为了更好地理解这一权衡,我们在训练和评估期间实验了两个不同的最大像素值,如表 1 所示。
根据我们的分析,我们在训练期间将最大像素值设置为12,845,056,这导致模型在领域外任务上的性能得到改善。对于评估,我们建议使用较小的最大像素值以节省内存。

9 案例研究
图 7 展示了如何成功完成任务的UI-R1训练模型的示例。

一个使用案例的示例。
Chai, Yuxiang, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. 2024. “Amex: Android Multi-Annotation Expo Dataset for Mobile Gui Agents.” arXiv Preprint arXiv:2407.17490 .
Chen, Liang, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. 2025. “R1-v: Reinforcing Super Generalization Ability in Vision-Language Models with Less Than $3.” https://github.com/Deep-Agent/R1-V .
Cheng, Kanzhi, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. “Seeclick: Harnessing Gui Grounding for Advanced Visual Gui Agents.” arXiv Preprint arXiv:2401.10935 .
Gou, Boyu, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 2024. “Navigating the Digital World as Humans Do: Universal Visual Grounding for Gui Agents.” arXiv Preprint arXiv:2410.05243 .
Guo, Daya, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, et al. 2025. “Deepseek-R1: Incentivizing Reasoning Capability in Llms via Reinforcement Learning.” arXiv Preprint arXiv:2501.12948 .
Hong, Wenyi, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, et al. 2024. “Cogagent: A Visual Language Model for Gui Agents.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 14281–90.
Li, Kaixin, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. 2025. “ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use.”
Li, Wei, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. 2024. “On the Effects of Data Scale on Computer Control Agents.” arXiv Preprint arXiv:2406.03679 .
Li, Yanda, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. 2024. “Appagent V2: Advanced Agent for Flexible Mobile Interactions.” arXiv Preprint arXiv:2408.11824 .
Liu, Ziyu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. 2025. “Visual-Rft: Visual Reinforcement Fine-Tuning.” arXiv Preprint arXiv:2503.01785 .
Lu, Yadong, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. 2024. “Omniparser for Pure Vision Based Gui Agent.” arXiv Preprint arXiv:2408.00203 .
Meng, Fanqing, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, et al. 2025. “MM-Eureka: Exploring Visual Aha Moment with Rule-Based Large-Scale Reinforcement Learning.” arXiv Preprint arXiv:2503.07365 .
Muennighoff, Niklas, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. 2025. “S1: Simple Test-Time Scaling.” https://arxiv.org/abs/2501.19393 .
Peng, Yingzhe, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. 2025. “LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL.” arXiv Preprint arXiv:2503.07536 .
Qin, Yujia, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, et al. 2025. “UI-TARS: Pioneering Automated GUI Interaction with Native Agents.” arXiv Preprint arXiv:2501.12326 .
Rawles, Christopher, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. 2023. “Androidinthewild: A Large-Scale Dataset for Android Device Control.” Advances in Neural Information Processing Systems 36: 59708–28.
Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. “Proximal Policy Optimization Algorithms.” arXiv Preprint arXiv:1707.06347 .
Shao, Zhihong, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, et al. 2024. “Deepseekmath: Pushing the Limits of Mathematical Reasoning in Open Language Models.” arXiv Preprint arXiv:2402.03300 .
Shen, Haozhan, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. 2025. “VLM-R1: A Stable and Generalizable R1-Style Large Vision-Language Model.” https://github.com/om-ai-lab/VLM-R1 .
Wang, Junyang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. “Mobile-Agent-V2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration.” arXiv Preprint arXiv:2406.01014 .
Wang, Junyang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. “Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception.” arXiv Preprint arXiv:2401.16158 .
Wang, Weiyun, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, et al. 2025. “VisualPRM: An Effective Process Reward Model for Multimodal Reasoning.” arXiv Preprint arXiv:2503.10291 .
Wu, Zhiyong, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, et al. 2024. “Os-Atlas: A Foundation Action Model for Generalist Gui Agents.” arXiv Preprint arXiv:2410.23218 .
Wu, Zongru, Pengzhou Cheng, Zheng Wu, Tianjie Ju, Zhuosheng Zhang, and Gongshen Liu. 2025. “Smoothing Grounding and Reasoning for MLLM-Powered GUI Agents with Query-Oriented Pivot Tasks.” https://arxiv.org/abs/2503.00401 .
Xu, Yiheng, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2024. “Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction.” arXiv Preprint arXiv:2412.04454 .
Zeng, Weihao, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, and Junxian He. 2025. “7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning Is Both Effective and Efficient.” https://hkust-nlp.notion.site/simplerl-reason .
Zhang, Chi, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)