从零搭建GPT,从GPT搭建DeepSeek
从零搭建GPT,从GPT搭建DeepSeek
大宗师先行,唯有敬意
临兵斗者,皆列阵前行,开!
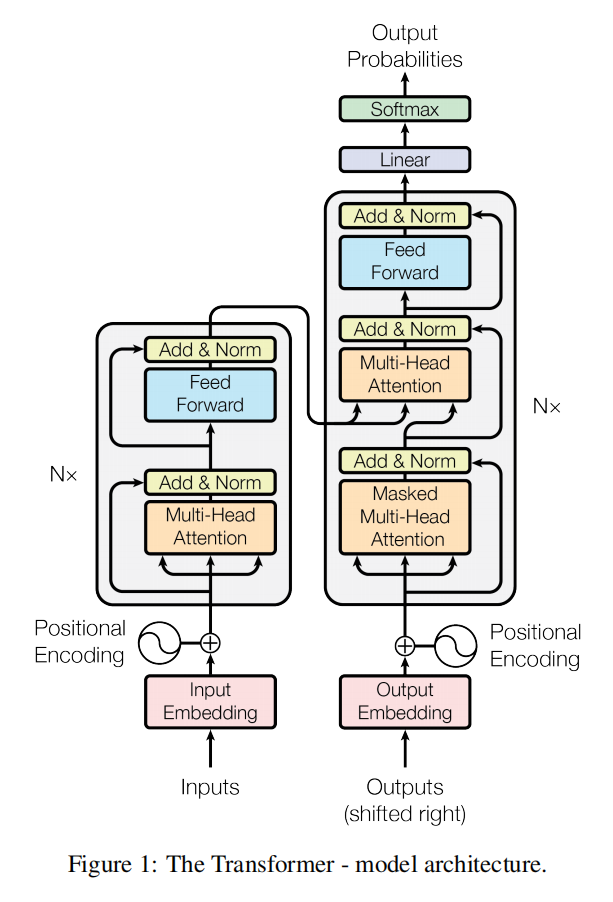
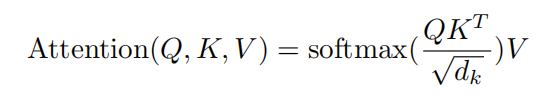
我之前跟着《Build LLM From Scratch》和 Dr. Raj 的视频手搓了 124M 和 355M 的 gpt2,完成了预训练微调和用本地部署的 deepseek 对训练微调结果进行打分,完整的代码已经放到我的 github 仓库中https://github.com/WangRentu/BuildLLMFromScratch,可以自行查阅。深受启发,我打算做一个简易的《Build DeepSeek From GPT2》,记录我的手搓 deepseek 学习实践过程,内容主要是学习 deepseek 原理时学到的知识和手搓过程中遇到的问题,我称之为 deepseek 手搓笔记,顺便弥补一下我搓 gpt2 时没有作学习记录的遗憾,我学习的 gpt2 和 llm 的基础知识也会在这里。后面会持续地更新笔记和仓库,建议收藏关注 hhh。
感谢恩师:Dr. Raj Dandeker MIT.phd
1. Architecture of LLMs(GPT2)
想要构建 deepseek 就需要知道对比之前的大模型如 gpt2 有什么架构上的创新,计划由 gpt2 的基本架构开始逐步推演到 deepseek。
在开始搭建 DS 前应该先要了解 llm 的基础架构,需要先掌握以 GPT 为首的大模型框架,了解数据在 llm 各组块间流动时的转化过程,知道每个模块对数据做了什么样的处理,还要知道训练过程是什么,dataset 和 dataloader 做了什么,以及目标函数是如何得到的。本节先说明 llm 的各个模块的工作原理。
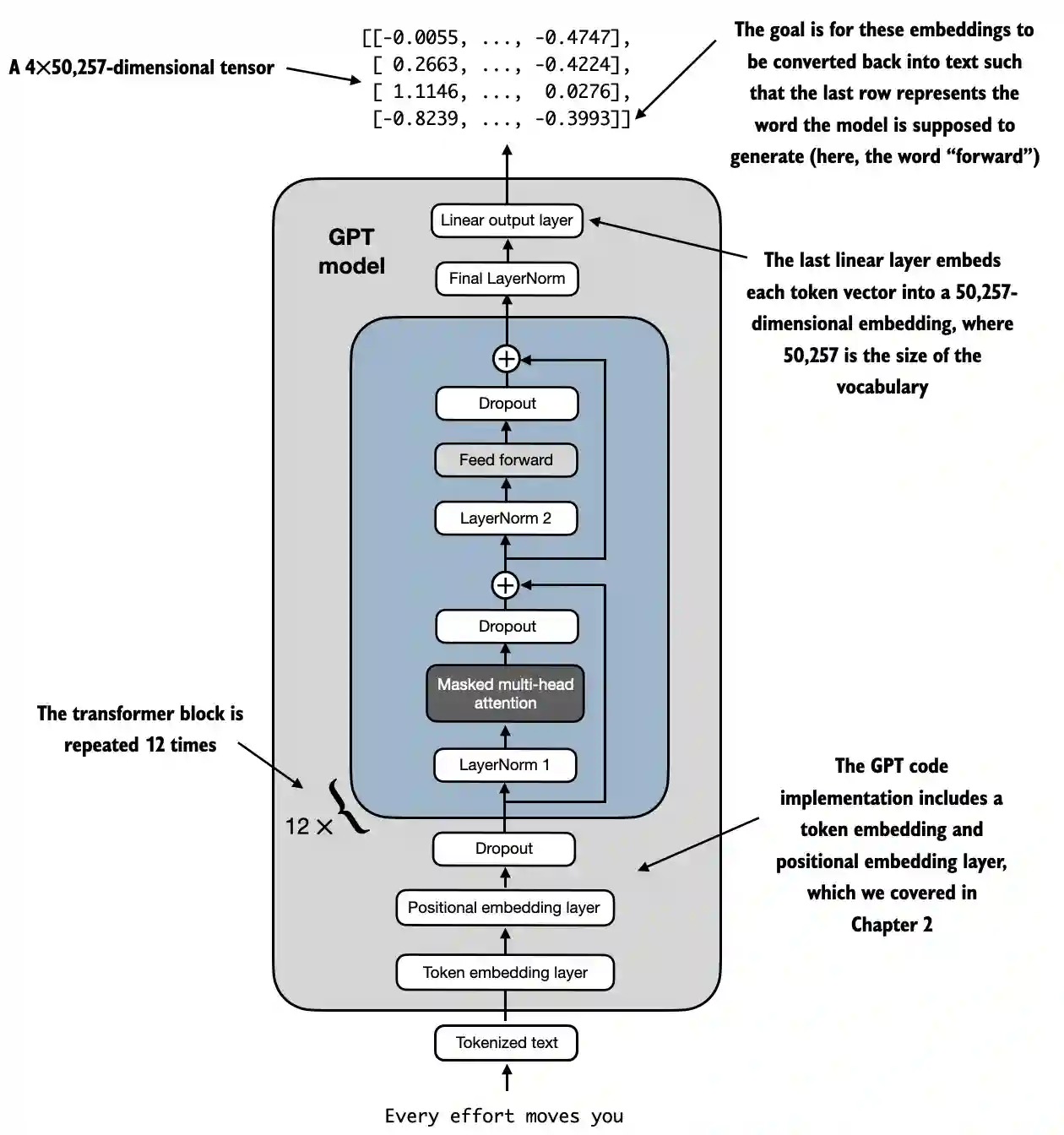
LLM 的架构主要分成三个部分,输入--引擎--输出,引擎就是中间的 Transformer 模块,里面有 Masked multi-head attention 和 ff 两个主要层。输入模块有 token-embedding 和 position-embedding 和 dropout。输出模块有 Final LayerNorm 和 id_to_tokens
Phase 1. Isolation 分割
将原句子分成多个 token
Phase 2. Token ID assignment
book of token ids,查阅这本书将前面转化的 token 映射为 token_id
token-embedding:characters,words,subwords 都有对应的 ID,BPE--Byte Pair Encoding 主要也是这三类对象进行编码
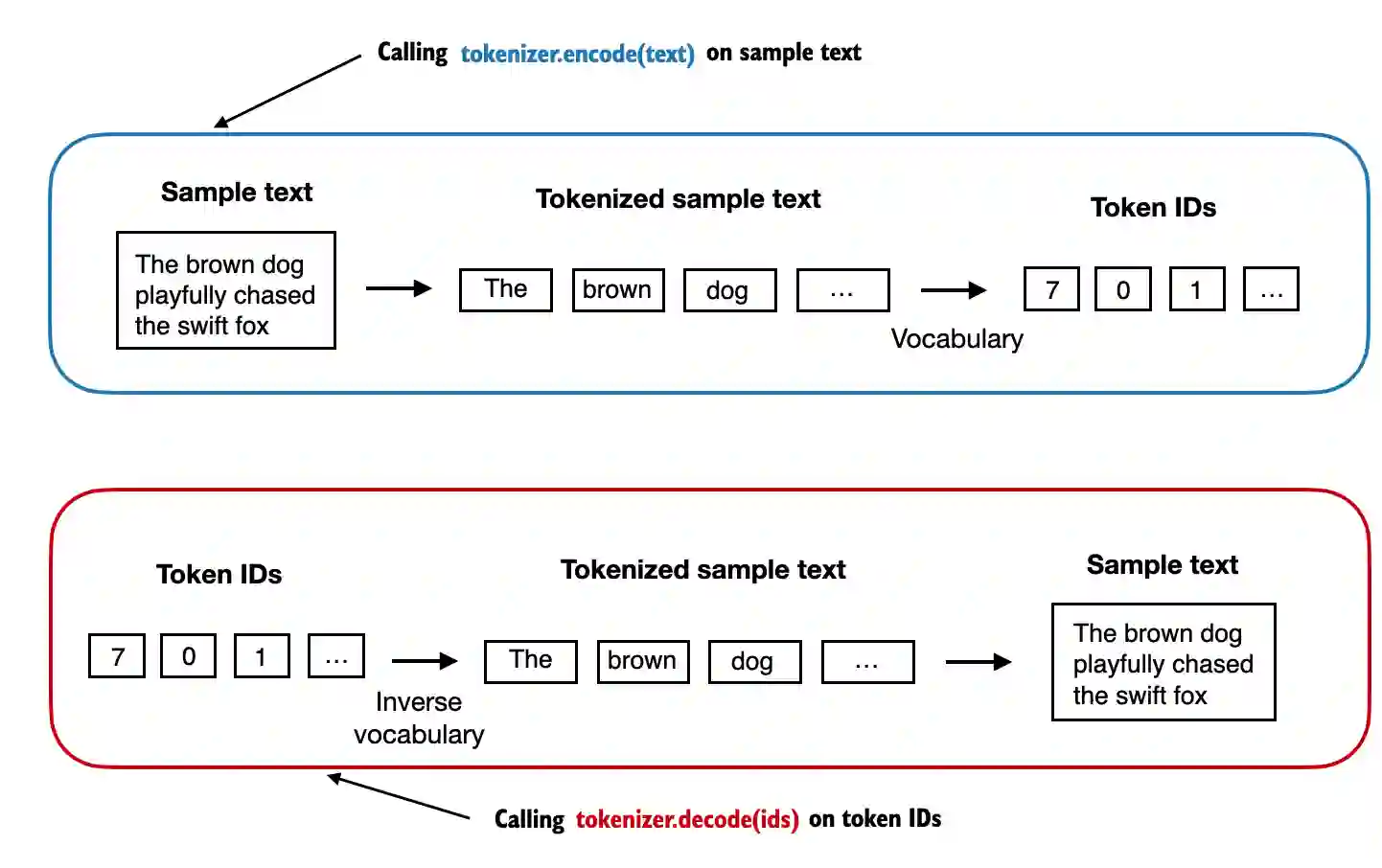
Phase 3. Token embedding assignment
token-id 嵌入后是是一个词向量,维度越高表达能力越强,每一维表达这个 token 的一个性质
可以理解为 768 维的词向量就是这个 token 对于 768 个问题的 0-1 的量化解答


Phase 4. Position embedding assignment
position embedding 也是 786 维,每一维度对应的问题都是关于这个 token 在原 seqence 中的位置问题
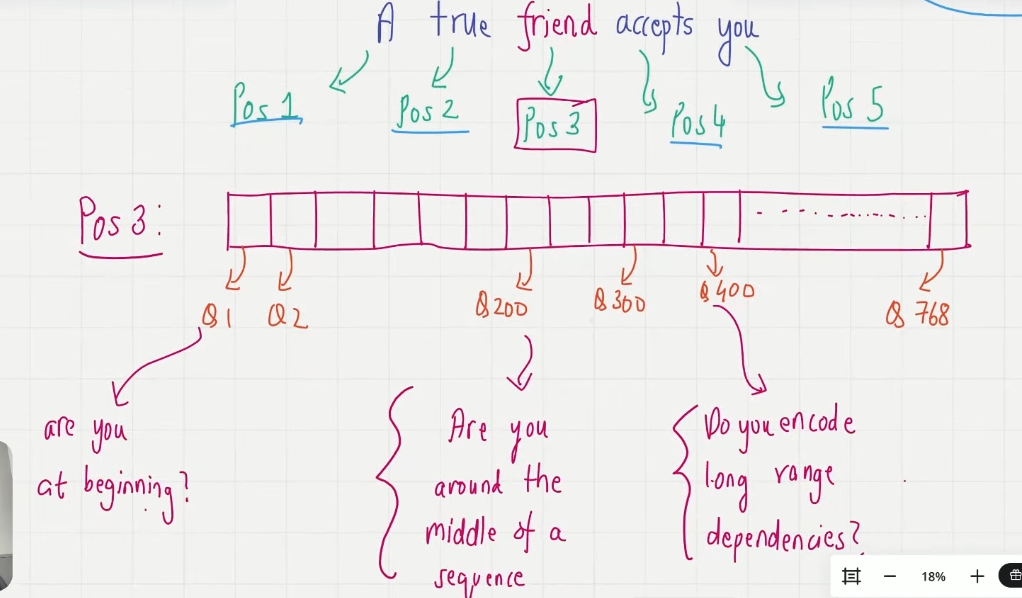
Phase 5. Input embedding = token_embd + pos_embd
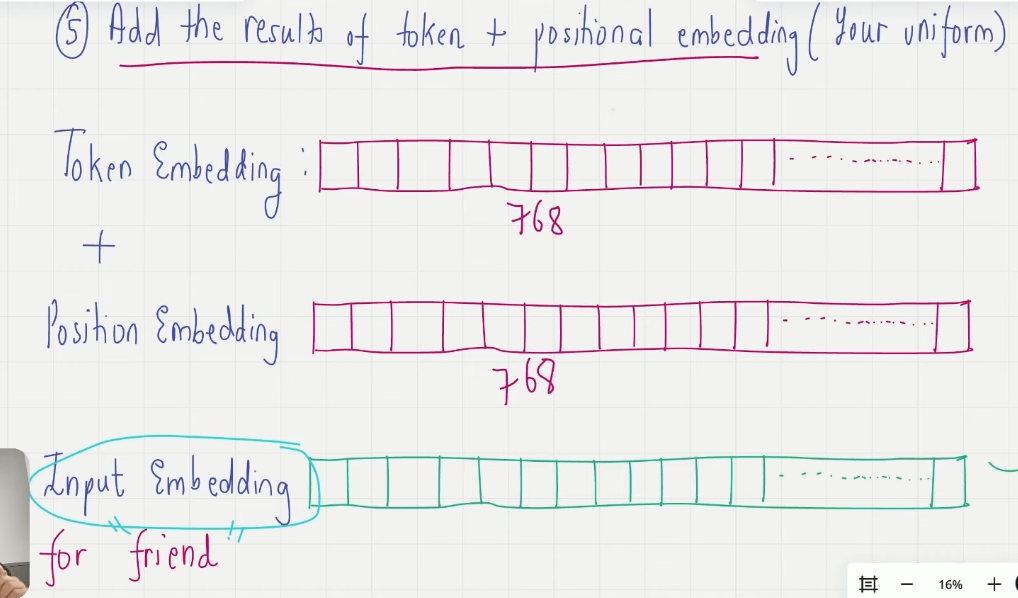
Phase 6. Go to Transformer block, onboard the train
注意:进入 Transformer 的数据是 input-embedding 数据,token-emb 和 pos-emb 和 dropout 实在 gpt-model 外壳内 Transformer 外完成的,gpt-model 接收的是 token-ids,所以在将数据传给 gpt-model 前要先进行 phase1.isolation 和 phase2.token_id assignment

Phase 7. Different compartments of the Transformer
Transform 是一个超级火车,由 n 列小火车串成的大火车
一个小火车有六节车箱,这是一节车厢:
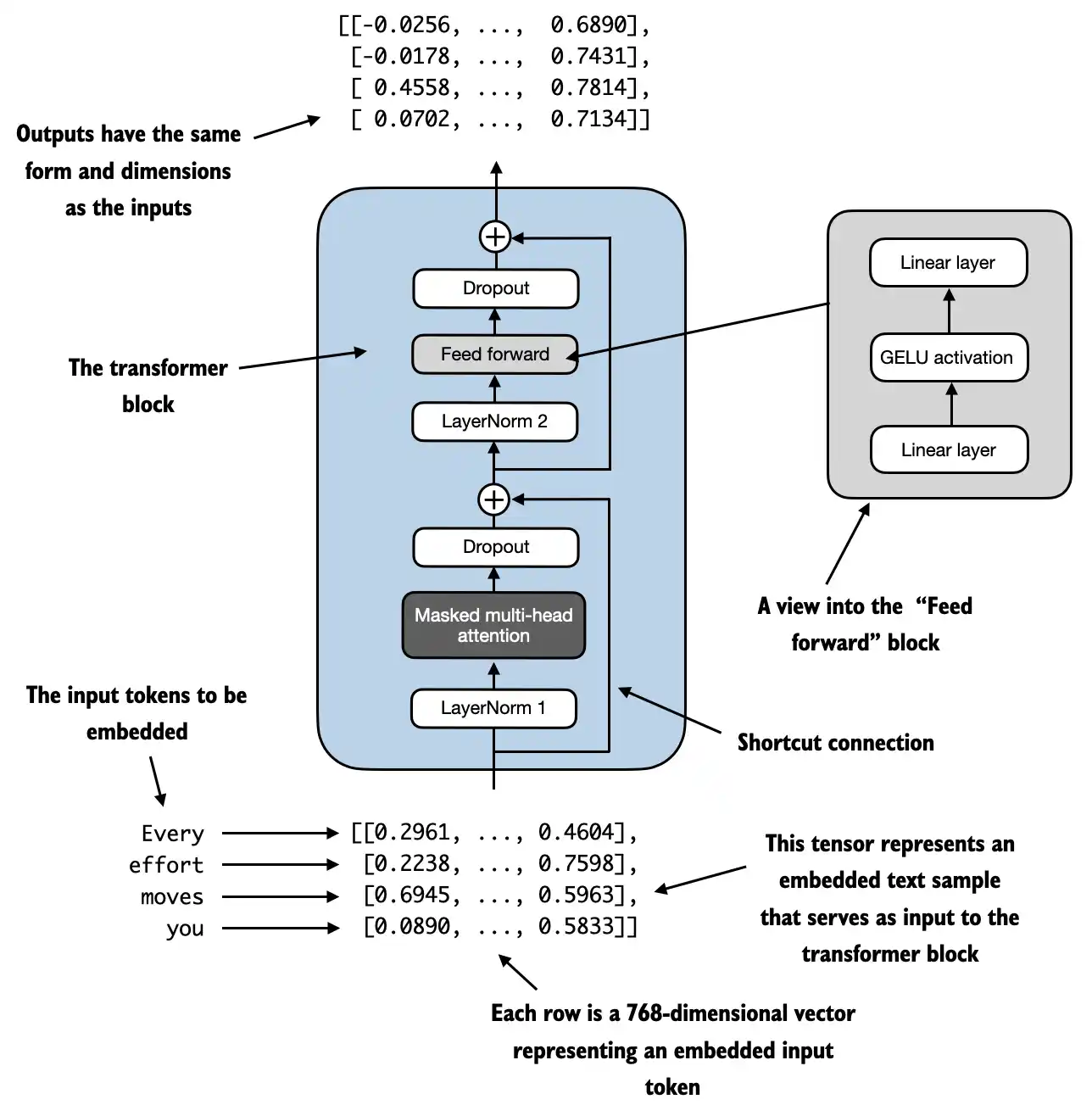
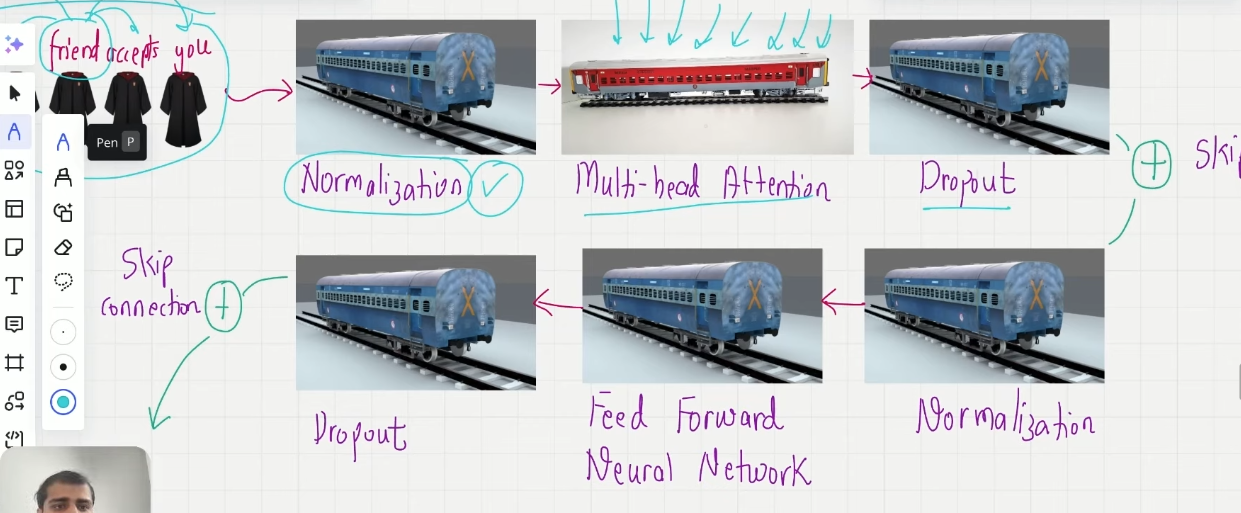
Multi-head Attention:多少注意力分配在周围的词上
注意:传入 gpt 的是一个 seqence,有多个 token,有固定的 max_length。Transfomer 能看到 seq 完整的句子,前面的只不过被 mask 起来了
特别注意:Transformer 是 Seq2Seq 模型。transfomer 一次处理一个 Sequence,不是一个 token 一个 token 处理。同理前面的各种 embeding 和 layer_norm 操作都处理的是 Sequence。Transformer 处理三维数据,一维是 batch_size,一维是 seq_len,一维是 emb_dim。Transformer 的输出也是(batch_size, seq_len, emb_dim)
而 mask 的主要工作原理是 keys@queries 后进行了 mask,只保留 mask 矩阵中为 1 的元素,变成了下三角矩阵
Phase 8. Go through all transformer blocks
Phase 9. A larger of normalization
从 Transfomer 模块中出来后的数据要做一此大的归一化,然后输出,从 emd 回到 token-id,回到 word
2. 构架创新
2.1. MLA:multi-head latent attention
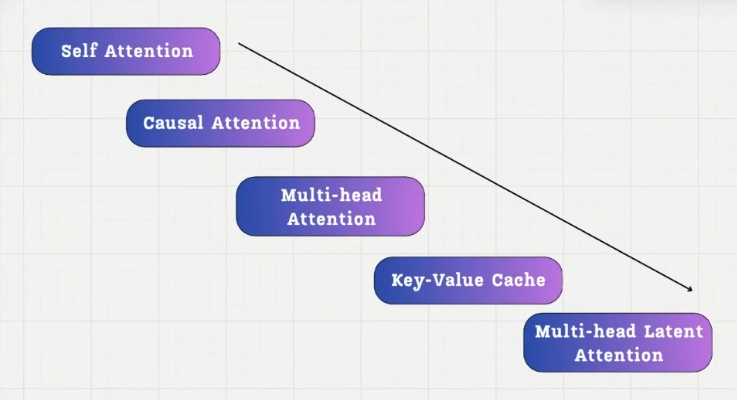
2.1.1. Self-attention
Neural networks can not deal with memory,Seq2Seq
1970s NN
1980s RNN
1997 LSTM
2014 Attention+RNN
2017 Attention+Transformer
2018 Attention+GPT
self-attention:自注意力主要是在关系矩阵中横向和纵向都是 Seqence 自身,而传统的翻译任务则是翻译前的语句和翻译后的语句。既然子注意力都是自身所以就出现了 mask 的需求,seq 前面的 token 不能看到后面的 token
Self-Attention:
Masked Self-attention:
Dropout:
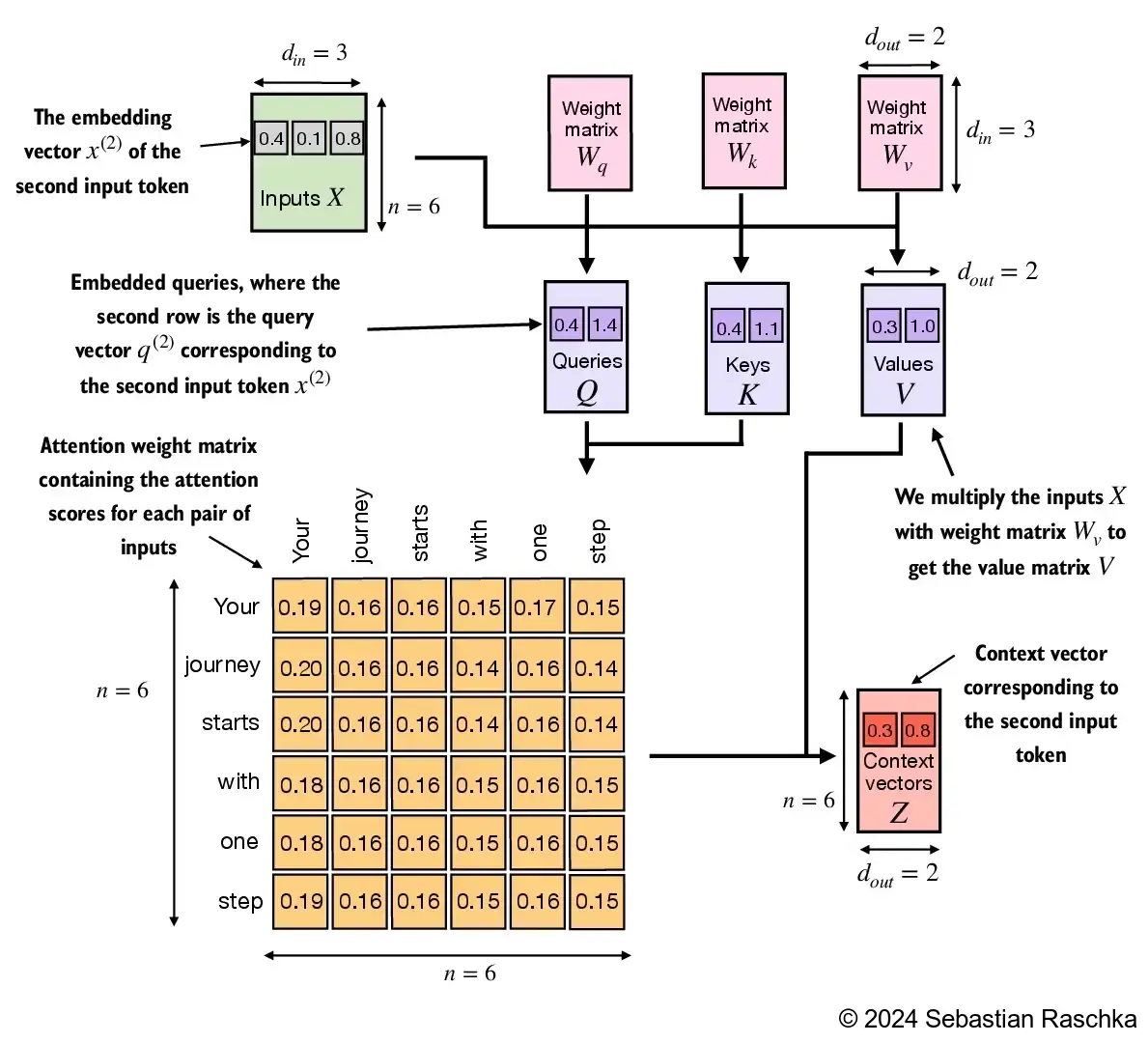
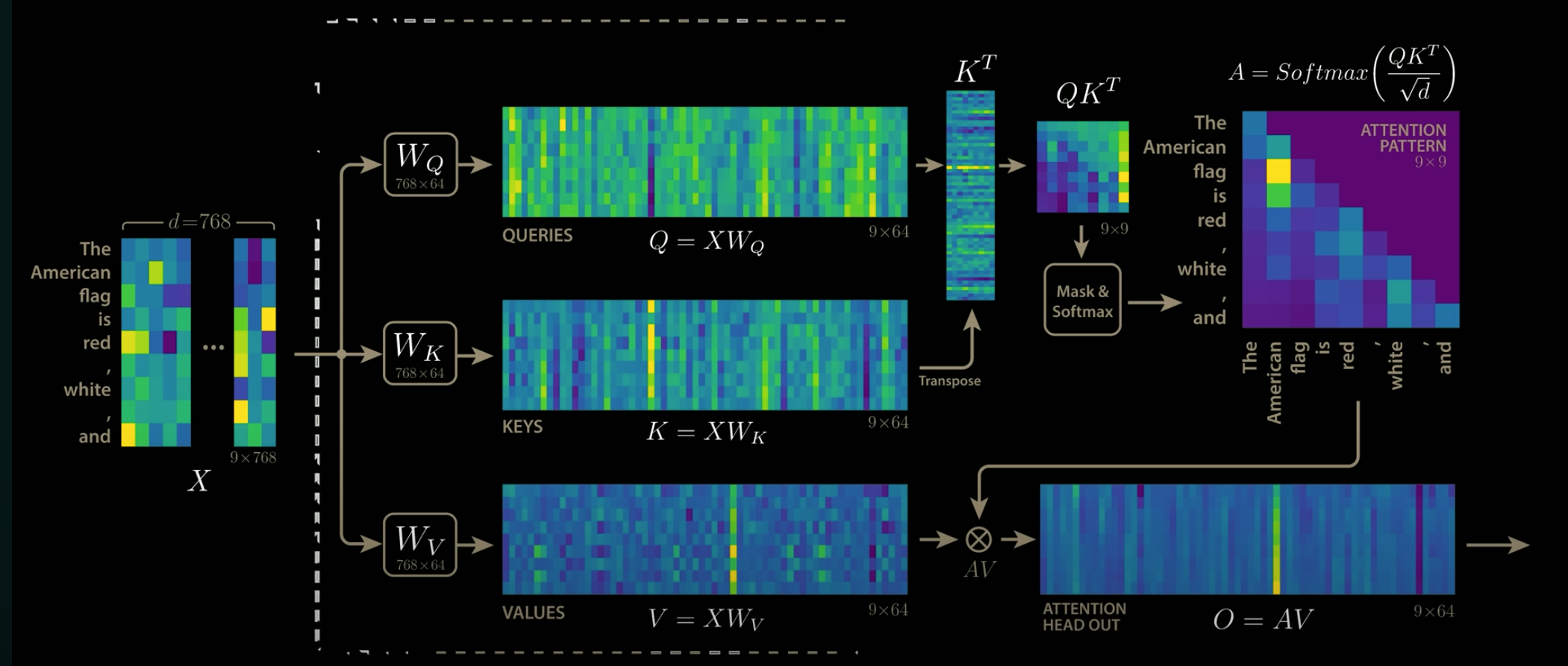
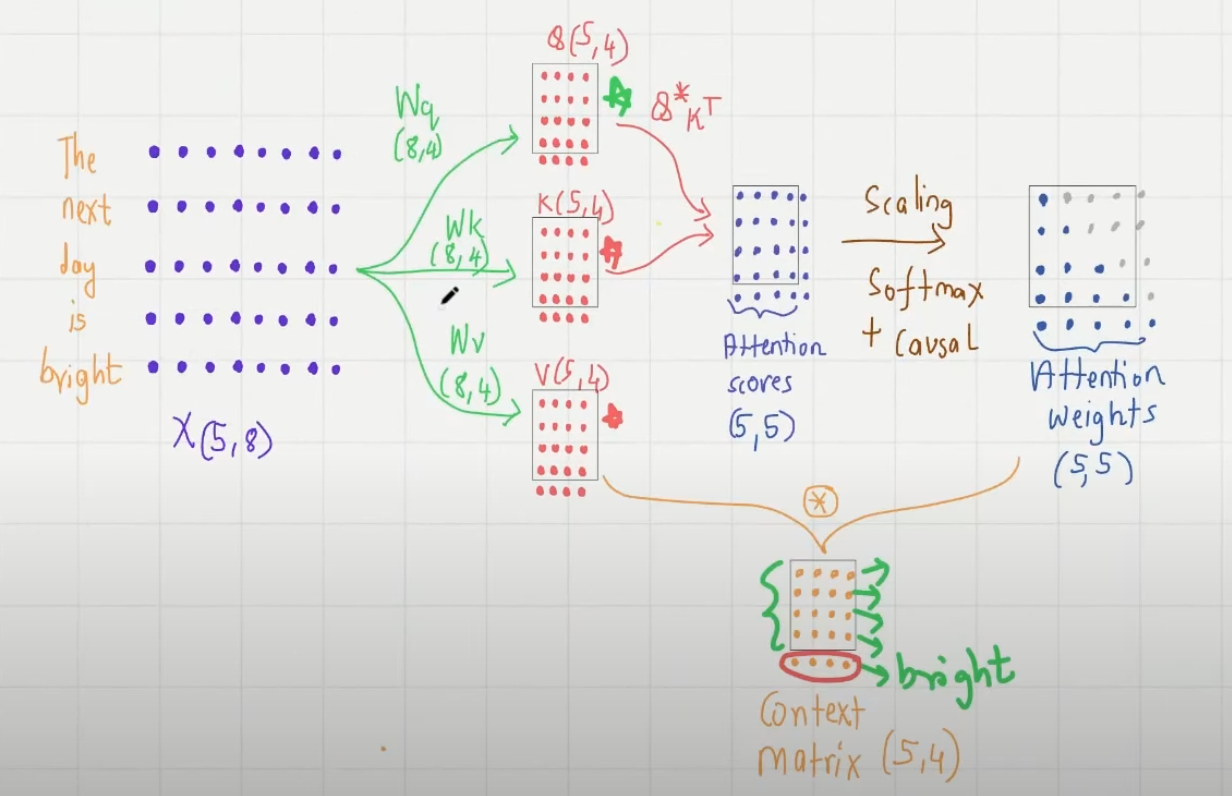
input_vec --> context_vec !!!
Step1. get qkv_vec
W_key,W_value,W_query 都将原 input_vec 向量映射到新特征空间中,称之 QKV 空间
下面的操作都在新的空间中进行
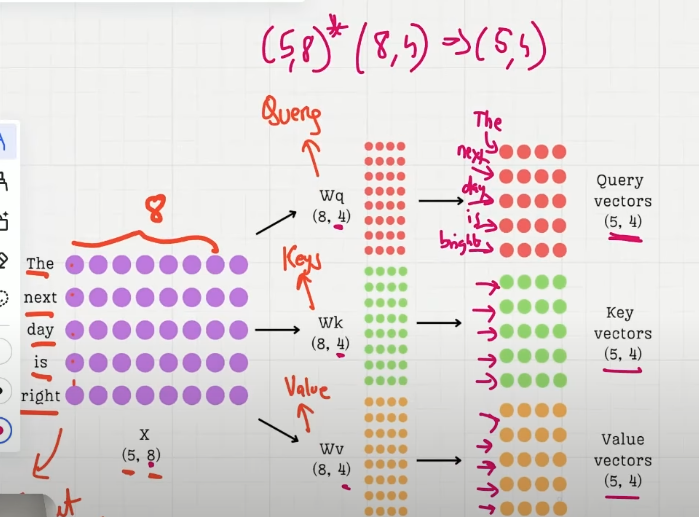
Step2. get attention_scores
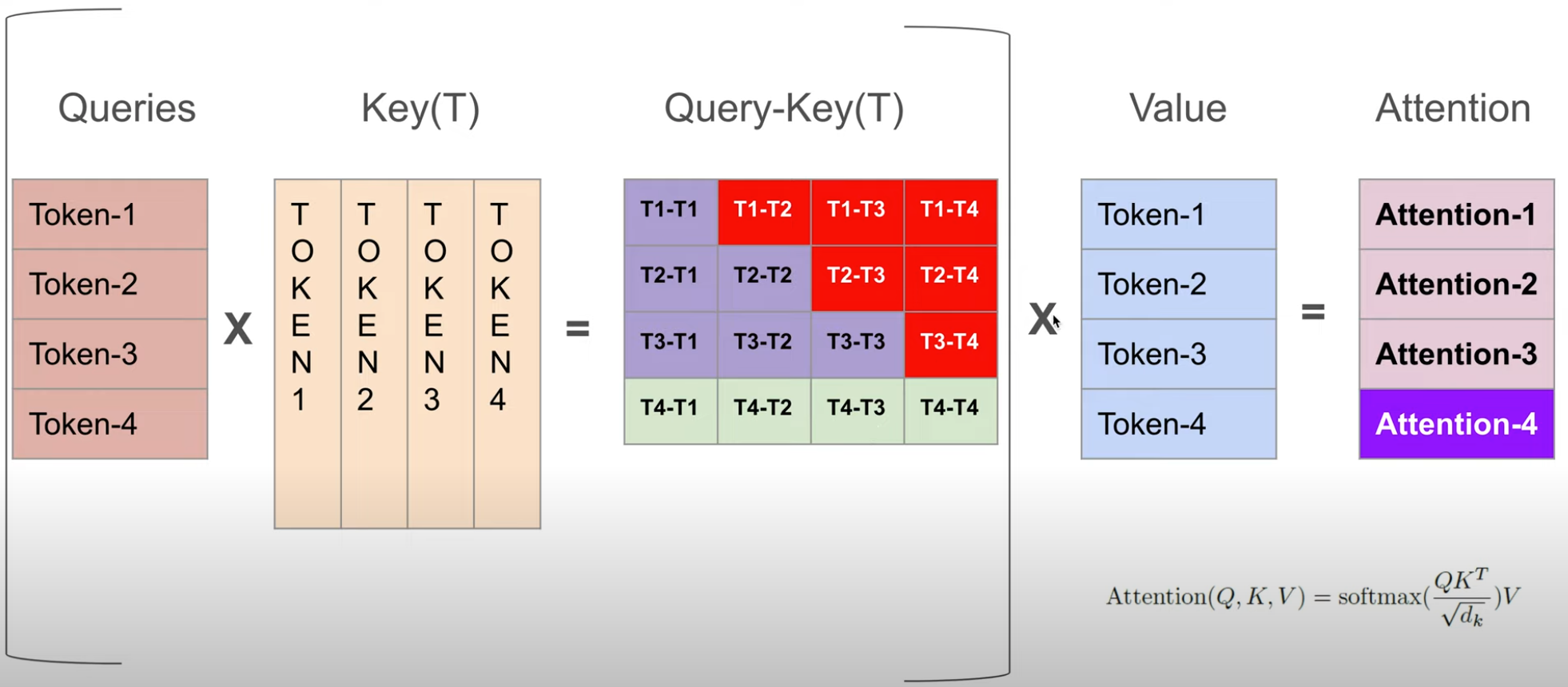
queries 和 keys 在做矩阵乘法时,queries 中的每一个 query 向量都与 keys 矩阵中的每个 token 的 key 向量做了内积,内积结果作为注意力向量对应维度上的值。此 token 与 sequence 中的其他 token 的相关性(内积值大小)作为此 token 的注意力向量,作用到 values 矩阵此向量的 value ,意作其他 token 对本 token 的上下文影响,也是此 token 的注意力作用后的结果。
每行中的元素是当前 token 向量与其他 token 向量的内积大小
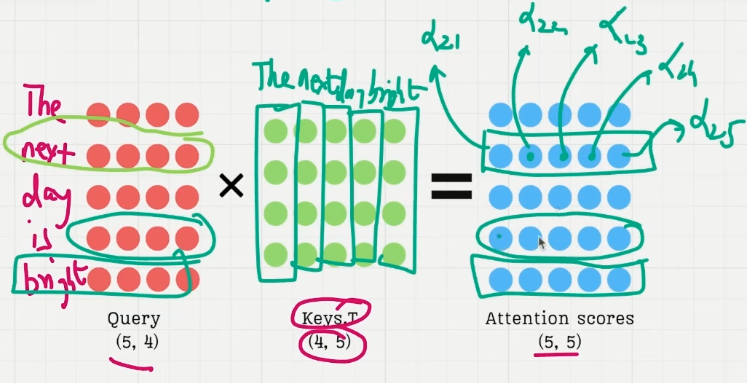
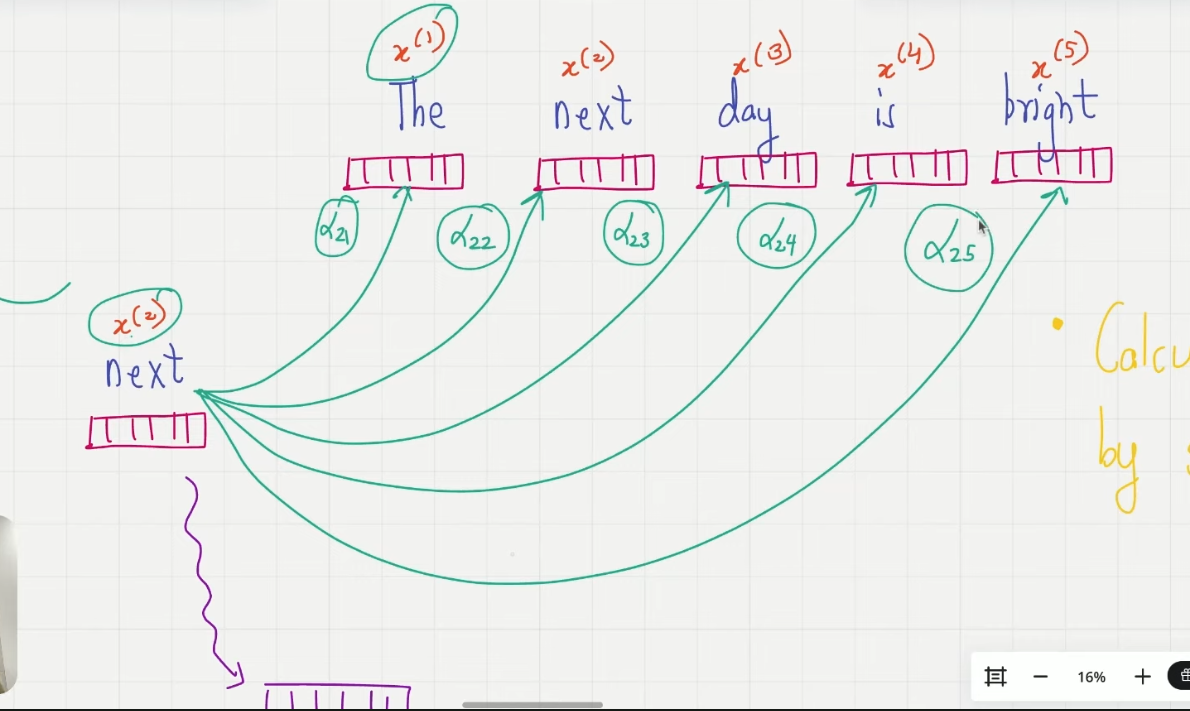
Step3. attention_weights
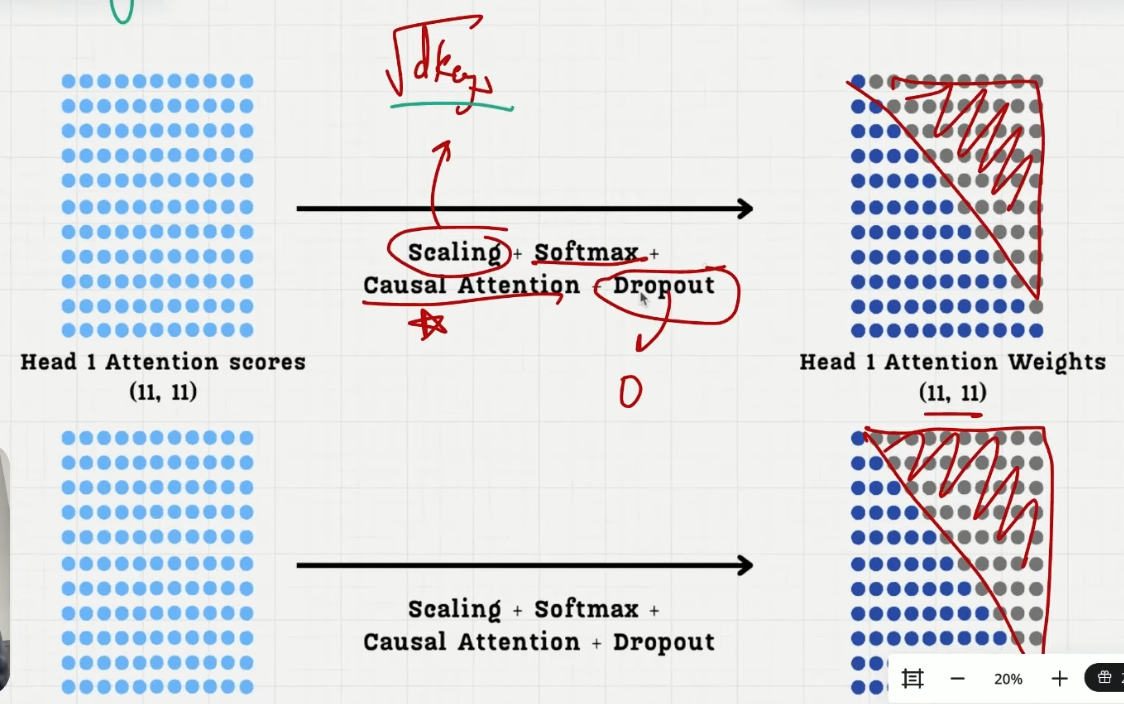
得到的 attention_scores 矩阵通过除 sqrt/d_keys,再过 softmax,让每行的元素相加为 1,转化为 attention_weight 矩阵,行中元素表示这个 token 给其他 token 的注意力大小,且总和为 1

Step4. attention_weights × values
在 attention_weight 中包含每个 token 对其他 token 的注意力权重,这个权重作用到 values 上,values 矩阵的每行是 token 的在 QKV 空间的向量,与每个 token 在 attention_weight 中的行向量相乘

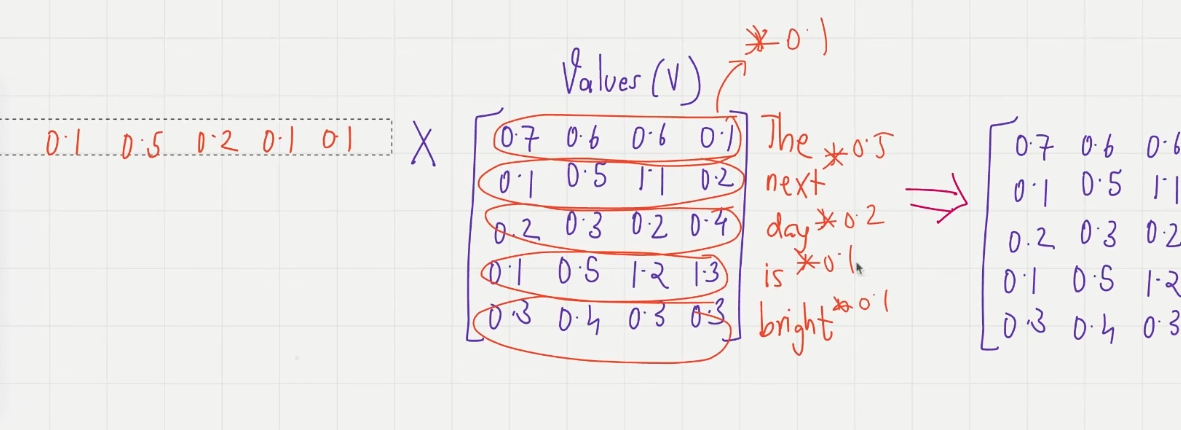
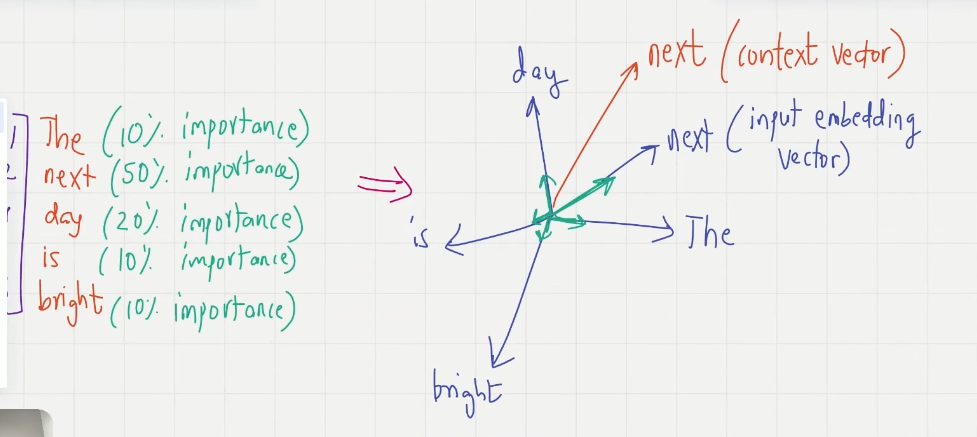
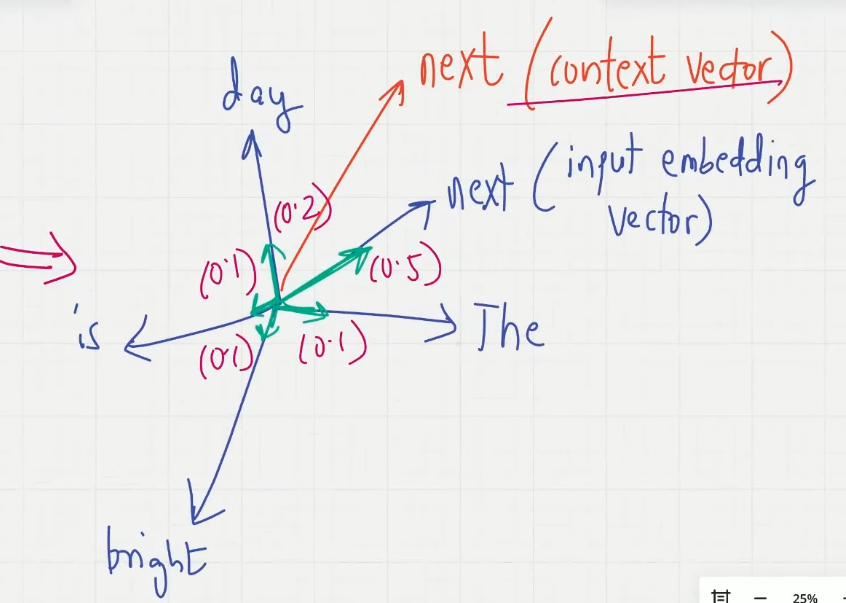
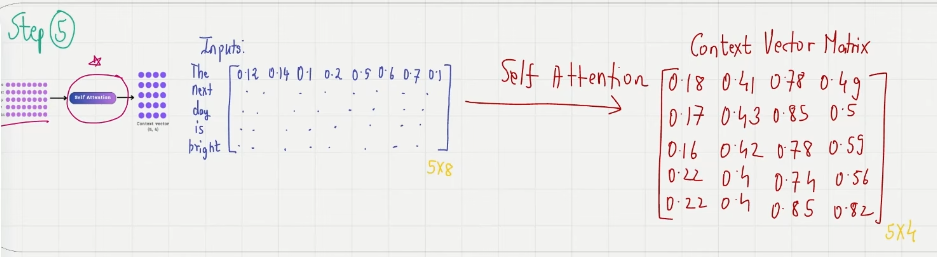
Step5. context vector matrix
每个 input_vec 都转化为 context_vec,构成 context_matrix
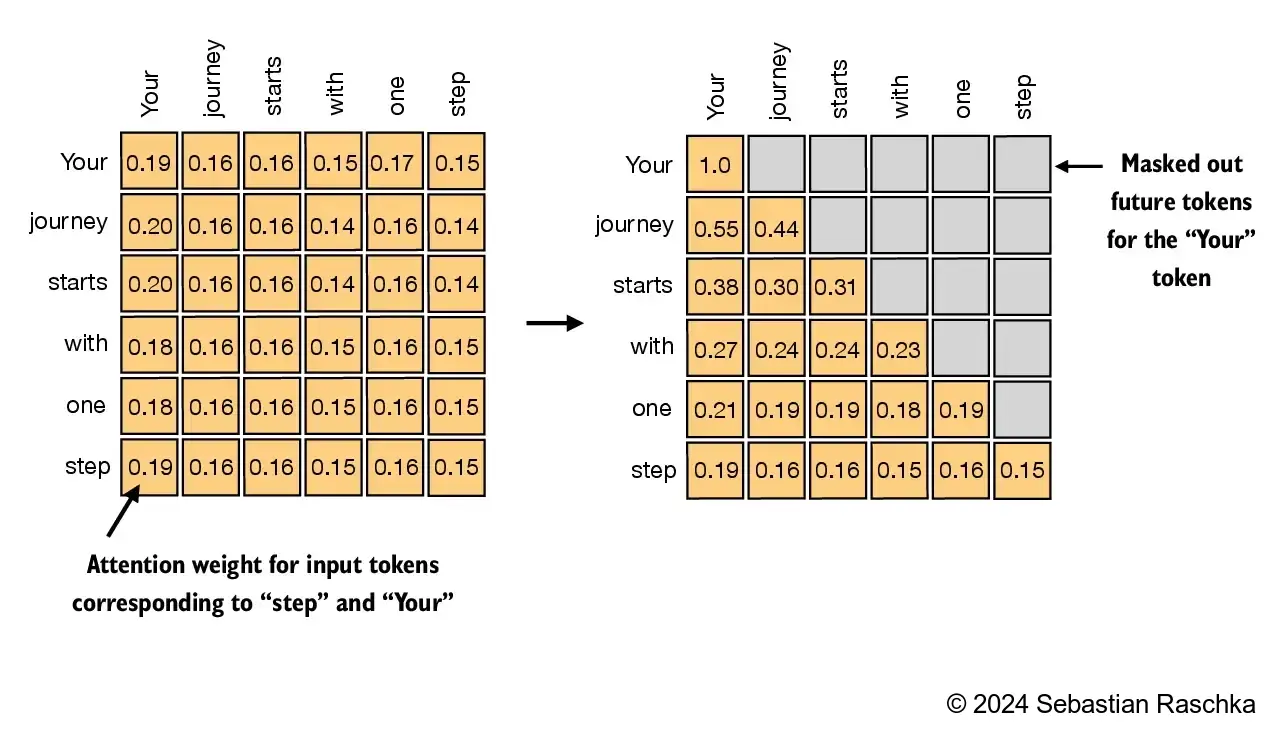
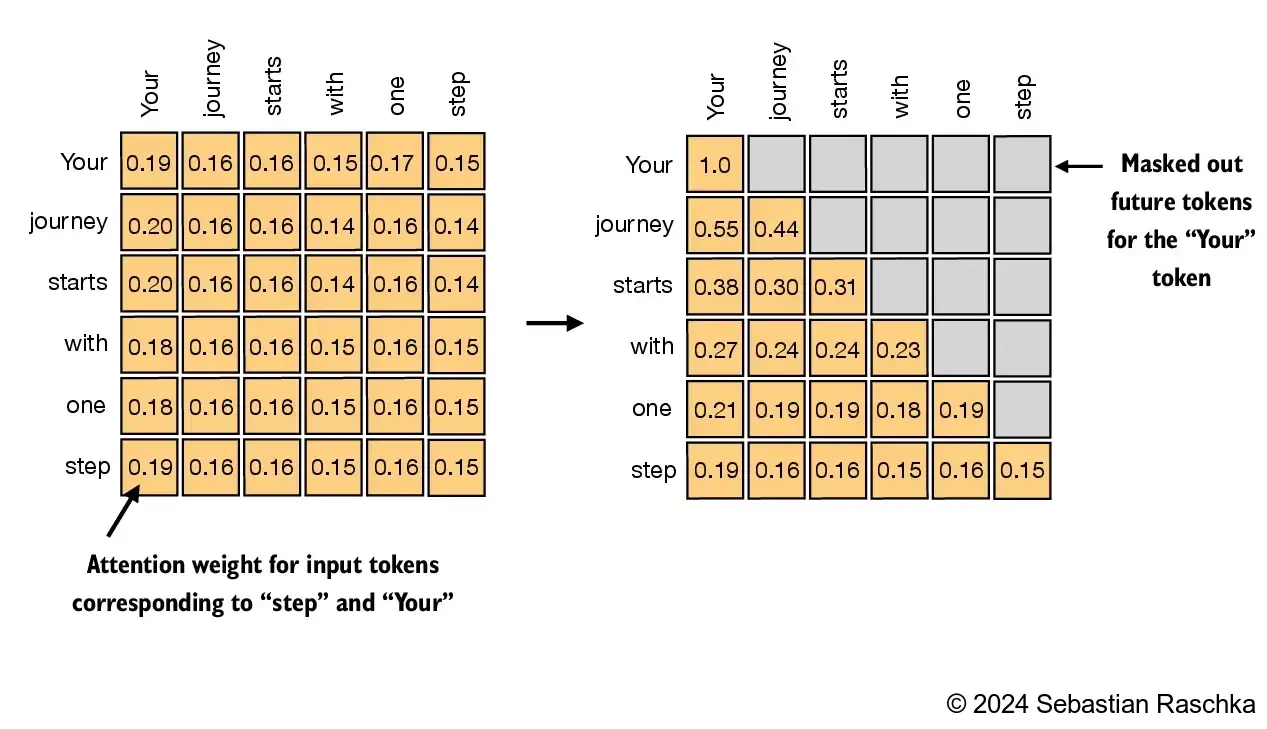
2.1.2. Causal Attention
Just don't peek into the future
queries 和 keys 乘完的 attention_scores 矩阵先进行 mask,后做除 sqrt/d_keys 和 softmax
这样保证中间的 token 只看到前面的 token

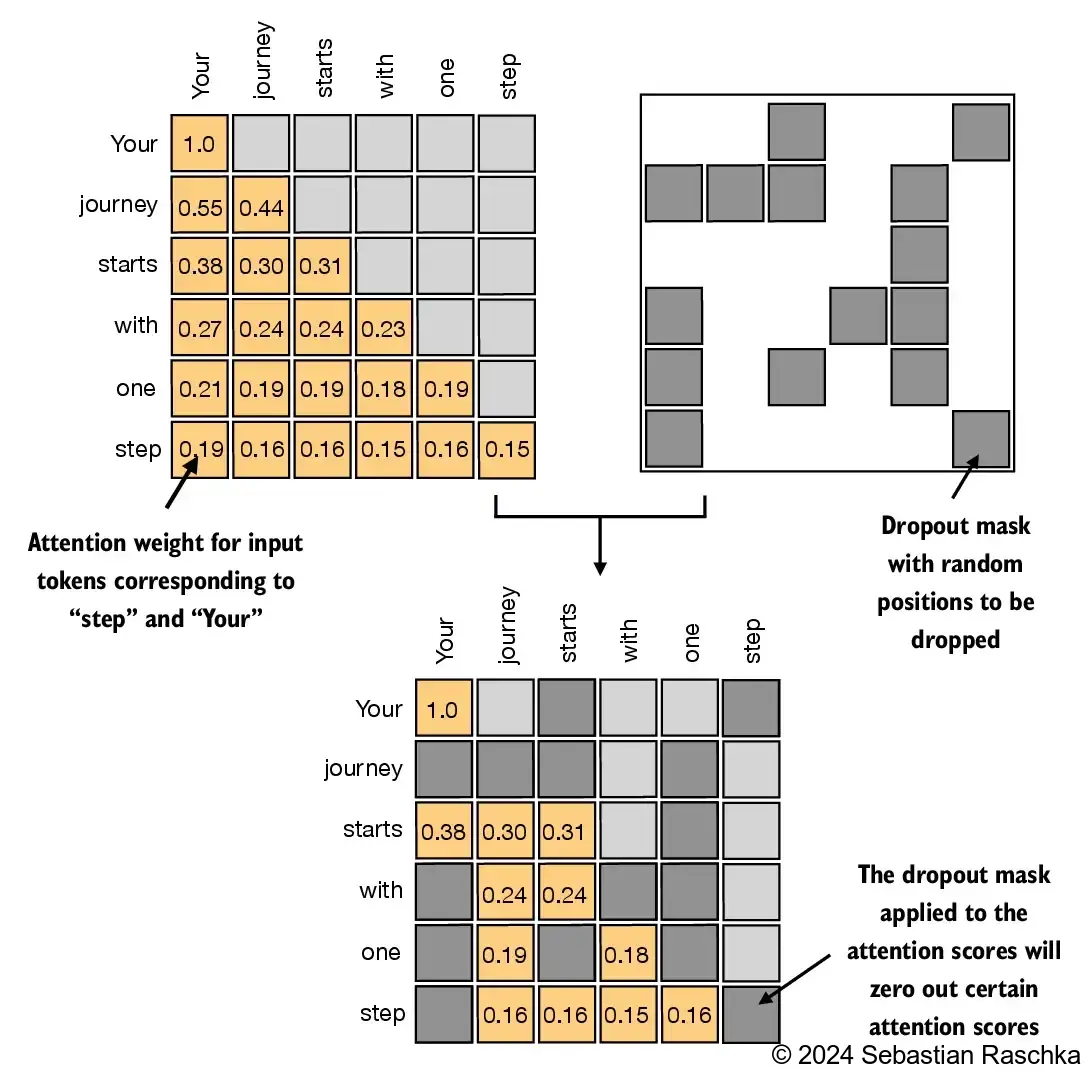
dropout
每个 token 不可能发挥 100%的注意力,完全注意到之前所有的信息,所有设置 p 的遗忘概率,将对某些其他某些 token 的注意力设置为 0,注意力权重被关闭
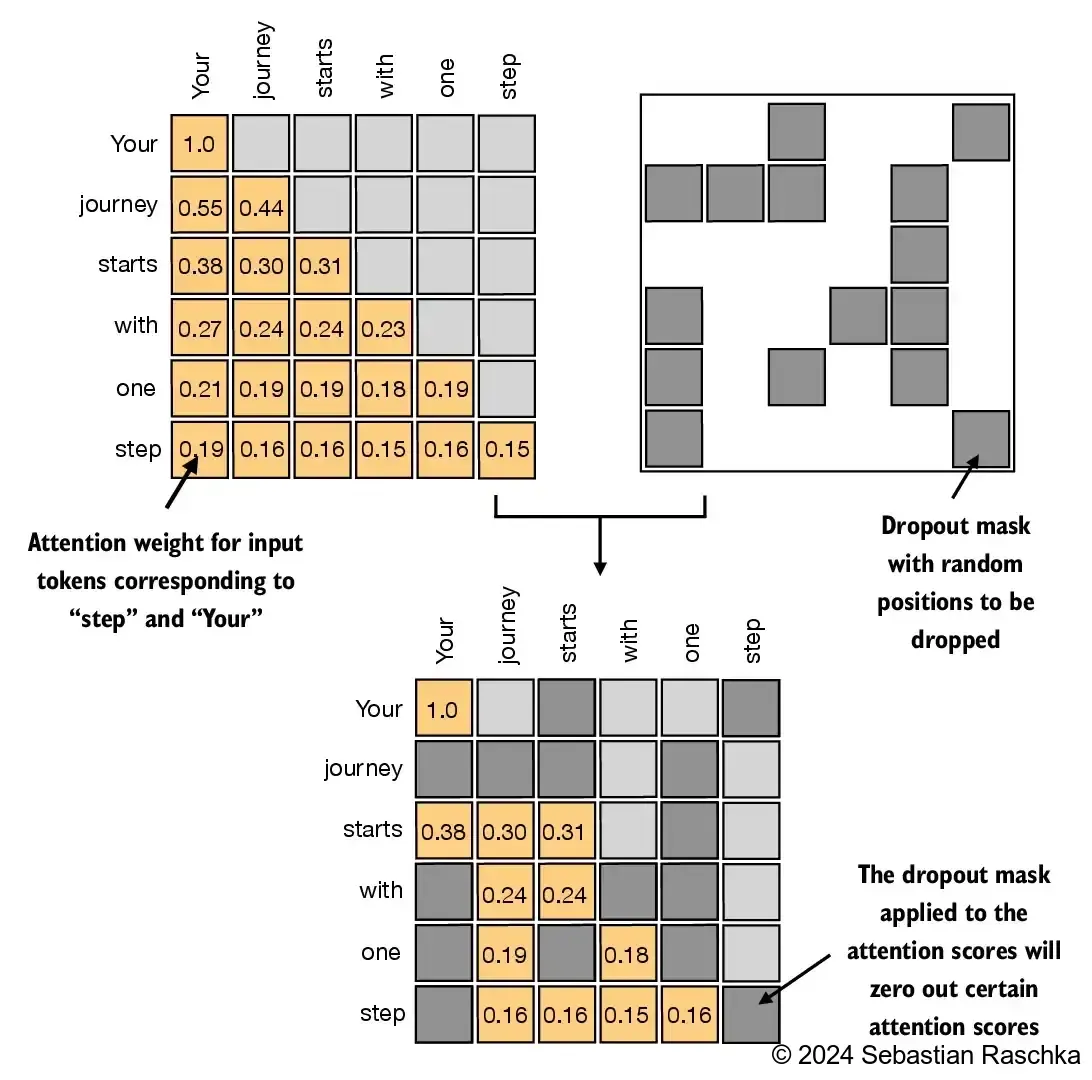
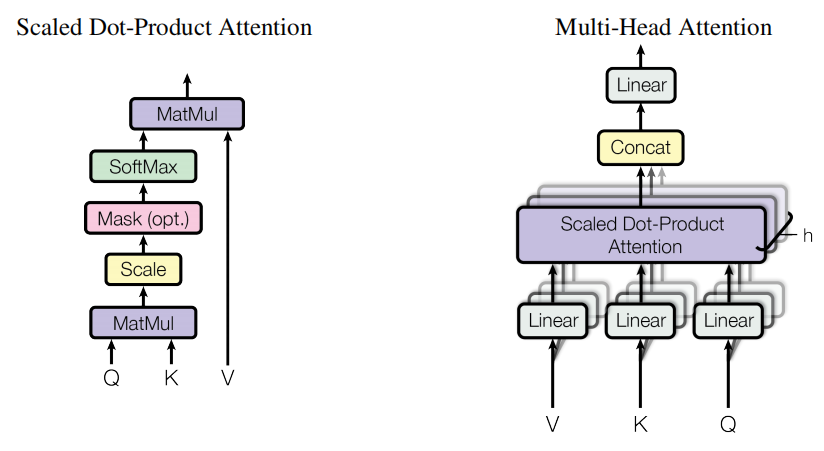
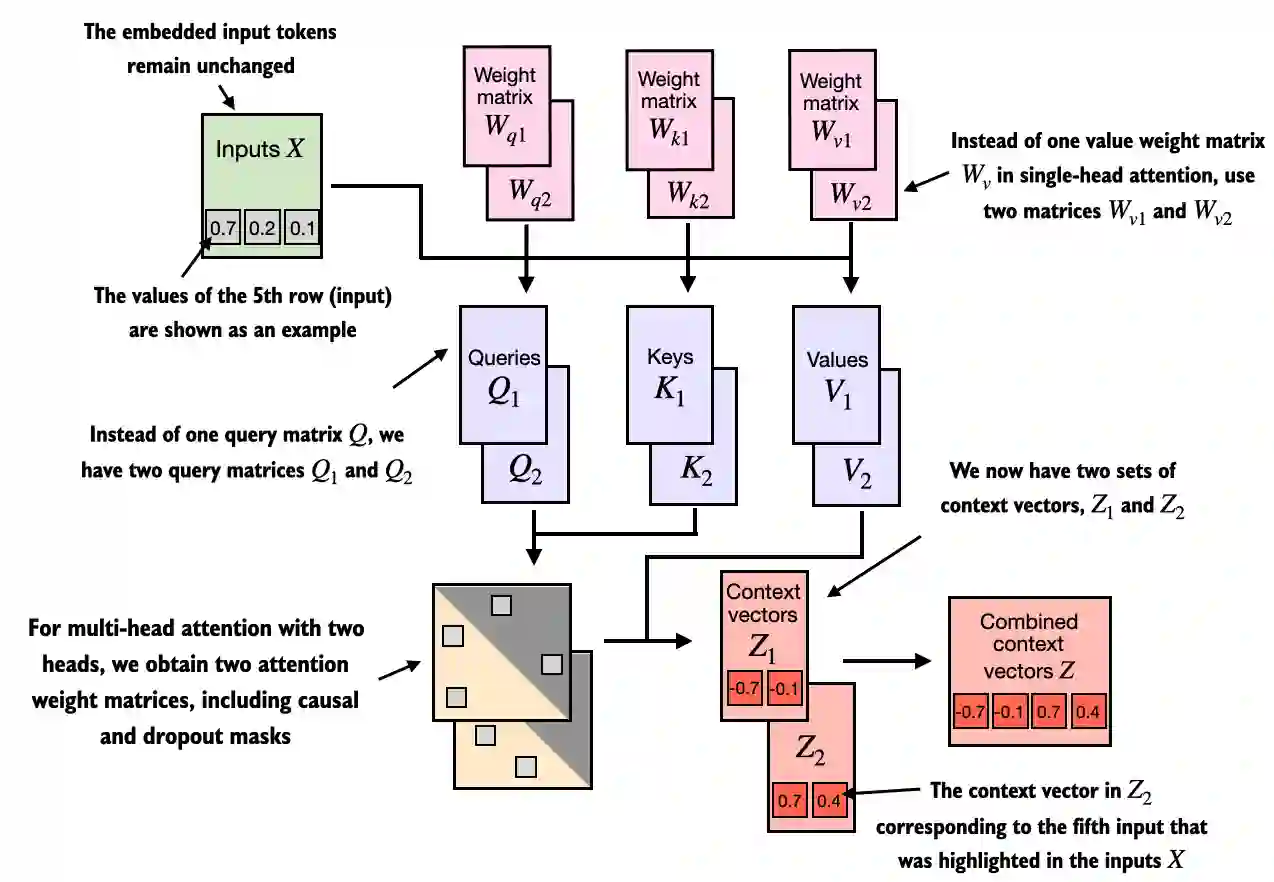
2.1.3. Multi-head Attention
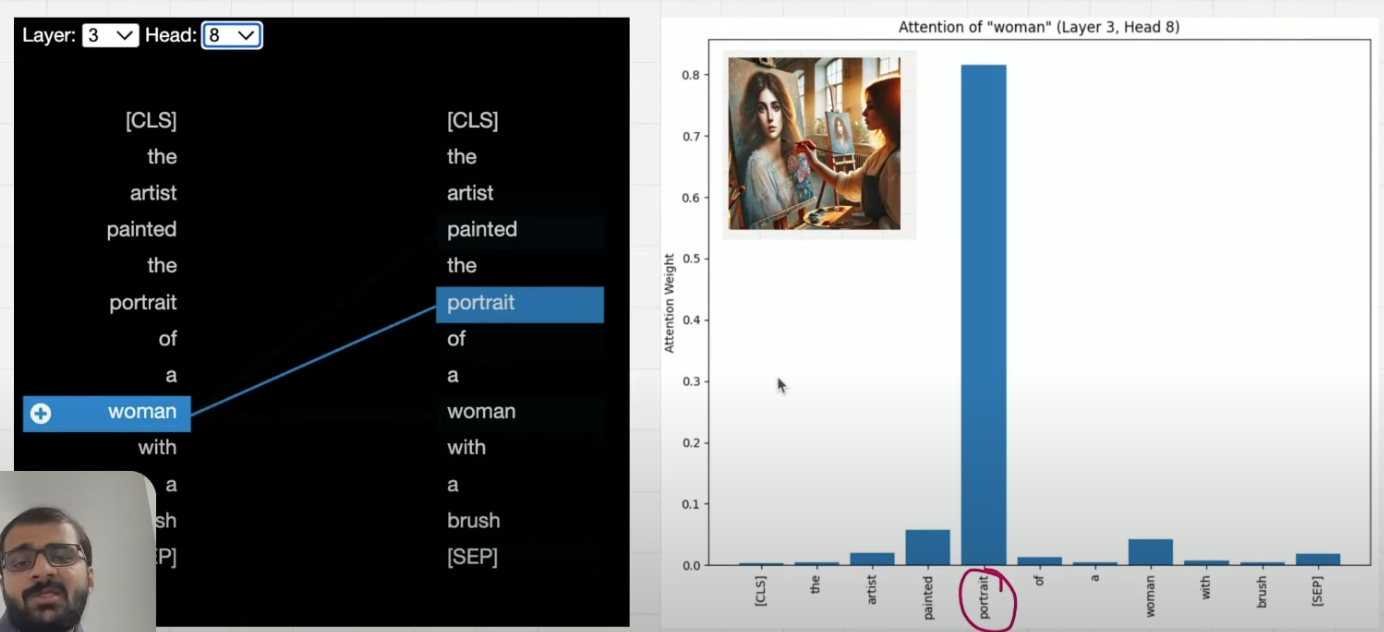
注意:同一句话有着不同的解释,不同的语义的词之间的注意力权重也不同
在本例中可注意 artist 和 portratit 对于 woman 和 brush 的注意力,也可以直接看 brush 分配的注意力权重
用刷子画女人,和画拿着刷子的女人两种语义 token 之间注意力的分布
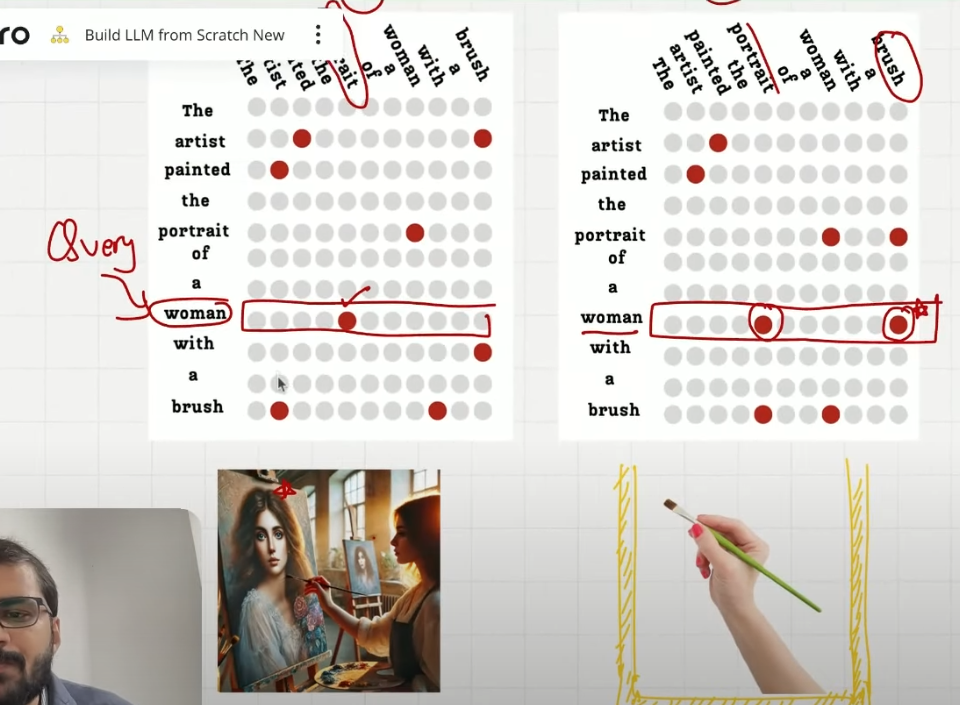
一个 self-attention 就只会有一个注意力矩阵,一个注意力矩阵只能表示一种语义,语义依赖于 token 间的关系
1 self-attention --> 1 perspective
multi self-attention --> mult perspective
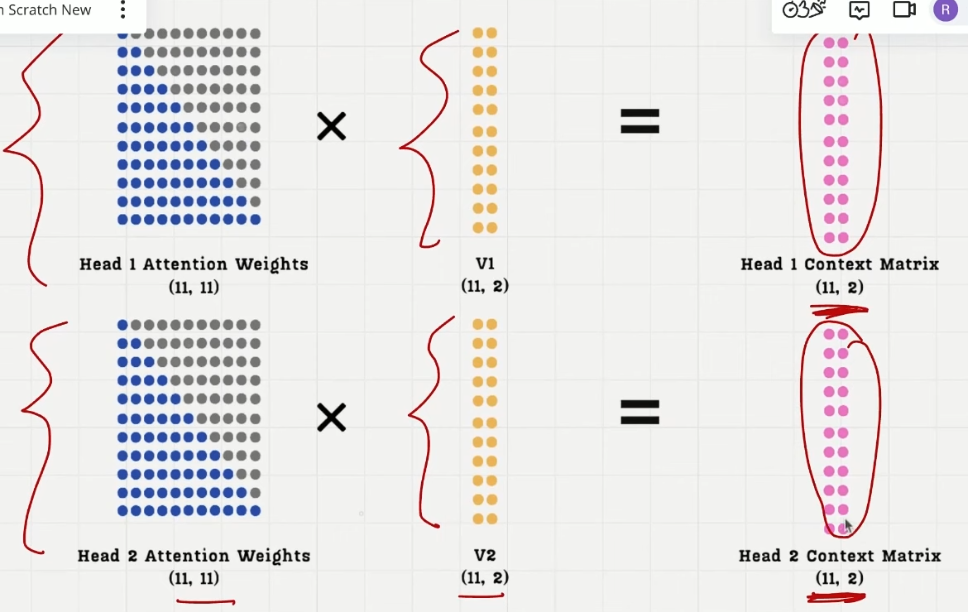
两个注意力头 --> 两个注意力得分矩阵 --> 两个注意力权重矩阵 --> 两个上下文向量矩阵
每个矩阵捕捉不同的 perspective
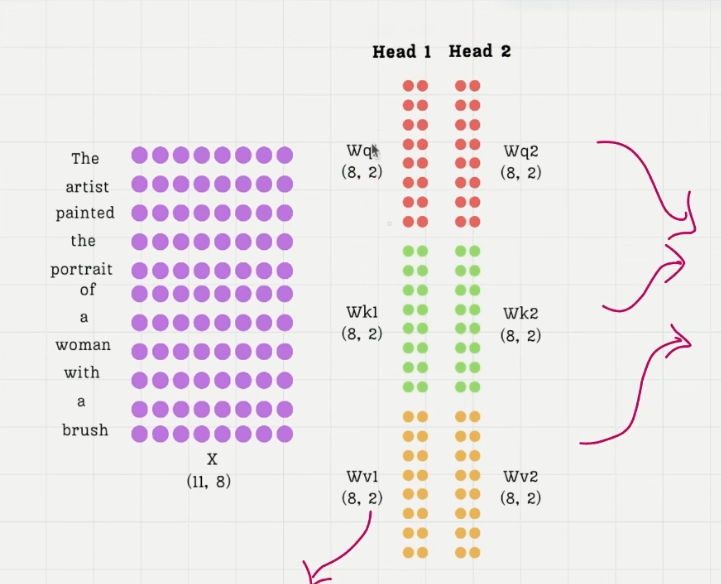
问题:多头注意力机制中的多头处理的是什么,比如gpt124M,一个token嵌入后是768维度的向量,gpt2min有12个注意力头,每个头处理的是768/12=64维度的子空间还是将将QKV矩阵的d_out的列数拆成了12个子矩阵,每个矩阵的d_in变仍是input_vec矩阵的列数?
答:不分割输入向量,而是拆分 QKV 矩阵,映射到 64 维度的子空间上。
每个头的本质是独立的线性投影 :
-
- 输入向量维度为
d_model=768(如GPT-2),头数h=12。 - 每个头将输入通过独立的Q、K、V矩阵 (维度为
768×64)投影到d_k=64维子空间。 - 所有头的投影参数是并行计算的 ,而非分割输入向量。
- 输入向量维度为
Q/K/V矩阵的拆分 :
-
- 总参数矩阵的维度为
768×768(对应d_model×d_model)。 - 实际实现中,这些矩阵被拆分为
h=12个子矩阵,每个子矩阵的维度为768×64(即d_model×d_k)。 - 输入维度(
d_in)始终是768 ,每个头的子矩阵仅改变输出维度(d_out=64)。
- 总参数矩阵的维度为
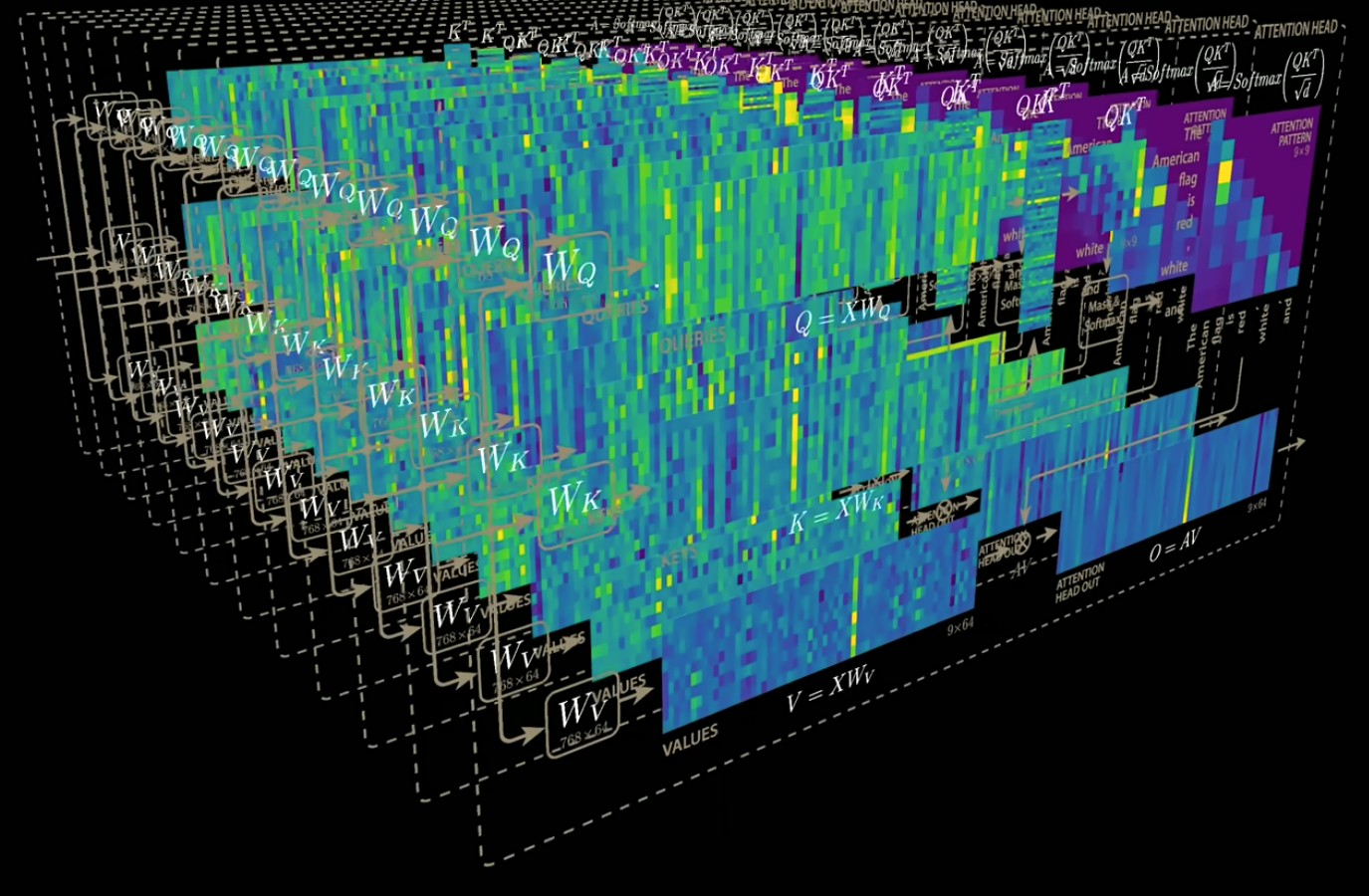
可视化拆分过程:
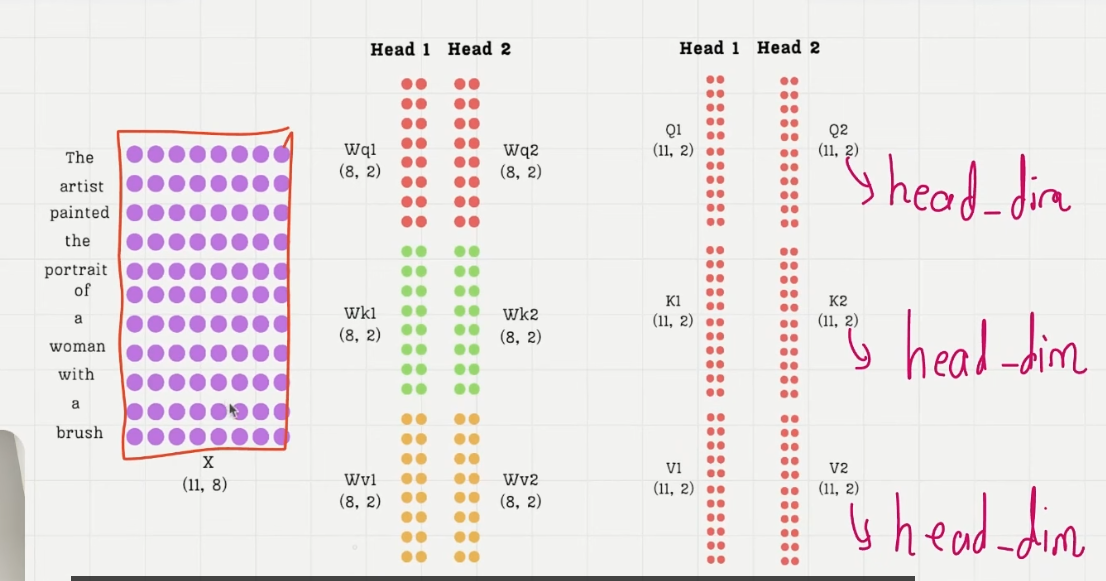
head_dim = d_out / n_heads --> (d_in, head_dim)
注意:seq_size = d_in
每个注意力头经过 quries@keys.T 得到注意力得分矩阵,注意力得分矩阵和注意力权重矩阵都是正方形,(seq_size, seq_size),不同的注意力头捕捉到了不同的 perspective,不同角度下语义
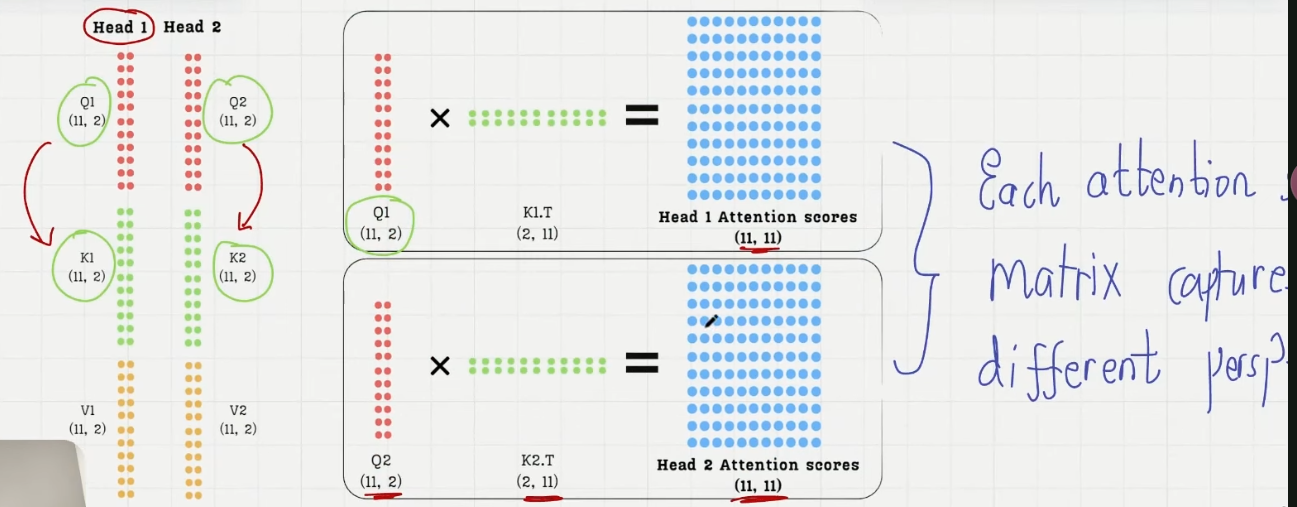
casual attention 的权重矩阵作用到对应的注意力头的 value 矩阵上,得到这个注意力头的 context_vec,(d_in, head_dim)
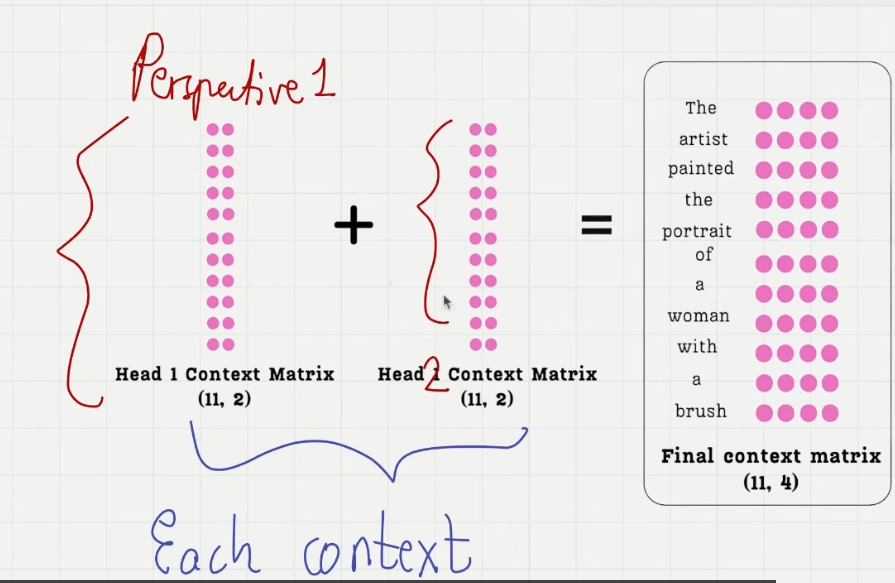
向量合并,语义合并,视角合并,回到高维度空间
这样的 context_vec 矩阵不止包含一个语义
mha 权重可视化
from bertviz.transformers_neuron_view import BertTokenizer, BertModel
from bertviz.neuron_view import show
sentence_a = "The artist painted the portrait of a woman with a brush"
model_type = 'bert'
model_version = 'bert-base-uncased' # 全小写模型
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=True)
show(model, model_type, tokenizer, sentence_a, layer=4, head=3)import torch
import matplotlib.pyplot as plt
from transformers import BertTokenizer, BertModel
from bertviz.neuron_view import show
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
sentence = "The artist painted the portrait of a woman with a brush"
inputs = tokenizer(sentence, return_tensors="pt")
# 手动补
tokens = tokenizer.tokenize(sentence)
tokens = ['[CLS]'] + tokens + ['[SEP]']
woman_index = tokens.index('woman')
outputs = model(**inputs, output_attentions=True)
attentions = outputs.attentions
def visual_attention_for_woman(layer_index, head_index):
attention_weights = attentions[layer_index][0, head_index].detach().numpy()
woman_attention = attention_weights[woman_index]
plt.figure(figsize=(10, 8))
plt.bar(tokens, woman_attention)
plt.xticks(rotation=90)
plt.ylabel('Attention Weight')
plt.title(f'Attention of "woman" (Layer {layer_index}, Head {head_index})')
plt.show()
for layer_index in range(len(attentions)):
for head_index in range(attentions[layer_index].size(1)):
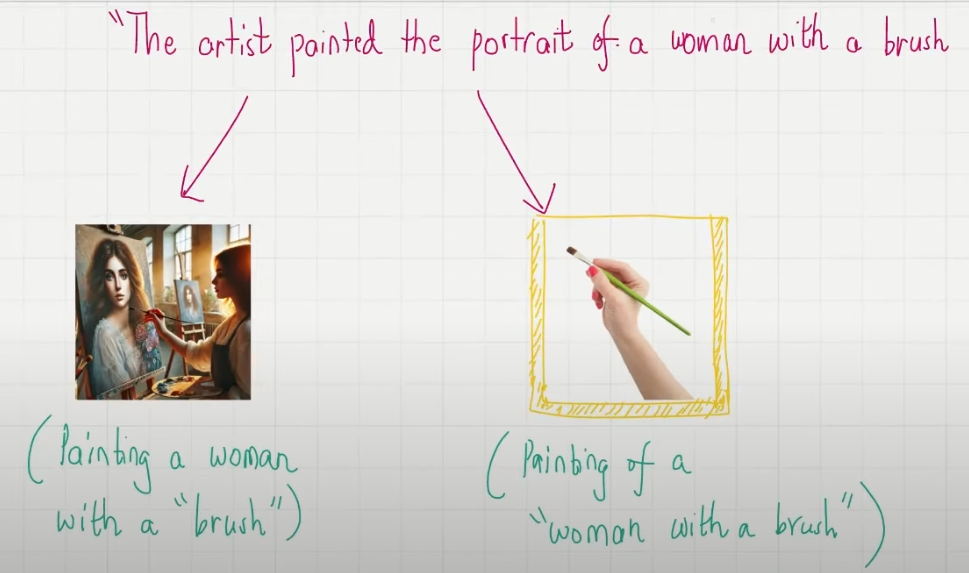
visual_attention_for_woman(layer_index, head_index) 语义 1:画家在用刷子画一个女人,重点:portrait of a woman, painted ... with a brush
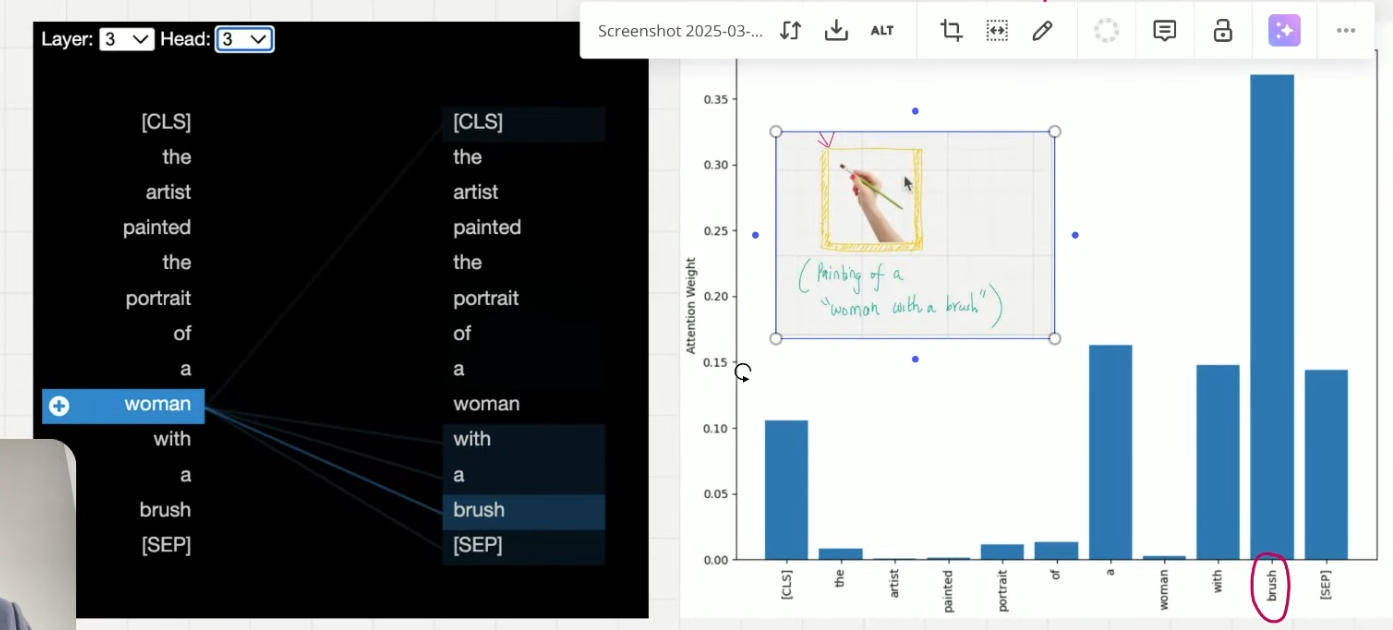
语义 2:画家在画一个拿着刷子的女人,portrait of a woman with a brush
动手实现 mha
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads ==0, "d_out of qkv-matrix must divisible by num-heads"
# mha类的全局变量,self存储,实例化对象的实例变量,否则其他函数不能使用
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, qkv_bias=False)
self.W_key = nn.Linear(d_in, d_out, qkv_bias=False)
self.W_value = nn.Linear(d_in, d_out, qkv_bias=False)
self.out_proj = nn.Linear(d_out, d_out) # 整合多头信息并映射到目标输出维度
self.dropout = nn.Dropout(dropout)
# diagonal=1 对角线上移一行
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x)
values = self.W_value(x)
queries = self.W_query(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1,2)
values = values.transpose(1,2)
queries = queries.transpose(1,2)
attn_scores = queries @ keys.transpose(2,3)
mask_bool = self.mask_bool()[:num_tokens, num_tokens]
attn_scores.mask_fill_(mask_bool, -torch.inf)
atten_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5) # 除根号head_dim
atten_weights = self.dropout(atten_weights)
context_vec = (atten_weights @ values).transpose(1,2)
context_vec = context_vec.contigous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec2.1.4. Key-Value Cache
图解 mha 复习

MHA层特性 :每个位置的输出都包含全局上下文信息(通过自注意力机制),因此第10个位置的context_vec实际上已经融合了前10个token的全部信息。
MLP层作用 :每个位置的context_vec都会独立经过MLP处理(位置级前馈网络),生成该位置的最终表示。对于语言模型任务,最后一个位置的输出(第10个位置的MLP输出)会被用于预测下一个token(第11个)。
MLP 和 MHA 不断地严格遵循因果性地混合学习 token 间的统计关系,从 10 个 input_vec 得到 10 个 context_vec,在这时最后一个 context_vec 已经充分学习了 seq 中先于它的所有 token 的语义(context_vec),这样就根据这个 context_vec 来预测下一个 token,预测结果是一个概率分布,范围是所有的 token_id(100% 确定的 token 就是独热编码),预测结果是 logits_vec
其实每一个 context_vec 都可以用于计算一个 logits_vec,所以 seq_size 个 token,预测结果就是 seq_size 个 logits_vec,每个 logits_vec 都可以用于计算 loss。
注意的是预测的时候是一个 context_vec 一个 logits_vec,计算 attn_weight 时是所有的 input_vec 一起计算的
预测机制 :
- 训练阶段 :输入10个token,模型会并行生成10个输出,其中第i个输出对应预测第i+1个token。因此最后一个输出(第10个位置)自然对应第11个token的预测。
- 推理阶段 :当需要生成第11个token时,模型确实只会使用第10个位置的输出经过softmax得到预测结果,然后将其作为输入的一部分继续生成后续token。
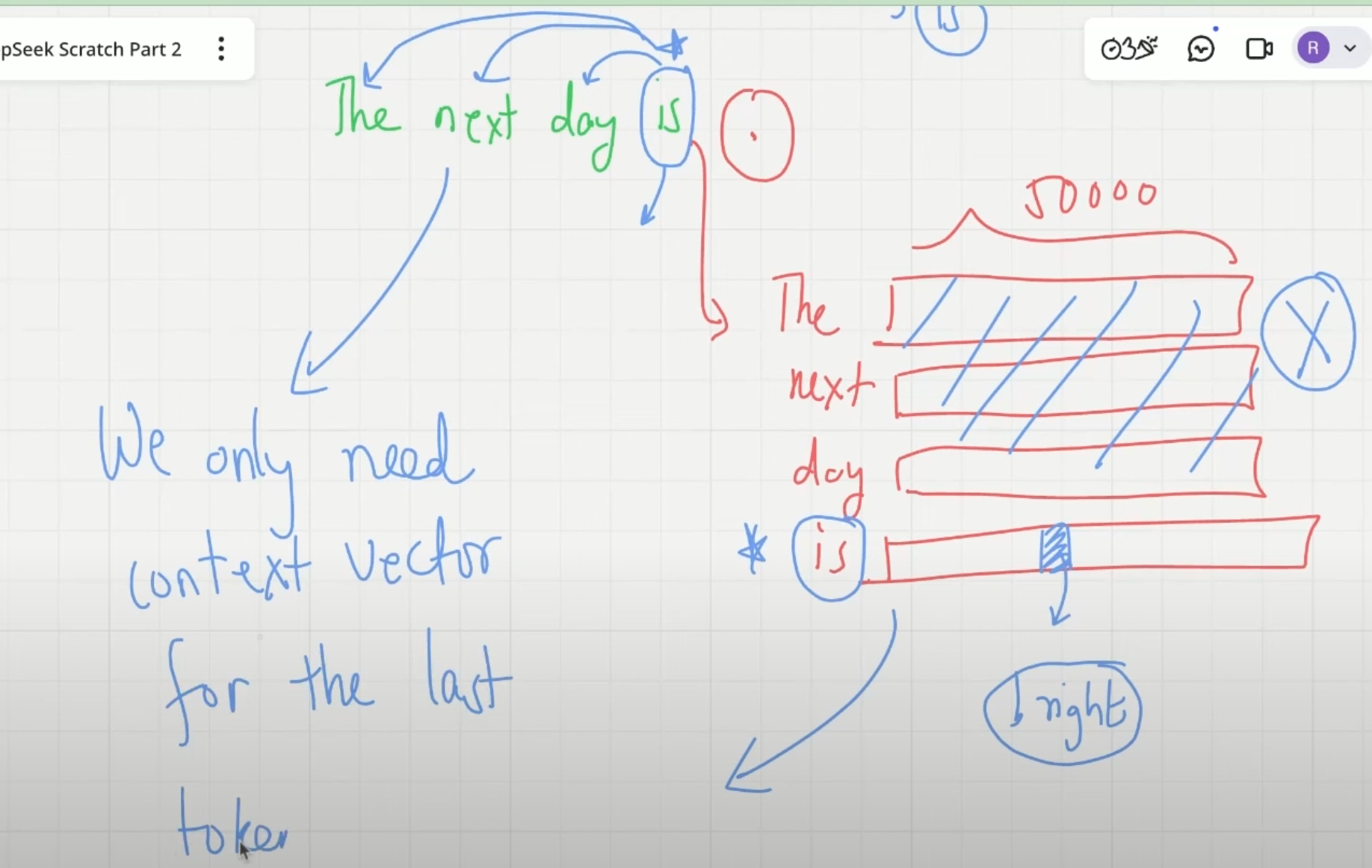
结论:只需要用到 seq 的最后一个 context_vec 来预测下一个 token
在 next-token-pred 中循环单位(预测单元)的阶段结果就是一个确定的 token 或者 token_id,在下一个 token 的预测过程中需要将这个刚预测出来的 token 进行 token_emb、pos_emb 得到 input_vec、在通过 MHA 和 MLP 得到 context_vec、通过映射得到 logits_vec,sample 出 next_token,进入下一个预测单元
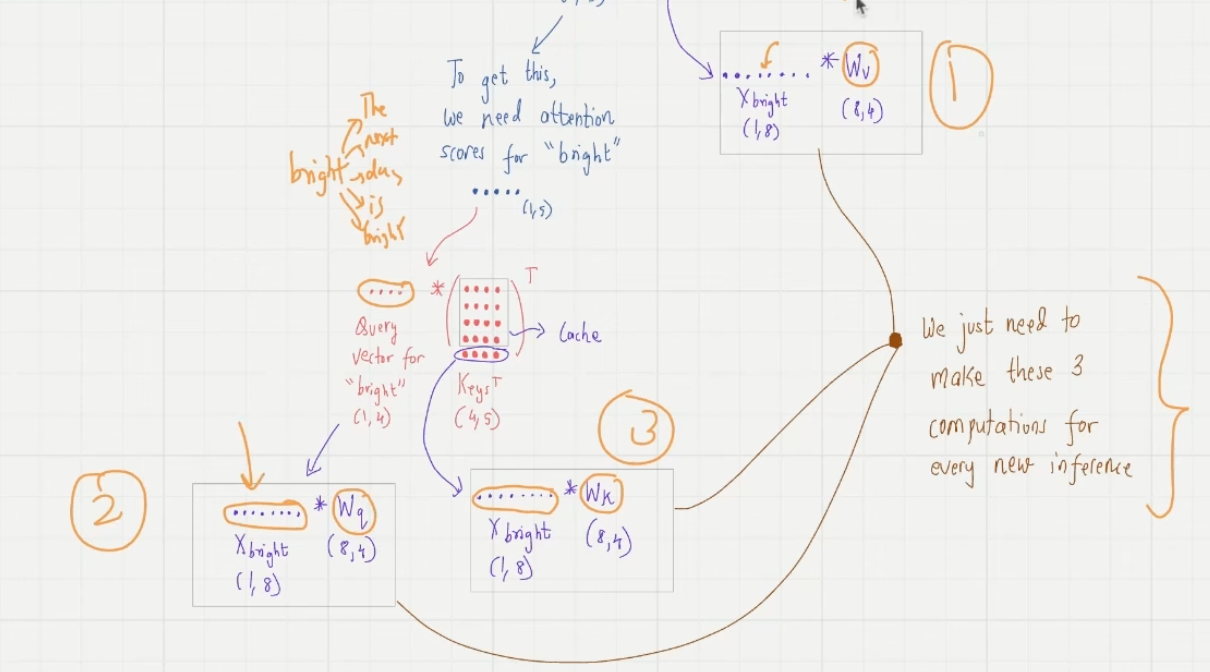
不难发现这个推理过程中有大量的重复计算,根据 is 的 context_vec 得到 bright 的过程和根据 bright 得到下一个 token 的过程中,“The next day is” 的 input_vec 在 MHA 和 MLP 中重复计算,所以可优化的点在于可以保存(Cache)前面的 token 的 attn 、QKV 信息,只计算上一个预测的 token 的 input_vec 与 Cache 中的变量的计算结果,可得到 context_vec
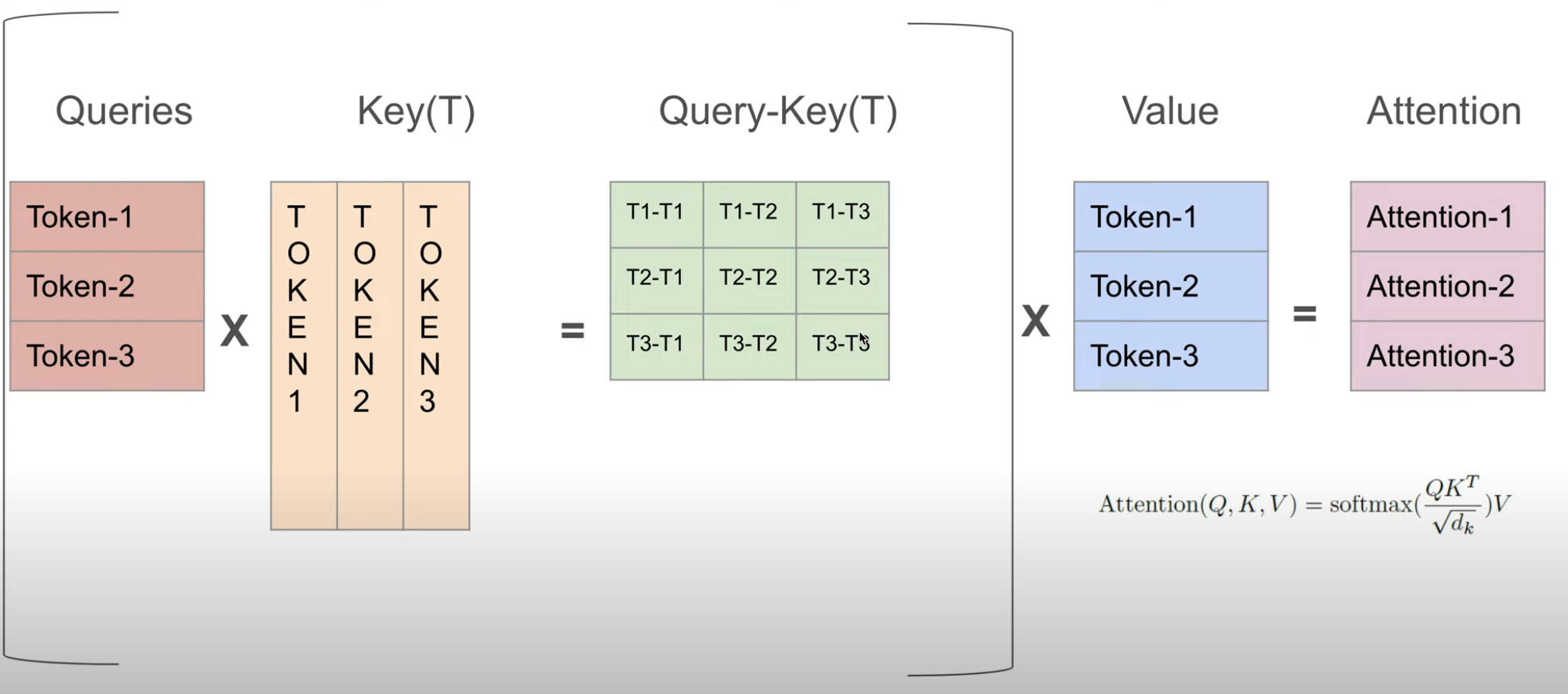
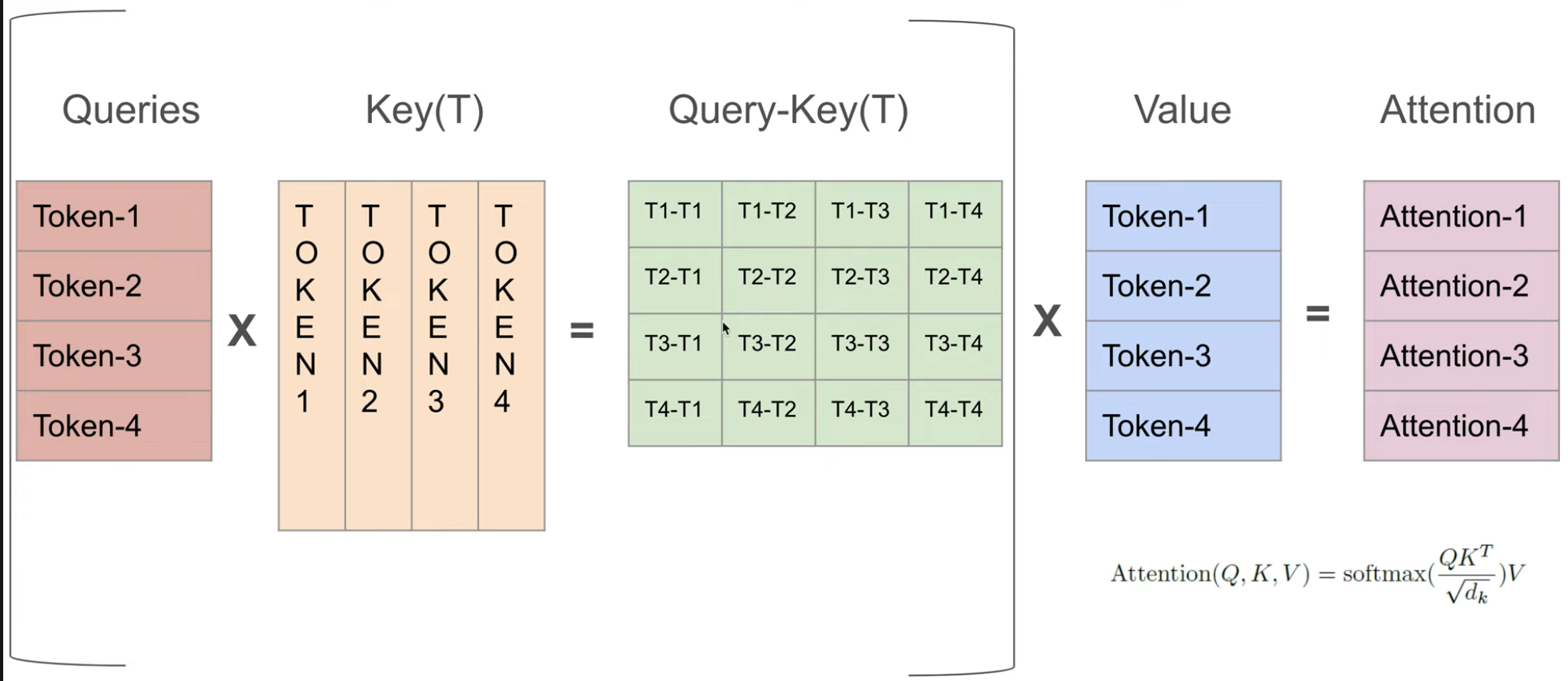
优化:new_input_vec 经过 W_q,W_k,W_v(对于所有 input_vec 都是这三个固定的矩阵),得到 query_vec,key_vec,value_vec,新计算 Attn_scores 矩阵的 n-1 列和 n-1 行,这一步原 query_vec 和 key_vec 也参与计算,scaling+causal+softmax --> attn _weights,value_vec 与 Attn_weights 计算得新的行向量,即 context_vec
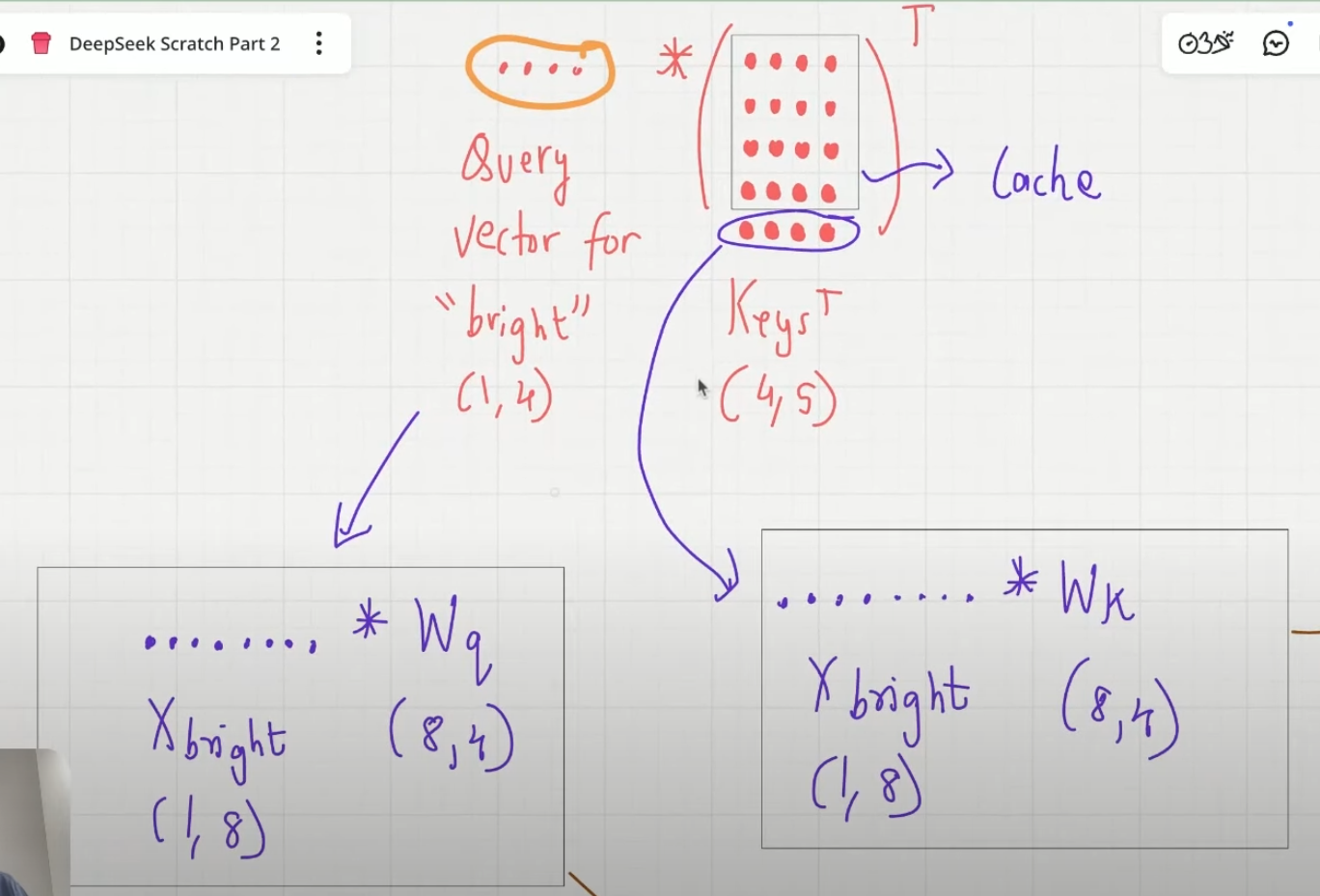
最后一行是 T4 在 T1,T2,T3,T4 上的注意力,在与 value 相乘时作用到对应的 context_vec 上
图解 KV-cache 1
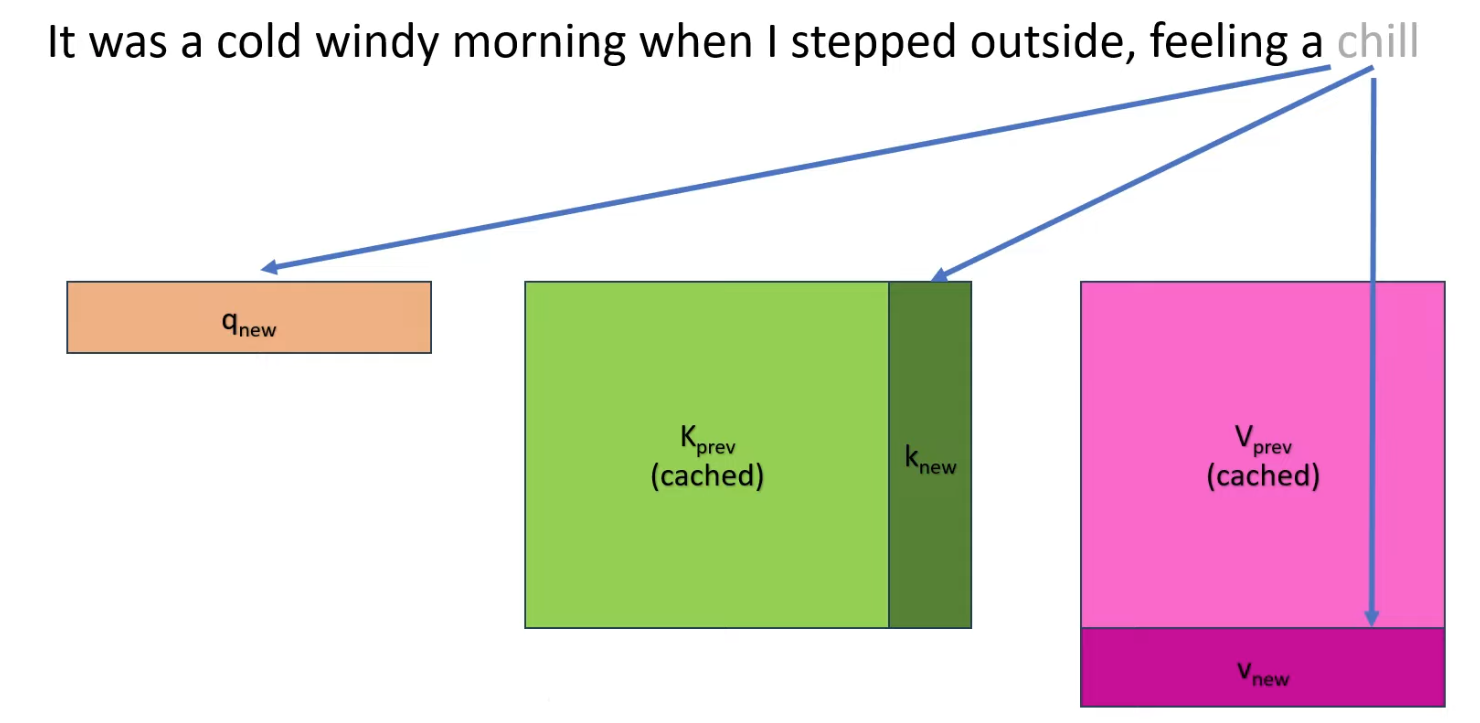
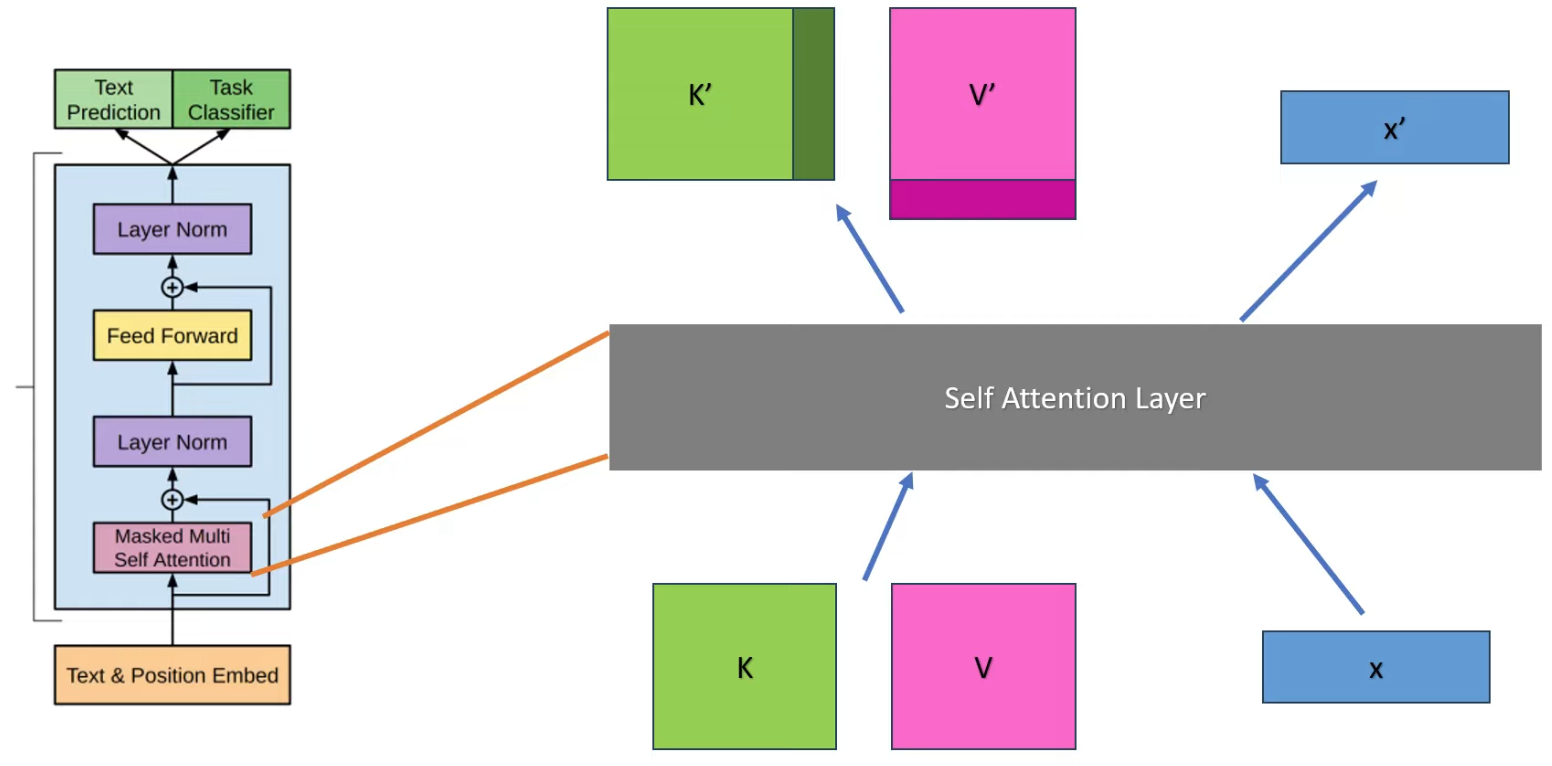
图解 KV-cache 2
缺点是 KV-Cache 会占用大量显存,V3 需要的显存是 400G



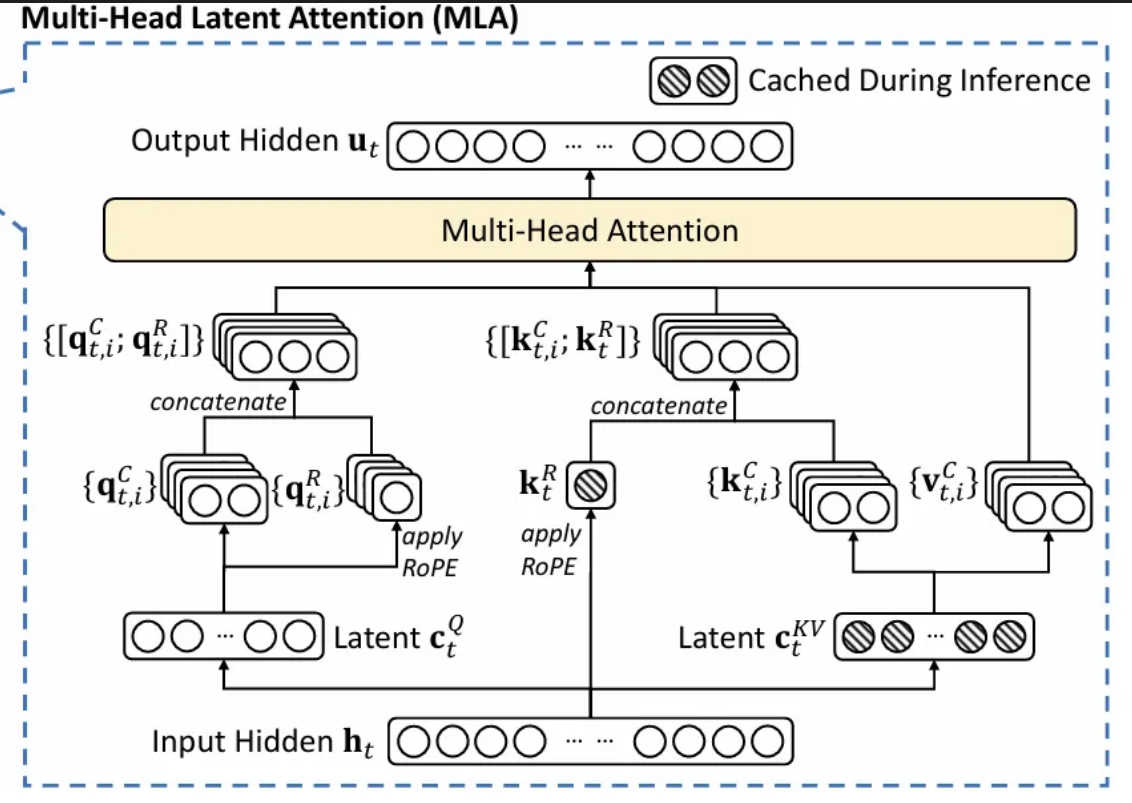
2.1.5. Multi-head Latent Attetion
2.2. MoE:mixture of experts
2.3. MTP:multi-token prediction
2.4. quantization
2.5. rotary position encodings (RoPE)
3. 训练方法
3.1. reforcement learning
3.2. GRPO
3.2.1. RL to teach complex reasoning to the model
3.2.2. Rule based reward system
4. 多 GPU 优化
4.1. PTX 编程加速
NVIDIA Parallel Thread Execution
5. 模型生态系统:model ecosytem
671B --> 1.5B

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)