零代码搭建本地知识库:基于DeepSeek+RAG+Ollama+Cherry Studio全流程指南
核心价值企业敏感数据100%离线处理个人知识库智能问答本地模型快速响应支持PDF/Word/网页等多格式文档工具链Ollama:开源模型托管平台(支持150+模型):深度求索开源的16K长文本大模型:中文语义向量模型:AI应用可视化客户端本方案在Intel i7-12700H + RTX 4070设备上实测,可流畅处理200页以内的技术文档问答。通过本地化部署既保障了数据安全,又充分发挥了Deep
一、方案优势与工具简介
核心价值:通过本地化部署的LLM(DeepSeek)与RAG技术结合,实现:
- 企业敏感数据100%离线处理
- 个人知识库智能问答
- 本地模型快速响应
- 支持PDF/Word/网页等多格式文档
工具链:
- Ollama:开源模型托管平台(支持150+模型)
- DeepSeek-R1:深度求索开源的16K长文本大模型
- dmeta-embedding:中文语义向量模型
- Cherry Studio:AI应用可视化客户端
二、环境准备与工具安装
1. 安装Ollama服务
访问Ollama官网下载对应系统安装包:
- Windows用户双击
.exe自动安装 - macOS使用
brew install ollama - Linux执行
curl -fsSL https://ollama.com/install.sh | sh
验证安装成功:
ollama --version
# 应显示版本号(如:0.1.25)
2. 获取模型文件
在终端执行以下命令(按设备配置选择模型):
# 基础版(8G显存+16G内存)
ollama run deepseek-r1:8b
# 高性能版(24G显存+32G内存)
ollama run deepseek-r1:128b
3. 安装嵌入模型
执行中文向量化模型安装:
ollama run shaw/dmeta-embedding-zh
三、Cherry Studio配置详解
-
客户端安装
从Cherry Studio官网下载最新版本,完成基础安装。 -
连接本地模型服务
-
左下角设置 → 模型服务 → Ollama
-
添加模型服务:```
API地址: http://localhost:11434/v1/
API密钥: 任意字符(本地验证可不填) -
点击「检查连接」确认状态正常
-
-
关键配置项
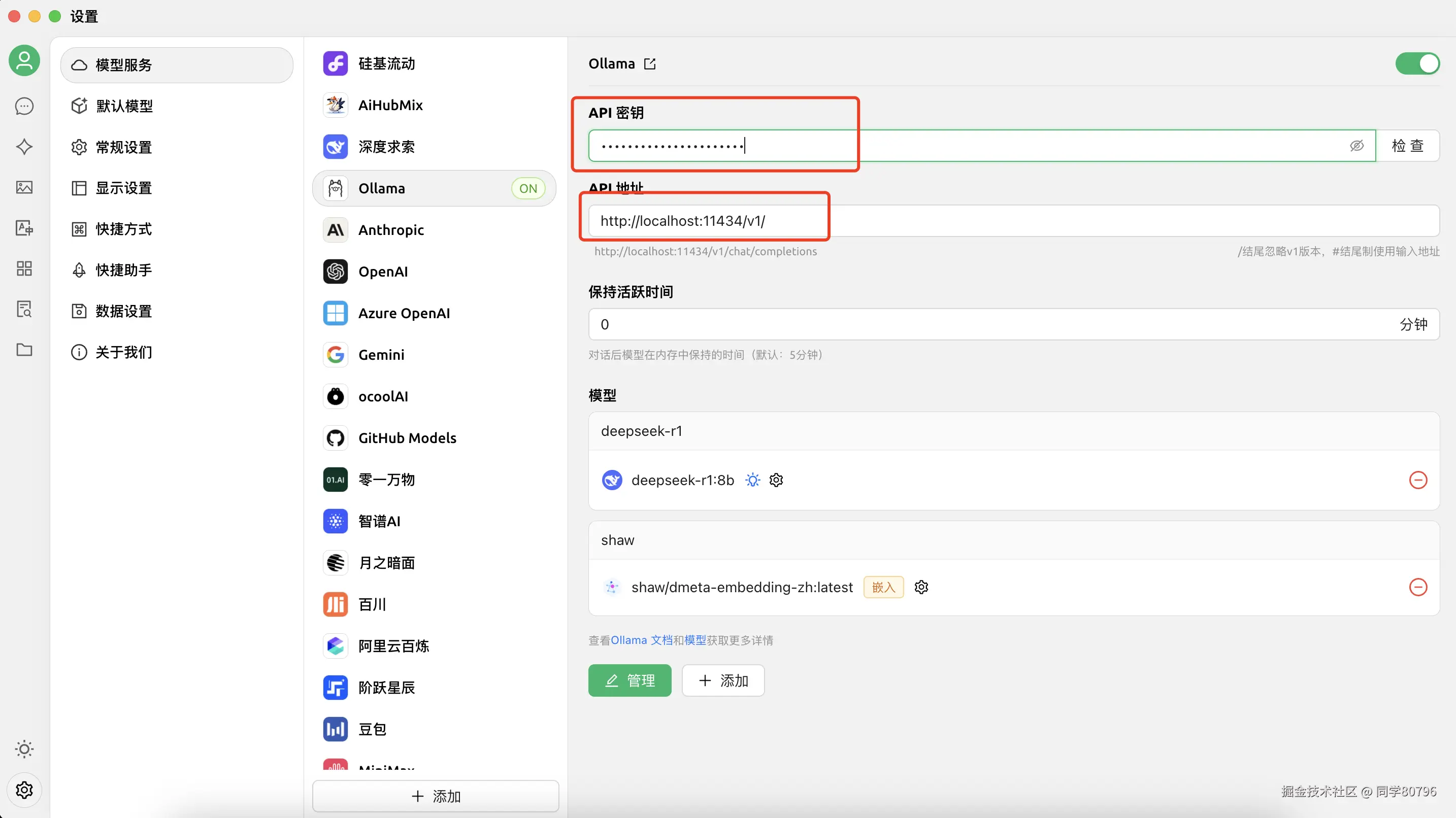
- 务必为
dmeta-embedding-zh选择嵌入模式 - 设置默认对话模型为
deepseek-r1 - 调整上下文长度至16K(匹配模型能力)
- 务必为
四、知识库创建实战
-
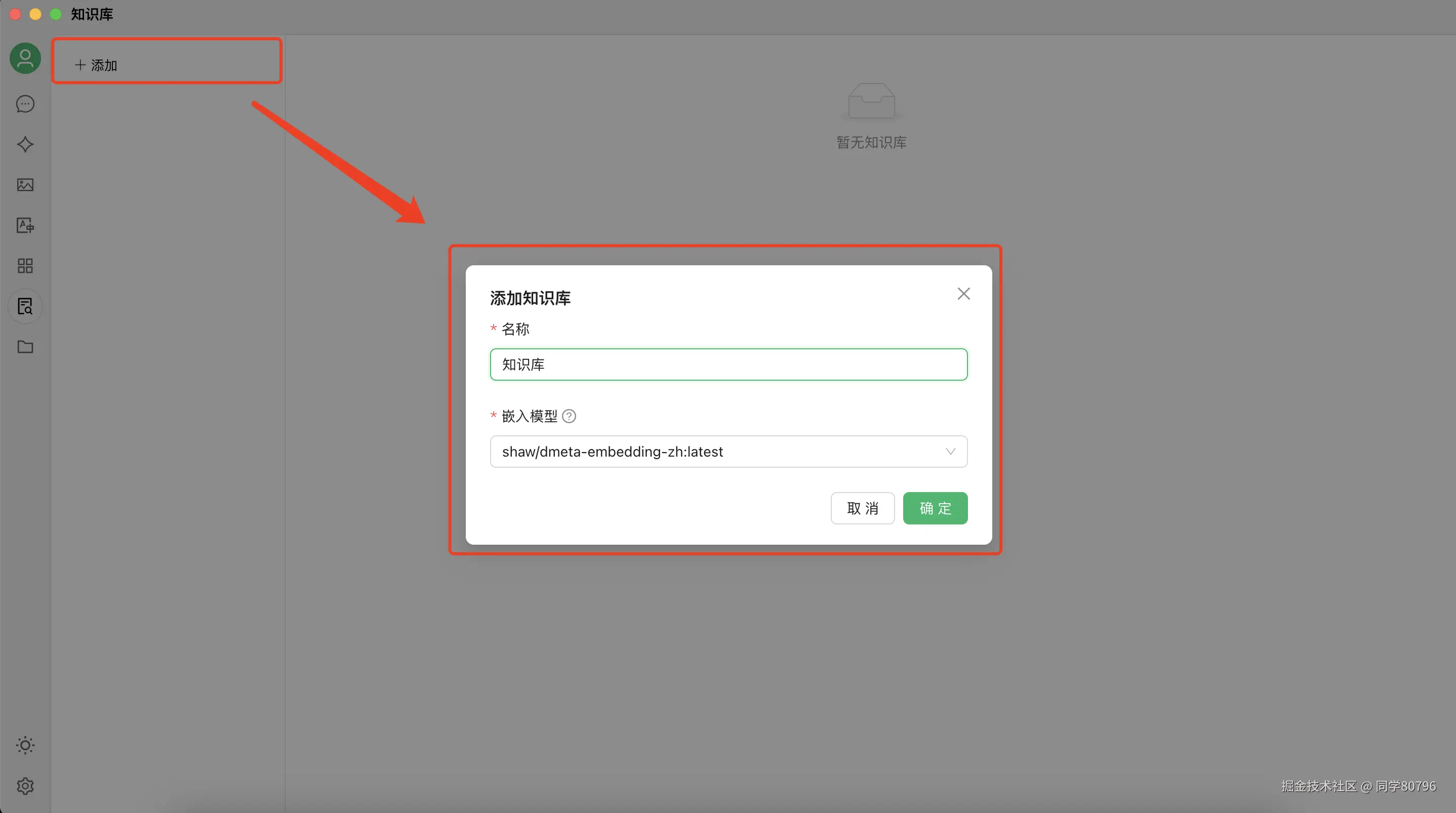
新建知识库
- 点击「知识库」→「新建」
- 命名后选择
dmeta-embedding-zh作为嵌入模型
-
文档导入技巧
- 支持格式:PDF/Word/Markdown/HTML/TXT
- 批量上传建议不超过50个文件
- 网页抓取需完整URL(支持https)
-
向量化处理
上传后自动启动解析,进度条显示绿色即完成。常见处理速度:- 文本文件:约100页/分钟
- PDF扫描件:依赖OCR识别速度
五、智能问答测试
-
基础对话测试
# 示例问题 "请解释RAG技术的工作原理"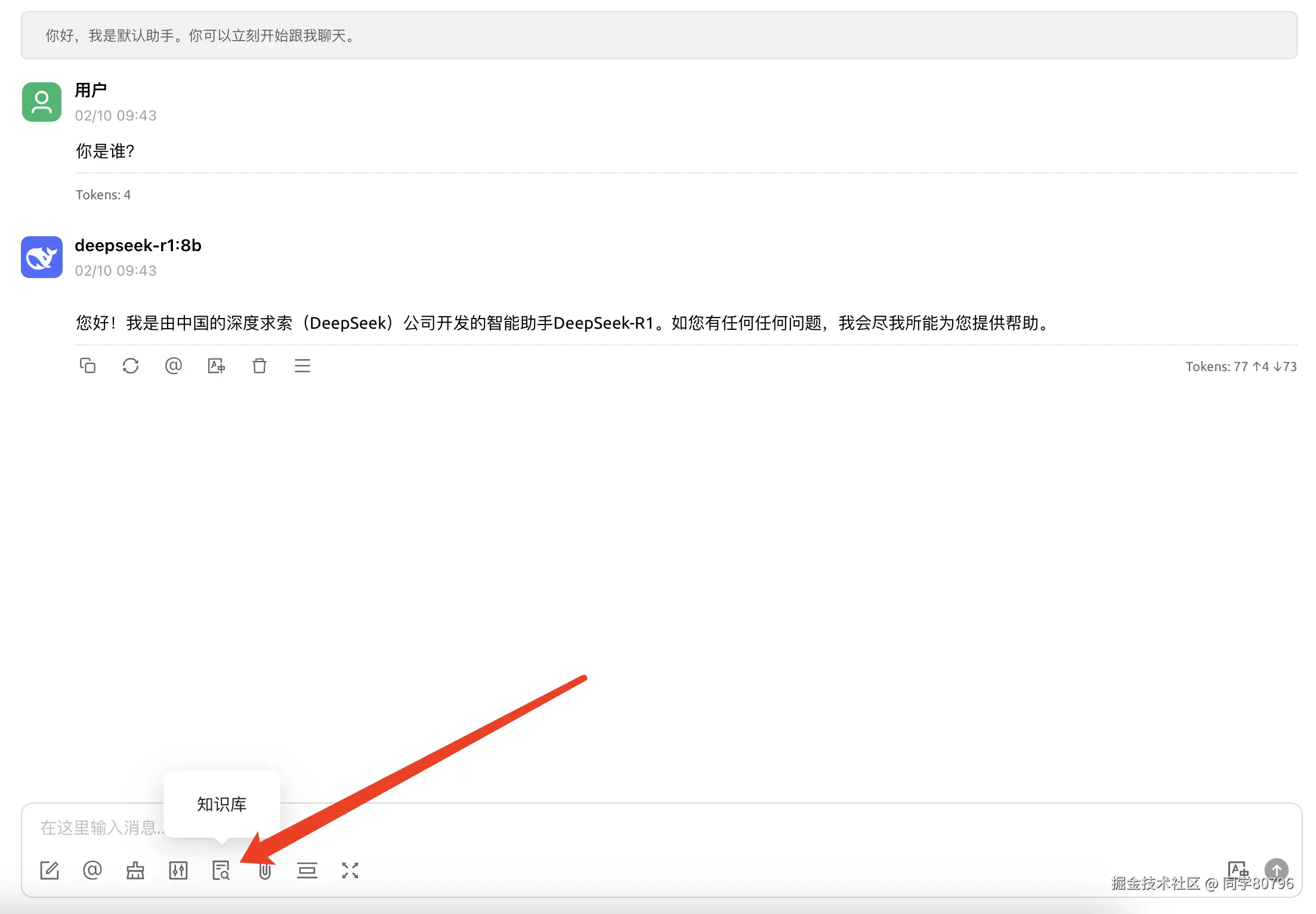
-
知识库检索验证
# 基于上传文档提问 "我们公司2023年的研发投入占比是多少?" -
混合问答模式
"结合行业趋势分析,我们的产品路线图需要哪些调整?"
六、高级配置技巧
-
性能优化方案
# 调整Ollama运行参数 OLLAMA_NUM_GPU=2 ollama serve -
多知识库协同
- 创建
技术文档、市场情报等分类库 - 通过
@知识库名称指定检索源
- 创建
-
API集成开发
import requests response = requests.post( "http://localhost:11434/v1/chat/completions", json={ "model": "deepseek-r1", "messages": [{"role": "user", "content": "问题内容"}] } )
七、常见问题排查
| 现象 | 解决方案 |
|---|---|
| 模型加载失败 | 检查显存占用,尝试较小模型 |
| 知识库检索无结果 | 确认dmeta模型设为嵌入模式 |
| 响应速度慢 | 调整Ollama的num_ctx参数 |
| 中文乱码 | 安装中文字体包并重启服务 |
结语
本方案在Intel i7-12700H + RTX 4070设备上实测,可流畅处理200页以内的技术文档问答。通过本地化部署既保障了数据安全,又充分发挥了DeepSeek模型的逻辑推理能力。建议企业用户可将此方案部署在内网服务器,配合NAS实现团队级知识管理。
技术演进路线:
- 短期:接入本地搜索引擎实现混合检索
- 中期:训练行业专属LoRA适配器
- 长期:构建自动化知识图谱系统
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 23
23 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)