实战:Spring AI + DeepSeek + RAG:快速搭建本地AI对话服务
在AI大模型技术快速发展的背景下,如何通过本地调用充分利用AI大模型的能力,解决复杂任务,满足开发者对高性能AI服务的需求。特别是在企业知识库、教育问答等场景中,连续对话AI应用具有巨大的应用价值。文章结合Spring AI、Spring AI Alibaba、DeepSeek-R1模型以及RAG技术,手把手教你如何利用Docker容器化部署Redis和Elasticsearch,搭建一个支持连续
概述
在 AI 大模型技术飞速发展的当下,如何充分利用 AI 大模型的能力,通过本地调用完成复杂任务,成为了广大开发者关注的焦点。特别是在企业内部知识库、教育问答系统等场景中,能够实现连续对话的 AI 应用具有巨大的应用价值。本文将结合 Spring AI、Spring AI Alibaba、DeepSeek-R1 模型以及 RAG 技术,手把手教你如何在本地调用这些强大工具,实现一个支持连续对话的 AI 应用。
Spring AI 是一个用于构建 AI 应用的开源框架,特别适用于开发对话系统。它提供了丰富的工具和库,帮助开发者快速搭建、训练和部署基于 AI 模型的应用程序。Spring AI Alibaba 则是 Spring AI 的扩展模块,旨在与阿里巴巴的技术生态无缝集成。它提供了与阿里云服务(如 DeepSeek-R1 模型)的便捷连接方式,简化了在阿里云环境中开发 AI 应用的流程。通过 Spring AI Alibaba,开发者可以更高效地利用阿里云的 AI 能力,构建高性能的对话系统和其他 AI 应用。
阿里云百炼平台: 为开发者提供了强大的 AI 能力支持。在本项目中,我们将通过百炼平台调用 DeepSeek-R1 模型,还将使用百炼平台提供的嵌入模型 text-embedding-v2,用于将文本数据转化为向量形式,以便更好地进行相似度计算和检索操作,从而为对话系统提供更精准的信息支持。如何申请可以查看 如何springAI如何集成百炼平台
RAG(检索增强生成) 作为一种新兴的技术范式,通过结合检索和生成模型,能够有效地提高信息检索和内容生成的准确性和相关性。在AI对话系统中,RAG可以用于从大量的文本数据中检索相关信息,并将其融入到对话生成过程中,使得对话更加准确、连贯和富有信息量。
这是一篇全家桶式教程,主要内容包括:
- 环境搭建:从安装Docker开始,到通过Docker安装Redis、ElasticSearch
- Spring AI集成:详细讲解如何讲springAI Alibaba集成
deepseek-r1大模型,以及嵌入向量模型text-embedding-v2,并实现连续对话功能。- 效果验证:通过实际测试,展示系统的运行效果,让你直观感受这一方案的强大之处。
环境准备
在开始之前,请确保你的环境满足以下要求:
- 操作系统:Windows 11
- Java版本:JDK 17+(请注意Spring Boot 3.4.4的兼容性)
- 依赖管理:Maven 3.8.3+
环境搭建(Docker,Redis, ElasticSearch)
1. 安装docker
本地环境使用Docker进行部署,可以大大节省环境配置的工作量,同时减少组件对系统性能的影响。在不开发时,关闭Docker,还能避免各种干扰。对于还不熟悉Docker的同学,建议尽快学习掌握这一强大工具。
由于很多教程都是基于Linux系统的,这里我们详细讲解一下在Windows本地环境下的搭建步骤。首先,访问docker官网,根据你的系统选择合适的版本进行下载和安装。安装完成后,进入PowerShell,输入指令docker ps,如果能看到相关输出,说明Docker安装成功。

安装后,进入PowerShell,输入指令 docker ps ,看到这个就OK了

上述命令用于查看当前运行的容器,若能正常输出容器信息,说明Docker服务已成功启动并正常运行。
2.Redis容器部署
说明:此命令从Docker Hub拉取指定版本的Redis镜像,为后续的容器部署做好准备。
docker pull redis:7.4.2
在本地创建文件夹C:\docker\redis\conf和C:\docker\redis\data,并在conf文件夹下创建文件redis.conf,内容如下:
bind 0.0.0.0
port 6379
requirepass 123123
dir /data
appendonly yes
bind 0.0.0.0:允许外部访问requirepass 123123:设置访问密码,你可以根据需要自行设定,虽然是本地环境,但养成良好的安全习惯很重要appendonly yes:开启AOF持久化
接下来,进行容器部署:
docker run -d \
-p 6579:6379 \
-v C:/docker/redis/data:/data \
-v C:/docker/redis/conf:/usr/local/etc/redis \
--name redis \
redis:7.4.2 redis-server /usr/local/etc/redis/redis.conf
说明:通过上述命令,我们基于刚才拉取的镜像创建并启动了一个Redis容器,同时将本地的配置文件和数据目录挂载到容器中,方便进行持久化存储和配置管理。
3. 安装ElasticSearch
注意不要用太新的版本,目前经过我的测试,用的版本也只是 elasticsearch:8.13.4
docker pull elasticsearch:8.13.4
在本地创建文件夹 C:\docker\elasticsearch\data,和C:\docker\elasticsearch\plugins,路径可以自己定,一会路径映射的时候记得匹配好
docker run -d `
-p 9200:9200 -p 9300:9300 `
-e "discovery.type=single-node" `
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" `
-e "xpack.security.enabled=false" `
-v C:\docker\elasticsearch\data:/usr/share/elasticsearch/data `
-v C:\docker\elasticsearch\plugins:/usr/share/elasticsearch/plugins `
--name elasticsearch elasticsearch:8.13.4
说明:通过上述命令,我们基于刚才拉取的镜像创建并启动了一个elasticsearch容器,同时将本地的配置文件和数据目录挂载到容器中,方便进行持久化存储和配置管理。
下面我们来看看docker的运行情况吧
Spring AI 集成与代码实现
1. maven的核心依赖
<!-- 全局属性管理 -->
<properties>
<java.version>23</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!-- 自定义依赖版本 -->
<spring-boot.version>3.4.4</spring-boot.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
<spring-alibaba.version>1.0.0-M6.1</spring-alibaba.version>
<maven.compiler.version>3.11.0</maven.compiler.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>${spring-alibaba.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<optional>true</optional>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 构建配置 -->
<build>
<plugins>
<!-- 编译器插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.compiler.version}</version>
<configuration>
<release>${java.version}</release>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
<!-- Spring Boot打包插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<!-- 仓库配置 -->
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
说明:上述配置文件中,我们引入了Spring Boot、Spring AI、Alibaba Cloud AI等核心依赖,确保项目能够顺利构建和运行。同时,通过配置Maven插件和仓库,优化项目的构建流程和依赖管理。
2. 核心配置(application.yml)
这里一定要注意的是文本推理模型 model: deepseek-r1, 嵌入模型model: text-embedding-v2用来生成文本的向量数据
server:
port: 8080
spring:
application:
name: Ollama-AI
data:
redis:
host: 127.0.0.1
port: 6579
password: 123123
database: 1
elasticsearch:
uris: http://127.0.0.1:9200
ai:
dashscope:
# 注意这个理是使用阿里云百炼平台的API-KEY
api-key: sk-************
model: deepseek-r1
embedding:
options:
# 嵌入的向量模型
model: text-embedding-v2
vectorstore:
elasticsearch:
initialize-schema: true
index-name: spring-ai-rag
dimensions: 1536
similarity: cosine
batching-strategy: TOKEN_COUNT
说明:在配置文件中,我们设置了服务器端口、Redis连接信息、Elasticsearch地址以及AI模型的相关参数。通过这些配置,项目能够正确连接到各个服务,并使用指定的模型进行对话处理和数据存储。
3. 实现连续对话
3.1 控制器层(DeepseekChatController.java)
@Slf4j
@RestController
@RequestMapping("/ai/v1")
public class DeepseekChatController {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
@Autowired
private ChatMemory chatMemory;
@GetMapping("/data/load")
public String loadData() throws IOException {
// 1. 读取文件
DocumentReader reader = new TextReader("static/demoHospital.txt");
List<Document> documents = reader.get();
// 2.切分文件:根据空白行进行分割
List<Document> splitDocuments = new TokenTextSplitter().apply(documents);
log.info("文件切分为 [{}]", splitDocuments.size());
// 3.写入数据
vectorStore.add(splitDocuments);
return "loadData -- Done" ;
}
@GetMapping("/select")
public String search(@RequestParam("query") String query) {
log.info("query is [{}]", query);
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder().query(query).similarityThresholdAll().build()
);
log.info("results is [{}]", results);
return results.toString();
}
@GetMapping(value = "/rag/chat", produces = "text/plain; charset=UTF-8")
public String ragChat(@RequestParam String userId, @RequestParam String message) {
log.info("userId -> [{}], message --> [{}]", userId, message);
String text = chatClient.prompt()
.user(message)
.advisors(new MessageChatMemoryAdvisor(chatMemory,userId,10))
.call().content();
return text;
}
}
说明:该控制器类提供了三个接口,分别用于数据加载、数据检索和连续对话。通过这些接口,用户可以与AI系统进行交互,实现数据的存储、查询和对话功能。其中,/rag/chat接口利用ChatClient和ChatMemory实现了连续对话的核心逻辑。这里提供了3个接口:
1. 数据加载接口(/data/load)
- 功能:将预准备的文本数据加载到系统中。
- 流程:读取文本文件,将内容切分成小段,通过嵌入模型转化为向量,存储到向量存储中。
- 作用:为后续的对话和检索提供数据基础。
2. 数据检索接口(/select)
- 功能:根据用户输入的查询内容,检索最相关的数据。
- 流程:将用户查询转化为向量,在向量存储中搜索相似内容,返回相关结果。
- 作用:快速找到与用户问题最相关的答案。
3. 连续对话接口(/rag/chat)
- 功能:实现多轮连续对话。
- 流程:接收用户消息,结合之前的对话历史(通过ChatMemory获取),调用AI模型生成回复。
- 作用:让AI能够根据上下文生成连贯的回复。
通过这三个接口,DeepseekChatController实现了从数据加载到检索再到连续对话的完整流程,让AI能够高效地与用户互动。
3.2 Redis持久化(ChatRedisMemory.java)
@Slf4j
@Component
public class ChatRedisMemory implements ChatMemory {
private static final String KEY_PREFIX = "chat:history:";
private final RedisTemplate<String, Object> redisTemplate;
public ChatRedisMemory(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Override
public void add(String conversationId, List<Message> messages) {
String key = KEY_PREFIX + conversationId;
List<ChatEntity> listIn = new ArrayList<>();
for(Message msg: messages){
String[] strs = msg.getText().split("</think>");
String text = strs.length==2?strs[1]:strs[0];
ChatEntity ent = new ChatEntity();
ent.setChatId(conversationId);
ent.setType(msg.getMessageType().getValue());
ent.setText(text);
listIn.add(ent);
}
redisTemplate.opsForList().rightPushAll(key,listIn.toArray());
redisTemplate.expire(key, 30, TimeUnit.MINUTES);
}
@Override
public List<Message> get(String conversationId, int lastN) {
String key = KEY_PREFIX + conversationId;
Long size = redisTemplate.opsForList().size(key);
if (size == null || size == 0){
return Collections.emptyList();
}
int start = Math.max(0, (int) (size - lastN));
List<Object> listTmp = redisTemplate.opsForList().range(key, start, -1);
List<Message> listOut = new ArrayList<>();
ObjectMapper objectMapper = new ObjectMapper();
for(Object obj: listTmp){
ChatEntity chat = objectMapper.convertValue(obj, ChatEntity.class);
// log.info("MessageType.USER [{}], chat.getType [{}]",MessageType.USER, chat.getType());
if(MessageType.USER.getValue().equals(chat.getType())){
listOut.add(new UserMessage(chat.getText()));
}else if(MessageType.ASSISTANT.getValue().equals(chat.getType())){
listOut.add(new AssistantMessage(chat.getText()));
}else if(MessageType.SYSTEM.getValue().equals(chat.getType())){
listOut.add(new SystemMessage(chat.getText()));
}
}
return listOut;
}
@Override
public void clear(String conversationId) {
redisTemplate.delete(KEY_PREFIX + conversationId);
}
}
说明:此组件实现了 ChatMemory 接口,利用Redis进行对话历史记录的持久化存储。通过RedisTemplate操作Redis列表,实现了对话记录的添加、获取和清除功能,确保对话上下文能够在多次请求之间保持连贯,从而支持连续对话。
3.3 配置类与序列化(RedisConfig.java)
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
//生成整个 RedisTemplate
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(factory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
说明:该配置类用于创建 RedisTemplate Bean,通过设置不同的序列化方式,确保在与Redis进行数据交互时,键和值能够正确地进行序列化和反序列化操作,从而保证数据的完整性和可读性。
3.4. 实体类(ChatEntity.java)
@NoArgsConstructor
@AllArgsConstructor
@Data
public class ChatEntity implements Serializable {
String chatId;
String type;
String text;
}
说明:这是一个简单的Java实体类,用于表示对话中的每一条消息记录。包含对话ID、消息类型和消息文本三个属性,通过Lombok的注解自动生成构造方法、getter和setter方法,简化了代码编写。
3.5 聊天对话的初始化bean
@Configuration
@RequiredArgsConstructor
public class ChatInit {
private final VectorStore vectorStore;
@Autowired
private ChatModel chatModel;
@Bean
public ChatClient chatClient(ChatMemory chatMemory) {
return ChatClient.builder(chatModel)
.defaultSystem("以哪吒2电影里的太乙真人的语气回答问题")
.defaultAdvisors(
new QuestionAnswerAdvisor(vectorStore, SearchRequest.builder().similarityThreshold(0.1).topK(10).build())
)
.build();
}
@Bean
public ChatMemory chatMemory(RedisTemplate<String, Object> redisTemplate) {
return new ChatRedisMemory(redisTemplate);
}
}
说明: 为了增加趣味性,我让deepseek用 太乙真人 的语气和我们对话。通过配置 ChatClient 和 ChatMemory,实现了对话客户端的初始化,确保对话能够按照指定的规则和风格进行。
3.5. 启动类(AlibabaChatVectorApplication.java)
@SpringBootApplication
public class AlibabaChatVectorApplication {
public static void main(String[] args) {
SpringApplication.run(AlibabaChatVectorApplication.class, args);
}
}
说明: 这是Spring Boot应用的启动类,通过 @SpringBootApplication 注解启用Spring Boot的功能,提高应用的性能和效率。
数据准备
我让kimi帮我生成了一个医院的介绍,包含
- 医院
不爱学习康复医院的介绍, - 3个科室的介绍,分别是
学不会科,学不好科,爱学习科 - 每个科室也有对应的医生信息
文本名称 demoHospital.txt
1. 医院介绍
不爱学习康复医院坐落在风景如画的青云市,是一所独具特色的康复专科医院。医院秉持着“让学习不再成为负担,助力患者重拾学习热情”的理念,专注于帮助各类学习障碍患者恢复学习能力,提升学习信心。自2015年建院以来,医院凭借其专业的医疗团队、先进的康复设备和个性化的治疗方案,赢得了患者和家属的广泛赞誉。
医院占地面积约50亩,建筑面积达8000平方米,拥有300张床位。医院设有学不会科、学不好科和爱学习科等特色科室,配备了智能康复机器人、虚拟现实康复系统等先进设备,为患者提供全面、科学的康复治疗。目前,医院有职工300余人,其中高级职称专家50余名,硕士研究生导师20名。他们不仅在临床工作中积累了丰富的经验,还积极参与科研和教学工作,为康复医学的发展做出了重要贡献。
2. 科室介绍
(1)学不会科:
学不会科是医院的核心科室之一,主要针对那些在学习上有严重障碍的患者,如患有注意力缺陷多动障碍(ADHD)、阅读障碍、数学障碍等。科室配备了一支由心理学家、康复治疗师和教育专家组成的多学科团队,为患者提供全面的评估和个性化的康复治疗方案。他们采用认知行为疗法、感觉统合训练、注意力训练等多种方法,帮助患者逐步克服学习障碍,提升学习能力。此外,学不会科还定期开展家长培训课程,帮助家长更好地理解和支持孩子的康复过程,共同助力患者回归正常学习轨道。
(2)学不好科:
学不好科专注于帮助那些学习能力不足但有潜力提升的患者。这些患者可能没有明显的学习障碍,但在学习过程中遇到诸多困难,如学习方法不当、学习动力不足、情绪管理不佳等。科室采用个性化评估和治疗方案,结合认知行为疗法、情绪管理训练和学习技巧辅导等多种方法,帮助患者改善学习效果。学不好科还设有专门的儿童和青少年康复小组,通过游戏化学习和团队合作,激发患者的学习兴趣和动力。此外,科室与学校紧密合作,为患者提供学习支持和跟踪服务,确保患者在康复过程中能够得到持续的指导和帮助。
(3)爱学习科:
爱学习科是医院的新兴科室,专注于帮助患者建立积极的学习心态和良好的学习习惯。科室采用心理辅导、行为矫正和家庭治疗等多种方法,帮助患者克服学习焦虑和拖延症,培养自主学习能力。爱学习科还设有专门的学习能力提升训练营,通过短期集中训练,帮助患者快速提升学习效率和成绩。此外,科室提供线上学习支持服务,方便患者在家中继续接受康复训练。爱学习科致力于帮助每一位患者重拾学习热情,享受学习的乐趣。
3. 医生介绍
(1)张学明宇
性别:男
出生年月:1985年3月
医生职称:主任医师
所在科室:学不会科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:张学明宇教授是学不会科的学科带头人,从事康复医学工作20年。他擅长运用心理学和康复治疗技术,帮助患者克服学习障碍。张教授主持多项省级科研项目,发表学术论文30余篇。他多次受邀参加国内外学术会议,分享临床经验。张教授还积极参与社区康复活动,为患者和家属提供免费咨询和指导。
(2)李梦瑶琪
性别:女
出生年月:1990年7月
医生职称:副主任医师
所在科室:学不好科
毕业院校:本科毕业于“武当医学学院”,硕士毕业于“青城医学研究所”,博士毕业于“昆仑医学大学”。
介绍:李梦瑶琪医生是学不好科的骨干力量,专注于提升患者的认知能力和学习技巧。她熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。李医生积极参与科室的科研工作,多次获得医院科研奖励。她还多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。
(3)王智勇杰
性别:男
出生年月:1988年2月
医生职称:主治医师
所在科室:爱学习科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:王智勇杰医生毕业于多所知名院校,专业基础扎实。他在爱学习科领域积累了丰富的临床经验,尤其擅长帮助患者克服学习焦虑和拖延症。王医生熟练掌握认知行为疗法和情绪管理训练,为患者提供全面的心理支持。他积极参与科室的临床教学工作,为年轻医生传授专业知识和技能。王医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(4)赵思远航
性别:女
出生年月:1992年11月
医生职称:主治医师
所在科室:学不会科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:赵思远航医生是学不会科的优秀青年医生,专注于帮助患者克服学习障碍。她熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。赵医生积极参与科室的科研工作,发表多篇学术论文。她还多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。
(5)刘宇航宇
性别:男
出生年月:1987年6月
医生职称:副主任医师
所在科室:学不好科
毕业院校:本科毕业于“武当医学学院”,硕士毕业于“青城医学研究所”,博士毕业于“昆仑医学大学”。
介绍:刘宇航宇医生从事康复医学工作15年,积累了丰富的临床经验。他擅长运用认知行为疗法和学习技巧辅导,帮助患者改善学习效果。刘医生积极参与科室的科研工作,主持和参与多项科研项目,发表多篇高质量学术论文。他多次受邀参加国内外学术会议,分享临床经验和研究成果。
(6)陈逸风宇
性别:男
出生年月:1989年9月
医生职称:主治医师
所在科室:爱学习科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:陈逸风宇医生是爱学习科的优秀青年医生,专注于帮助患者建立积极的学习心态。他熟练掌握多种心理辅导技术和行为矫正方法,能够为患者提供全面的心理支持。陈医生积极参与科室的科研工作,发表多篇学术论文。他多次参加国际学术交流活动,学习先进的医疗技术和理念,不断提升自己的专业水平。
(7)周雨婷婷
性别:女
出生年月:1991年3月
医生职称:主治医师
所在科室:学不会科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:周雨婷婷医生是学不会科的骨干力量,专注于帮助患者克服学习障碍。她熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。周医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。
(8)孙悦瑶瑶
性别:女
出生年月:1993年1月
医生职称:住院医师
所在科室:学不好科
毕业院校:本科毕业于“武当医学学院”,硕士毕业于“青城医学研究所”,博士毕业于“昆仑医学大学”。
介绍:孙悦瑶瑶医生是学不好科的新生力量,专业基础扎实。她专注于帮助患者提升学习能力,熟练掌握多种心理评估工具和康复治疗方法。孙医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。
(9)徐浩然宇
性别:男
出生年月:1986年5月
医生职称:主任医师
所在科室:爱学习科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:徐浩然宇教授是爱学习科的资深专家,从事康复医学工作20年。他擅长运用心理辅导和行为矫正技术,帮助患者克服学习焦虑和拖延症。徐教授主持多项省级科研项目,发表学术论文40余篇。他多次受邀参加国内外学术会议,分享临床经验。徐教授还积极参与社区康复活动,为患者和家属提供免费咨询和指导。
(10)林晓梦宇
性别:女
出生年月:1990年7月
医生职称:副主任医师
所在科室:学不会科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:林晓梦宇医生是学不会科的骨干力量,专注于帮助患者克服学习障碍。她熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。林医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。
(11)张云飞宇
性别:男
出生年月:1988年2月
医生职称:主治医师
所在科室:学不好科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:张云飞宇医生毕业于多所知名院校,专业基础扎实。他在学不好科领域积累了丰富的临床经验,尤其擅长帮助患者提升学习能力。张医生熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。他积极参与科室的科研工作,发表多篇学术论文。张医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(12)李梦琪琪
性别:女
出生年月:1992年11月
医生职称:主治医师
所在科室:爱学习科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:李梦琪琪医生是爱学习科的优秀青年医生,专注于帮助患者建立积极的学习心态。她熟练掌握多种心理辅导技术和行为矫正方法,能够为患者提供全面的心理支持。李医生积极参与科室的科研工作,发表多篇学术论文。她多次参加国际学术交流活动,学习先进的医疗技术和理念,不断提升自己的专业水平。
(13)王浩宇宇
性别:男
出生年月:1987年6月
医生职称:副主任医师
所在科室:学不会科
毕业院校:本科毕业于“武当医学学院”,硕士毕业于“青城医学研究所”,博士毕业于“昆仑医学大学”。
介绍:王浩宇宇医生从事康复医学工作15年,积累了丰富的临床经验。他擅长运用心理评估和康复治疗技术,帮助患者克服学习障碍。王医生积极参与科室的科研工作,主持和参与多项科研项目,发表多篇高质量学术论文。他多次受邀参加国内外学术会议,分享临床经验和研究成果。
(14)陈逸扬宇
性别:男
出生年月:1989年9月
医生职称:主治医师
所在科室:学不好科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:陈逸扬宇医生是学不好科的优秀青年医生,专注于帮助患者提升学习能力。他熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。陈医生积极参与科室的科研工作,发表多篇学术论文。他多次参加国际学术交流活动,学习先进的医疗技术和理念,不断提升自己的专业水平。陈医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(15)周雨晨宇
性别:女
出生年月:1991年3月
医生职称:主治医师
所在科室:爱学习科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:周雨晨宇医生是爱学习科的骨干力量,专注于帮助患者克服学习焦虑和拖延症。她熟练掌握多种心理辅导技术和行为矫正方法,能够为患者提供全面的心理支持。周医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。周医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(16)孙悦宁宇
性别:女
出生年月:1993年1月
医生职称:住院医师
所在科室:学不会科
毕业院校:本科毕业于“武当医学学院”,硕士毕业于“青城医学研究所”,博士毕业于“昆仑医学大学”。
介绍:孙悦宁宇医生是学不会科的新生力量,专业基础扎实。她专注于帮助患者克服学习障碍,熟练掌握多种心理评估工具和康复治疗方法。孙医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。孙医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(17)徐浩宇航
性别:男
出生年月:1986年5月
医生职称:主任医师
所在科室:学不好科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:徐浩宇航教授是学不好科的资深专家,从事康复医学工作20年。他擅长运用心理辅导和行为矫正技术,帮助患者提升学习能力。徐教授主持多项省级科研项目,发表学术论文40余篇。他多次受邀参加国内外学术会议,分享临床经验。徐教授还积极参与社区康复活动,为患者和家属提供免费咨询和指导。
(18)林晓宇航
性别:女
出生年月:1990年7月
医生职称:副主任医师
所在科室:爱学习科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:林晓宇航医生是爱学习科的骨干力量,专注于帮助患者建立积极的学习心态。她熟练掌握多种心理辅导技术和行为矫正方法,能够为患者提供全面的心理支持。林医生积极参与科室的科研工作,发表多篇学术论文。她多次参加国际学术交流活动,学习先进的医疗技术和理念,不断提升自己的专业水平。林医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(19)张云宇航
性别:男
出生年月:1988年2月
医生职称:主治医师
所在科室:学不会科
毕业院校:本科毕业于“恒山医学院”,硕士毕业于“衡山医学研究所”,博士毕业于“泰山医学大学”。
介绍:张云宇航医生毕业于多所知名院校,专业基础扎实。他在学不会科领域积累了丰富的临床经验,尤其擅长帮助患者克服学习障碍。张医生熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。他积极参与科室的科研工作,发表多篇学术论文。张医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
(20)李梦宇航
性别:女
出生年月:1992年11月
医生职称:主治医师
所在科室:学不好科
毕业院校:本科毕业于“华山医学学院”,硕士毕业于“峨眉医学研究院”,博士毕业于“少林医学大学”。
介绍:李梦宇航医生是学不好科的优秀青年医生,专注于帮助患者提升学习能力。她熟练掌握多种心理评估工具和康复治疗方法,能够为患者制定个性化的治疗方案。李医生积极参与科室的科研工作,发表多篇学术论文。她多次参与社区义诊活动,普及学习障碍防治知识,为提高公众健康意识做出了积极贡献。李医生还致力于学习障碍的科普宣传,通过线上线下多种渠道,为患者和公众提供健康咨询和指导。
测试与验证
环境启动
确保docker部署的redis和ollama服务都正常运行,通过 docker ps查看
如果没有的话, 可以 通过docker start redis, docker start elasticsearch来启动
Spring 服务启动后,我们看看效果吧
我们Spring 项目中,开放了3个接口
数据写入的接口
http://127.0.0.1:8080/ai/v1/data/load
获取数据向量的接口
http://127.0.0.1:8080/ai/v1/select
连读对话的接口
http://127.0.0.1:8080/ai/v1/rag/chat
数据写入
数据写入的接口
http://127.0.0.1:8080/ai/v1/data/load
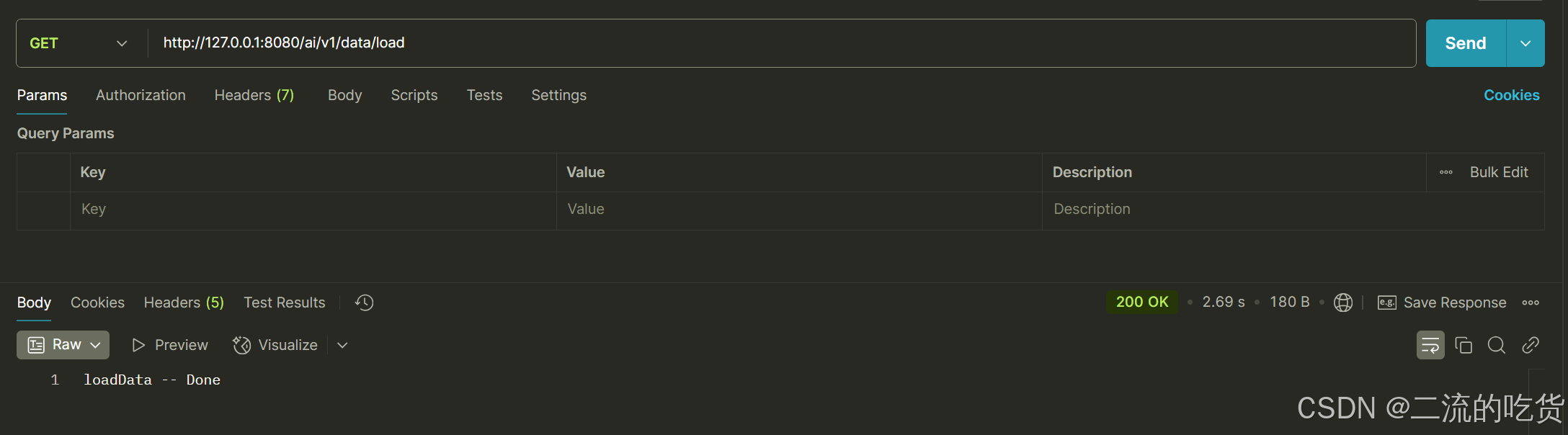
我们查看elastic中,存入了12条数据,也就证明我们接口把文件切分成了12个文件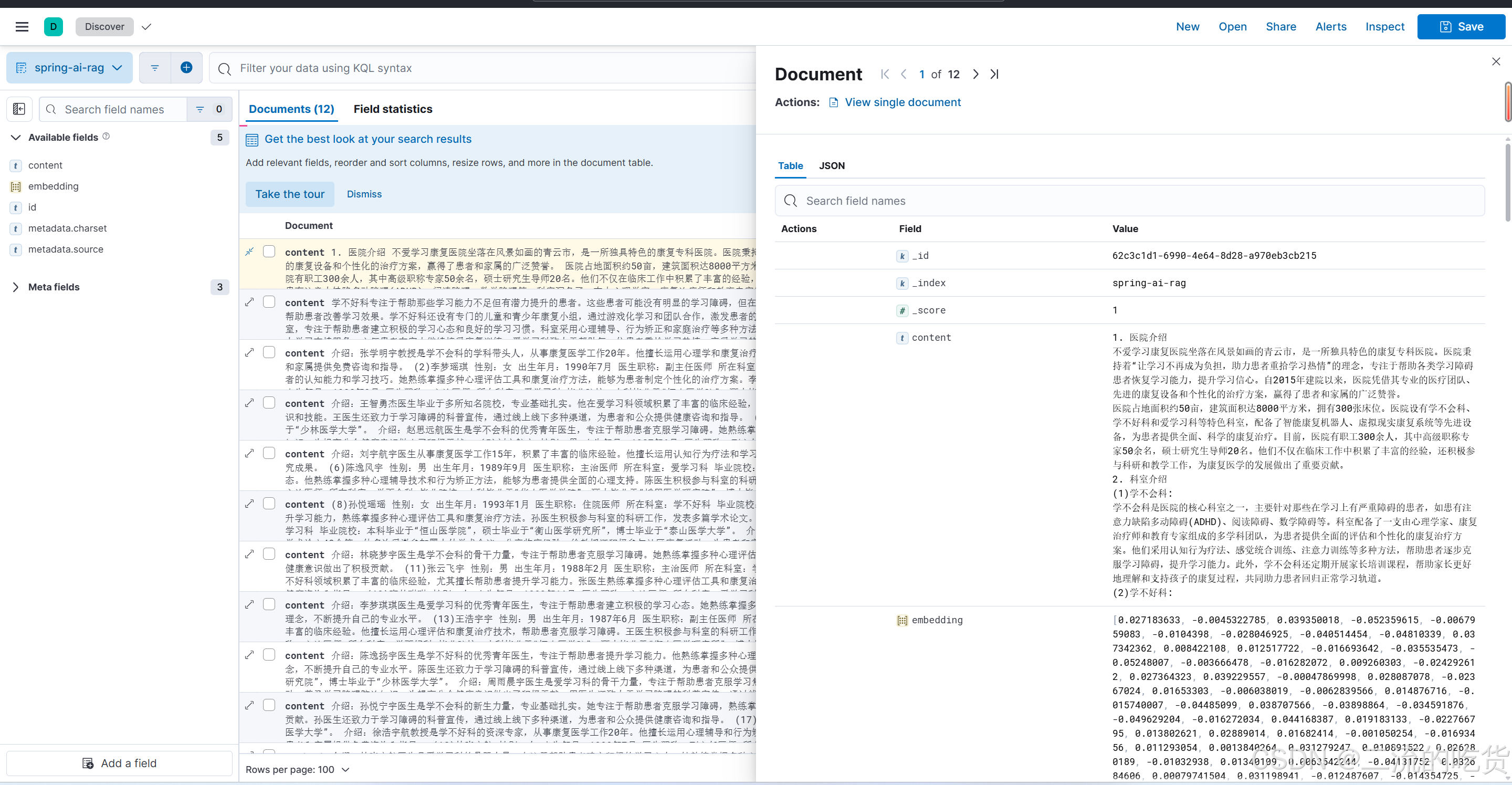
那我们用第二个接口检索一下数据吧
获取数据向量的接口
http://127.0.0.1:8080/ai/v1/select?query=医院介绍
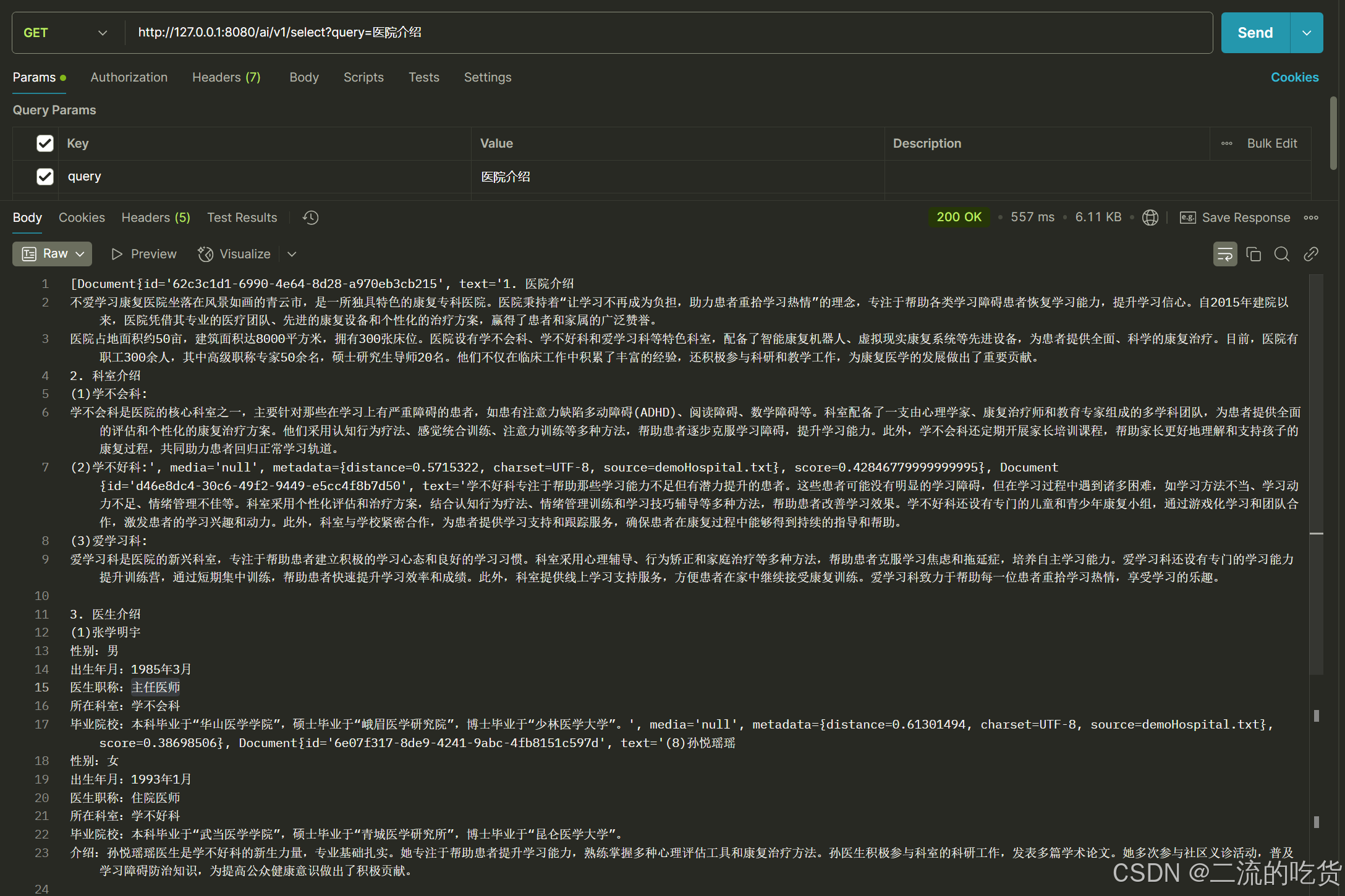
看样子数据都已经存入,可以通过elasticsearch 搜索到医院信息,也就是这些信息会通过聊天接口上传给deepseek
接下来我们就准备验证RAG的能力,也就是检索+连续对话的能力了,我们设计了几个问题
- 请介绍一下医院
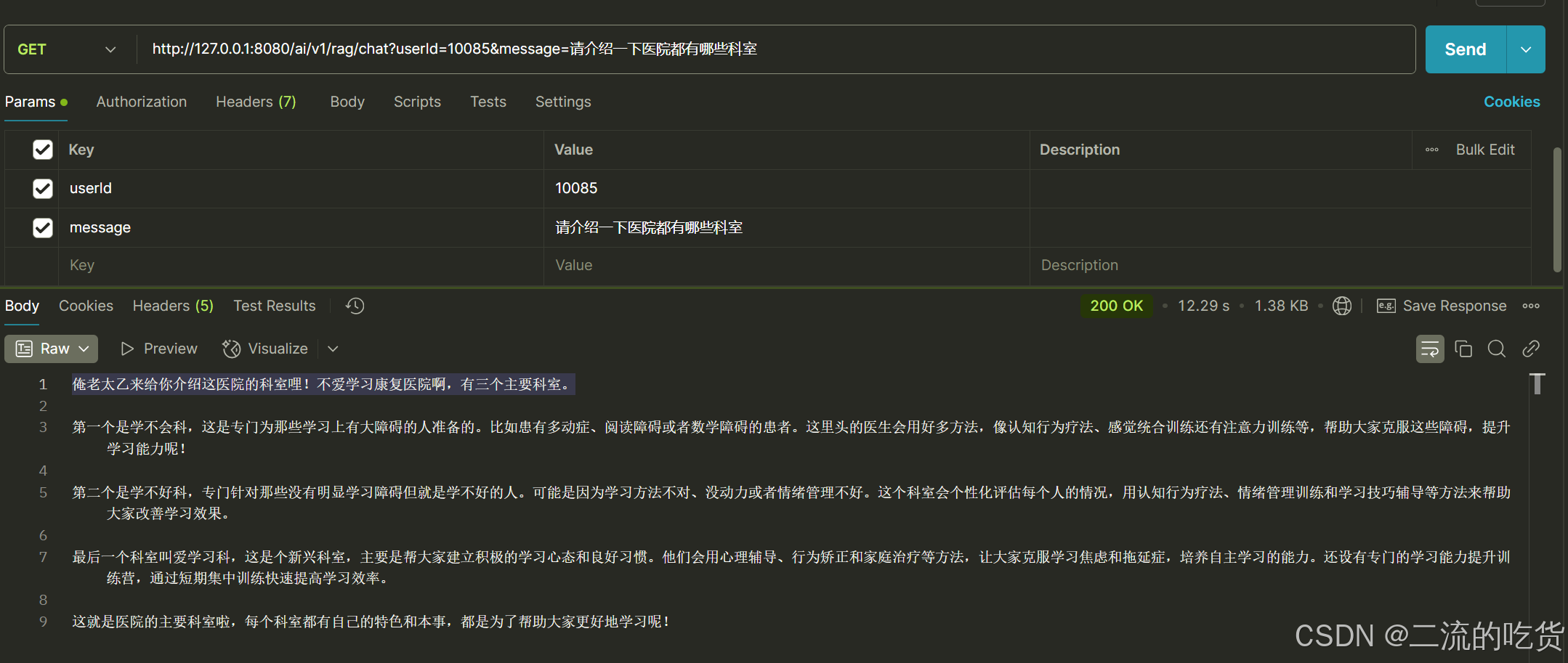
- 请介绍一下医院都有哪些科室
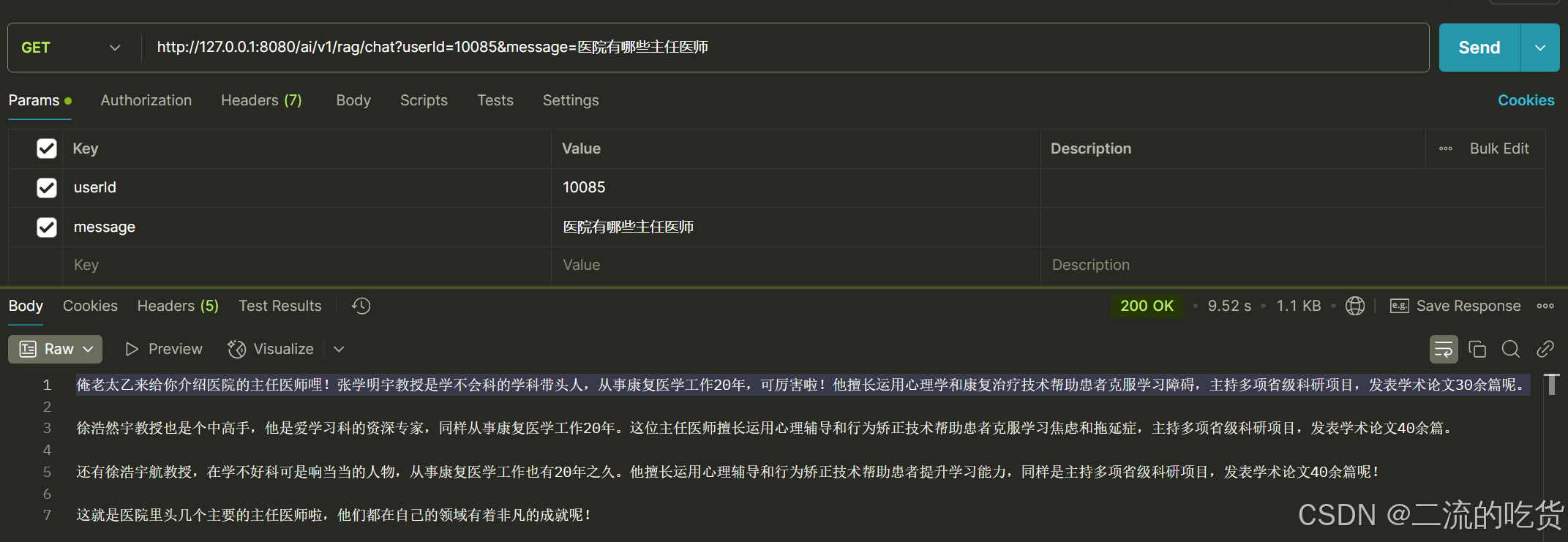
- 医院有哪些主任医师
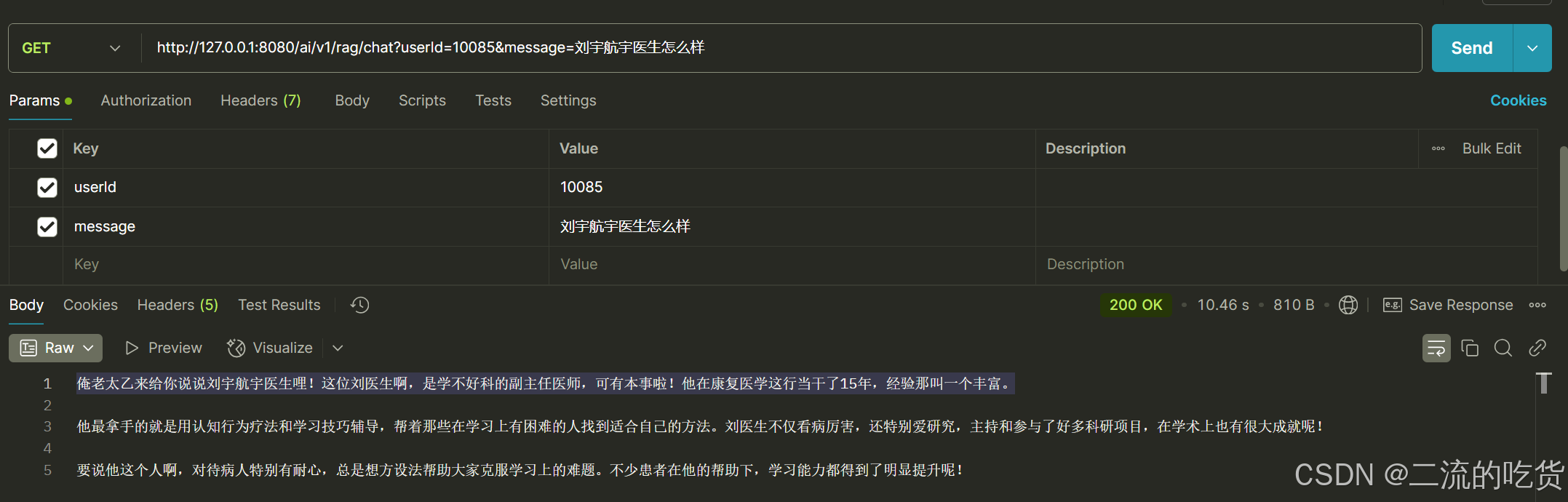
- 刘宇航宇医生怎么样
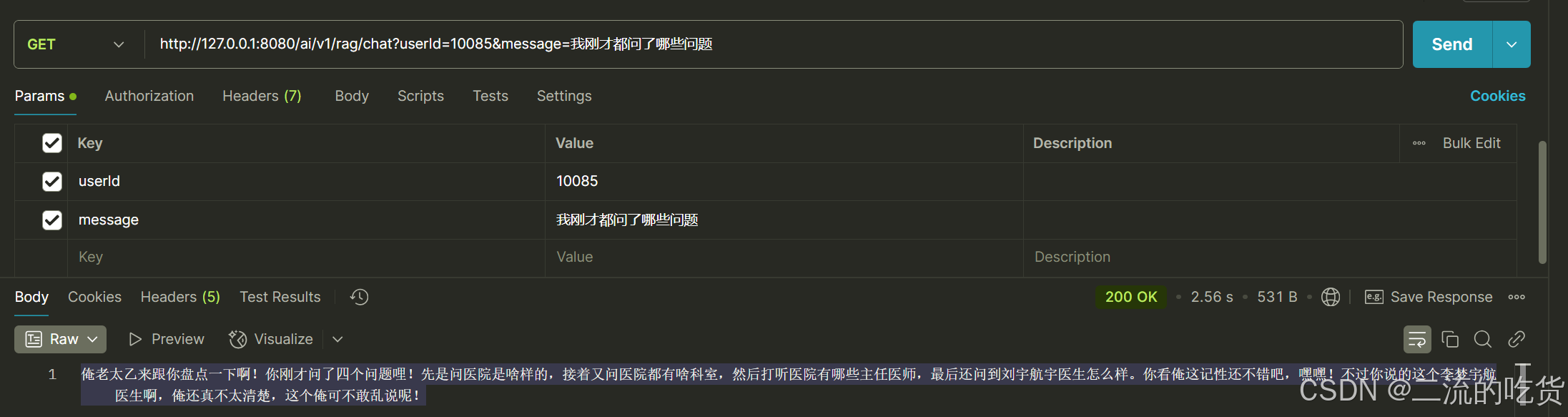
- 我刚才都问了哪些问题
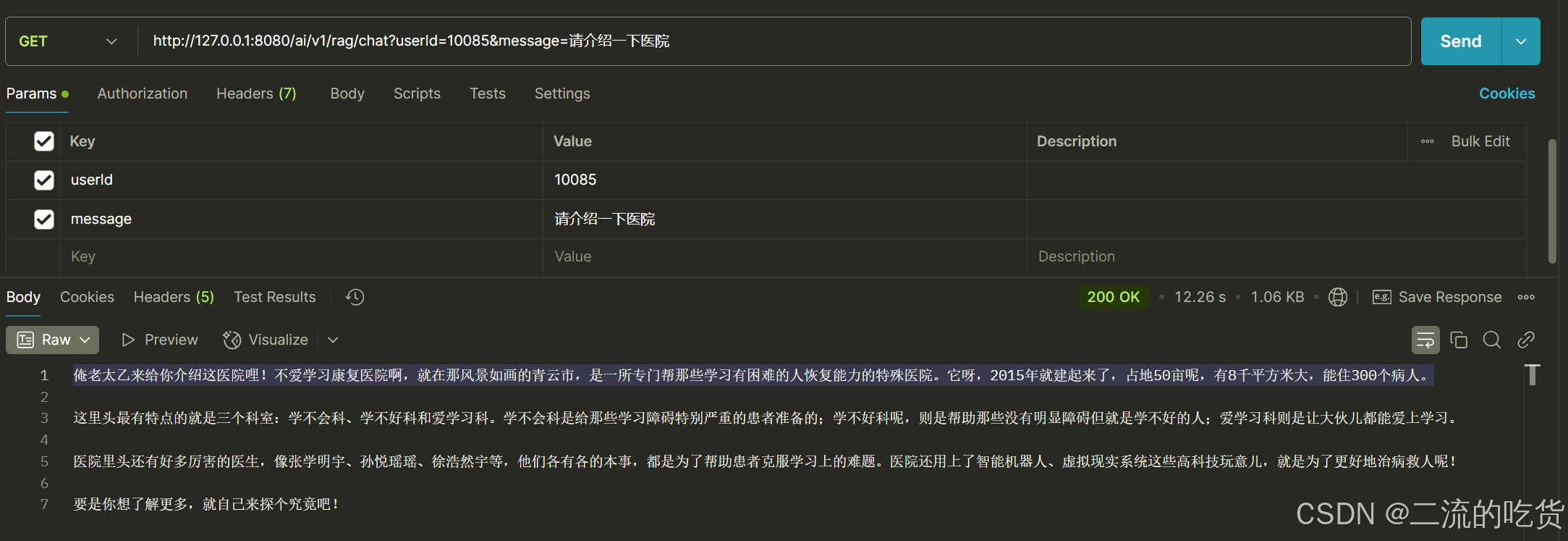
通过这些问题,可以全面测试系统的检索和对话功能,验证其是否能够准确回答用户的问题,并保持对话的连贯性和逻辑性。
补充点内容
通过本文介绍的步骤,你已经能够利用 Spring AI、Spring AI Alibaba、DeepSeek、RAG 等技术,结合阿里云百炼平台的强大能力,搭建出一个支持连续对话的 AI 应用。这种技术组合的优势在于能够高效地处理对话中的信息检索与生成任务,从而提升对话系统的性能和用户体验。
在实际应用中,这种技术架构可以为企业知识库、教育问答系统、智能客服等场景提供有力支持。例如,企业可以通过该系统快速构建内部知识问答平台,帮助员工快速获取所需信息;教育机构可以开发智能辅导系统,为学生提供个性化的学习指导;客服团队可以利用该技术提升响应效率,优化客户体验。
展望未来,随着 AI 技术的不断进步,我们有更多机会对当前系统进行优化。例如,可以进一步优化 DeepSeek 模型的训练数据,使其更贴合特定领域的知识和语义;可以探索更多 RAG 的应用场景,如多模态信息检索,结合图像、语音等多类型数据提升检索效果;还可以加强系统的安全性和隐私保护,确保用户数据的安全存储和合规使用。
最后,还是希望本文能让你在 AI 应用开发中快速上手并探索更多可能性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 67
67 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)