
飞桨框架paddlepaddle3.0部署DeepSeek-R1-Distill系列模型实践(动态图部署)
飞桨框架paddlepaddle3.0部署DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek-R1-Distill-Llama-8B/70b,非docker方法。作为新手第一次接触,受益匪浅。感谢Gemini、Deepseek等GPT老师,感谢飞桨官方。
目录
1.1、单卡A800 80G,控制变量飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek-R1-Distill-Llama-8B
1.2.1、单卡RTX4090 24G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B;
1.2.2、单卡A100 40G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-14B/32B
2.1、双卡A100 40G、双卡A800 80G,飞桨框架3.0推理DepSeek-R1-Distill-Qwen-32B
2.2、双卡/四卡A800 80G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B
3.1、Macmini m4 16G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-1.5B/7B
3.2、ollama推理deepseek-r1:7b-qwen-distill-q8_0对比
一、单卡推理情况
1.1、单卡A800 80G,控制变量飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek-R1-Distill-Llama-8B
示例截图:
| 指标 | DeepSeek-R1-Distill-Qwen-32B (2025-03-26 23:17:02) | DeepSeek-R1-Distill-Qwen-14B (2025-03-26 23:30:43) | DeepSeek-R1-Distill-Qwen-7B (2025-03-26 23:38:54) | DeepSeek-R1-Distill-Qwen-1.5B (2025-03-26 23:41:52) | DeepSeek-R1-Distill-Llama-8B (2025-03-26 23:48:55) |
|---|---|---|---|---|---|
| 输入文本长度 | 18 tokens | 18 tokens | 18 tokens | 18 tokens | 18 tokens |
| 输入文本 | 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。 | 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。 | 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。 | 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。 | 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。 |
输出文本长度 (含 <think>) | ~250 字符 | ~500 字符 | ~800 字符 | ~1500 字符 | ~650 字符 |
| 部分输出文本 | 中国首都是北京,位于华北平原的北部边缘,背靠燕山山脉,东邻渤海湾。北京历史悠久,是多个朝代的都城,拥有丰富的文化遗产,如故宫、长城等。</think>中国的首都是北京,这座城市不仅在中国的政治和经济中占据重要地位,而且在历史上也有着深远的影响。… | (关于中国首都的介绍) 嗯,用户问的是中国的首都是哪里,并且希望详细介绍这座城市的地理位置、历史和文化。首先,我得确认一下,中国的首都确实是北京,这一点没问题。 …</think>中国的首都是北京。 ### 地理位置 北京位于中国华北平原的北部,东经115°25′至117°25′ | 1. 首都的定义:首都通常是指一个国家的政治中心,拥有重要的行政、立法和司法权力。 … | 并用简明扼要的中文描述一下中国的主要地理特征。
| 包括主要景点、经济活动以及政府机构等。
|
| 耗时 | 36.23s | 35.63s | 21.65s | 16.91s | 23.18s |
| GPU 显存占用 | [73073] | [36785] | [20021] | [8137] | [21039] |
| token/s (含 | 6.90 | 14.03 | 39.26 | 88.70 | 18.25 |
| PaddlePaddle 版本 | 3.0.0-rc1 | 3.0.0-rc1 | 3.0.0-rc1 | 3.0.0-rc1 | 3.0.0-rc1 |
| PaddlePaddle 编译选项 - CUDA 支持 | True | True | True | True | True |
| PaddlePaddle 运行时配置 - CPU 绑核 | gpu:0 | gpu:0 | gpu:0 | gpu:0 | gpu:0 |
| 优化器信息 - 类型 | Adam | Adam | Adam | Adam | Adam |
| 优化器信息 - 学习率 | 1e-05 | 1e-05 | 1e-05 | 1e-05 | 1e-05 |
| 总 API 调用次数 | 511659 | 431506 | 253446 | 253446 | 327141 |
matmul 调用次数 | 44634 | 38800 | 22800 | 22800 | 26000 |
matmul 总耗时 | 1.522s | 1.237s | 0.834s | 0.772s | 0.815s |
concat 调用次数 | 89139 | 77503 | 45543 | 45543 | 51935 |
concat 总耗时 | 1.465s | 1.267s | 0.747s | 0.704s | 0.845s |
transpose 调用次数 | 66432 | 57600 | 33600 | 33600 | 38400 |
transpose 总耗时 | 0.248s | 0.211s | 0.124s | 0.120s | 0.144s |
in_dygraph_mode 调用次数 | 244276 | 212000 | 124000 | 124000 | 167200 |
| PaddlePaddle 内存分配 | 74117707520 | 35982534912 | 18989340928 | 7312283904 | 20355502336 |
环境(软件环境同下所有,mac平台除外):
A800-PCIE-80GB *1_linux_gpu
miniconda--ubuntu24.04--python3.12
(FunHPC | 算力简单易用 AI乐趣丛生 租用硬件)
代码示例(1.5B)(同下,mac平台除外,只更改模型名称运行,其他不变):
# rtx4090/a100/a800
pip install --upgrade paddlenlp==3.0.0b4
python -m pip install paddlepaddle-gpu==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/ #1.5b.py
import os
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
cache_dir = '/data/coding/paddlenlp_models'
os.makedirs(cache_dir, exist_ok=True) #确保目录存在
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", cache_dir=cache_dir)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", cache_dir=cache_dir)#1.5b1.py
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
import logging
import time
import os
import psutil
import subprocess
import inspect
import json # 导入 json 模块,用于结构化日志
import argparse # 导入 argparse 模块
# 定义日志保存路径
log_dir = "/data/coding/"
# 确保日志目录存在,如果不存在则创建
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 配置 server.log (生产环境优化)
server_logger = logging.getLogger('server')
server_logger.setLevel(logging.INFO) # 生产环境通常使用 INFO 级别
server_formatter = logging.Formatter(
json.dumps({ # 使用 JSON 格式化
'time': '%(asctime)s',
'level': '%(levelname)s',
'message': '%(message)s',
'module': '%(module)s', # 添加模块名
'line': '%(lineno)d' # 添加行号
})
)
server_file_handler = logging.FileHandler(os.path.join(log_dir, 'server.log'))
server_file_handler.setFormatter(server_formatter)
server_logger.addHandler(server_file_handler)
# 配置 infer.log
infer_logger = logging.getLogger('infer')
infer_logger.setLevel(logging.INFO)
infer_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
infer_file_handler_infer = logging.FileHandler(os.path.join(log_dir, 'infer.log'))
infer_file_handler_infer.setFormatter(infer_formatter)
infer_logger.addHandler(infer_file_handler_infer)
# 配置 paddle.log
paddle_logger = logging.getLogger('paddle')
paddle_logger.setLevel(logging.INFO)
paddle_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
paddle_file_handler_paddle = logging.FileHandler(os.path.join(log_dir, 'paddle.log'))
paddle_file_handler_paddle.setFormatter(paddle_formatter)
paddle_logger.addHandler(paddle_file_handler_paddle)
def flatten(lst):
"""展平嵌套列表"""
result = []
for i in lst:
if isinstance(i, list):
result.extend(flatten(i))
else:
result.append(i)
return result
def get_gpu_memory():
"""获取 GPU 显存占用"""
try:
result = subprocess.check_output(
["nvidia-smi", "--query-gpu=memory.used", "--format=csv,noheader"], encoding='utf-8')
gpu_memory = [int(x.strip().split()[0]) for x in result.strip().split('\n')]
return gpu_memory
except Exception as e:
return f"获取 GPU 显存占用失败: {e}"
def get_cpu_memory():
"""获取 CPU 内存占用"""
memory_usage = psutil.virtual_memory().percent
return memory_usage
def get_paddle_build_info():
"""获取 PaddlePaddle 的编译选项"""
build_info = {}
# 尝试获取 CUDA 支持
try:
build_info['CUDA 支持'] = paddle.is_compiled_with_cuda()
except AttributeError:
build_info['CUDA 支持'] = "未知"
return build_info
def get_paddle_run_config():
"""获取 PaddlePaddle 的运行时配置"""
run_config = {}
# 尝试获取线程数
try:
run_config['线程数'] = paddle.device.get_device().split(":")[1] # 获取当前设备,并从中提取线程数
except AttributeError:
run_config['线程数'] = "未知"
# 尝试获取 CPU 绑核
try:
run_config['CPU 绑核'] = paddle.get_device()
except AttributeError:
run_config['CPU 绑核'] = "未知"
return run_config
def get_optimizer_info(optimizer):
"""
获取优化器信息。
Args:
optimizer: PaddlePaddle 优化器实例。
Returns:
包含优化器信息的字典,如果无法获取,则返回None。
"""
if optimizer is None:
return None
optimizer_info = {}
optimizer_info['类型'] = type(optimizer).__name__
# 获取优化器参数,需要处理不同的优化器类型
if hasattr(optimizer, '_learning_rate'):
optimizer_info['学习率'] = optimizer._learning_rate
if hasattr(optimizer, '_beta1'):
optimizer_info['beta1'] = optimizer._beta1
if hasattr(optimizer, '_beta2'):
optimizer_info['beta2'] = optimizer._beta2
if hasattr(optimizer, '_epsilon'):
optimizer_info['epsilon'] = optimizer._epsilon
if hasattr(optimizer, 'weight_decay'):
optimizer_info['权重衰减'] = optimizer.weight_decay
return optimizer_info
def main():
# 使用 argparse 获取命令行参数
parser = argparse.ArgumentParser(description="Run inference with optional profiling.")
parser.add_argument("--disable_profile", action="store_true", help="Disable profiling.")
args = parser.parse_args()
enable_profiler = not args.disable_profile # 默认启用,除非指定 --disable_profile
# 记录服务器启动信息到 server.log (JSON 格式)
server_logger.info(json.dumps({'message': 'Server started', 'port': 8080})) # 添加更多上下文
try:
# 记录 PaddlePaddle 版本
paddle_logger.info(f"PaddlePaddle 版本: {paddle.__version__}")
# 记录 PaddlePaddle 编译选项
build_info = get_paddle_build_info()
paddle_logger.info(f"PaddlePaddle 编译选项: {build_info}")
# 记录 PaddlePaddle 运行时配置
run_config = get_paddle_run_config()
paddle_logger.info(f"PaddlePaddle 运行时配置: {run_config}")
# 加载模型
cache_dir = '/data/coding/paddlenlp_models'
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
cache_dir=cache_dir,
)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
cache_dir=cache_dir,
dtype="float16", # 使用 float16 优化显存
)
optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.parameters()) # 创建优化器
# 记录优化器信息
optimizer_info = get_optimizer_info(optimizer)
if optimizer_info:
paddle_logger.info(f"优化器信息: {optimizer_info}")
else:
paddle_logger.info("未使用优化器。")
# 输入提示
input_text = "中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。"
inputs = tokenizer(input_text, return_tensors="pd")
# 记录推理开始时间
start_time = time.time()
api_call_count = {}
api_call_time = {}
profiler_path = os.path.join(log_dir, "profiler_report.json")
# 启用 Profiler (根据命令行参数)
if enable_profiler:
with paddle.profiler.Profiler(targets=["cpu", "gpu"]) as prof:
# 猴子补丁,统计 API 调用次数和时间
def record_api_call(func):
def wrapper(*args, **kwargs):
func_name = func.__qualname__
api_call_count[func_name] = api_call_count.get(func_name, 0) + 1
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
duration = end_time - start_time
api_call_time[func_name] = api_call_time.get(func_name, 0) + duration
return result
return wrapper
# 应用猴子补丁
for name, obj in inspect.getmembers(paddle):
if inspect.isfunction(obj):
setattr(paddle, name, record_api_call(obj))
# 生成参数
with paddle.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=400,
decode_strategy="sampling",
temperature=0.2,
top_k=20,
top_p=0.9,
repetition_penalty=1.1,
)
# 导出 Profiler 结果
prof.export(profiler_path) # 使用定义的路径
#记录性能数据
paddle_logger.info(f"API 调用次数: {api_call_count}")
paddle_logger.info(f"API 调用耗时: {api_call_time}")
else:
with paddle.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=200,
decode_strategy="sampling",
temperature=0.2,
top_k=20,
top_p=0.9,
repetition_penalty=1.1,
)
# 记录推理结束时间
end_time = time.time()
# 计算推理时间
inference_time = end_time - start_time
# 类型转换与解码
ids = [int(i) for i in flatten(outputs[0].numpy().tolist())]
result = tokenizer.decode(ids, skip_special_tokens=True)
# 计算 token/s
input_tokens = len(inputs["input_ids"][0])
output_tokens = len(ids)
total_tokens = input_tokens + output_tokens
tokens_per_second = total_tokens / inference_time
# 获取 GPU 显存占用
gpu_memory = get_gpu_memory()
# 获取 CPU 内存占用
cpu_memory = get_cpu_memory()
# 记录推理结果到 infer.log
infer_logger.info(f"输入文本长度: {input_tokens} tokens")
infer_logger.info(f"输入: {input_text}")
infer_logger.info(f"输出: {result}")
infer_logger.info(f"耗时: {inference_time:.2f}s")
infer_logger.info(f"GPU 显存占用: {gpu_memory}")
infer_logger.info(f"CPU 内存占用: {cpu_memory}%")
infer_logger.info(f"token/s: {tokens_per_second:.2f}")
# 记录 PaddlePaddle 内存分配情况
paddle_logger.info(f"PaddlePaddle 内存分配: {paddle.device.cuda.memory_allocated()}")
except Exception as e:
# 记录错误信息到 infer.log (包含堆栈跟踪)
infer_logger.exception(f"Error during inference: {str(e)}")
server_logger.error(json.dumps({'message': 'Inference error', 'error': str(e)}), exc_info=True) # 使用 JSON 格式,记录堆栈
finally:
# 记录服务器关闭信息到 server.log (JSON 格式)
server_logger.info(json.dumps({'message': 'Server finished', 'exit_code': 0})) # 添加更多上下文
if __name__ == "__main__":
main()
1.2、其他单卡推理
1.2.1、单卡RTX4090 24G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B;
中间跑了一趟deepseek-ai/DeepSeek-R1-Distill-Qwen-14B,显存不足,在log里了。
2025-03-26 12:35:55,906 - INFO - 输入文本长度: 18 tokens
2025-03-26 12:35:55,907 - INFO - 输入: 中国的首都是哪座城市?请详细介绍该城市的地理位置、历史和文化。
2025-03-26 12:35:55,907 - INFO - 输出: 1. **首都的定义**:首都通常是指一个国家的政治中心,拥有重要的行政、立法和司法权力。
2. **中国首都**:中国的首都是北京市。
3. **地理位置**:
- 北京市位于中国大陆的北方地区。
- 地处华北平原北部边缘,东边有北京城,西边与天津相接。
- 地理位置优越,交通便利,是东西向交通要道的重要枢纽。
4. **历史背景**:
- 北京自古以来就是重要的政治、军事和文化中心。
- 曾是汉朝的都城,汉武帝时期被称为“九河之都”。
- 秦朝建立后,秦始皇在此修建长城,统一六国,巩固了北京作为政治中心的地位。
- 晋代以后,北京逐渐被北方的少数民族政权所占据,但元朝时期仍由汉族统治。
- 明清两朝,北京成为皇帝的居所,并在此建立了许多重要机构和文化设施。
- 随着历史变迁,北京在不同朝代的角色有所变化,但仍保持其重要性。
5. **文化特色**:
- **历史遗迹**:北京拥有众多的历史古迹,如故宫、天坛、颐和园等。
- 故宫是中国古代宫殿建筑的代表,始建于1406年,明成祖朱棣始建,清高宗乾隆年间完成。
- 天坛是明朝 Great Wall of China 的一部分,始建于1420年,是皇家祭天的场所。
- 颐和园是中国四大名园之一,始建于1759年,以水乡园林著称。
- **传统节日**:中秋节是中国的传统节日,每年农历八月十五举行,北京作为首都,中秋节的庆祝活动非常热闹。
-
2025-03-26 12:35:55,907 - INFO - 耗时: 19.54s
2025-03-26 12:35:55,907 - INFO - GPU 显存占用: [19975]
2025-03-26 12:35:55,907 - INFO - CPU 内存占用: 5.9%
2025-03-26 12:35:55,907 - INFO - token/s: 21.39
2025-03-26 12:59:46,772 - ERROR - Error during inference: Can't load the model for 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B'. If you were trying to load it from 'BOS', make sure you don't have a local directory with the same name. Otherwise, make sure 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B' is the correct path to a directory containing one of the ['model-00002-of-000004.safetensors']
Traceback (most recent call last):
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/utils/download/__init__.py", line 251, in resolve_file_path
cached_file = bos_download(
^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/utils/download/bos_download.py", line 241, in bos_download
http_get(
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/utils/download/common.py", line 181, in http_get
temp_file.write(chunk)
File "/data/miniconda/envs/default/lib/python3.12/tempfile.py", line 499, in func_wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
OSError: [Errno 28] No space left on device
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/data/coding/51.py", line 159, in main
model = AutoModelForCausalLM.from_pretrained(model_name, dtype="float16") # 使用 float16 优化显存
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/auto/modeling.py", line 798, in from_pretrained
return cls._from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/auto/modeling.py", line 346, in _from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/model_utils.py", line 2462, in from_pretrained
resolved_archive_file, resolved_sharded_files, sharded_metadata, is_sharded = cls._resolve_model_file_path(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/model_utils.py", line 1890, in _resolve_model_file_path
resolved_sharded_files, sharded_metadata = get_checkpoint_shard_files(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/utils.py", line 702, in get_checkpoint_shard_files
cached_filename = resolve_file_path(
^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/utils/download/__init__.py", line 286, in resolve_file_path
raise EnvironmentError(
OSError: Can't load the model for 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B'. If you were trying to load it from 'BOS', make sure you don't have a local directory with the same name. Otherwise, make sure 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B' is the correct path to a directory containing one of the ['model-00002-of-000004.safetensors']
2025-03-26 13:37:18,938 - ERROR - Error during inference:
--------------------------------------
C++ Traceback (most recent call last):
--------------------------------------
0 paddle::pybind::eager_api_uniform(_object*, _object*, _object*)
1 uniform_ad_func(paddle::experimental::IntArrayBase<paddle::Tensor>, phi::DataType, paddle::experimental::ScalarBase<paddle::Tensor>, paddle::experimental::ScalarBase<paddle::Tensor>, int, phi::Place)
2 paddle::experimental::uniform(paddle::experimental::IntArrayBase<paddle::Tensor> const&, phi::DataType, paddle::experimental::ScalarBase<paddle::Tensor> const&, paddle::experimental::ScalarBase<paddle::Tensor> const&, int, phi::Place const&)
3 void phi::UniformKernel<phi::dtype::float16, phi::GPUContext>(phi::GPUContext const&, paddle::experimental::IntArrayBase<phi::DenseTensor> const&, phi::DataType, paddle::experimental::ScalarBase<phi::DenseTensor> const&, paddle::experimental::ScalarBase<phi::DenseTensor> const&, int, phi::DenseTensor*)
4 phi::dtype::float16* phi::DeviceContext::Alloc<phi::dtype::float16>(phi::TensorBase*, unsigned long, bool) const
5 phi::DenseTensor::AllocateFrom(phi::Allocator*, phi::DataType, unsigned long, bool)
6 paddle::memory::allocation::Allocator::Allocate(unsigned long)
7 paddle::memory::allocation::StatAllocator::AllocateImpl(unsigned long)
8 paddle::memory::allocation::Allocator::Allocate(unsigned long)
9 paddle::memory::allocation::Allocator::Allocate(unsigned long)
10 std::string phi::enforce::GetCompleteTraceBackString<std::string >(std::string&&, char const*, int)
11 common::enforce::GetCurrentTraceBackString[abi:cxx11](bool)
----------------------
Error Message Summary:
----------------------
ResourceExhaustedError:
Out of memory error on GPU 0. Cannot allocate 135.000000MB memory on GPU 0, 23.565063GB memory has been allocated and available memory is only 79.687500MB.
Please check whether there is any other process using GPU 0.
1. If yes, please stop them, or start PaddlePaddle on another GPU.
2. If no, please decrease the batch size of your model.
(at ../paddle/phi/core/memory/allocation/cuda_allocator.cc:71)
Traceback (most recent call last):
File "/data/coding/51.py", line 166, in main
model = AutoModelForCausalLM.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/auto/modeling.py", line 798, in from_pretrained
return cls._from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/auto/modeling.py", line 346, in _from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/model_utils.py", line 2546, in from_pretrained
model = cls(config, *init_args, **model_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/utils.py", line 289, in __impl__
init_func(self, *args, **kwargs)
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/qwen2/modeling.py", line 1475, in __init__
self.qwen2 = Qwen2Model(config)
^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/utils.py", line 289, in __impl__
init_func(self, *args, **kwargs)
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/qwen2/modeling.py", line 1150, in __init__
Qwen2DecoderLayer(
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/qwen2/modeling.py", line 758, in __init__
self.mlp = Qwen2MLP(config, skip_recompute_ops=skip_recompute_ops)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddlenlp/transformers/qwen2/modeling.py", line 453, in __init__
self.up_proj = Linear(self.hidden_size, self.intermediate_size, bias_attr=False) # w3
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/nn/layer/common.py", line 208, in __init__
self.weight = self.create_parameter(
^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/nn/layer/layers.py", line 811, in create_parameter
return self._helper.create_parameter(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/base/layer_helper_base.py", line 443, in create_parameter
return self.main_program.global_block().create_parameter(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/base/framework.py", line 4617, in create_parameter
initializer(param, self)
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/nn/initializer/initializer.py", line 69, in __call__
return self.forward(param, block)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/miniconda/envs/default/lib/python3.12/site-packages/paddle/nn/initializer/xavier.py", line 154, in forward
out_var = _C_ops.uniform(
^^^^^^^^^^^^^^^
MemoryError:
--------------------------------------
C++ Traceback (most recent call last):
--------------------------------------
0 paddle::pybind::eager_api_uniform(_object*, _object*, _object*)
1 uniform_ad_func(paddle::experimental::IntArrayBase<paddle::Tensor>, phi::DataType, paddle::experimental::ScalarBase<paddle::Tensor>, paddle::experimental::ScalarBase<paddle::Tensor>, int, phi::Place)
2 paddle::experimental::uniform(paddle::experimental::IntArrayBase<paddle::Tensor> const&, phi::DataType, paddle::experimental::ScalarBase<paddle::Tensor> const&, paddle::experimental::ScalarBase<paddle::Tensor> const&, int, phi::Place const&)
3 void phi::UniformKernel<phi::dtype::float16, phi::GPUContext>(phi::GPUContext const&, paddle::experimental::IntArrayBase<phi::DenseTensor> const&, phi::DataType, paddle::experimental::ScalarBase<phi::DenseTensor> const&, paddle::experimental::ScalarBase<phi::DenseTensor> const&, int, phi::DenseTensor*)
4 phi::dtype::float16* phi::DeviceContext::Alloc<phi::dtype::float16>(phi::TensorBase*, unsigned long, bool) const
5 phi::DenseTensor::AllocateFrom(phi::Allocator*, phi::DataType, unsigned long, bool)
6 paddle::memory::allocation::Allocator::Allocate(unsigned long)
7 paddle::memory::allocation::StatAllocator::AllocateImpl(unsigned long)
8 paddle::memory::allocation::Allocator::Allocate(unsigned long)
9 paddle::memory::allocation::Allocator::Allocate(unsigned long)
10 std::string phi::enforce::GetCompleteTraceBackString<std::string >(std::string&&, char const*, int)
11 common::enforce::GetCurrentTraceBackString[abi:cxx11](bool)
----------------------
Error Message Summary:
----------------------
ResourceExhaustedError:
Out of memory error on GPU 0. Cannot allocate 135.000000MB memory on GPU 0, 23.565063GB memory has been allocated and available memory is only 79.687500MB.
Please check whether there is any other process using GPU 0.
1. If yes, please stop them, or start PaddlePaddle on another GPU.
2. If no, please decrease the batch size of your model.
(at ../paddle/phi/core/memory/allocation/cuda_allocator.cc:71)
1.2.2、单卡A100 40G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-14B/32B
14B可运行,32B显存不足报错,理由同上。
二、多卡推理情况
2.1、双卡A100 40G、双卡A800 80G,飞桨框架3.0推理DepSeek-R1-Distill-Qwen-32B
双卡A100 40G显存不足报错,A800-PCIE-80GB *2可以运行,但当时运行至32b1.py了,显示两个显存占用,输出token速度比单卡A800 80G的10.05token/s要慢。(未计算think)应该是只有一张卡再跑,没有并行,因为32b2.py代码没有作用。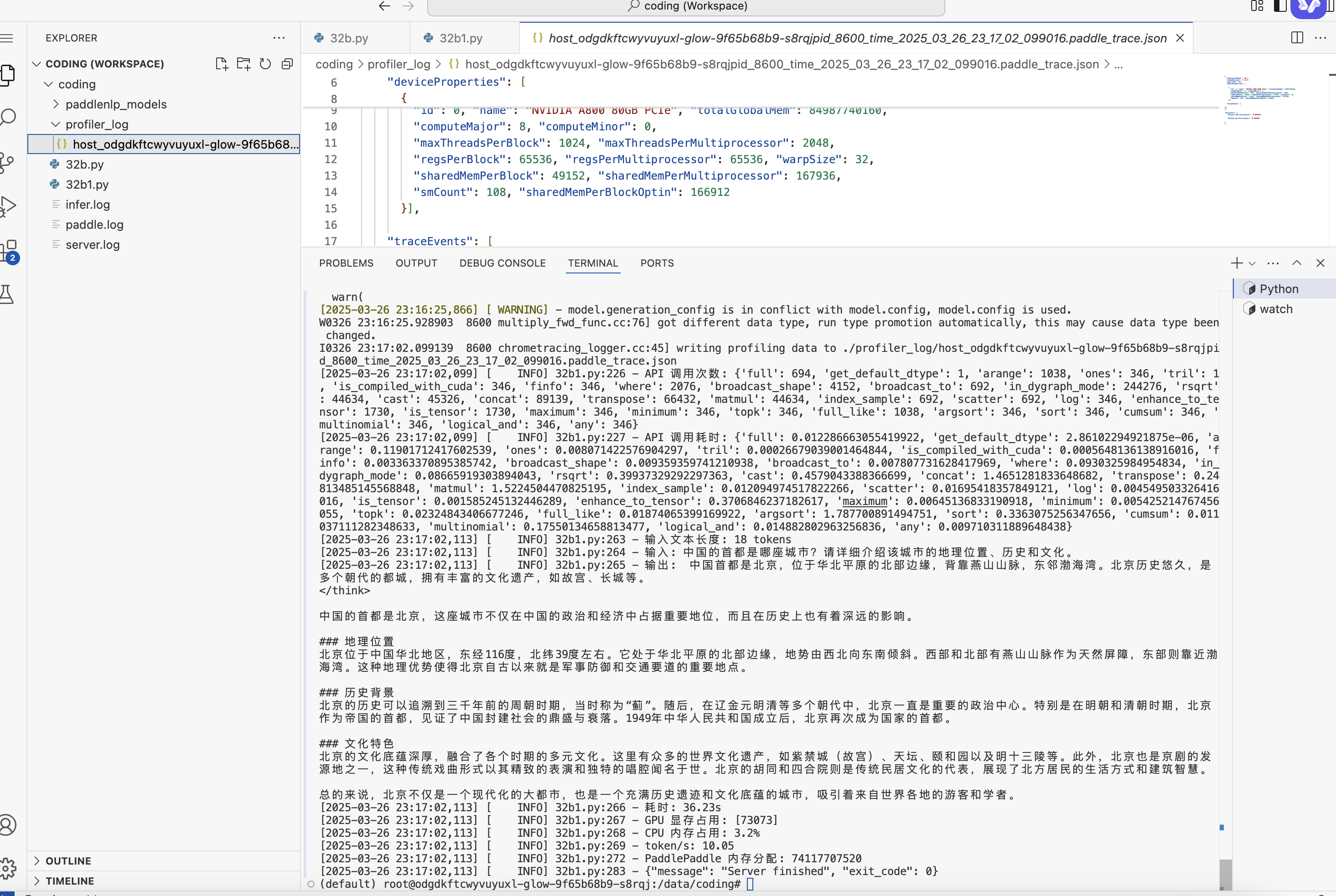
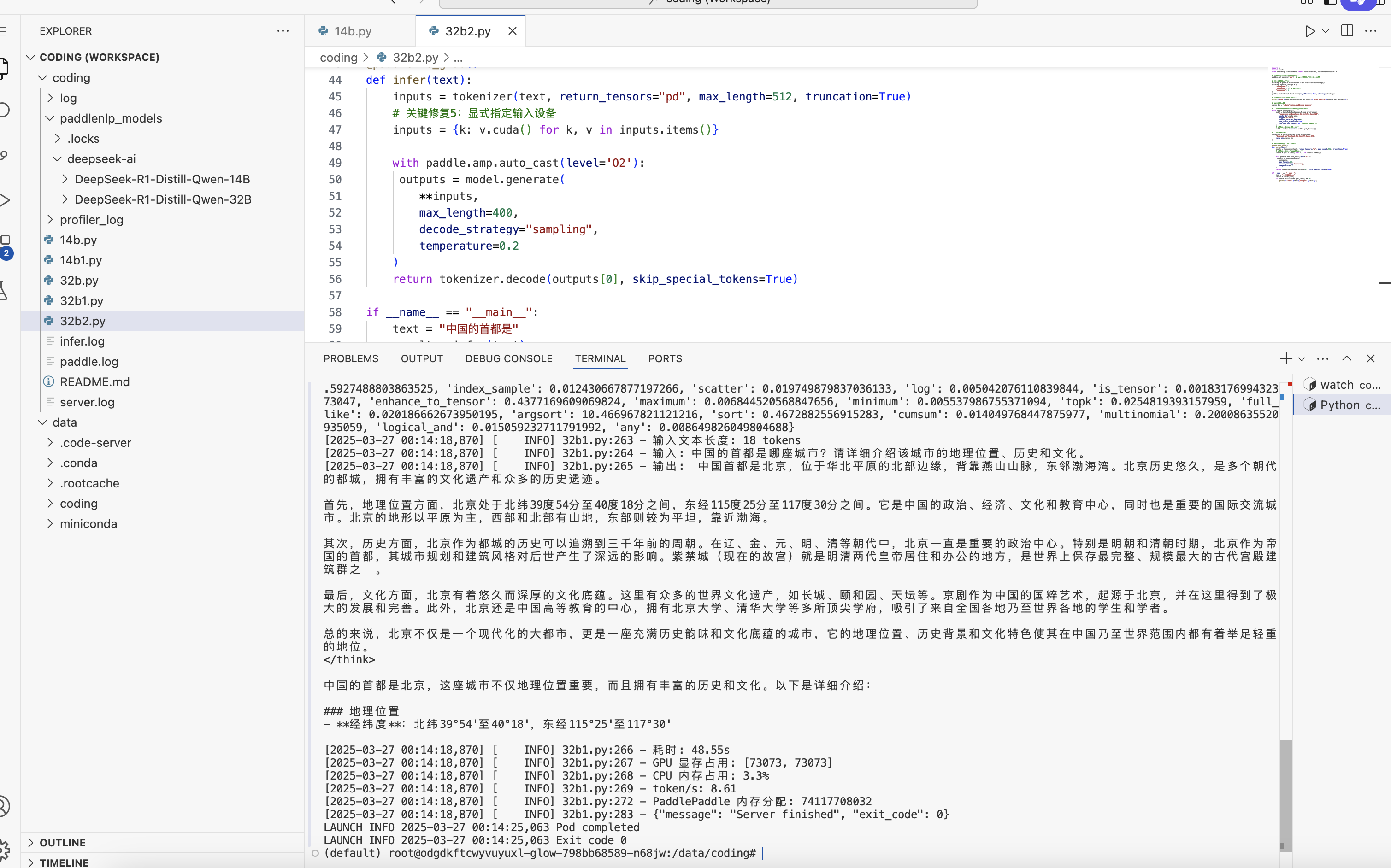
###实际并未运行,参考下面的分布推理
import os
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
# 关键修复1:显式设置默认设备
paddle.set_device('gpu') # 必须在分布式初始化前设置
# 初始化分布式环境
strategy = paddle.distributed.fleet.DistributedStrategy()
strategy.hybrid_configs = {
"dp_degree": 1,
"mp_degree": 2, # 模型并行
"pp_degree": 1
}
paddle.distributed.fleet.init(is_collective=True, strategy=strategy)
# 关键修复2:验证设备可见性
print(f"Rank {paddle.distributed.get_rank()} using device: {paddle.get_device()}")
# 指定缓存路径
cache_dir = '/data/coding/paddlenlp_models'
# 加载模型(关键修复3:调整初始化顺序)
with paddle.LazyGuard():
model = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
cache_dir=cache_dir,
dtype="bfloat16",
tensor_parallel_degree=2,
use_flash_attention=True,
low_cpu_mem_usage=True # 减少CPU内存占用
)
# 关键修复4:提前分配设备
model = model.to(device=paddle.get_device())
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
cache_dir=cache_dir
)
# 推理函数(添加设备同步)
@paddle.no_grad()
def infer(text):
inputs = tokenizer(text, return_tensors="pd", max_length=512, truncation=True)
# 关键修复5:显式指定输入设备
inputs = {k: v.cuda() for k, v in inputs.items()}
with paddle.amp.auto_cast(level='O2'):
outputs = model.generate(
**inputs,
max_length=400,
decode_strategy="sampling",
temperature=0.2
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
if __name__ == "__main__":
text = "中国的首都是"
result = infer(text)
if paddle.distributed.get_rank() == 0:
print(f"Input: {text}\nOutput: {result}")rm -rf ./log && python -m paddle.distributed.launch \
--gpus 0,1 \
--log_dir ./log \
your_script.py参考:paddnlp里的文本摘要算法分布式训练
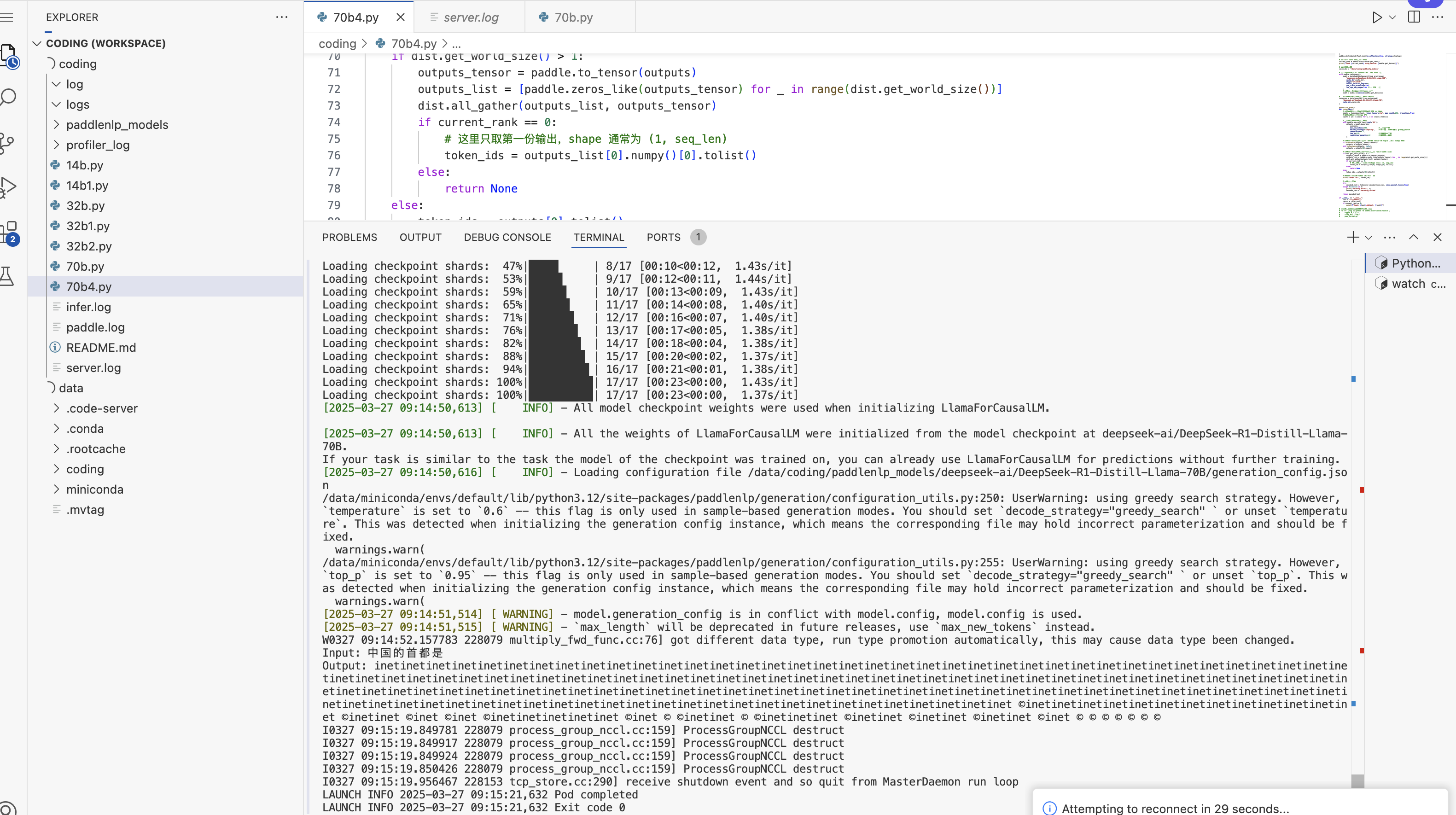
2.2、四卡A800 80G,飞桨框架3.0推理DeepSeek-R1-Distill-Llama-70B
代码可以运行,但输出乱码。
GPT优化了很多遍,云服务却突然到期了,卡也被租走,没卡不能跑了= 。=

import os
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
import paddle.distributed as dist
import numpy as np
# 关键修复1:在分布式初始化前显式设置设备为 GPU
paddle.set_device('gpu')
# 初始化分布式环境
strategy = paddle.distributed.fleet.DistributedStrategy()
strategy.hybrid_configs = {
"dp_degree": 1,
"mp_degree": 4, # 模型并行
"pp_degree": 1
}
paddle.distributed.fleet.init(is_collective=True, strategy=strategy)
# 输出当前 rank 信息和设备状态
current_rank = paddle.distributed.get_rank()
print(f"Rank {current_rank} using device: {paddle.get_device()}")
# 指定缓存路径
cache_dir = '/data/coding/paddlenlp_models'
# 在 LazyGuard() 内加载模型,降低 CPU 内存占用
with paddle.LazyGuard():
model = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
cache_dir=cache_dir,
dtype="bfloat16",
tensor_parallel_degree=4,
use_flash_attention=True,
low_cpu_mem_usage=True # 低 CPU 占用
)
# 关键修复2:将模型移动到当前设备
model = model.to(device=paddle.get_device())
# 加载 tokenizer,以确保和模型参数匹配
tokenizer = AutoTokenizer.from_pretrained(
"deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
cache_dir=cache_dir
)
@paddle.no_grad()
def infer(text):
# 对输入文本进行编码,并截断至 256 个 token
inputs = tokenizer(text, return_tensors="pd", max_length=256, truncation=True)
# 将输入数据显式移动到 GPU
inputs = {k: v.cuda() for k, v in inputs.items()}
# 使用自动混合精度进行推理
with paddle.amp.auto_cast(level='O2'):
outputs = model.generate(
**inputs,
max_new_tokens=200, # 使用新参数
decode_strategy="sampling", # 若倾向于采样,勿用 greedy_search
temperature=0.1,
top_p=0.95, # 采样控制参数
repetition_penalty=1.2 # 避免重复生成
)
# 关键修复3:确保输出类型一致,将 tensor 或 tuple 转换为 numpy 数组
if isinstance(outputs, paddle.Tensor):
outputs = outputs.numpy()
elif isinstance(outputs, tuple):
outputs = outputs[0].numpy()
# 关键修复4:在分布式模式下,只使用 rank 0 的输出解码
if dist.get_world_size() > 1:
outputs_tensor = paddle.to_tensor(outputs)
outputs_list = [paddle.zeros_like(outputs_tensor) for _ in range(dist.get_world_size())]
dist.all_gather(outputs_list, outputs_tensor)
if current_rank == 0:
# 这里只取第一份输出,shape 通常为 (1, seq_len)
token_ids = outputs_list[0].numpy()[0].tolist()
else:
return None
else:
token_ids = outputs[0].tolist()
# 调试输出:打印 token ids 以便检查
print("Token IDs:", token_ids)
# 尝试进行解码
try:
decoded_text = tokenizer.decode(token_ids, skip_special_tokens=True)
except Exception as e:
print("Decoding error:", e)
decoded_text = "Decoding failed"
return decoded_text
if __name__ == "__main__":
text = "中国的首都是"
result = infer(text)
if current_rank == 0:
print(f"Input: {text}\nOutput: {result}")
# 示例运行命令(清理旧日志后运行):
# rm -rf ./log && python -m paddle.distributed.launch \
# --gpus 0,1,2,3 \
# --log_dir ./log \
# your_script.py
#???
#outputs = model.generate(
# **inputs,
# max_new_tokens=200,
# decode_strategy="greedy_search" # 改用贪婪搜索
#
三、macos arm平台推理
3.1、Macmini m4 16G,飞桨框架3.0推理DeepSeek-R1-Distill-Qwen-1.5B/7B
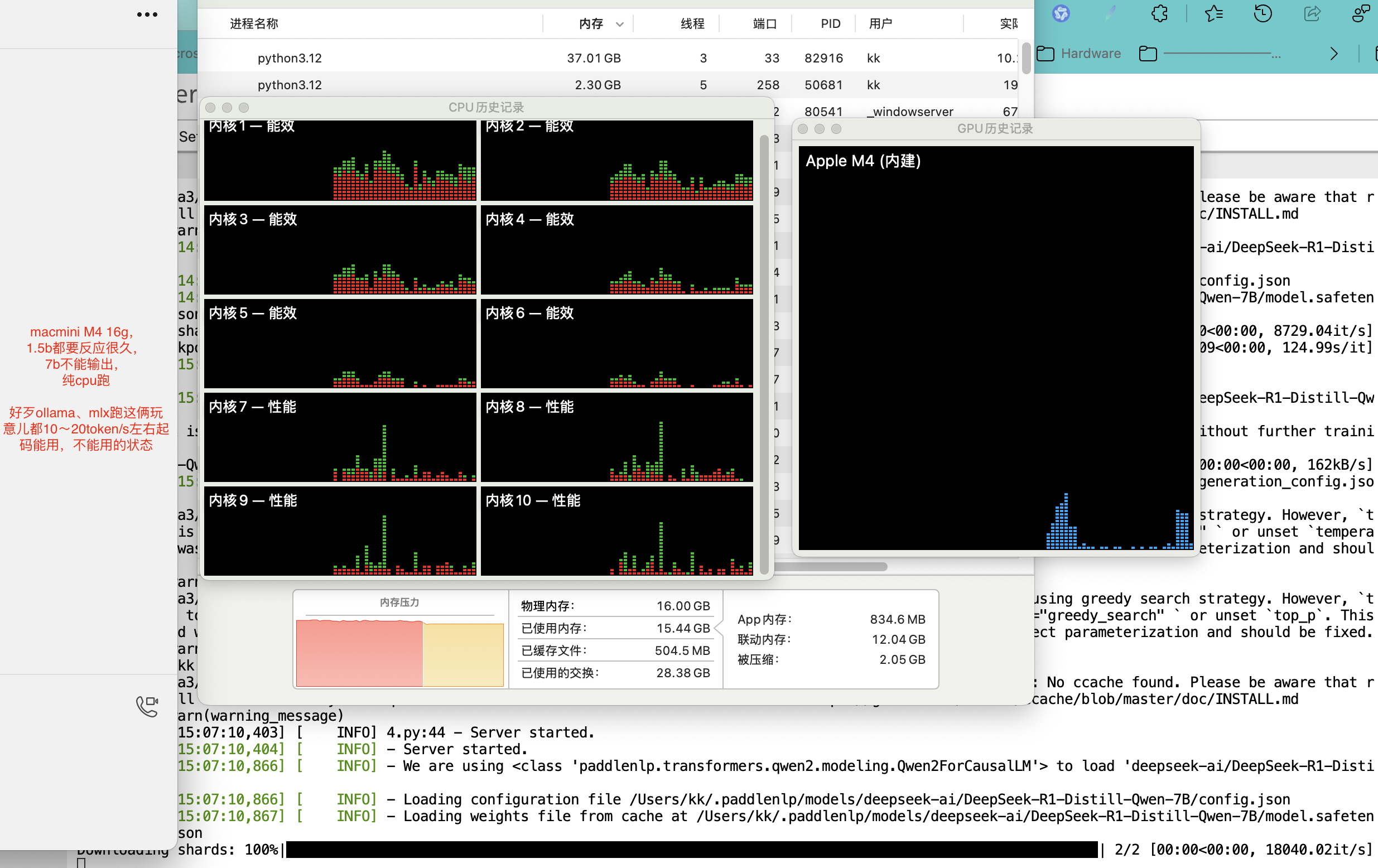
目前3.0版本只支持用cpu推理,期望可以适配GPU并且操作简化,就像ollama等。开始使用_飞桨-源于产业实践的开源深度学习平台;deepseek-r1:7b-qwen-distill-q8_0。
# cpu macos m4
pip install --upgrade paddlenlp==3.0.0b4
python -m pip install paddlepaddle==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/ 
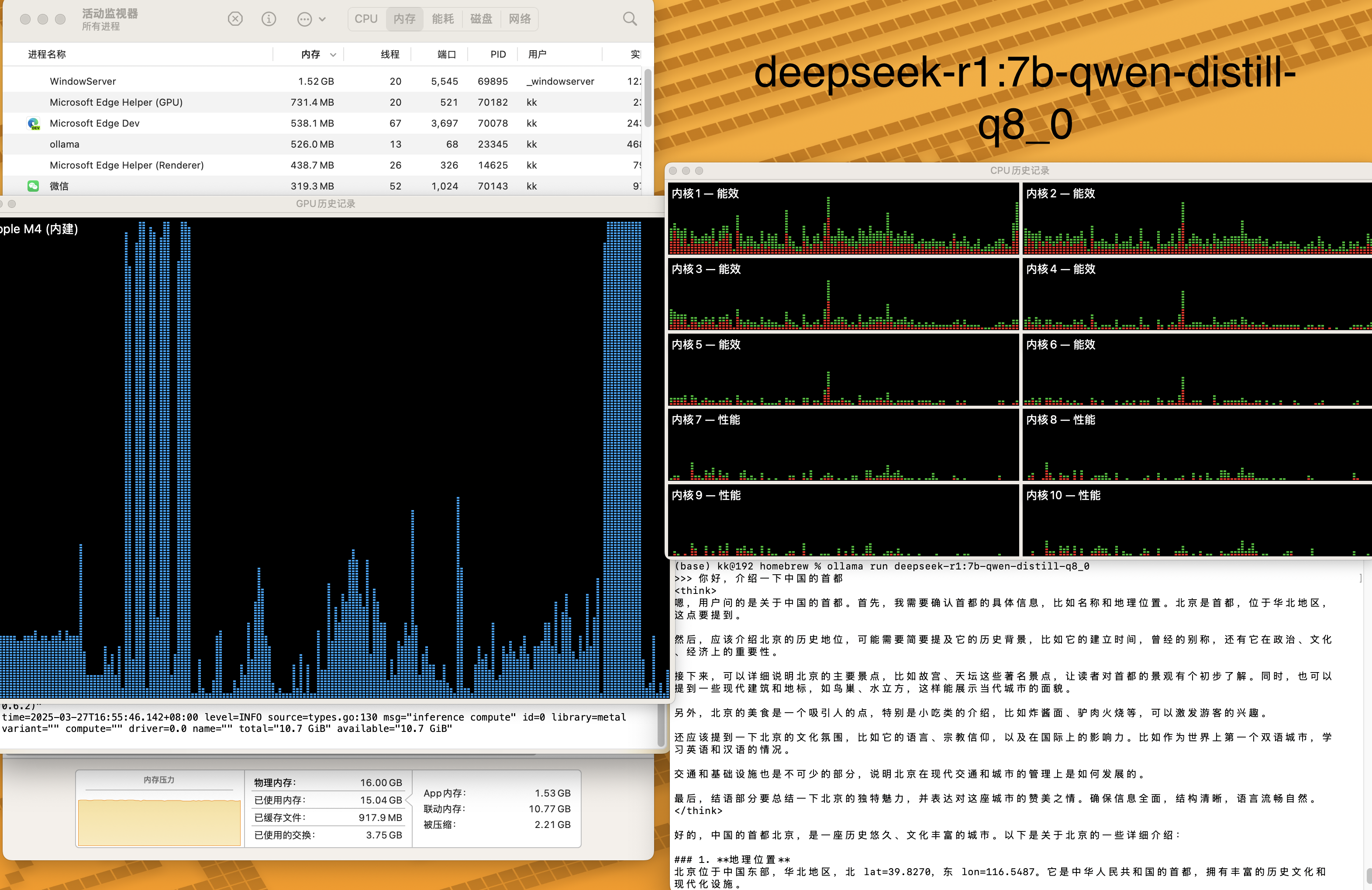
3.2、ollama推理deepseek-r1:7b-qwen-distill-q8_0对比
ollma 7b可以跑,但14b在没清空其他进程的情况下会卡住。
四、其他
作为新手第一次接触,受益匪浅。感谢Gemini、Deepseek等GPT老师,感谢飞桨官方。
参考书签url及整合包:
kk.zip官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘提取码:NcaS
新闻:
飞桨框架3.0推理升级:支持多款主流大模型、DeepSeek-R1满血版实现单机部署,吞吐提升一倍!
Github站:https://github.com/PaddlePaddle/PaddleNLP
飞桨平台(教程/文档/...):飞桨PaddlePaddle-源于产业实践的开源深度学习平台;
tips:
主流模型大部分都是bfloat16的类型, 依赖SM80以上的设备推理(20250327);
1、2、4、8卡--双机,3卡切不动片;
#一般指令
watch -n 1 nvidia-smi # 应看到两张卡均有显存占用
df -h #查看硬盘占用
#pip设置镜像源:
pip install --upgrade paddlenlp==3.0.0b4 -i https://pypi.tuna.tsinghua.edu.cn/simple
#参考: https://zhuanlan.zhihu.com/p/616174273

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)