DeepSeek正式发布了新一代模型 DeepSeek V3–0324
根据官方的提示,DeepSeek-V3-0324 在几个关键方面比其前身 DeepSeek-V3 有了显著的改进。:给出了在MMLU-Pro(百科知识)、GPQA(知识问答)、AIME 2024(数学竞赛)、LiveCodeBench(代码任务)和几大模型的比较。:新版 V3 在生成前端代码时,不仅功能更完善,提高了代码的可执行性,还注重代码的可读性和视觉美感。在数学和代码类评测中,表现超过了 G
2025年3月24日,Deepseek迎来了一次悄悄的更新,正式发布了新一版本的模型 DeepSeek V3–0324,并继续完整开放模型参数和权重。 这一版本在编程能力与复杂推理任务中表现尤为出色。目前在 Hugging Face 上,DeepSeek V3–0324排趋势榜首。
上热搜了
这次更新有哪些亮点呢?根据官方的提示,DeepSeek-V3-0324 在几个关键方面比其前身 DeepSeek-V3 有了显著的改进。核心优化包括,训练数据优化--清洗低质量数据,增加特定领域(如数学、代码)的高质量样本。微调策略改进--采用更高效的损失函数或蒸馏技术。推理效率提升--通过模型压缩(如量化)或计算优化,在相同参数下实现更快响应。
一 ,推理能力提升,基准测试性能的显著改进:给出了在MMLU-Pro(百科知识)、GPQA(知识问答)、AIME 2024(数学竞赛)、LiveCodeBench(代码任务)和几大模型的比较。在数学和代码类评测中,表现甚至超过了 GPT-4.5,成为非推理模型中的佼佼者。
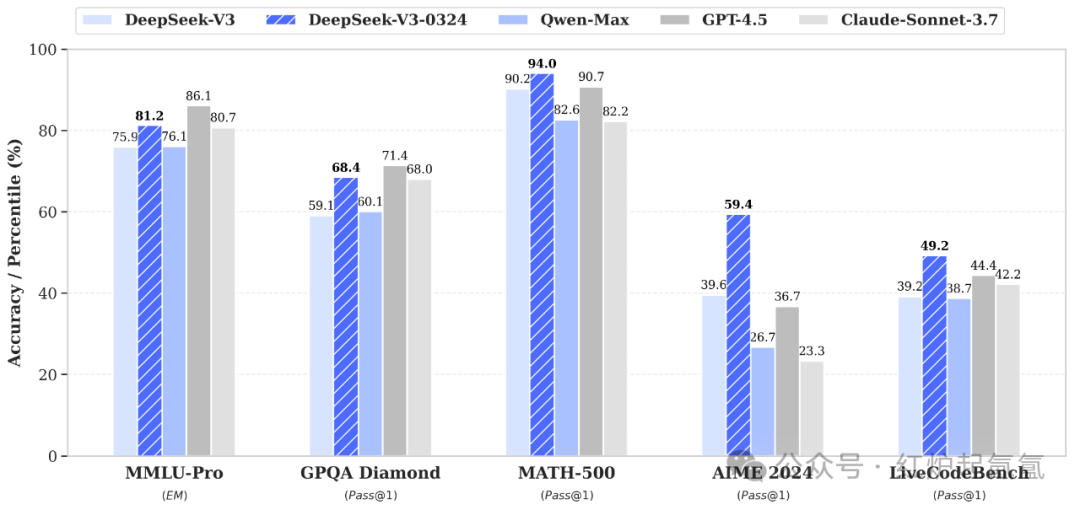
在数学和代码类评测中,表现超过了 GPT-4.5和C哪ude-Sonnet-.7,成为非推理模型中的佼佼者。
二 ,长文本处理及效率优化:128K上下文窗口下,关键信息提取速度提升30%。长文档问答时,减少重复或遗漏。新版 V3 生成速度提升至 60 TPS,同时保持高质量输出。例如:上传10万字符文本提取核心观点,回答速度比上个版本节约60%的时间。高并发API请求延迟降低20%,极端负载下崩溃率减少50%。
三 ,代码优化:新版 V3 在生成前端代码时,不仅功能更完善,提高了代码的可执行性,还注重代码的可读性和视觉美感。生成更美观的网页和游戏前端。支持更多编程语言(如Rust、Go)。生成的代码增加类型注解和异常处理。如:
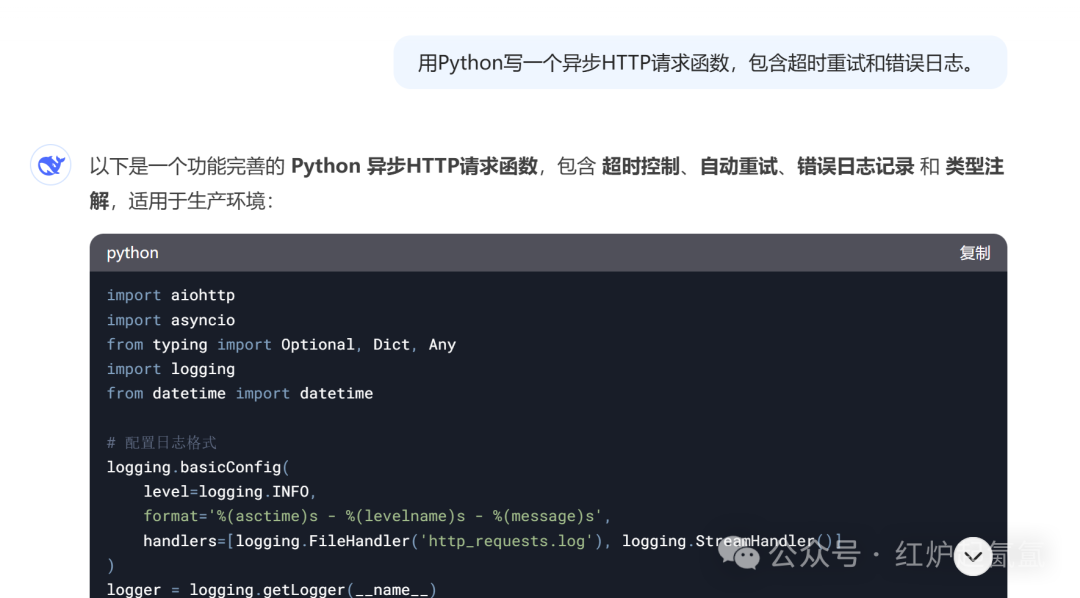
生成的代码可用于生产环境,挺自信的
四 ,中文写作能力提升:增强的样式和内容质量:与 R1 写作风格保持一致;更好的中长格式写作质量;改进的多轮交互式重写;优化翻译质量和信件写作。语言更生动,细节更丰富。例如:
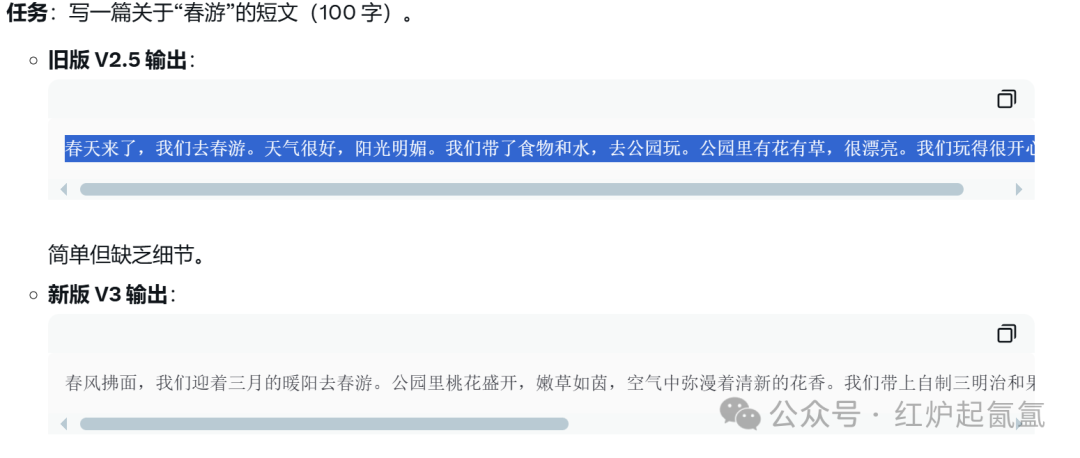
一目了然
在多语言,如中英文、日语等上做了优化。
五 ,开源协议更宽松,继续支持私有化部署。
例子: 旧版 V2.5:需要手动调整较多配置文件。 新版 V3:只需更新两个文件:
1. 下载 checkpoint 文件(deepseek-v3-0324.pth) 2. 更新 tokenizer_config.json(支持 128K 上下文) 3. 运行:python run_model.py --model deepseek-v3-0324
部署更简便,文档清晰。
此外 安全与合规性上也有优化:敏感内容(暴力、违法信息)拦截率提升至99.5%。用户隐私数据(如电话号码)自动脱敏。
许多科技博主认为 DeepSeek-V3-0324 的更新是一次成功的迭代,推理、前端开发、中文能力、速度和开源支持的全面提升让它在非推理模型中脱颖而出,甚至挑战了闭源模型的地位。
很多人推测,DeepSeek V3–0324 很可能是即将到来的 DeepSeek-R2 的简化模型。
DeepSeek R2 或将在 3-6个月后上线。
(更多关于AI的信息请扫码关注查看)


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)