微调大模型认知的方法
至此,对模型DeepSeek-R1-Distill-Qwen-1.5B基于LoRA(Low-Rank Adaptation)的监督式微调(Supervised Fine-Tuning, SFT)已经完成,自我身份认知测试结果正常。勾选虚拟机平台、适用于 Linux 的 Windows 子系统,(如有 Hyper-V,建议也勾选)。本手册介绍基于LoRA(Low-Rank Adaptation)的监
目录
2.1 powersheel 安装 liunx 子系统... 4
3.运行test.ipynb测试训练检查点的效果... 14
1.运行merged.ipynb合并训练后的模型,得到merged_identity_model 14
一、实验环境
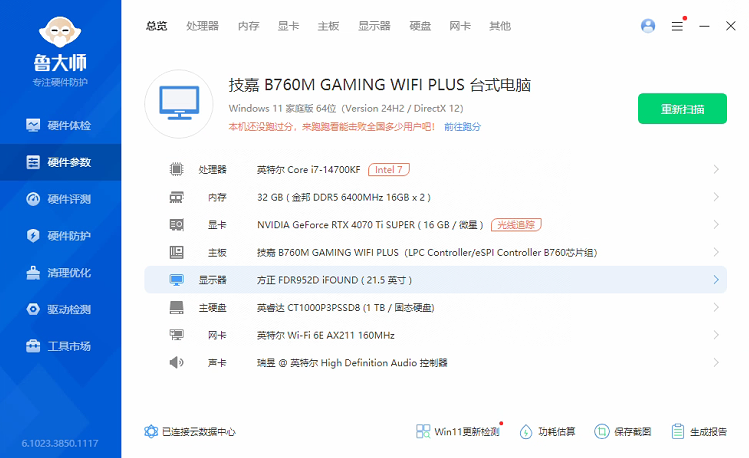
1.硬件配置
普通家用PC:
系统:windows11 专业版 24H2
处理器:Intel(R) Core(TM) i7-14700KF 3.40 GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4070 Ti SUPER
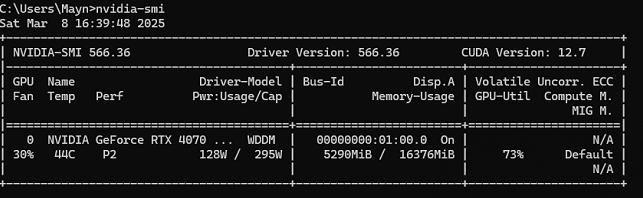
2.软件环境配置
2.1 powersheel 安装 liunx 子系统
(linux配置环境比较方便,在Windows很容易出错且容易有安装残留,此处建议在linux子系统操作,便于出错时候推到重新来过)
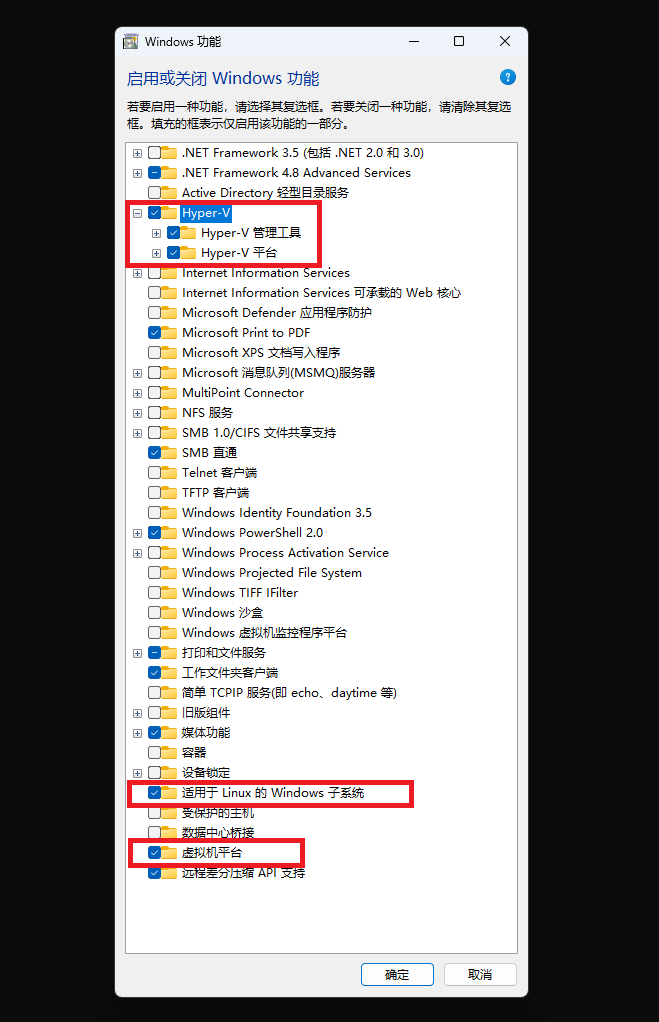
打开【控制面板】→【程序】→【启用或关闭 Windows 功能】。勾选虚拟机平台、适用于 Linux 的 Windows 子系统,(如有 Hyper-V,建议也勾选)。点击确定后,重启计算机。
在cmd打开后运行安装:
wsl –install

2.2 安装 Anaconda3
(学习过python应该使用过,包管理器很方便)
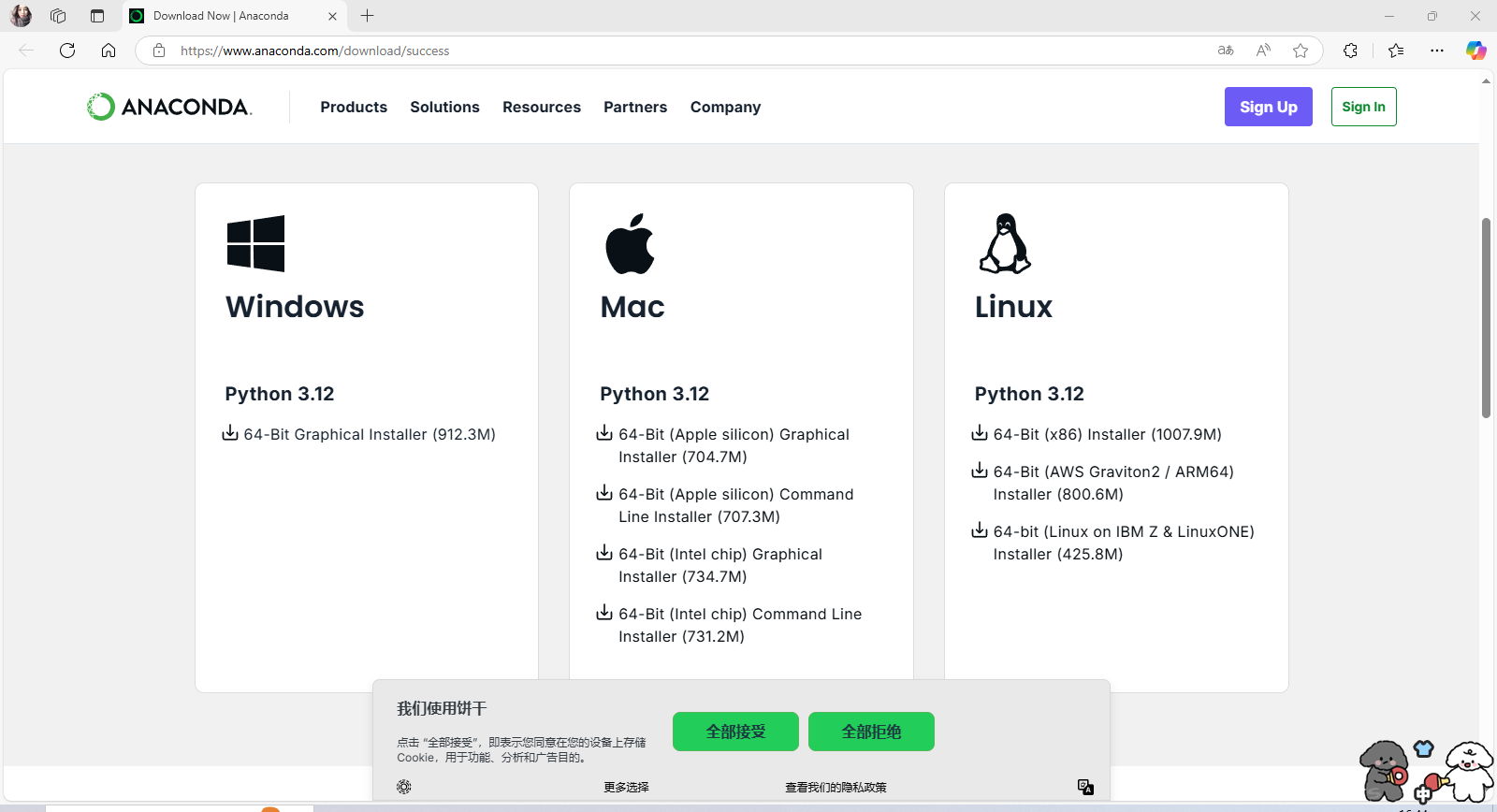
下载地址 Download Now | Anaconda(最初下载的是Windows版本,但是很容易在后面环境配置失败,而且由于残留基本上后续仍会失败,建议是下载linux版本)
Linux 子系统中
cd /home/keyen
找到 windows 下 Anaconda3-2024.10-1-Linux-x86_64.sh 文件
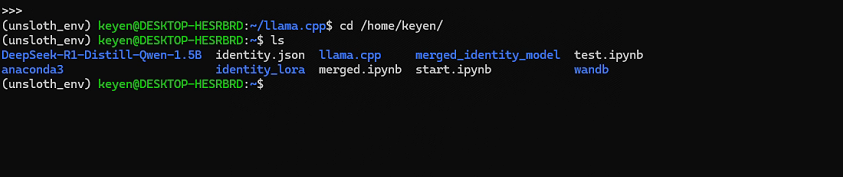
执行
./Anaconda3-2024.10-1-Linux-x86_64.sh
开始安装(建议挂梯子,不然很容易下载失败连接不上)
激活 Anaconda 环境
eval "$(./anaconda3/bin/conda shell.bash hook)"
2.3 安装 unsloth(市面上较为主流)
conda create --name unsloth_env \
python=3.11 \
pytorch-cuda=12.1 \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \ -y
(依次输入,\也要按照格式输入)
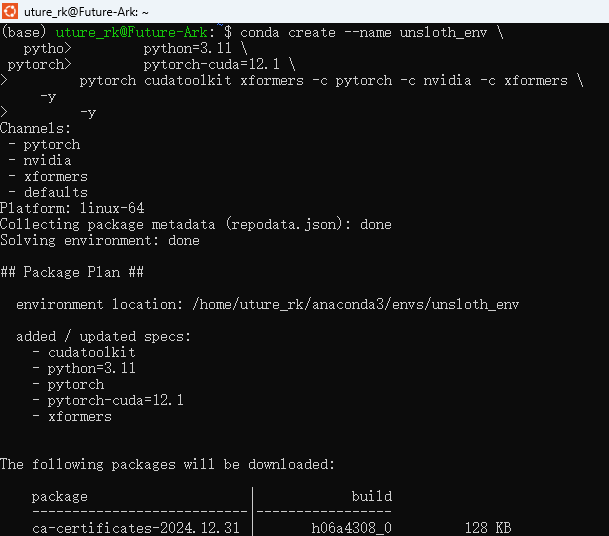
出现如图中情况则为正常情况
在安装完成后激活unsloth_env环境(和pycharm中询问是否使用virtual env类似)
conda activate unsloth_env
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps trl peft accelerate bitsandbytes
激活成功后在前面会出现一行小字视为成功

2.4 安装modelscope

pip install modelscope
下载模型(此处实例为1.5b)
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir ./DeepSeek-R1-Distill-Qwen-1.5B
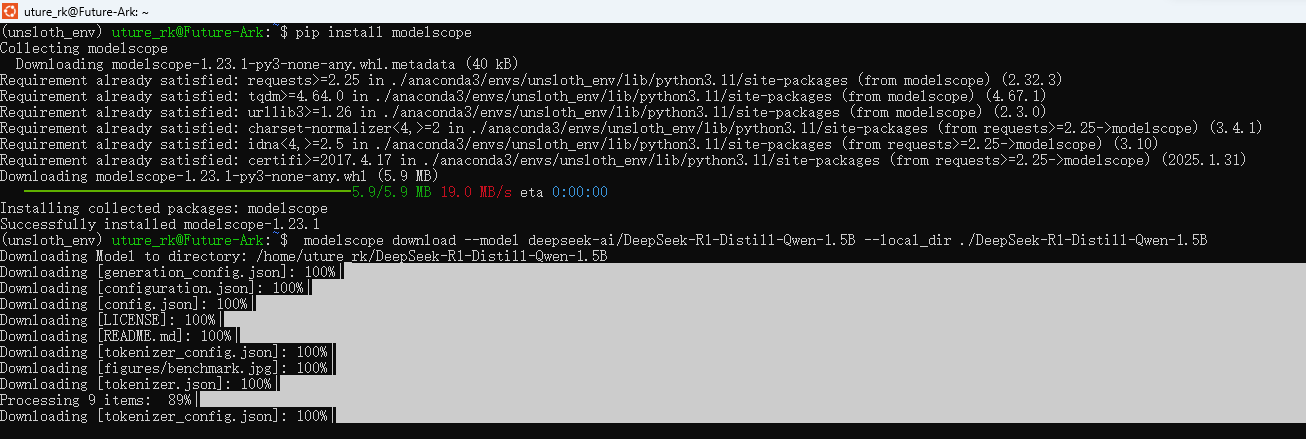
进度条走完即为下载完成
2.5安装wandb(用于记录训练过程 可选)
官网注册api key (Weights & Biases)
同样,也需要科学上网
pip install wandb
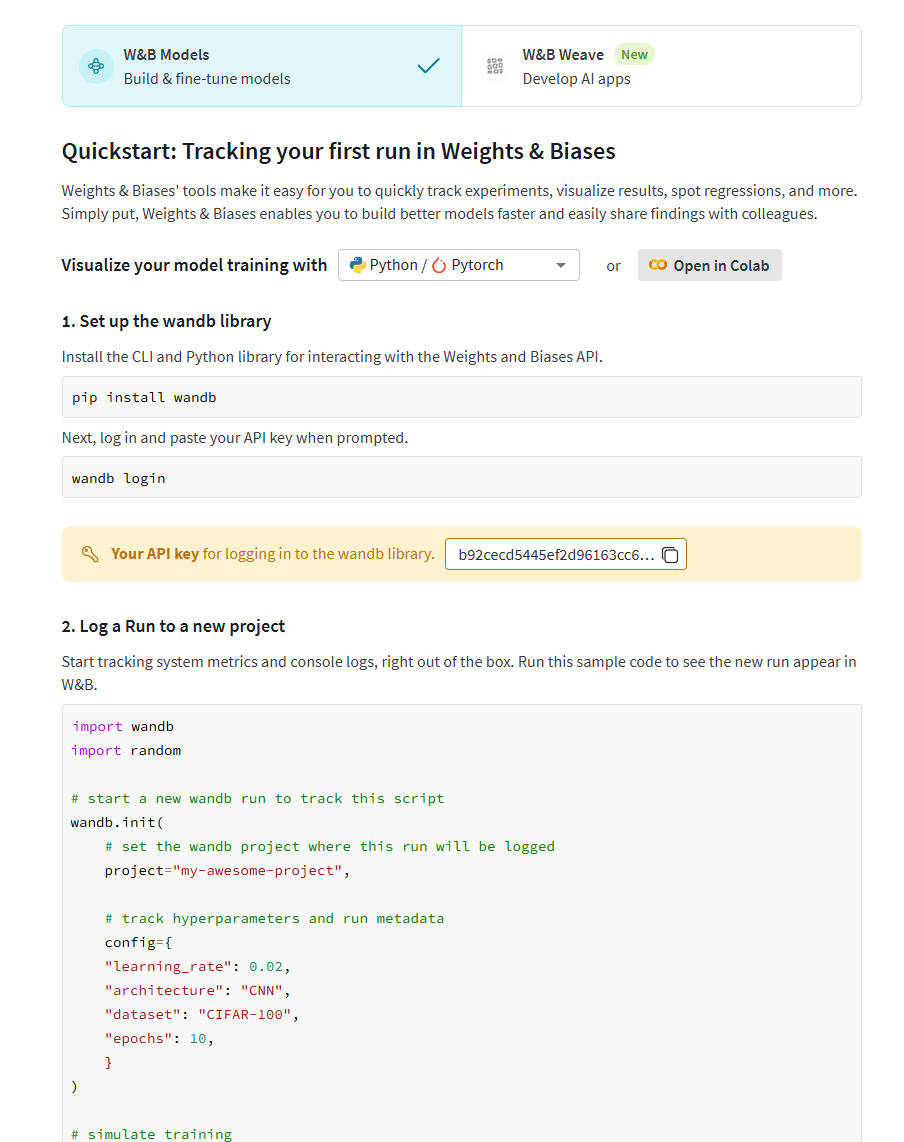
wandb login 填写wandb注册的apikey
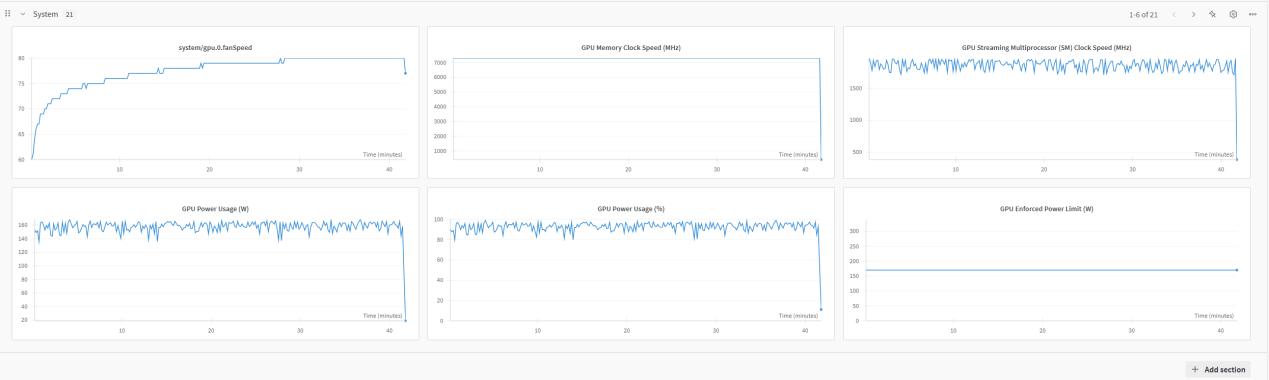
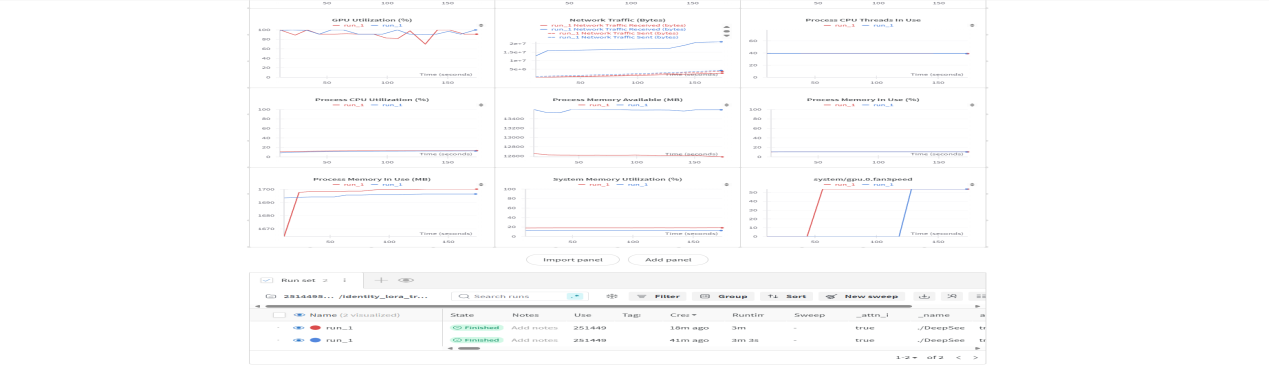
可以看到训练过程的一些图表
2.6 安装jupyter
pip install jupyte
- 微调过程
本手册介绍基于LoRA(Low-Rank Adaptation)的监督式微调(Supervised Fine-Tuning, SFT),对模型自我身份认知进行微调。
- 启动jupyter
jupyter lab
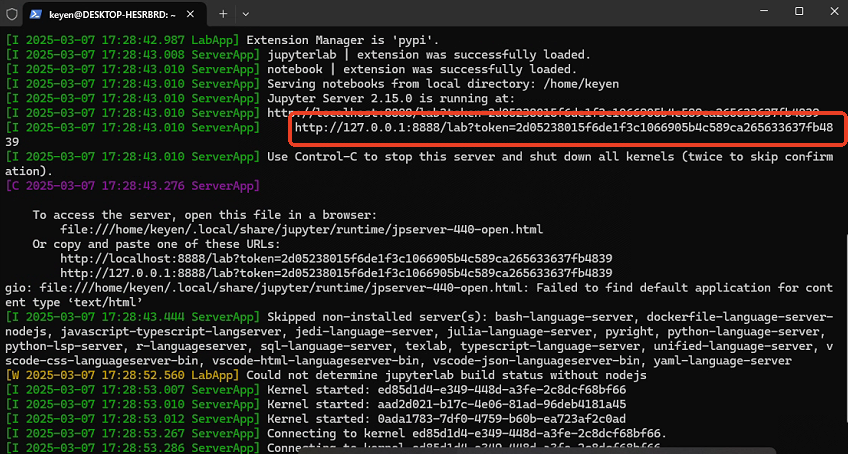
复制红框地址浏览器打开
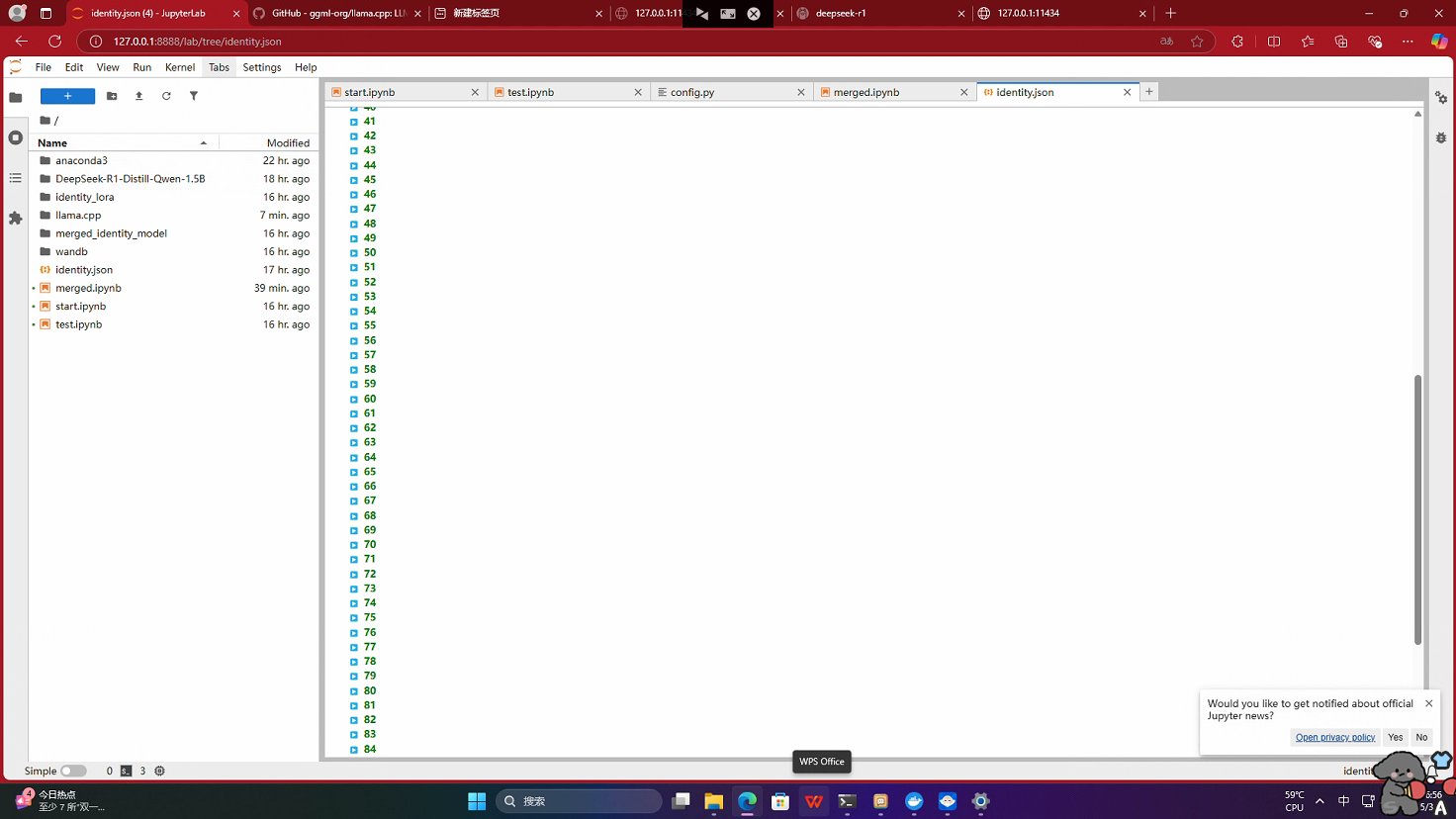
- 运行 start.ipynb 开始微调,得到identity_lora(训练检查点目录文件)
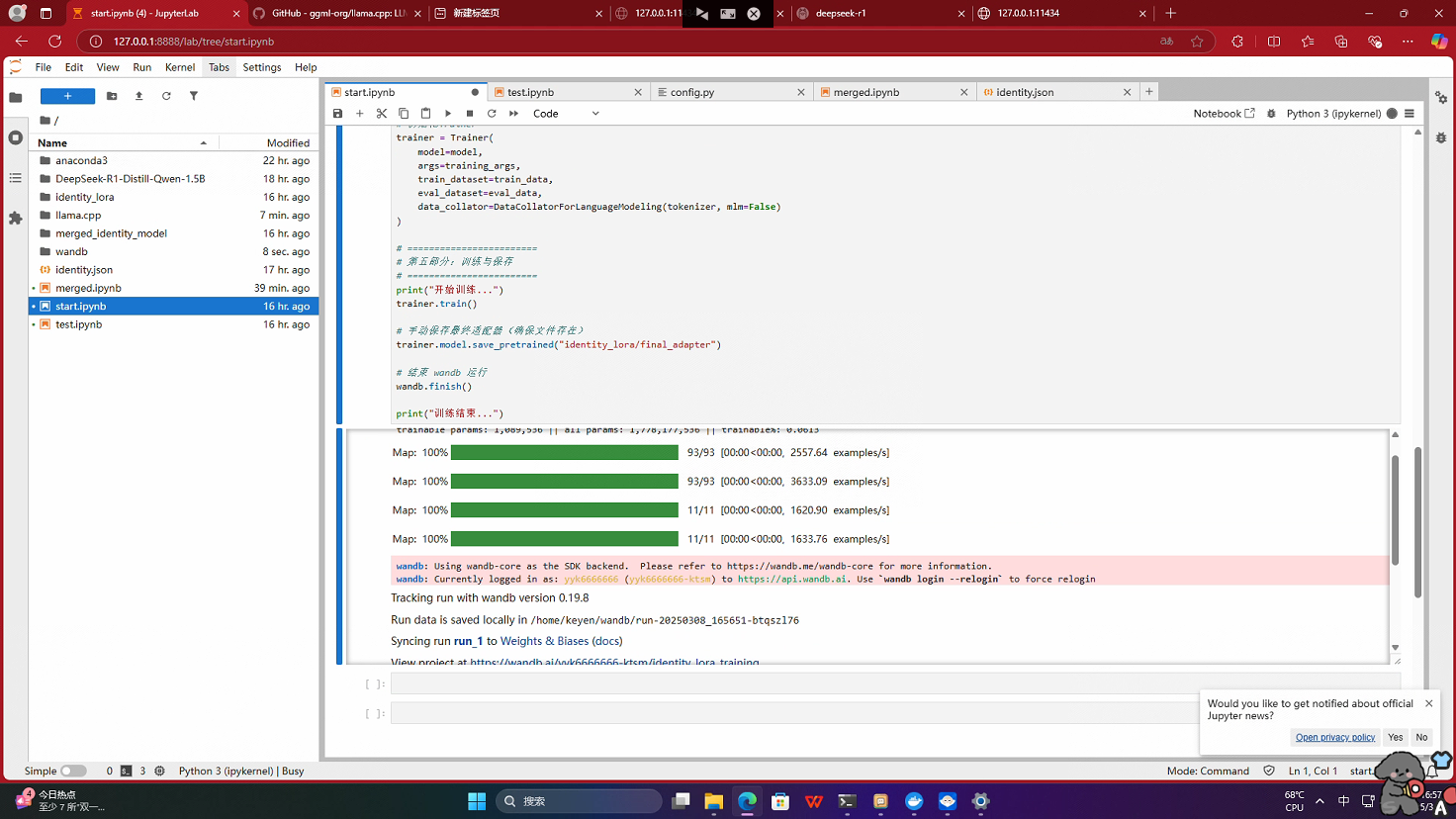
同时会生成 wandb记录报告(wandb较为优秀的一点,可以不用去官网直接可以在运行后查看)
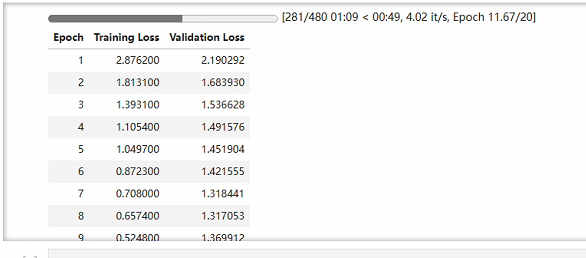
第一次训练建议使用较少数据
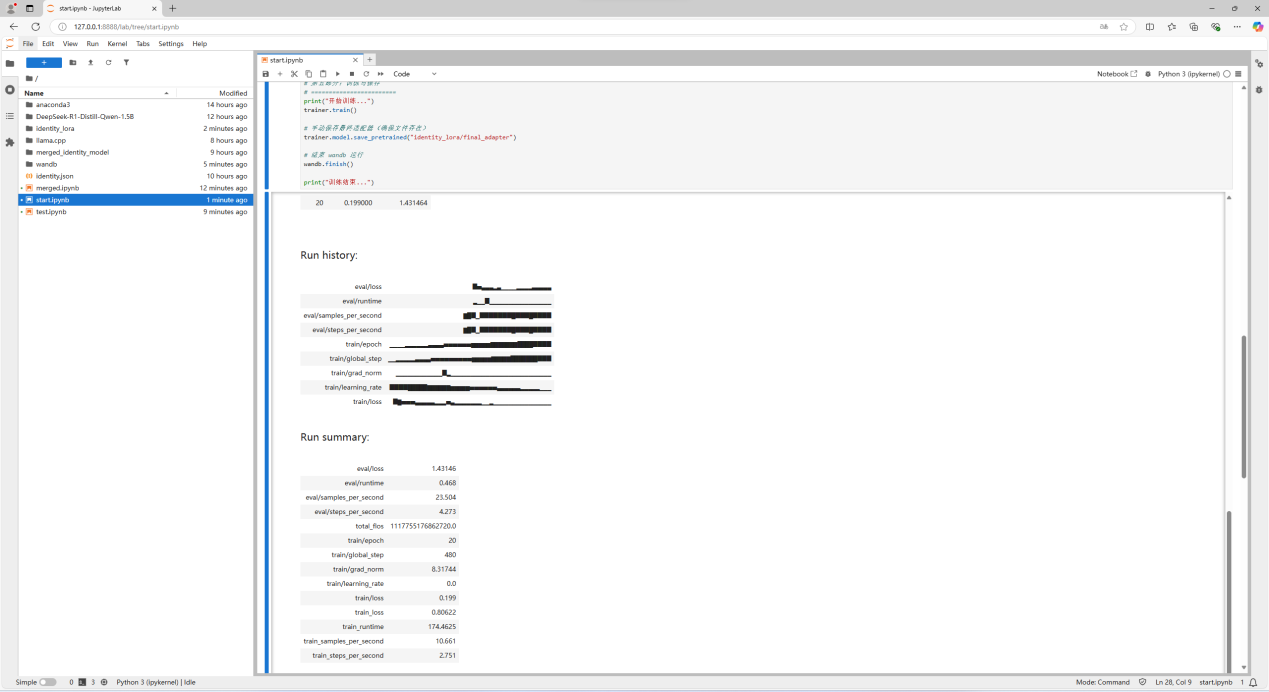
同样可以访问 https://wandb.ai,查看记录报告
3.运行test.ipynb测试训练检查点的效果
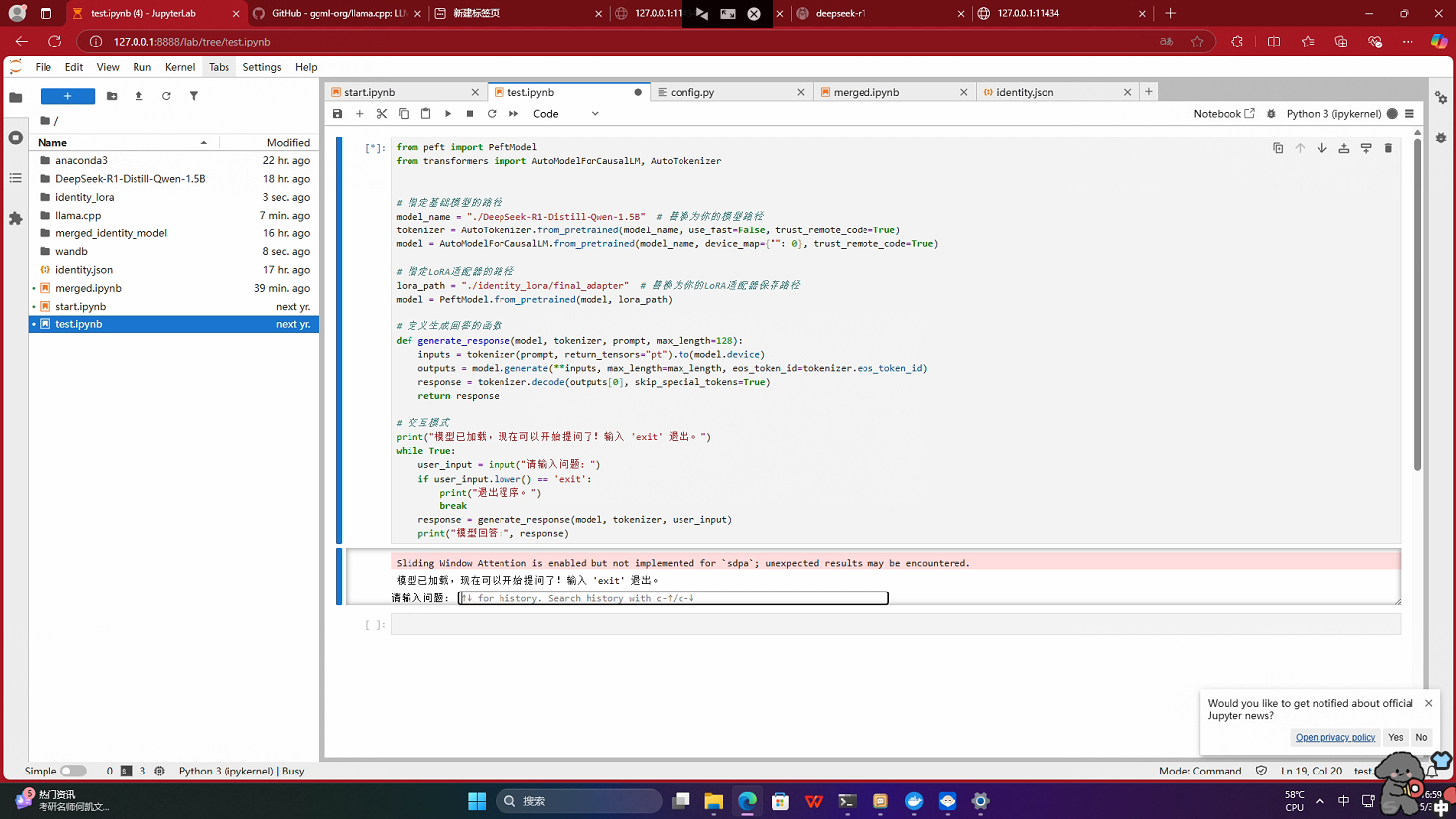
测试结果已调整自我认知
1.运行merged.ipynb合并训练后的模型,得到merged_identity_model
目录文件
# 加载基础模型
# 加载 LoRA适配器
# 合并权重并保存
# 保存 tokenizer
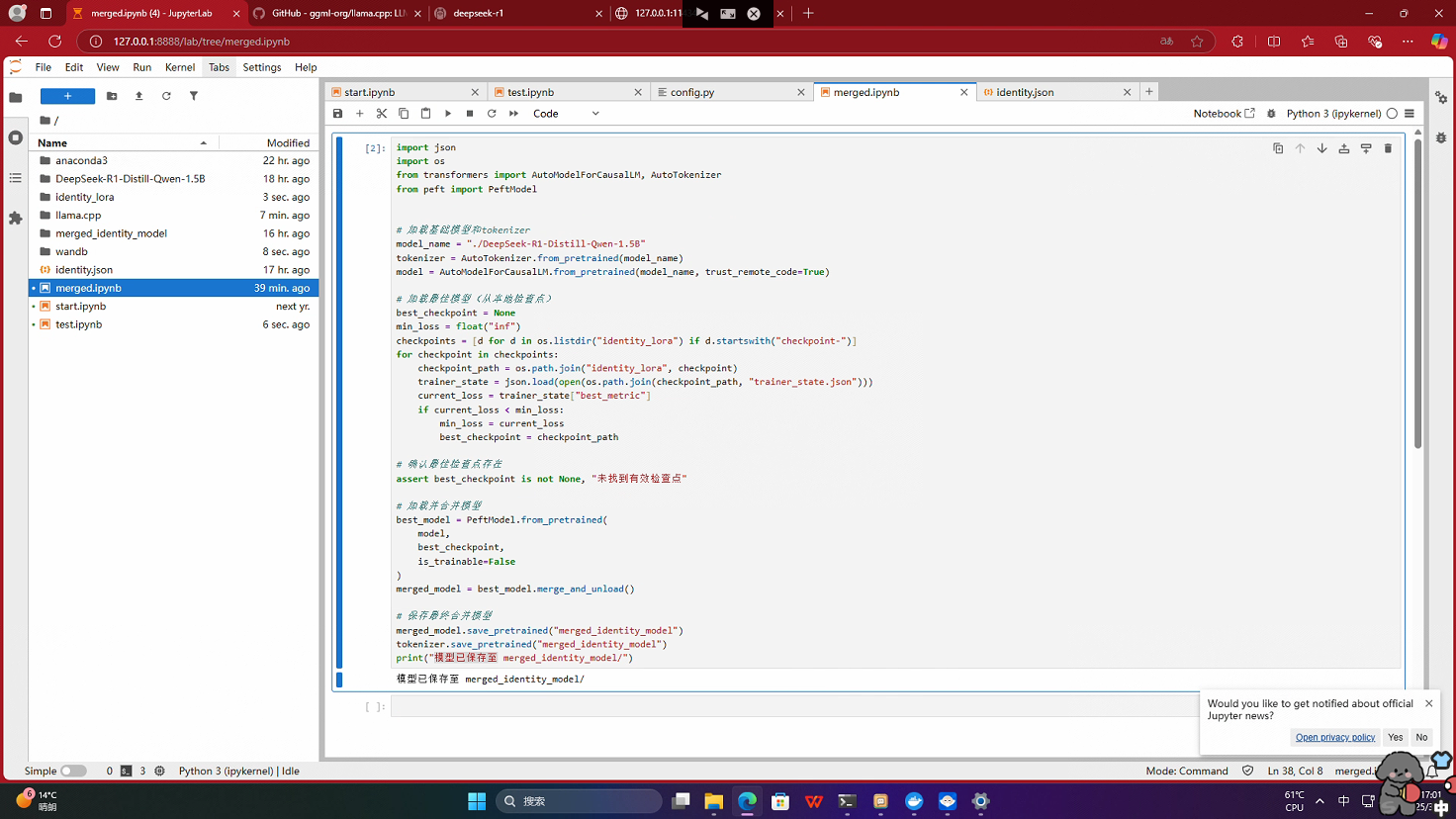
2.GGUF格式转换
将merged_identity_model目录文件转化成GGUF文件
# 安装基础编译工具
sudo apt update && sudo apt install -y \ build-essential \
cmake \
make
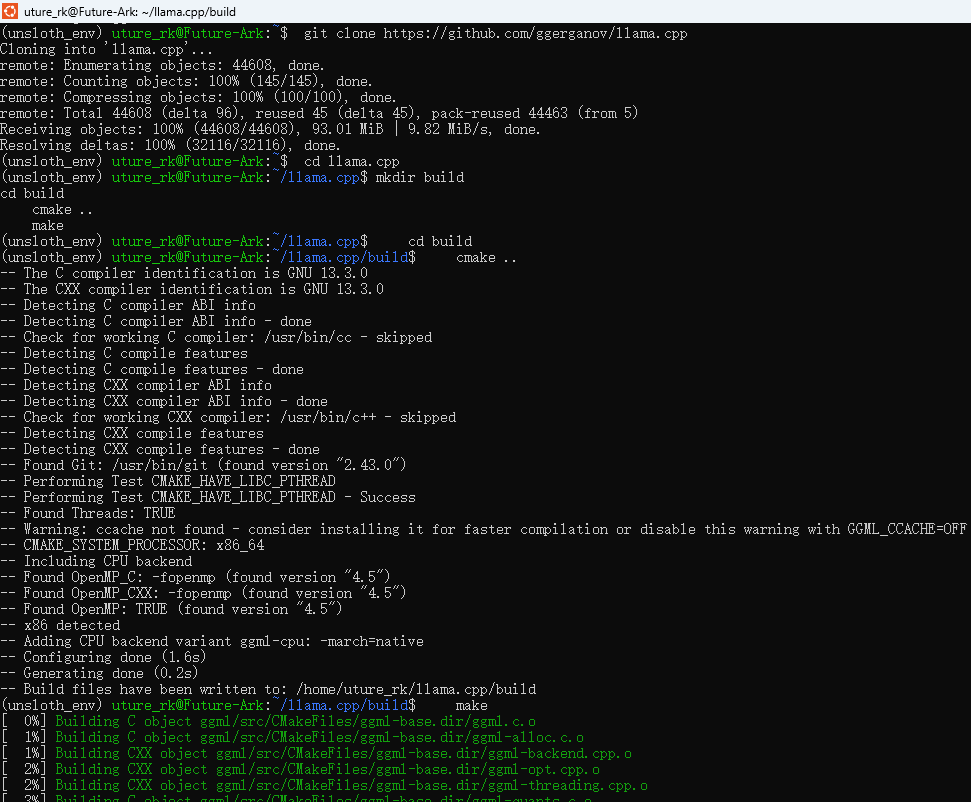
# 克隆llama.cpp仓库
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp
#编译工具
mkdir build
cd build
cmake ..
make
#通过工具转换格式
python3 /home/keyen/llama.cpp/convert_hf_to_gguf.py /home/keyen/merged_identity_model --outtype f16 --outfile deepseek-r1-distill-qwen-1.5B-TEST.gguf
生成deepseek-r1-distill-qwen-1.5B-TEST.gguf文件

(这一步应该大家都会)
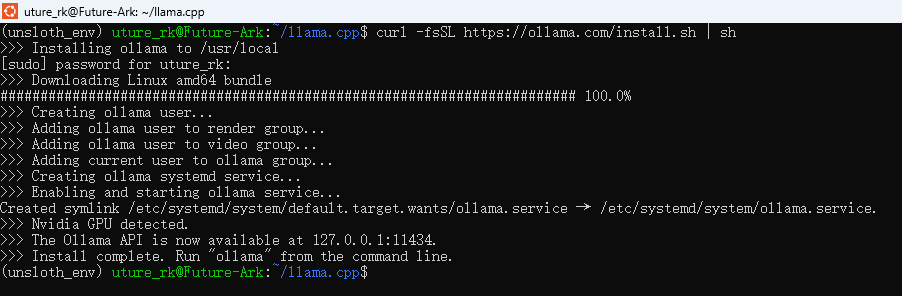
#安装ollama
curl -fsSL https://ollama.com/install.sh | sh
# 创建并编辑Modelfile
# 创建并编辑Modelfile
cat > Modelfile << EOF
FROM ./deepseek-r1-distill-qwen-1.5B-TEST.gguf
SYSTEM """
xxxxx
示例回答风格:
用户:xxxxx
助手:.....
"""
PARAMETER temperature 0.6
PARAMETER num_ctx 2048
PARAMETER stop ""
PARAMETER stop ""
PARAMETER repeat_penalty 1.1
EOF

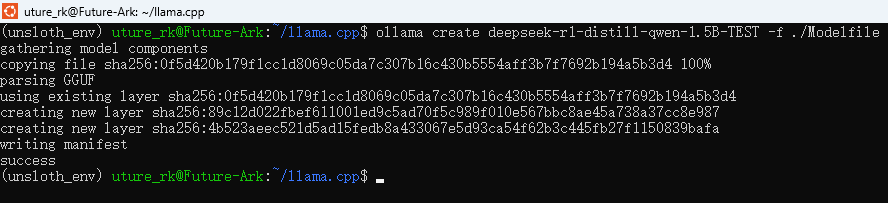
# 构建Ollama模型(这步将刚训练好的模型构建出来)
ollama create deepseek-r1-distill-qwen-1.5B-TEST -f ./Modelfile
# 运行测试
ollama run deepseek-r1-distill-qwen-1.5B-TEST
至此,对模型DeepSeek-R1-Distill-Qwen-1.5B基于LoRA(Low-Rank Adaptation)的监督式微调(Supervised Fine-Tuning, SFT)已经完成,自我身份认知测试结果正常。
构建的新模型文件可以部署到任何平台。
 如需部署到windows系统,只需安装上述软件导入模型文件,过程简单,不再阐述,可翻阅之前ollama部署教程等文件。
如需部署到windows系统,只需安装上述软件导入模型文件,过程简单,不再阐述,可翻阅之前ollama部署教程等文件。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)