停止过度思考:大语言模型的有效推理综述(下)
25年3月来自休斯敦 Rice U 的论文“Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models”。大语言模型 (LLM) 在复杂任务中表现出卓越的能力。大型推理模型 (LRM)(例如 OpenAI o1 和 DeepSeek-R1)的最新进展通过利用监督微调 (SFT) 和强化学习 (RL) 技术
25年3月来自休斯敦 Rice U 的论文“Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models”。
大语言模型 (LLM) 在复杂任务中表现出卓越的能力。大型推理模型 (LRM)(例如 OpenAI o1 和 DeepSeek-R1)的最新进展通过利用监督微调 (SFT) 和强化学习 (RL) 技术来增强思维链 (CoT) 推理,进一步提高了数学和编程等系统 2 推理领域的性能。然而,虽然较长的 CoT 推理序列可以提高性能,但它们也会因冗长和冗余的输出而引入大量计算开销,这被称为“过度思考现象”。
高效推理旨在优化推理长度,同时保留推理能力,可提供实际好处,例如降低计算成本和提高对实际应用的响应能力。尽管高效推理具有潜力,但仍处于研究的早期阶段。
本文是一个结构化综述,系统地调查和探索当前在 LLM 中实现高效推理的进展。总体而言,依托 LLM 的内在机制,将现有工作分为几个关键方向:(1)基于模型的高效推理,考虑将全-长度推理模型优化为更简洁的推理模型或直接训练高效推理模型;(2)基于推理输出的高效推理,旨在在推理过程中动态减少推理步骤和长度;(3)基于输入提示的高效推理,旨在根据输入提示的属性(例如难度或长度控制)来提高推理效率。此外,介绍使用高效数据训练推理模型的方法,探索小型语言模型的推理能力,并讨论评估方法和基准测试。
。。。。。。。继续。。。。。。。
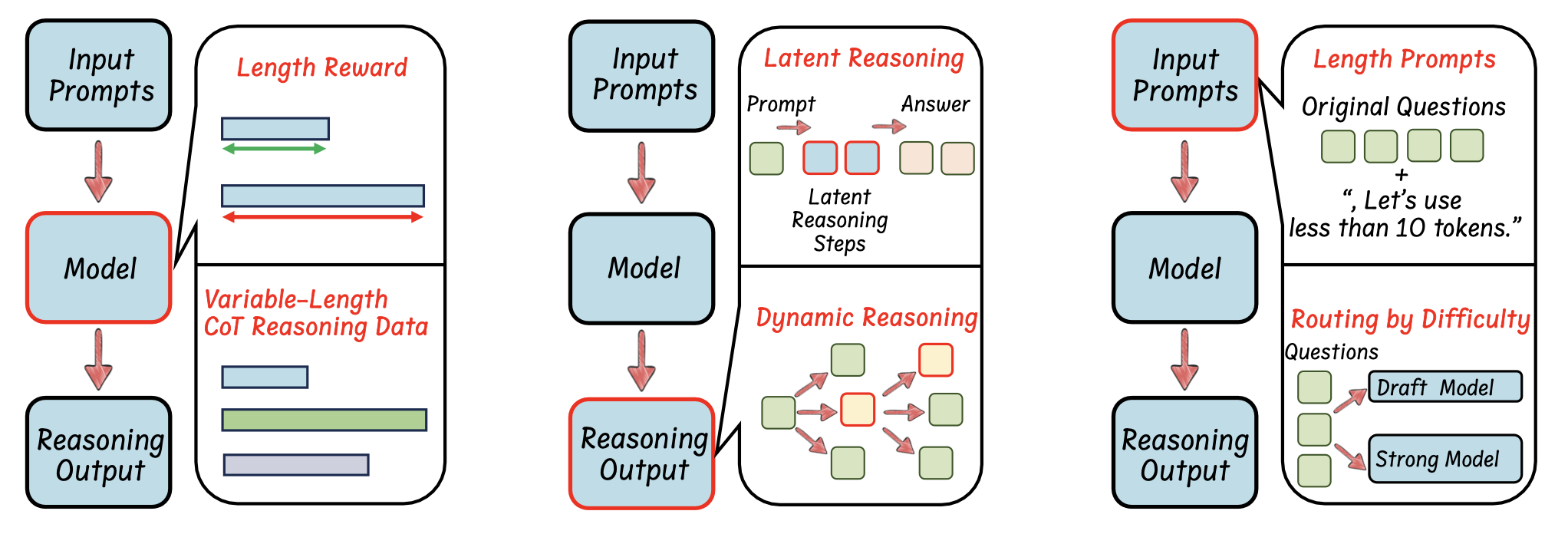
基于推理输出的高效推理
从输出中推理步骤的角度来看,这类工作侧重于修改输出范式,以增强 LLM 简洁高效推理的能力。
将推理步骤压缩为更少的潜表示
虽然标准 CoT 方法通过明确编写推理步骤来提高 LLM 性能,但最近的研究 [22] 表明,只需添加中间“思考”token,甚至添加毫无意义的填充符(例如“…”)[63],也可以提高性能。[29] 通过在隐空间中反复扩展而不是冗长的文本来扩展更深层次的推理。这些发现强调,好处往往在于更多的隐藏计算,而不是纯粹的文本分解。基于潜在推理可以让 LLM 更高效、更灵活地推理,使用更少(或没有)显式文本中间步骤的见解,几种新方法侧重于用更紧凑的潜表示压缩或替换显式 CoT。
总体而言,这些方法可分为两类:使用潜表示训练 LLM 进行推理或使用辅助模型。如图显示其中一些方法的可视化比较。

推理过程中的动态推理范式
现有研究侧重于修改推理范式以实现更高效的推理。推理过程中的关键是选择适当的标准来指导推理策略。当前的无训练方法使用各种标准探索动态推理,例如奖励引导、基于置信度和基于一致性的选择性推理。此外,基于总结的动态推理方法,在训练过程中内在地整合 LLM 的输出总结范式。
通过显式标准进行动态推理。使用 RL [31] 进行训练-时间扩展可以显著增强 LLM 的推理能力。然而,它需要大量的计算资源来扩大模型训练,这使得它的成本过高 [31]。作为一种替代方案,研究人员探索测试-时间推理,也称为测试-时间扩展 [72]。测试-时间扩展不是依靠训练来学习 CoT 推理步骤,而是利用各种推理策略,使模型能够对复杂问题“思考更长远和更广泛”。这种方法通过增加推理期间分配的计算资源,持续提高需要推理的具有挑战性数学和代码问题性能 [5, 72]。
测试-时间扩展,利用各种推理策略来生成更长、更高质量的 CoT 响应。有几种方法可以扩大推理范围。(1)N 中最佳采样 [76, 85] 涉及为给定提示生成多个响应,扩大搜索空间以识别更好的解决方案。生成后,使用多数投票来选择最佳响应,其中选择最常出现的响应;或通过奖励模型,根据预定义的标准评估响应质量。这种方法已被证明可以显著增强 LLM 的推理能力 [5]。(2)基于波束搜索 [5, 24, 28],它与 N 中最佳不同,它将生成分为多个步骤。波束搜索不是一次性生成整个响应,而是在每一步使用过程奖励模型(PRM) [81] 选择最有希望的中间输出,同时丢弃较少的最优输出。这样可以更细粒度地优化响应生成和评估。 (3) 蒙特卡洛树搜索 (MCTS) [41],其中并行探索多个解决方案路径。 MCTS 沿着解决方案树的不同分支生成部分响应,对其进行评估,并将奖励值反向传播到较早的节点。 然后,该模型选择具有最高累积奖励的分支,与传统的波束搜索相比,确保了更精细的选择过程。
虽然测试-时间扩展可以显着减少训练时间扩展开销 [5],但生成的大量响应仍然使推理在计算上很昂贵。 为了解决这个问题,最近的研究一直在探索优化测试-时间扩展的方法。
基于总结的动态推理。一些现有方法选择通过训练 LLM 总结中间思维步骤来优化推理效率。LightThinker [101] 建议训练 LLM 学习何时以及如何压缩中间推理步骤。LightThinker 不会存储长思维链,而是将冗长的推理压缩为紧凑的“要点(gist)token”,以减少内存和计算成本。实现这种总结范式需要一个稀疏模式的注意掩码,确保模型只关注必要的压缩表示。InftyThink [94] 引入一种迭代推理方法,该方法可以实现本质上无限的推理链,同时保持很强的准确性,而不会超过上下文窗口限制。它通过迭代地生成一个想法、总结它并丢弃以前的想法和总结,只保留最新的总结来实现这一点。此外,InftyThink 提供一种将现有推理数据集转换为迭代格式的技术,以便在该范式下训练模型。
基于输入提示的高效推理
从输入提示和问题的角度来看,这类工作侧重于根据输入提示的特点强制长度约束或路由 LLM,以实现简洁高效的推理。
提示引导的高效推理
提示引导的高效推理明确指示 LLM 生成更少的推理步骤,可以成为提高推理模型效率的一种直接而高效的方法。如表所示,不同的方法提出不同的提示,以确保模型的简洁推理输出。

提示属性驱动的推理路由
用户提供的提示范围从简单到困难。高效推理的路由策略根据查询的复杂性和不确定性动态确定语言模型如何处理查询。理想情况下,推理模型可以自动将较简单的查询,分配给速度更快但推理能力较弱的 LLM,同时将较复杂的查询,定向到速度较慢但推理能力较强的 LLM。
通过高效的训练数据和模型压缩提高推理能力
使用更少的数据训练推理模型
提高推理模型的效率不仅需要优化模型架构,还需要优化用于训练的数据。最近的研究表明,仔细选择、构建和利用训练数据可以显著减少数据需求,同时保持甚至提高推理性能。虽然所有方法都侧重于高效的数据选择,但它们在定义和利用效率方面有所不同。
通过蒸馏和模型压缩实现小型语言模型的推理能力
LLM 已在各种复杂任务中展现出卓越的推理能力,这得益于它们对各种数据集的广泛训练。然而,它们对计算和内存的大量需求对在资源受限的环境(如边缘设备、移动应用程序和实时系统)中的部署提出了挑战。在效率、成本或延迟是主要考虑因素的情况下,小型语言模型 (SLM) 提供了一种可行的替代方案。SLM 在严格的资源限制下仍然运行时保持强大推理能力的能力,对于扩大 AI 驱动的推理系统的可访问性和实用性至关重要。为了实现这一目标,探索两类主要方法:蒸馏和模型压缩。
评估和基准
最近的研究引入基准和评估框架,以系统地评估 LLM 的推理能力。随着 LLM 在执行复杂推理任务的能力方面不断进步,对严格、标准化的评估指标和框架的需求变得越来越重要。
Sys2Bench。[62] 开发 Sys2Bench,这是一个全面的套件,旨在评估五个推理类别的 LLM,包括算术、逻辑、常识、算法和规划任务。该基准包含 11 个不同的数据集,涵盖各种推理任务。它包括用于算术问题的 GSM8K 和 AQuA、用于常识推理的 StrategyQA 和 HotPotQA、用于逻辑推理的 ProntoQA、用于算法任务的 Game of 24 和 Bin Packing,以及用于规划任务的 BlocksWorld、Rubik’s Cube、TripPlan 和 Calendar Plan。
评估过度思考。[19] 引入一个框架来系统地分析 LLM 中的“过度思考”,其中模型倾向于扩展内部推理而不是必要的环境交互。通过检查智体任务中的 4,018 条轨迹,该研究发现诸如分析瘫痪、流氓行为和过早脱离等模式。[19] 还提出了一种“过度思考分数”,并表明分数越高,任务绩效越差之间存在很强的相关性。缓解策略(例如选择过度思考分数较低的解决方案)可以将性能提高 30%,同时将计算开销降低 43%。
计算最佳测试-时间扩展 (TTS)。 [49] 研究 TTS 策略对 LLM 性能的影响,重点研究策略模型、过程奖励模型和问题难度如何影响 TTS 的有效性。他们的研究结果表明,计算最优的 TTS 策略高度依赖于这些因素。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)