手把手傻瓜式一分钟部署DeepSeek到个人电脑
通过Ollama工具链,开发者可快速实现DeepSeek模型的本地化部署,结合不同参数版本的特性灵活选型。未来随着国产AI硬件的普及(如华为昇腾),本地部署成本有望进一步降低,推动AI技术在边缘计算场景的深度应用。
一、DeepSeek本地化部署的意义
DeepSeek作为国产高性能AI大模型,在创意写作、代码生成、办公自动化等领域表现突出。本地化部署可解决云端服务因访问量过大导致的服务器繁忙问题,同时提升数据隐私性(数据无需上传云端)和响应速度。对于开发者而言,本地部署还能支持定制化模型优化和私有化业务集成。虽然私有化部署的性能比不上现在网上提供的DeepSeek模型,但是我们可以更好地了解大模型的工作原理,特别是AI时代,AI应用门槛已经越来越低,我们对它了解越多,我们在社会就越有竞争优势。
二、核心工具Ollama的安装与配置
1. Ollama安装步骤
- 官网下载:Ollama是开源跨平台大模型工具,可以轻松帮你私有化部署各种模型,非常适合在个人电脑学习使用。访问 Ollama官网,选择与操作系统(Windows/macOS/Linux)匹配的版本下载安装包。我的电脑是Macbook,就选择macOS即可,其他系统可以选择对应版本。
安装完成在App列表就能看到,双击就能自动运行
- 验证安装:终端输入
ollama --version,若显示版本号(如0.6.1)即安装成功。
evan@EvandeMBP ~ % ollama --version
ollama version is 0.6.1
evan@EvandeMBP ~ %
- 后台服务启动:默认安装后Ollama会自动启动服务,端口为
11434。
三、DeepSeek模型的本地部署
1. 模型下载与安装
- 基础命令:在终端执行
ollama run deepseek-r1:7b,自动下载并安装7B参数模型。ollama官网可以看到支持的模型,其他模型安装也是一样,安装示例如下,显示success就已经完成本地化部署啦!是不是很简单呢?
evan@EvandeMBP / % ollama run deepseek-r1:7b
pulling manifest
pulling 96c415656d37... 100% ▕████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>> “用Python写一个函数”
<think>
嗯,用户说要用Python写一个函数。不过,他们没有具体说明是需要哪个类型的函数,
或者有什么特定的功能需求。
首先,我应该考虑最常见的需求,比如计算阶乘、斐波那契数列之类的。这样既简单又
容易理解,适合新手学习。
然后,我可以先问用户是否已经有了具体的使用场景,这样可以根据他们的需求来提供
更准确的建议。但作为一个初步的回答,写一个通用且基础的函数可能比较合适。
</think>
当然!请告诉我您需要这个函数的功能或用途是什么?
>>>
- 加速技巧:若下载缓慢,可通过环境变量设置镜像源(如
export OLLAMA_MODELS=https://mirror.example.com)。
export OLLAMA_MODELS="/your/custom/path"
- 满血版部署:部分教程提到使用第三方工具(如迅游手游加速器)获取
DeepSeek-R1-671B完整版,但需注意非官方渠道的安全风险。
2. 高级配置
-
修改模型存储路径
若默认存储路径(~/.ollama/models)空间不足,可通过环境变量自定义路径:export OLLAMA_MODELS="/your/custom/path" # 替换为目标路径重启终端生效。
-
性能优化
- 内存限制:若内存不足,启动时添加参数限制显存:
OLLAMA_GPU_UTILIZATION=50% ollama run deepseek-r1:7b - 量化模型:减少内存占用(可能降低精度):
ollama run deepseek-r1:7b --quantize q4_1 ```。
- 内存限制:若内存不足,启动时添加参数限制显存:
3. 可视化交互界面
- Chatbox(非技术人员推荐这方式) :安装 Chatbox客户端,配置Ollama API地址为
http://localhost:11434,选择deepseek-r1模型即可对话。
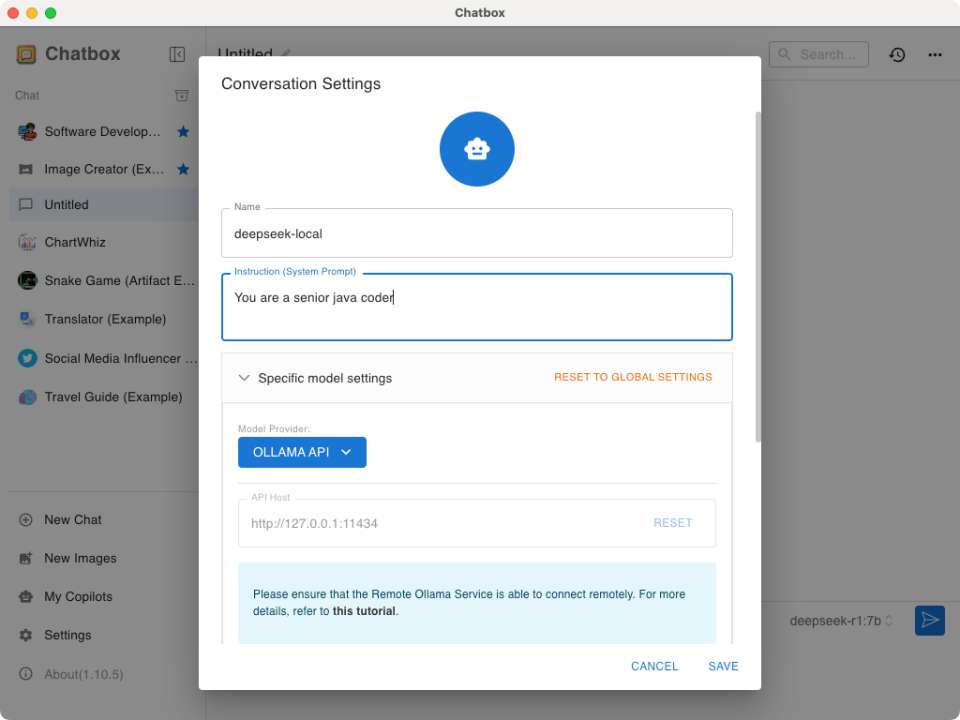
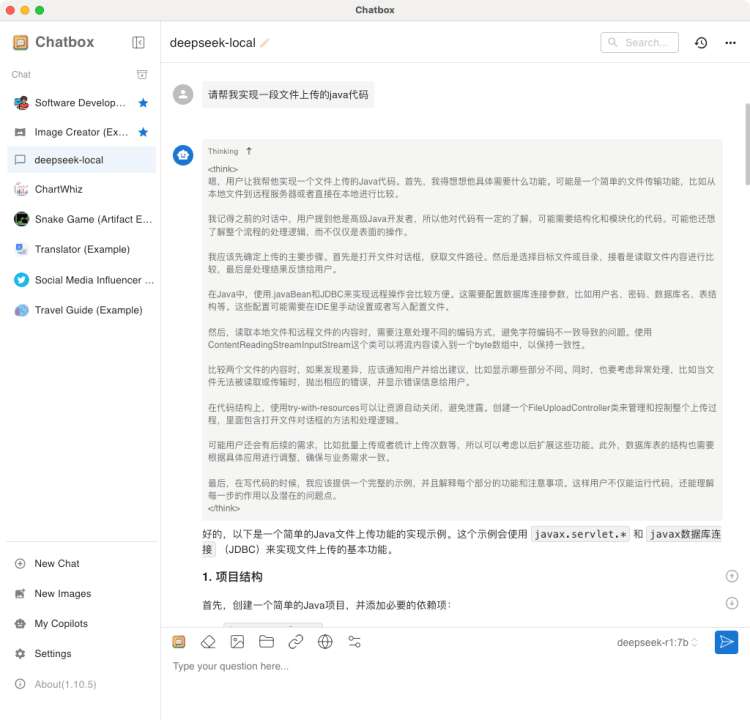
- Open WebUI:通过Docker部署网页版交互界面,支持多模型管理和对话记录保存。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
4. 常见问题解决
-
模型知识陈旧
DeepSeek-R1 7B的知识库可能截止至2024年7月,可通过提示词要求模型联网查询补充(需额外工具如Page Assist)。 -
下载中断或卡顿
检查网络连接,或尝试更换镜像源重新下载。 -
内存不足报错
关闭其他占用内存的应用,或换用更小模型(如deepseek-r1:1.5b)。
四、本地调用DeepSeek的方法
1. HTTP API调用
- 请求示例:向
http://localhost:11434/api/generate发送POST请求,JSON体包含模型名和提示词:{ "model": "deepseek-r1:7b", "prompt": "用Python实现快速排序", "stream": false, "options": {"temperature": 0.7} } - 流式响应:设置
stream: true可逐块接收生成结果,避免长文本超时。
2. 编程语言集成
- Java示例:使用
okhttp3库调用API:
package org.example;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import okhttp3.*;
import java.io.IOException;
public class OllamaClient {
private static final String OLLAMA_API_URL = "http://localhost:11434/api/generate";
private static final ObjectMapper mapper = new ObjectMapper();
public static String generateResponse(String prompt) throws IOException {
// 构建请求体
RequestBody body = buildRequestBody(prompt);
// 发送请求
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url(OLLAMA_API_URL)
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) throw new IOException("Unexpected code: " + response);
// 解析流式响应(Ollama API返回逐块数据)
StringBuilder result = new StringBuilder();
String line;
while ((line = response.body().source().readUtf8Line()) != null) {
JsonNode node = mapper.readTree(line);
if (node.has("response")) {
result.append(node.get("response").asText());
}
}
return result.toString();
}
}
private static RequestBody buildRequestBody(String prompt) {
// 构造JSON参数
String json = String.format("""
{
"model": "deepseek-r1:7b",
"prompt": "%s",
"stream": true,
"options": {
"temperature": 0.7,
"max_tokens": 5000
}
}
""", prompt.replace("\"", "\\\"")); // 处理双引号转义
return RequestBody.create(json, MediaType.parse("application/json"));
}
public static void main(String[] args) {
try {
String response = generateResponse("用Java写一个快速排序算法");
System.out.println("AI响应:\n" + response);
} catch (IOException e) {
e.printStackTrace();
}
}
}
<dependencies>
<!-- HTTP客户端 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON处理 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.16.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
</dependencies>
五、DeepSeek不同模型的差异与选型建议
| 模型版本 | 参数量 | 硬件需求 | 适用场景 | 特点 |
|---|---|---|---|---|
| DeepSeek-R1 7B | 70亿 | 8GB内存,无GPU可运行 | 轻量级任务(文本生成、简单代码) | 响应快、资源占用低,适合个人开发者 |
| DeepSeek-R1 8B | 80亿 | 16GB内存,推荐CUDA GPU | 复杂代码生成、多轮对话 | 支持更长上下文,生成质量更高 |
| DeepSeek-R1 671B | 6710亿 | 5张RTX 4090显卡,64GB内存 | 企业级应用、大规模数据处理 | 完整功能版,需高性能硬件支持 |
选型建议:
- 个人用户:优先选择
7B/8B版本,平衡性能与资源消耗。 - 企业级应用:若需处理复杂任务(如全栈代码生成、长文档分析),可部署
671B版本,但需投资高性能计算集群。
六、安全与优化注意事项
- 性能调优:
- 量化加载:使用8bit量化减少显存占用(如
load_in_8bit=True)。 - 分块处理:对长文本分段处理,避免超出模型上下文限制。
- 量化加载:使用8bit量化减少显存占用(如
- 漏洞防范:
- 定期更新Ollama至安全版本,修复已知漏洞(如CVE-2024系列)。
- 避免使用默认配置直接暴露公网,防止未授权访问。
七、总结
通过Ollama工具链,开发者可快速实现DeepSeek模型的本地化部署,结合不同参数版本的特性灵活选型。未来随着国产AI硬件的普及(如华为昇腾),本地部署成本有望进一步降低,推动AI技术在边缘计算场景的深度应用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)