vLLM 0.8版本,助力DeepSeek-R1 671B吞吐量破10000 Tokens
大模型推理引擎明星项目 vLLM 正式推出 0.8.0 版本,本次更新包含从核心引擎到硬件支持的全方位升级,堪称推理"加速器的史诗级增强"。无论是性能、模型支持,还是分布式并行能力,vLLM再次刷新行业标杆!
大模型推理引擎明星项目 vLLM 正式推出 0.8.0 版本,本次更新包含从核心引擎到硬件支持的全方位升级,堪称推理"加速器的史诗级增强"。无论是性能、模型支持,还是分布式并行能力,vLLM再次刷新行业标杆!
其中,新版本发布了大量关于 DeepSeek 的优化和增强:

在2台配置了8卡H100的的小集群上,部署vLLM 0.8.1进行性能验证:
- 并发:1024,输入长度:1024,输出长度:512
Benchmarking summary:
Backend: vllm
Traffic request rate: inf
Max reqeuest concurrency: not set
Successful requests: 1024
Benchmark duration (s): 174.12
Total input tokens: 1048576
Total generated tokens: 524288
Total generated tokens (retokenized): 522306
Request throughput (req/s): 5.88
Input token throughput (tok/s): 6022.28
Output token throughput (tok/s): 3011.14
Total token throughput (tok/s): 9033.42
Concurrency: 671.03- 并发:512,输入长度:4096,输出长度:512
Benchmarking summary:
Backend: vllm
Traffic request rate: inf
Max reqeuest concurrency: not set
Successful requests: 512
Benchmark duration (s): 227.12
Total input tokens: 2097152
Total generated tokens: 262144
Total generated tokens (retokenized): 260967
Request throughput (req/s): 2.25
Input token throughput (tok/s): 9233.50
Output token throughput (tok/s): 1154.19
Total token throughput (tok/s): 10387.69
Concurrency: 329.08此用例的吞吐量已经超过10000 Tokens/s。
英智及时跟进大模型的最新发展动态,向客户提供最具性价比的大模型API服务。
技术团队已在NVIDIA H系列高性能智算集群上验证和部署 vLLM 0.8.1 框架,全面提升了英智目前已上线的 DeepSeek-R1-671B、阿里千问QwQ-32B 等顶级开源大模型的推理性能,欢迎访问官网体验使用。
同时,英智提供多种形式的大模型推理服务,可以满足不同用户、各种场景的应用需求。
英智 DeepSeek 系列产品
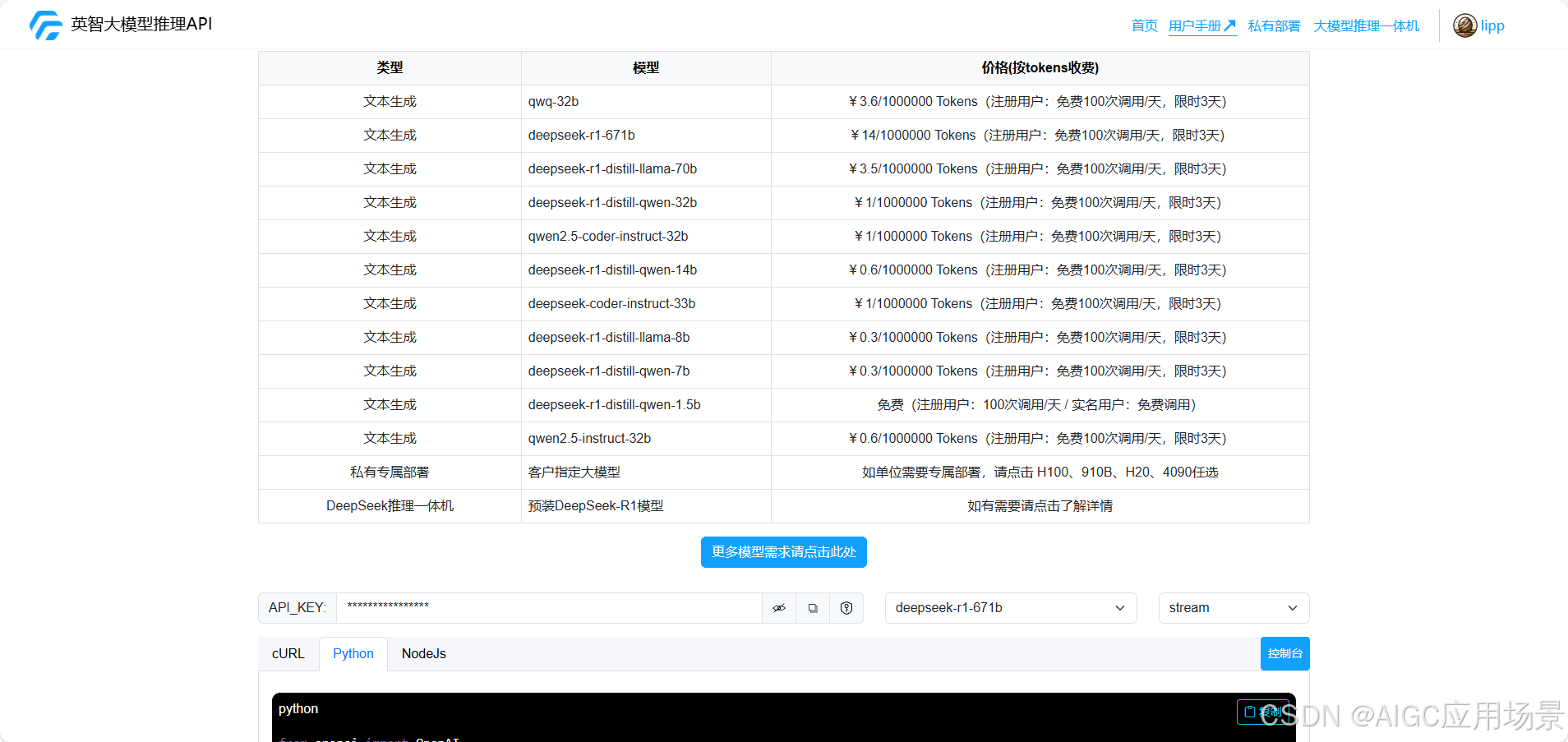
1. 英智大模型API公有云服务
英智大模型API公有云服务,面向大模型应用开发者及AI初创企业,提供基于DeepSeek等顶尖大模型的一站式智能云服务解决方案。通过开放兼容的API接口与弹性算力支持,助力客户快速构建生产级人工智能应用。
如果您对此感兴趣,请访问:https://api.gpubook.cn
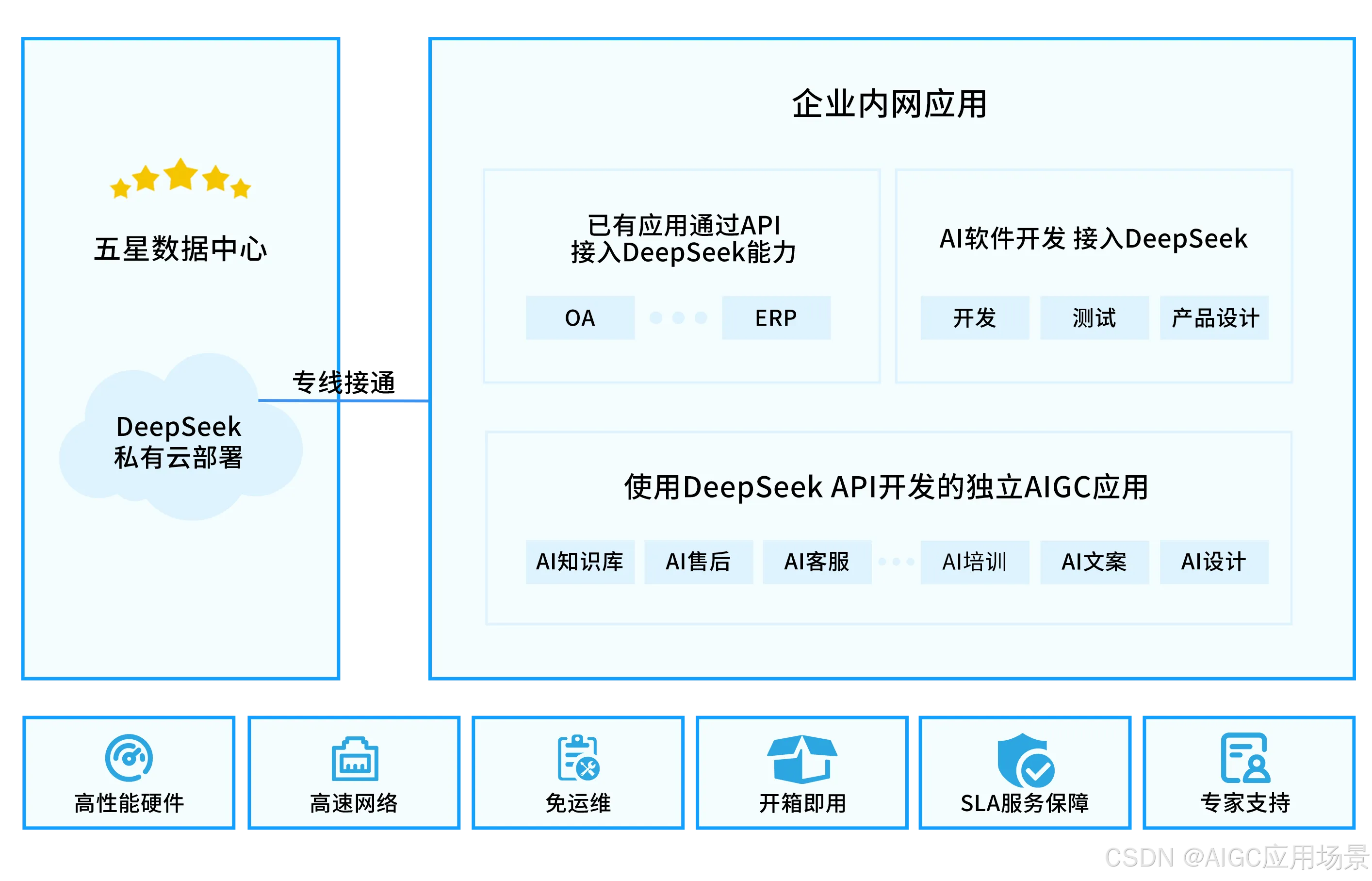
2. 英智大模型API私有部署托管服务
私有化部署托管是一种高效、低成本的大模型部署方案。企业可以通过与英智合作,租赁一台或多台高性能GPU服务器,在这些服务器上部署DeepSeek R1模型。部署完成后,这些服务器将成为企业的专属计算资源,仅为企业内部使用,确保数据安全和使用独占性。
在DeepSeek模型的部署和API平台的搭建过程中,英智将为客户提供全程技术支持,直接协助客户完成模型和平台的搭建。客户只需打通与企业内部网络的连接,即可快速投入使用,免去繁琐的配置和调试过程。
此外,英智还将定期为客户进行模型的升级和系统维护,确保平台始终保持在最佳性能状态,帮助企业在模型效果和响应速度上保持行业领先。
如果您对此感兴趣,请访问:https://api.gpubook.cn/privateDeployment
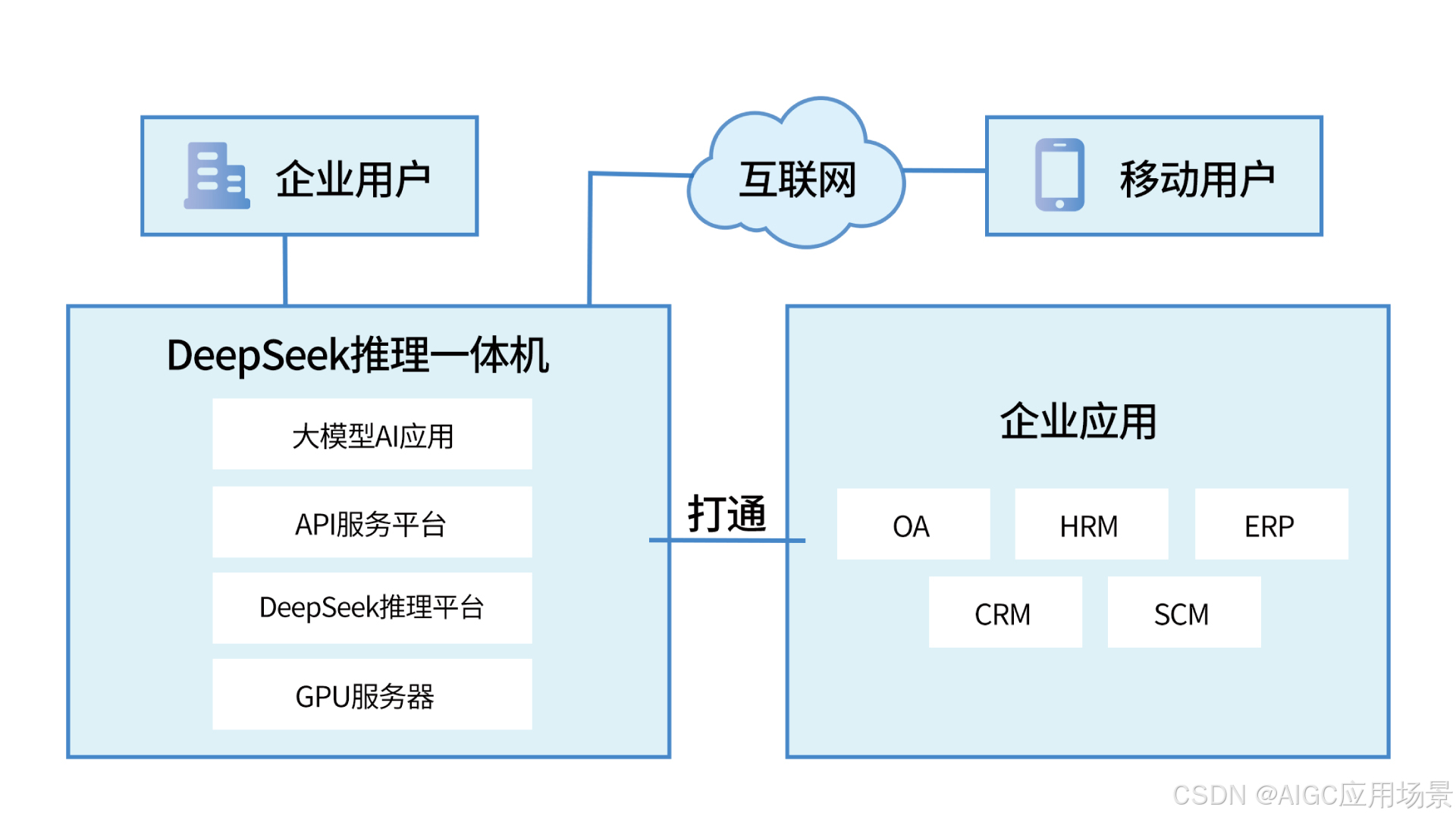
3. 英智大模型推理一体机
英智DeepSeek推理一体机以“硬件 + 软件 + 服务”三位一体架构为核心优势,构建企业级AI推理解决方案。其顶级硬件配置包括NVIDIA H100/H20/L40/4090等旗舰级GPU,搭配Intel多核处理器与高速内存系统,可实现千亿参数模型的快速响应,从容应对多任务并发处理与复杂推理场景。
系统预装深度优化的DeepSeek-R1模型,通过Transformer架构增强与行业场景适配,具备业内领先的自然语言理解与生成能力。该模型原生支持多模态交互、跨领域任务处理等核心功能,用户无需复杂配置即可实现文本生成、智能问答、代码开发等场景的即开即用。
英智为所有一体机产品提供定期的模型免费升级,确保模型性能和效果始终保持在行业领先水平。同时,提供长达3年的软硬件一体化服务,涵盖设备维护、软件更新和技术支持,助力企业在 AI 应用中保持稳定运行和持续创新。
如果您对此感兴趣,请访问:https://aio.gpubook.cn

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)