从入门到精通:DeepSeek实战全攻略(附代码)
从入门到精通:DeepSeek实战全攻略(附代码)
目录
1 DeepSeek API 调用
1.1 DeepSeek官网的API
https://platform.deepseek.com/usage
api现已支持充值
1.2 其他平台的API
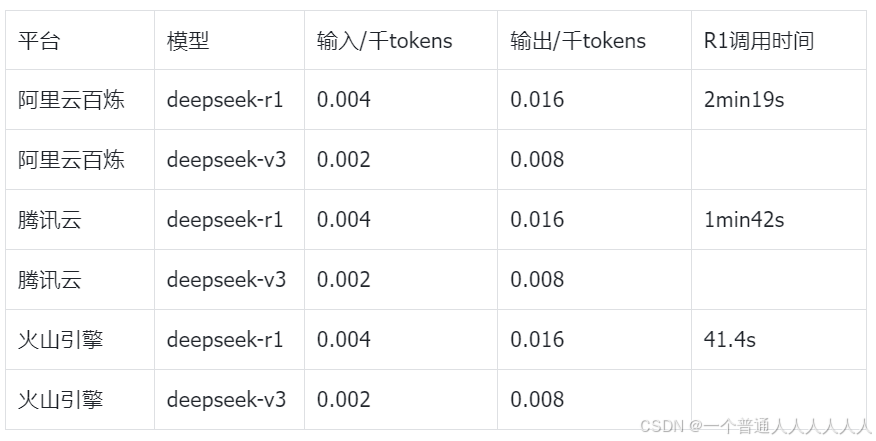
1.3 阿里云百炼
https://bailian.console.aliyun.com/detail/deepseek-r1#/prompt-manage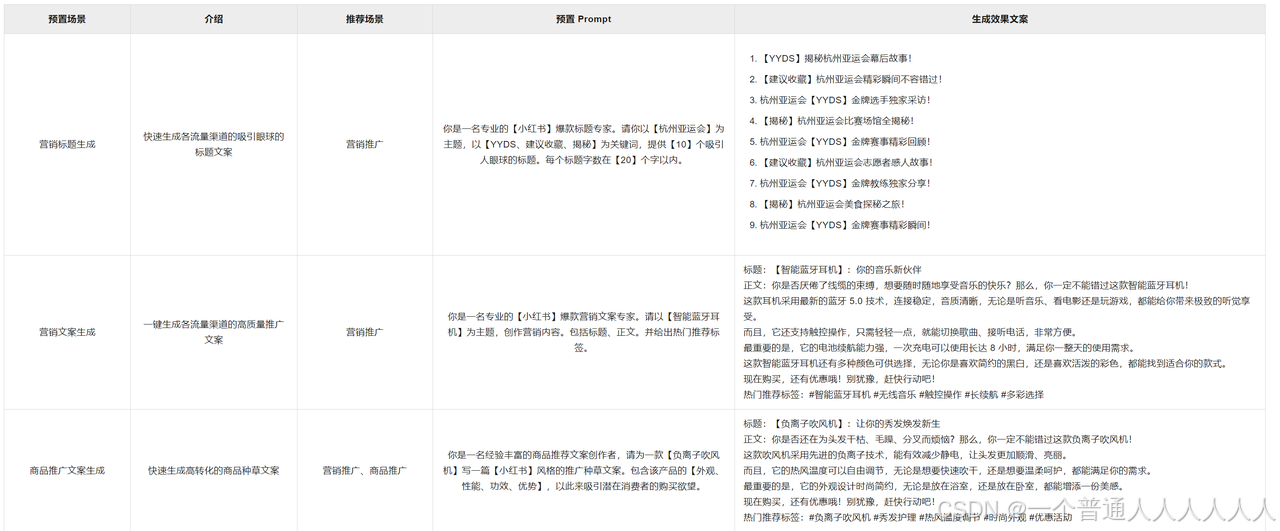
请根据以下信息编写一段直播带货的剧本,重点在于清晰阐述 p r o d u c t 的核心卖点,并通过场景化介绍展示其如何针对性地解决目标买家的痛点需求。产品名称: {product}的核心卖点,并通过场景化介绍展示其如何针对性地解决目标买家的痛点需求。产品名称: product的核心卖点,并通过场景化介绍展示其如何针对性地解决目标买家的痛点需求。产品名称:{product},目标用户群体: b u y e r p r o f i l e ,主要功能 / 特点: {buyer_profile},主要功能/特点: buyerprofile,主要功能/特点:{features},优惠活动: d i s c o u n t , 预期直播时长: {discount}, 预期直播时长: discount,预期直播时长:{duration}分钟, 其他信息:${other_info}。在剧本中,请务必包含产品的实际演示环节和解答常见问题的部分,以增加观众的信任度和购买意愿。
阿里的prompt工程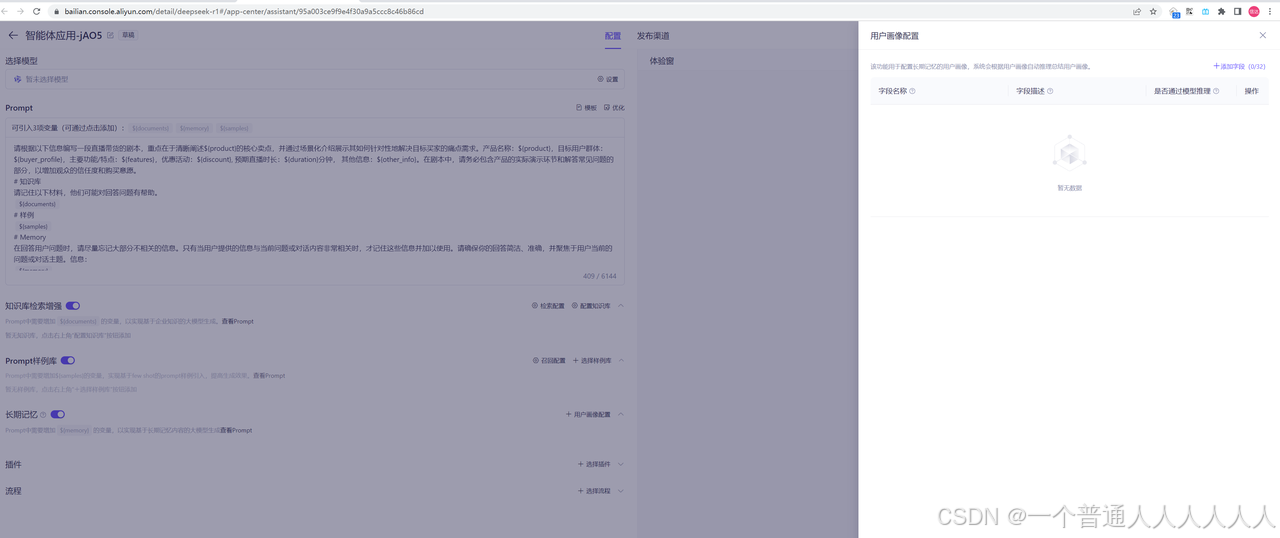
模型微调不支持deepseek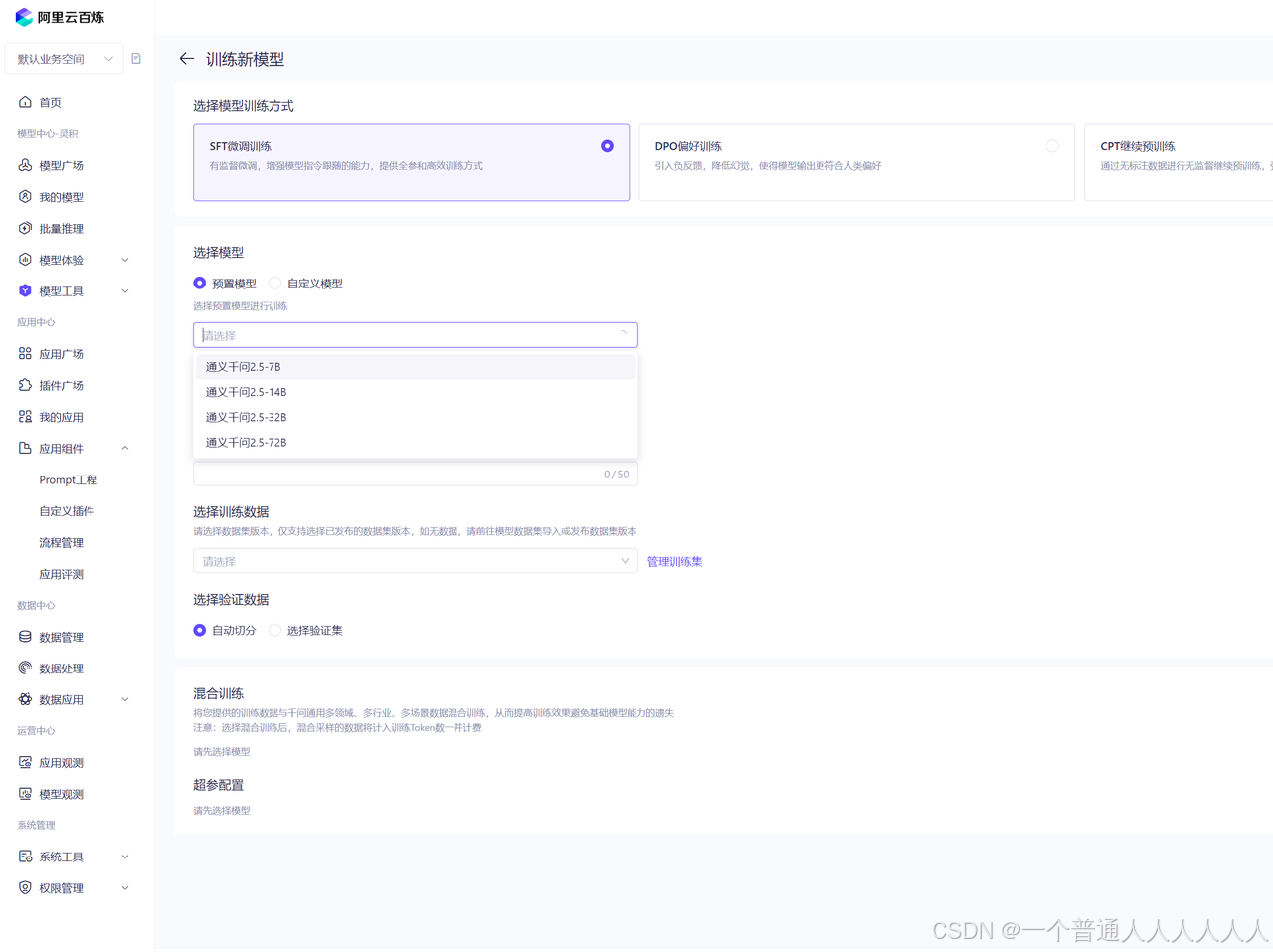
阿里的DeepSeek API调用结果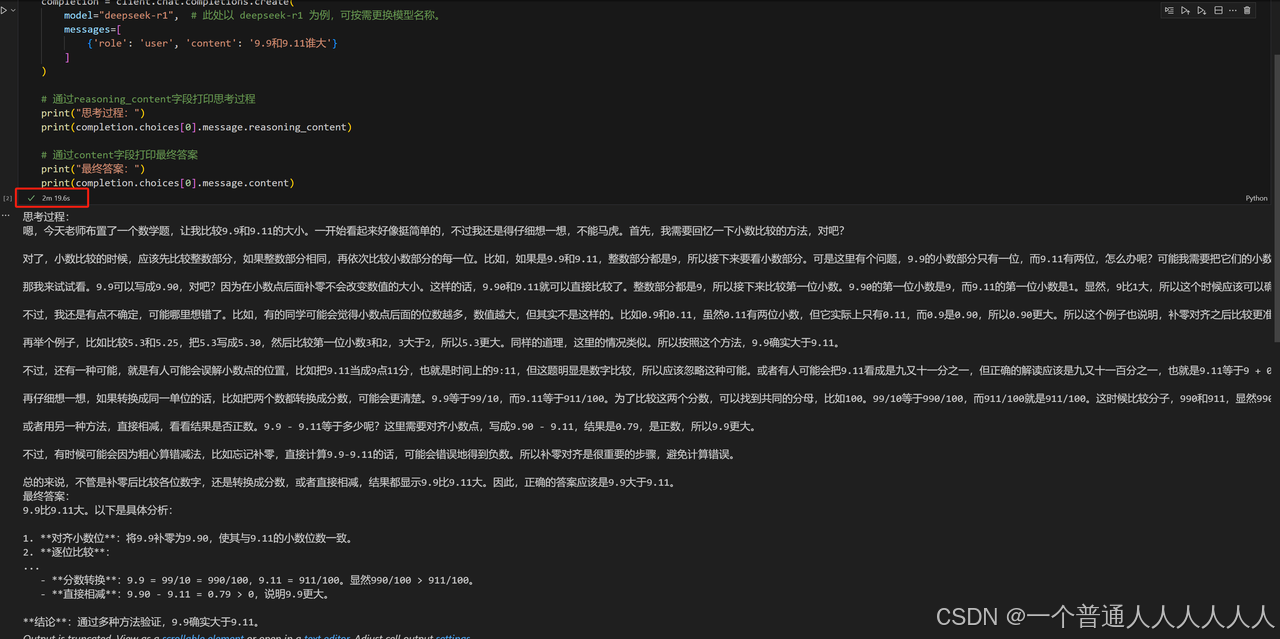
1.4 腾讯云
https://console.cloud.tencent.com/lkeap/api
腾讯云更关注数据库等产品
唯一和文案有关的产品如下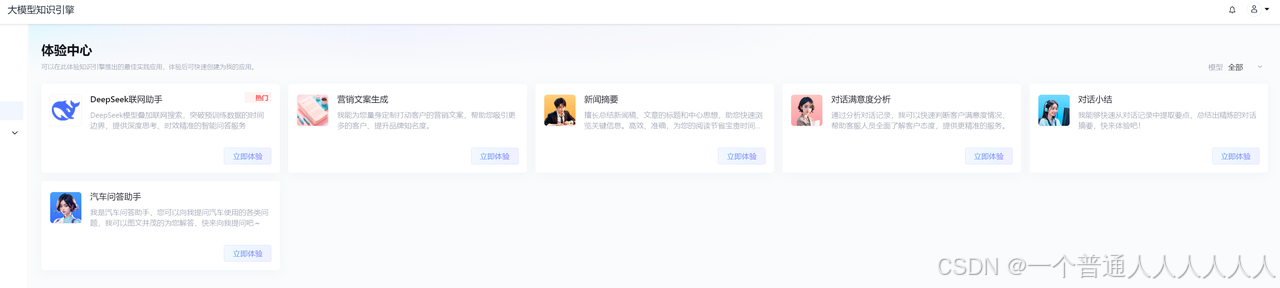
腾讯云的DeepSeek API调用结果
1.5 火山引擎
火山引擎的DeepSeek API调用结果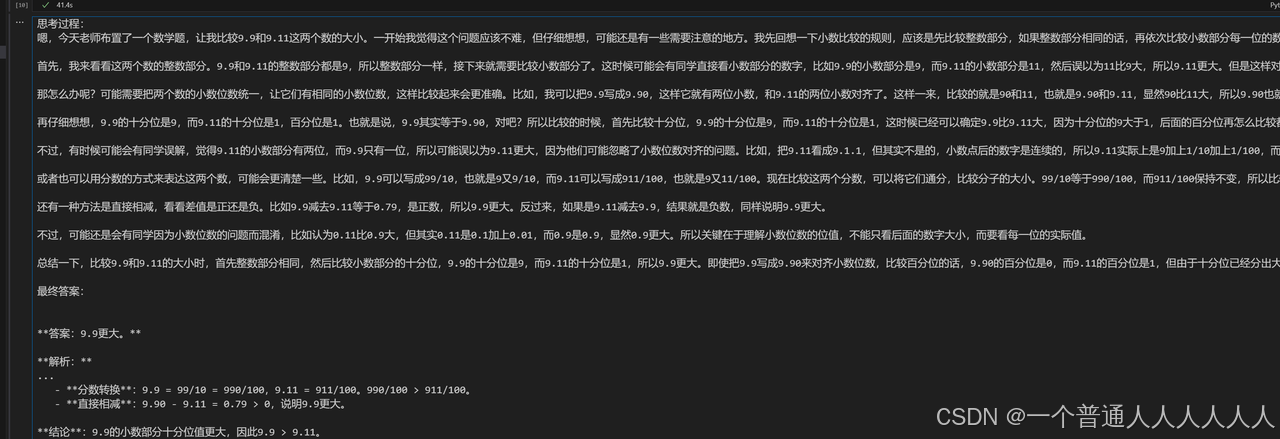
https://console.volcengine.com/ark/region:ark+cn-beijing/autope/workbench/ta-20250219083117-2432o?revisionId=prv-20250219083151-8A6z8
火山的prompt工程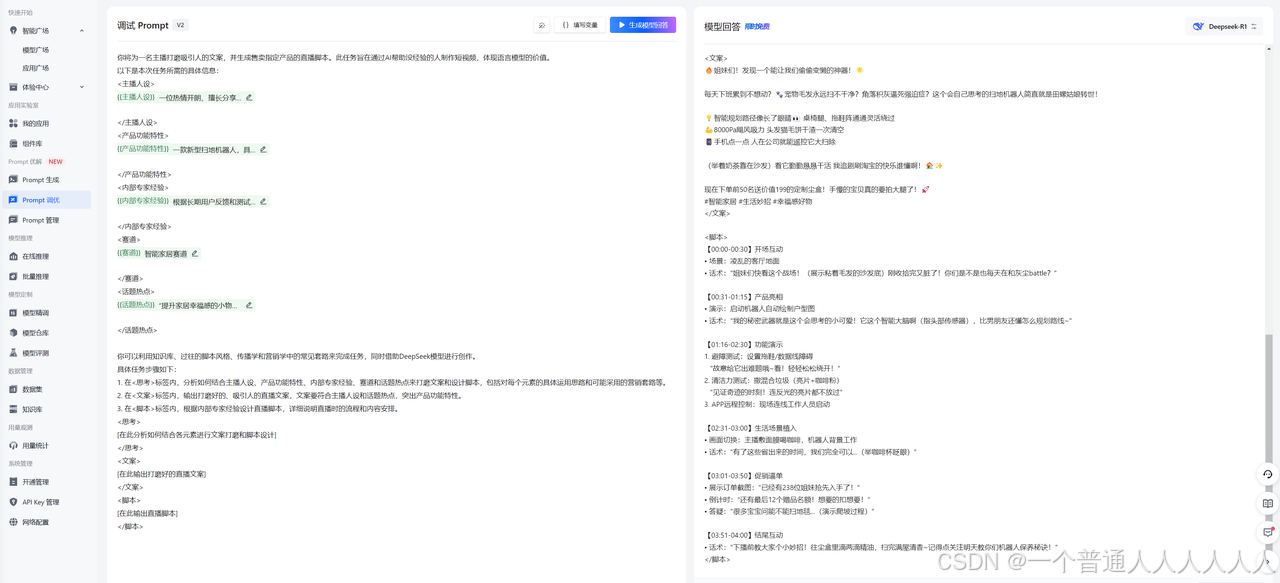
2 DeepSeek微调
为什么需要微调DeepSeek模型?
领域适配性:预训练模型虽泛用性强,但难以精准应对医疗、金融等专业领域需求。
性能提升:微调可使模型输出更符合特定任务风格(模型回答时间缩短35%)。
资源效率:相比全量训练,LORA等高效微调技术可节省90%显存
2.1 开源项目, 671B参数+Lora全量微调
DeepSeek 671B BF16 Lora
https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalChat/examples/training_scripts/lora_finetune.py
硬件配置: 24 个 H100 GPU
https://huggingface.co/deepseek-ai/DeepSeek-R1
DeepSeek官方开源参数
2.2 官方7B微调
DeepSeek 7B LLM
https://huggingface.co/deepseek-ai/deepseek-llm-7b-base
BaseModel: Qwen2.5-Math-7B
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
BaseModel: Qwen2.5-14B
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
2.3 四步完成高效微调(附代码)
2.3.1 模型加载与量化
# 4-bit量化加载(网页7核心代码)
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-r1", quantization_config=bnb_config)
2.3.2 LORA参数配置
关键模块选择:q_proj和v_proj对推理性能影响显著
2.3.3 训练策略优化
梯度累积(Gradient Accumulation)解决小批量训练不稳定问题
混合精度(FP16)加速训练速度
2.3.4 分布式微调技巧
使用Llama-Factory实现多GPU并行
2.3.5 三大核心技巧与避坑指南
技巧1:数据增强
添加噪声数据提升鲁棒性(如医疗问答中引入20%干扰项)。
技巧2:渐进式学习率
初始3e-4,每10k步衰减10%。
避坑点:
避免过拟合:早停法(Early Stopping)结合验证集监控。
显存溢出对策:gradient_checkpointing
总结
DeepSeek微调技术通过领域适配与参数优化,显著提升模型实用价值。关键成功要素包括:高质量数据集设计(如思维链构建)、高效微调方法选择(LORA+量化),以及分布式训练方案应对超大模型。未来趋势指向自动化微调(Auto-SFT)与多模态适配扩展
后续我会出消费级GPU上实现deepseek微调的完整代码

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)