(2024|DeepSeek,为理解与生成设计独立的视觉编码路径)Janus:解耦视觉编码以实现统一的多模态理解和生成
本文提出了 Janus,一个通过视觉编码器解耦的统一多模态框架。Janus 分别为理解与生成任务设计独立的视觉编码路径,并使用统一的 Transformer 处理输入,从而缓解任务间冲突,提升灵活性。
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation

目录
1. 引言
近年来,多模态大模型在理解与生成任务上取得了显著进展。早期工作如 LLaVA 通过视觉编码器桥接图像与大语言模型(LLM),使其具备图像理解能力。与此同时,扩散模型在视觉生成方面表现突出,近期也有研究探索使用自回归方法进行图像生成。
然而,许多统一多模态模型如 Emu,将生成任务外包给扩散模型,因此难以称为真正统一。其他工作如 Chameleon 尝试使用单一视觉编码器支持理解与生成任务,但由于两者所需的表示粒度不同,这一策略存在性能折衷问题。
为解决此矛盾,本文提出了 Janus,一个通过视觉编码器解耦的统一多模态框架。Janus 分别为理解与生成任务设计独立的视觉编码路径,并使用统一的 Transformer 处理输入,从而缓解任务间冲突,提升灵活性。
实验显示,Janus 在多项理解与生成基准测试中均取得了领先性能,超越多个任务专用模型。

2. 相关工作
2.1 视觉生成
视觉生成任务近年来迅速发展,受自然语言处理和 Transformer 架构的启发,自回归模型在该领域中广泛应用。这些模型通常将视觉数据离散化为视觉 token(如 codebook ID),并采用类似 GPT 的方式进行预测。
此外,基于 BERT 的遮盖预测方法也被引入,提升了生成效率,并在视频生成任务中得到应用。
同时,连续扩散模型在视觉生成方面也表现出卓越能力,其基于概率建模的方法与离散方法形成互补。
2.2 多模态理解
多模态大语言模型(MLLM)整合了图像与文本输入,借助预训练的 LLM 展现出强大的跨模态理解能力。
近期方法尝试结合扩散模型为 MLLM 添加图像生成能力,属于 “工具调用” 范式,即使用 MLLM 输出的条件引导扩散模型生成图像。
然而,这类方法本质上并不能赋予 MLLM 直接生成图像的能力,整体生成性能受限于外部扩散模块,效果不如直接使用扩散模型。
2.3 统一多模态理解与生成
统一的多模态理解与生成模型致力于在不同模态间实现无缝推理与生成。传统方法通常采用单一视觉表示用于理解与生成,无论其构建基于自回归模型还是扩散模型。
例如,Chameleon 使用 VQ Tokenizer 对图像编码,并统一用于两个任务。这种方法忽视了理解与生成任务在信息需求上的差异,导致视觉编码器难以在两种任务间取得平衡。
与此不同,Janus 显式地为理解与生成任务设计独立的视觉编码路径,承认不同任务对信息粒度的不同需求,从而实现更优的任务表现。
3. Janus:一个简单、统一且灵活的多模态框架
Janus 的核心思想在于通过 “解耦视觉编码器”(理解 / 生成),同时保留统一的 Transformer 语言模型,实现多模态理解与生成任务的兼容与协同。
3.1 架构
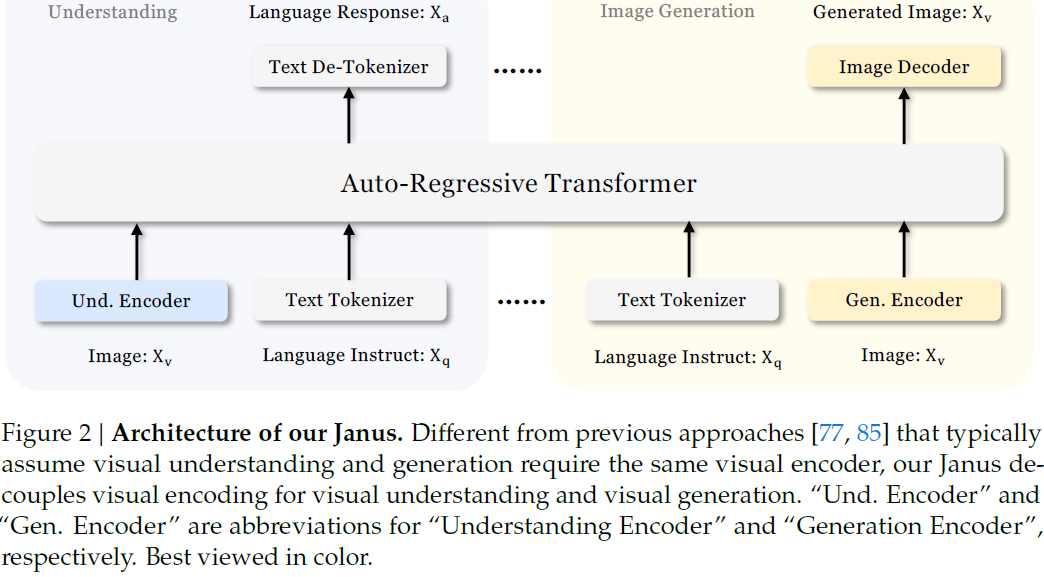
Janus 的整体架构如图 2 所示,包含以下主要组成部分:
-
文本理解:使用 LLM 内置 tokenizer 将文本转为离散 ID,并生成对应的特征表示。
-
多模态理解:利用 SigLIP 编码器提取图像高维语义特征,展平成一维序列后通过理解适配器(understanding adaptor)映射至 LLM 输入空间。
-
图像生成:使用 VQ tokenizer 将图像编码为离散 ID,经过生成适配器(generation adaptor)处理后输入 LLM。图像生成预测通过随机初始化的生成头完成。
以上特征序列被拼接成统一的多模态输入,输入至一个共享的自回归Transformer。文本生成任务使用 LLM 的内建头,图像生成使用独立的预测头。整个架构不依赖专门的注意力 mask 设计,保持简洁。
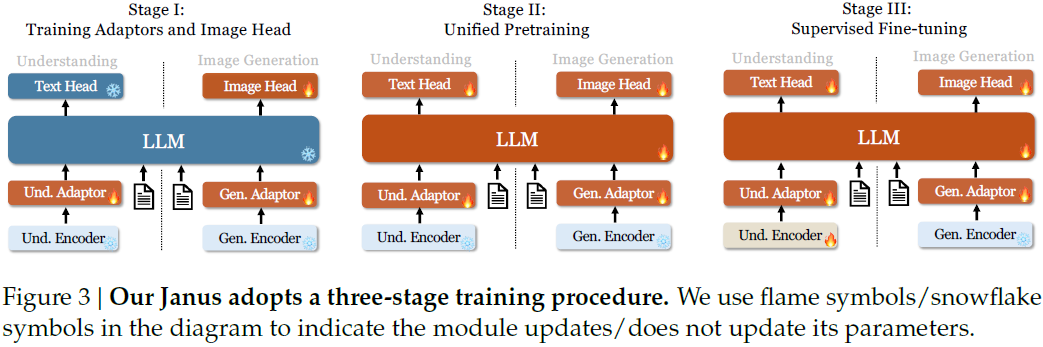
3.2 训练流程
Janus 采用三阶段训练策略,具体如下(如图 3 所示):
- 阶段 I:训练适配器与生成头。冻结视觉编码器与 LLM,仅训练理解适配器、生成适配器和图像生成头。目的是建立图文之间的嵌入关联,并初步具备图像生成能力。
- 阶段 II:统一预训练。解冻 LLM,并混合三类数据(文本、理解、生成)进行预训练。图像生成训练先使用 ImageNet-1k 建立基础像素建模能力,再引入开放域文本图像数据增强开放场景的生成能力。
- 阶段 III:有监督微调。使用指令数据进行多轮对话能力增强,训练时仅冻结生成编码器。采用融合文本、图文和图像生成数据的混合任务训练,提升任务通用性。
3.3 训练目标
Janus 作为自回归模型,采用标准的交叉熵损失函数进行训练:

其中 P_θ (⋅) 为由模型参数建模的条件概率。对于理解任务,仅在文本 token 上计算损失;对于生成任务,仅在图像 token 上计算。训练过程中不区分任务权重,保持整体设计的简洁性。
3.4 推理
推理阶段采用标准的 “下一个token预测” 机制:
-
文本/多模态理解:按顺序采样生成token。
-
图像生成:引入无分类引导(CFG)机制提升生成质量:
![]()
其中 l_c 为条件 logit,l_u 为非条件 logit,默认 scale s = 5。
3.5 可扩展性
Janus 架构的核心优势之一是良好的可扩展性:
1)多模态理解扩展:
-
可替换更强视觉编码器如 EVA-CLIP、InternViT;
-
动态高分辨率处理如 LLaVA-v1.5 的动态分辨率技术;
-
图像 token 压缩方法如 pixel shuffle,降低计算开销。
2)图像生成扩展:
-
使用更细粒度编码器如 MoVQGan;
-
融入视觉生成专用 loss 如 diffusion loss;
-
结合自回归与并行预测方法,减缓生成误差累积。
3)支持更多模态:
-
可添加额外编码器处理如 3D 点云、触觉信号或 EEG 脑电信号;
-
经适配器映射后统一输入 LLM,提升模型通用性。
4. 实验
4.1 实现细节
【注:Janus 与以 LLaVA 为代表的 VLM 具有相似的框架和训练范式:视觉编码器,语言模型,连接器(或投影器,本文称之为适配器,使用与 LLaVA-1.5 相同的两层 MLP)
(2023|NIPS,LLaVA,指令遵循,预训练和指令微调,Vicuna,ViT-L/14,LLaVABench)视觉指令微调
(2024|CVPR,LLaVA-1.5,LLaVA-1.5-HD,CLIP-ViT-L-336px,MLP 投影,高分辨率输入,组合能力,模型幻觉)通过视觉指令微调改进基线
(2024,LLaVA-NeXT(LLaVA-1.6),动态高分辨率,数据混合,主干扩展)
】
语言模型:采用 DeepSeek-LLM(1.3B),最大序列长度为 4096。
视觉编码器:
-
理解:使用 SigLIP-Large-Patch16-384。
-
生成:使用 VQ tokenizer(codebook 大小为 16384,图像下采样比例为 16)。
-
适配器:理解与生成适配器均为两层 MLP。
图像处理:
-
输入统一为 384×384 分辨率。
-
图文任务中按长边缩放,短边填充背景色(RGB: 127,127,127);
-
生成任务中短边缩放,长边裁剪。
训练平台:使用 HAI-LLM 分布式框架,在 16 台 A100(40GB)GPU 的集群上训练 7 天。
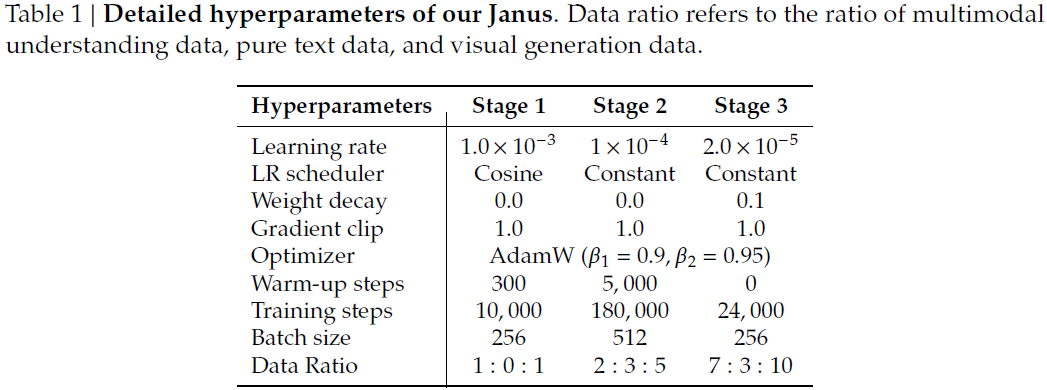
训练优化:
-
阶段一(适配器训练):10K 步,LR = 1e-3;
-
阶段二(预训练):180K 步,LR = 1e-4;
-
阶段三(微调):24K 步,LR = 2e-5;
-
所有阶段均使用 AdamW 优化器,gradient clip 为 1.0。
4.2 数据设置
阶段一:
-
多模态理解:ShareGPT4V(1.25M 图文对);
-
图像生成:ImageNet-1k(1.2M 张图像)。
阶段二(统一预训练):
-
文本数据:DeepSeek-LLM 的预训练文本;
-
图文数据:
-
维基百科 HowTo、WIT;
-
图像描述数据集(如 COCO、OpenImages、SBU 等);
-
表格与图表数据:DeepSeek-VL;
-
图像生成数据:多种图文对数据集 + 2M 自建数据。
-
-
采样策略:前期更多 ImageNet 数据(前 120K 步),后期替换为复杂场景(后 60K 步)。
阶段三(监督微调):
-
文本理解:OneVision 数据;
-
多模态理解:多种指令微调数据;
-
图像生成:部分阶段二数据 + 4M 自建图文数据。
4.3 评估设置
多模态理解评估:使用 8 个公开基准:VQAv2、GQA、POPE、MME、SEED、MMB、MM-Vet、MMMU。
视觉生成评估:
-
图像质量:MSCOCO-30K、MJHQ-30K,采用 FID 指标;
-
图文一致性:GenEval,测试模型对描述的精准生成能力。
4.4 与现有方法比较
4.4.1 多模态理解
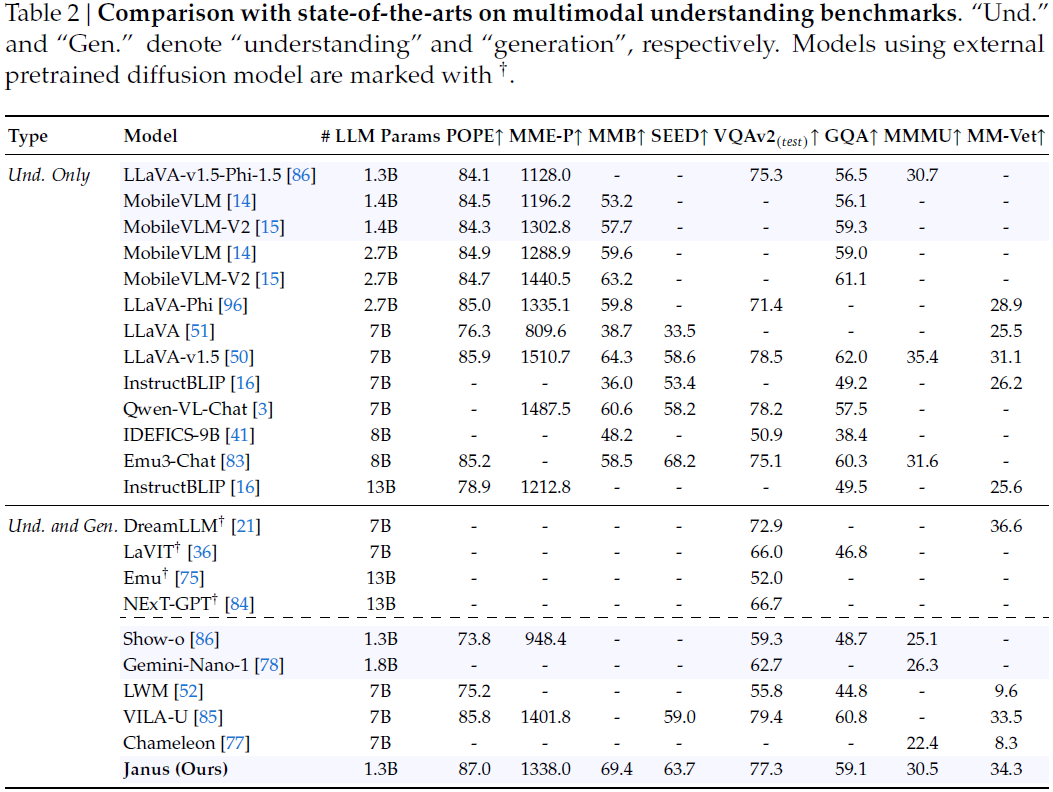
Janus 在多个基准上超过同规模和更大模型,尤其在 MMB、SEED、MM-Vet 等上显著领先。
4.4.2 视觉生成
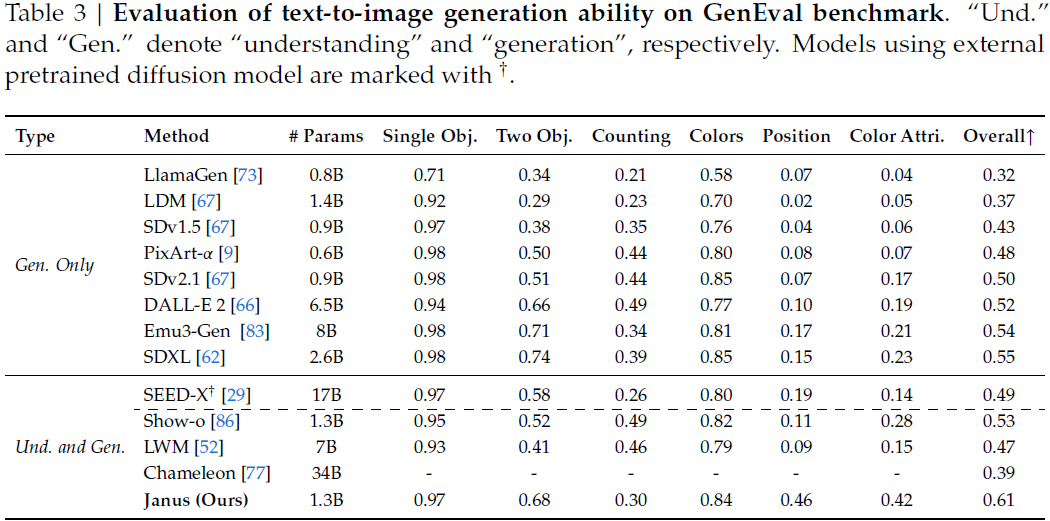
GenEval 准确率(Overall):Janus 超越专用生成模型 SDXL 与统一模型 Show-o,展现强指令遵循能力。
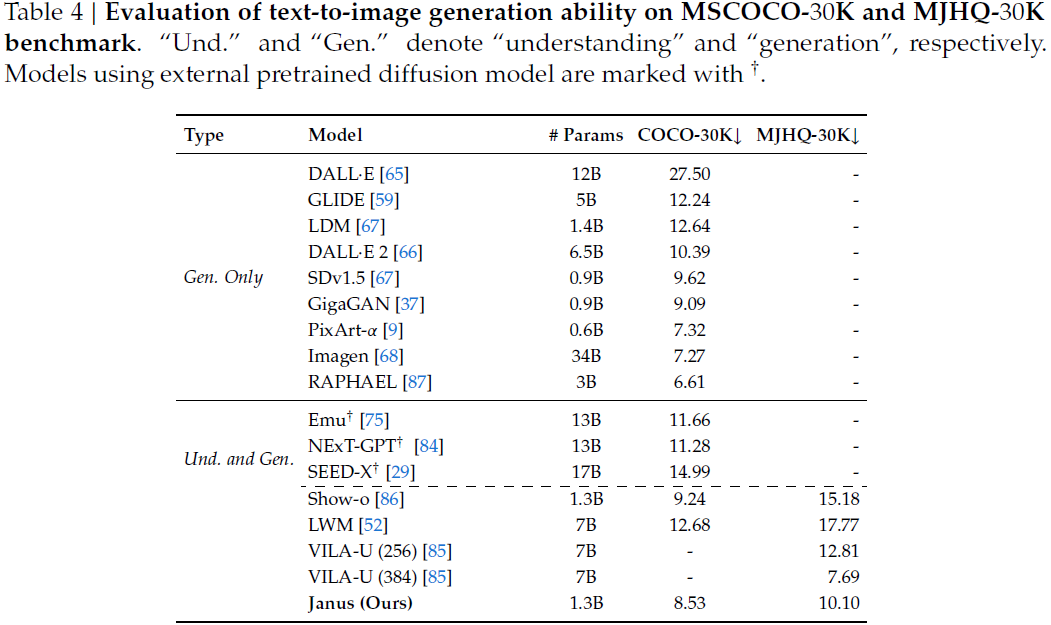
COCO / MJHQ 的 FID(↓ 越好):Janus 生成图像的质量在统一模型中居首,接近或超过某些专用模型。
4.5 消融实验
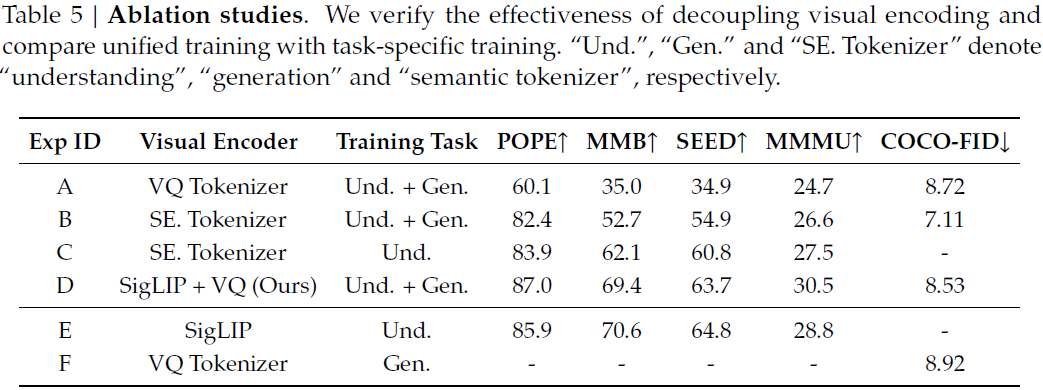
单一编码器存在显著性能折中;
解耦设计(D)在理解与生成上均表现更优;
统一训练的结果(D)与单任务训练(E / F)性能相近,显示 Janus 具备通用能力。
4.6 定性结果

图像生成示例(图 4):
-
Janus生成的图像细节丰富,贴合文本指令,优于SDXL与LlamaGen;
-
展现良好的空间结构与语义一致性。
图文理解示例(图 5、图 9。见原论文):
-
在 Meme、图表、LaTeX 公式、艺术图像等不同类型输入上,Janus 均能精准理解;
-
相比 Chameleon、Show-o,其文本解释更完整、表述更贴近语境。
5. 结论
本文提出的 Janus 模型通过解耦视觉编码器,有效缓解多模态理解与生成间的表示冲突,提升了统一多模态建模的能力。实验表明,Janus 在多项基准任务中均表现出领先性能,并具备良好的扩展性。其简单、统一且灵活的架构为下一代多模态通用模型的发展提供了新思路。
论文地址:https://arxiv.org/abs/2410.13848
项目页面:https://github.com/deepseek-ai/Janus
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)