手把手教你用DeepSeek+SpringAI搭建RAG知识库,解锁AI应用新姿势!
它能够将信息检索与文本生成相结合,在用户查询时,首先从海量知识库中检索出相关信息,然后利用生成模型生成更精准、更易懂的答案,极大地提升了知识库的智能化水平。核心思想是,我们通过用户的提问从向量数据库中查询相似的,再将查询出来的内容与问题一起给到大模型,来检索增强生成。作为国内领先的AI技术提供商,其强大的自然语言处理能力和海量数据积累,为构建RAG知识库提供了坚实的技术基础。生成答案:最后,AI把
还在为构建企业专属知识库而烦恼?DeepSeek携手SpringAI,强强联合,手把手教你搭建RAG知识库,解锁AI应用新姿势,让知识管理更智能、更高效!
在信息爆炸的时代,如何高效地管理和利用海量知识,成为企业提升竞争力的关键。传统的知识库系统往往存在检索效率低、信息更新不及时等问题,难以满足企业日益增长的知识管理需求。
RAG(Retrieval-Augmented Generation) 作为一种新兴的AI技术,为知识库的构建带来了革命性的变革。它能够将信息检索与文本生成相结合,在用户查询时,首先从海量知识库中检索出相关信息,然后利用生成模型生成更精准、更易懂的答案,极大地提升了知识库的智能化水平。
DeepSeek 作为国内领先的AI技术提供商,其强大的自然语言处理能力和海量数据积累,为构建RAG知识库提供了坚实的技术基础。而 SpringAI 作为一款开源的AI应用框架,则能够帮助开发者快速构建和部署AI应用,极大地降低了开发门槛。
RAG工作原理
简单来说,RAG就像一个超级聪明的助手。它不仅靠自己的“知识储备”回答问题,还能从外部信息库中找到最相关的资料来辅助回答。想象一下,你问AI:“最近的GIS技术有哪些突破?”如果AI只凭过去的记忆回答,可能不够全面。但有了RAG,它会先去翻阅最新的文章和报告,找到相关内容,再结合这些信息给出答案。
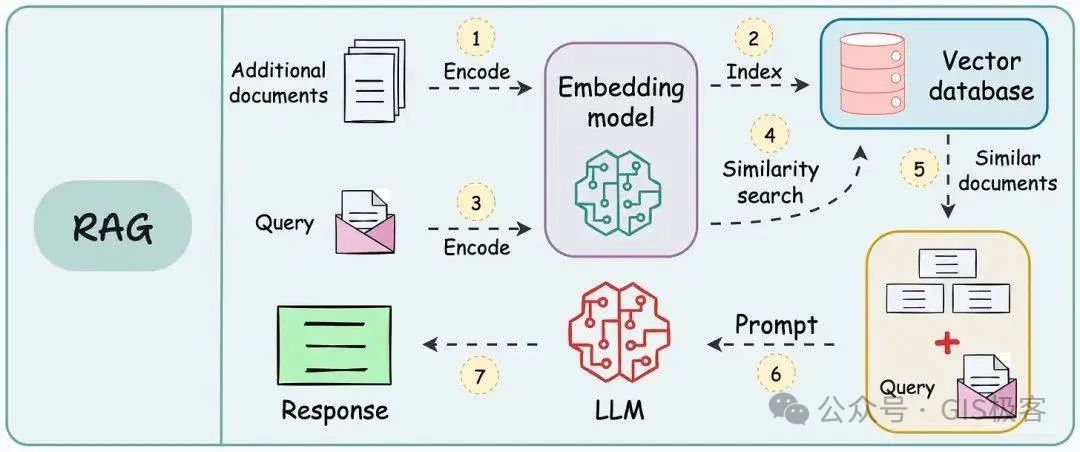
RAG的具体工作流程可以拆成三个步骤:
-
存储信息:把大量的文档(比如文章、报告)转化成一种特殊的数学形式——向量,存起来备用。
-
匹配问题:当你提出问题时,AI会把问题也变成向量,然后在信息库中找到与之最匹配的内容。
-
生成答案:最后,AI把这些匹配的内容和你的问题一起交给大语言模型(LLM),生成一个更准确、更贴切的回答。
DeepSeek+SpringAI,强强联合,手把手教你搭建RAG知识库:
一、环境准备
1、基础环境安装
-
安装DeepSeek模型《DeekSeek本地化部署初体验》
-
安装PGVector向量数据量《轻松搞定PGVector安装部署,开启AI私有库构建之旅》
2、开发环境与版本
-
JDK 17
-
Eclipse 4.34.0
-
Maven 3.9.9
-
SpringBoot 3.3.9
-
SpringAI 1.0.0-M6
二、搭建框架
在Eclipse中新建maven项目,添加依赖配置:
引入SpringBoot配置
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.9</version></parent>
我们以ollama搭配deepseek-14b作为大模型基座
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId></dependency>
配置ollama的deepseek模型与embedding
spring:ai:ollama:base-url: http://localhost:11434chat:options:model: deepseek-r1:14btemperature: 0.7embedding:options:model: nomic-embed-text:latest
添加pgvector向量数据库依赖
<!--spring ai pgvector 的向量数据库--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId></dependency>
配置pgvector向量数据库对应参数
spring:ai:vectorstore:pgvector:table-name: vector_storeinitialize-schema: trueindex-type: hnswdimensions: 768datasource:username: postgrespassword: postgresurl: jdbc:postgresql://localhost:5432/vectordb
添加文档分割的依赖
<!--Tika (DBF, DOCX, PPTX, HTML...)--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId></dependency>
三、直接上代码
1、将我们准备好的文档切割后写入向量库
@RestController@RequestMapping("rag")@AllArgsConstructorpublic class RagController {@Autowiredprivate VectorStore vectorStore;public void addVectorStore() {File documentation = new File("D:\\北京大学-DeepSeek应用场景中需要关注的十个安全问题和防范措施.pdf");TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(new FileSystemResource(documentation));TokenTextSplitter splitter = new TokenTextSplitter(1000, 200, 10, 400, true);List<Document> documents = splitter.apply(tikaDocumentReader.get());documents.forEach(document -> {vectorStore.add(List.of(new Document(document.getFormattedContent())));});}}
运行后,查看数据库
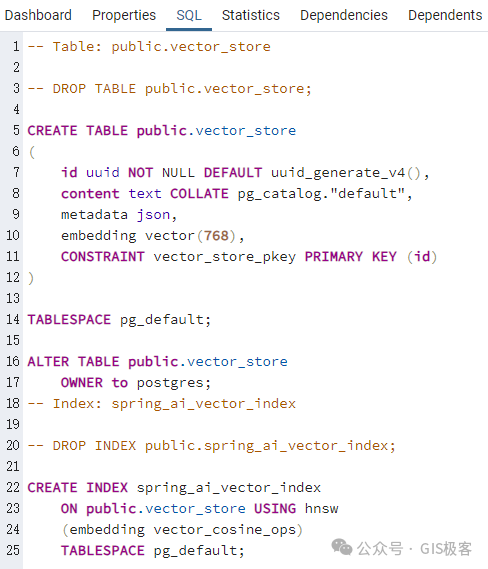
查看数据表记录
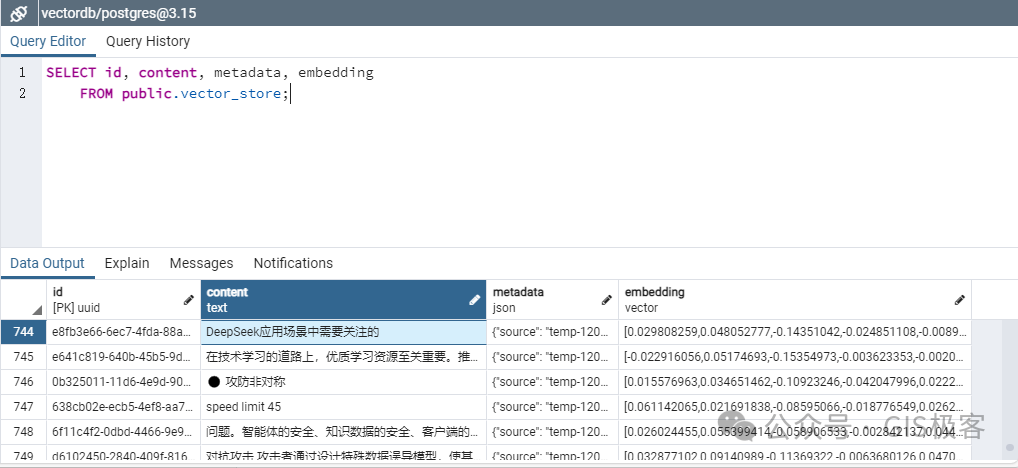
至此我们的文档内容就已经存在向量数据库了。
2、开始调大模型!!!
核心思想是,我们通过用户的提问从向量数据库中查询相似的,再将查询出来的内容与问题一起给到大模型,来检索增强生成。
@Autowiredprivate ChatModel chatModel;@GetMapping("/chat")public String chat(@RequestParam String question) {List<Document> documents = vectorStore.similaritySearch(SearchRequest.builder().query(question).topK(1).build());String prompt = """你是一个智能助手,你可以根据下面搜索到的内容回复用户### 用户的问题是%s###具体内容%s""";prompt= String.format(prompt, question, documents.get(0).getText());Prompt prompt1 = new Prompt(prompt);ChatResponse call = chatModel.call(prompt1);String result = call.getResult().getOutput().getText();System.out.println(result);return result;}
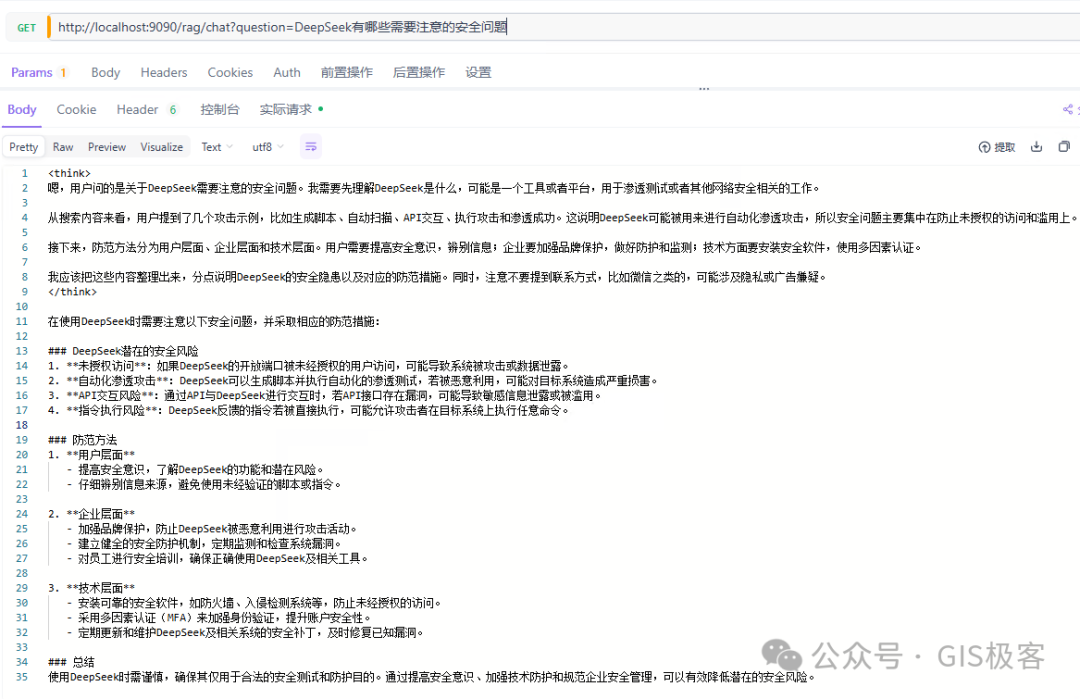
请求一个接口我们看看效果
http://localhost:9090/rag/chat?question=DeepSeek有哪些需要注意的安全问题
就这样一个简单的RAG代码就写完了,让我们看看效果
四、DeepSeek+SpringAI,优势尽显
高效检索:DeepSeek强大的自然语言处理能力,能够快速精准地从海量知识库中检索出相关信息。
智能生成:结合生成模型,能够生成更精准、更易懂的答案,提升用户体验。
灵活部署:SpringAI框架支持多种部署方式,能够满足不同企业的需求。
开源免费:SpringAI框架开源免费,降低了开发成本。
五、结 语
DeepSeek+SpringAI,为企业构建RAG知识库提供了一站式解决方案,助力企业实现知识管理的智能化升级。还在等什么?快来体验吧!
更多学习资料,请关注公众号【GIS极客】,或者加微信【eryeiscool】进技术交流群!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)