SuperCLUE:中文大模型基准测评2025年3月报告
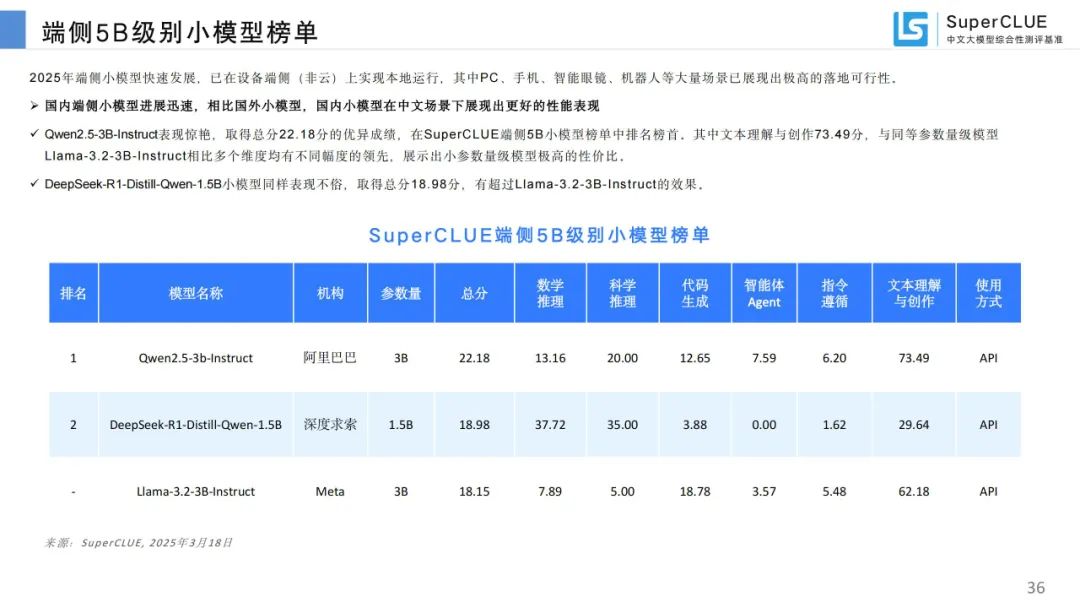
端侧 5B 级别小模型榜单:国内端侧小模型进展迅速,Qwen2.5 - 3B - Instruct 和 DeepSeek - R1 - Distill - Qwen - 1.5B 表现出色。10B 级别小模型榜单:DeepSeek - R1 - Distill - Qwen - 7B 和 Gemma - 2 - 9b - it 分列国内外榜首,国内 10B 以内模型性价比高。基础模型总榜:国内头部
报告由 SuperCLUE 团队发布,对中文大模型进行了全面测评与分析,涵盖关键进展、测评体系、结果分析及 DeepSeek 系列模型深度剖析等内容。
2025 年度关键进展及趋势
-
大模型关键进展:自 ChatGPT 发布,AI 大模型历经准备期、跃进期、繁荣期和深化期。海外如 OpenAI 发布 Sora、GPT - 4o 等,国内多模态领域发展迅速,通用模型持续更新,开源生态活跃。
-
中文大模型全景图:包含通用闭源、通用开源、多模态等多种类型模型,在各行业广泛应用。
-
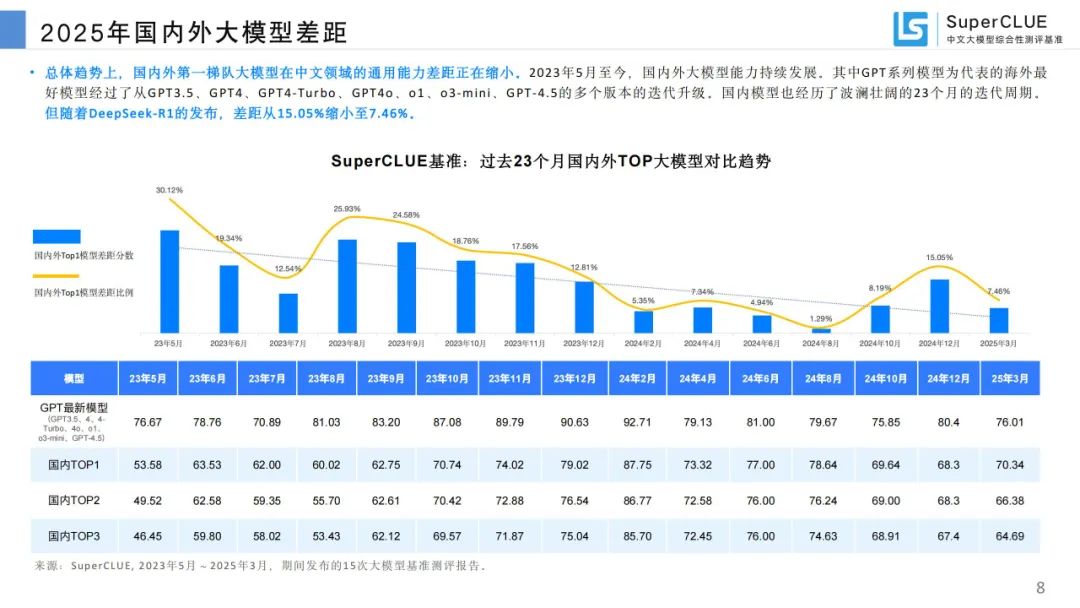
国内外大模型差距:国内外第一梯队大模型在中文领域通用能力差距缩小,随着 DeepSeek - R1 发布,差距从 15.05% 缩小至 7.46%。
年度通用测评介绍
-
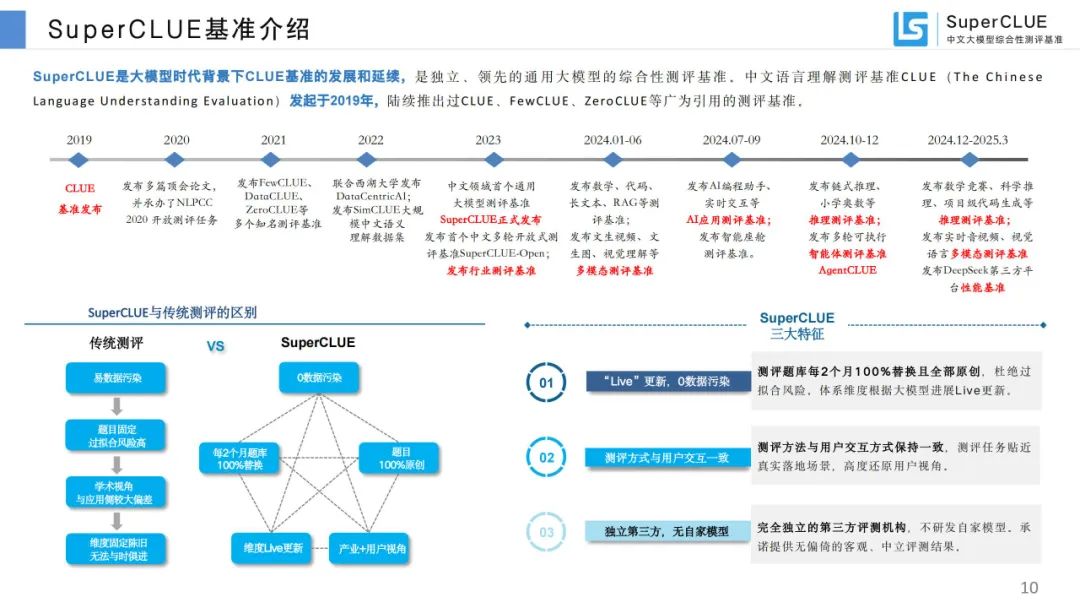
SuperCLUE 基准介绍:是 CLUE 基准的发展延续,具有 “Live” 更新、测评方式与用户交互一致、独立第三方等特征。
-
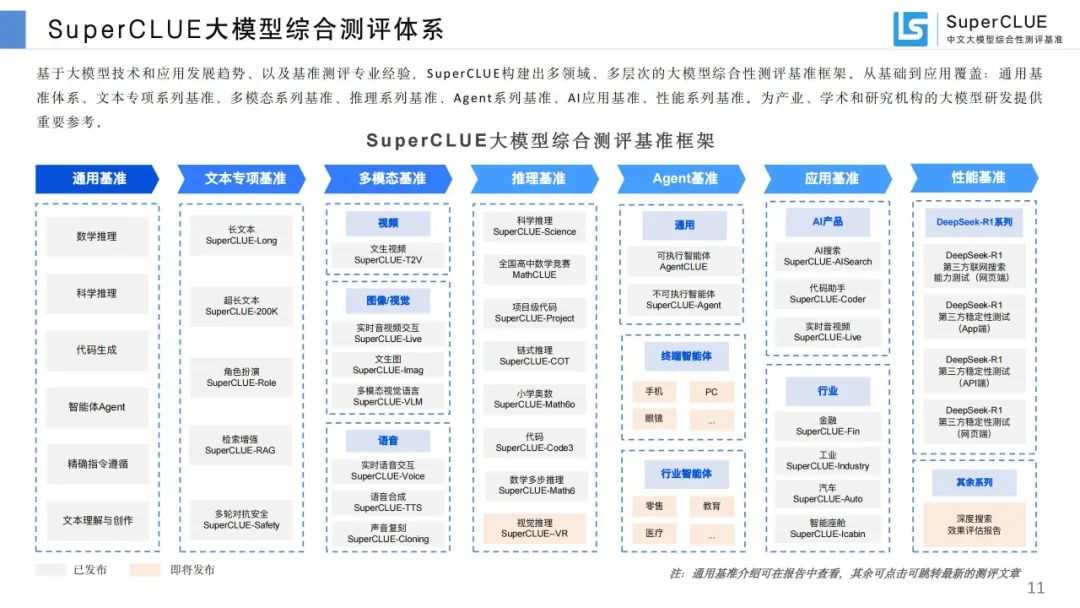
大模型综合测评体系:构建多领域、多层次测评框架,涵盖通用、文本、多模态、推理等系列基准。
-
通用测评基准数据集及评价方式:聚焦通用能力测评,由数学推理、科学推理等六大维度构成,题目为原创新题,采用多种评价方式。
-
各维度测评说明及示例:对六大维度的测评内容、方法、示例及评价标准详细说明。
-
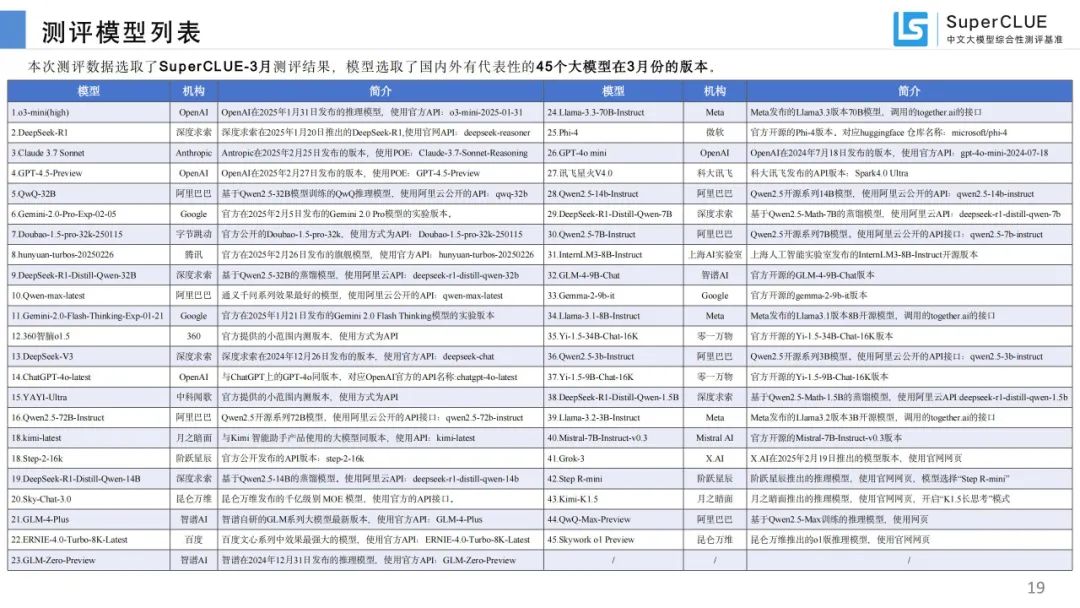
测评模型列表:选取国内外 45 个有代表性大模型 3 月份版本进行测评。
总体测评结果与分析
-
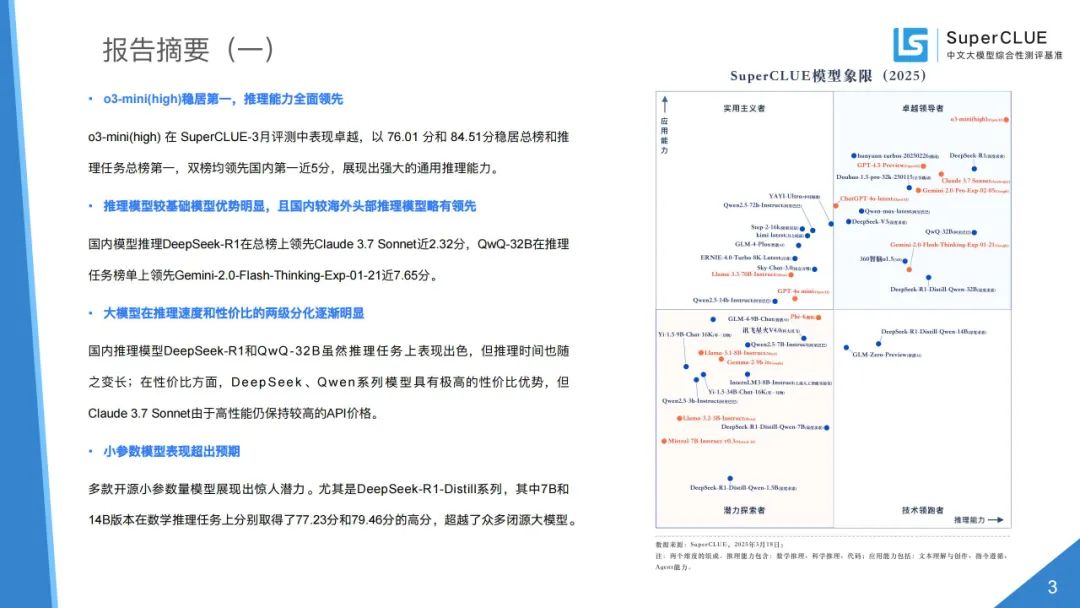
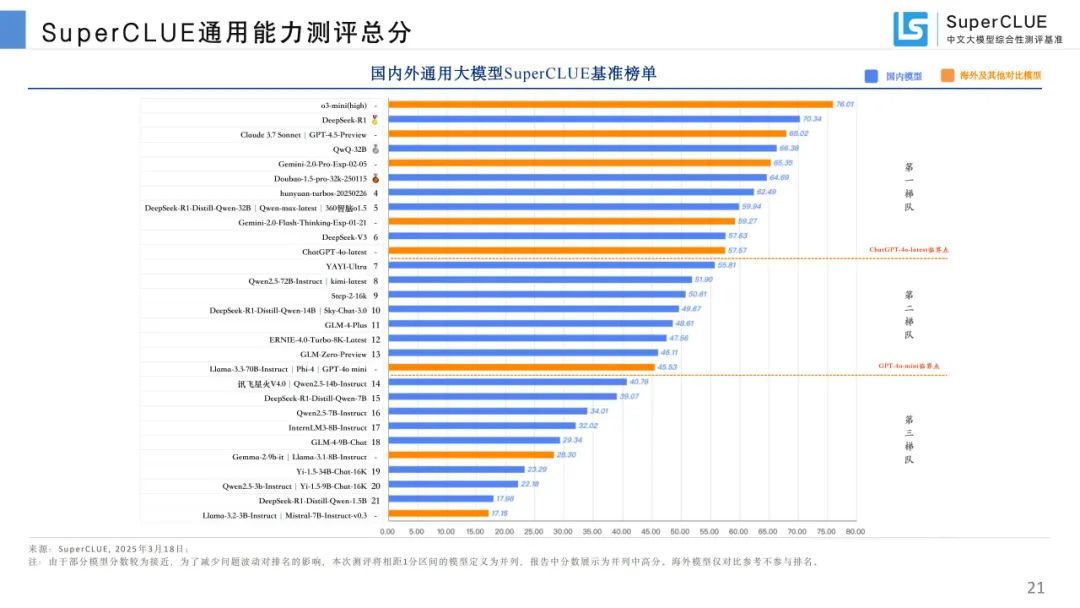
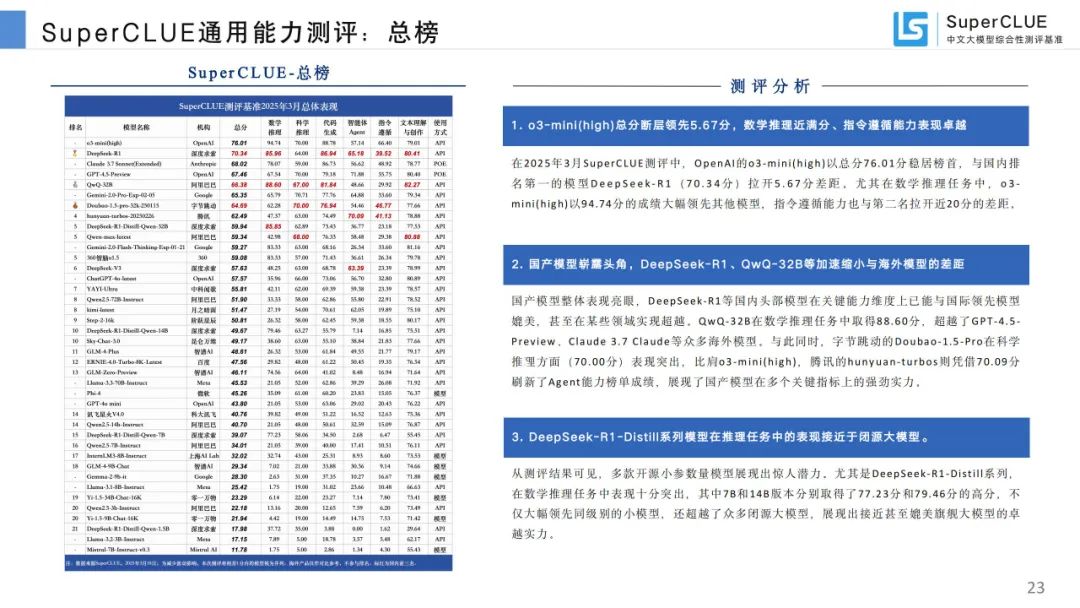
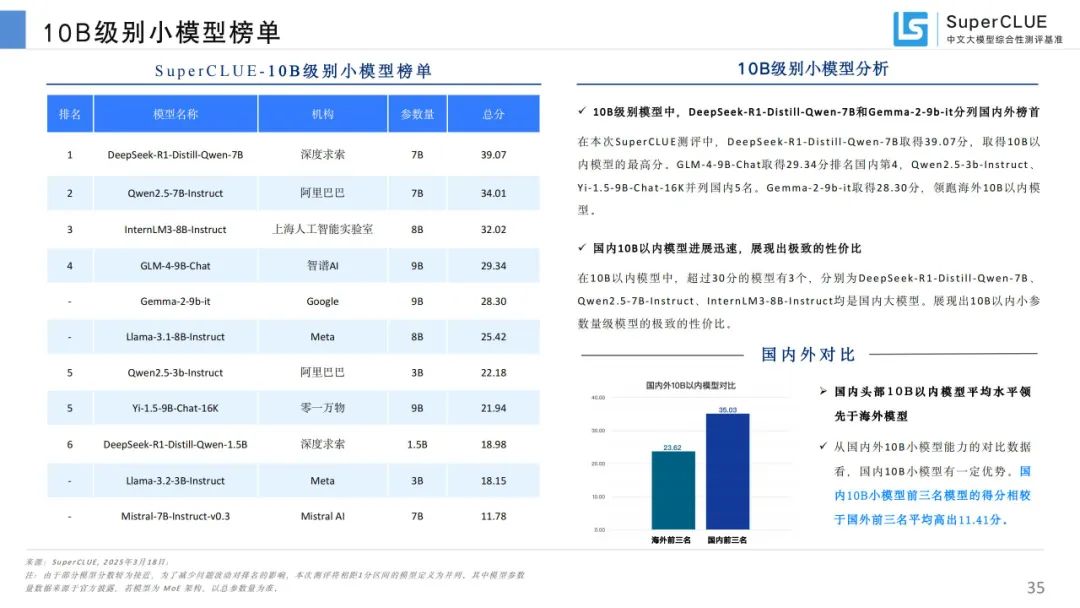
通用能力测评总榜:o3 - mini (high) 总分 76.01 分稳居榜首,国产模型表现亮眼,DeepSeek - R1 等与国际领先模型差距缩小。
-
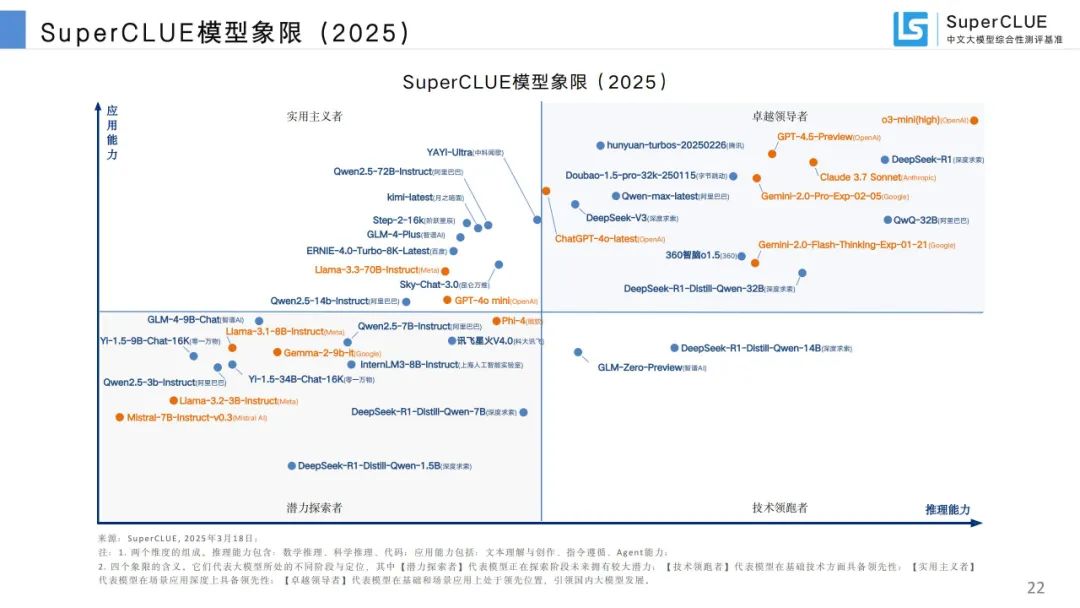
模型象限:根据推理和应用能力划分四个象限,展示各模型所处阶段与定位。
-
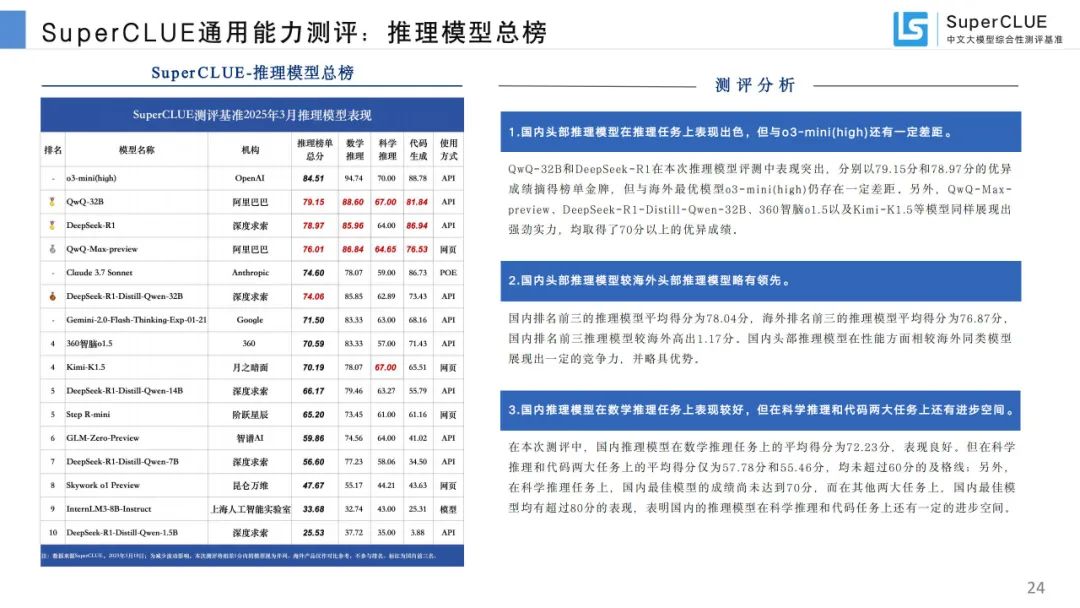
推理模型总榜:QwQ - 32B 和 DeepSeek - R1 表现突出,但与 o3 - mini (high) 有差距,国内头部推理模型较海外略有领先。
-
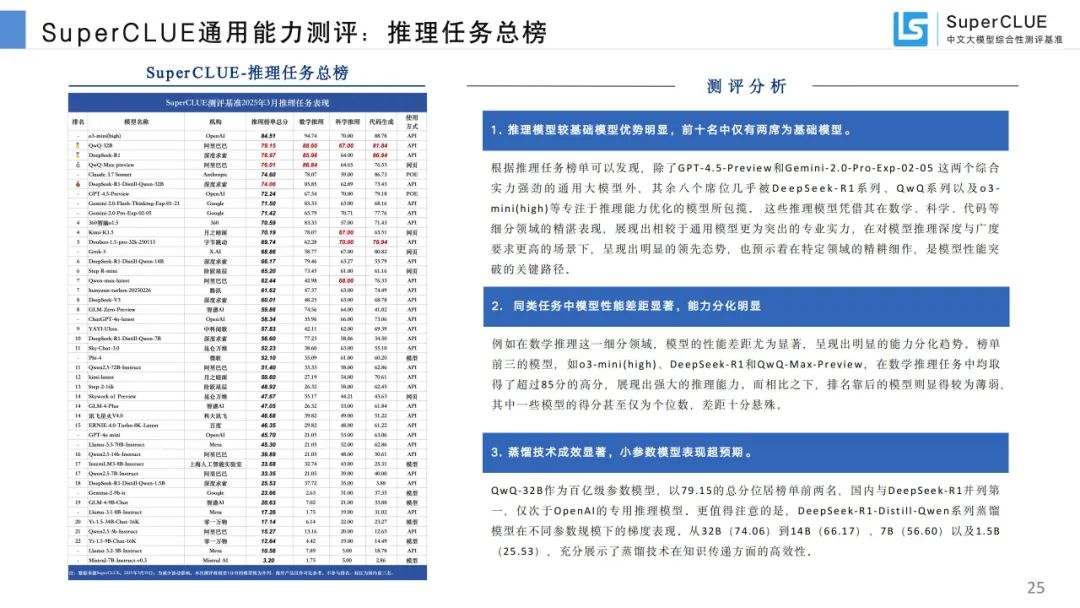
推理任务总榜:推理模型优势明显,同类任务模型性能差距大,蒸馏技术成效显著。
-
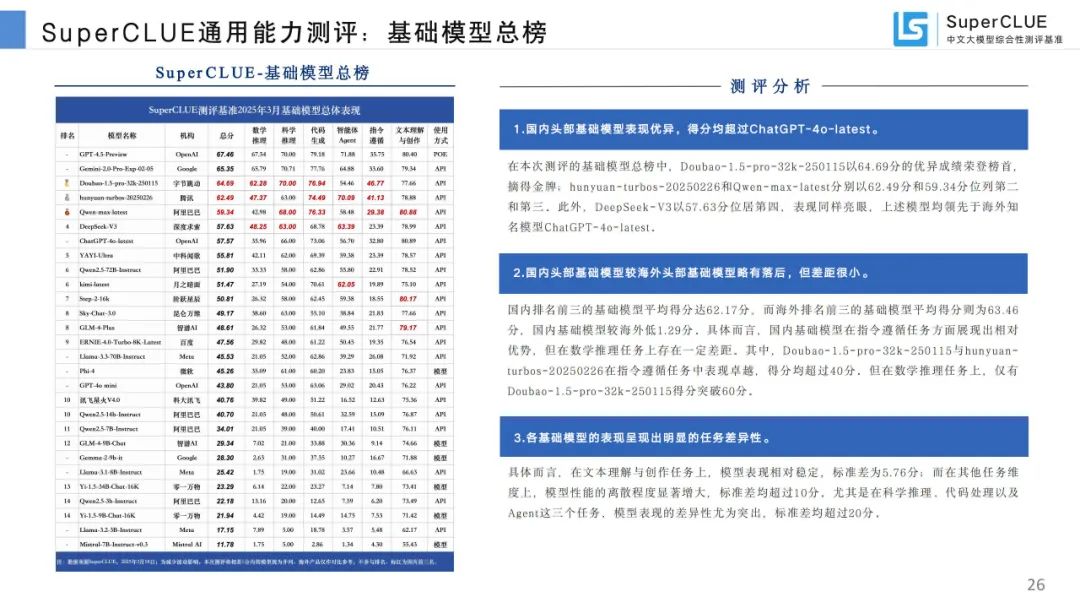
基础模型总榜:国内头部基础模型表现优异,较海外头部模型略有落后但差距小,各模型任务表现差异明显。
-
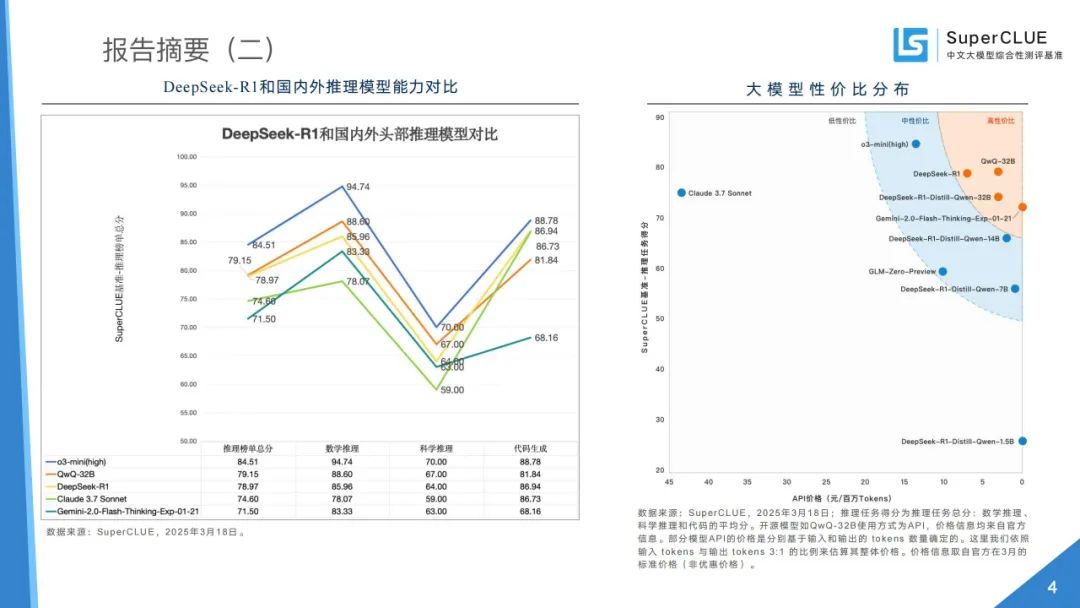
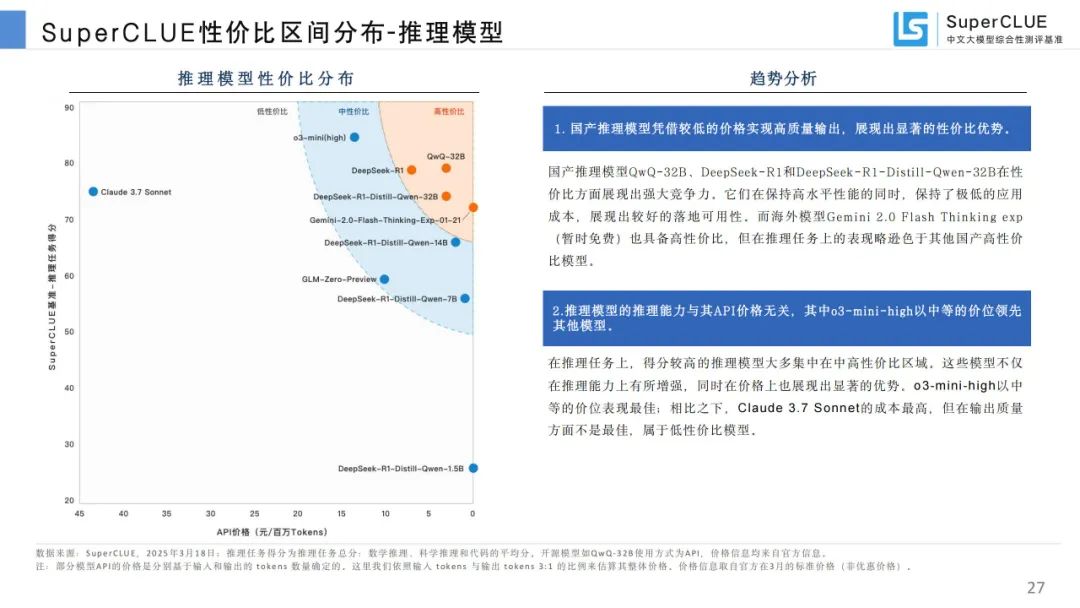
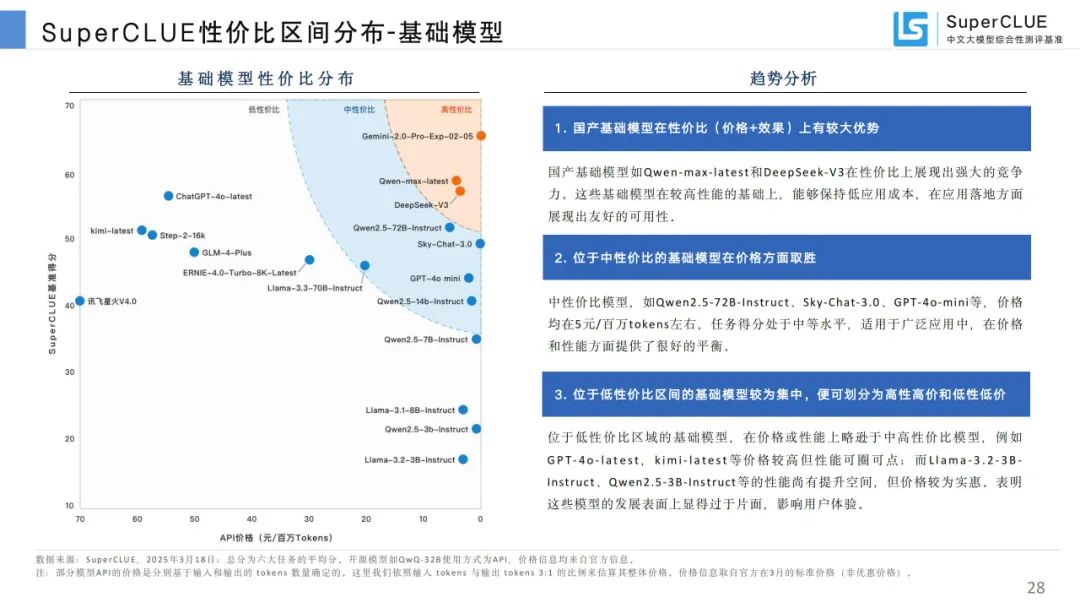
性价比区间分布:国产推理和基础模型在性价比上有优势,推理模型推理能力与 API 价格无关。
-
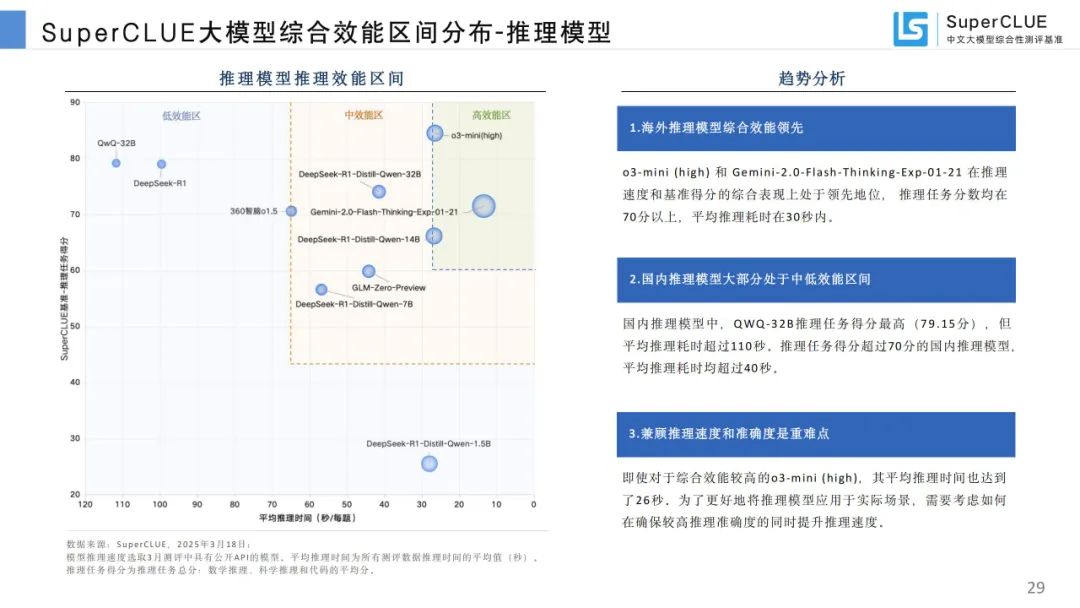
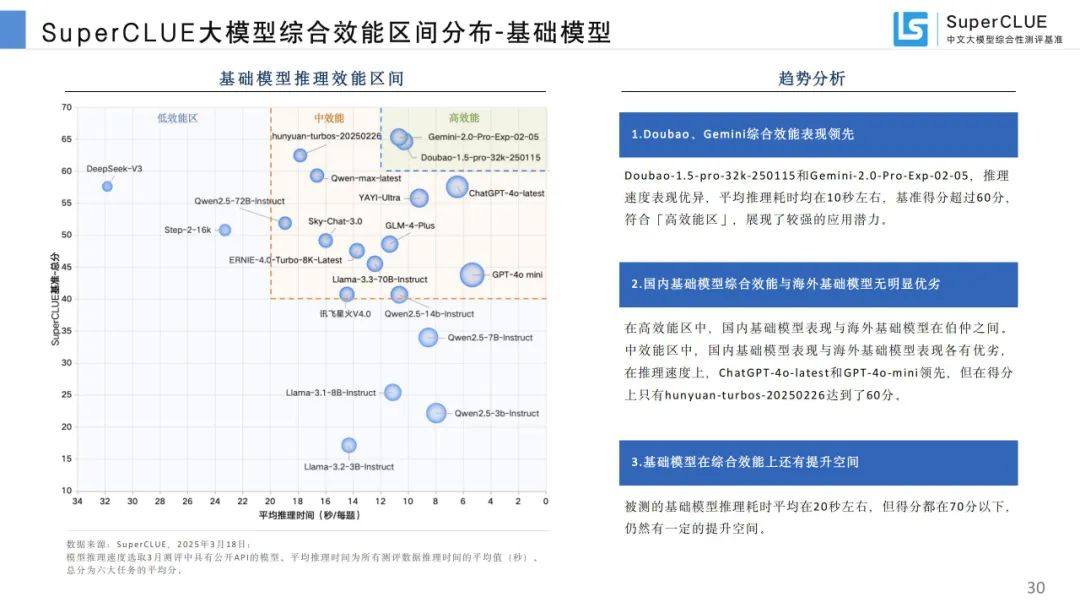
综合效能区间分布:海外推理模型综合效能领先,国内推理模型多处于中低效能区间,基础模型综合效能有提升空间。
-
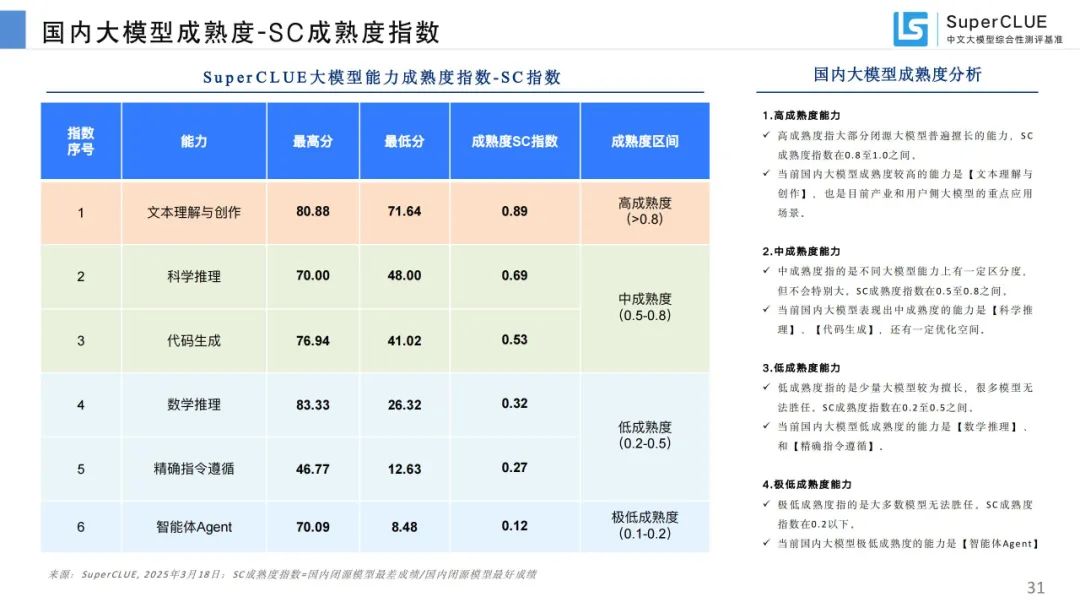
国内大模型成熟度:国内大模型在文本理解与创作上成熟度高,智能体 Agent 成熟度低。
-
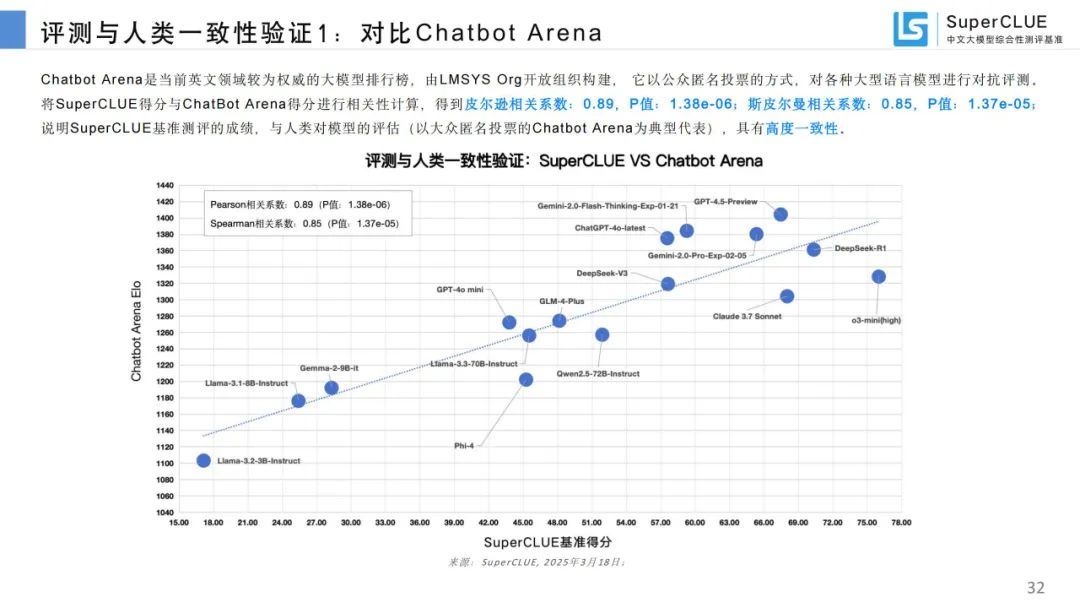
评测与人类一致性验证:SuperCLUE 基准测评成绩与人类评估高度一致,自动化评价可靠性高。
-
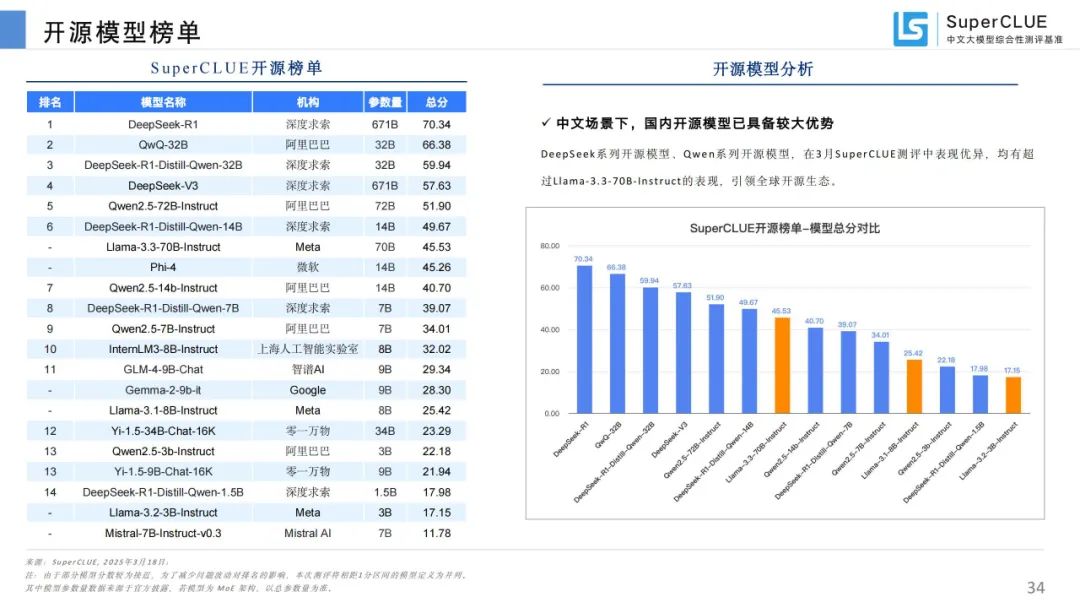
开源模型榜单:中文场景下国内开源模型优势大,DeepSeek 系列和 Qwen 系列表现优异。
-
10B 级别小模型榜单:DeepSeek - R1 - Distill - Qwen - 7B 和 Gemma - 2 - 9b - it 分列国内外榜首,国内 10B 以内模型性价比高。
-
端侧 5B 级别小模型榜单:国内端侧小模型进展迅速,Qwen2.5 - 3B - Instruct 和 DeepSeek - R1 - Distill - Qwen - 1.5B 表现出色。
DeepSeek 系列模型深度分析
-
DeepSeek - R1 及其蒸馏模型对比:DeepSeek - R1 在各维度领先,推理模型在总榜和推理任务榜单上分差较大,R1 - Qwen 蒸馏模型系列实用性较高。
-
DeepSeek - R1 和国内外推理模型能力对比:综合能力接近海外头部模型,数学推理和代码生成任务表现优异,科学推理相对薄弱。
-
DeepSeek - R1 第三方平台联网搜索能力测试(网页端):各平台整体表现差异大,基础检索能力优秀但分析推理能力弱,回复率高,平均耗时差异大。
-
DeepSeek - R1 第三方平台稳定性测试(网页端、App 端、API 端):不同平台稳定性差异显著,付费版优于免费版,国外付费平台在回复率和推理耗时方面有优势,国内付费平台准确率高。

















欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)