
基于vLLM本地部署企业级DeepSeek
本文介绍了如何利用 vLLM工具在本地部署 DeepSeek大模型,帮助企业搭建高效、安全的智能服务系统。通过 vLLM 的动态批处理和显存优化技术,充分发挥 DeepSeek 在自然语言处理上的强大能力,实现了低延迟、高吞吐的企业级私有化推理服务。这套方案不仅确保了数据隐私和系统高性能,还能灵活满足多场景应用需求,为企业的智能化转型提供了可靠支持。
vLLM框架是一个高效的大语言模型推理和部署服务系统
1、高效的内存管理:通过PagedAttention 算法,VLLM实现了对KV缓存的高效管理,减少了内存浪费,优化了模型的运行效率。
2、高吞吐量:VLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度 。
3、易用性:VLLM与HuggingFace 模型无缝集成,支持多种流行的大型语言模型,简化了模型部署和推理的过程。兼容 OpenAl的 API服务器。
4、分布式推理:框架支持在多 GPU环境中进行分布式推理,通过模型并行策略和高效的数据通信,提升了处理大型模型的能力。
5、开源共享:vLLM 由于其开源的属性,拥有活跃的社区支持,这也便于开发者贡献和改进,共同推动技术发展。
本文基于vLLM与Qwen 7B模型,整合LangChain、Faiss向量数据库及RAG技术的完整实践
1. 环境准备
1.1 硬件要求
- CPU:多核处理器,⽀持 x86_64 或 ARM 架构。
- 内存:⾄少 16 GB 内存,推荐 32 GB 或更⾼,因为 vLLM 会消耗⼤量内存。
- 显卡:如果使⽤ GPU 加速推理,推荐 NVIDIA 显卡(CUDA ⽀持),如 V100、A100 等。
1.2 软件要求
- 操作系统:推荐使用 Linux 系统,本文采用 Ubuntu24 版本
- Python 版本:Python 3.10 。
- CUDA 版本:如果使用 GPU 加速,确保 CUDA 版本与您的 GPU 驱动兼容,通常建议CUDA 11.2 以上版本(如果没有 GPU 资源可以忽略)。
- PyTorch:vLLM 依赖于 PyTorch,支持最新的 PyTorch 版本。
1.3 环境说明
vLLM 需要运行的环境比较严格,只⽀持:
- Linux 环境且带 GPU 显卡
- Linux 环境如果不带 GPU,则需要 CPU 支持以下指令集
- AVX512 或 **AVX2(**常见于 Intel/AMD 现代 CPU)
- Power9+ ISA(IBM Power 架构)
- ARMv8(ARM 架构)
2. CPU环境下安装 vLLM
由于 vLLM 默认并不⽀持 CPU 部署和推理,为了验证和演示 CPU 部署和推理过程,可以按照下面的步骤来操作。
CPU 模式下,编译打包 vLLM 框架(你没有看错:CPU 模式需要我们自己编译打包)
通过 CPU 模式,演示多种方式部署和推理 Qwen2 大模型(其他模型也⼀样)
vLLM 官网源代码地址:https://github.com/vllm-project/vllm
vLLM 支持目前主流大模型,详细官方查看:https://docs.vllm.ai/en/latest/models/supported_models.html
Qwen2 系列大模型在 vLLM ⽀持大模型之列,本⽂将详细介绍通过 vLLM 部署和推理 Qwen2-0.5B 大语言模型(之所以选择 0.5B 小尺⼨模型,纯粹下载更快、演示更方便,其他 vLLM 所⽀持的所有大模型,其部署和推理过程完全⼀样,大家可以根据自己的需要选择不同的模型)
2.1 vLLM 环境准备
vLLM目前只支持 Linux 操作系统(包括 Windows WSL 子系统),因此环境准备分为 2 部分:
- Linux 环境准备:我们的操作系统如果是 Linux 系统,那就无需其他操作;如果是Windows 操作系统,需要首先安装和配置好 WSL 子系统,本文用的是 Ubuntu24 版本。
- Python 研发环境准备:默认使用 Miniconda,需要安装和设置。
2.2 安装 Miniconda工具
Linux/Windows WSL 系统,可以通过命令行完成安装:
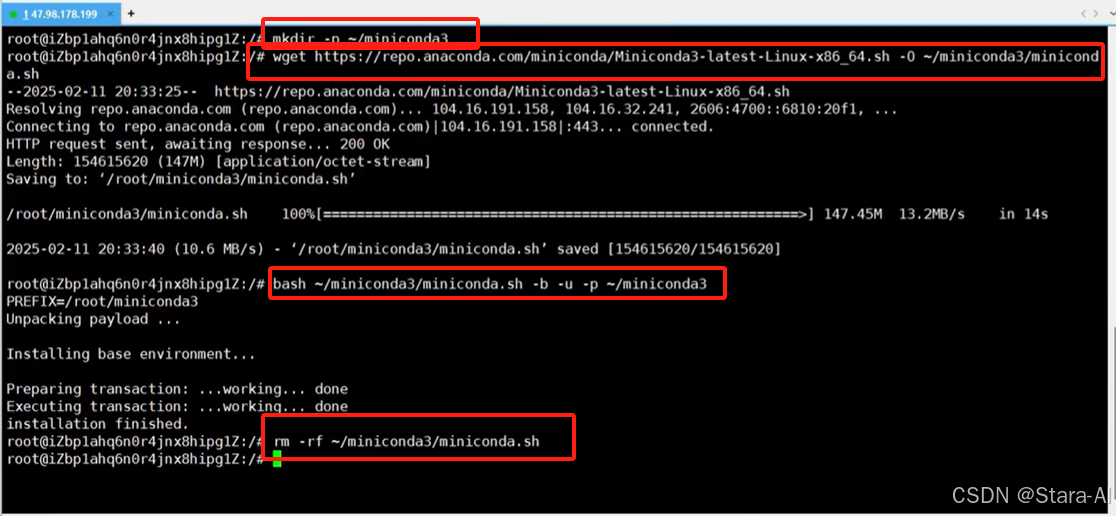
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
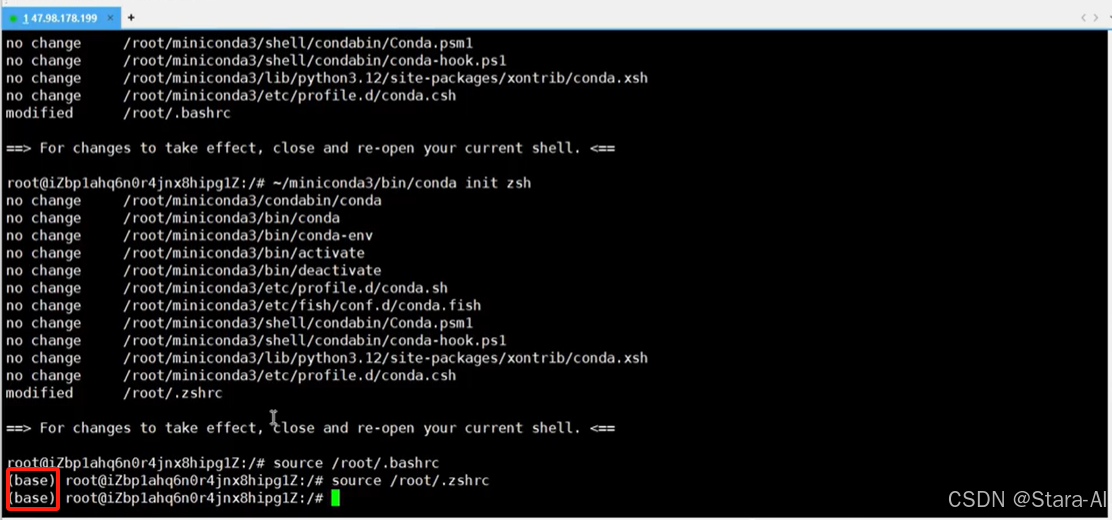
Shell 上下文激活 Miniconda 相关命令:
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
# root⽤⼾,所以路径是root,如果是⾮root,则直接替换⽬录⽤⼾⽬录就⾏
source /root/.bashrc
source /root/.zshrc
2.3 设置 Miniconda 国内镜像
配置镜像是为了提升依赖包下载速度,强烈建议进行配置。
Miniconda 配置文件路径:/root/miniconda3/.condarc,⼀般情况下配置文件不存在,
可以创建并初始化它:conda config --set show_channel_urls yes
然后打开配置文件,设置依赖包镜像渠道:
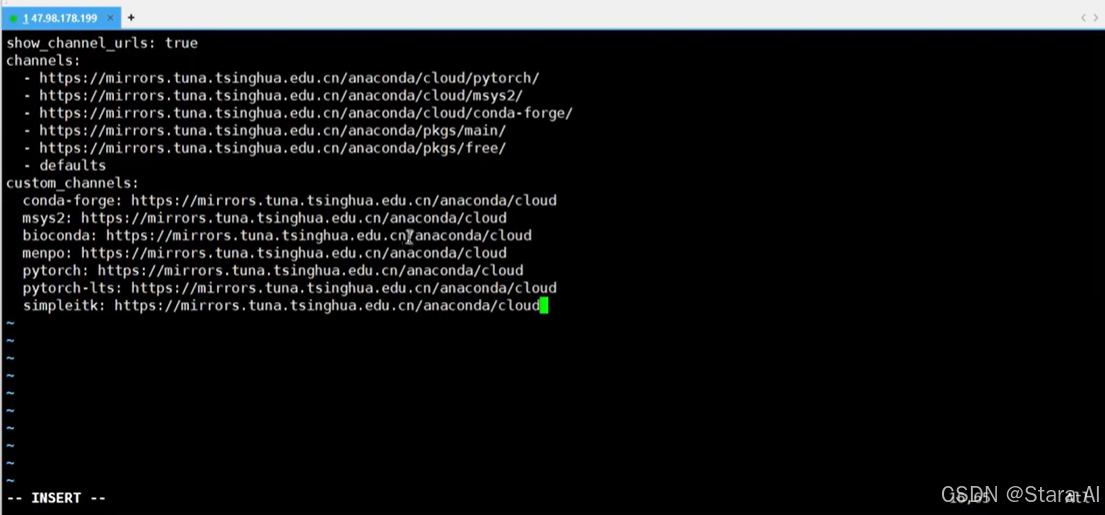
show_channel_urls: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
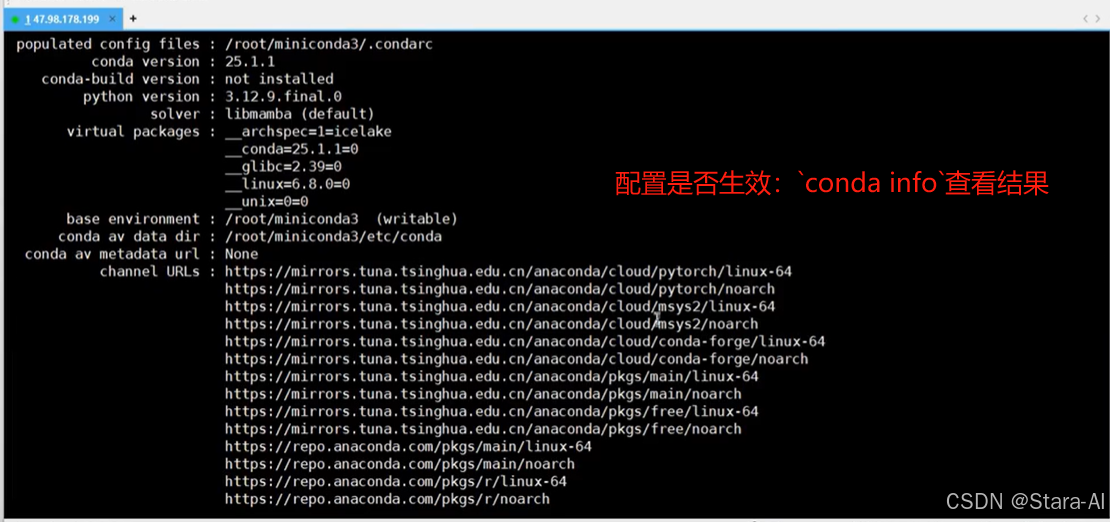
保存配置⽂件,我可以查看配置是否生效:conda info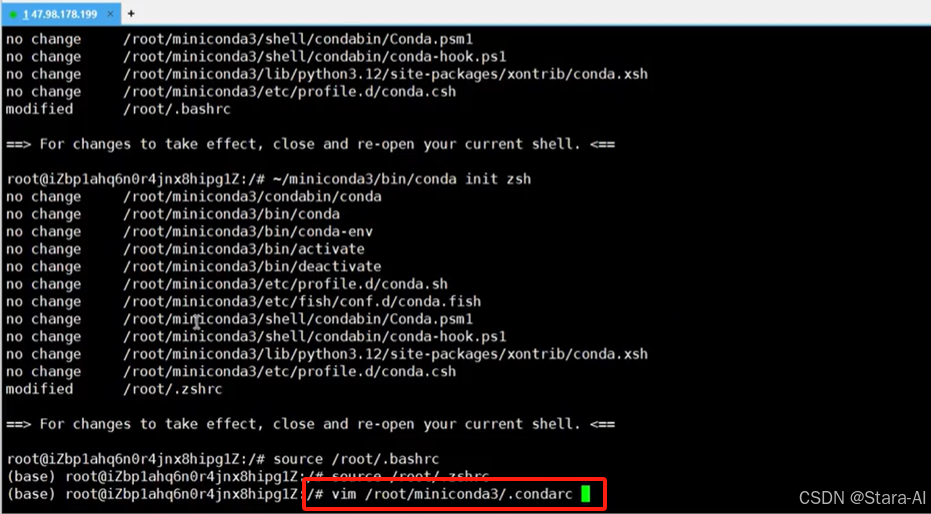
2.4 创建Python版本和虚拟环境
conda create --name vLLM python=3.10 -y
# 激活环境:
conda activate vLLM
特别注意:Python 版本号建议为 3.10!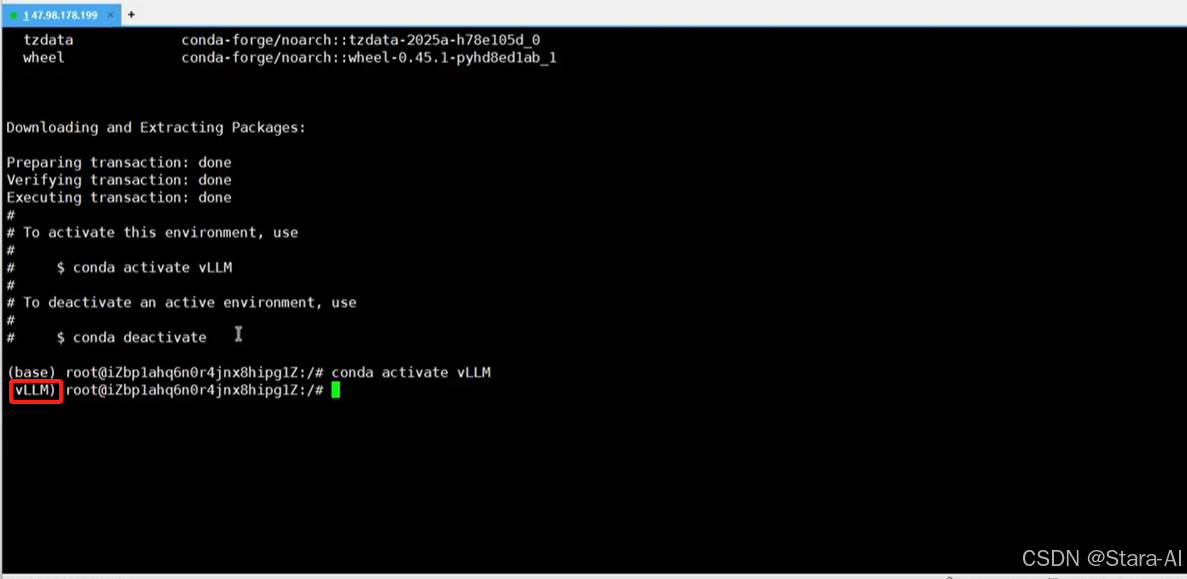
2.5 通过CPU编译安装vLLM
全新的 Ubuntu 环境下,先把所有 navidia 的驱动都卸载
sudo apt-get remove --purge '^nvidia-.*'
sudo apt-get remove --purge '^libnvidia-.*'
sudo apt-get remove --purge '^cuda-.*'
首先,下载 vLLM 源代码
安装⽬录:
/data/program/vllm-project
mkdir -p data/program
cd /data/program
git clone https://github.com/vllm-project/vllm.git vllm-project
然后,安装源代码 GCC 编译器:
sudo apt-get update -y
sudo apt-get install -y gcc-12 g++-12 libnuma-dev
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 10 --slave /usr/bin/g++ g++ /usr/bin/g++-12
接下来,需要安装 vLLM 便于打包的依赖:
cd /data/program/vllm-project
pip install --upgrade pip
pip install wheel packaging ninja "setuptools>=49.4.0" numpy
pip install -v -r requirements-cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu
最后,可以进行 vLLM 打包安装了:
cd /data/program/vllm-project
VLLM_TARGET_DEVICE=cpu python setup.py install
vLLM 打包安装完成 !
2.5.1 可能出现的错误
问题:git clone https://github.com/vllm-project/vllm.git,出现如下错误!
fatal: ⽆法访问 'https://github.com/vllm-project/vllm.git/':GnuTLS recv
error (-110): The TLS connection was non-properly terminated.
解决方案:
apt-get update
apt-get install gnutls-bin
git config --global http.sslVerify false
git config --global http.postBuffer 1048576000
问题 2:RuntimeError: Cannot find CMake executable
解决方案:
pip install cmake
问题 3:vLLM CPU backend requires AVX512, AVX2, Power9+ ISA or ARMv8 support
解决方案:
这个错误表明你正在尝试在 CPU 上运⾏ vLLM,但你的 CPU 不⽀持 vLLM 所需的指令集
(如 AVX512、AVX2、Power9+ ISA 或 ARMv8)。vLLM 是⼀个⾼性能的推理库,通常需要
现代 CPU 的特定指令集来加速计算。
检查 CPU 是否⽀持所需的指令集
vLLM 需要以下指令集之⼀:
- AVX512 或 AVX2(常⻅于 Intel/AMD 现代 CPU)
- Power9+ ISA(IBM Power 架构)
- ARMv8(ARM 架构)
你可以通过以下命令检查你的 CPU 是否支持这些指令集:
- 在 Linux 上使用
lscpu命令:lscpu |grep-i avx 如果输出中包含avx512或avx2,则你的CPU⽀持这些指令集。如果没有输出,则不⽀持。 - 在 ARM 架构上,检查是否⽀持 ARMv8:
lscpu |grep-i armv8 如果发现你的 CPU 不⽀持这些指令集,可能需要升级硬件或使⽤其他解决⽅案。
3. GPU 环境下安装 vLLM
安装Miniconda和创建Python虚拟环境与上面一样,不做赘述!
需要先安装 navidia 驱动以及cuda,然后才安装vllm,否则直接用 pip install vllm,虽然也能安装好,但是识别不到 gpu 环境。
3.1 安装 navidia 驱动
这个环节必须要按照下面的步骤执行,只要和我版本完全保持⼀致,是不会有任何问题的
步骤 1:更新系统
sudo apt update
sudo apt upgrade -y
步骤 2:安装依赖项
sudo apt install -y build-essential dkms
步骤 3:禁⽤ Nouveau 驱动
Nouveau 是开源的 NVIDIA 驱动,可能与官⽅驱动冲突。禁用 Nouveau:
-
创建配置⽂件:
sudo nano /etc/modprobe.d/blacklist-nouveau.conf -
添加以下内容:
blacklist nouveau options nouveau modeset=0
-
更新 initramfs:
sudo update-initramfs -u
-
重启服务器:
sudo reboot
步骤 4:安装 NVIDIA 驱动
-
下载并安装 NVIDIA 驱动包:
下载地址:https://cn.download.nvidia.com/tesla/550.144.03/nvidia-driver-local-repo-ubuntu2404-550.144.03_1.0-1_amd64.deb
如果和我的环境不⼀致,可以在这个页面:https://www.nvidia.cn/drivers/lookup/选择自己合适的环境的驱动进行下载。
下载的文件放在 :/data/program/目录下cd /data/program sudo dpkg -i nvidia-driver-local-repo-ubuntu2404-550.144.03_1.0-1_amd64.deb sudo apt update sudo apt install -y cuda-drivers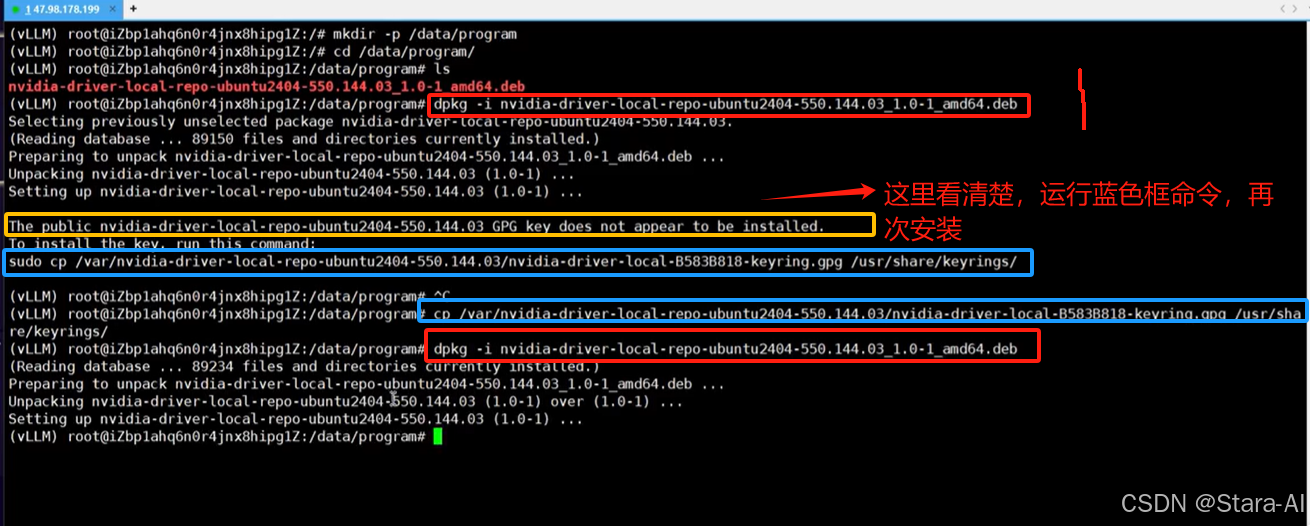
-
安装完成后,重启服务器
sudo reboot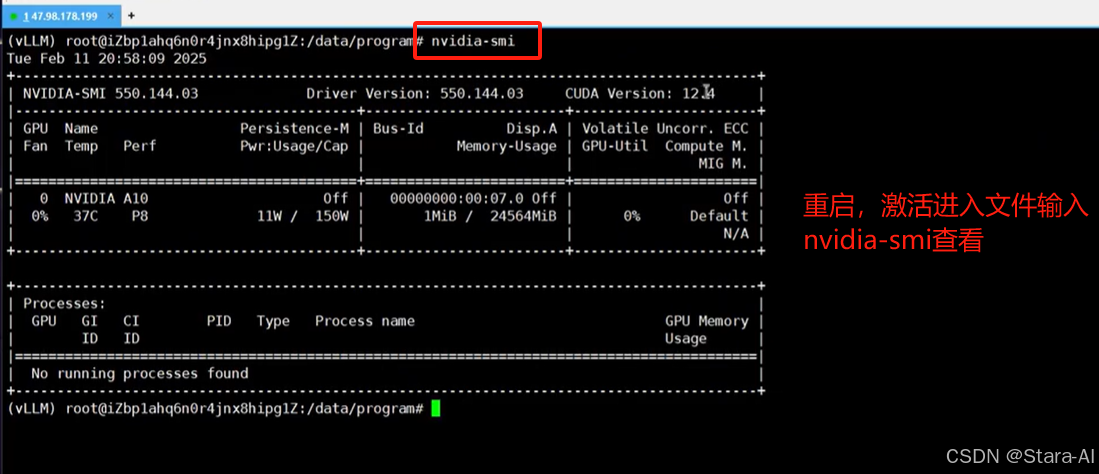
3.2 安装 CUDA 工具包
从上面的信息可以看到,GPU 支持的最高 CUDA 版本是 12.4。
打开网站:https://developer.nvidia.com/cuda-toolkit-archive
然后,选择合适的平台,12.4 版本,对应的系统平台最高是 22.04, 就选择最⾼版本就行,这个不影响。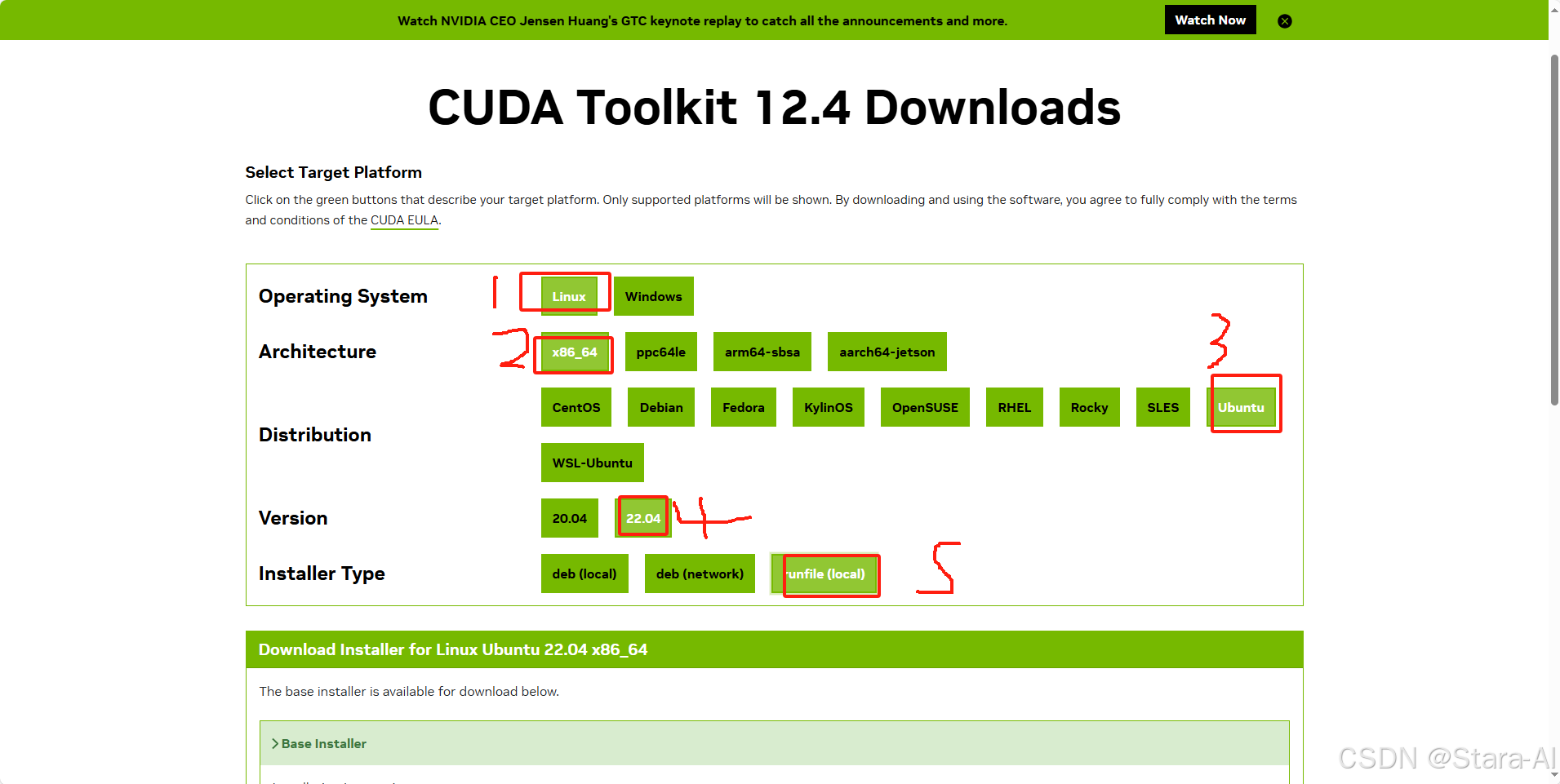
安装通过它给的脚本安装: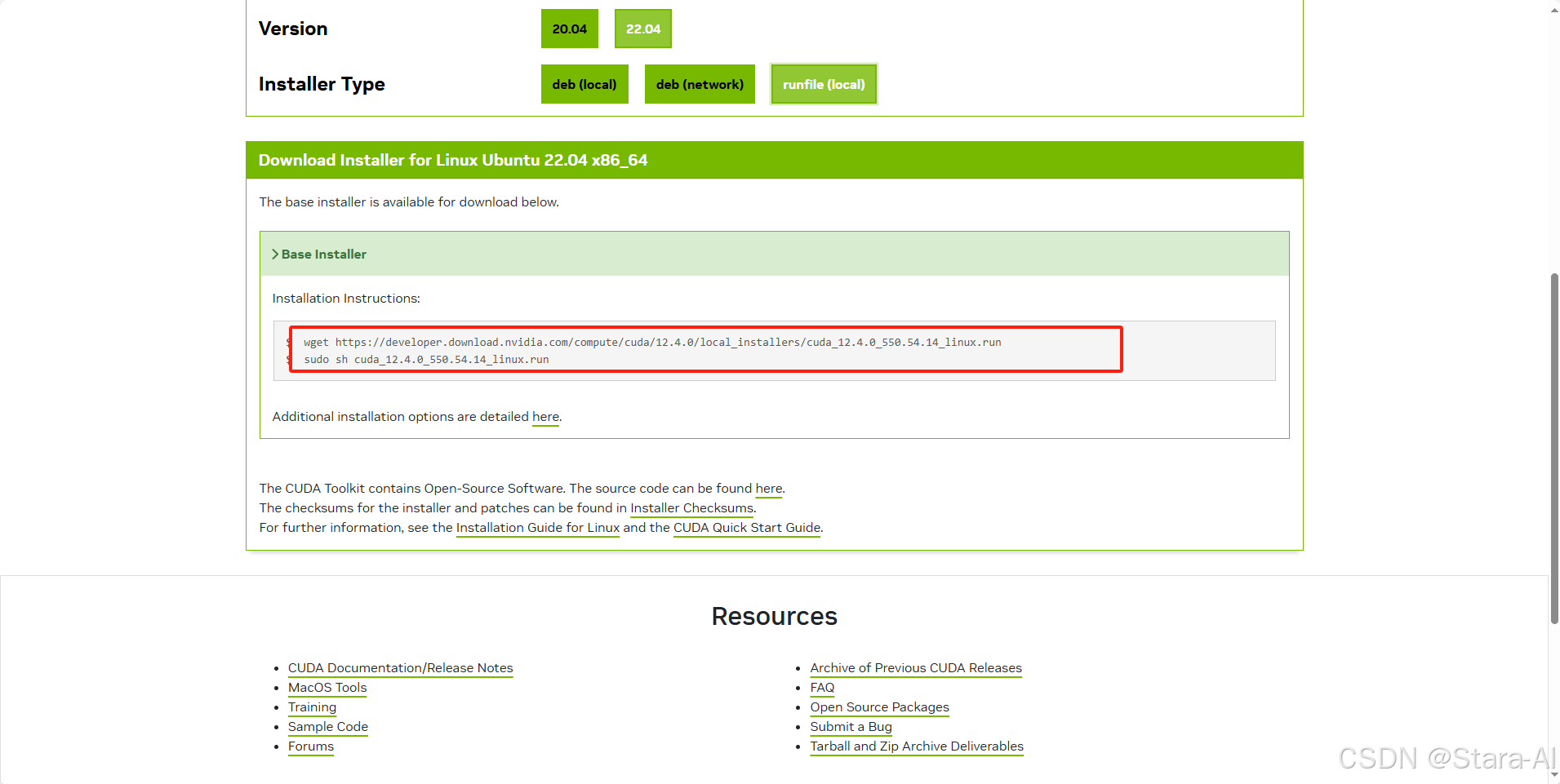
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
sudo sh cuda_12.4.0_550.54.14_linux.run
由于文件比较大,可以自己手动下载文件以后上传到服务器上:(cuda_12.4.0_550.54.14_linux.run)
cd /data/program
chmod a+x cuda_12.4.0_550.54.14_linux.run
./cuda_12.4.0_550.54.14_linux.run
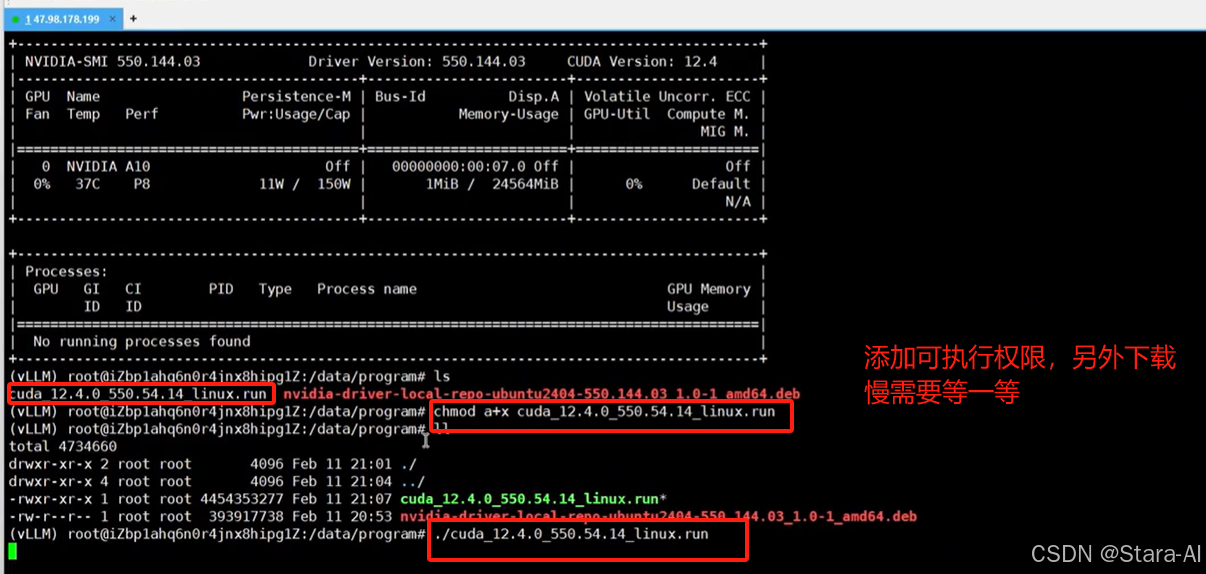
执⾏以后会弹出:Existing package manager installation of the driver found. It is strongly x x recommended that you remove this before continuing.直接选择 continue 就行。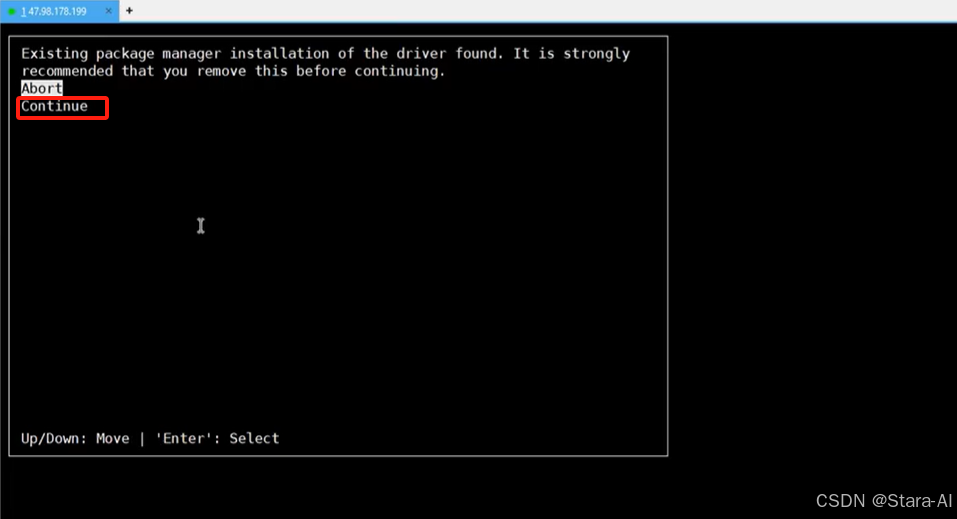
中途会弹出界面:输⼊ accept 并回车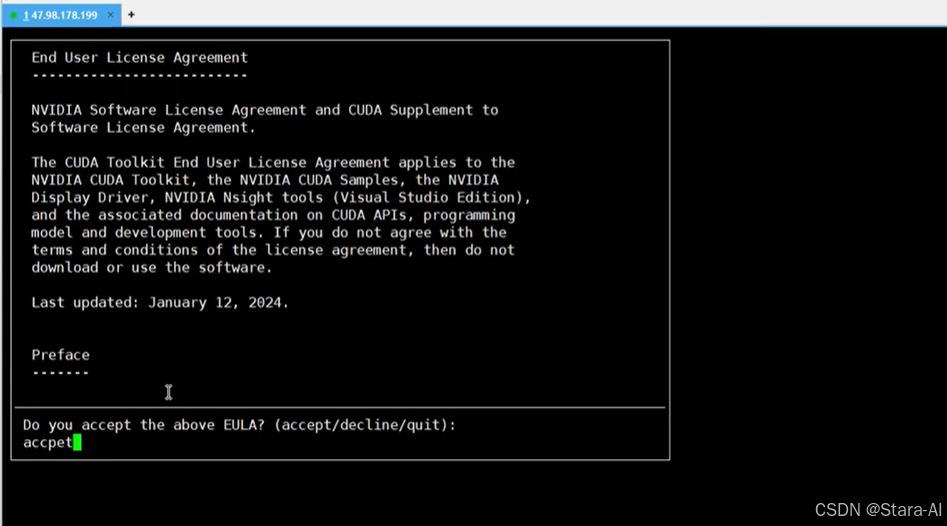
由于我们之前已经安装了显卡驱动,所以这里不需要再安装了,按空格键即可去掉选中(x),
然后移到最下面的 install 按回车即可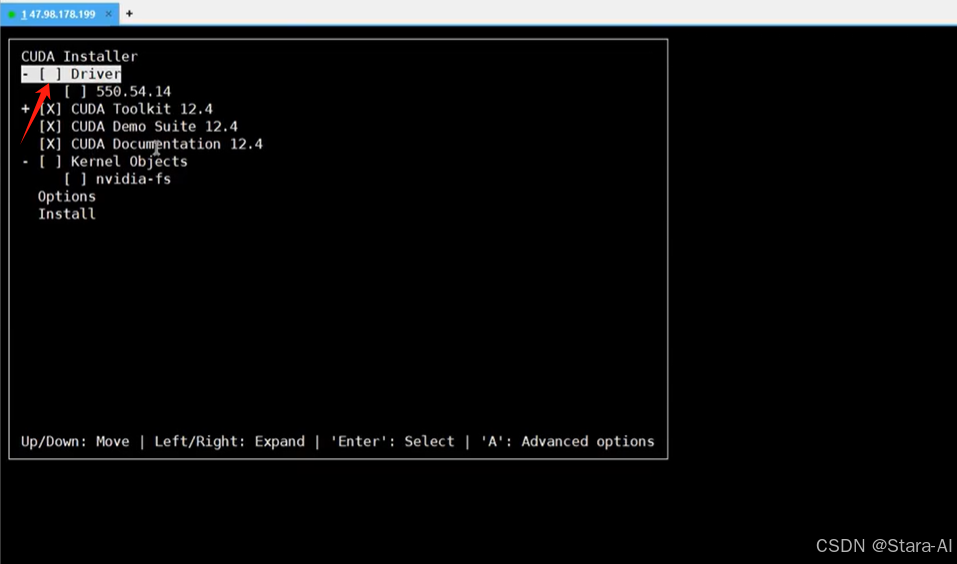
安装完成以后,需要设置环境变量,使得我们可以在控制台直接执行 cuda 相关指令。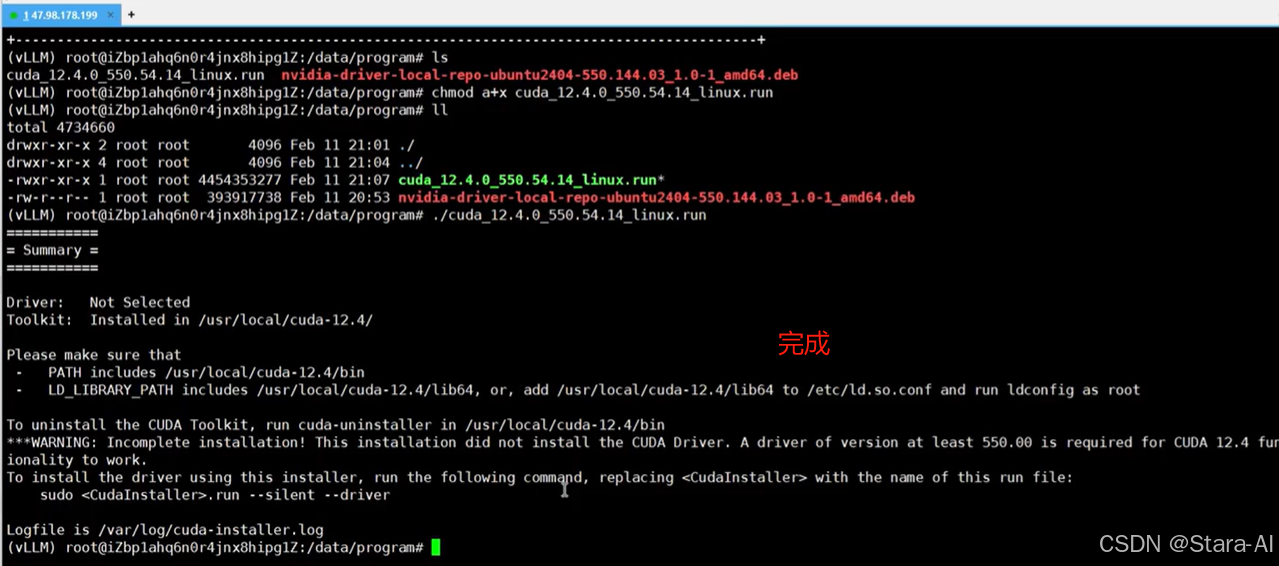
在/root/.bashrc⽂件末尾输⼊:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.4/lib64
export PATH=$PATH:/usr/local/cuda-12.4/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.4
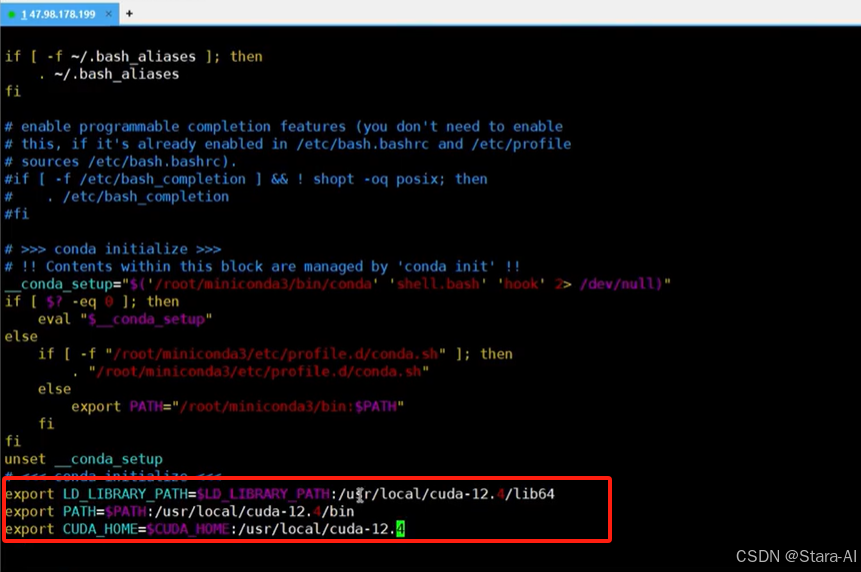
更新环境上配置生效:source /root/.bashrc
如果没有任何问题,那么执行 nvcc --version 就可以得到如下结果就安装好了。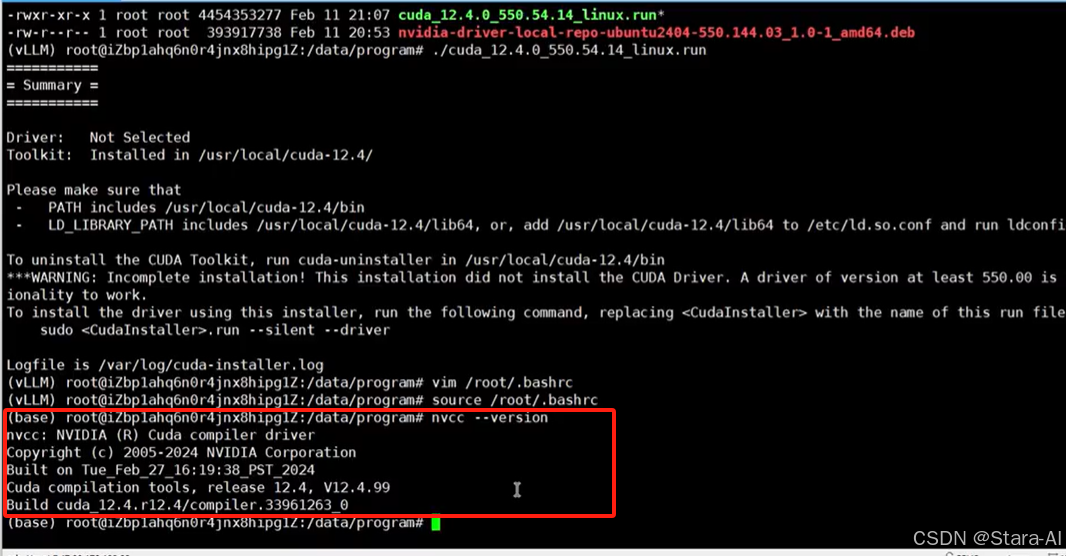
3.3 安装 Pytorch 环境
为了避免后续出现各种意外,确保所有的版本保持⼀致,安装 torch 选择Python3.10 版本,以及 cuda12.4 版本。
通过下面网址,全局搜索cu124:https://download.pytorch.org/whl/torch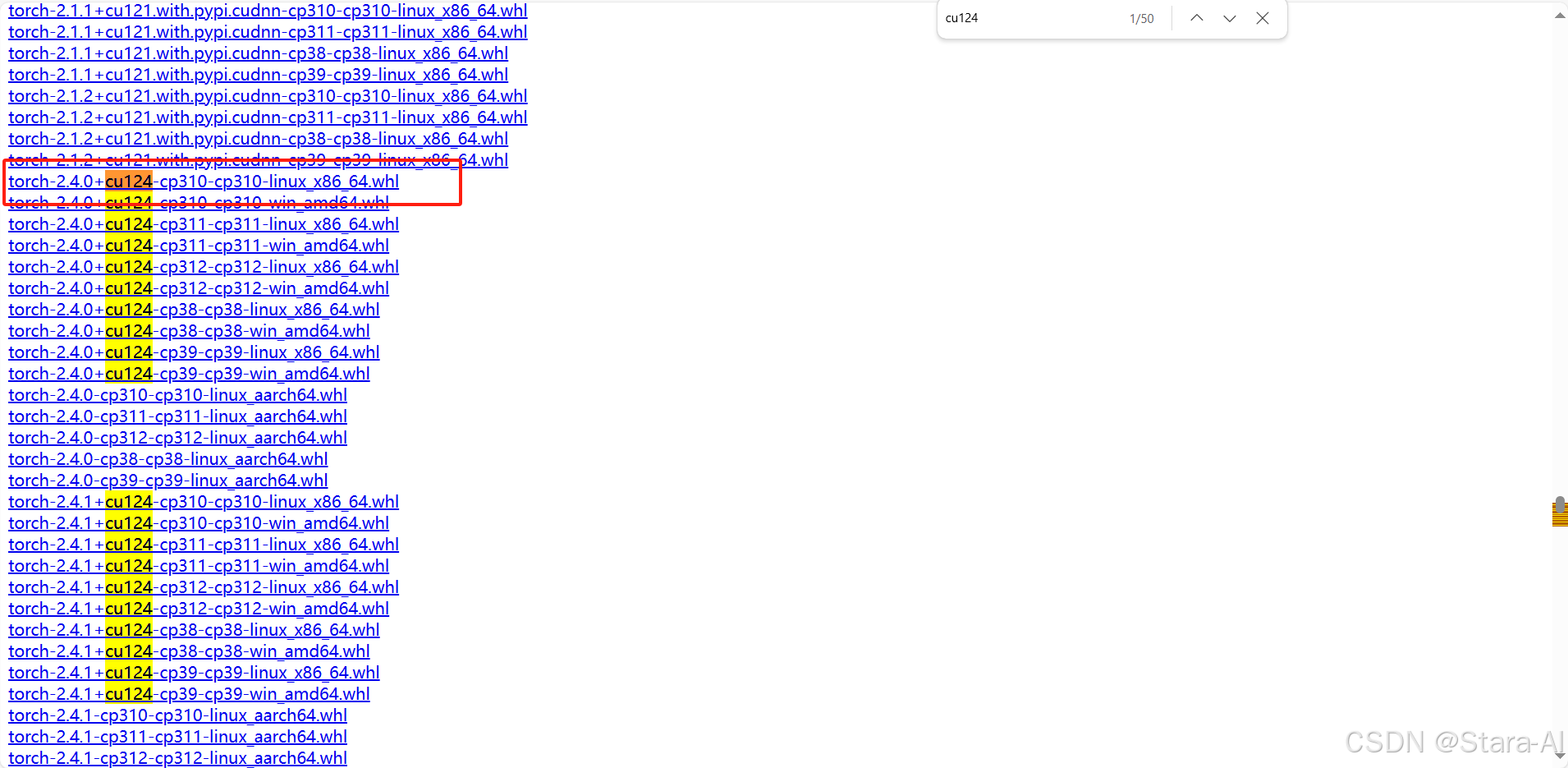
下载以后,同样放在 :/data/program/ 目录下,执行下面的命令进行本地安装
conda activate vLLM
pip install torch-2.4.0+cu124-cp310-cp310-win_amd64.whl
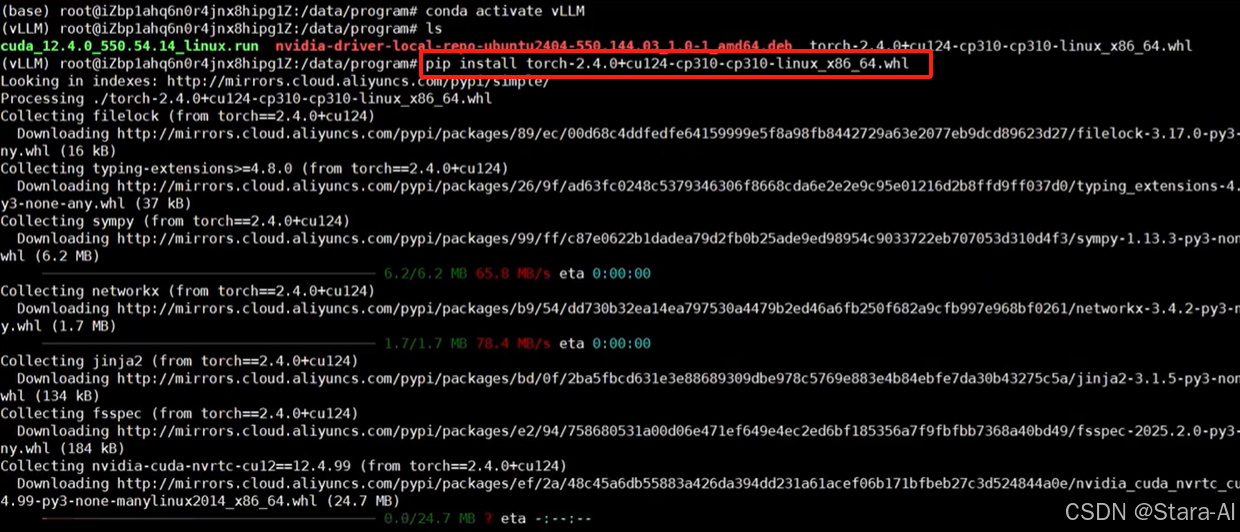
安装安装完成后通过pip list查看安装包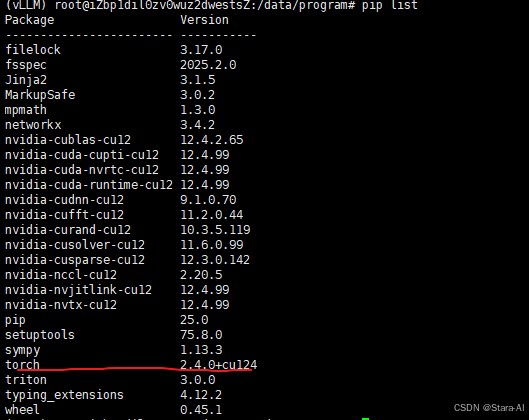
3.4 安装 vLLM
pip install vLLM
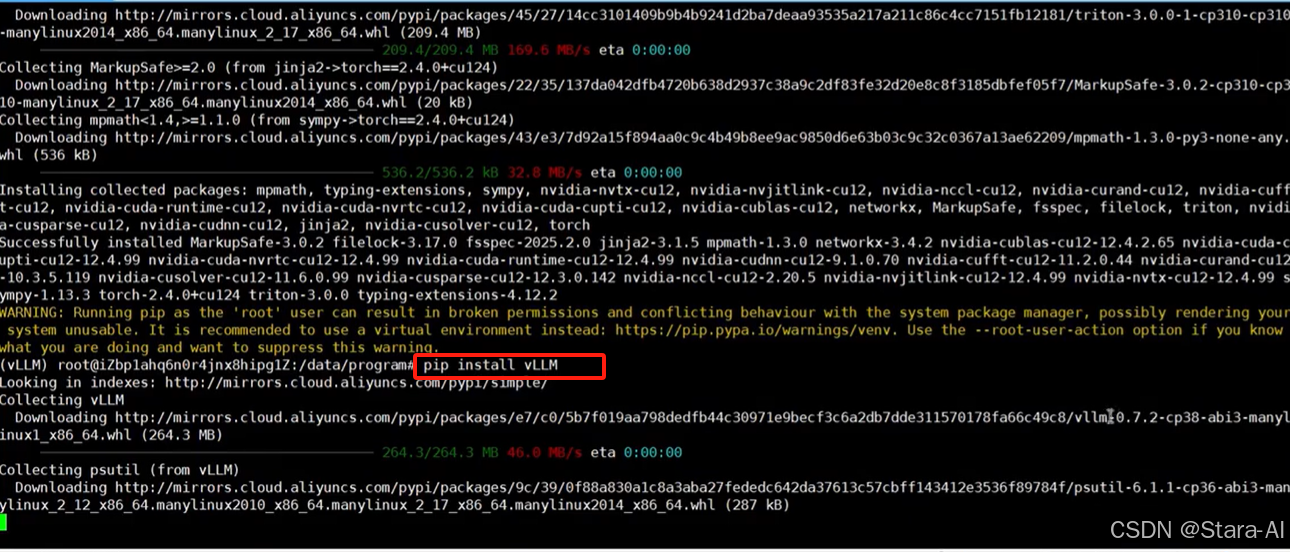
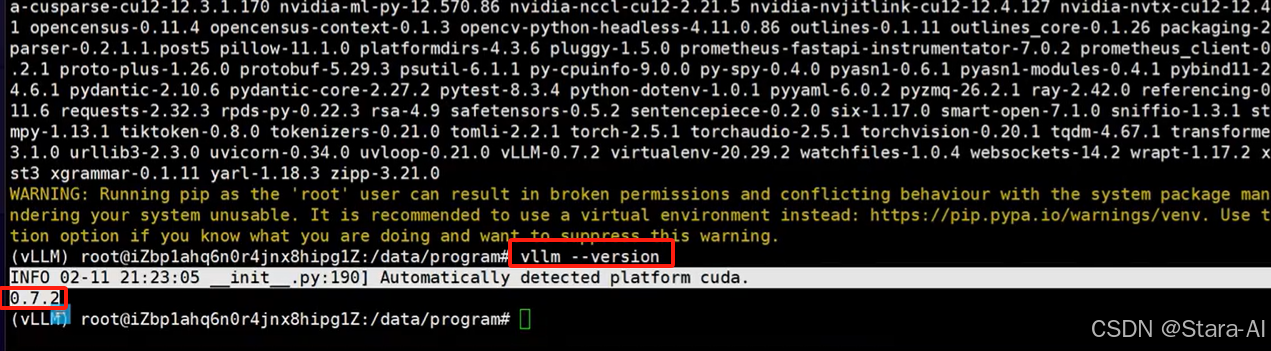
验证 vllm 安装结果
vllm --version
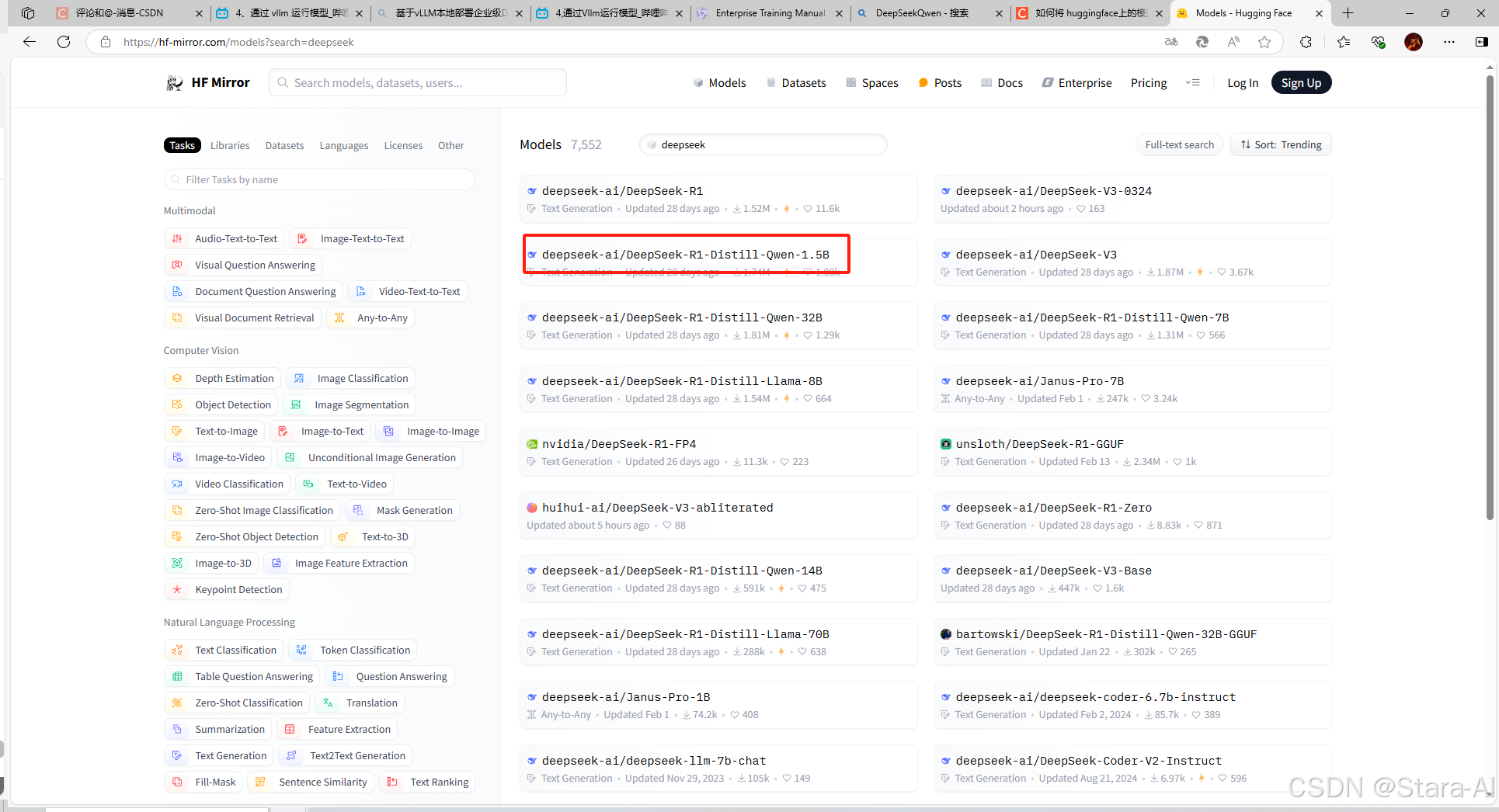
4. 下载 DeepSeek 模型
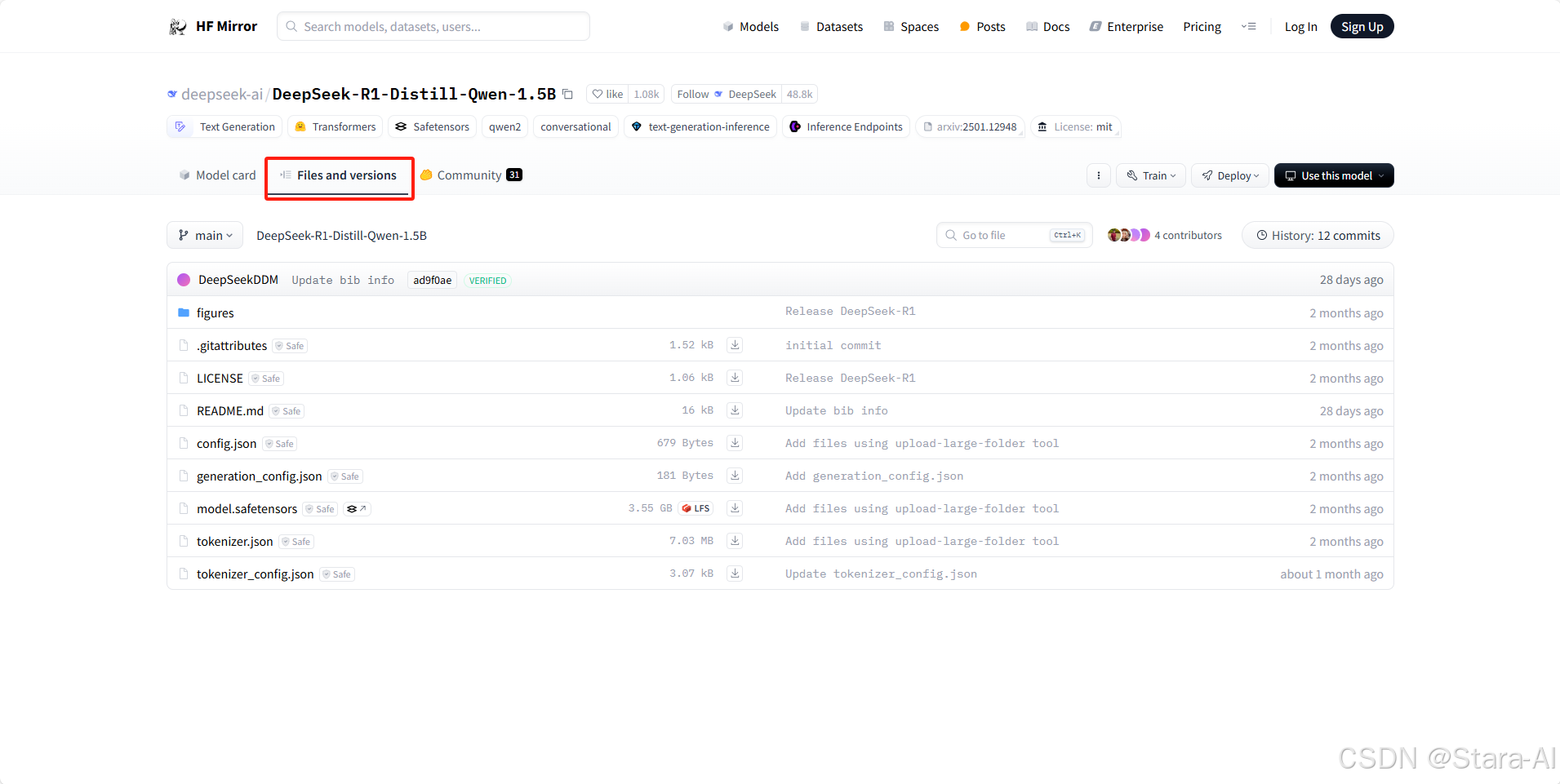
下载过程有点慢,如果不想等,可以在 hugging-face 的镜像网站:https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main上用迅雷下载 / Git 下载 / 命令行下载。
方式一:迅雷下载:
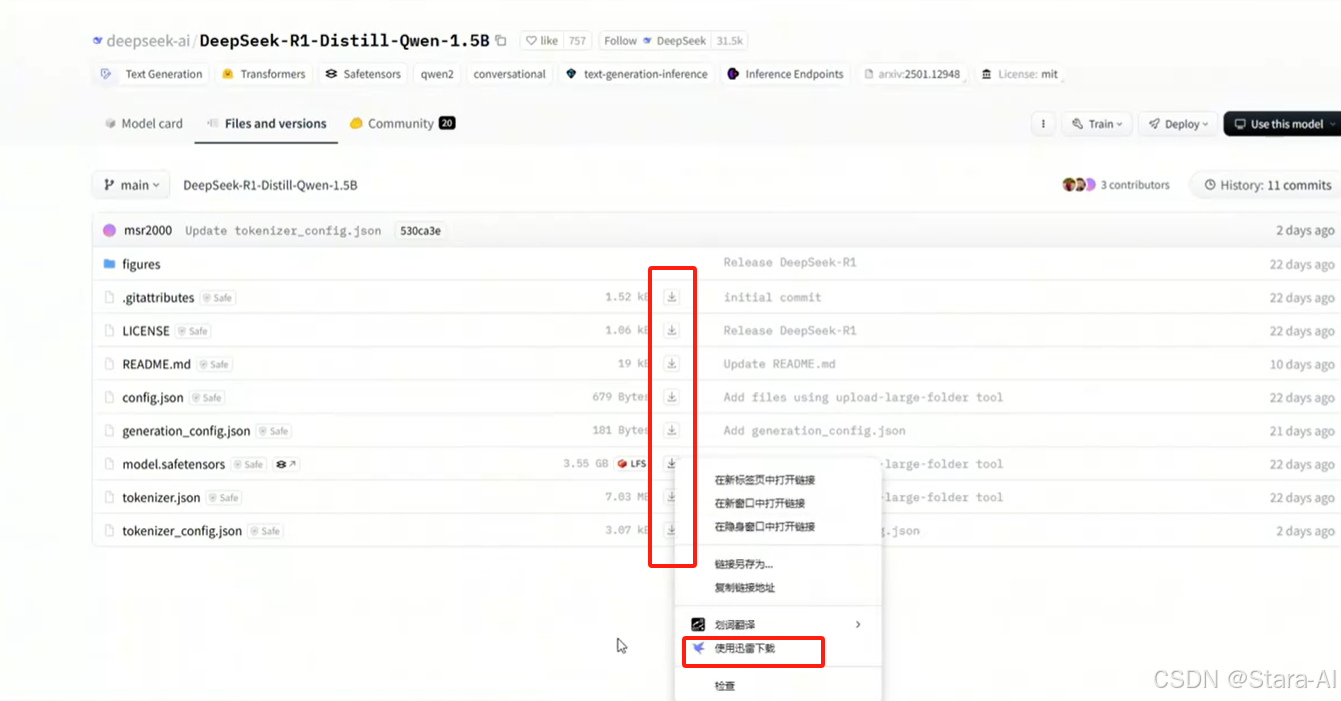
下载以后,保存到/data/ModeScope/目录下
方式二:Git 方式
若没有安装,则通过命令进行安装:sudo apt-get install git同时,Qwen2 / DeepSeek 模型权重文件比较大,我们需要用到 Git 大文件系统,因此需要提前安装好:sudo apt-get install git-lfs,开始下载模型权重文件到本地目录:/data/ModelSpace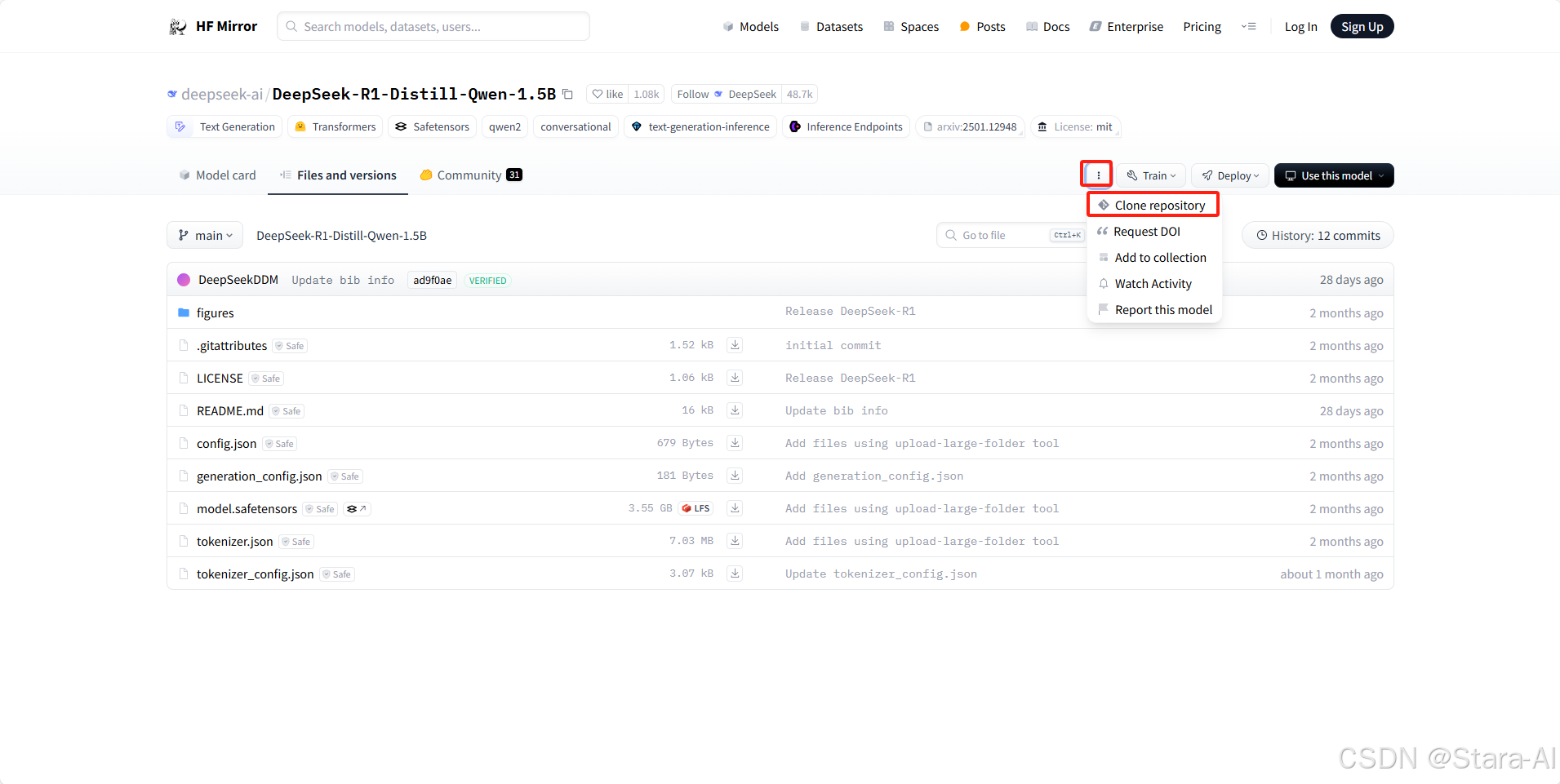
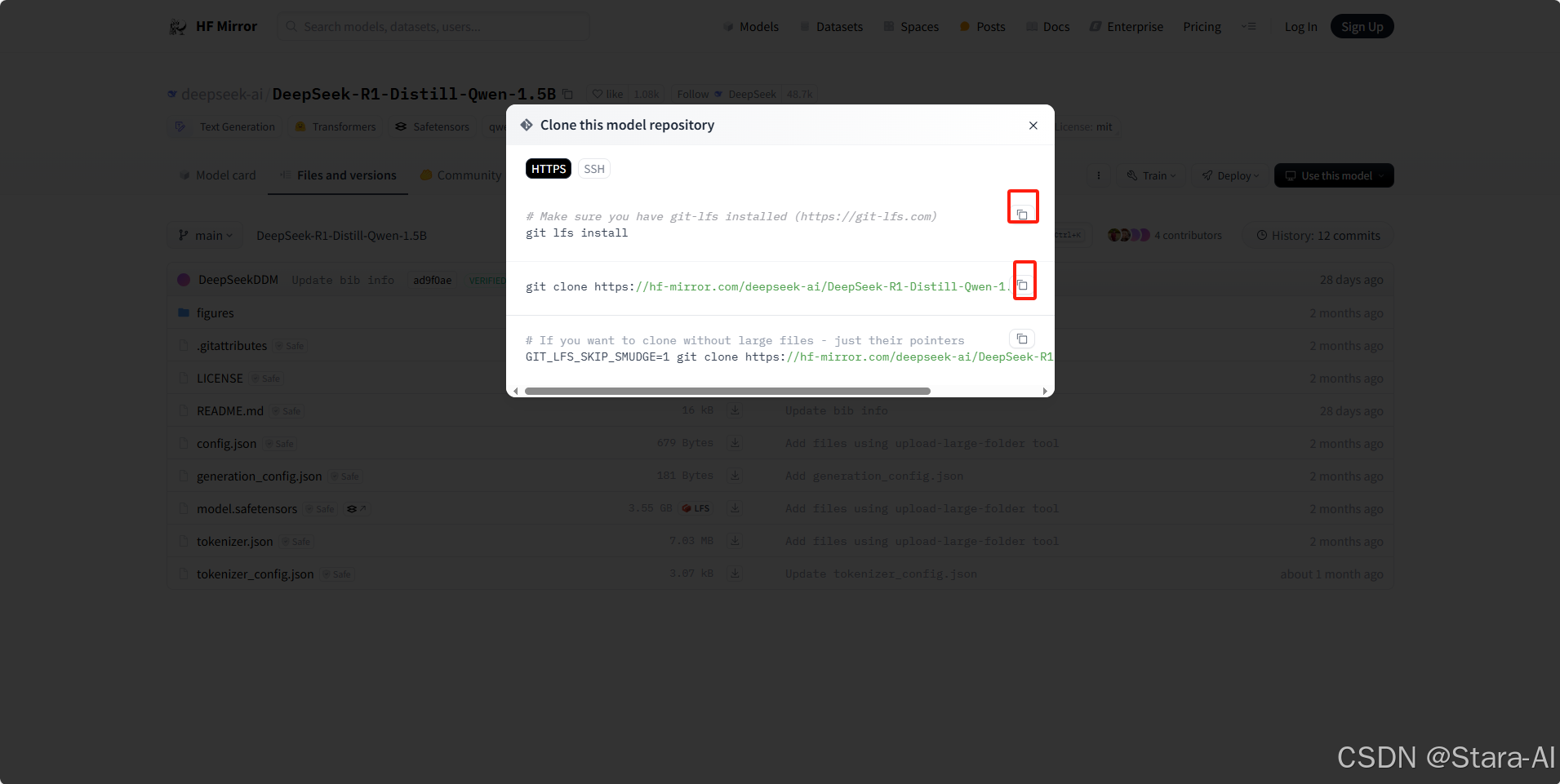
# 创建⽬录
mkdir -p /data/ModelSpace && cd /data/ModelSpace
# 下载⽂件
git lfs install
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
下载过程中,如果因网络等原因中断,我们可以继续断点下载:
cd /data/ModelSpace/DeepSeek-R1-Distill-Qwen-1.5B
git lfs pull
下载成功之后,在 /data/ModelSpace 目录下,就可以看到
方式三:通过 SDK 下载
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download('DeepSeek-R1-Distill-Qwen-1.5B')
方式四:通过命令行下载
pip install modelscope
modelscope download --model DeepSeek-R1-Distill-Qwen-1.5B
下载以后,保存到/data/ModeScope/目录下。
5. vLLM 推理大模型
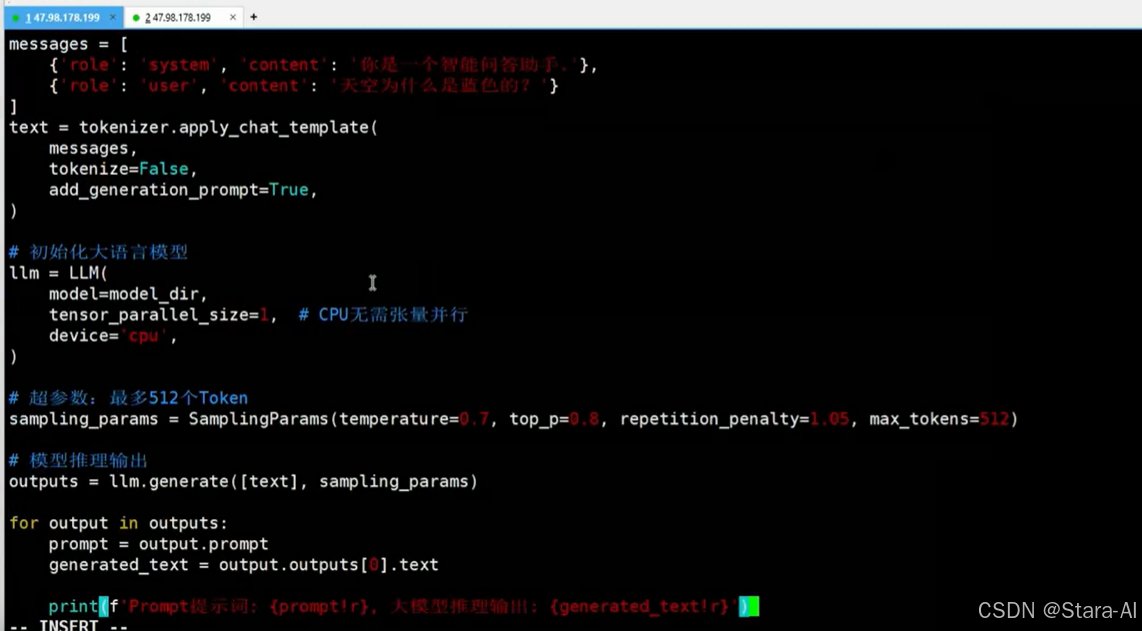
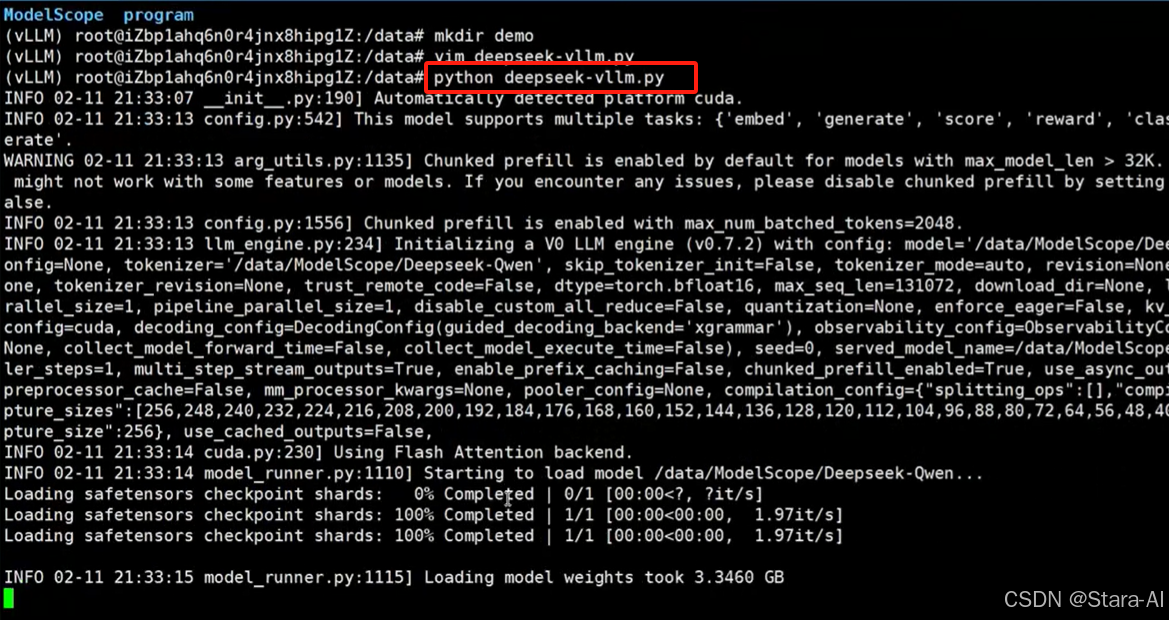
编写⼀个测试脚本,deepseek-vllm.py
import os
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# 设置环境变量(cpu环境需要单独设置,GPU环境不需要)
os.environ['VLLM_TARGET_DEVICE'] = 'cpu'
# 模型ID:我们下载的模型权重⽂件⽬录
model_dir = '/data/ModeScope/DeepSeek-R1-Distill-Qwen-1.5B'
# Tokenizer初始化
tokenizer = AutoTokenizer.from_pretrained(
model_dir,
local_files_only=True,
)
# Prompt提⽰词
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '天空为什么是蓝⾊的?'}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 初始化⼤语⾔模型
llm = LLM(
model=model_dir,
tensor_parallel_size=1, # CPU⽆需张量并⾏
device='cpu',
)
# 超参数:最多512个Token
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# 模型推理输出
outputs = llm.generate([text], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
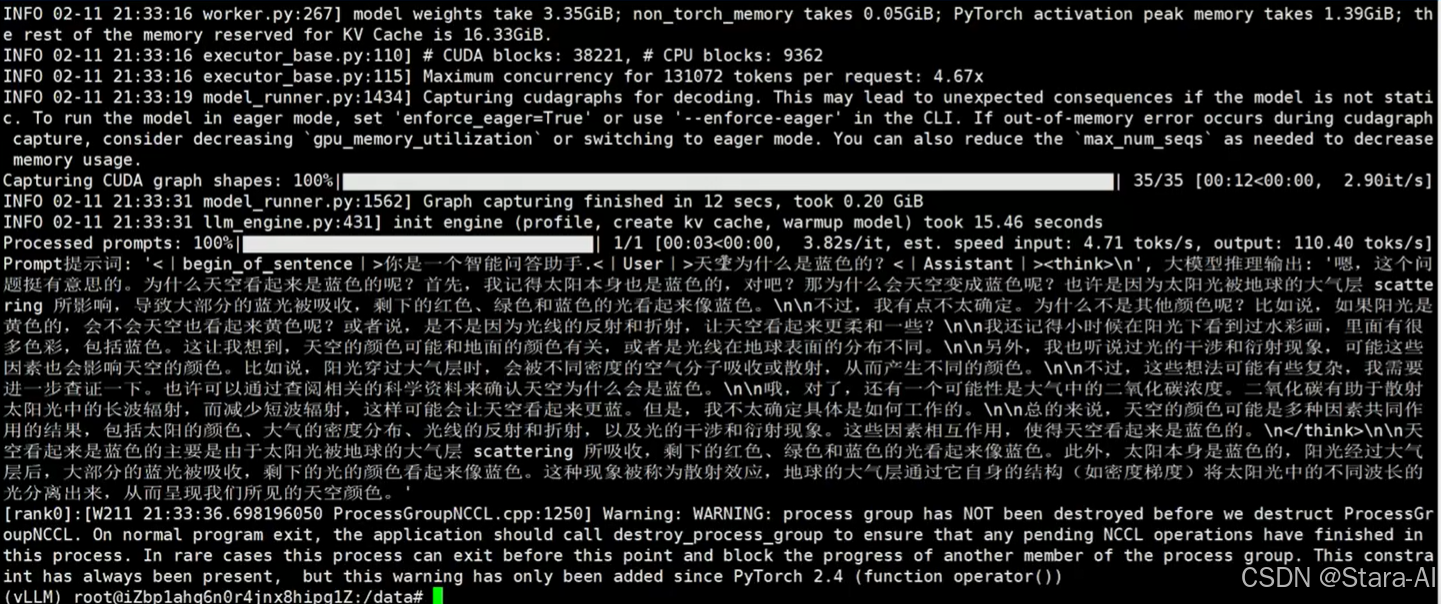
print(f'Prompt提⽰词: {prompt!r}, ⼤模型推理输出: {generated_text!r}')
如果运行上面的脚本报如下错误:
ValueError: The model's max seq len (131072) is larger than the maximu
m number of tokens that can be stored in KV cache (122960). Try increas
ing `gpu_memory_utilization` or decreasing `max_model_len` when initial
izing the engine.
[rank0]:[W207 22:38:09.116981831 ProcessGroupNCCL.cpp:1250]
这个提示说明模型的最大序列长度(max_seq_len )超过了当前显存配置下能够支持的 KV Cache(键值缓存)的最大容量。KV Cache 是用于加速大模型推理(如生成文本)时存储历史键值向量的内存空间,如果超出限制会导致显存不足的问题。
修改上面脚本的部分代码如下:
llm = LLM(
model=model_dir,
gpu_memory_utilization=0.95,
max_model_len=8089, # 限制⻓度
)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)