DeepSeekMoE: Towards Ultimate Expert Specialization inMixture-of-Experts Language Models
研究动机:这篇文章主要讲的是如何让大型AI模型变得更聪明、更省电。就像我们人类有不同领域的专家(比如医生、工程师、厨师)一样,AI模型内部也可以分成很多“小专家”。传统的方法有点像每次只请几个大专家来解决问题,但这些大专家可能懂的东西有重复,效率不高。核心贡献:1、细粒度专家分割技术将原N个专家细分为m×N个更小的专家单元,每次激活m×K个单元。优势:增强专家组合的灵活性,促进知识聚焦,减少专家间
原文地址:2401.06066
代码地址:modeling_deepseek.py · deepseek-ai/deepseek-moe-16b-base at main
团队:DeepSeek AI
摘要
研究动机:这篇文章主要讲的是如何让大型AI模型变得更聪明、更省电。就像我们人类有不同领域的专家(比如医生、工程师、厨师)一样,AI模型内部也可以分成很多“小专家”。传统的方法有点像每次只请几个大专家来解决问题,但这些大专家可能懂的东西有重复,效率不高。
核心贡献:
1、细粒度专家分割技术
将原N个专家细分为m×N个更小的专家单元,每次激活m×K个单元。
优势:增强专家组合的灵活性,促进知识聚焦,减少专家间的知识重叠。
2、共享专家隔离机制
固定保留Kₛ个专家作为共享专家,专门学习通用知识。优势:避免通用知识重复存储,降低路由计算冗余
实验结果就像考试成绩单:
小模型(2B参数)能达到之前大模型(2.9B)的水平,但更省电
中模型(16B)用40%的电量就能达到知名模型LLaMA2(7B)的水平
超大模型(145B)甚至接近更贵模型(67B)的能力,但电费只要1/3
科普
大模型扩展的成效与成本矛盾
研究证实,增加模型参数和计算资源能显著提升语言模型性能(如GPT系列),但随之而来的极高计算成本成为瓶颈。 MoE架构的解决方案与优势: 混合专家(MoE)模型通过在模型中动态激活部分专家模块,实现参数规模扩大(如万亿参数)的同时,控制实际计算量(仅激活约10%-20%参数)。 Transformer结合MoE的实践(如Switch Transformer、GLaM等)已证明其有效性,既能保持模型性能,又将训练/推理成本降低数倍,展现了高效扩展模型的潜力。
| 关键对比: | 普通大模型(左) vs MoE模型(右) |
|---|---|
| 计算成本: | 100% → 10%-20% |
| 参数量: | 千亿级 → 万亿级 |
| 性能: | 强 → 更强(相同计算资源下) |
传统MoE架构细节
-
结构替代:
-
用MoE层取代Transformer中的前馈网络(FFN)
-
每个MoE层包含多个并行专家(Experts)
-
-
专家结构:
-
每个专家与标准FFN结构相同
-
典型配置:每个MoE层含8-128个专家
-
-
路由机制:
-
动态门控网络(Gating Network)决定token分配
-
两种典型策略:
-
Top-1路由(Switch Transformer):每个token选择1个专家
-
Top-2路由(GShard):每个token选择2个专家
-
-
# 伪代码示例
class MoELayer(nn.Module):
def forward(self, x):
# 1. 计算路由权重
gates = gating_network(x) # [B,T,N_experts]
# 2. 选择Top-K专家
topk_gates, topk_indices = torch.topk(gates, k=2)
# 3. 加权计算输出
output = 0
for i in range(2):
expert_output = experts[topk_indices[:,i]](x)
output += topk_gates[:,i] * expert_output
return outputMoE(混合专家)层在Transformer中的实现原理
- 传统FFN:每个Transformer层中的FFN是单一神经网络,处理所有输入token。
- MoE层:将FFN替换为多个独立专家FFN(数量为N),每个token根据动态路由选择Top-K专家(通常K=1或2)进行处理。
数学表达式
对于第层MoE层,其输出隐藏状态
计算为:

输入:是第
个token在第
层的输入向量。
门控值:决定第
个专家对当前token的贡献权重,通过稀疏选择实现:
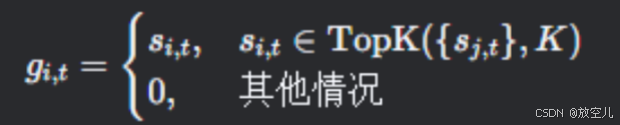
亲和度得分:衡量token与专家的匹配程度:
:第
层第
个专家的中心向量(可学习参数),表征专家擅长的特征空间。
DeepSeekMoE Architecture
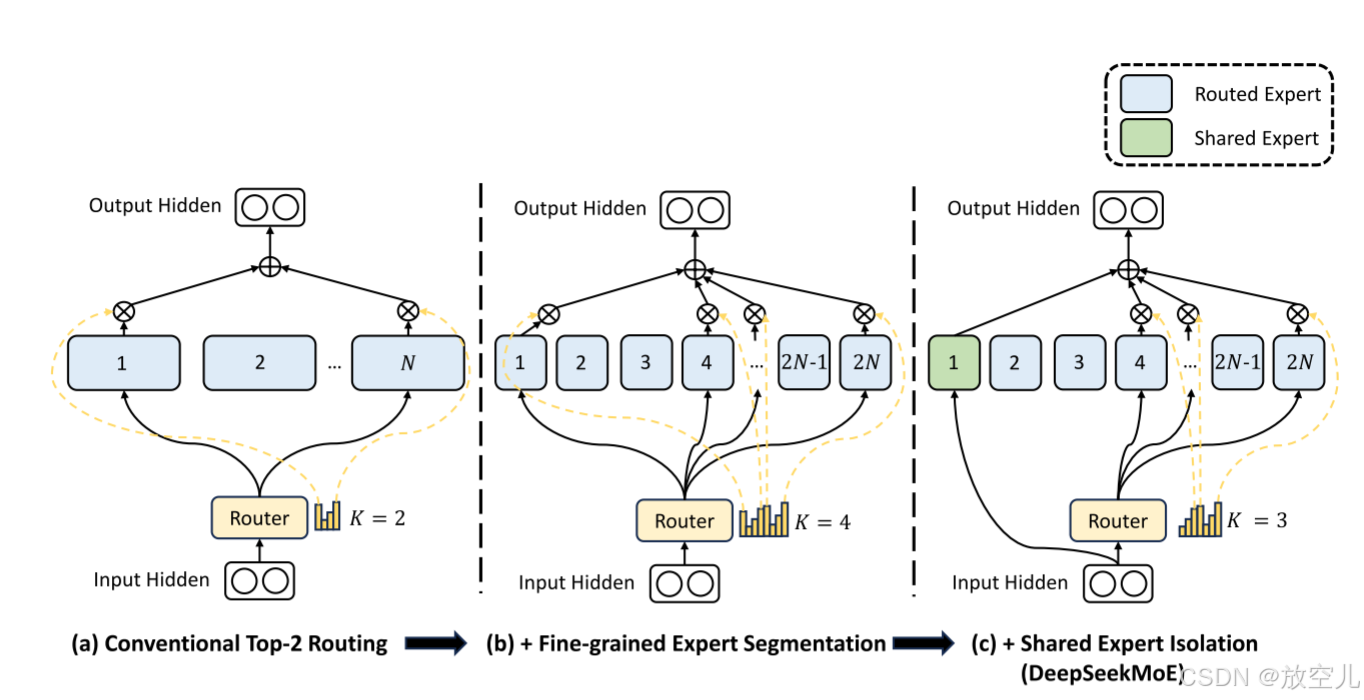
细粒度专家分割(Fine-Grained Expert Segmentation)}:
- 子专家拆分:将每个原始专家拆分为
个更小的子专家,总专家数从
增至
。
- 组合灵活性:每个token动态选择
个子专家(如原
,分割后激活 8 个),组合模式从
增至
。
- 参数控制:子专家中间层维度缩小至
原尺寸,总参数量保持不变。
共享专家隔离(Shared Expert Isolation):
- 固定共享专家:指定
个专家强制激活,专门学习跨任务通用知识(如气温、水温的共性变化)。
- 动态路由调整:剩余
个专家通过门控动态选择
个(如总激活数保持
,共享占1个,路由激活7个)。
- 容量扩展:共享专家的中间层维度扩大

负载均衡
在混合专家(MoE)模型中,动态路由可能导致负载不均衡,表现为某些专家被过度使用(路由崩溃)或跨设备计算瓶颈。DeepSeekMoE通过双层平衡损失(专家级 + 设备级)优化负载分配,兼顾模型性能与计算效率。
专家级平衡损失
目标:防止路由崩溃,确保每个专家被公平训练。
实现方式:
1、专家选择频率:统计所有token中专家i被选中的比例。
:路由专家总数(总专家数 - 共享专家数)。
:每次激活的路由专家数(总激活数 - 共享专家数)。
2、平均选择概率:衡量所有token对专家的平均依赖程度。
3、损失函数:通过惩罚选择频率偏差,迫使路由均匀分配token。
为小值(如0.01),轻微约束专家级平衡,避免过度限制模型性能。
作用:
避免某些专家长期闲置(如专家A处理90%的输入,专家B仅处理10%)。
确保所有专家充分参与训练,提升模型整体容量。
设备级平衡损失:

双层平衡的作用:
| 层级 | 核心目标 | 超参数设置 | 实际影响 |
|---|---|---|---|
| 专家级 | 避免路由崩溃,均衡专家训练机会 | α₁ 小 | 专家参数多样化,提升模型表达能力 |
| 设备级 | 跨设备计算负载均衡 | α₂ 大 | 提升硬件利用率,加速训练与推理过程 |
代码讲解
代码部分,为了大家更好的阅读和探讨我在飞书举了一个例子进行上传,有问题大家可以在疑问区域直接评论和且代码部分每个公式我也做了详细数学介绍,绝对通俗易懂!
代码位置:
Docs![]() https://h1sy0ntasum.feishu.cn/wiki/N20rwbZxgiKkbhkikVjcjevbnEh?from=from_copylink
https://h1sy0ntasum.feishu.cn/wiki/N20rwbZxgiKkbhkikVjcjevbnEh?from=from_copylink

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)