【小白都能简单部署,本地私有化通过Linux在Docker部署deepseek-r1:7b详细再详细的步骤】
详细不能再详细的本地私有化部署Deepseek,并配置知识库
本次部署私有化Deepseek模型,主要使用rocky-Linux9.5版本的操作系统,通过部署Docker,在Docker中部署ollama,通过ollama拉取deepseek-r1:7b、Embedding模型,主机上安装Dify,通过Dify集成Deepseek模型、Embedding模型,并配置知识库,所有坑已踩完,直接一步到位!
文章目录
前言
DeepSeek 是一款开创性的开源大语言模型,凭借其先进的算法架构和反思链能力,为 AI 对话交互带来了革新性的体验。通过私有化部署,可以充分掌控数据安全和使用安全。还可以灵活调整部署方案,并实现便捷的自定义系统。
提示:以下是deepseek-r1对应GPU和显存,选择合适的版本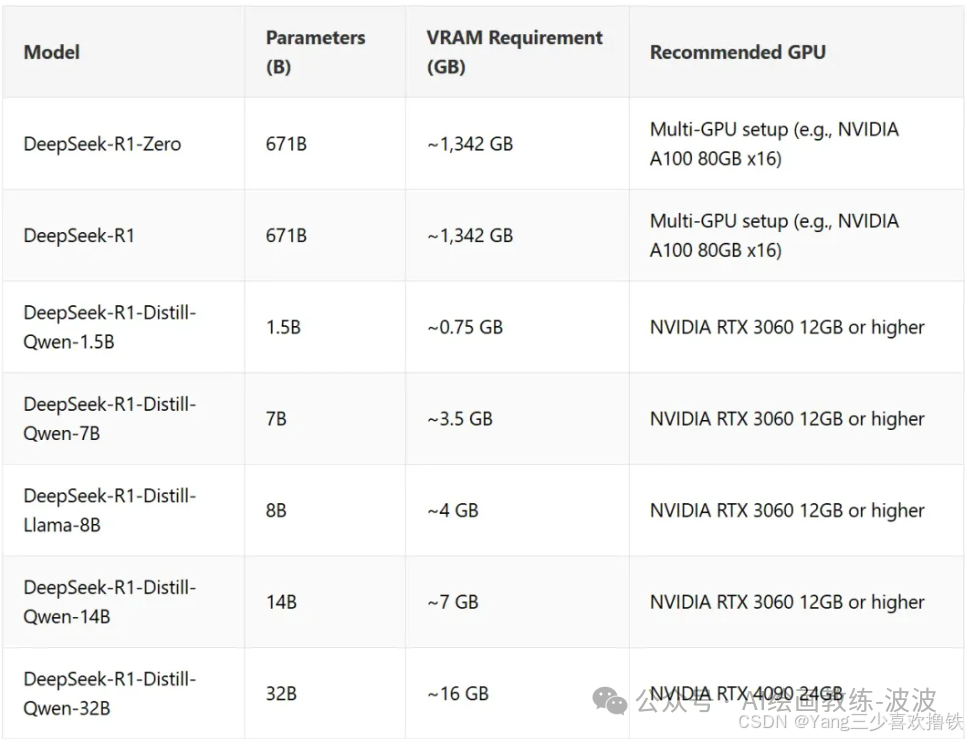
部署DeepSeek-r1:7b硬件要求:
CPU:推荐8核或以上(需支持AVX指令集)
内存:至少16GB(建议32GB以上以提升性能)
存储:50GB以上可用空间(模型文件约4.7GB)
GPU(可选):若需加速推理,推荐NVIDIA显卡(显存≥8GB)并安装CUDA驱动
一、Rocky-Linux-9.5(或Centos)部署Docker
1.1、安装系统依赖
# 更新系统
sudo dnf update -y
# 安装Docker依赖
sudo dnf install -y yum-utils device-mapper-persistent-data lvm2
1.2、安装Docker
1.2.1 添加Docker官方仓库
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
1.2.2 安装Docker引擎
sudo dnf install docker-ce docker-ce-cli containerd.io -y
sudo systemctl start docker && sudo systemctl enable docker
1.2.3 配置用户权限
sudo usermod -aG docker $USER
newgrp docker # 刷新用户组
1.2.4 配置daemon.json加速器
#创建文件
mkdir -p /etc/docker
#创建docker加速器文件
vim /etc/docker/daemon.json
#复制配置内容
{
"registry-mirrors": [
"https://dockerpull.org",
"https://docker.1panel.dev",
"https://docker.foreverlink.love",
"https://docker.fxxk.dedyn.io",
"https://docker.xn--6oq72ry9d5zx.cn",
"https://docker.zhai.cm",
"https://docker.5z5f.com",
"https://a.ussh.net",
"https://docker.cloudlayer.icu",
"https://hub.littlediary.cn",
"https://hub.crdz.gq",
"https://docker.unsee.tech",
"https://docker.kejilion.pro",
"https://registry.dockermirror.com",
"https://hub.rat.dev",
"https://dhub.kubesre.xyz",
"https://docker.nastool.de",
"https://docker.udayun.com",
"https://docker.rainbond.cc",
"https://hub.geekery.cn",
"https://docker.1panelproxy.com",
"https://atomhub.openatom.cn",
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://docker.linkedbus.com"
]
}
#加载文件生效
systemctl daemon-reload
systemctl restart docker
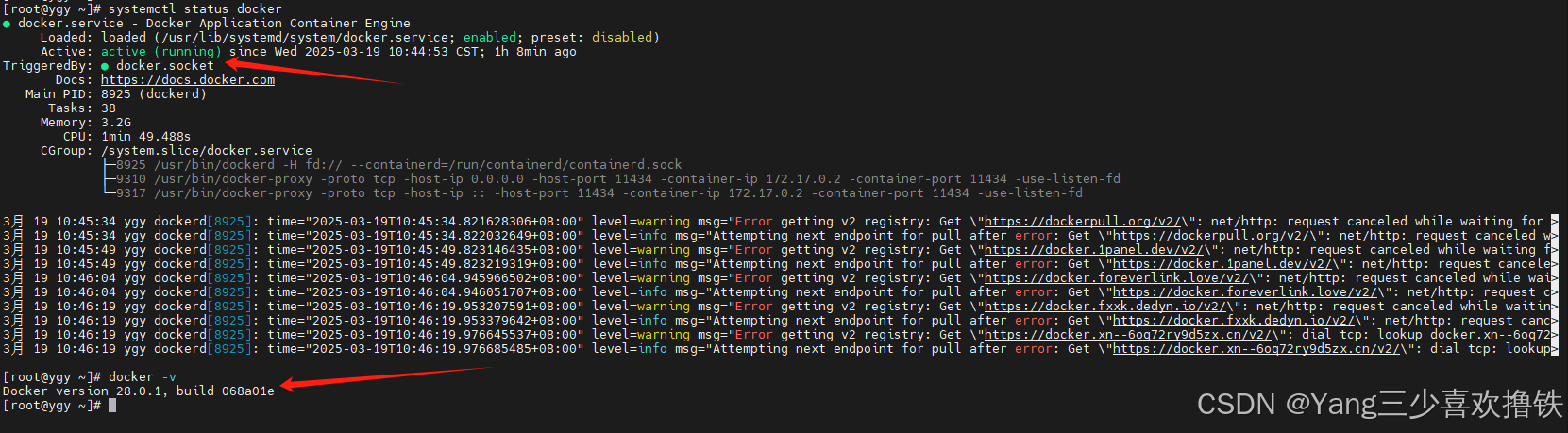
1.2.5 查看Docker状态及版本
一、Ubuntu22.04.5部署Docker
1.1、更新系统
# 更新系统
sudo apt update
1.2、安装vim、curl
sudo apt install git vim curl
1.3、安装Docker
sudo apt install docker.io
1.4、启动Docker服务
sudo systemctl start docker
sudo systemctl enable docker
1.5、查看Docker版本以及配置daemon.json容器加速器参考上面。
二、部署Ollama与DeepSeek-R1-7b
2.1、拉取ollama镜像
docker pull ollama/ollama
2.2、创建ollama服务并运行(基于CPU版本)
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.3、创建ollama服务并运行(基于GPU版本)
docker run -d --gpus=all -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.4、查看ollama

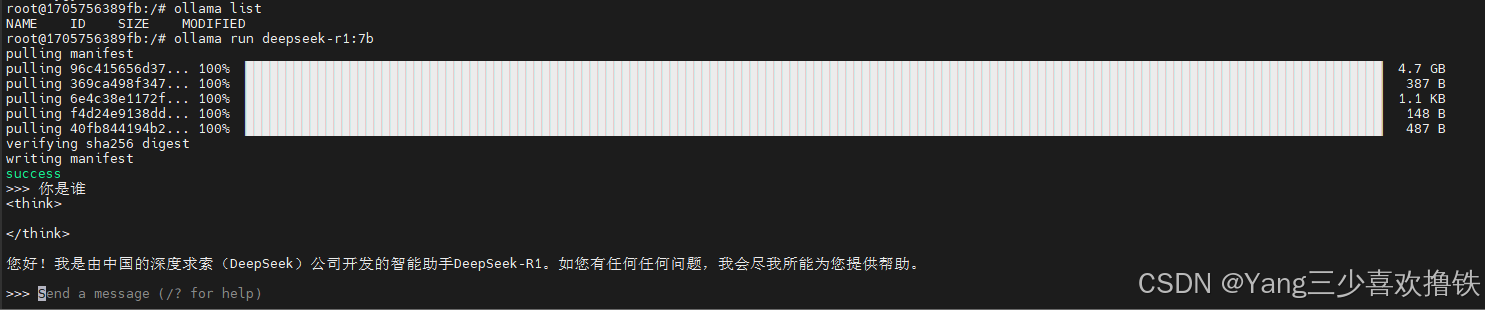
2.5、ollama拉取deepseek-r1:7b模型
根据自己的硬件条件选择对应的模型版本,拉取deepseek的时候,到后面拉取速度很慢的话,可以直接CTRL + C中止拉取,然后再重新执行拉取命令,会自动续上原拉取的进度,并且速度会提升。
#进入ollama容器
docker exec -it ollama /bin/bash
#ollama容器中拉取并运行deepseek模型
ollama run deepseek-r1:7b
#ollama容器中拉取Embedding模型
ollama pull bge-m3
#ollama容器中查看拉取的模型
ollama list

三、开放防火墙策略或者直接关闭
3.1、防火墙放通ollama端口
#开放ollama端口
firewall-cmd --zone=public --add-port=11434/tcp --permanent
firewall-cmd --reload
3.2、Centos防火墙开通或关闭
#防火墙命令(Centos、Rocky)
systemctl start firewalld
systemctl stop firewalld
3.3 Ubuntu防火墙开通或关闭
#防火墙命令(Ubuntu)
sudo ufw enable
sudo ufw default deny
sudo ufw disable
四、部署Dify并应用DeepSeek模型
4.1、下载并配置Dify
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
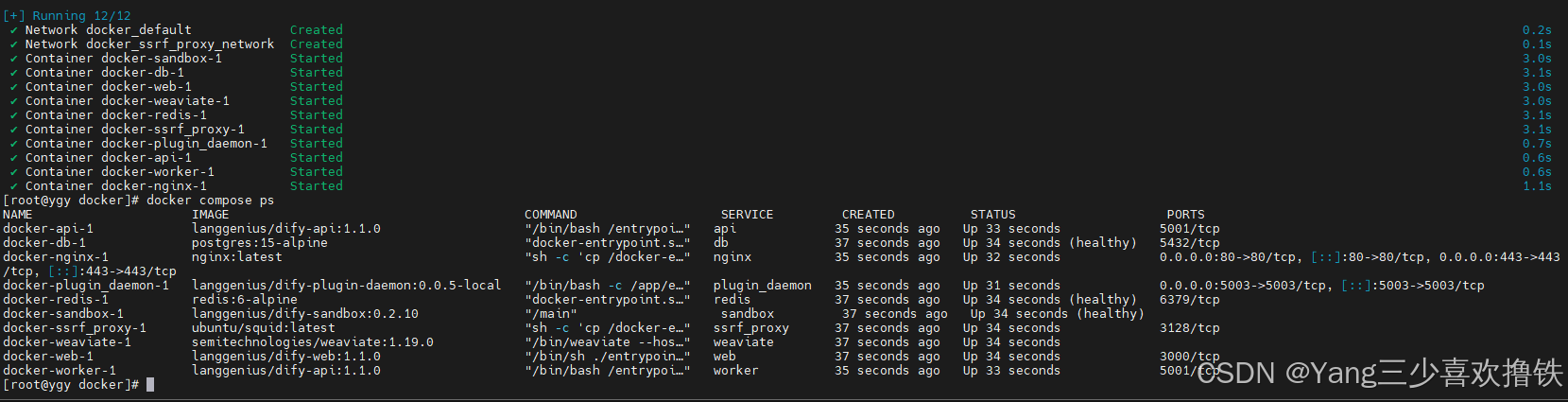
docker compose up -d
#查看容器状态
docker compose ps
4.2、设置账号并登录Dify
Dify 社区版默认使用 80 端口,点击链接 http://your_server_ip 即可访问你的私有化 Dify 平台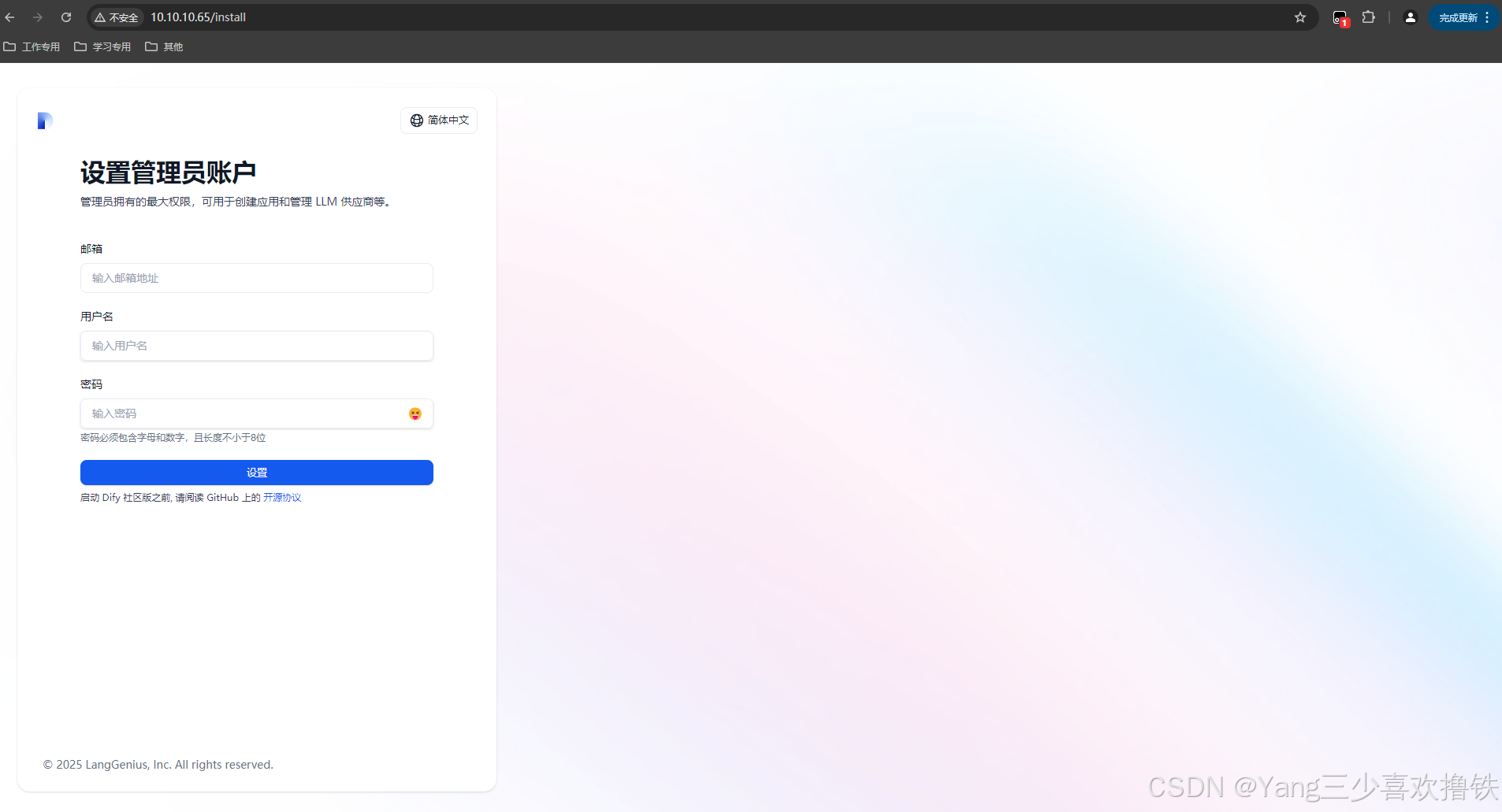
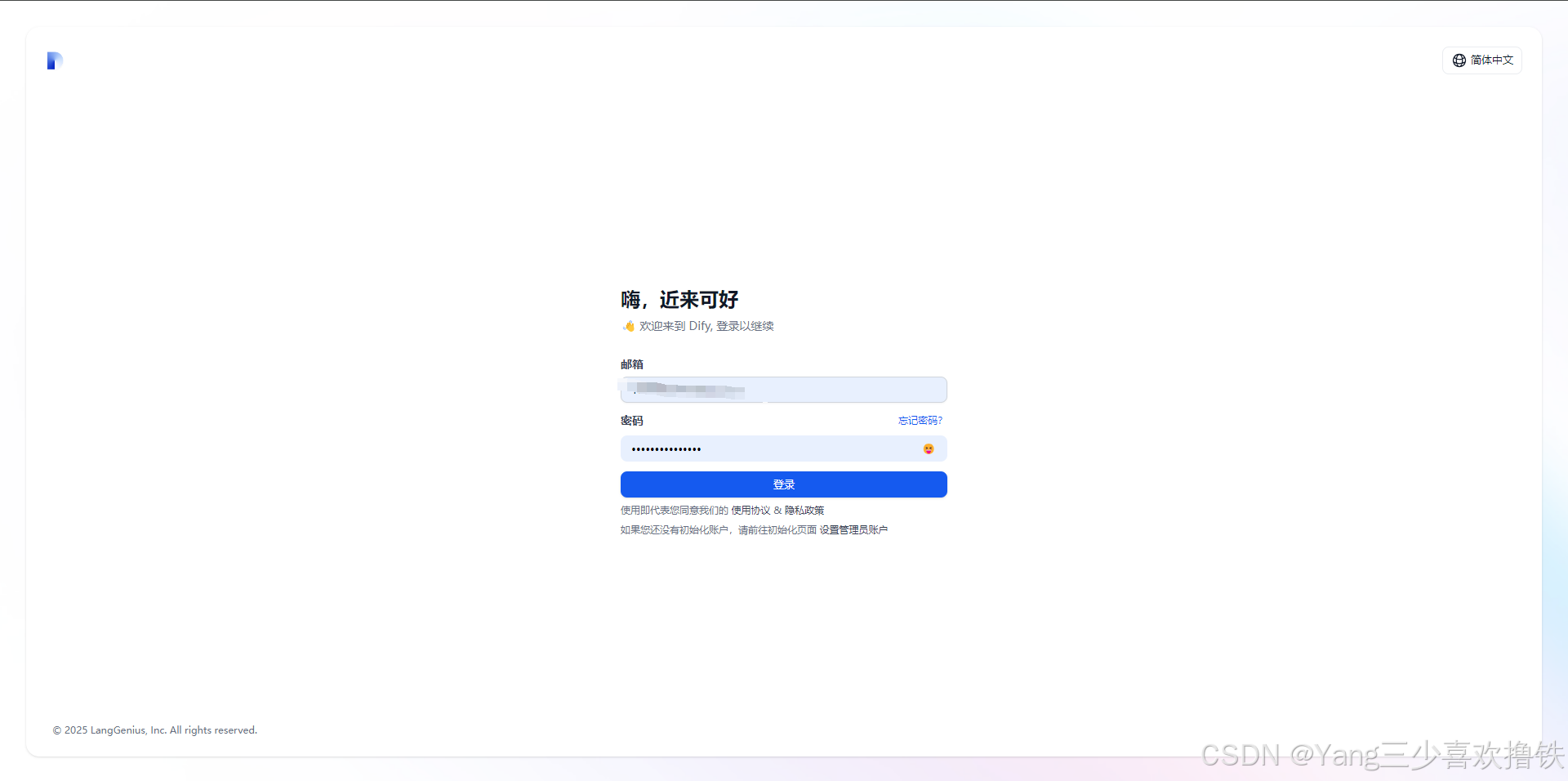
4.3、Dify集成DeepSeek-r1
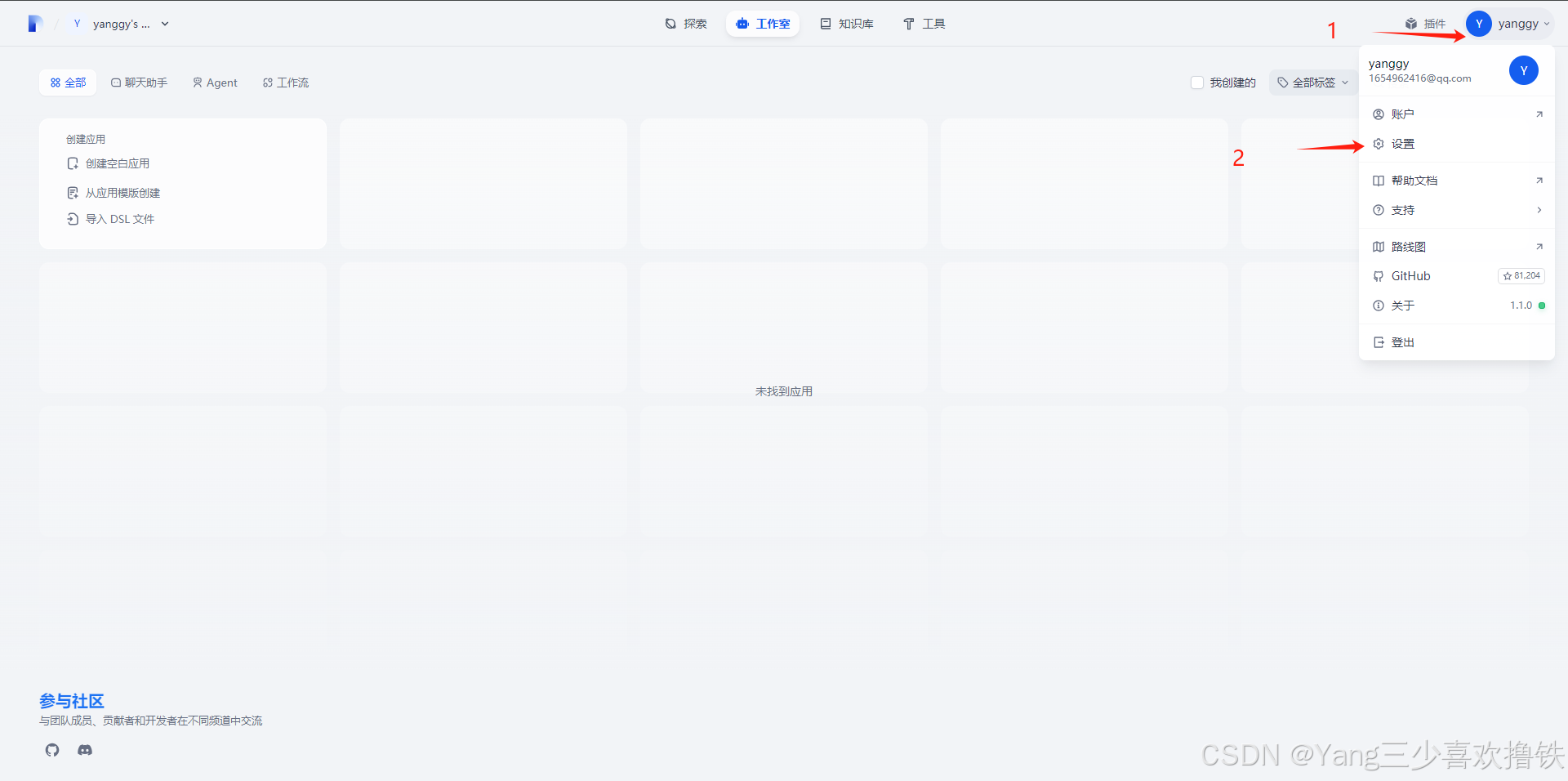
4.4、安装ollama并添加模型
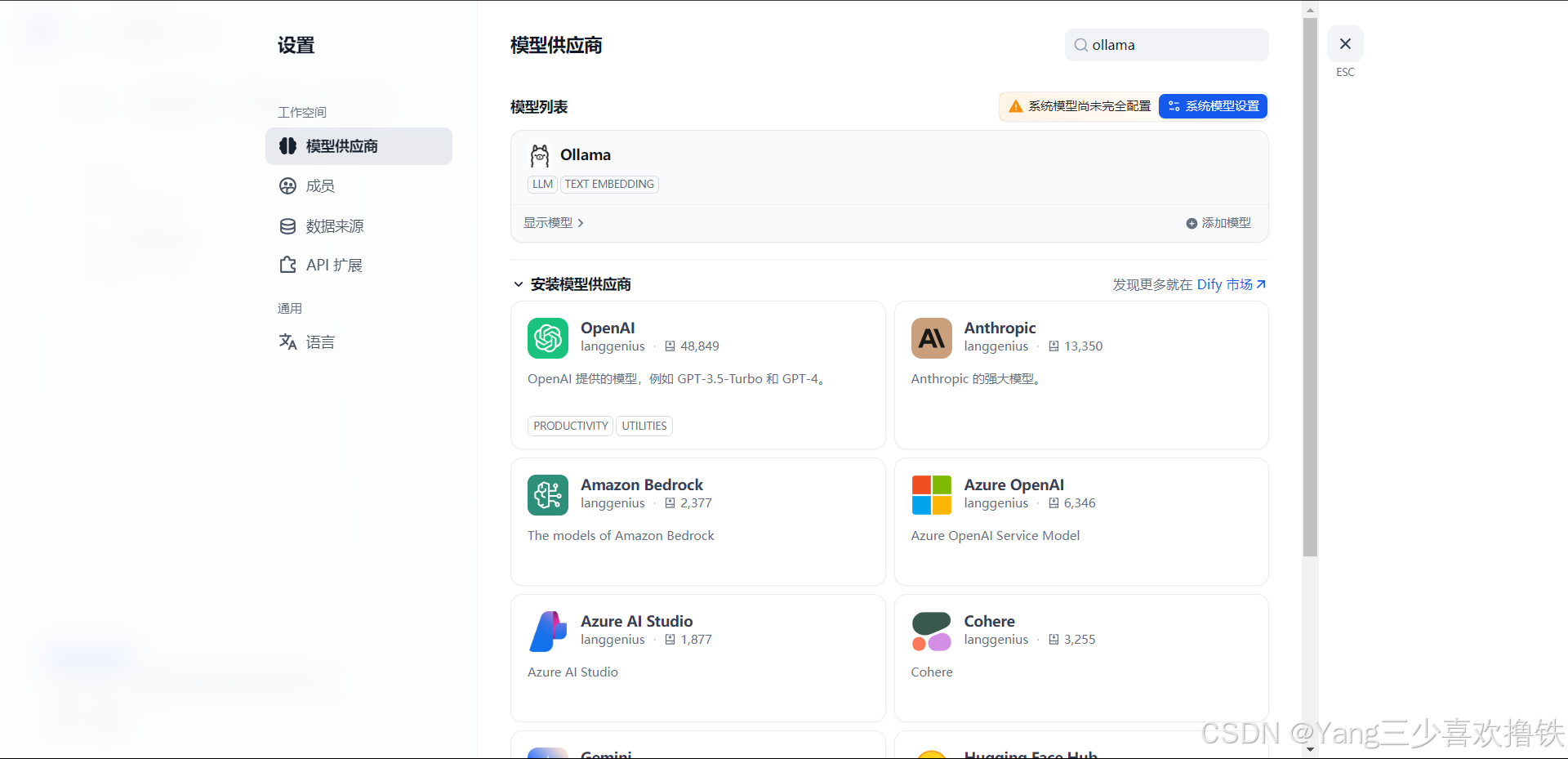
4.5、ollama集成Deepseek模型
模型供应商内的 DeepSeek 对应在线 API 服务;本地部署的 DeepSeek 模型对应 Ollama 客户端。请确保本地的 DeepSeek 模型已成功部署由 Ollama 客户端部署选择 LLM 模型类型。模型名称,填写具体部署的模型型号。上文部署的模型型号为 deepseek-r1 7b,因此填写 deepseek-r1:7b 基础 URL,填写 Ollama 客户端的运行地址,通常为 http://your_server_ip:11434。如遇连接问题,请参考常见问题。其它选项保持默认值。根据 DeepSeek 模型说明,最大生成长度为 32,768 Tokens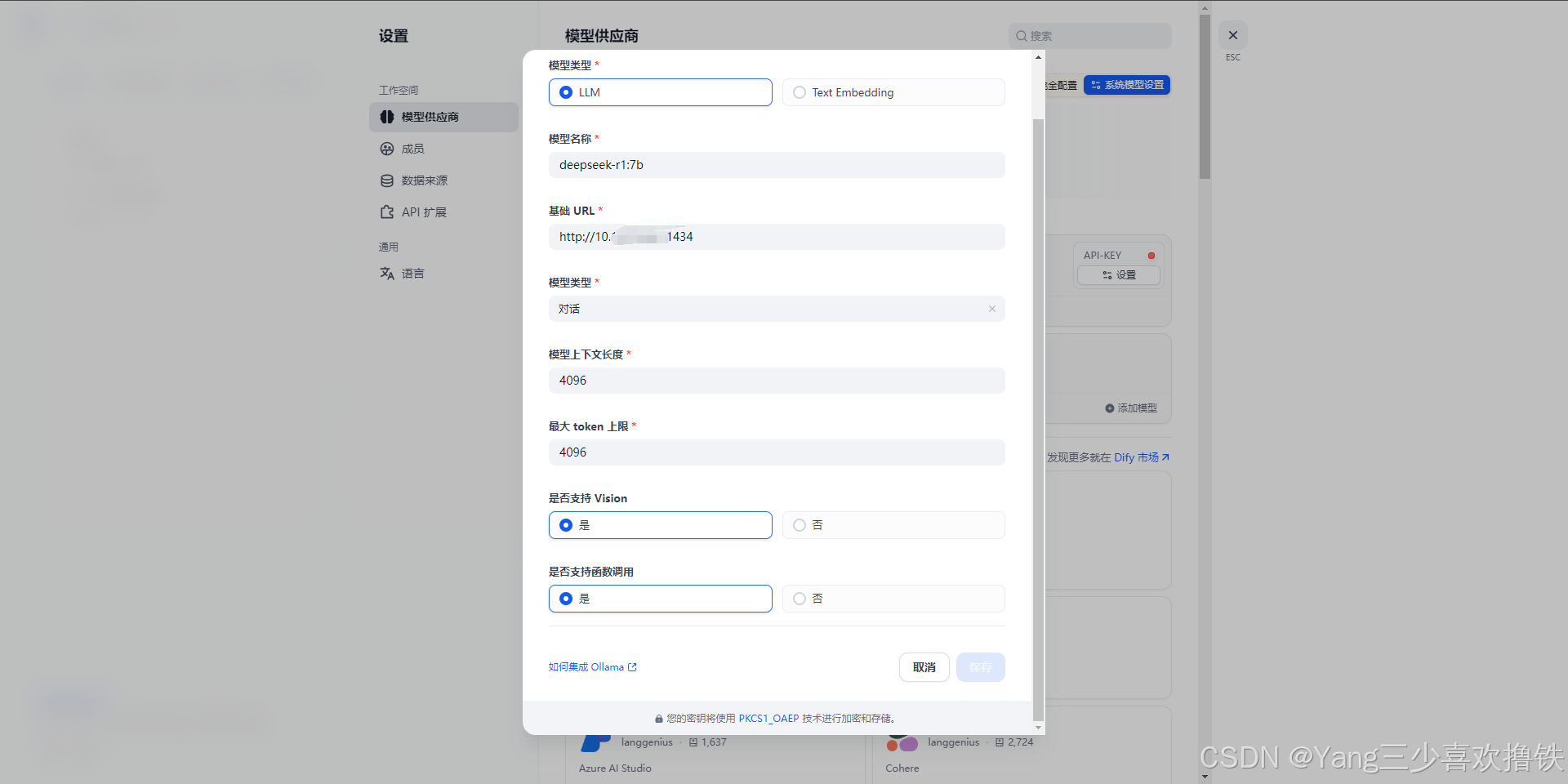
4.6、ollama集成bge-m3模型
选择Text Embedding类型,自定义名称,基础URl输入:http://your_server_ip:11434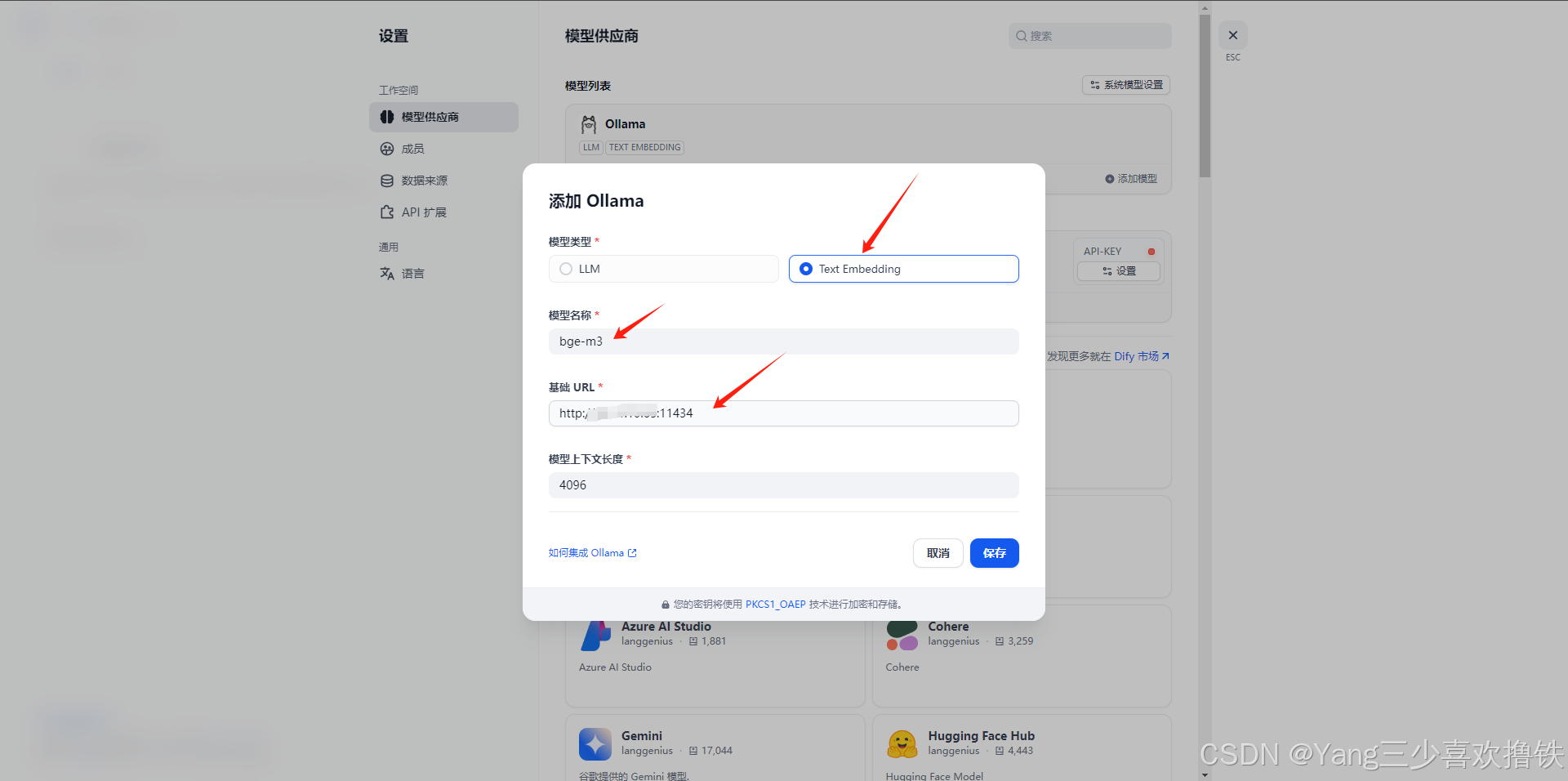
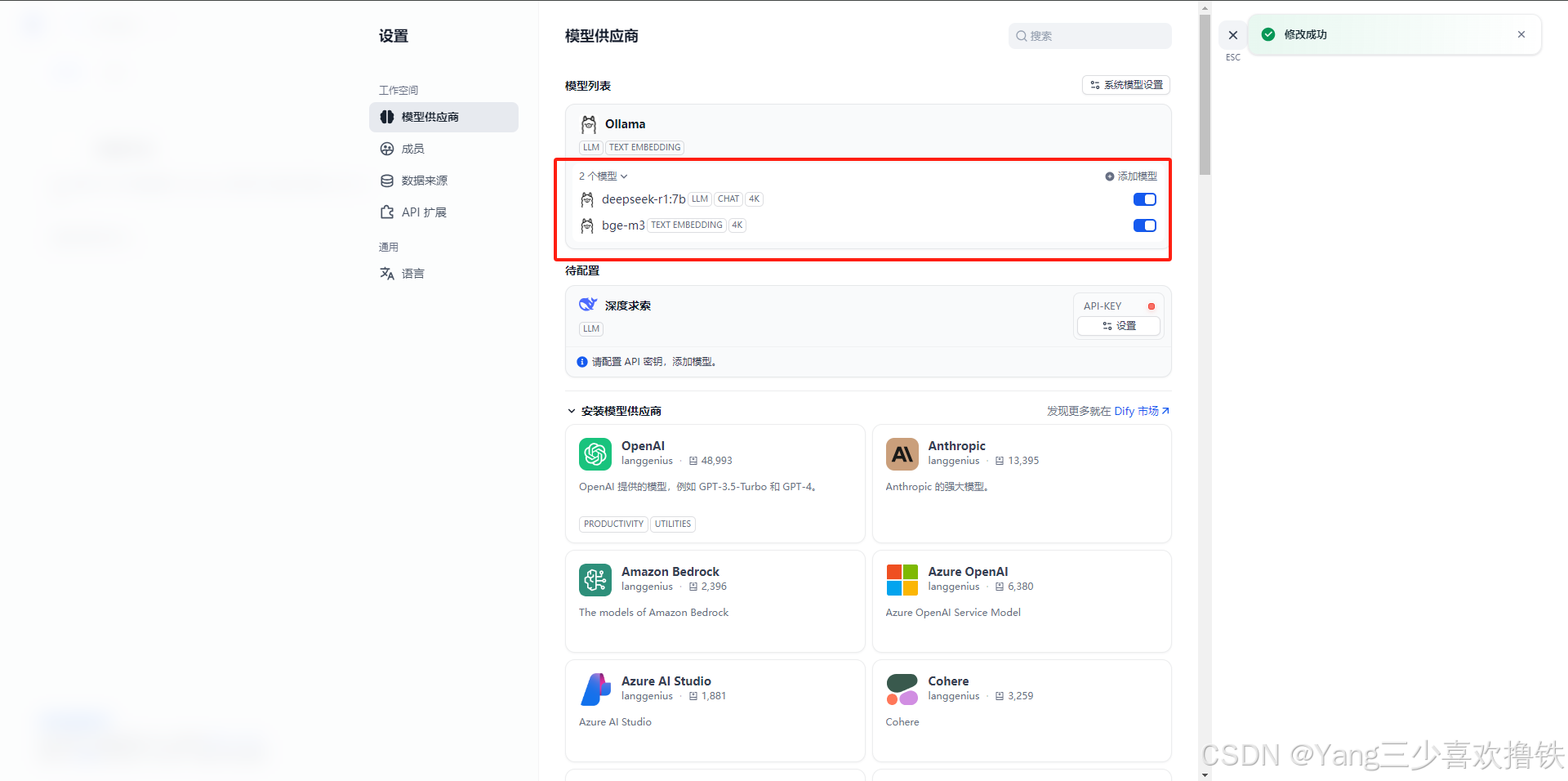
4.7、查看ollama集成模型
4.8、首页创建空白应用
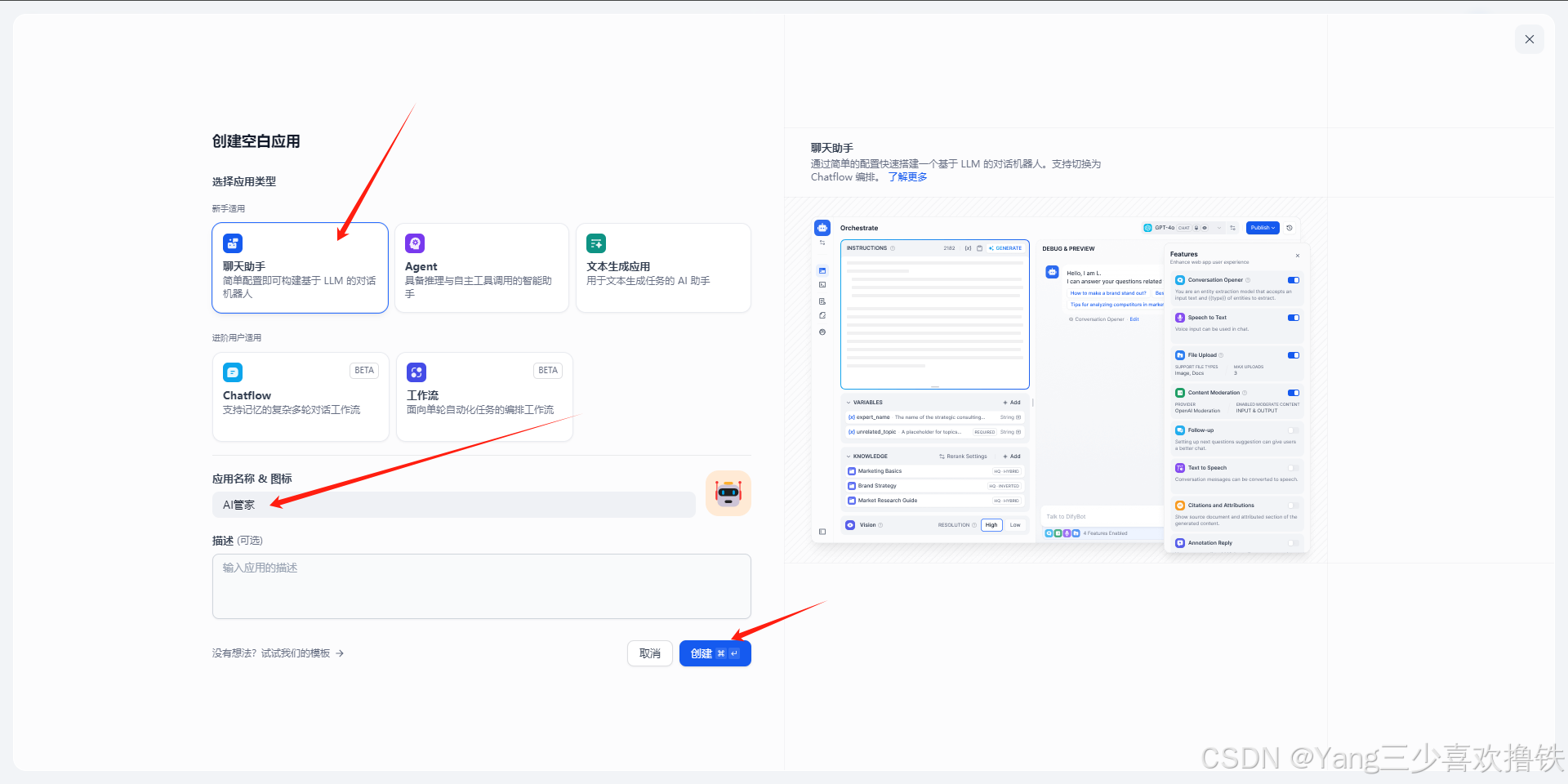
4.9、右上侧会自动选择部署好的AI模型
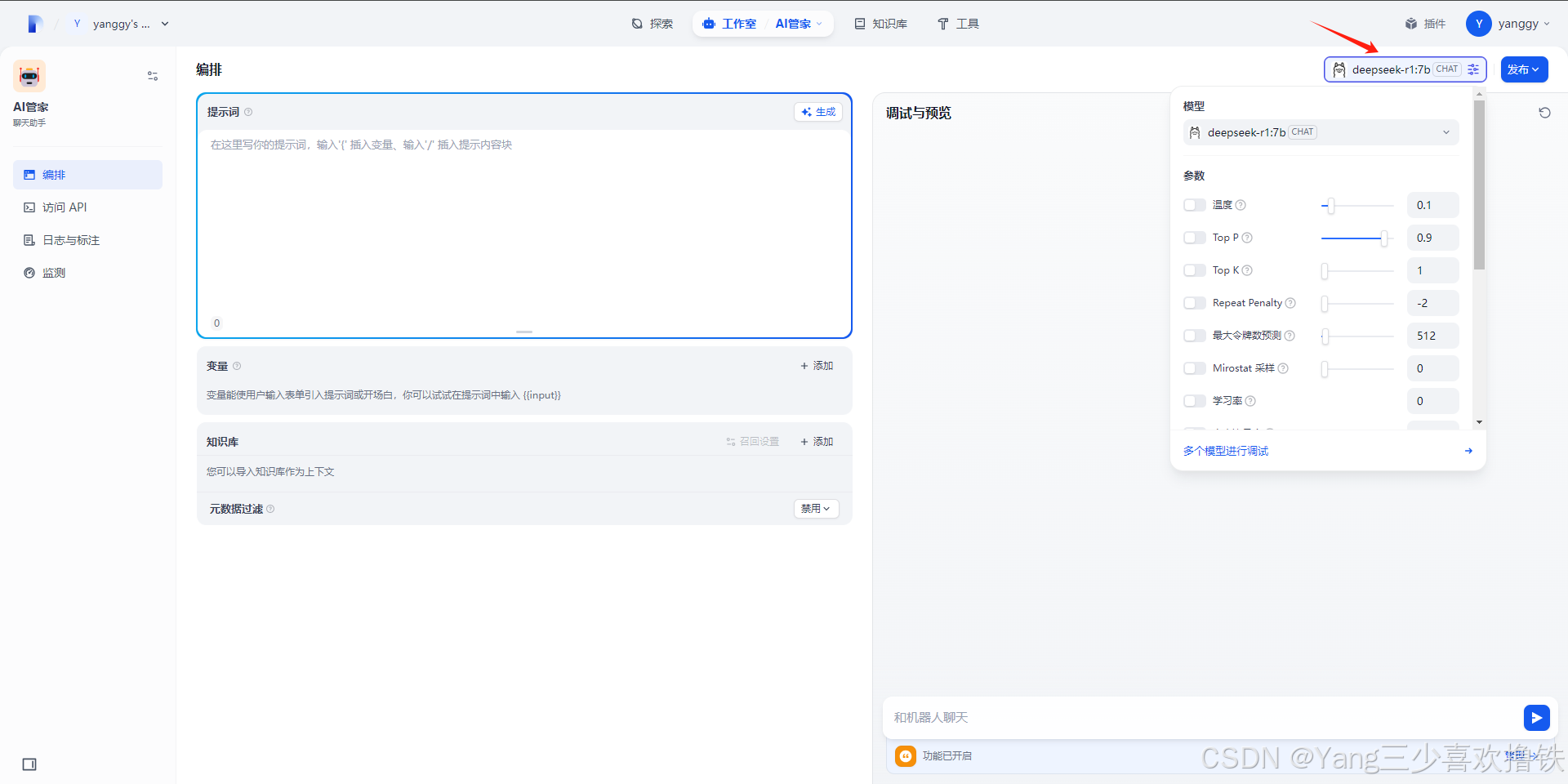
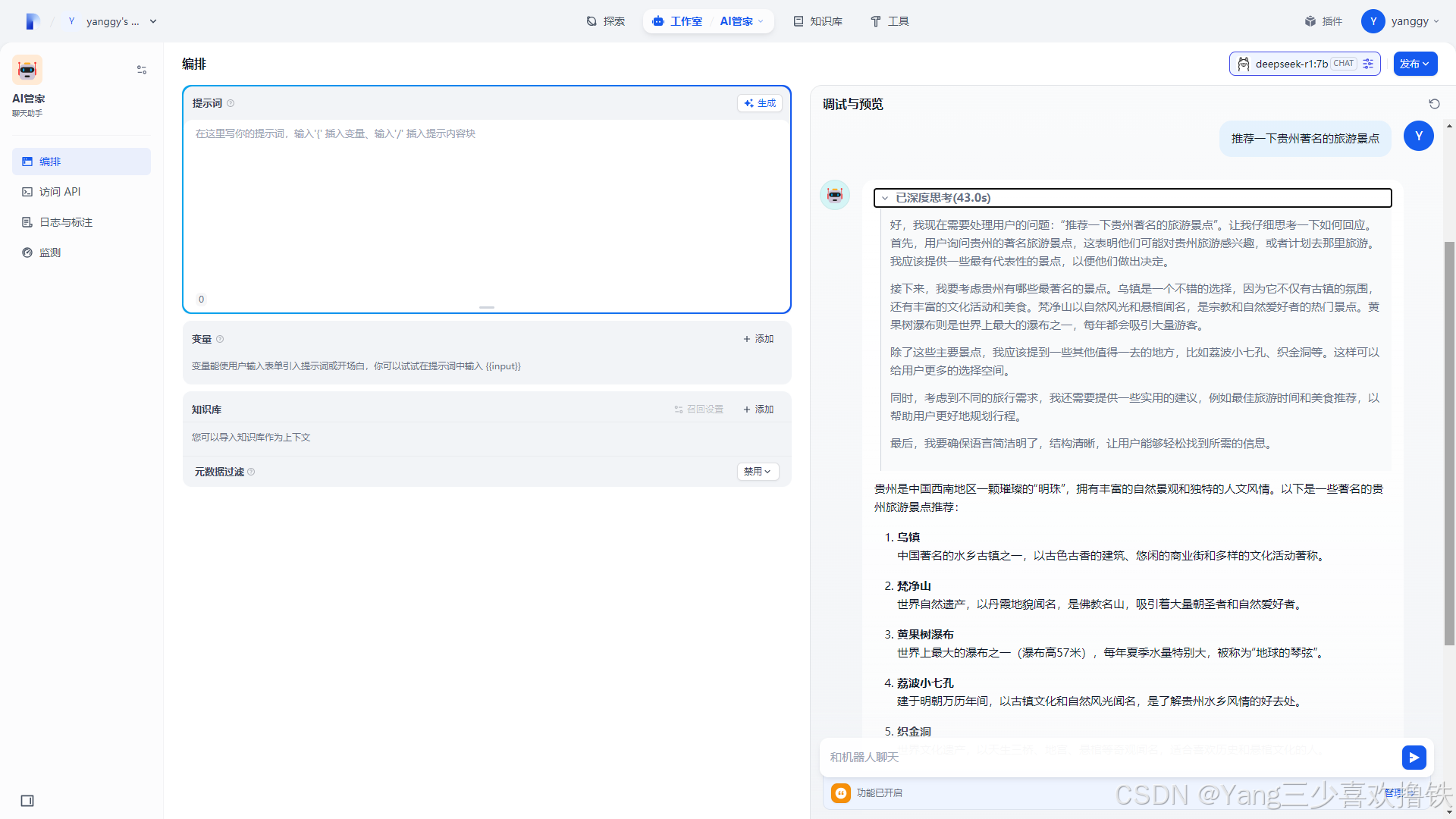
4.10、AI正常对话
4.11、创建进阶AI(Chatflow)
Chatflow / Workflow 应用可以帮助你搭建功能更加复杂的 AI 应用,例如具备文件识别、图像识别、语音识别等能力
轻点 Dify 平台首页左侧的"创建空白应用",选择"Chatflow" 类型应用并进行简单的命名。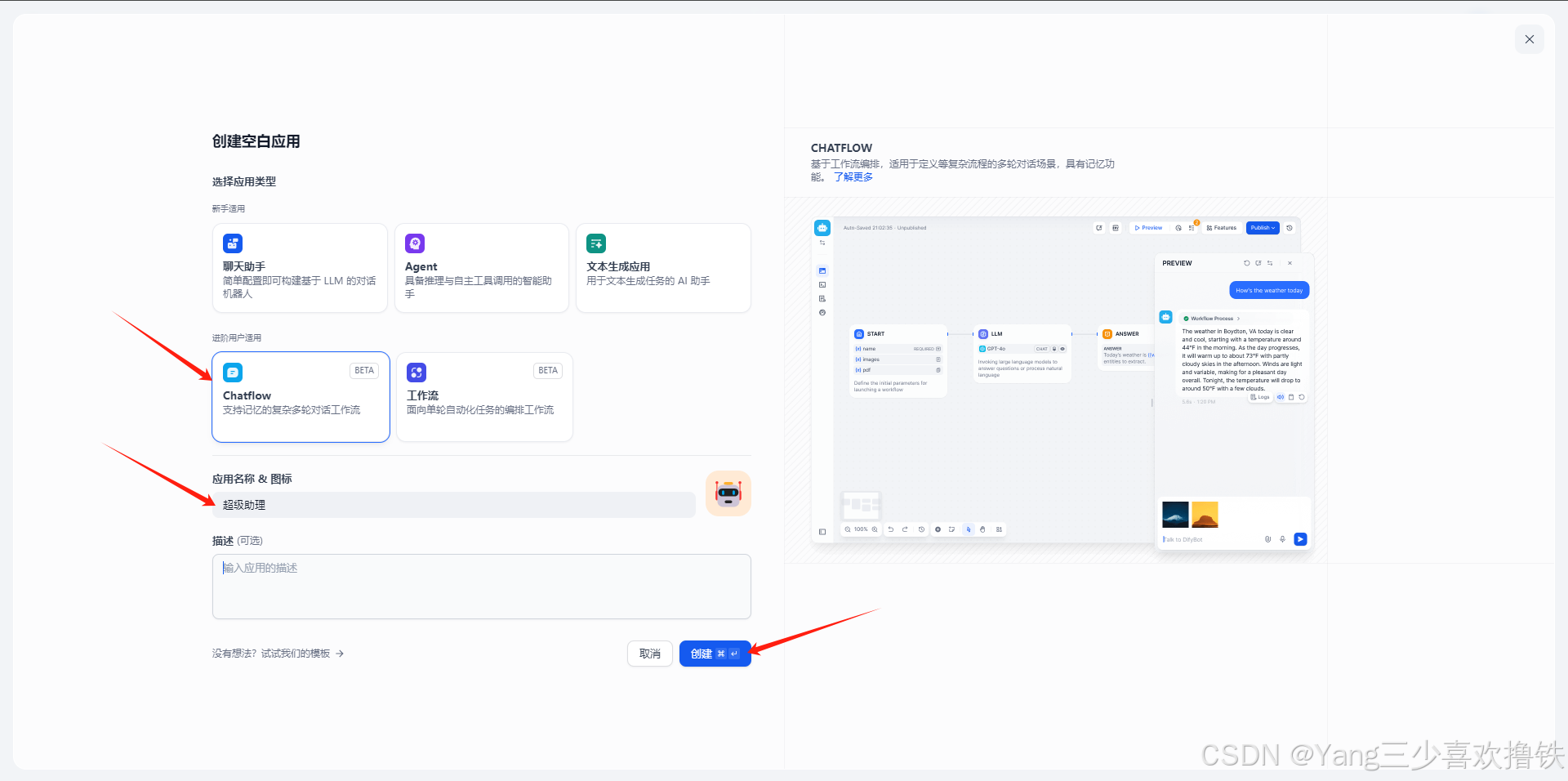
添加 LLM 节点,选择 Ollama 框架内的 deepseek-r1:7b 模型,并在系统提示词内添加 {{#sys.query#}} 变量以连接起始节点。如遇 API 异常,可以通过负载均衡功能或异常处理节点进行处理。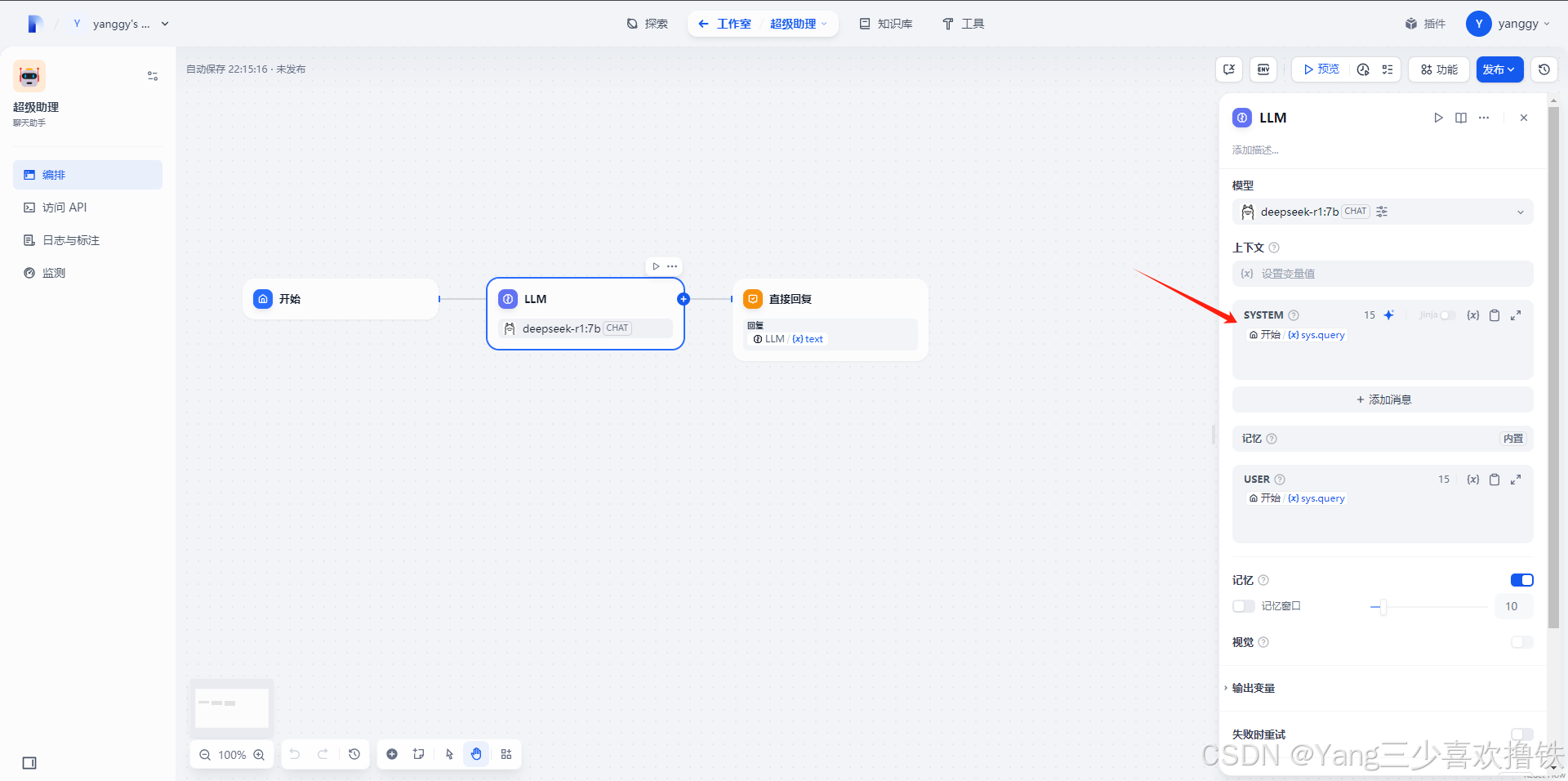
添加结束节点完成配置。可以点击预览并在对话框中输入内容以进行测试。生成答复后意味着 AI 应用的搭建已完成。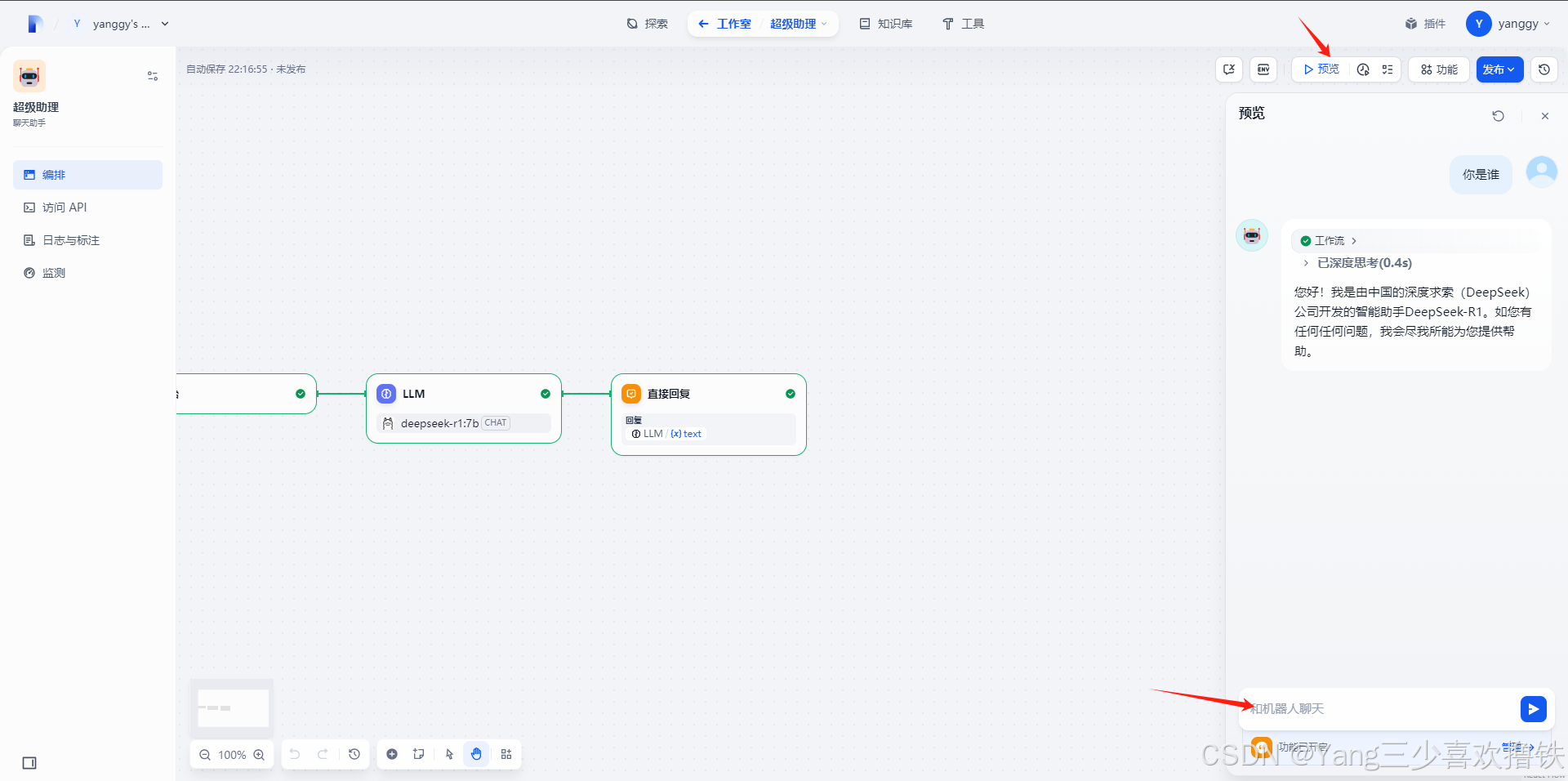
最后点击发布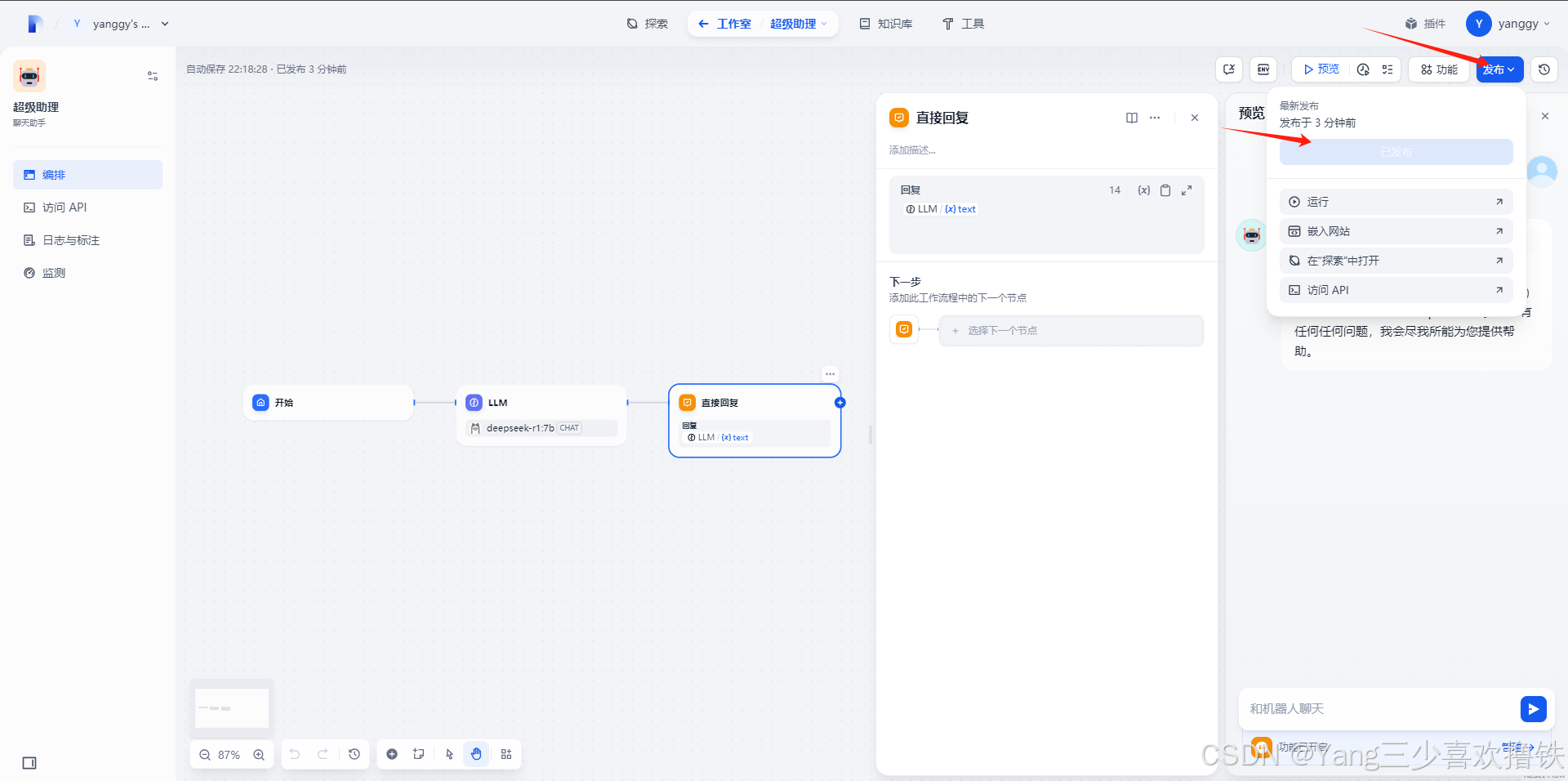
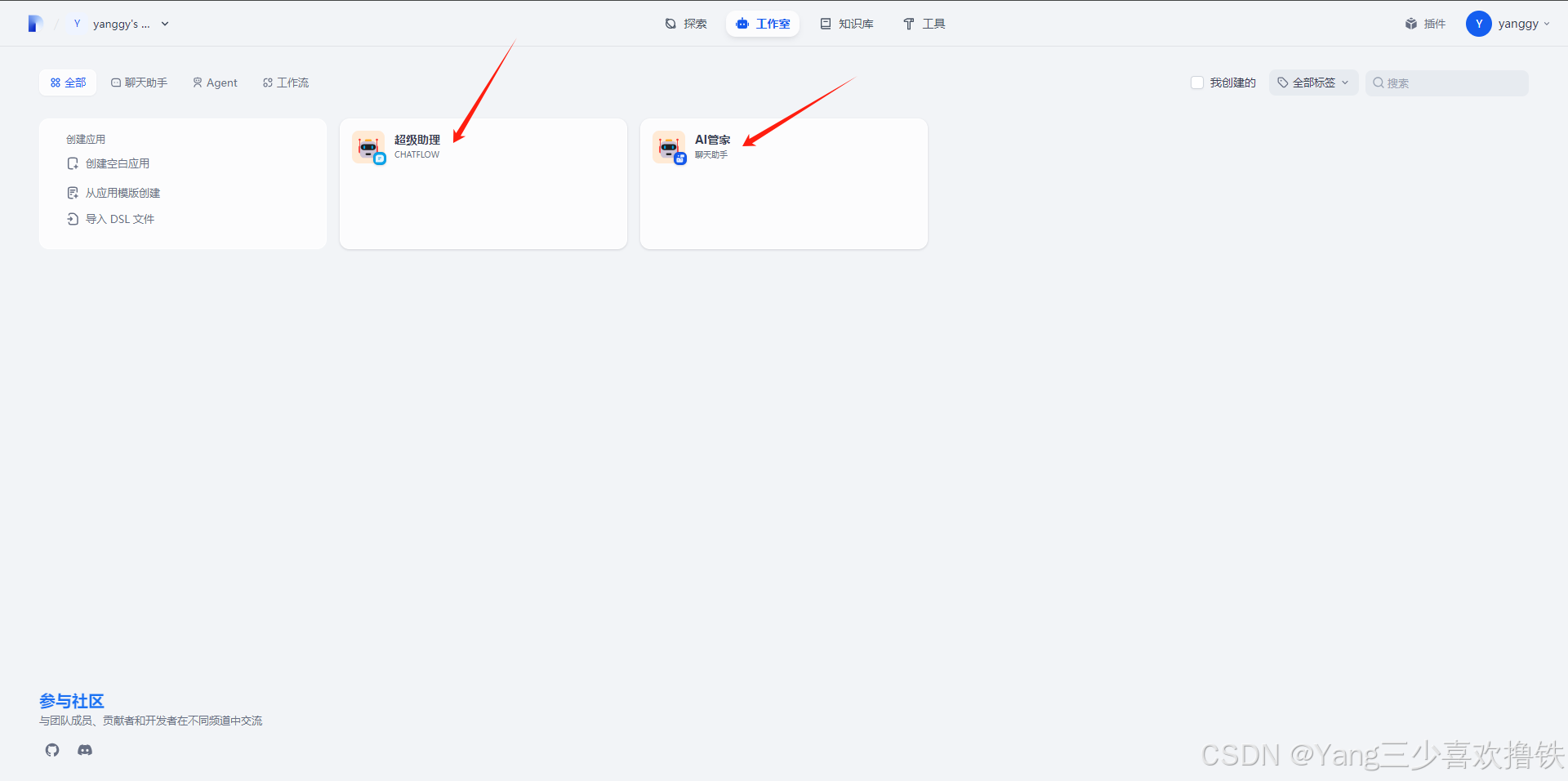
4.12、首页显示创建好的AI助理
五、部署知识库
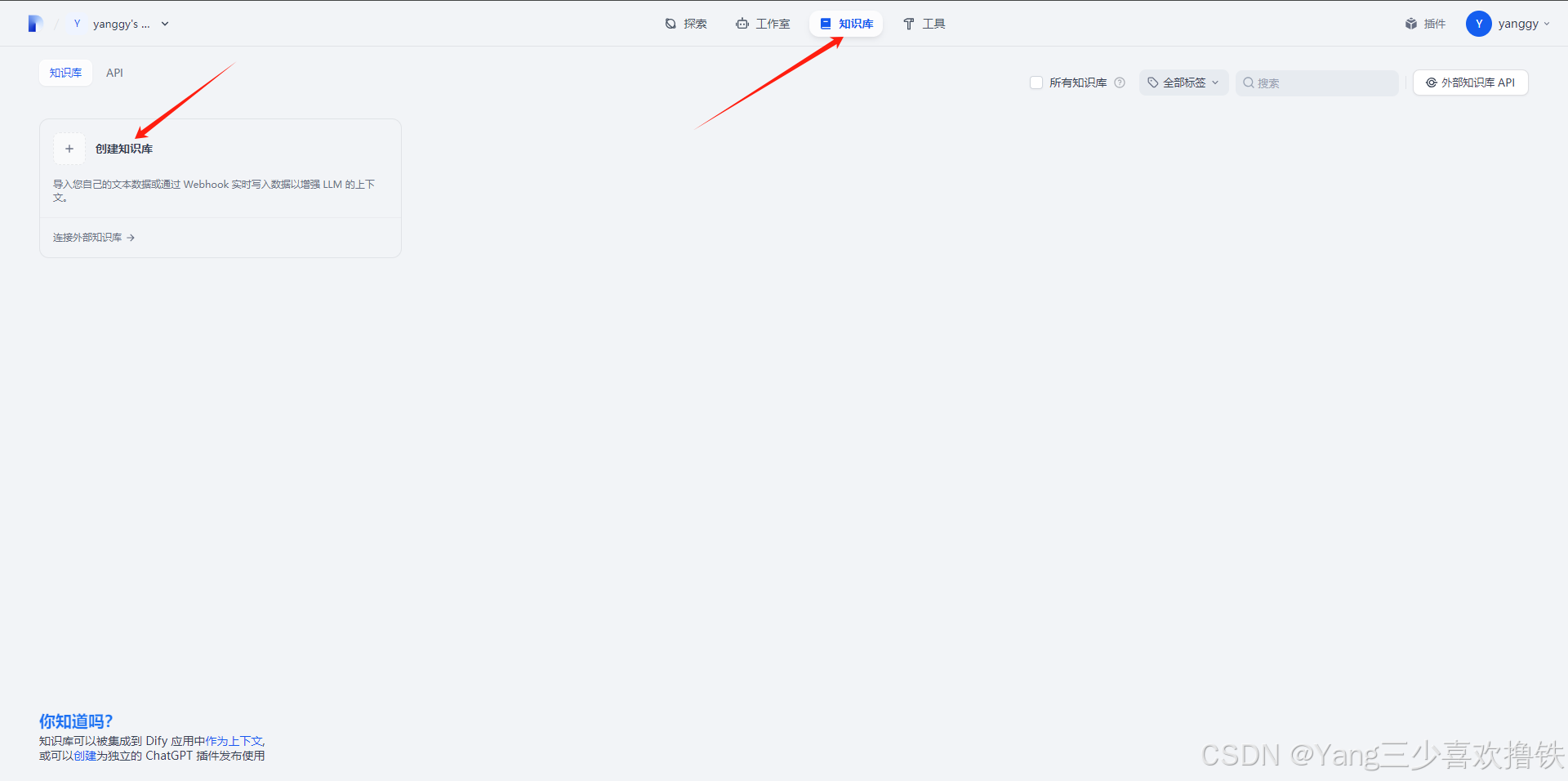
5.1、点击创建知识库
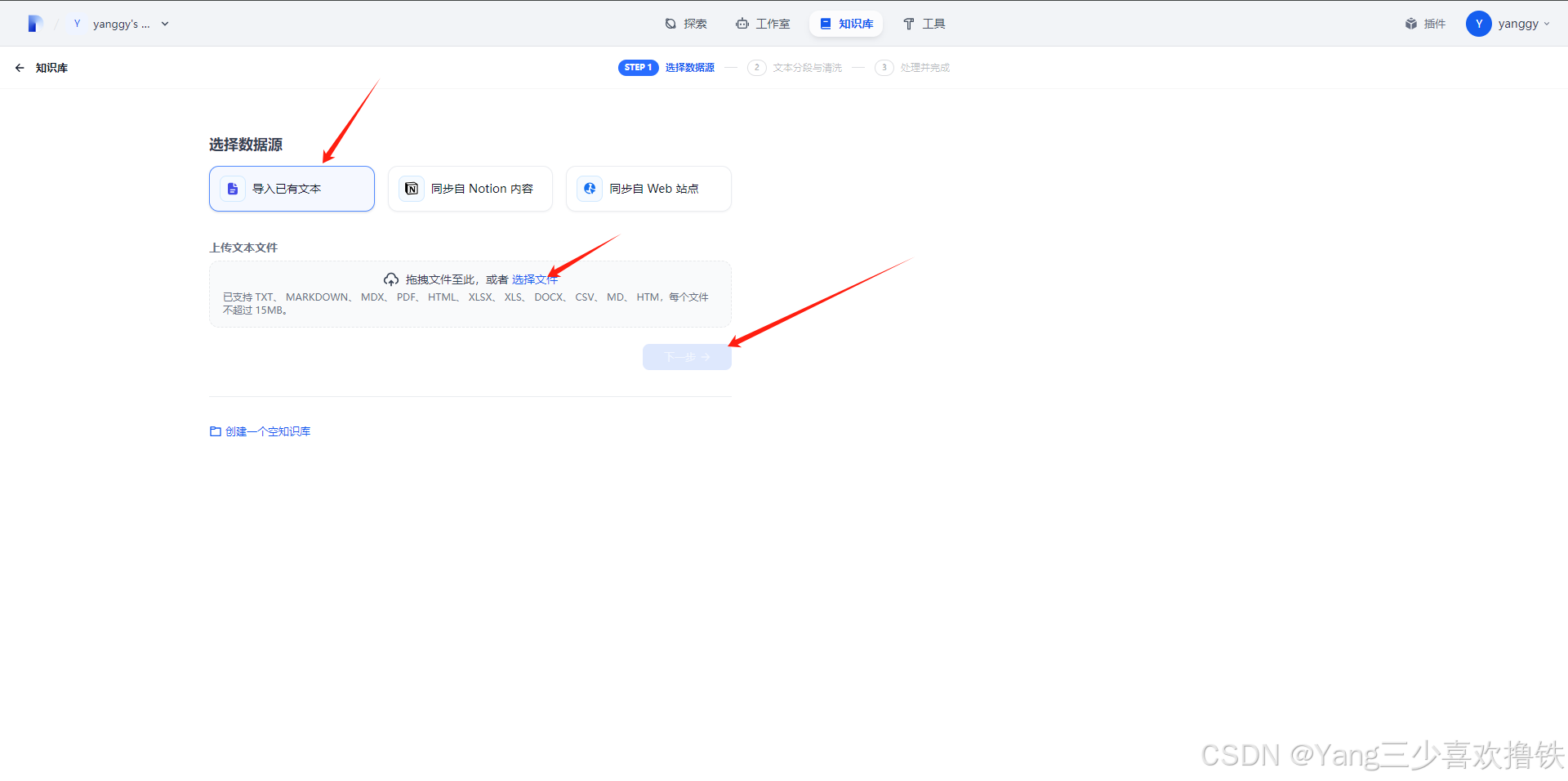
5.2、导入文本数据源
5.3、配置数据预处理
索引方式选择高质量,Embedding 模型会自动选择bge-m3,其他配置可以根据自己需求选择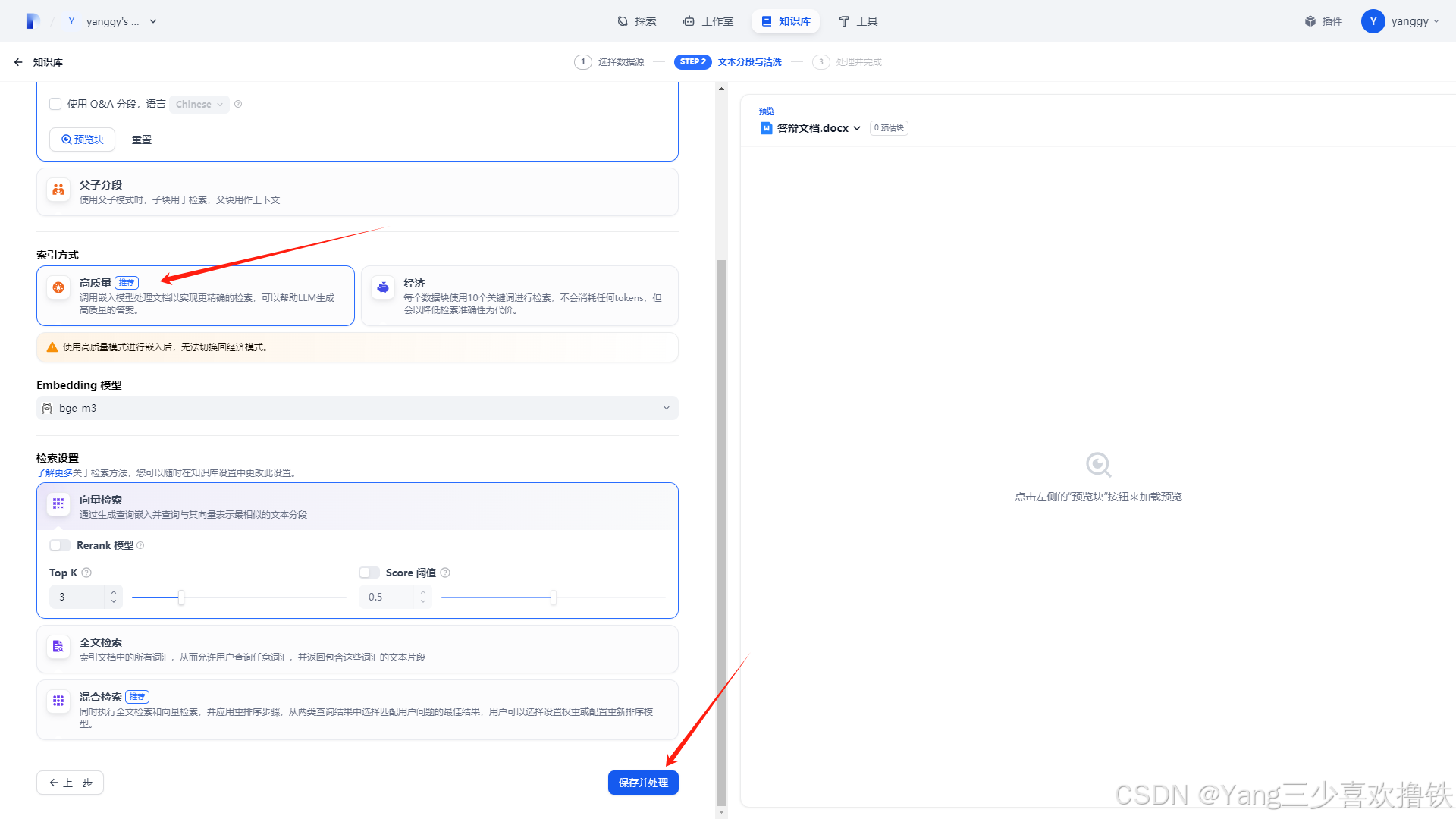
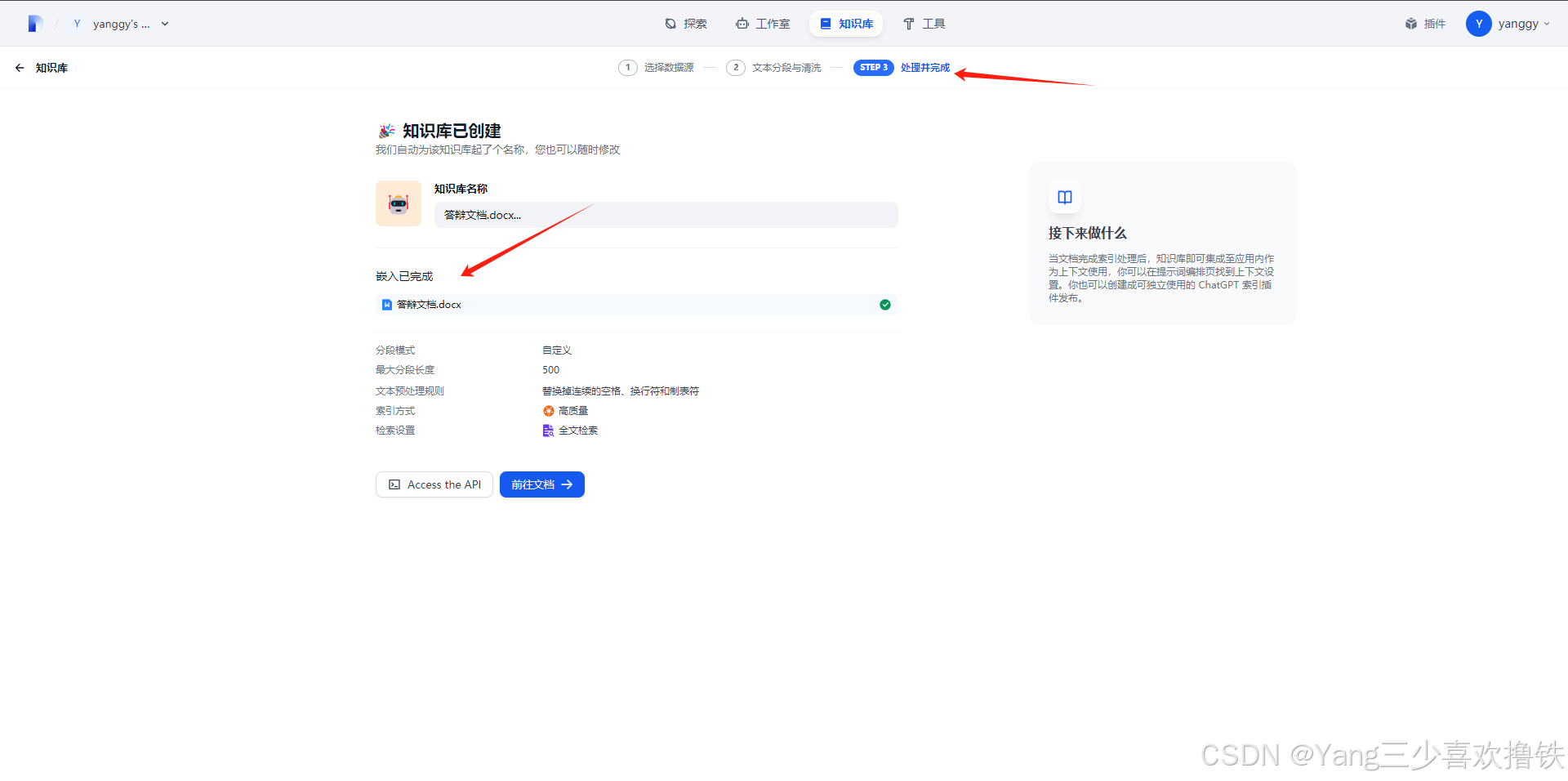
5.4、显示处理完成
5.5、首页选择创建好的AI管家
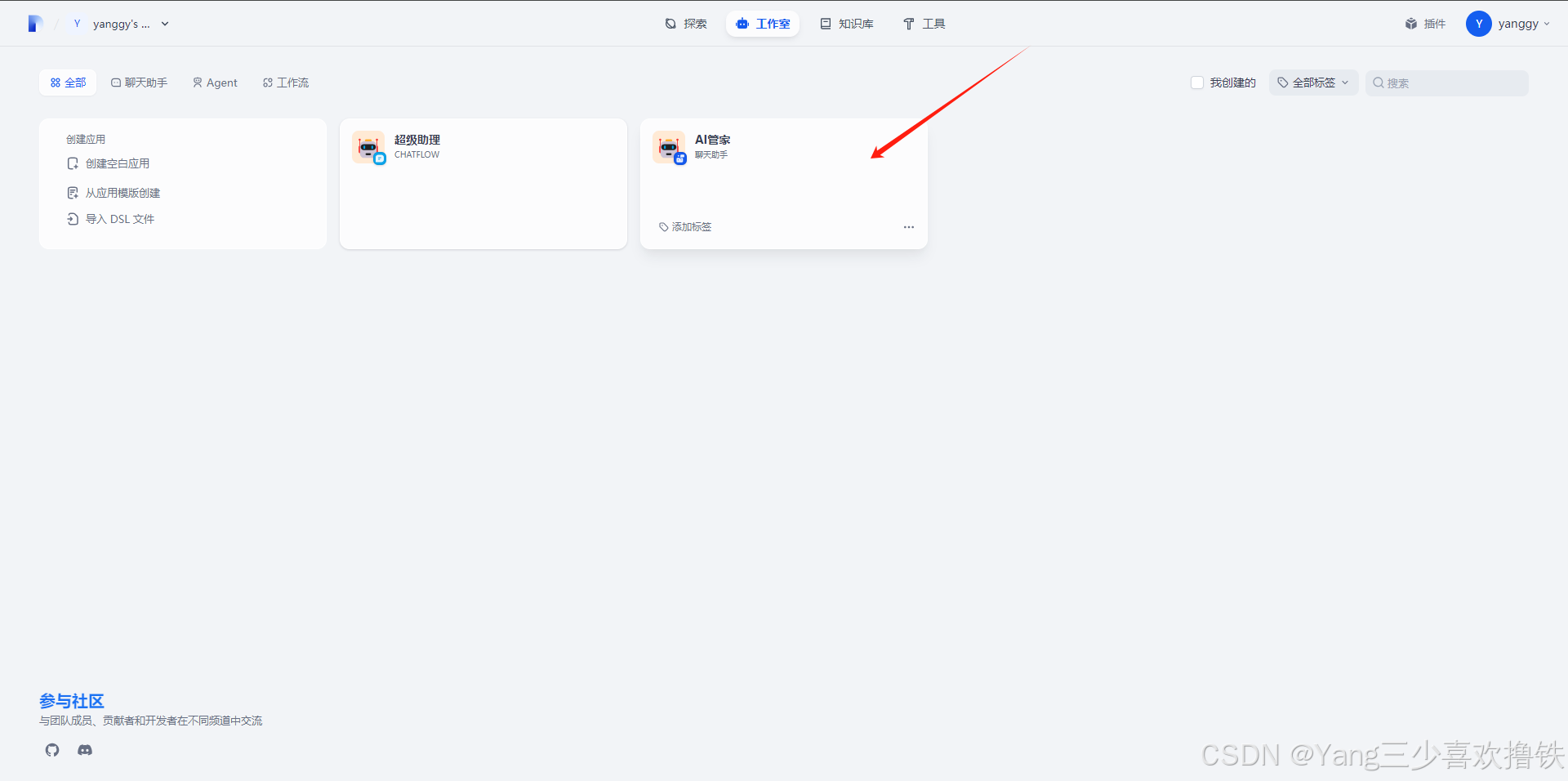
5.6、配置知识库的数据源
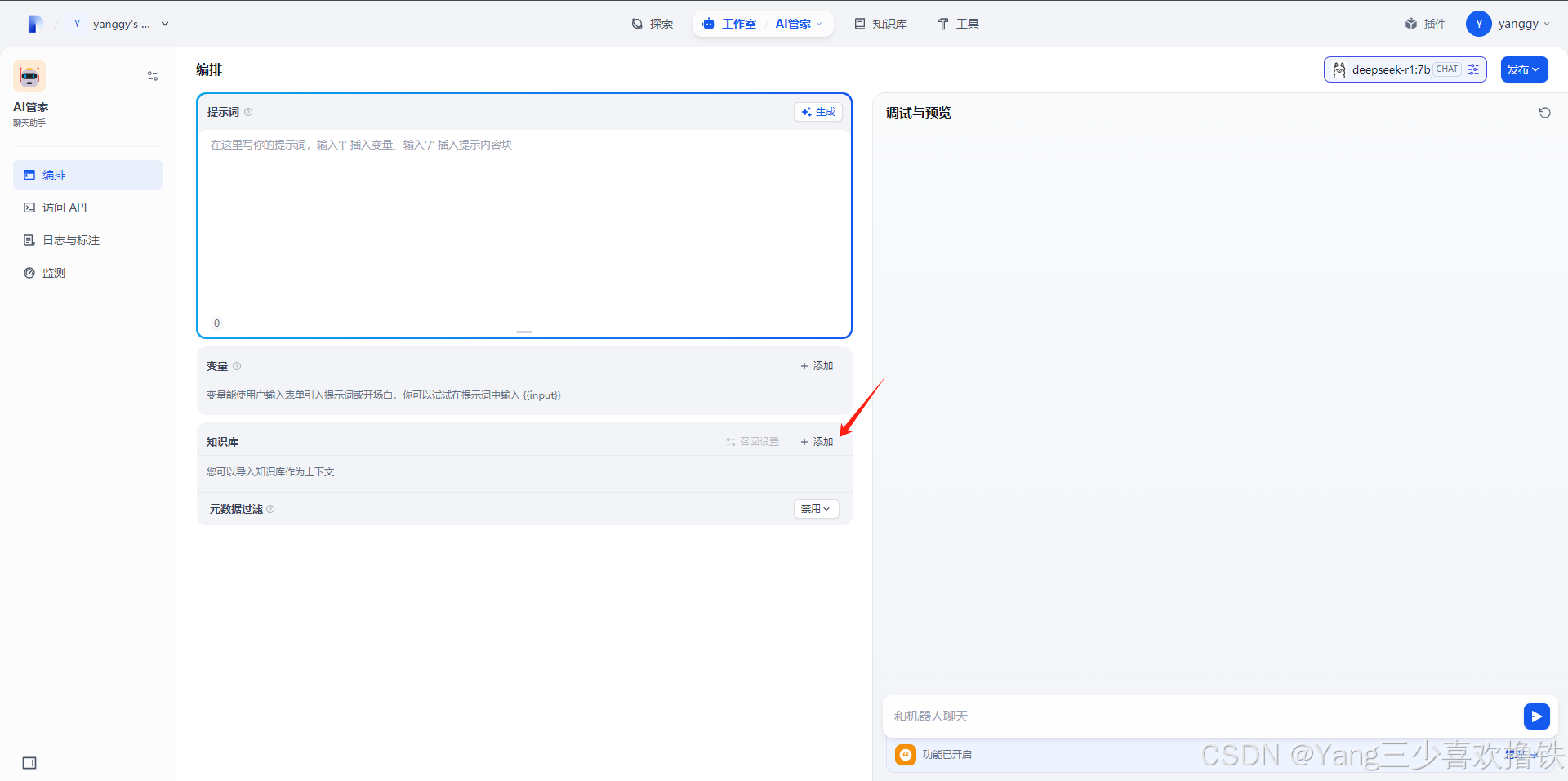
5.7、点击导入文本并添加
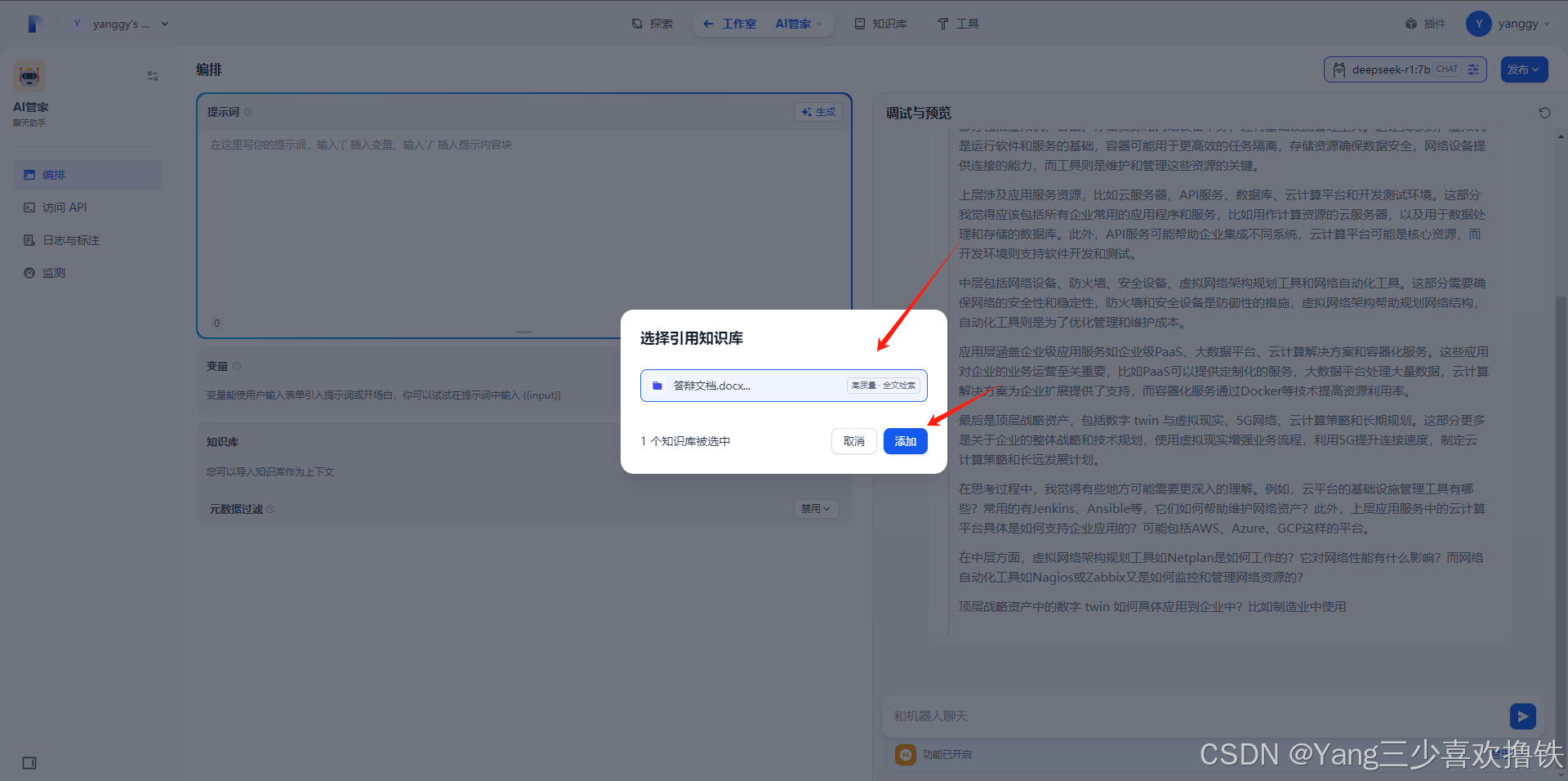
5.8、点击重新开始
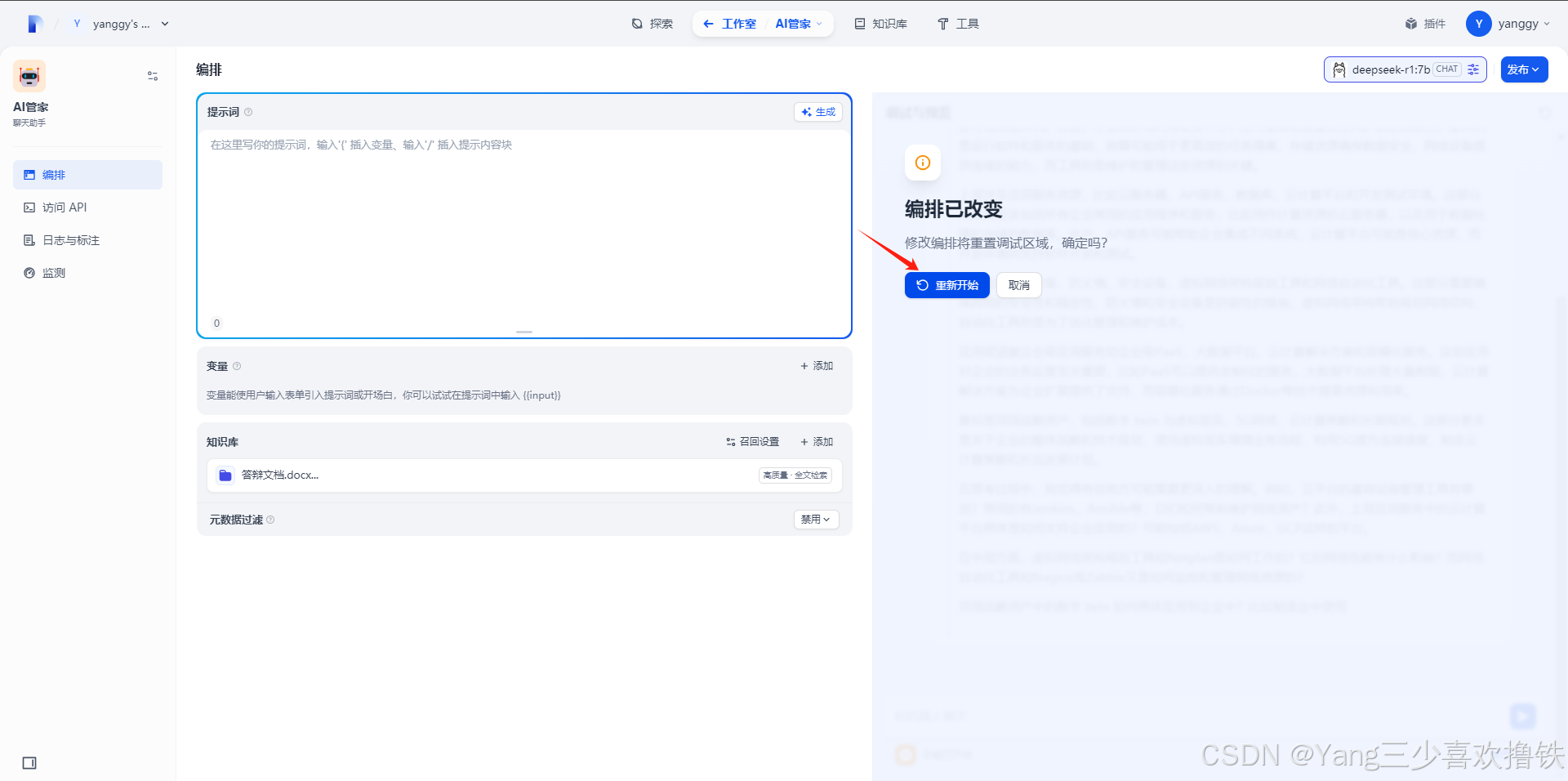
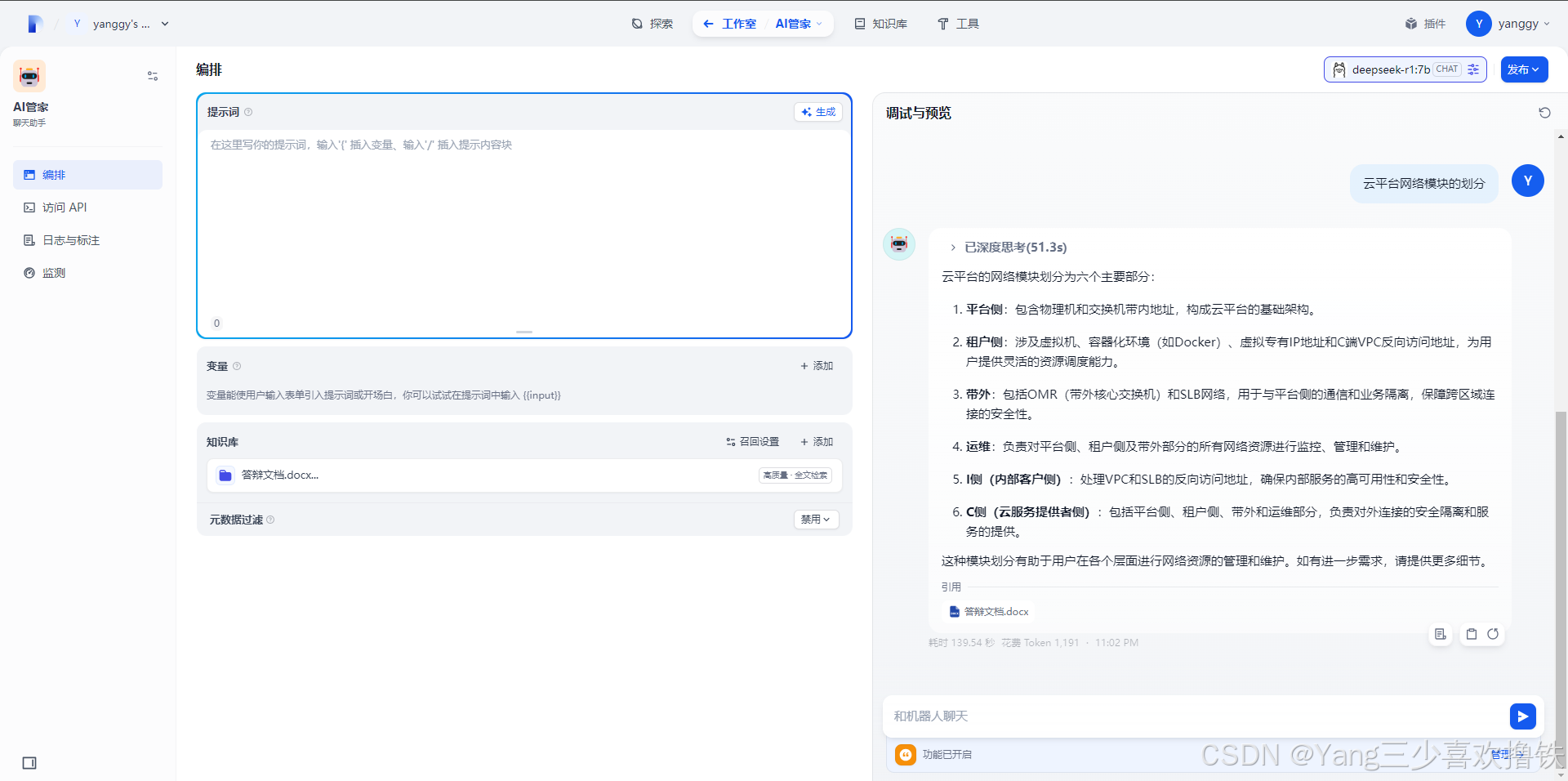
5.9、知识库AI管家配置成功
总结
提示:知识库管家可能会存在乱回答的问题,需要更进一步的去调整配置参数
本文共创建了两个AI助理,“AI管家”主要用于知识库方面;“超级助理”主要用于AI涉及的所有领域,解决个人需求问题,帮助人们在生活中更加简便处理事务。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 62
62 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)