大模型知识引擎 | 如何一站式快速构建智能客服
在ChatGPT和DeepSeek未出现之前,智能这个词的概念已经逐渐展现在运营商的各个领域。其整体业务流程是通过在掌上营业厅预置一些比较常见的套餐、流量问题,去引导客户触发这些问题。当下是AI的时代,未来是AI Agent的时代,在大模型知识引擎构建智能客服的过程中,感受了低代码的魅力,除了卓越的UI交互体验,简单易懂的功能也使我从零基础快速入门上手。对于普通开发者来说,腾讯云大模型知识引擎提供
前言
在ChatGPT和DeepSeek未出现之前,智能这个词的概念已经逐渐展现在运营商的各个领域。其整体业务流程是通过在掌上营业厅预置一些比较常见的套餐、流量问题,去引导客户触发这些问题。
智能客服
例如,在进入对话页的时候,会弹出很多预设的问题。如果我们点击或者输入这些问题,就会触发电话回访预约。
痛点
如果我们输入的问题与预设的问题不符合,那么就会引导用户朝着设定好的问题上靠拢,然后触发电话回访预约。我们可以看到在智能客服业务流程中,因为智能客服的后台只做数据采集,识别用户问题中的关键字,但是当我们问到一些日常故障的问题,智能客服就无法回复用户提出的问题。
所以,我们的目标是构建一个既能满足现有预约业务场景,也能准确理解客户问题的智能客服。
解决方案
在 DeepSeek 未出现之前,我们考虑最多的是,到底什么样的技术选型才能让智能客服变得更“智能”。在 DeepSeek 出现之后,就开始考虑如何在DeepSeek赋予更多的能力,并能满足以下的需求:
- 高效:快速响应客户咨询,减少客户等待时间
- 精准:准确理解客户问题,提供针对性解决方案
- 可扩展:系统可灵活扩展,适应业务增长和变化
所以单单只靠 DeepSeek 大模型是无法完成上面要求的,后来了解到腾讯云的大模型知识引擎 LKE,于是开始尝试是否可以满足智能客服的构建需求。
大模型知识引擎 LKE
大模型知识引擎(LLM Knowledge Engine)是基于大语言模型的知识应用构建平台,可以通过知识库的构建,来结合企业专属数据,提供知识问答等应用范式,更快更高效地完成大模型应用的构建,推动大语言模型在企业服务场景的应用落地。

产品优势
在DeepSeek的热度浪潮下,市场上涌现了很多基于DeepSeek构建大模型应用的产品,而选择LKE的的原因在于:

- 高效搭建大模型应用:提供大模型应用构建工作台,同时提供公有云和私有化两个版本,无需下载任何软件,在浏览器中克随时随地完成大模型应用的搭建。
- 复杂知识处理能力强:基于混元大模型技术及多行业丰富高质量数据训练,内置 OCR、LLM+RAG 、MLLM 等多种技术能力,对复杂的非结构化图文类文档进行准确智能解析,提升知识提取质量和效率。
- 配套工具链完善:开放模型配置、知识配置等配套工具链,提供最小的必要输入即可获得良好的效果,支持测试 - 修正 - 发布 - 反馈增强的一站式流程。
体验中心
目前LKE开放了产品体验服务,在LKE主页点击产品体验,即可进入LKE体验中心。
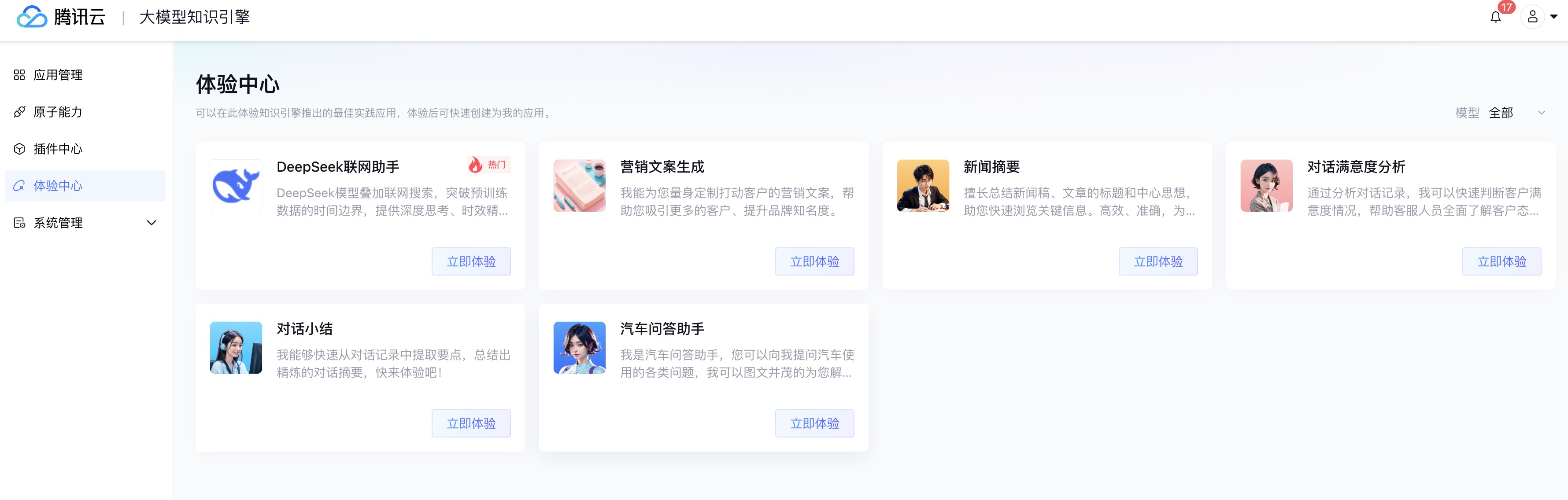
提供了很多优秀的大模型应用,点击立即体验即可使用大模型应用。

如果想要借鉴大模型应用的构建过程,或者这些大模型应用的基础上构建自己的应用,可以通过点击对话页面上方的 创建为我的应用 按钮,这样在 应用管理 下就可以看到刚刚“复制”的应用。
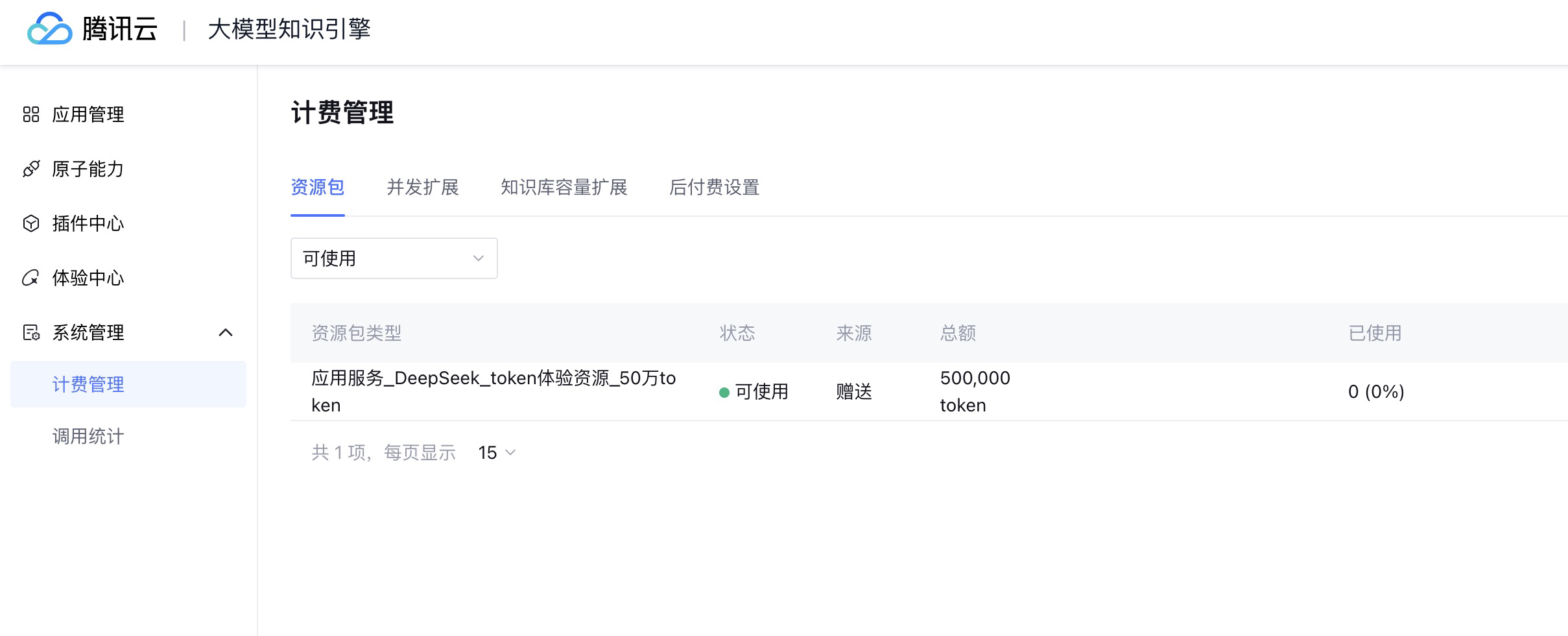
资源计费
关于资源计费,很多人会担心在体验或者测试过程中消耗token产生费用,目前LKE为公测阶段,开通体验即可获得token免费额度。
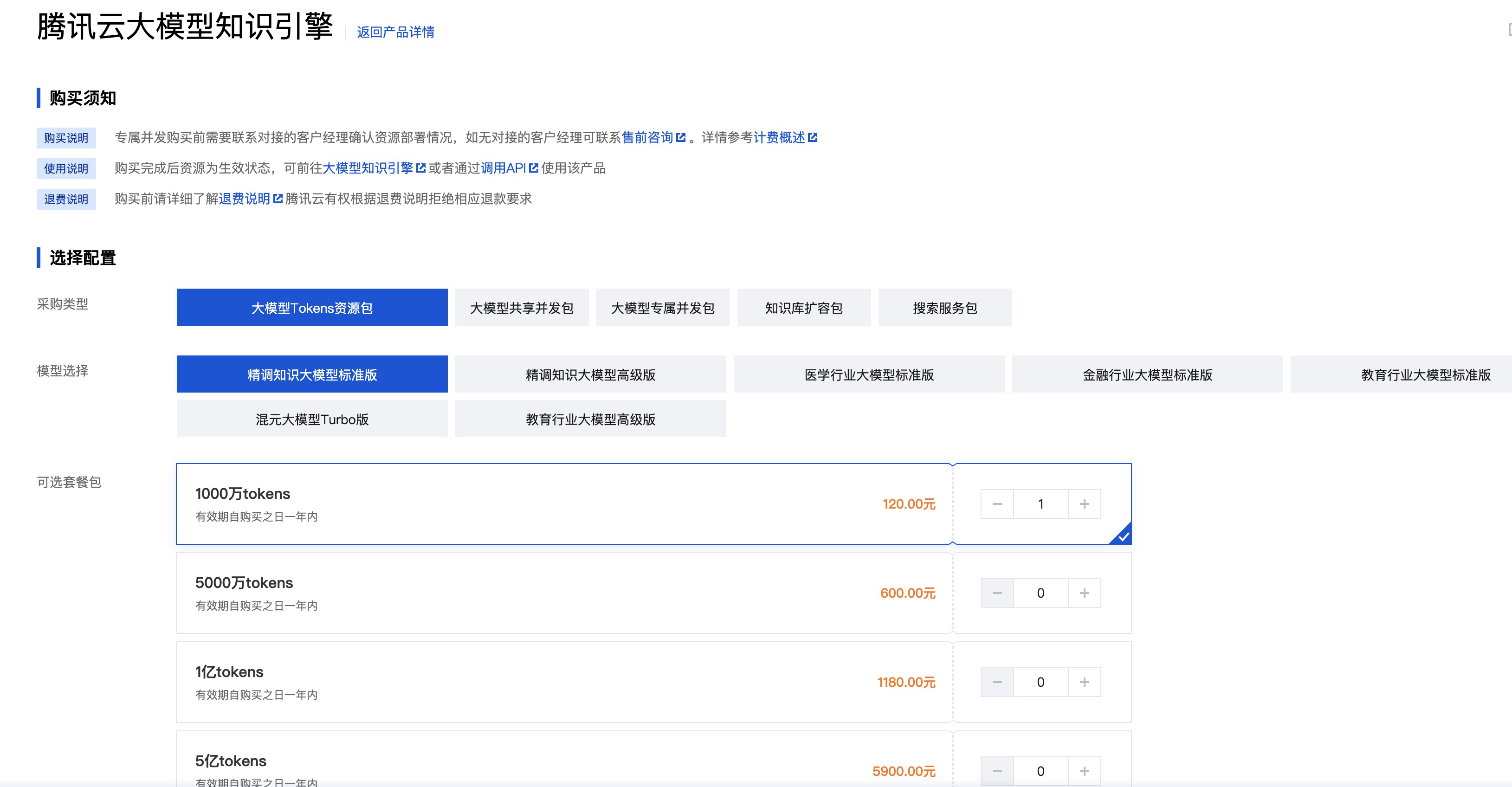
如果想要接入应用生产,也可以根据需要,在LKE资源包购买页购买合适的资源包。
构建智能客服
我们在应用管理页面新建一个智能客服的应用。

输入名称之后进入到应用配置页面。
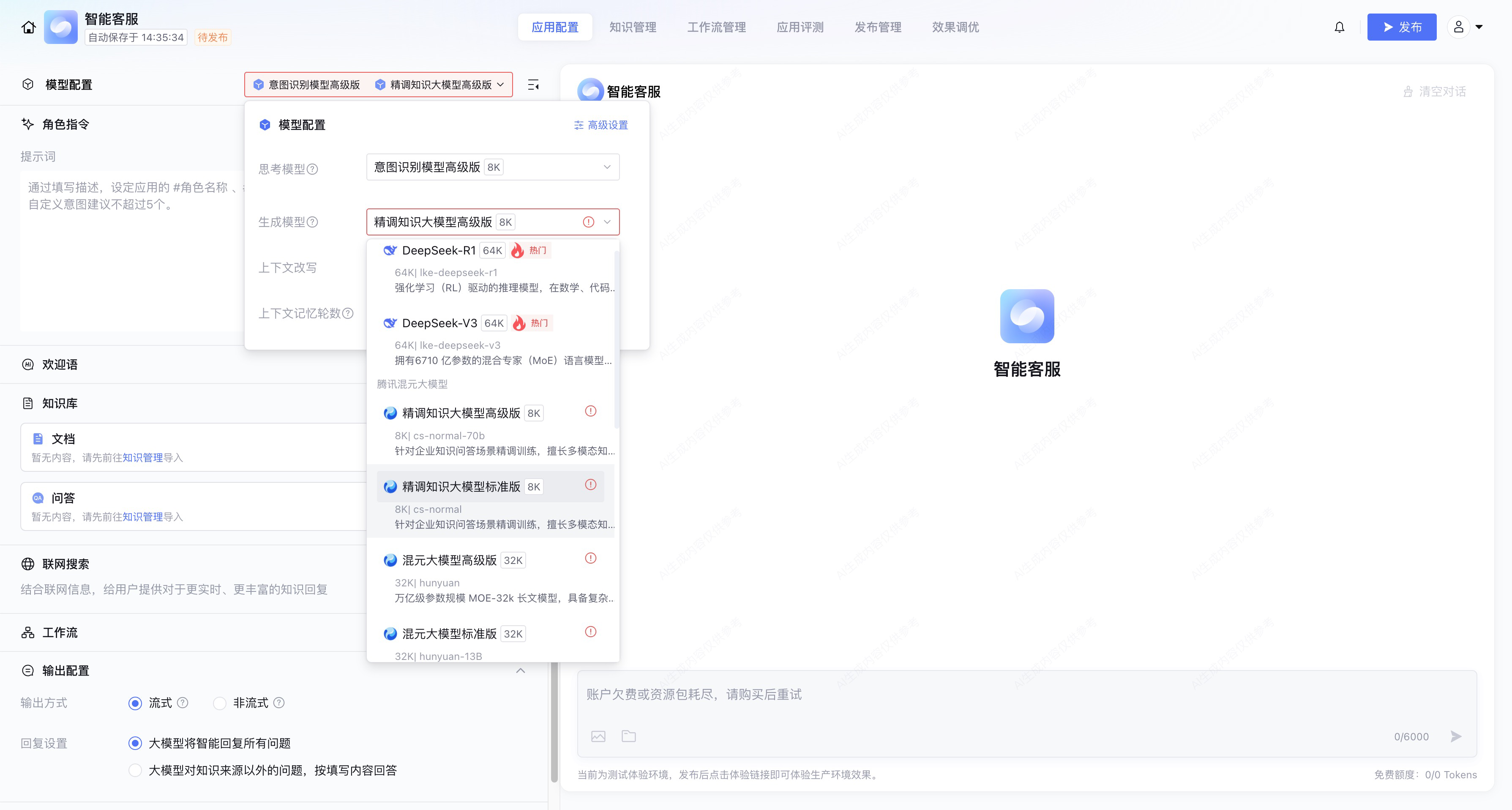
在此页面选择模型配置,除了基本的DeepSeek R1和V3模型,还可以选择精调知识大模型和各个垂直行业的大模型,例如金融、医疗。

这里我选择满血版的DeepSeek V3模型,然后就是配置角色指令。

对于角色指令可以使用模版,然后进行内容填充,这样更准确。
知识库构建
知识库对于构建智能客服系统非常必要。为了提升回答的准确性,我们可以将业务把办理流程、常见故障排查方法、套餐等信息整合到文档中,以此来构建知识库。智能客服通过匹配用户问题,迅速查找标准答案,实时提供专业解答,提升客户满意度和服务质量。
在大模型知识引擎中,提供了两种方式来构建知识库:
- 文档:结合知识引擎的能力,基于导入的文档形成有关知识的业务知识库,智能客服可直接根据知识库中的内容对用户问题进行解答
- 问答FAQ:针对于需要进行标准化、稳定的问题回复的情况,需要引入FAQ(问答对)进行处理
在构建知识库之前,我们要进行知识提取和筛选,将复杂的内容简化为易于理解的形式,去除重复、过时或无关的信息,保证数据准确性、实用性、完整性和时效性。
文档
我们在知识管理点击导入按钮,这里支持网页内容导入和本地文档导入,这里选择从本地文档导入,添加要上传的文档列表。
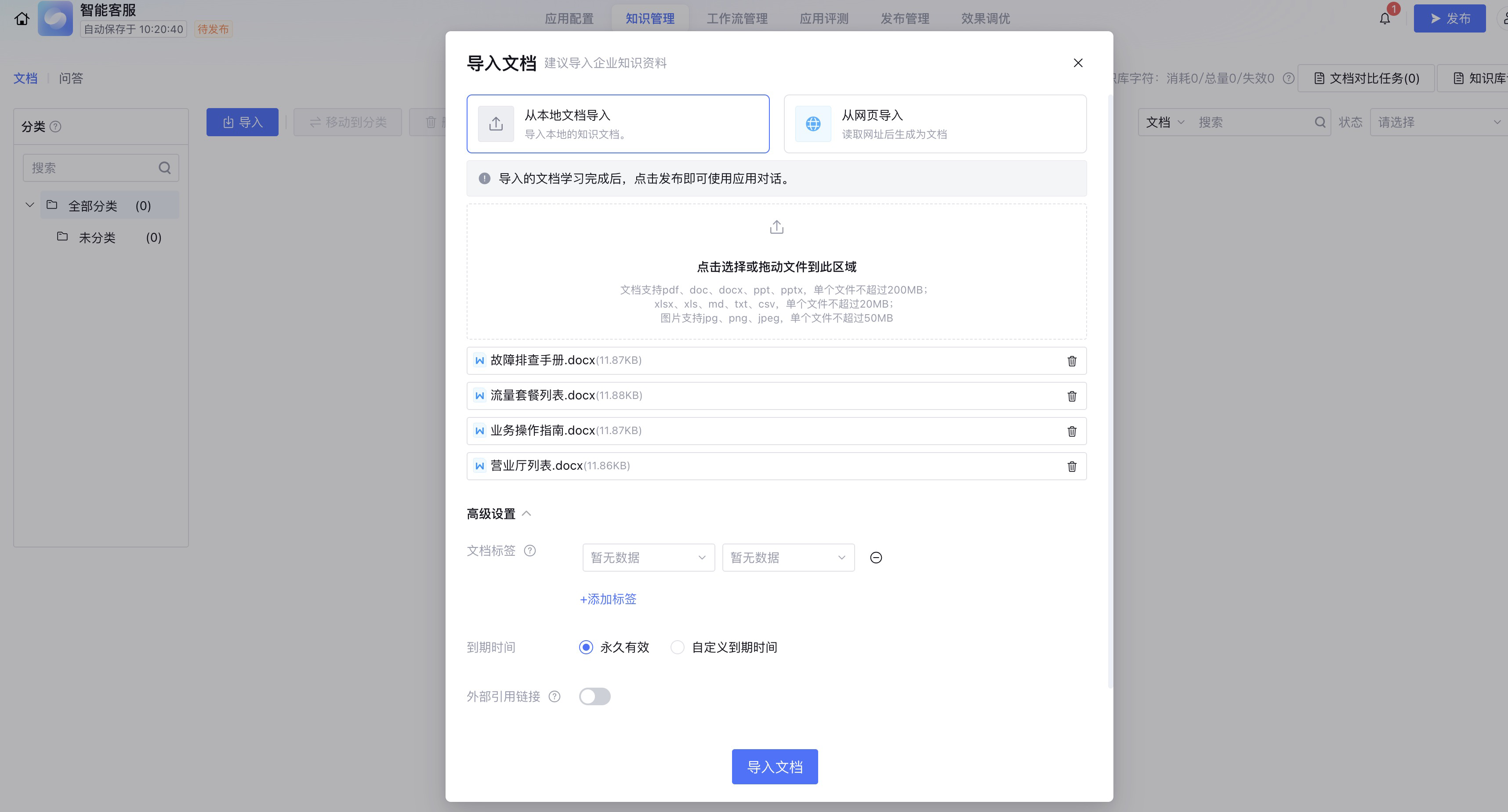
在这里我将故障排查手册、流量套餐列表和业务操作指南等文档上传,在点击导入文档之后,文档列表里就可以看到我们上传的文档。
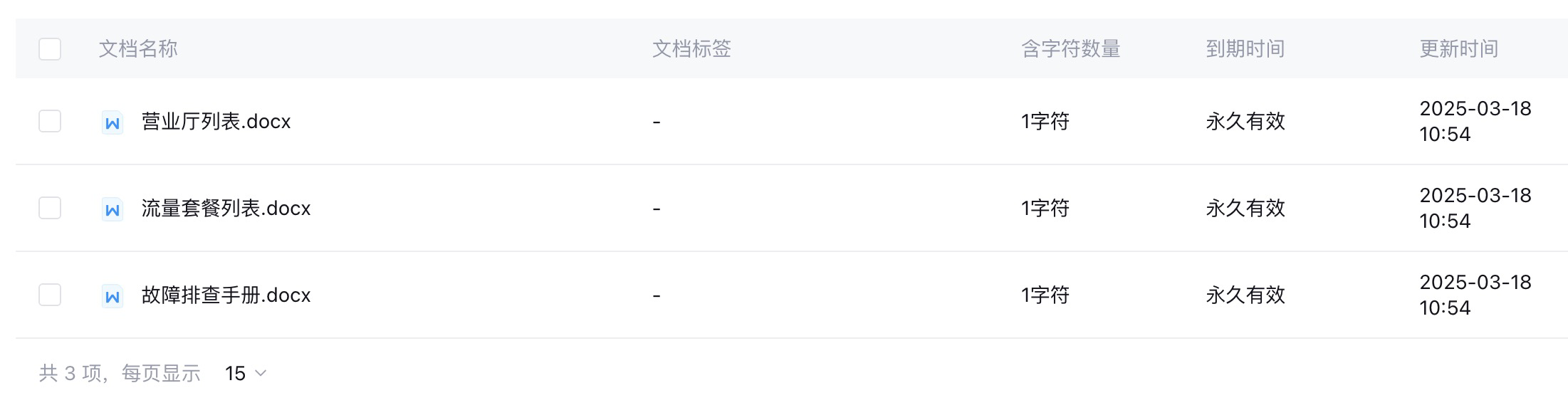
在大模型引擎解析过后,基于这些文档就形成了智能客服的知识库。
问答FAQ
我们可以整理出来高频固定的问题,生成FAQ导入到我们的智能客服中,这样可以提高智能客服的回复速度,并保证回复的标准化。例如:
Q: 如何更换套餐?下月生效吗?
A: 您可通过APP“套餐变更”页面操作,新套餐次月生效,本月剩余流量可结转。
Q: 可以办副卡吗?副卡收费吗?
A: 主套餐支持1-2张副卡,每张副卡月费10元,共享主卡流量和通话。
Q: Wi-Fi信号满格但网速慢怎么办?
A: 请尝试:1. 重启路由器;2. 减少连接设备数量;3. 切换至5GHz频段(如有)。若仍无效,请联系客服。
Q: 出国后手机无法上网,如何开通漫游?
A: 发送短信“KTGJMY”至100,或登录APP开通国际漫游套餐。需确保手机已开启数据漫游功能。
1. FAQ录入
我们在知识管理页面选择问答,点击新建可以看到有三种方式新建FAQ:

如果使用批量的话,需要将问题和答案整理到excel中然后导入。
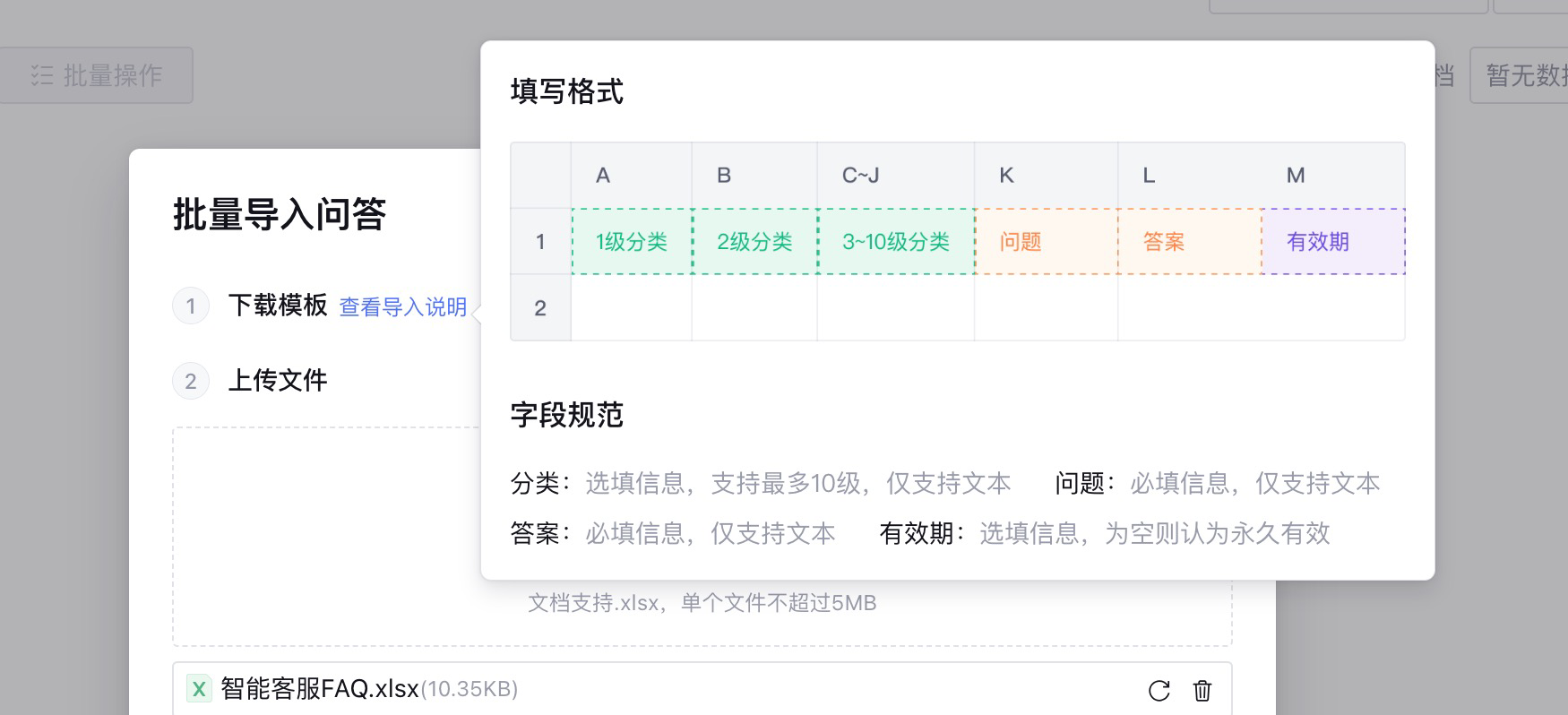
在这里我使用的是手工录入,因为这样可以使用AI自动生成相似问。在手工录入页面输入问题之后,点击问题上方的相似问。

2. 相似问
点击AI一键生成相似问,这样就会自动生成10个相似问。
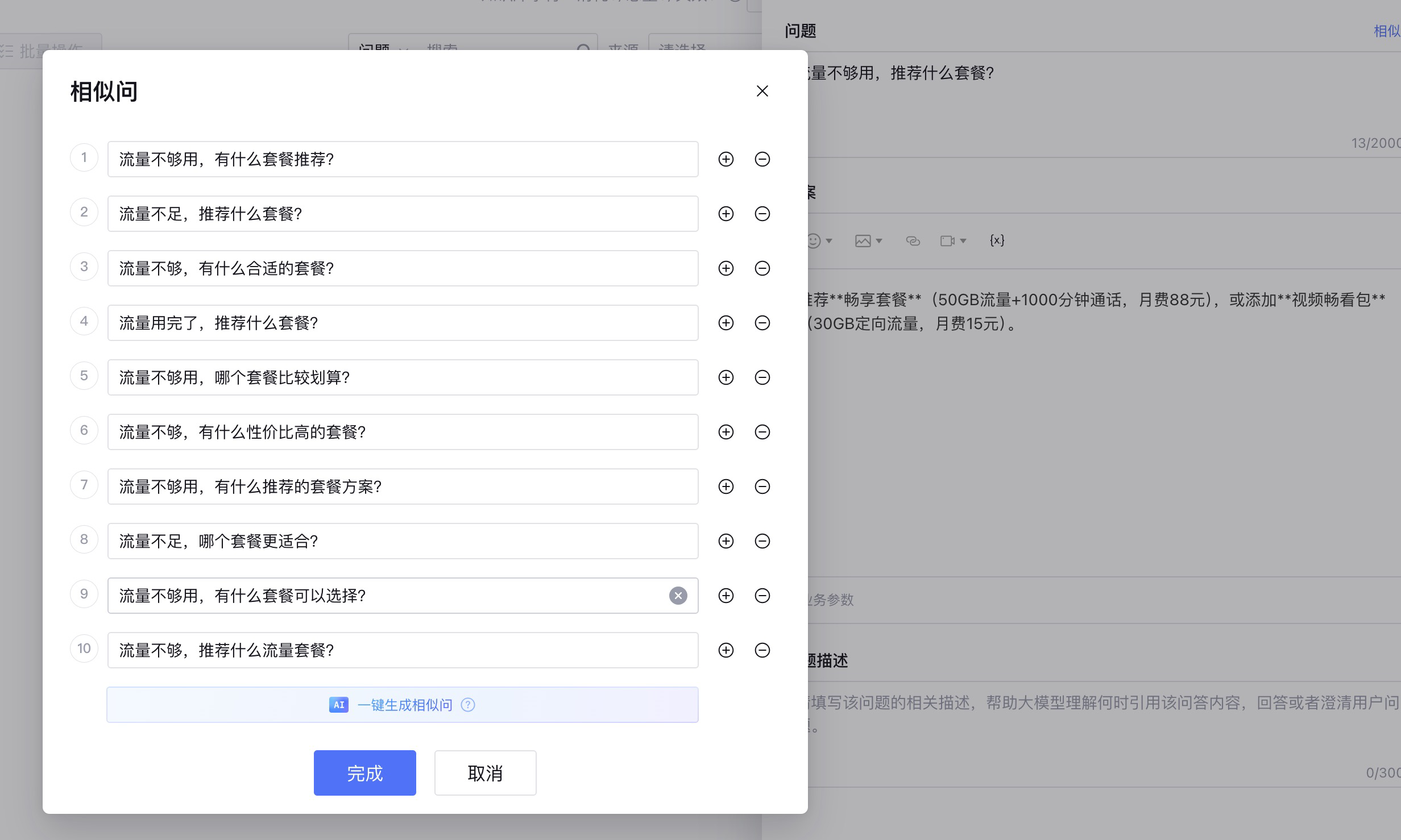
点击完成之后,相似问就和问题绑定。

如上图所示,相似问就变成了10个,当用户提出这些问题的时候,智能客服都会使用你设定的答案完成回复。
在新增FAQ的过程中,我们需要遵循以下原则:
- 确认现有知识库中是否有问题类似的问题,避免出现知识库中(包括 FAQ、文档、任务流)出现问题相似/相同、但答案不同甚至冲突的情况
- 系统会根据 Q自动检测冲突的 FAQ,需要按照系统提示保留其中一个FAQ
高级设置
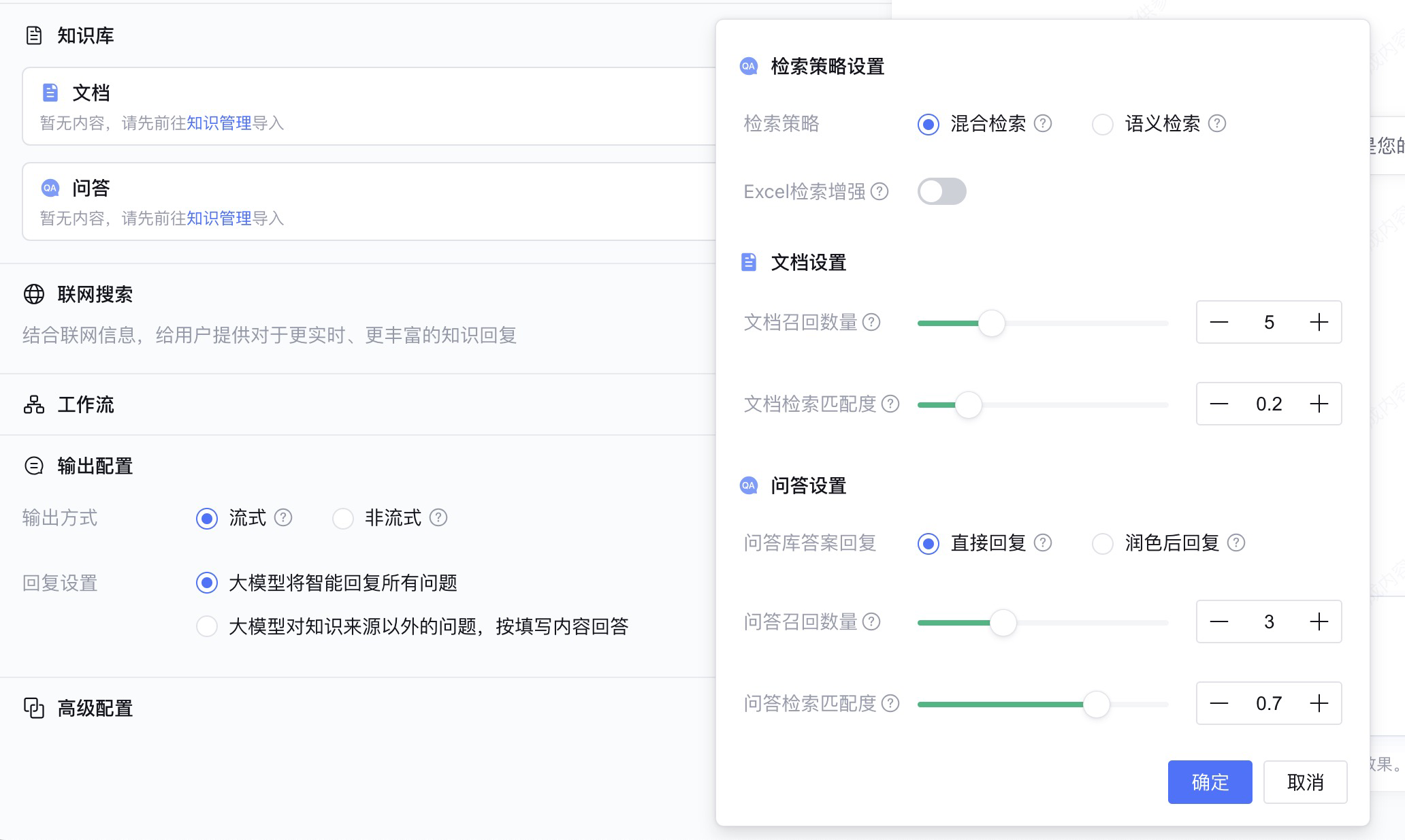
我们可以对知识库设定一些高级选型,对检索策略、文档设置和问答设置进行参数设置。
工作流
大模型知识引擎和知识库弥补了智能客服的短板,解决了无法解决实际问题的场景,对于原有的预约场景,可以通过工作流的形式来实现。
在工作流管理页面中选择新建。

在工作流描述之后,可以通过AI一键优化格式。
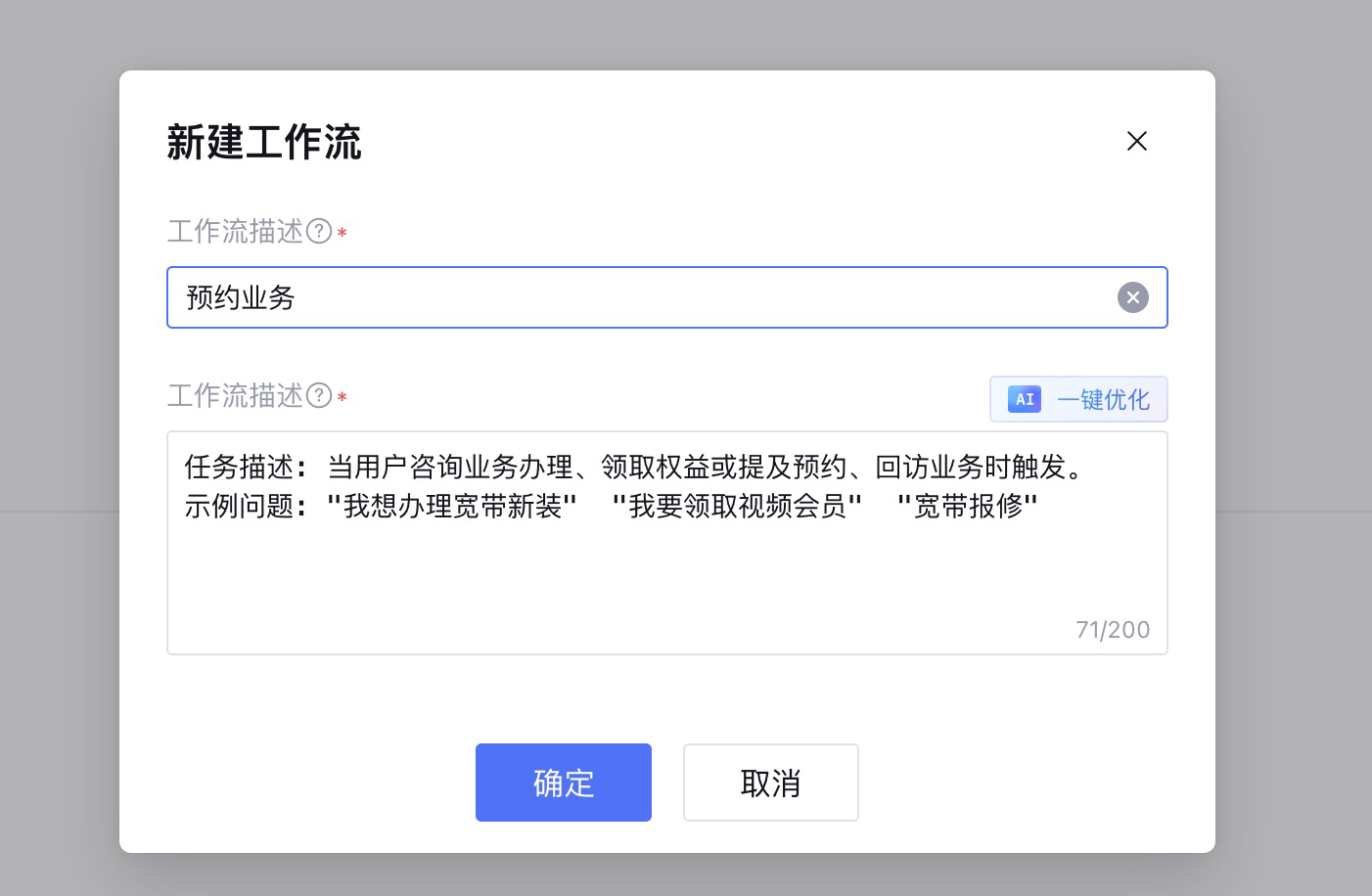
点击确定,就进入到工作流开发页面。
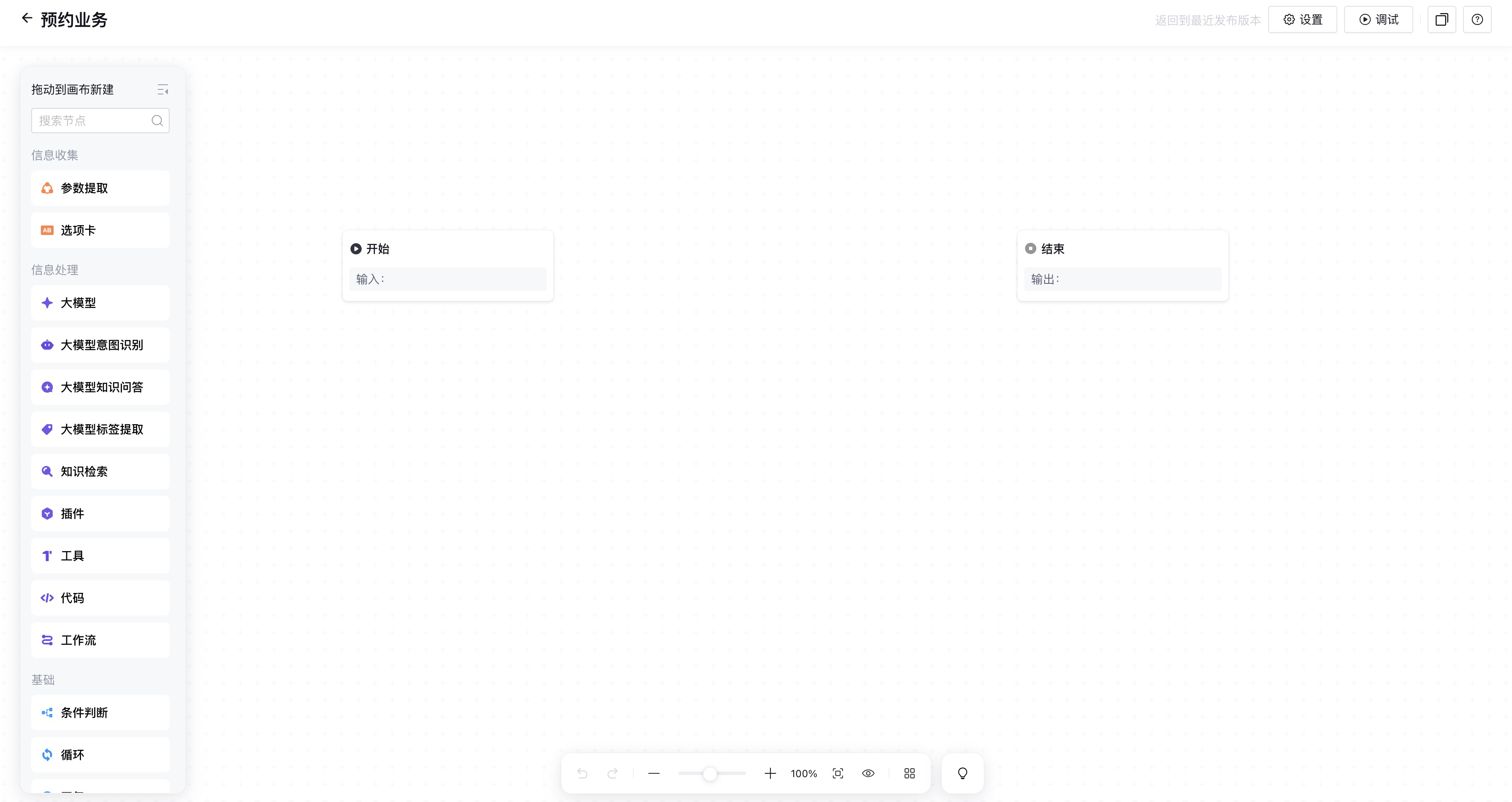
中间画布只有开始和结束节点,我们需要中开始和结束节点之间,使用页面做的的信息处理节点,来构造业务预约的工作流。
工作流的起点是开始节点,首先查看一下节点信息。
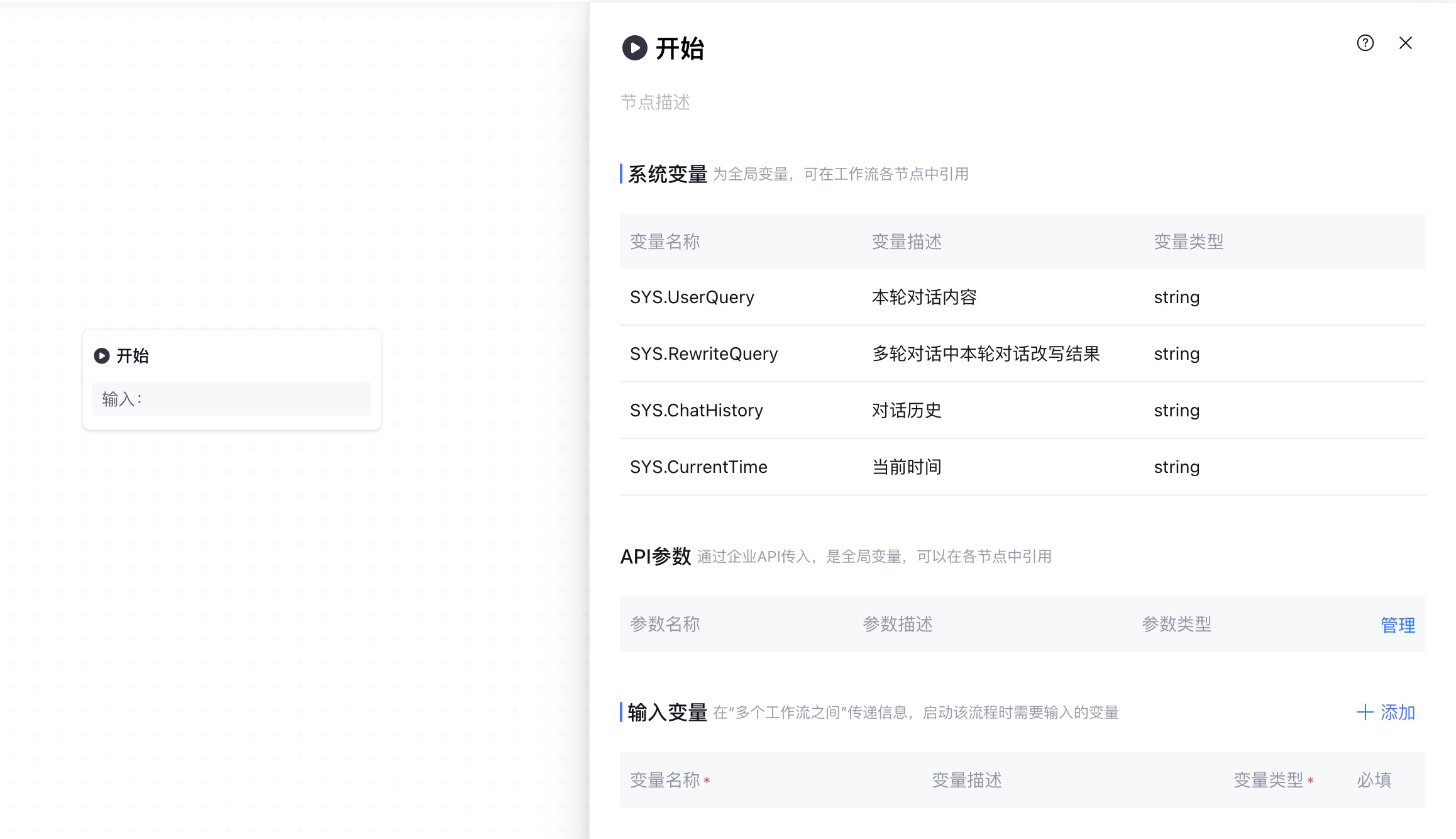
在开始节点要关注的是系统变量,这些变量会在各个节点传递引用。对于预约业务,我们要关注本轮对话内容UserQuery和当前时间CurrentTime这两个变量。
1. 变量提取
预约业务首先需要知道用户的手机号。我们在业务预约常见下,通过API调用大模型知识引擎时,可以在对话内容userQuery中将号码传递过来,然后我们进行提取。
可以通过 大模型标签提取 节点,提取 UserQuery 中的手机号码。

但是这里我使用 代码 节点,因为为了保证数据的隐私和安全性,通常需要对手机号这类的信息进行加密,在代码节点中,我们可以实现解密逻辑。这里先不讨论加密的问题,在业务预约场景中,约定好手机号和业务预约内容之间使用逗号分割。
这里拉取一个 代码 节点,代码节点支持用户编写Python代码,并内置了numpy等常用python包,这里将UserQuery 作为输入变量:
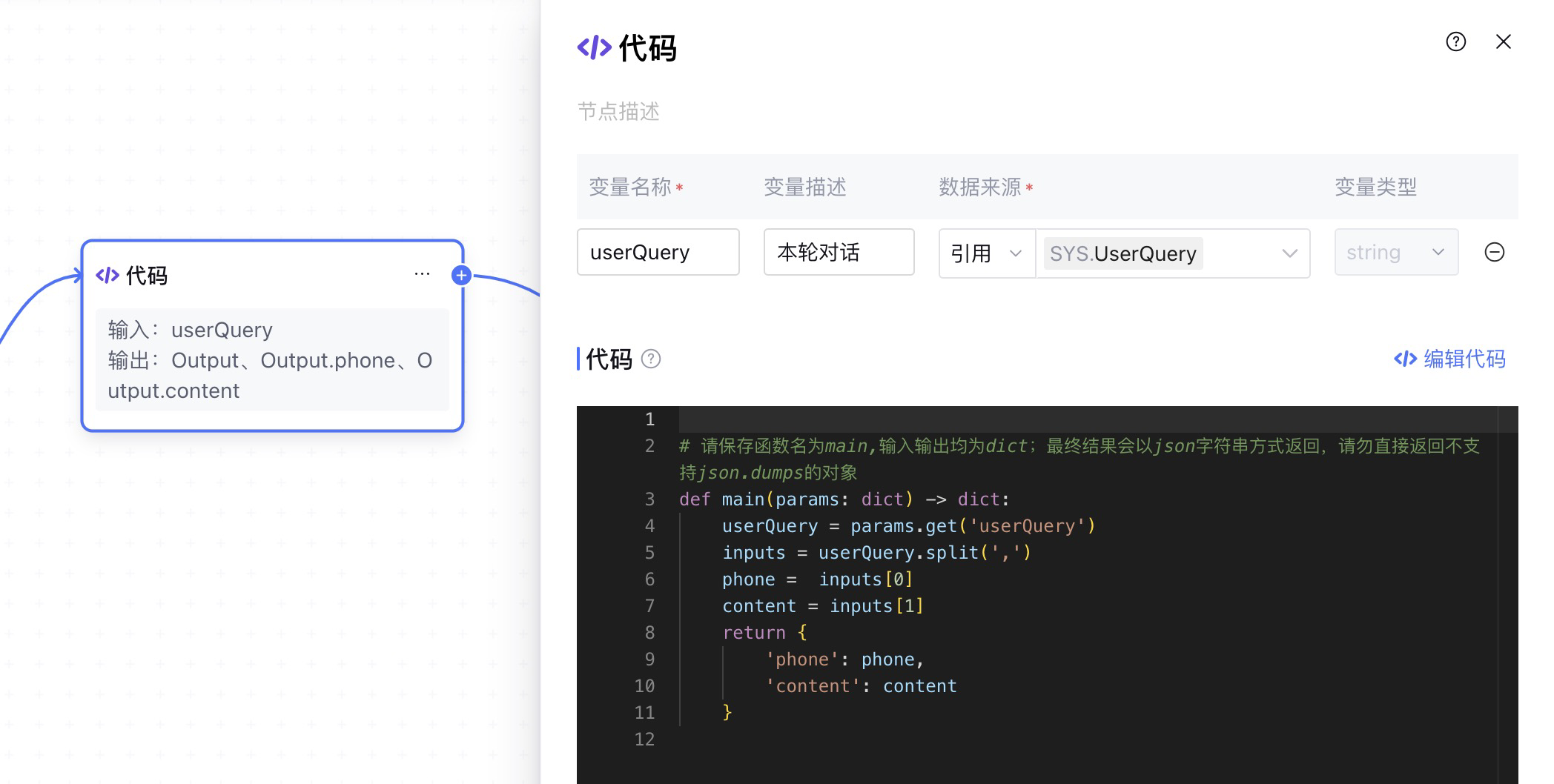
点击 编辑代码,对输入的userQuery进行处理。
# 请保存函数名为main,输入输出均为dict;最终结果会以json字符串方式返回,请勿直接返回不支持json.dumps的对象
def main(params: dict) -> dict:
userQuery = params.get('userQuery')
inputs = userQuery.split(',')
phone = inputs[0]
content = inputs[1]
return {
'phone': phone,
'content': content
}
在编辑区域下方输入测试数据:
15000000000,宽带新装
点击测试。

在输出结果中输出了代码处理后的变量。
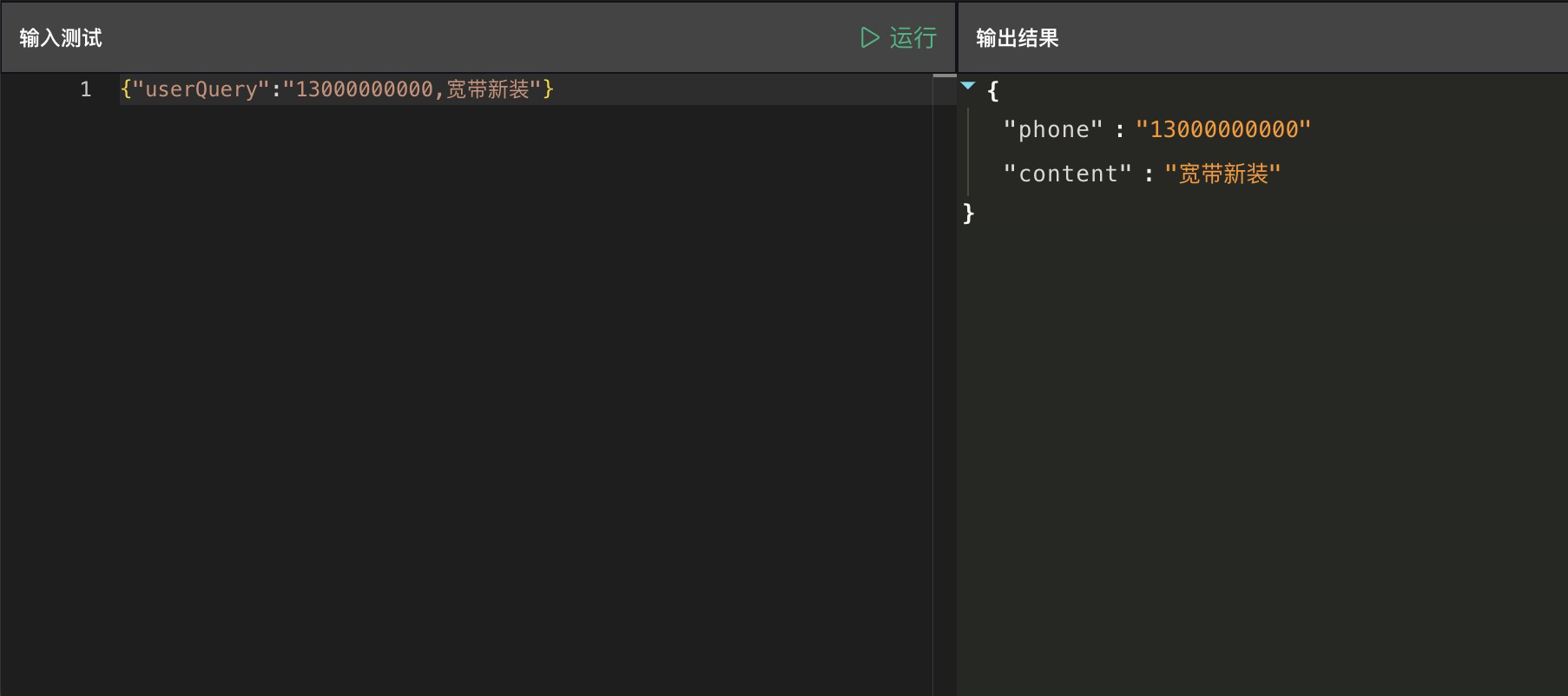
为了将输出的 phone 和 content 变量传递给下一个节点,通过点击 解析到输出变量,代码输出的变量就会自动添加到输出变量中。

2. 预约推送
当用户触发了工作流,通过代码节点提取了变量,接下来就是要将触发工作流的预约业务数据,推送到后台的事件系统用于预约外呼,所以这里需要实现一个接口来接收这些数据。
接口开发
真累使用搭载了DeepSeek满血版的腾讯云AI代码助手来实现这个接口。
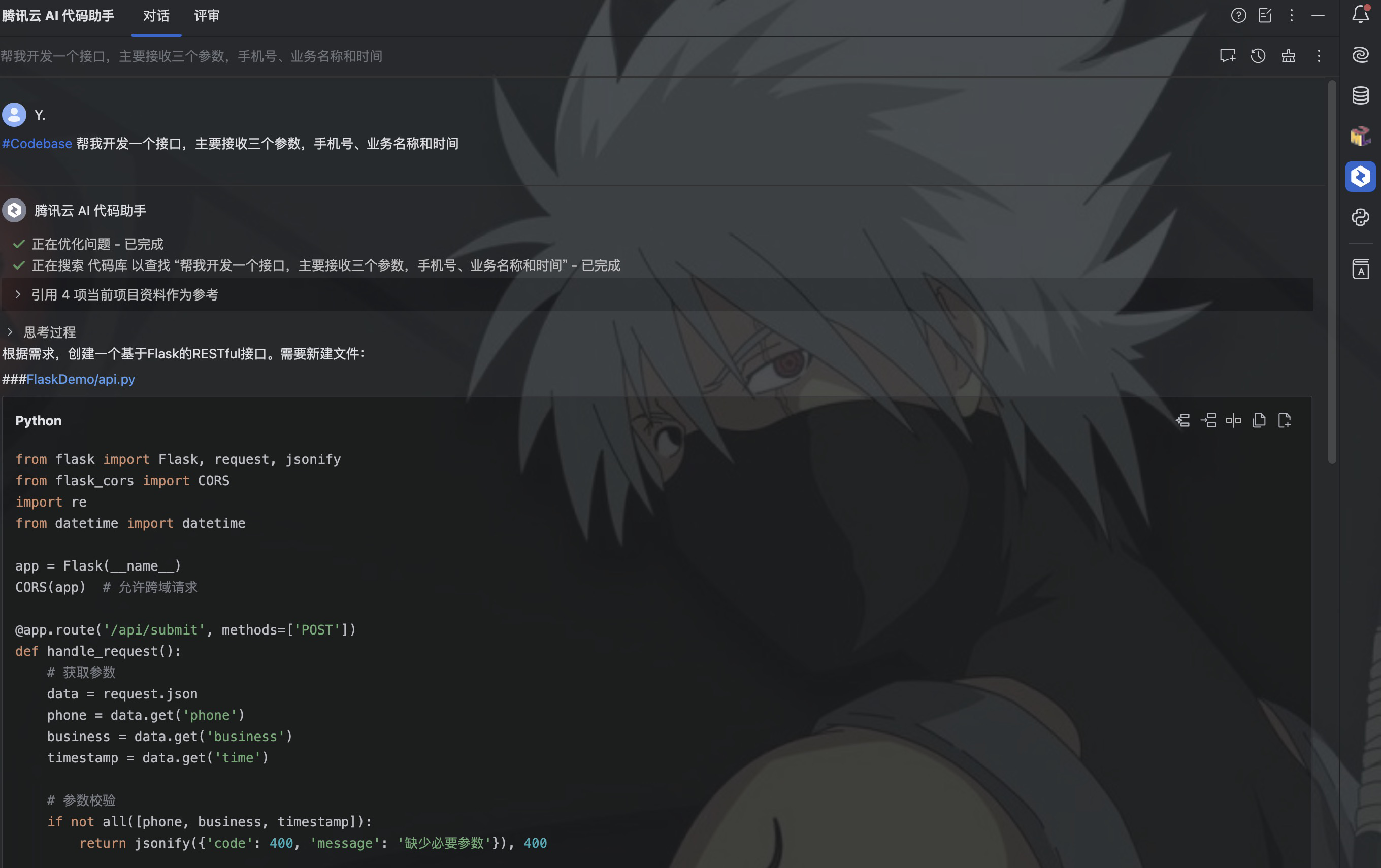
在这里限定了三个参数:手机号、业务和时间,腾讯云AI代码助手使用flask实现了 /api/submit 接口。具体代码如下:
from flask import Flask, request, jsonify
from flask_cors import CORS
import re
from datetime import datetime
app = Flask(__name__)
CORS(app) # 允许跨域请求
@app.route('/api/submit', methods=['POST'])
def handle_request():
# 获取参数
data = request.json
phone = data.get('phone')
business = data.get('business')
timestamp = data.get('time')
# 参数校验
if not all([phone, business, timestamp]):
return jsonify({'code': 400, 'message': '缺少必要参数'}), 400
# 手机号格式校验
if not re.match(r'^1[3-9]\d{9}$', phone):
return jsonify({'code': 400, 'message': '手机号格式错误'}), 400
# 业务逻辑处理(示例)
# TODO: 添加实际业务处理逻辑
print(f'手机号:{phone}\n业务:{business}\n时间:{timestamp}'
return jsonify({
'code': 200,
'message': '请求成功',
'data': {
'phone': phone,
'business': business,
'time': timestamp
}
})
if __name__ == '__main__':
app.run(debug=True, port=5000)
这里只打印接收的参数,不实现具体的业务逻辑。将程序部署在腾讯云轻量服务器上,启动服务监听5000端口。通过curl测试一下服务是否可用:
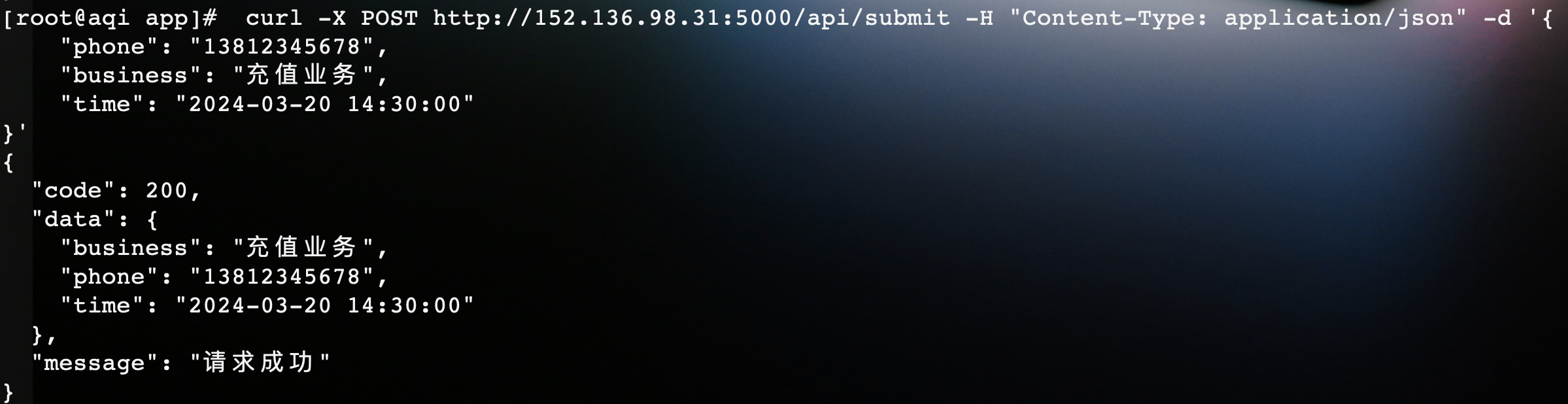
接口访问成功并返回了响应数据。
3. 工具节点
我们需要在工作流中调用上面的接口,使用 工具 节点,即可访问外部的api。先填写节点的基础信息,包括接口链接、请求方式和header。
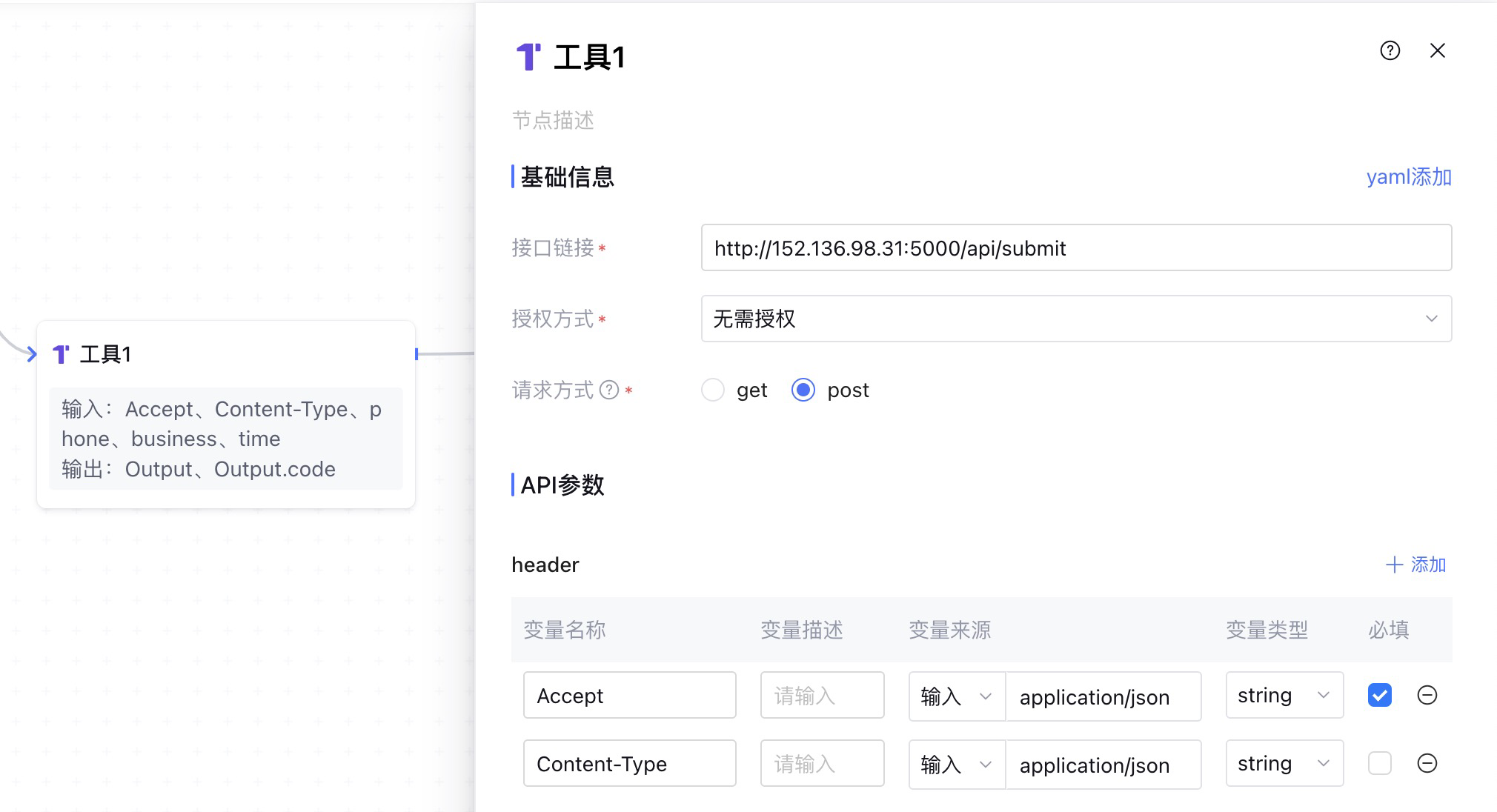
设置 Content-Type 为json格式。然后在body中设置要请求参数。
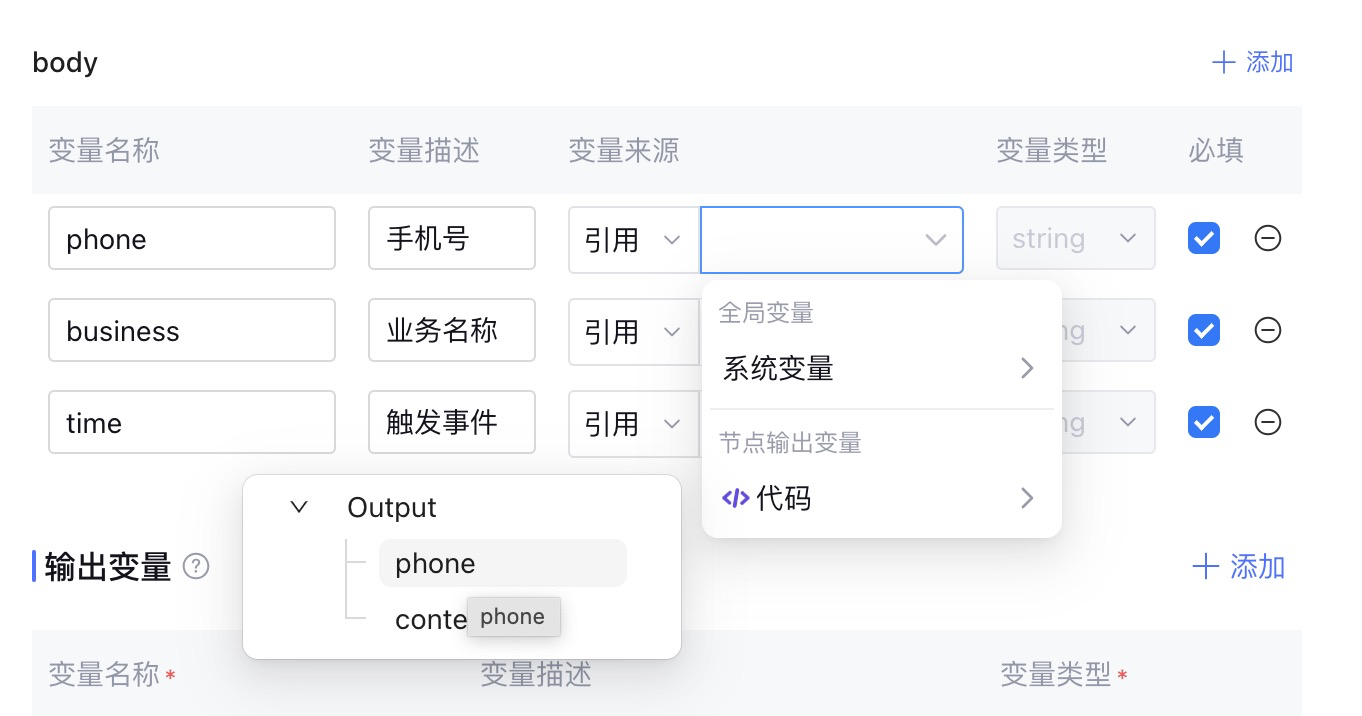
phone 和 bussiness 使用的是 代码节点 生成的变量,time 是想用的是 开始节点 的系统变量,系统时间如果和你想要的时间戳不一致,可以在代码节点中自行处理。
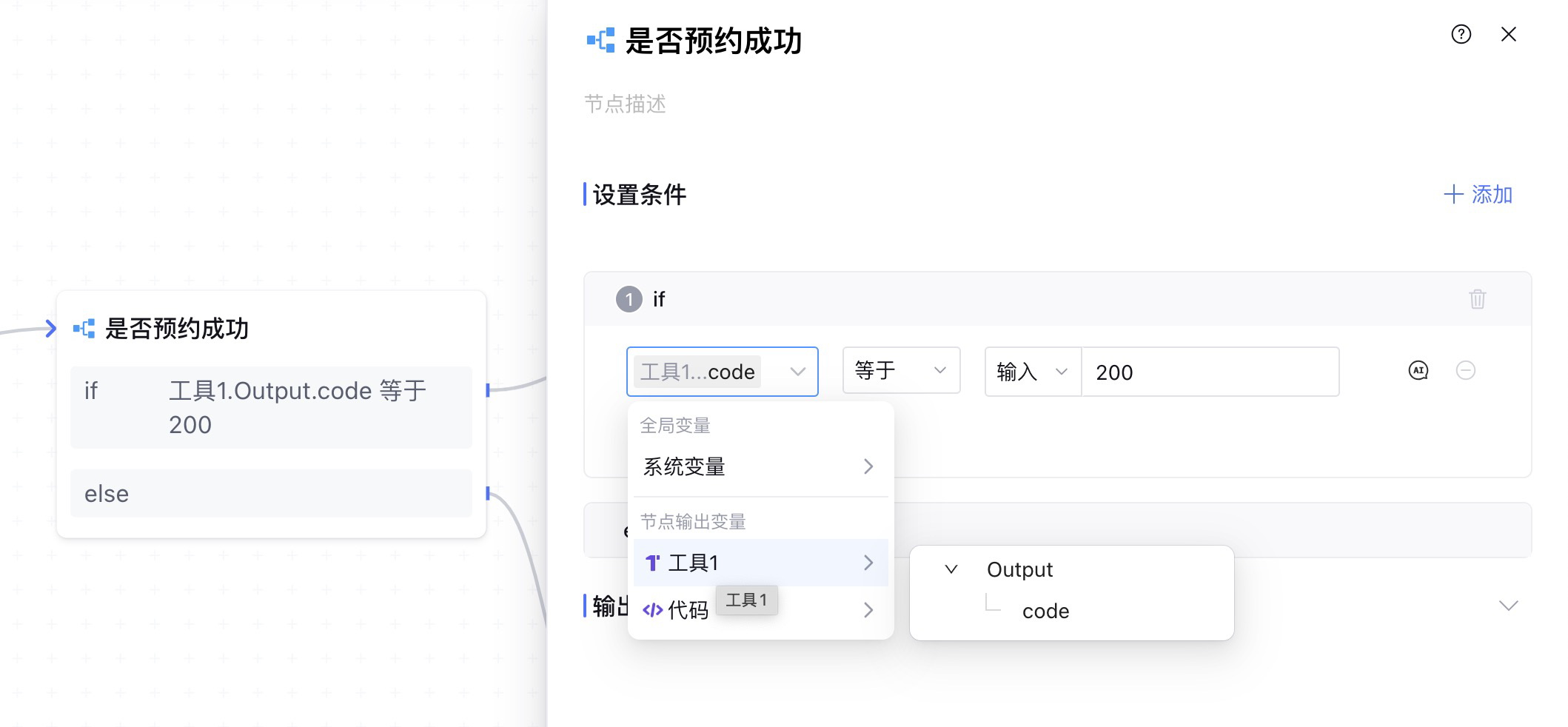
4. 判断节点
我们要根据接口返回的响应数据来判断,预约业务是否触发成功。这里我们使用 条件判断 节点实现,如果响应码为200,则表示预约成功,其他则表示预约失败。
5. 回复节点
我们拉取两个 回复 节点,分别对预约成功和预约失败,进行不同的回复。
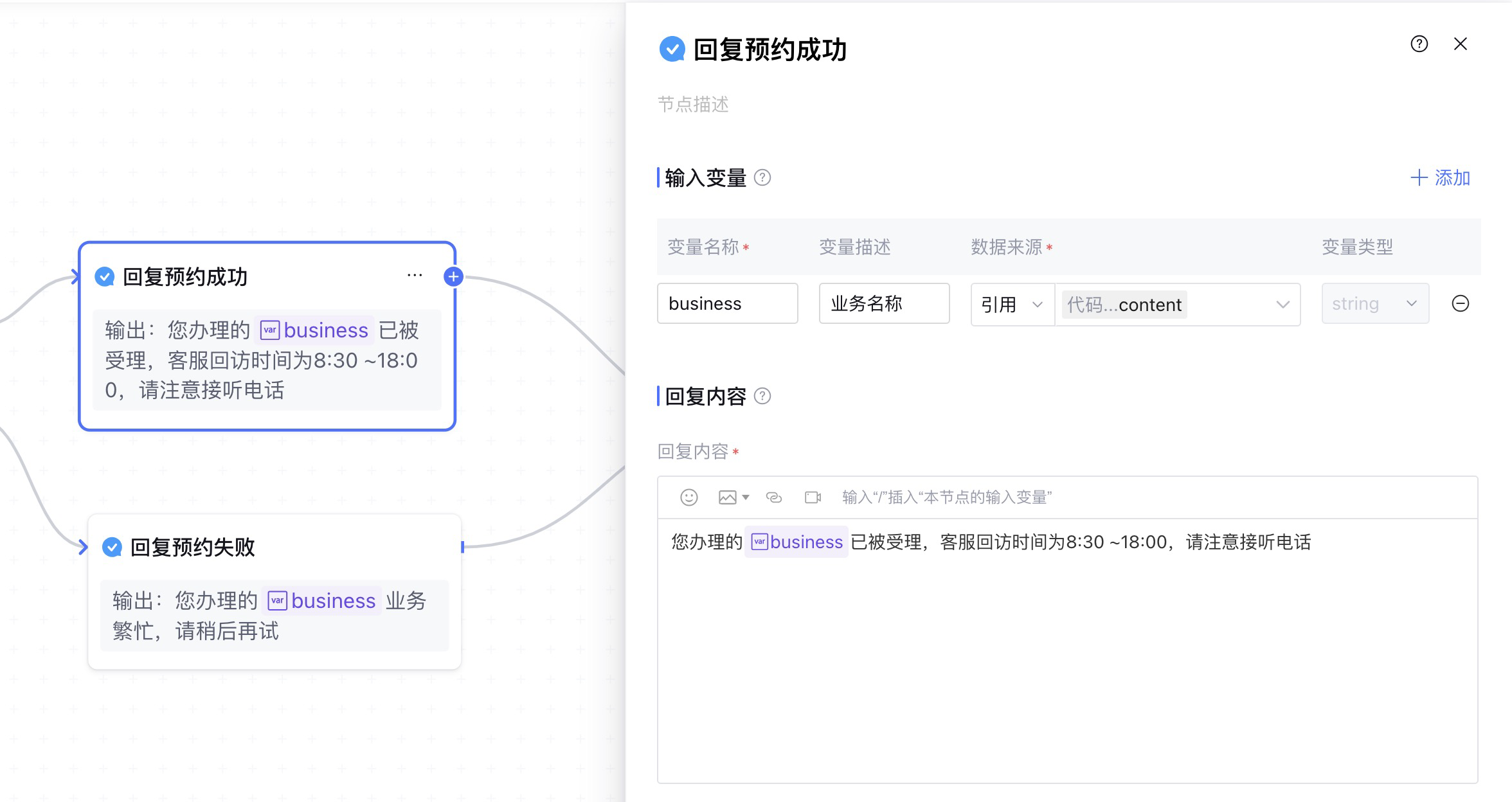
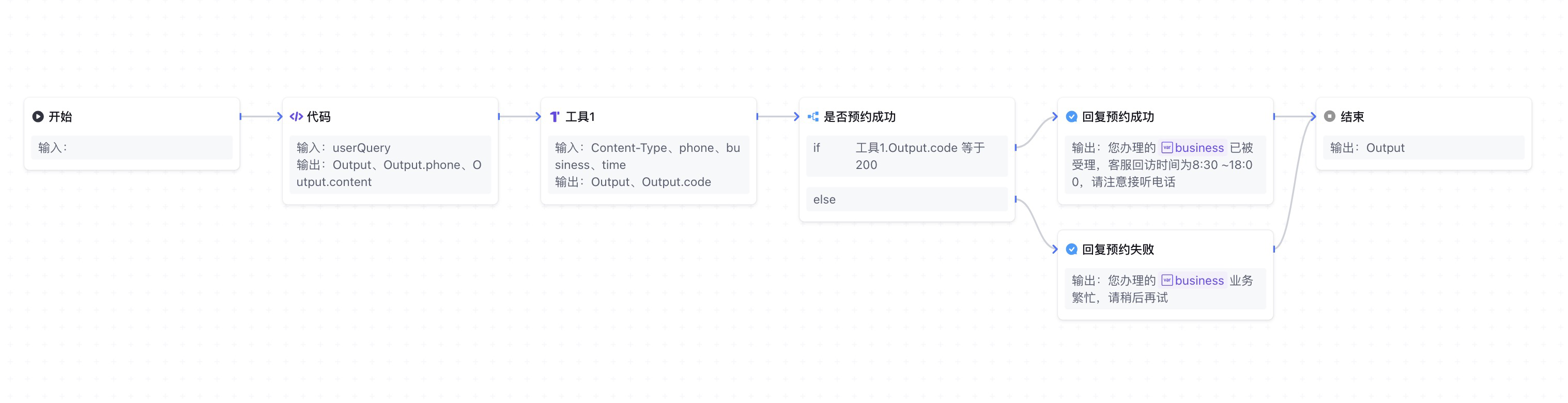
最后将回复节点连接到结束节点形成闭环,这样就完成了整个预约业务工作流的构建。使用 画布整理 功能,最后工作流展示如下:
6. 调试
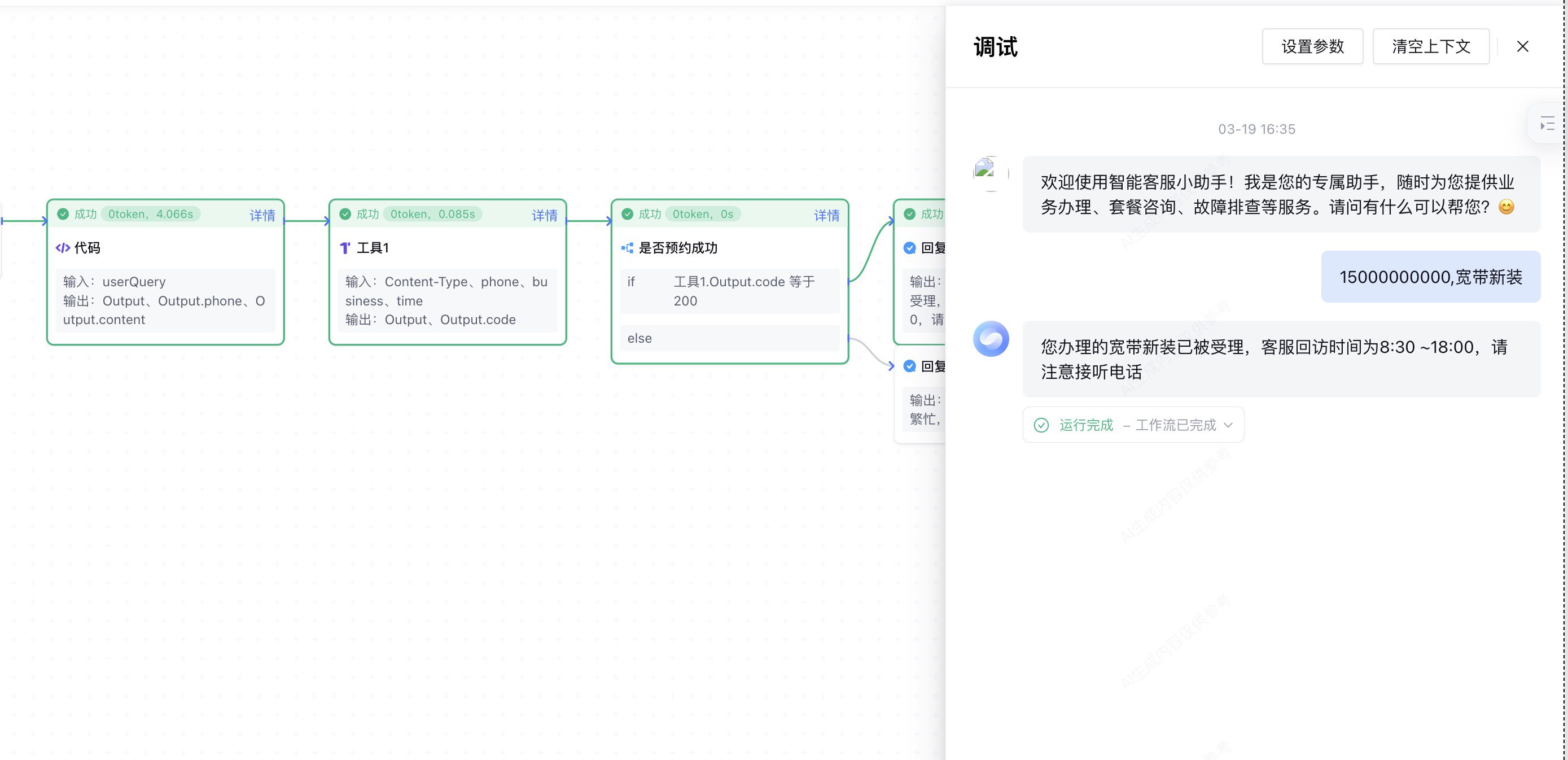
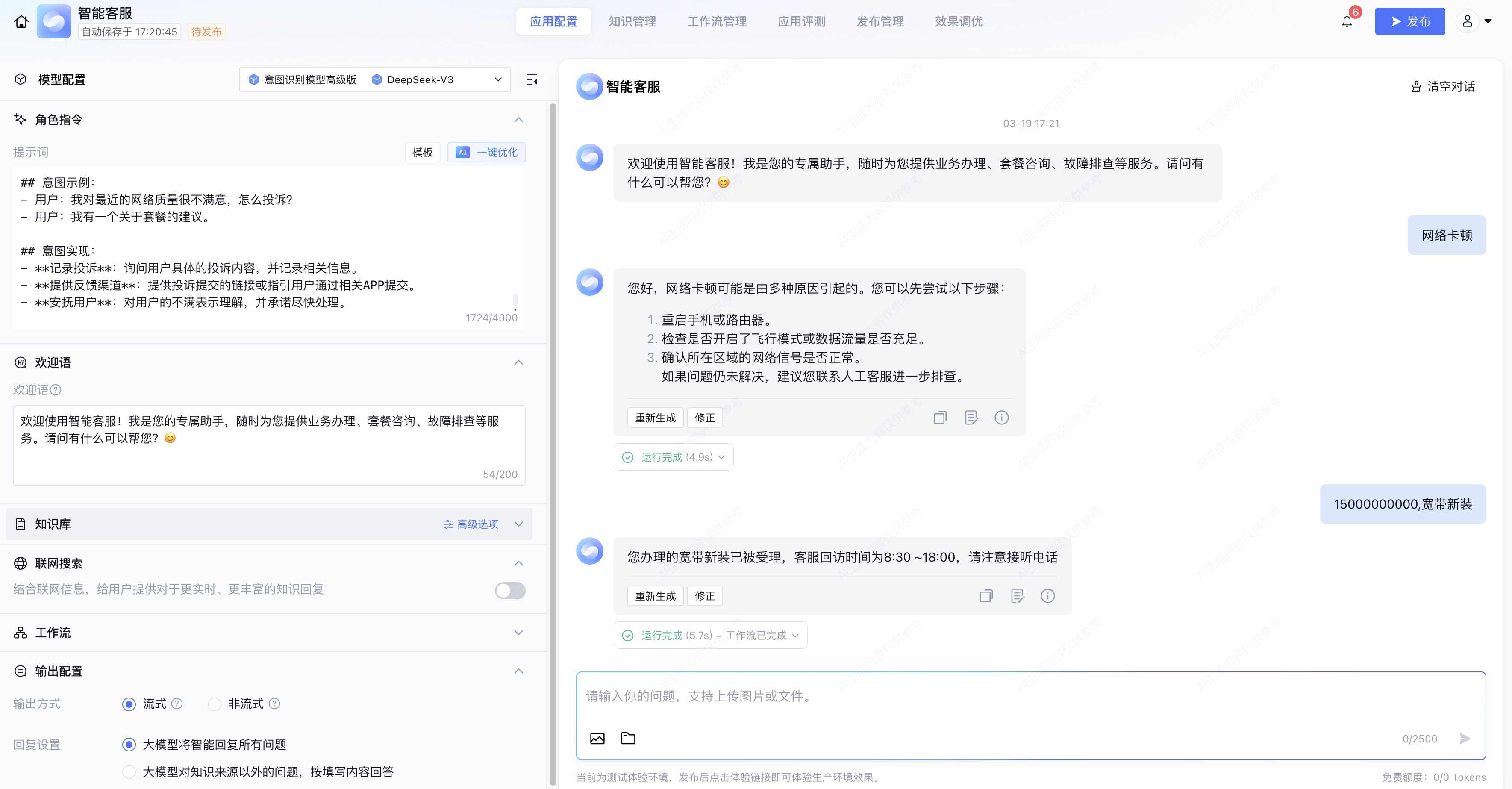
我们点击调试,进入到智能客服对话页面:

将手机号和预约业务作为参数输入,智能客服就会调用工作流。

预约业务接口调用成功,智能客服使用 预约成功回复节点 的内容进行回复。
7. 发布
返回到工作流管理页面,点击右上角的 发布,点击确定就完成了工作流的发布,并启用工作流。

在智能客服中,既能使用工作流来完成预约业务,也能为用户解决一些常用的问题。
在大模型知识引擎构建了智能客服之后,可以直接使用API的形式调用集成。

根据API管理指引,我们可以在现有的代码中集成智能客服,而不用推翻原有架构重新开发整个应用。
结语
当下是AI的时代,未来是AI Agent的时代,在大模型知识引擎构建智能客服的过程中,感受了低代码的魅力,除了卓越的UI交互体验,简单易懂的功能也使我从零基础快速入门上手。
对于普通开发者来说,腾讯云大模型知识引擎提供了一站式Agent构建平台,降低了Agent的开发门槛。大模型知识引擎目前已接入精调知识大模型、混元大模型、行业大模型、DeepSeek 等十余种模型,对于企业而言,降低了训练成本、提高了开发效率,期待看到大家在大模型知识引擎的作品。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 71
71 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)