【8G显卡-使用Ollama安装CudaToolkit工具提高Gemma3及Deepseek-14B等大模型的运行速度】
Gemma 3 被谷歌称为目前最强的开源视觉模型之一。该模型支持超过35种语言,能够分析文本、图像和短视频。值得注意的是,Gemma 3 的视觉编码器经过升级,支持高分辨率和非方形图像,并引入了 ShieldGemma 2 图像安全分类器,用于过滤被分类为性暗示、危险或暴力的内容。这些特性使得 Gemma 3 成为当前最强大的开源视觉模型之一。此图表按 Chatbot Arena Elo 得分对
Ollama提高GPU的使用率
1 Gemma 3简介
Gemma 3 被谷歌称为目前最强的开源视觉模型之一。 该模型支持超过35种语言,能够分析文本、图像和短视频。值得注意的是,Gemma 3 的视觉编码器经过升级,支持高分辨率和非方形图像,并引入了 ShieldGemma 2 图像安全分类器,用于过滤被分类为性暗示、危险或暴力的内容。这些特性使得 Gemma 3 成为当前最强大的开源视觉模型之一。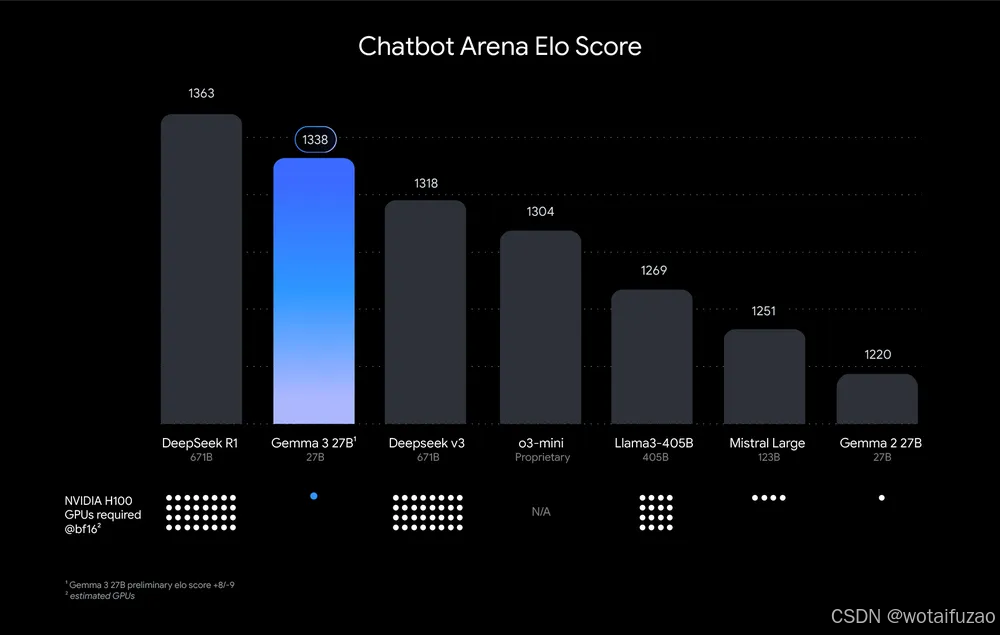
此图表按 Chatbot Arena Elo 得分对 AI 模型进行排名;得分越高(数字越大),表示用户偏好越高。点表示估计的 NVIDIA H100 GPU 要求。Gemma 3 27B 排名靠前,只需要一个 GPU,而其他模型则需要多达 32 个。
1.1 新的功能
- 使用世界上最好的单加速器模型进行构建: Gemma 3 以其尺寸提供最先进的性能,在 LMArena 排行榜的初步人类偏好评估中胜过 Llama3-405B、DeepSeek-V3 和 o3-mini。这可以帮助您创建可安装在单个 GPU 或 TPU 主机上的引人入胜的用户体验。
- 以 140 种语言走向全球:构建使用客户语言的应用程序。Gemma 3 提供对超过 35 种语言的开箱即用,支持和对超过 140 种语言的预训练支持。
- 打造具备高级文本和视觉推理能力的AI:轻松构建分析图片、文本、短视频等应用,开启交互智能化新可能1。
- 使用扩展的上下文窗口处理复杂任务: Gemma 3 提供 128k 令牌上下文窗口,让您的应用程序处理和理解大量信息。
- 使用函数调用创建 AI 驱动的工作流程: Gemma 3 支持函数调用和结构化输出,以帮助您自动执行任务并构建代理体验。
- 通过量化模型更快地实现高性能: Gemma 3 引入了官方量化版本,减少了模型大小和计算要求,同时保持了高精度。
1.2 不同蒸馏版本对比
| 预先训练 | 指令调整 | 多式联运 | 多种语言 | 输入下文窗口 |
|---|---|---|---|---|
| gemma-3-1b-pt | gemma-3-1b-it | ❌ | 英语 | 32千 |
| Gemma-3-4b-pt | gemma-3-4b-it | ✅ | +140 种语言 | 128千 |
| gemma-3-12b-pt | gemma-3-12b-it | ✅ | +140 种语言 | 128千 |
| gemma-3-27b-pt | gemma-3-27b-it | ✅ | +140 种语言 | 128千 |
对于 1B 版本,输入上下文窗口长度已从 Gemma 2 的 8k 增加到32k ,对于其他所有版本,则增加到 128k。与其他 VLM(视觉语言模型)一样,Gemma 3 会根据用户输入生成文本,这些文本可能由文本组成,也可能由图像组成。示例用途包括问答、分析图像内容、总结文档等。
2.使用ollama安装Gemma 3
2.1 安装官方的ollama
下载官方 Ollama 【点击前往】 ,并通过下方的安装命令执行下载:
具体步骤可以参考【ollama安装deepseek的文章】只要对于指令替换一下即可
2.2 安装大模型
普通用户可以安装4b和12b(本人使用是16g内容、8G的GPU,使用是12b的),显卡特别好的可以安装27b。
ollama run gemma3:1b
ollama run gemma3:4b
ollama run gemma3:12b
ollama run gemma3:27b
进入CMD窗口输入:ollama run gemma3:12b,如下图(记得科学上网一下,不然下载会有问题)
2.3 安装Web UI
通过Chrome插件调用本地Gemma 3视觉大模型【点击下载】,如果不懂,可以参考这个【文章】的第四小节。
点击右上方的按钮进行启动插件
3.使用Gemma 3对话
1.选择大模型 -->输入内容–>3.展示对话内容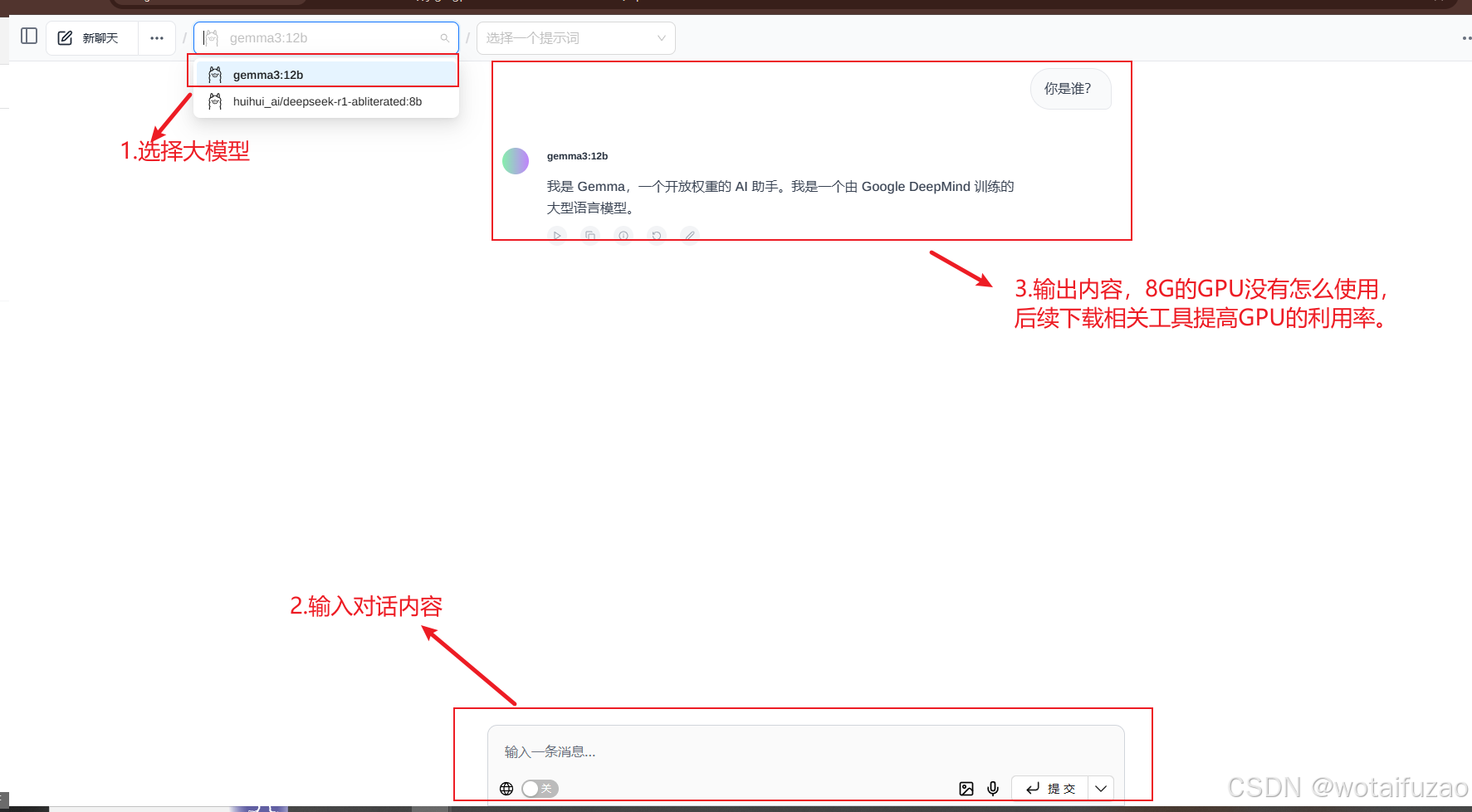
4.ollama使用GPU运行大模型
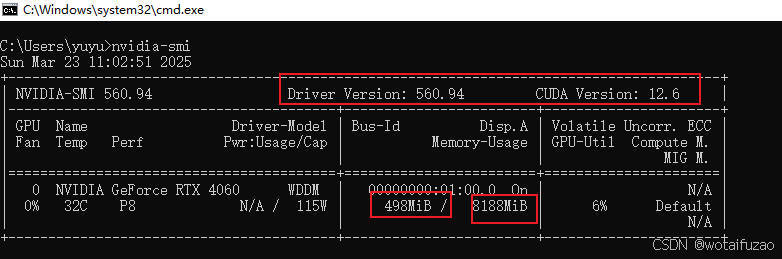
4.1 查询Cuda版本
使用控制台命令查看当前显卡驱动中的cuda版本,如下图CUDA版本是12.6
nvidia-smi
4.2 安装CudaToolKit工具
注意:CudaToolkit版本不能大于上面的显卡Cuda版本
- Cuda各版本下载地址:【CudaToolkit官网下载】
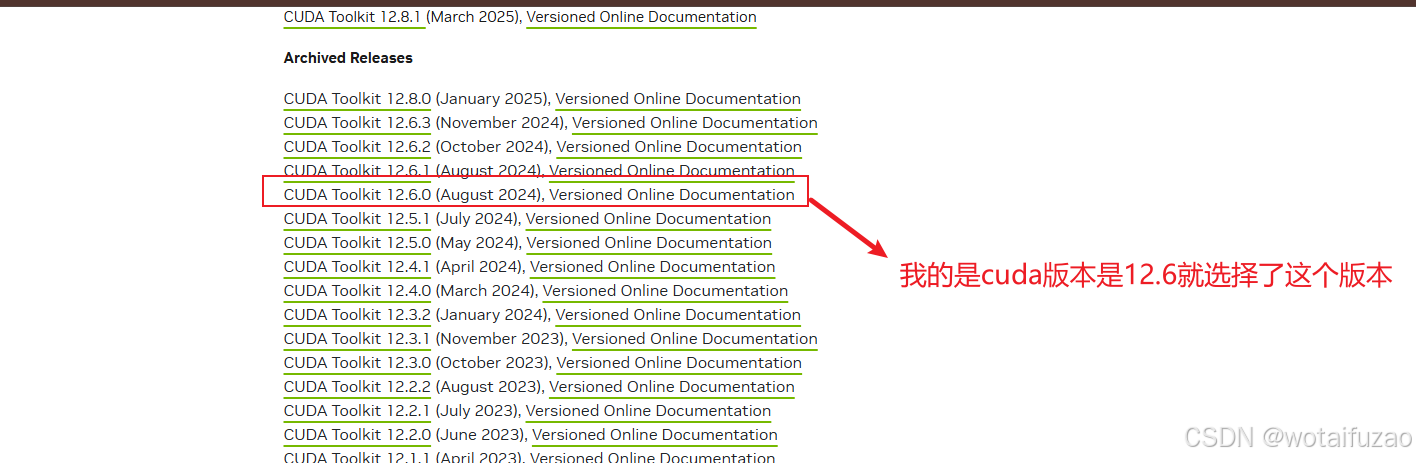
- 具体参数的选择如下图:
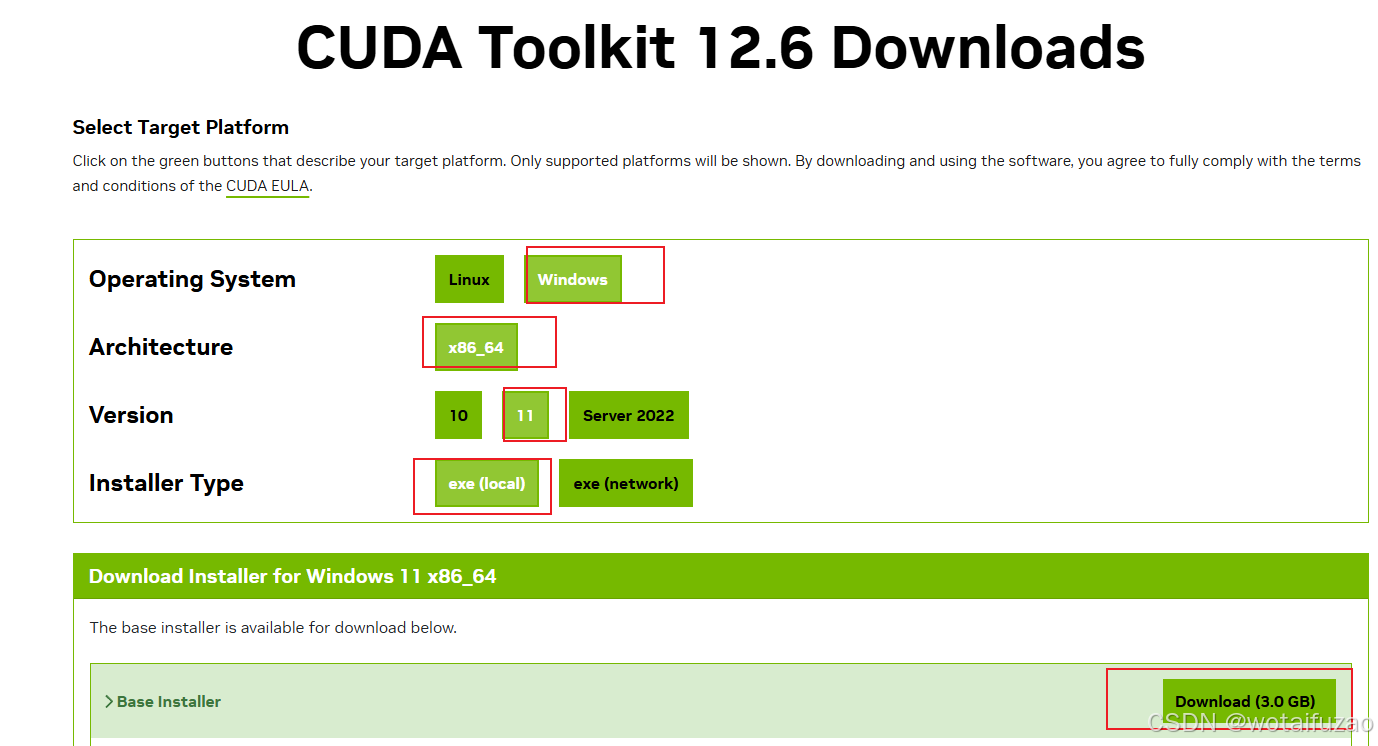
- 下载后双击执行:

双击后有一个临时提取文件安装,路径可以不修改,安装后会自动删除(前提C盘空间够)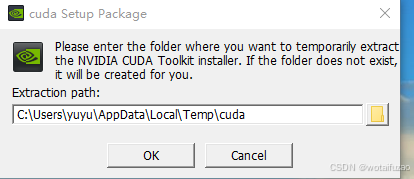
- 选择自定义安装
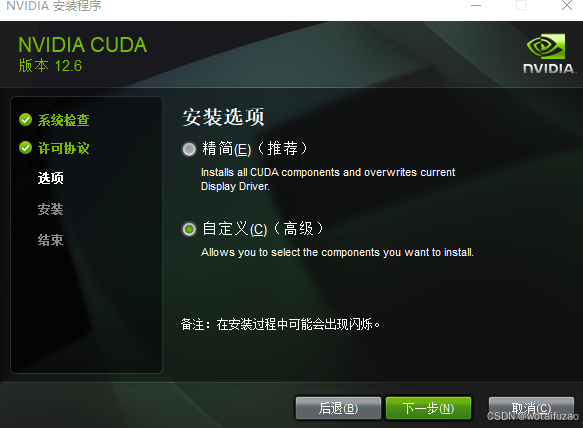
- 第一次直接点击下一步安装
如果你是第一次安装,尽量全选
如果你是第n次安装,尽量只选择第一个,不然会出现错误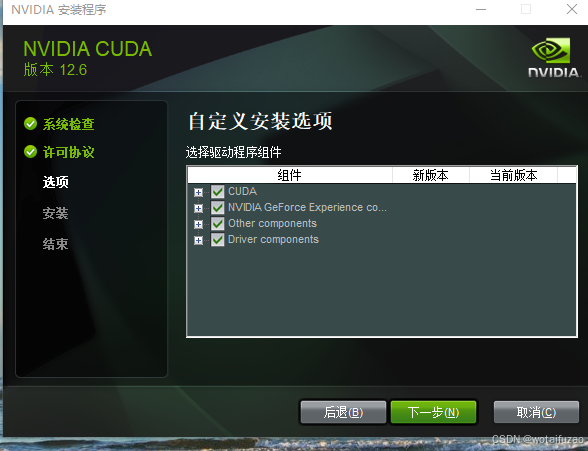
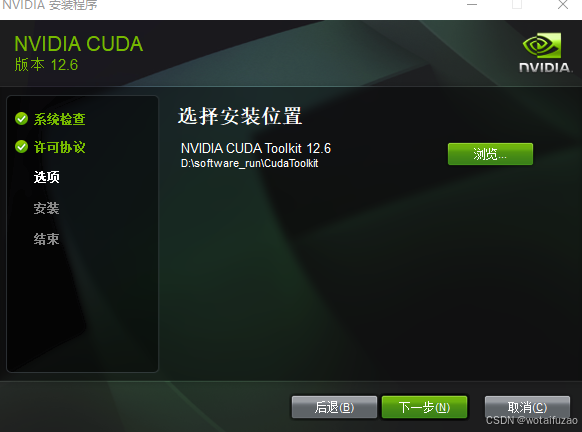
- 选择自定义的系统盘中,我选择子的软件盘中:
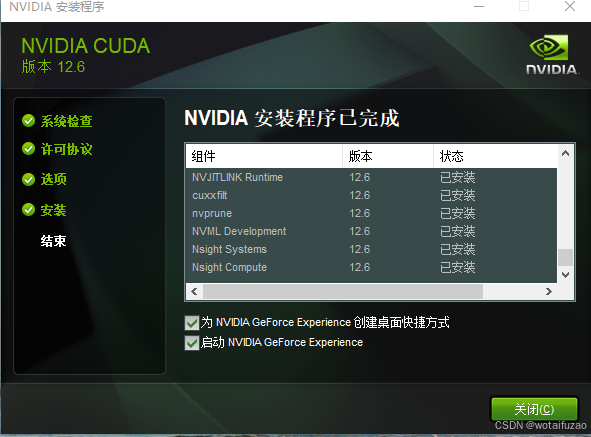
- 点击完整关闭,第一次会有相关账号可以注册一下
4.3 CUDA环境变量配置
在环境变量界面新建环境变量–>填充cuda地址–>确定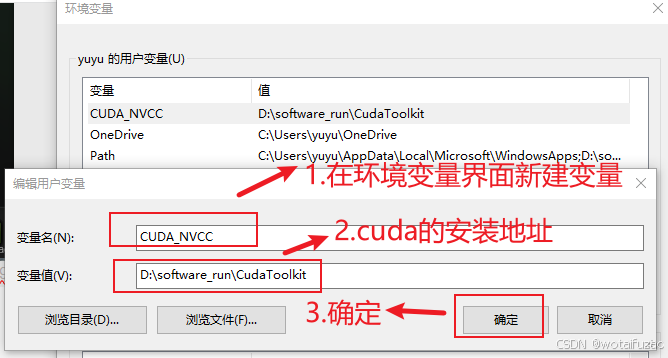
1.选择Path–>2.编辑Path–>3.新建环境变量–>4.添加定义的变量–>5.确认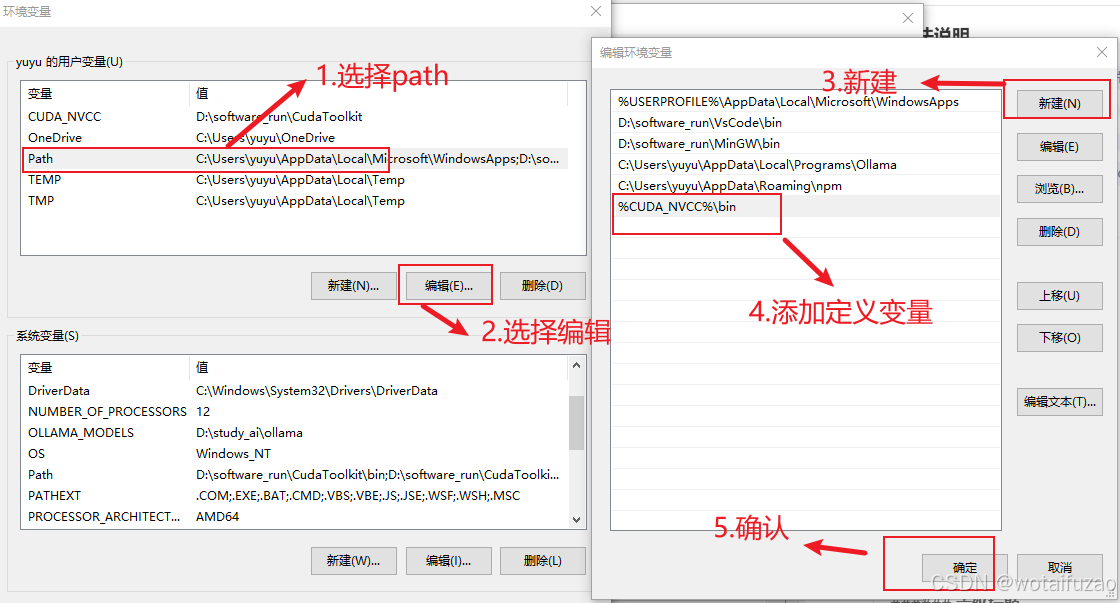
在CMD中输入:nvcc --version,有下面说明安装成功: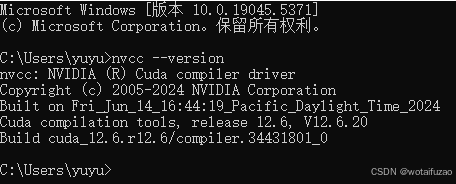
4.4 设置Ollama的环境变量
在控制台输入:nvidia-smi -L,即可查看GPU的UUID,后面备用。
nvidia-smi -L
 Ollama安装好后,为了让推理跑在GPU上,可以按照如下步骤 设置环境变量:
Ollama安装好后,为了让推理跑在GPU上,可以按照如下步骤 设置环境变量:
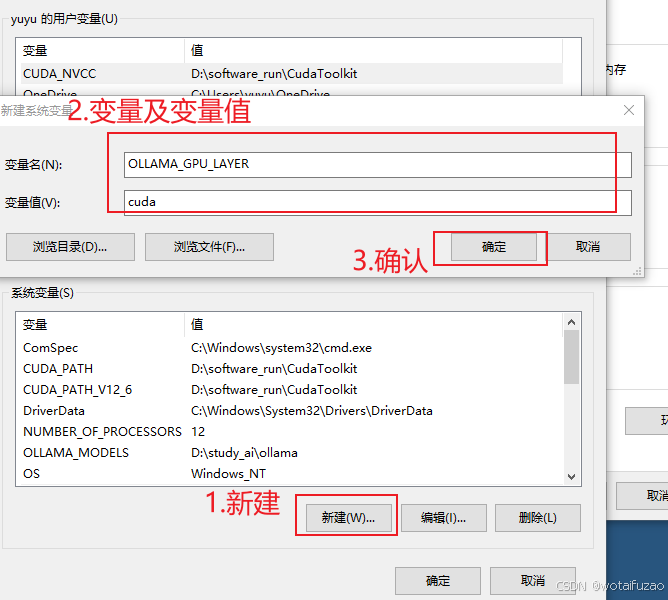
- 在“系统变量”中,点击“新建”按钮
- 添加以下环境变量–>变量名:OLLAMA_GPU_LAYER 变量值:cuda
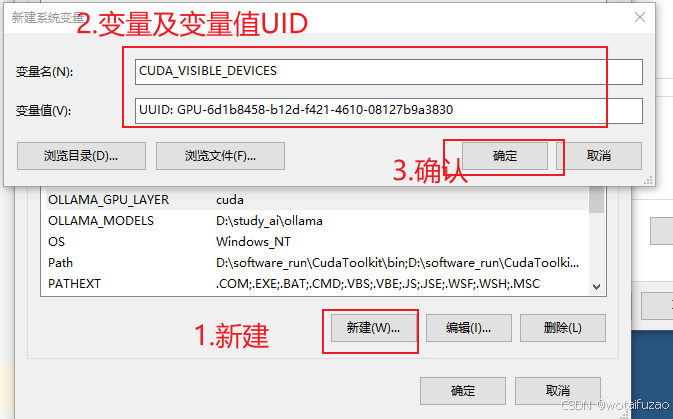
- 需要指定特定的 GPU,可以添加以下环境变量:变量名:CUDA_VISIBLE_DEVICES 变量值:GPU的UUID(按编号有时找不到,所以使用UUID)
5.实际加上测试
笔误;软考开发 ,但是大模型识别也是开发的规范、
具体CPU和GPU的调用情况,如下: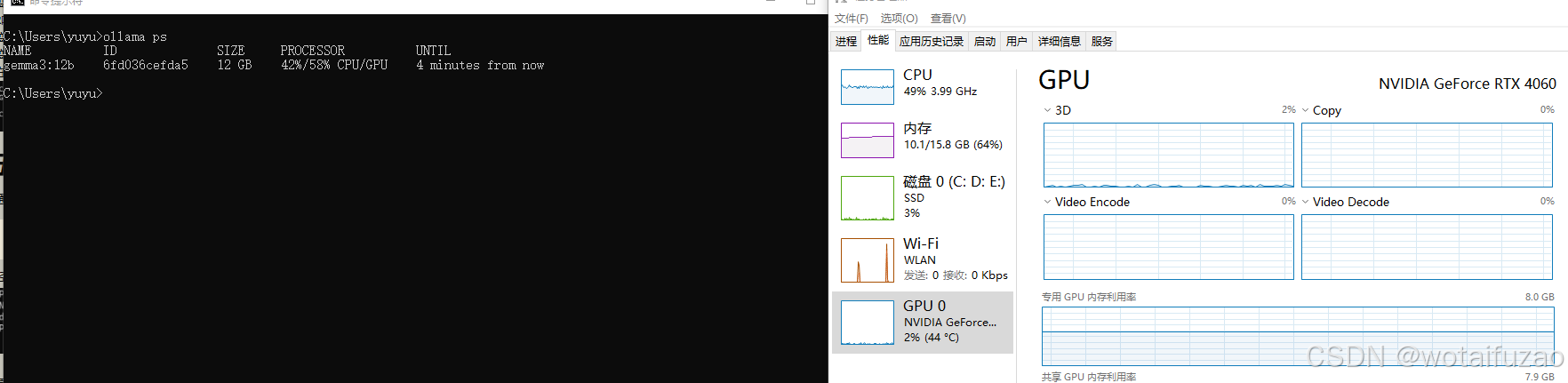
网上也有人:经验证:8G的显卡,跑8b的模型可以100%用GPU,非常流畅。跑14b的cpu和gpu基本4/6开,可以观察SIZE模型运行需要的大小。具体可以参考这个blog。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)