DeepSeek R1来源、使用及部署
1985年,出生于广东湛江。2002年,以高考状元考入浙大电子信息工程专业。2005年,获全国大学生电子设计竞赛一等奖。2007年,考上浙大信息与通信工程研究生。2008年,开始探索全自动量化交易。2010年,获硕士学位,研究目标跟踪算法。2013年,与徐进创立杭州雅克比投资公司。2015年,成立杭州幻方科技,专注量化投资。2016年,幻方推出首个AI模型,实现策略AI化。2018年,幻方确立以A
文章目录
一. DeepSeek R1的来源
1. 梁文锋简介
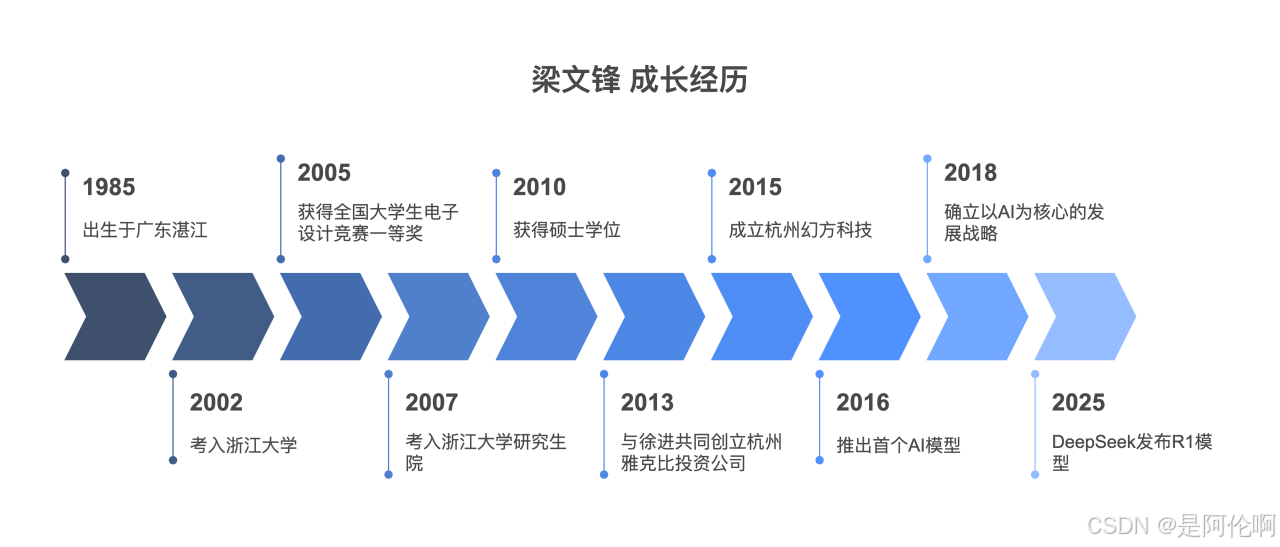
- 1985年,出生于广东湛江。
- 2002年,以高考状元考入浙大电子信息工程专业。
- 2005年,获全国大学生电子设计竞赛一等奖。
- 2007年,考上浙大信息与通信工程研究生。
- 2008年,开始探索全自动量化交易。
- 2010年,获硕士学位,研究目标跟踪算法。
- 2013年,与徐进创立杭州雅克比投资公司。
- 2015年,成立杭州幻方科技,专注量化投资。
- 2016年,幻方推出首个AI模型,实现策略AI化。
- 2018年,幻方确立以AI为核心的发展战略。
- 2019年,研发“萤火一号”训练平台。
- 2020年,“萤火一号”AI超级计算机投入运作。
- 2021年,“萤火二号”投入10亿元,幻方资产破千亿。
- 2023年,宣布进军通用人工智能(AGI)。
- 2024年,DeepSeek发布V2和V3模型,公布技术细节。
- 2025年,DeepSeek发布R1模型,震动美国科技界。
2. 幻方量化的发展历程
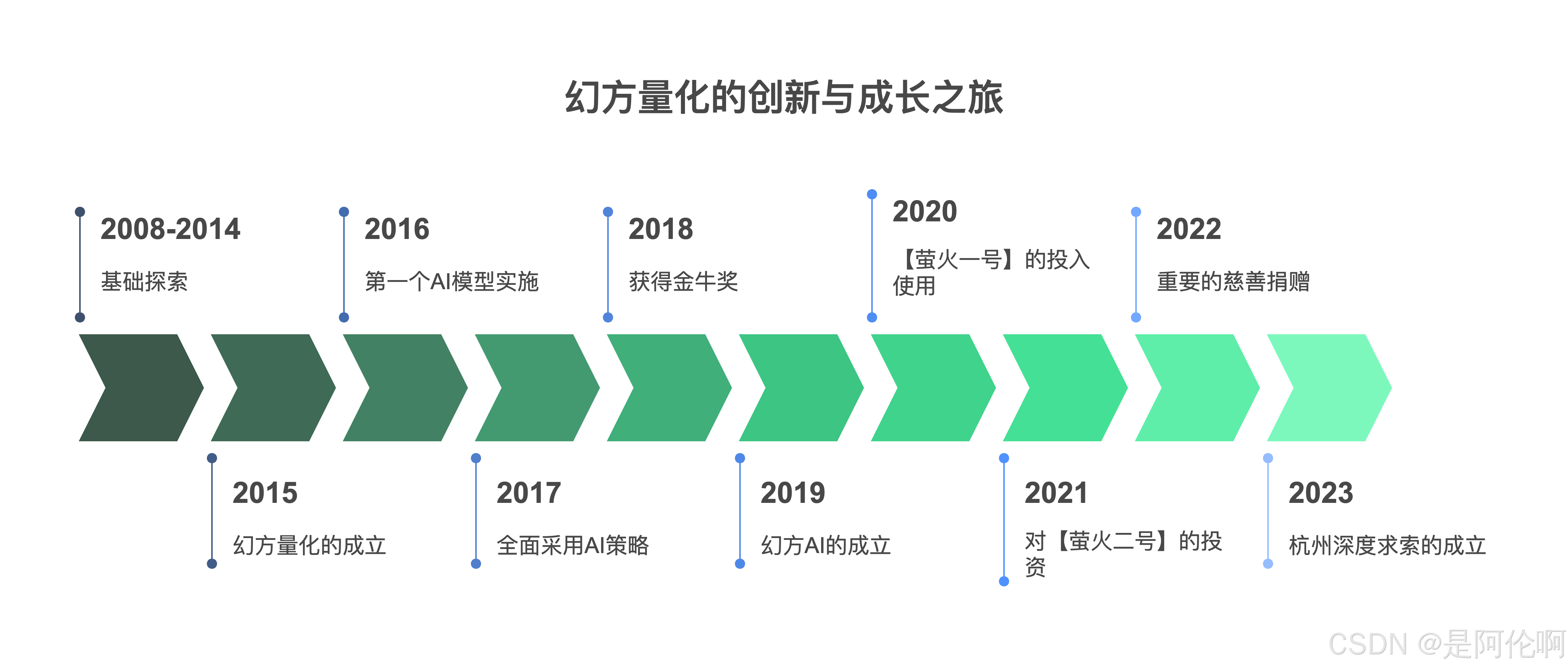
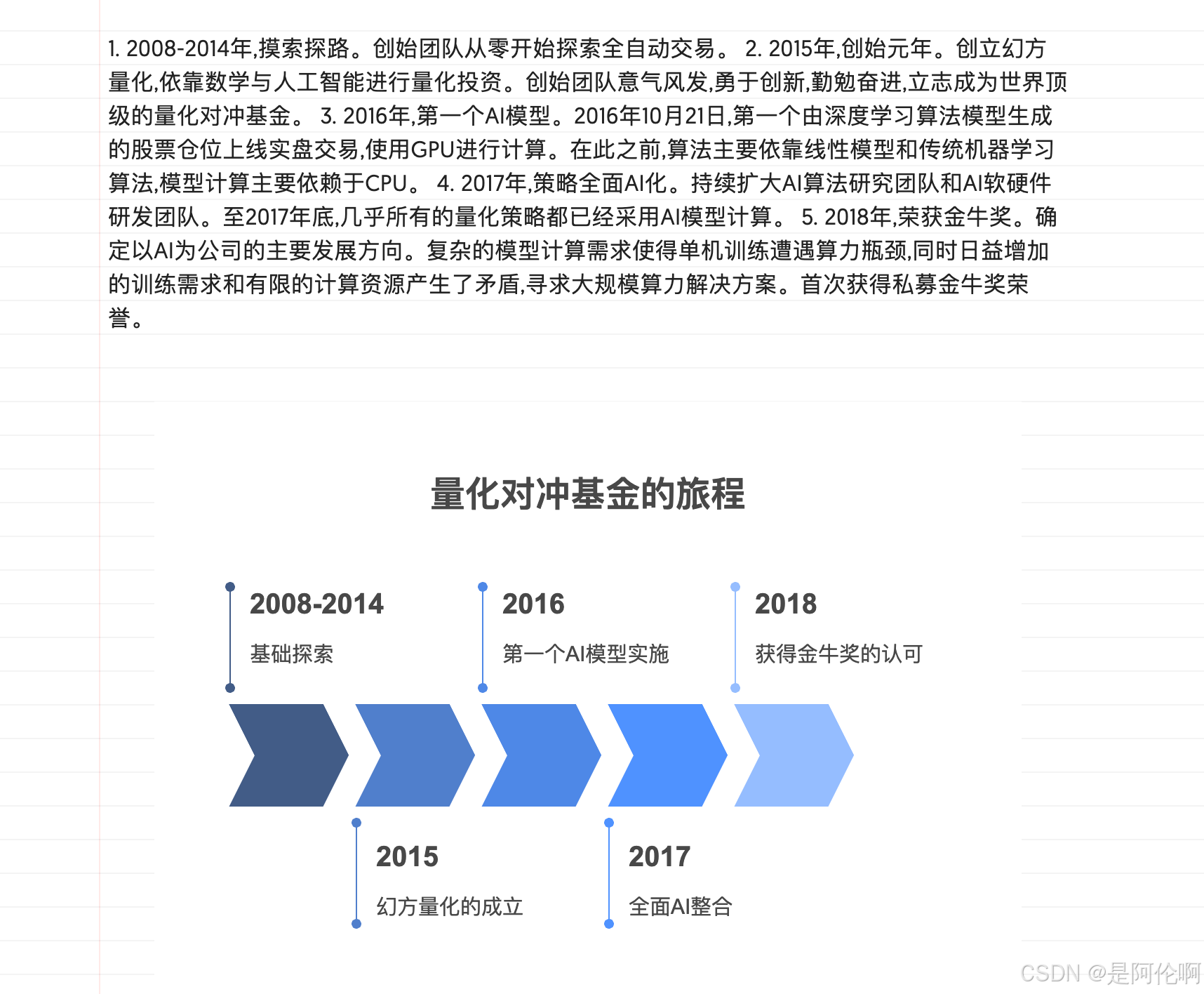
- 2008-2014年,摸索探路。创始团队从零开始探索全自动交易。
- 2015年,创始元年。创立幻方量化,依靠数学与人工智能进行量化投资。创始团队意气风发,勇于创新,勤勉奋进,立志成为世界顶级的量化对冲基金。
- 2016年,第一个AI模型。2016年10月21日,第一个由深度学习算法模型生成的股票仓位上线实盘交易,使用GPU进行计算。在此之前,算法主要依靠线性模型和传统机器学习算法,模型计算主要依赖于CPU。
- 2017年,策略全面AI化。持续扩大AI算法研究团队和AI软硬件研发团队。至2017年底,几乎所有的量化策略都已经采用AI模型计算。
- 2018年,荣获金牛奖。确定以AI为公司的主要发展方向。复杂的模型计算需求使得单机训练遭遇算力瓶颈,同时日益增加的训练需求和有限的计算资源产生了矛盾,寻求大规模算力解决方案。首次获得私募金牛奖荣誉。
- 2019年,百亿量化。幻方AI(幻方人工智能基础研究有限公司)注册成立,致力于AI的算法与基础应用研究。AI软硬件研发团队自研幻方【萤火一号】AI集群,搭载了500块显卡,使用200Gbps高速网络互联。 幻方资本成立,获得香港九号牌。幻方量化跻身百亿私募。
- 2020年,【萤火一号】投入使用。【萤火一号】总投资近2亿元,搭载1100加速卡,于当年正式投用,为幻方的AI研究提供算力支持。 换房资本获批合格境外机构投资者资格,吸引海外资金长期投资A股市场。
- 2021年,幻方AI投入十亿元建设【萤火二号】。【萤火二号】一期确立一任务级分时调度共享AI算力的技术方案,从软硬件两方面共同发力:高性能加速卡、节点间200Gbps高速互联网络、自研分布式并行文件系统(3FS)、网络拓扑通讯方案(hfreduce)、算子库(hfai.nn),高易用性应用层等,
将【萤火二号】的性能发挥至极致。幻方公益工作小组成立,以专业化可持续的公益方式回馈社会。 - 2022年,守望相助,突破极限。幻方量化共计向慈善机构捐赠2.2138亿元,公司员工"一只平凡的小猪"个人捐助1.38亿元,支持15家慈善机构的23个公益项目,在全国范围内帮助弱势群体,促进社会的公平和发展。
- 2023年,成立杭州深度求索人工智能基础技术研究有限公司。
3. DeepSeek LLM模型的发展历程
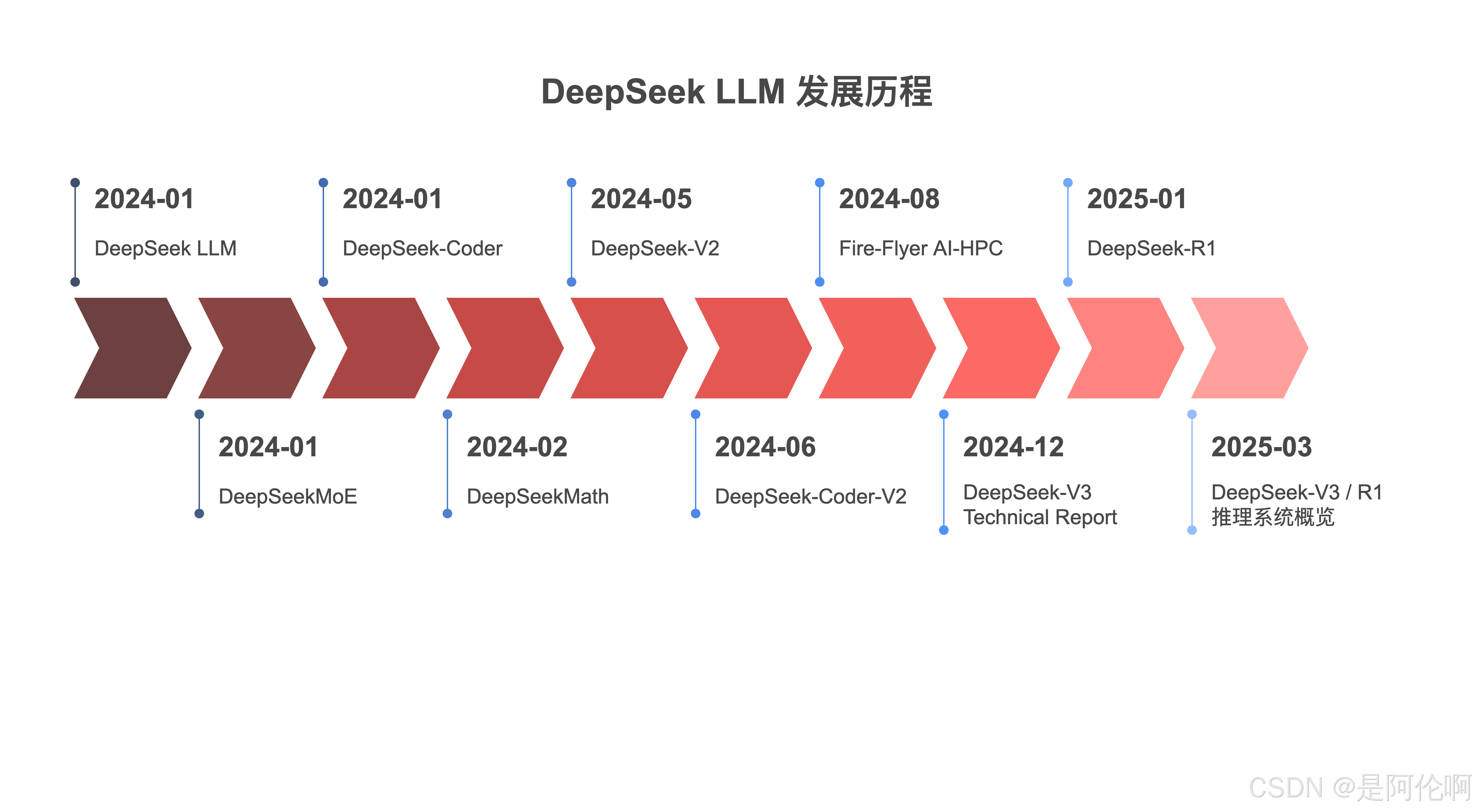
- 2024-01:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- 2024-01:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- 2024-01:DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence
- 2024-02:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- 2024-03:DeepSeekVL: Towards Real-World Vision-Language Understanding
- 2024-05:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- 2024-05:DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
- 2024-06:DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
- 2024-07:Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
- 2024-08:Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
- 2024-08:DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
- 2024-10:Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
- 2024-11:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
- 2024-12:DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
- 2024-12:DeepSeek-V3 Technical Report
- 2025-01:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
- 2025-01:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 2025-03:DeepSeek-V3 / R1 推理系统概览
4. DeepSeek R1论文浅析
4.1. 评测效果
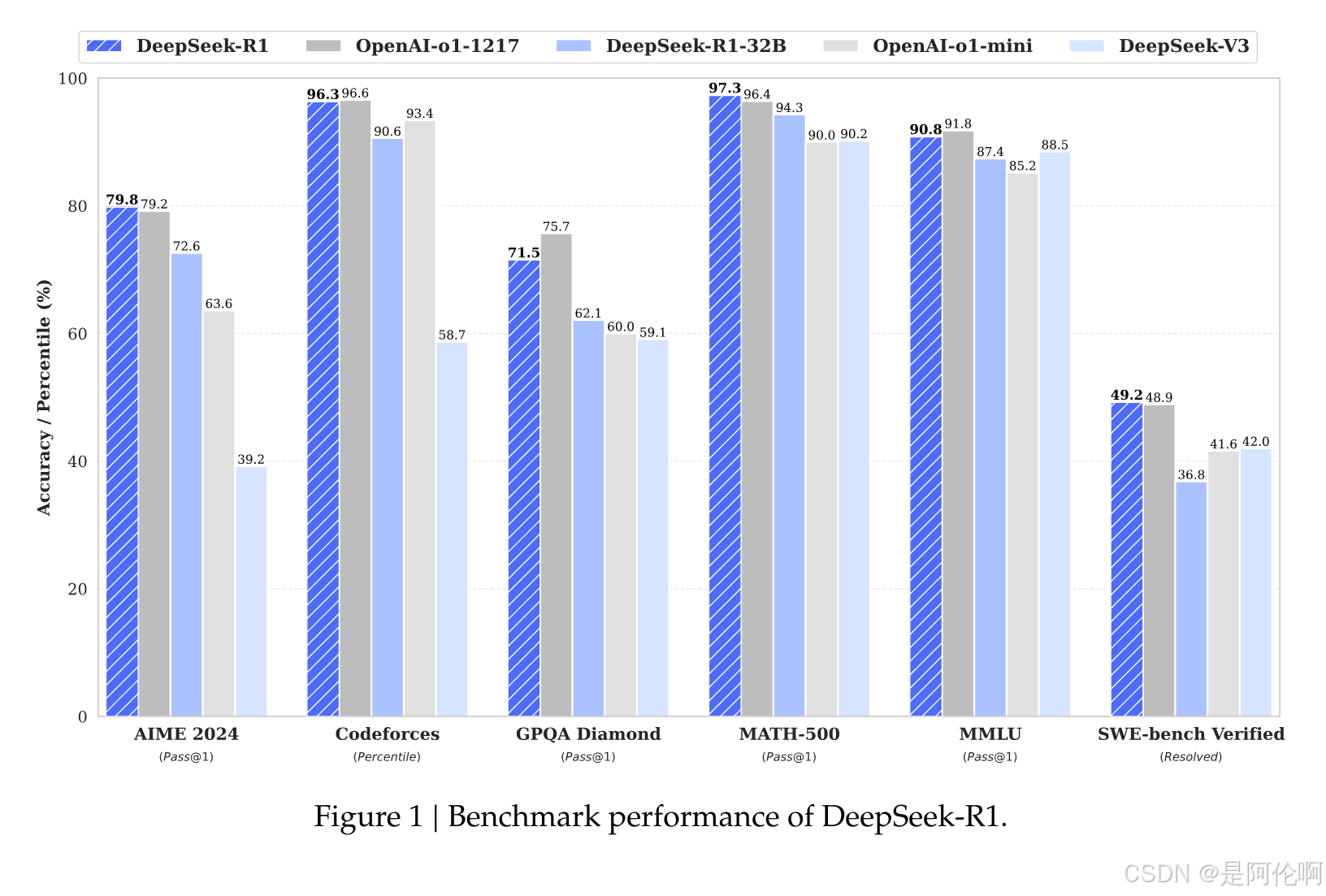
测试集介绍:
- AIME 2024 (Pass@1):数学竞赛。AIME是美国数学邀请赛,题目难度高,需创造性数学思维。
- Codeforces (Percentile):编程竞赛。Codeforces 是全球知名编程竞赛平台,题目涵盖算法、数据结构、动态规划等。
- GPQA Diamond (Pass@1):专业知识问答。GPQA是一个高难度问答数据集,涵盖科学、法律、医学等专业领域,需深度领域知识。
- MATH-500 (Pass@1):数学问题。包含500道高难度数学题(如数论、几何、微积分),需严格推导和符号运算。
- MMLU (Pass@1):综合知识理解。MMLU(Massive Multitask Language Understanding)涵盖57个学科(如历史、计算机、伦理等),测试广泛知识覆盖。
- SWE-bench Verified (Resolved):软件工程。SWE-bench 是软件工程任务测试集,要求模型修复真实GitHub仓库中的代码缺陷或实现功能。
总结:
在编码、数学、软件工程方面可以达到OpenAI-o1-1217的效果,在专业和综合知识领域略逊于OpenAI-o1-1217版本。
在业务上,可以作为OpenAI-o1的平替,且可以本地部署以保证企业私有数据的安全性。
4.2. 关键技术
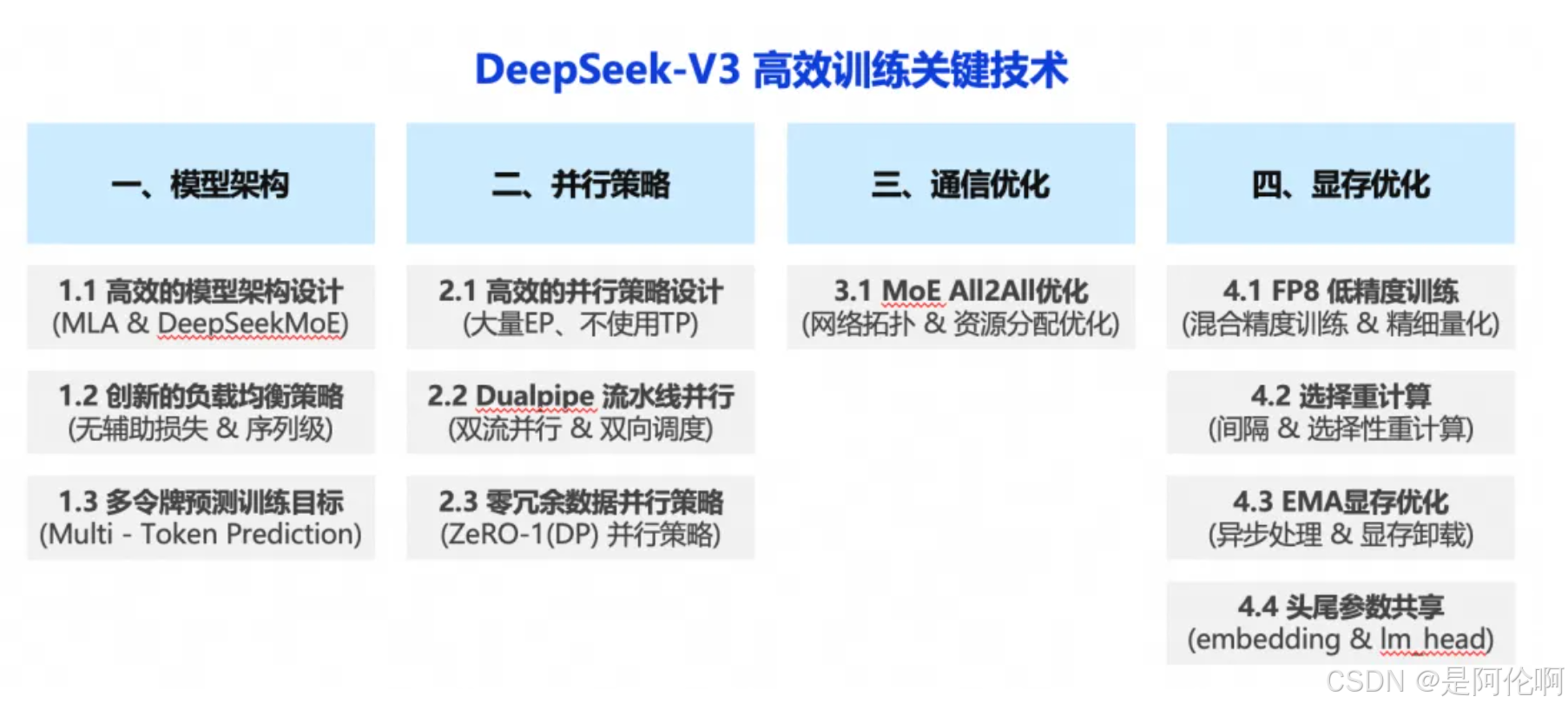
4.2.1. DeepSeek-V3
- 核心技术:
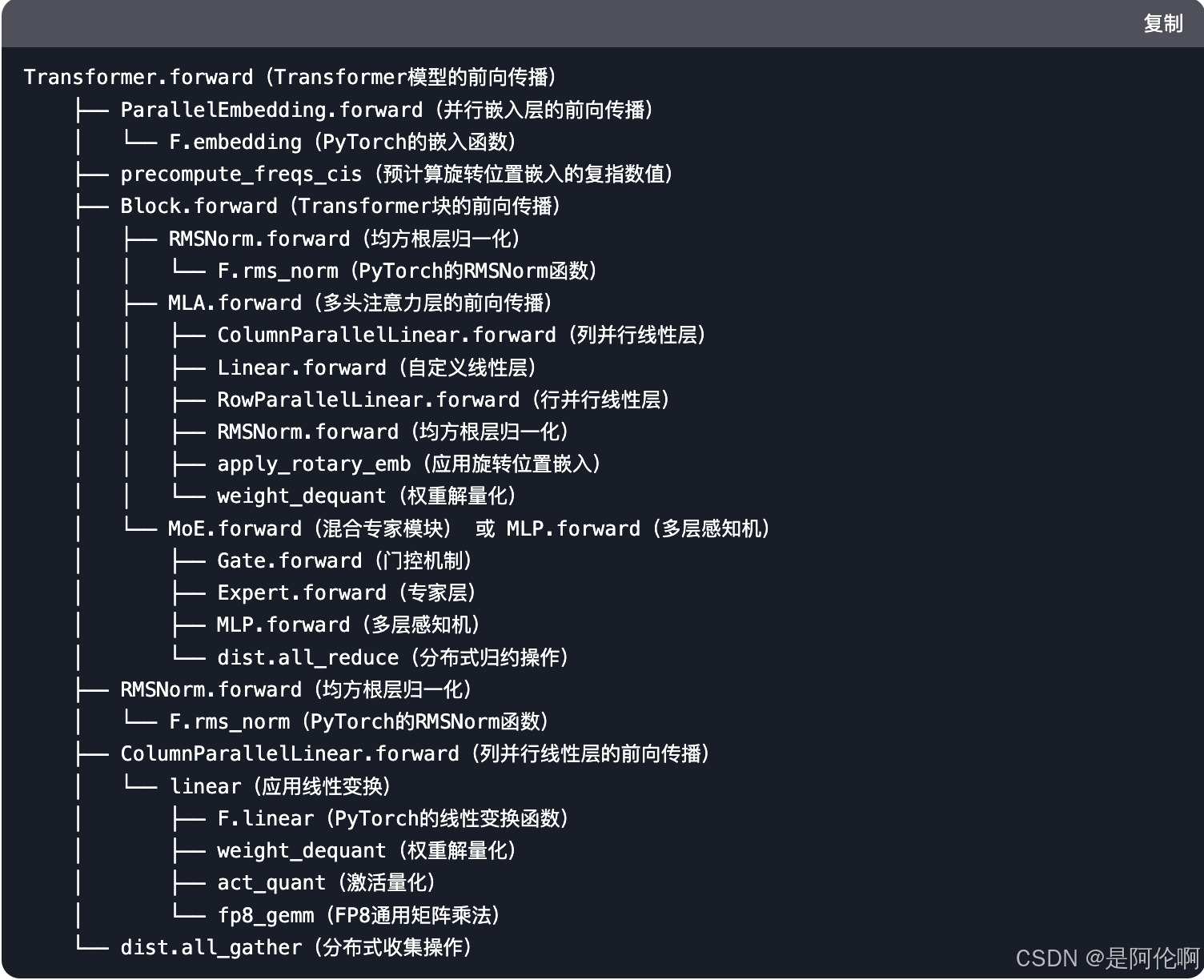
- 模型结构:
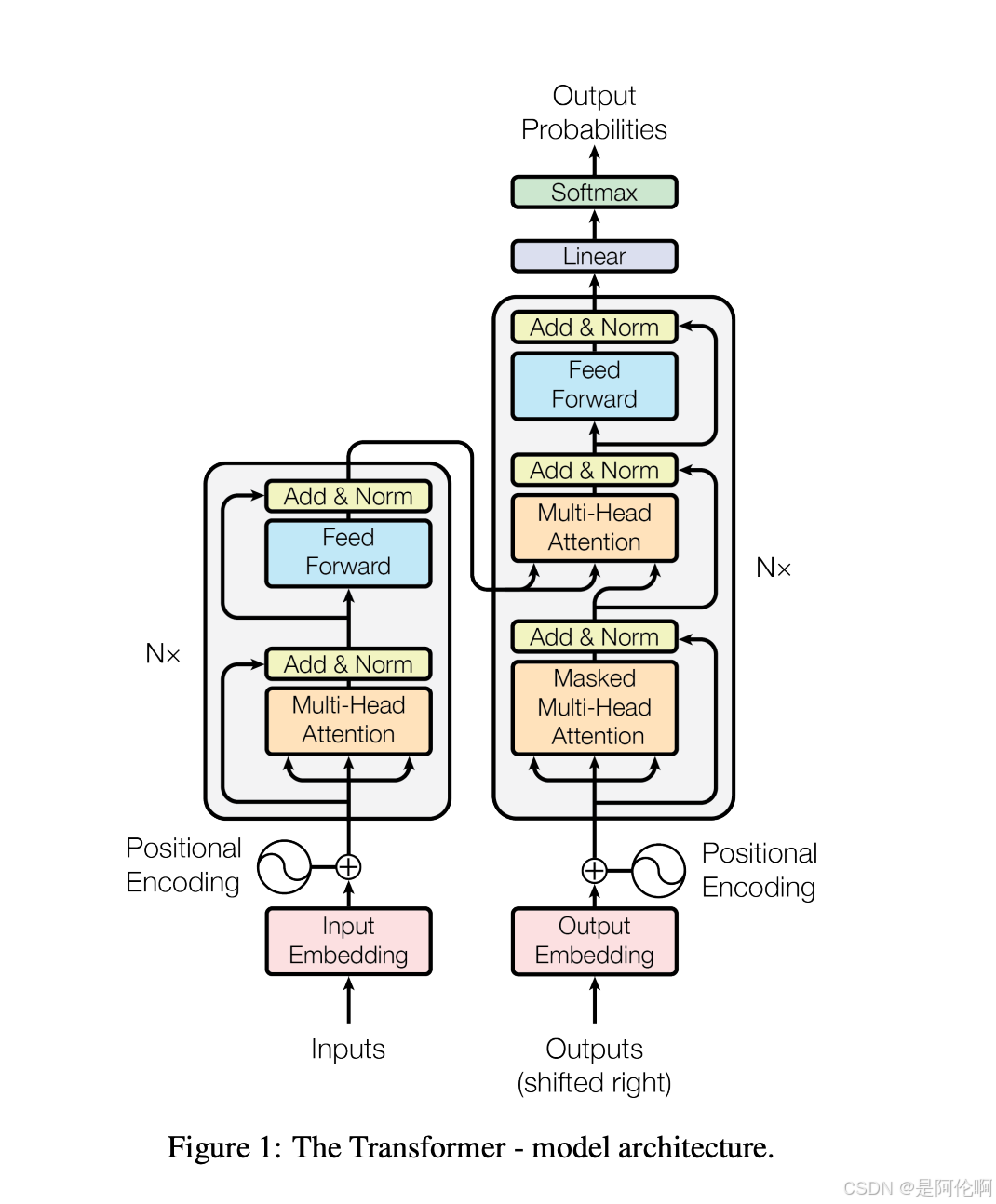
- Transormer模型结构:
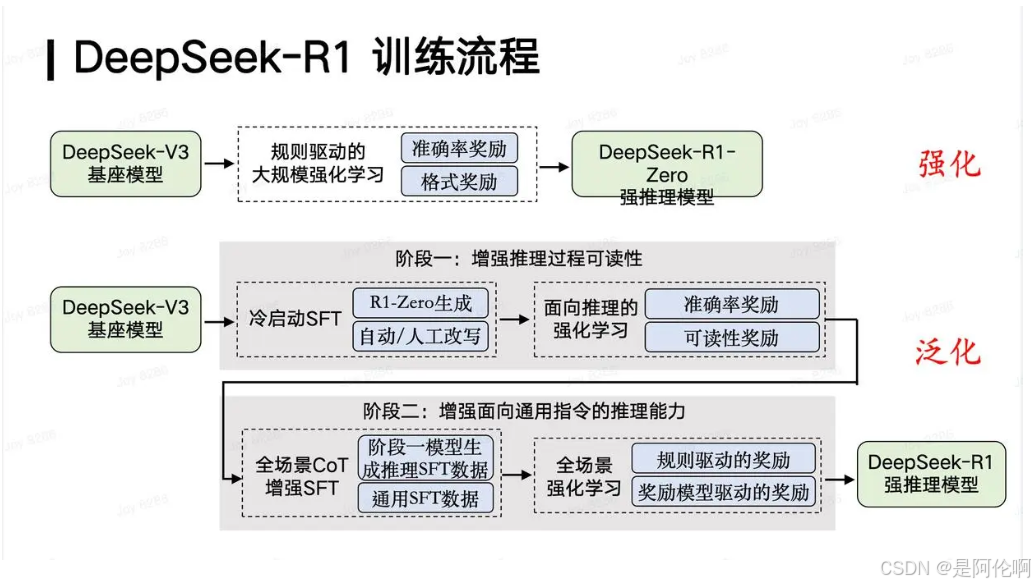
4.2.2. DeepSeek-R1-Zero
- 顿悟时刻:通过重新评估其初始方法学会为问题分配更多思考时间。

- 主体处理流程:基于DeepSeek-V3基座模型,采用对于准确率奖励/格式奖励的规则驱动的大规模强化学习,采用GRPO的组相对策略优化算法,得到了一个纯粹通过强化学习增强的强推理模型,即是DeepSeek-R1-Zero。
- 启示:它强调了强化学习的强大和美感:我们不是明确地教模型如何解决问题,而只是提供正确的激励,然后它自主发展出高级的解决问题策略。
4.2.3. DeepSeek-R1
- 冷启动(生成数据、微调):让R1-Zero生成几千条包括反思、验证的数据,经过人类注释后处理完善处理结果,形成几千条长COT数据。使用生成的几千条长COT数据,微调DeepSeek-V3-Base模型,从而增强模型的可读性和潜力。
- 以推理为导向的强化学习(强化学习):对于冷启动微调后的模型,采用对于准确率奖励/格式奖励/语言一致性奖励的面向推理的强化学习,知道其在推理任务上达到收敛。
- 拒绝采样和监督式微调(生成数据、微调):让训练以推理为导向的强化学习的模型收敛时,生成数据,通过人工过滤,收集了大约60万个推理相关的训练样本。加上20万的事实等非推理数据。使用上述80万条数据对模型进行两个周期的微调。
- 所有场景的强化学习(强化学习):基于规则驱动的奖励/基于奖励模型驱动的奖励,从而提升对于人类偏好、有用性、无害性等能力的提升。
4.3. 出圈的点
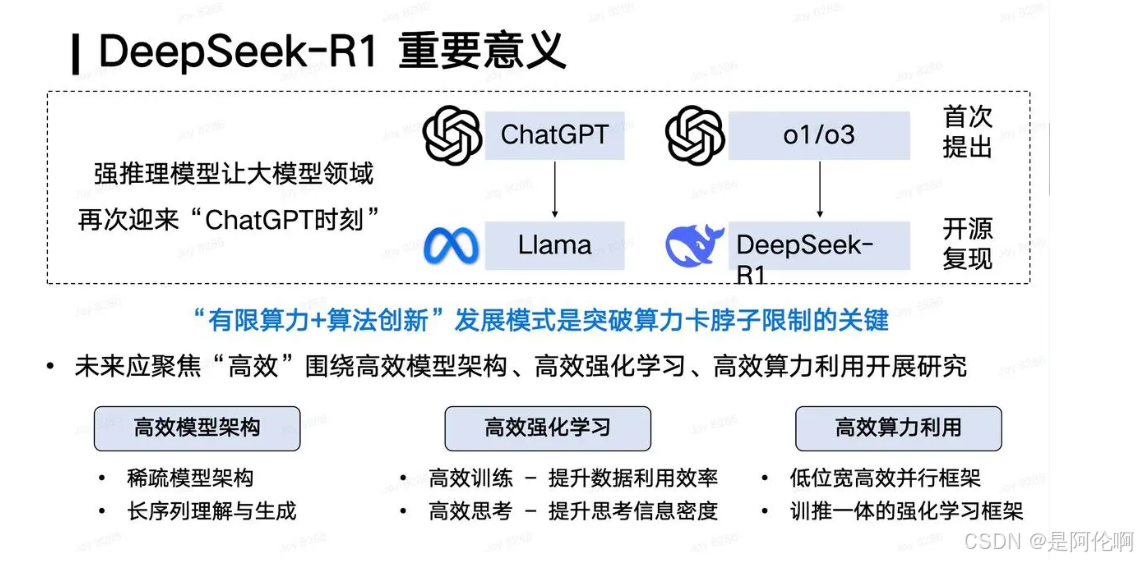
- 2025年DeepSeek-R1的博客和模型开源类似于2023年Llama的开源。
- OpenAI:发布o1后,不开源/隐藏思维过程/收费高
- DeepSeek R1:开源且发布较为详细的技术报告,且整体训练的成本只有500余万美元,不到GPT4训练的十分之一
- 意义:在非常有限的算力资源支持下,通过强大的算法创新,突破了算力瓶颈,也能够做出具有全球意义的领先成果。
5. 本小节参考文献
- 百度百科. 2024. “梁文锋.”
- High-Flyer. 2024. “History.”
- InfoQ. 2024. “刘知远详解 DeepSeek 出圈背后的逻辑”
- arXiv. 2025. “DeepSeek LLM: Scaling Open-Source Language Models with Longtermism.”
- GitHub. 2024. “DeepSeek-V3.”
- DeepSeek. 2024a. “DeepSeek LLM: Scaling Open-Source Language Models with Longtermism.”
- DeepSeek. 2024b. “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models.”
- DeepSeek. 2024c. “DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence.”
- DeepSeek. 2024d. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.”
- DeepSeek. 2024e. “DeepSeekVL: Towards Real-World Vision-Language Understanding.”
- DeepSeek. 2024f. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.”
- DeepSeek. 2024g. “DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data.”
- DeepSeek. 2024h. “DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence.”
- DeepSeek. 2024i. “Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning.”
- DeepSeek. 2024j. “Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models.”
- DeepSeek. 2024k. “DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search.”
- DeepSeek. 2024l. “Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation.”
- DeepSeek. 2024m. “JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation.”
- DeepSeek. 2024n. “DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding.”
- DeepSeek. 2024o. “DeepSeek-V3 Technical Report.”
- DeepSeek. 2025a. “Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling.”
- DeepSeek. 2025b. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.”
- 知乎. 2025. “DeepSeek-V3 / R1 推理系统概览.”
二. DeepSeek R1的应用
1. 普通用户使用
网址或者手机APP使用
2. API调用
2.1. 对话
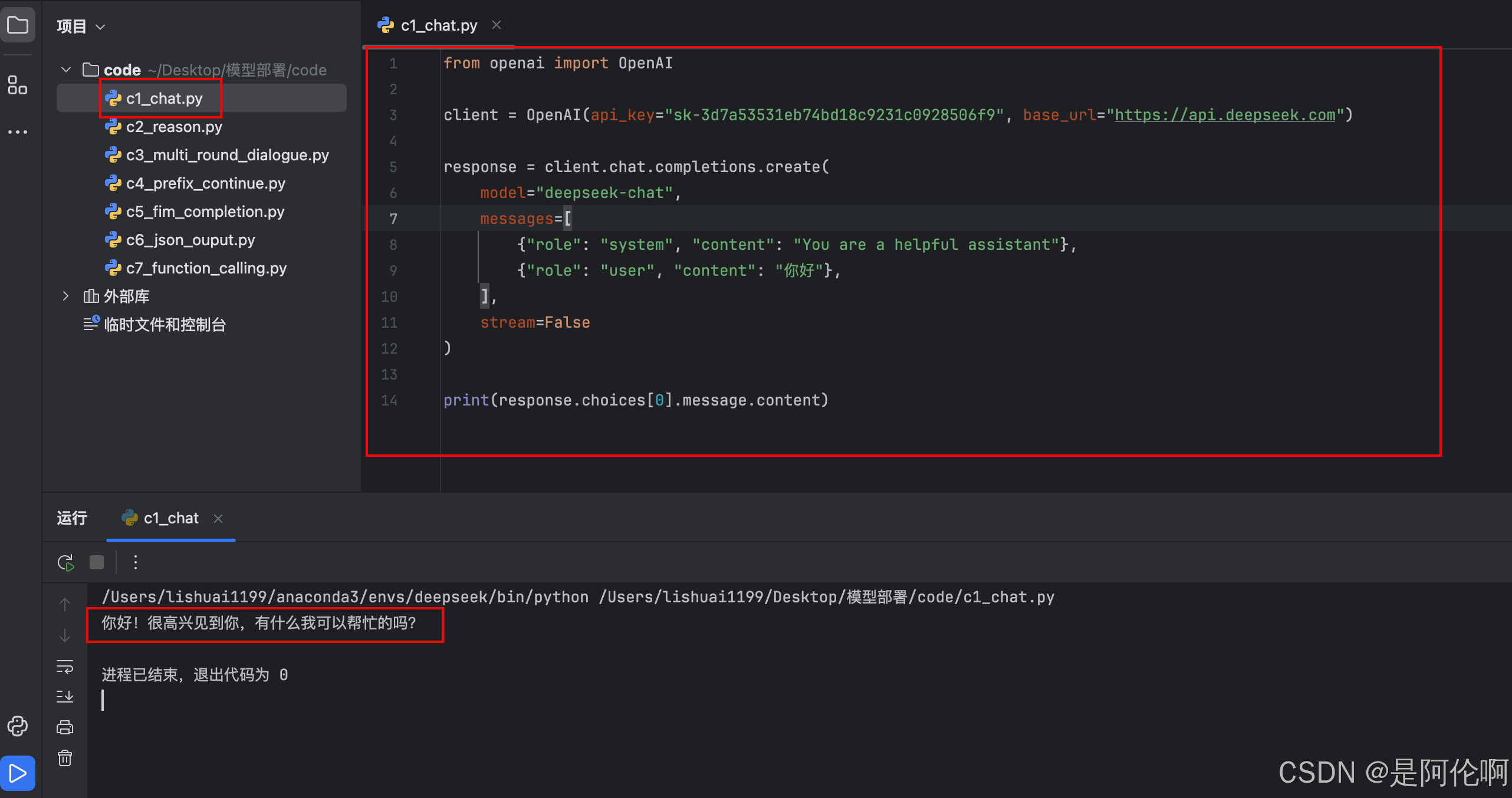
测试样例:你好?
2.2. 推理模型
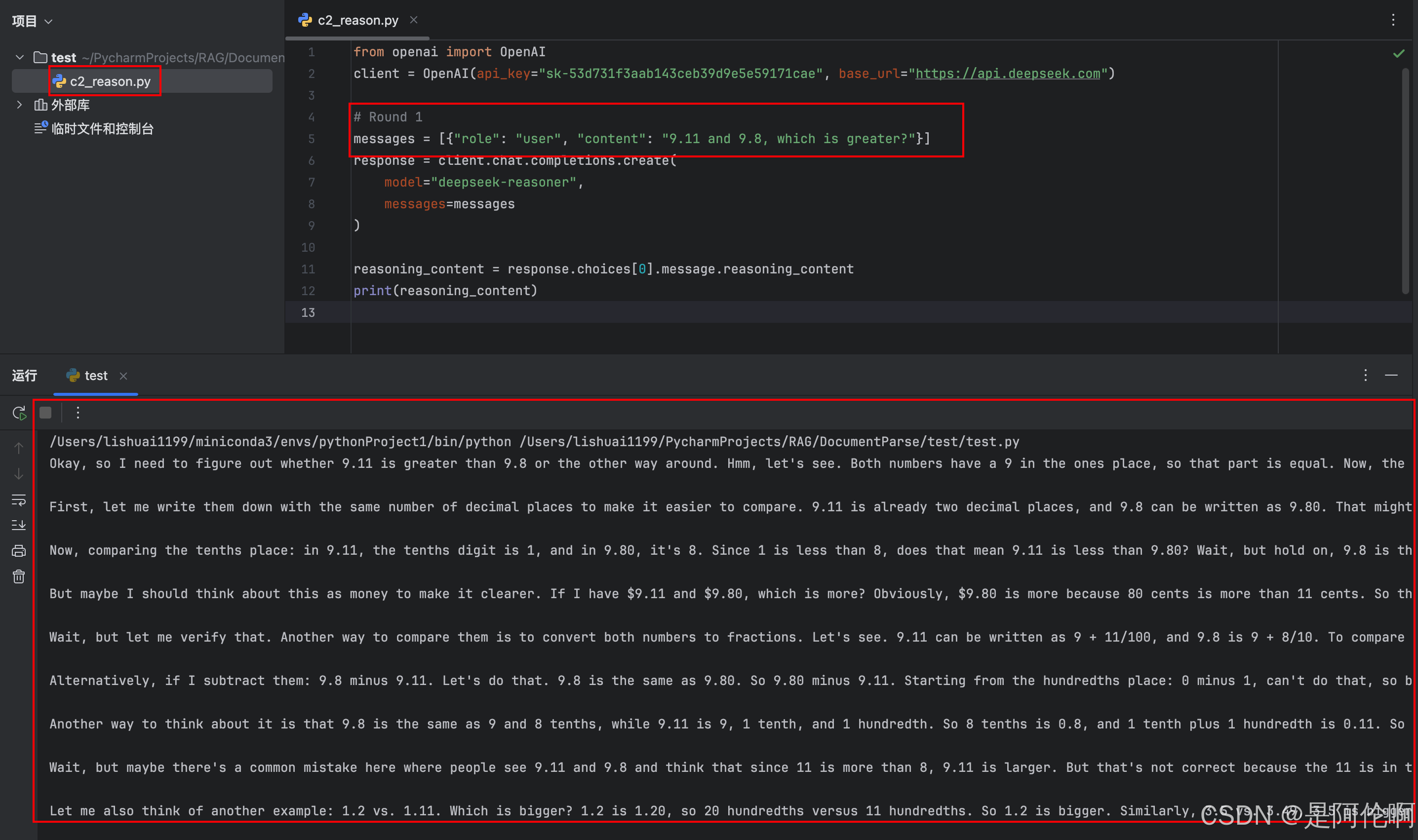
测试样例:3.11和3.9哪个更大?
2.3. 多轮对话
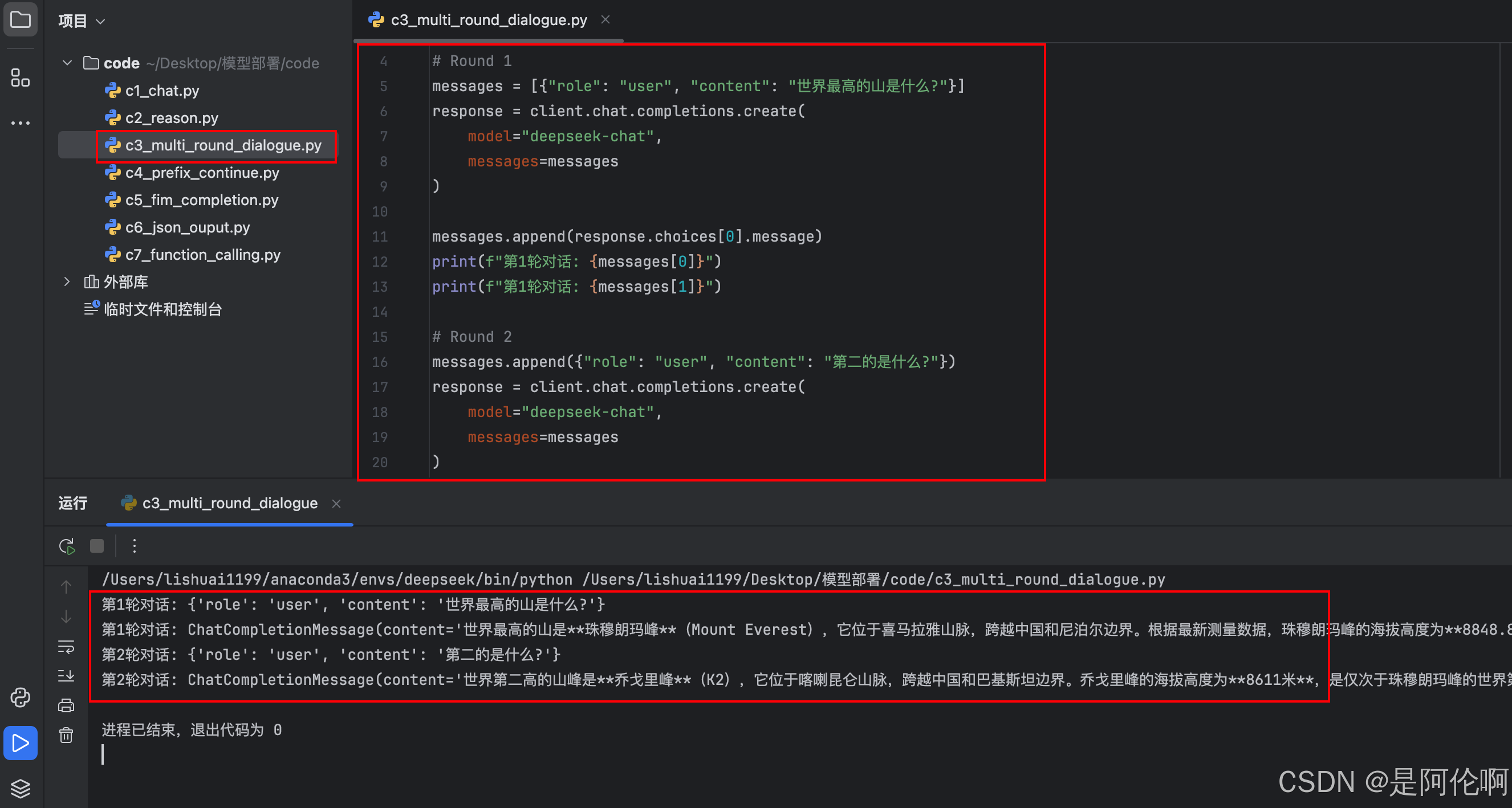
测试样例:世界最高的山是什么?第二的是什么?
2.4. 对话前缀续写
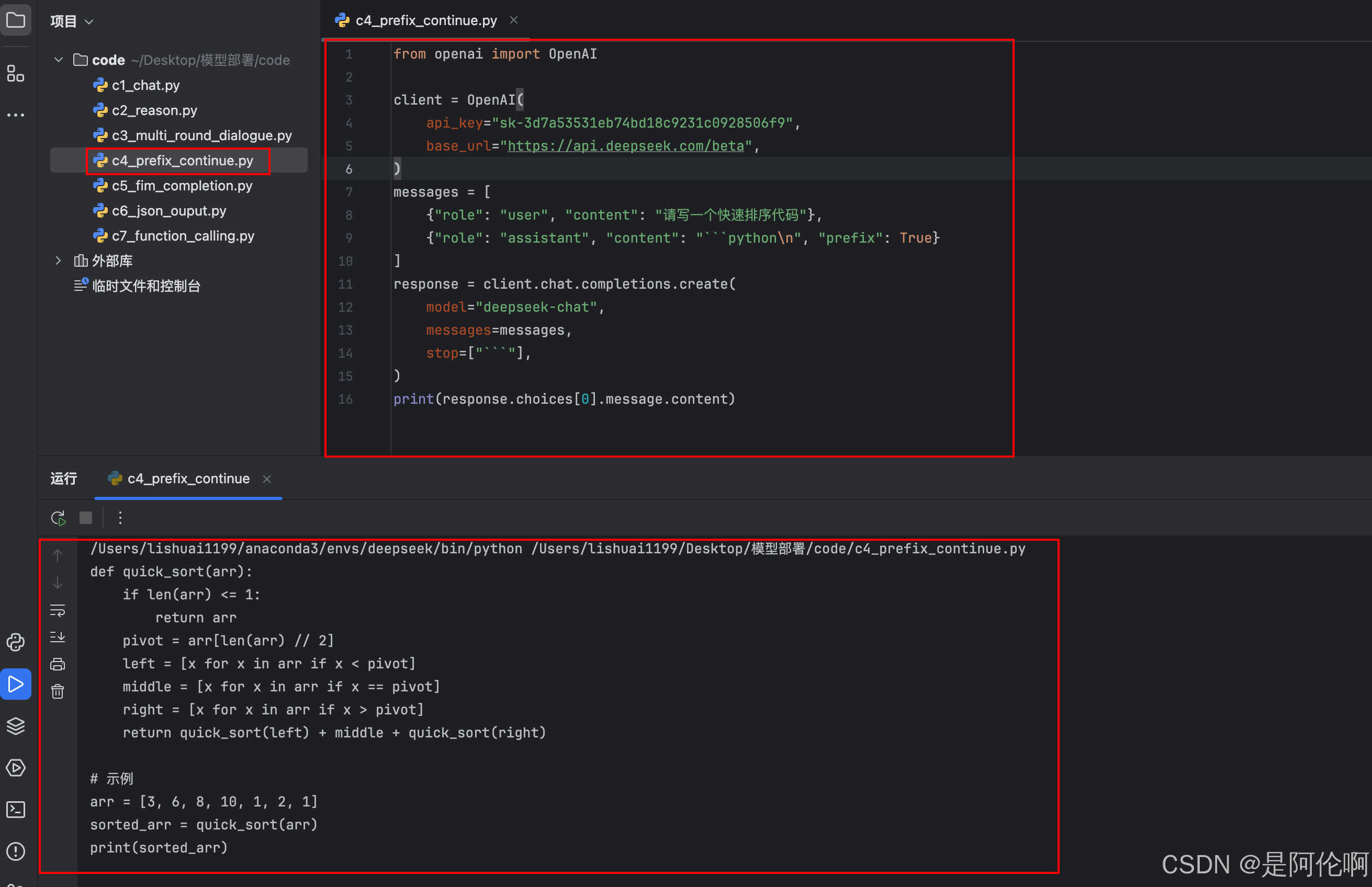
测试样例:代码编写:使用python写一个快排的代码
2.5. FIM补全
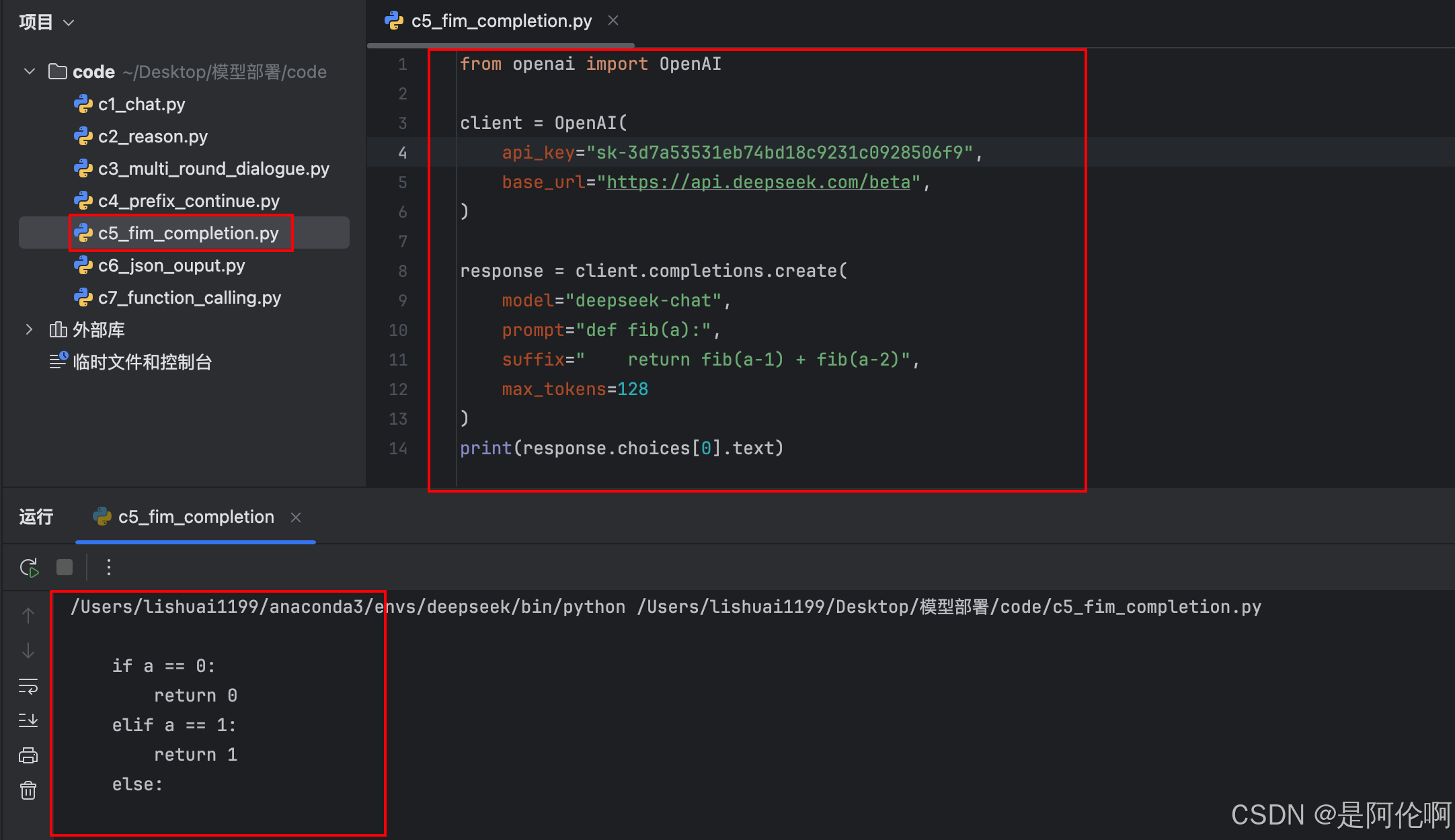
测试样例:代码编写:规定输入和输出:斐波拉契数
2.6. JSON Output
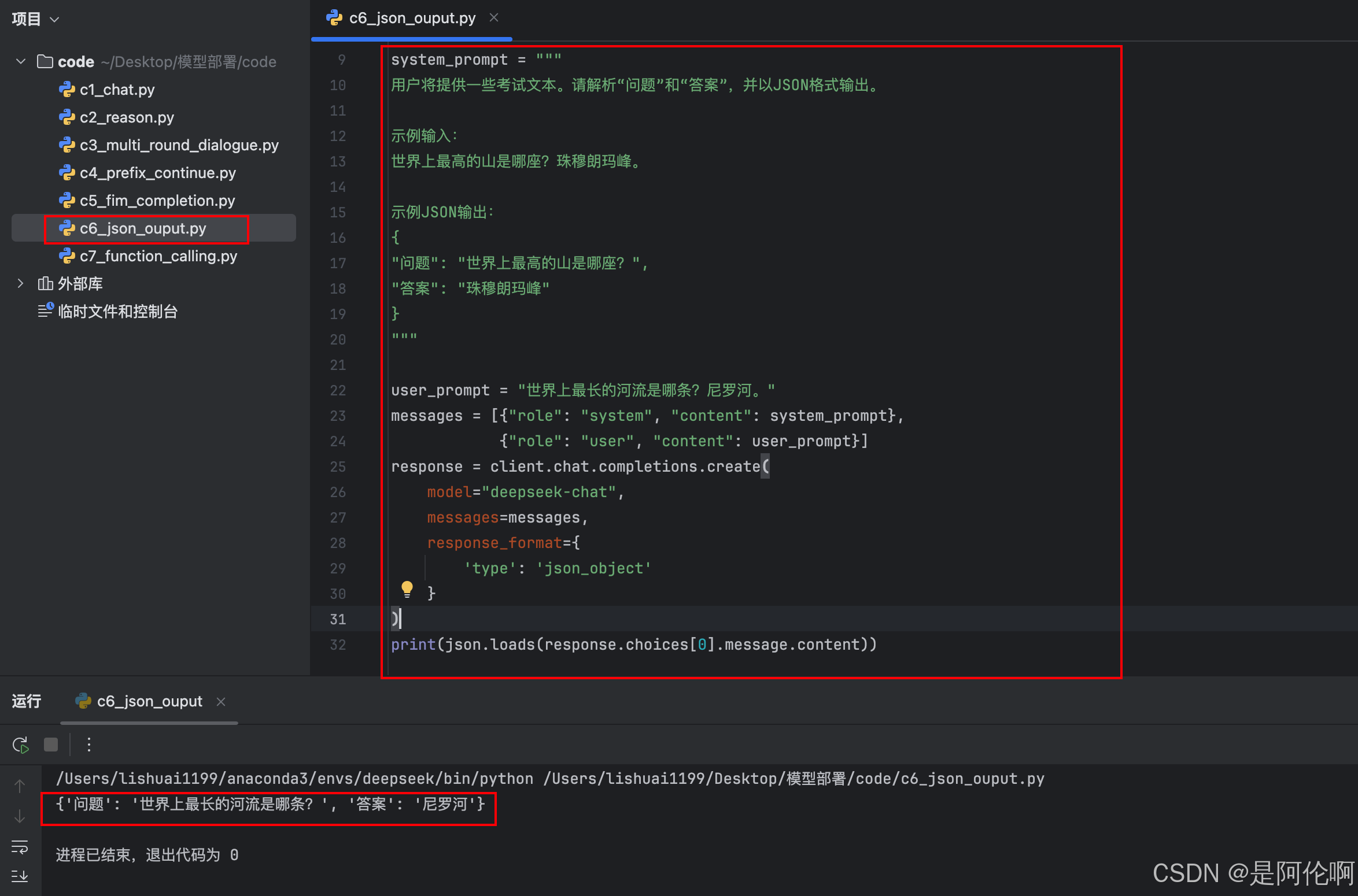
测试样例:提取问答对
3. 大模型应用技术
3.1. RAG知识库
- 流程图:
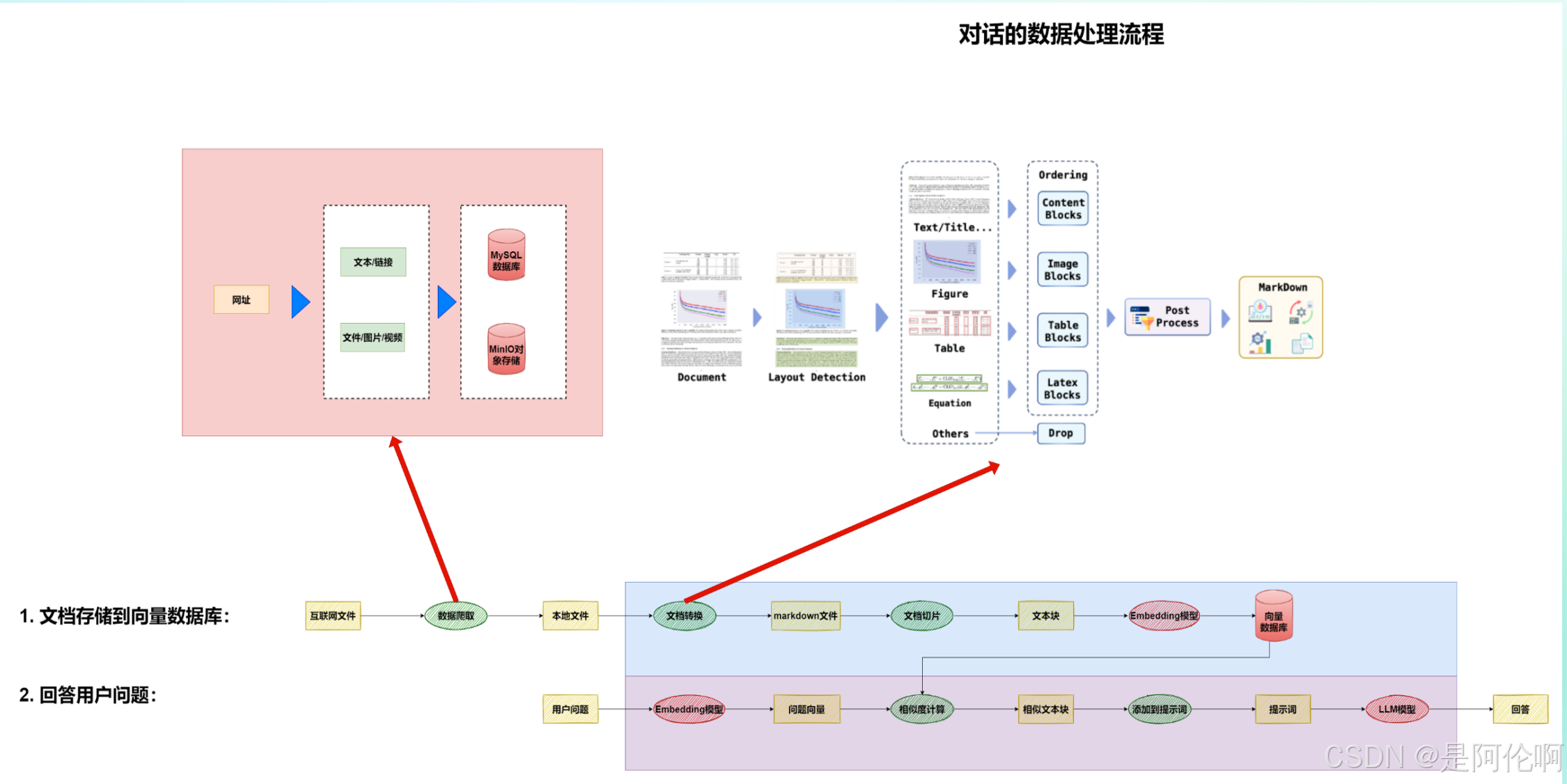
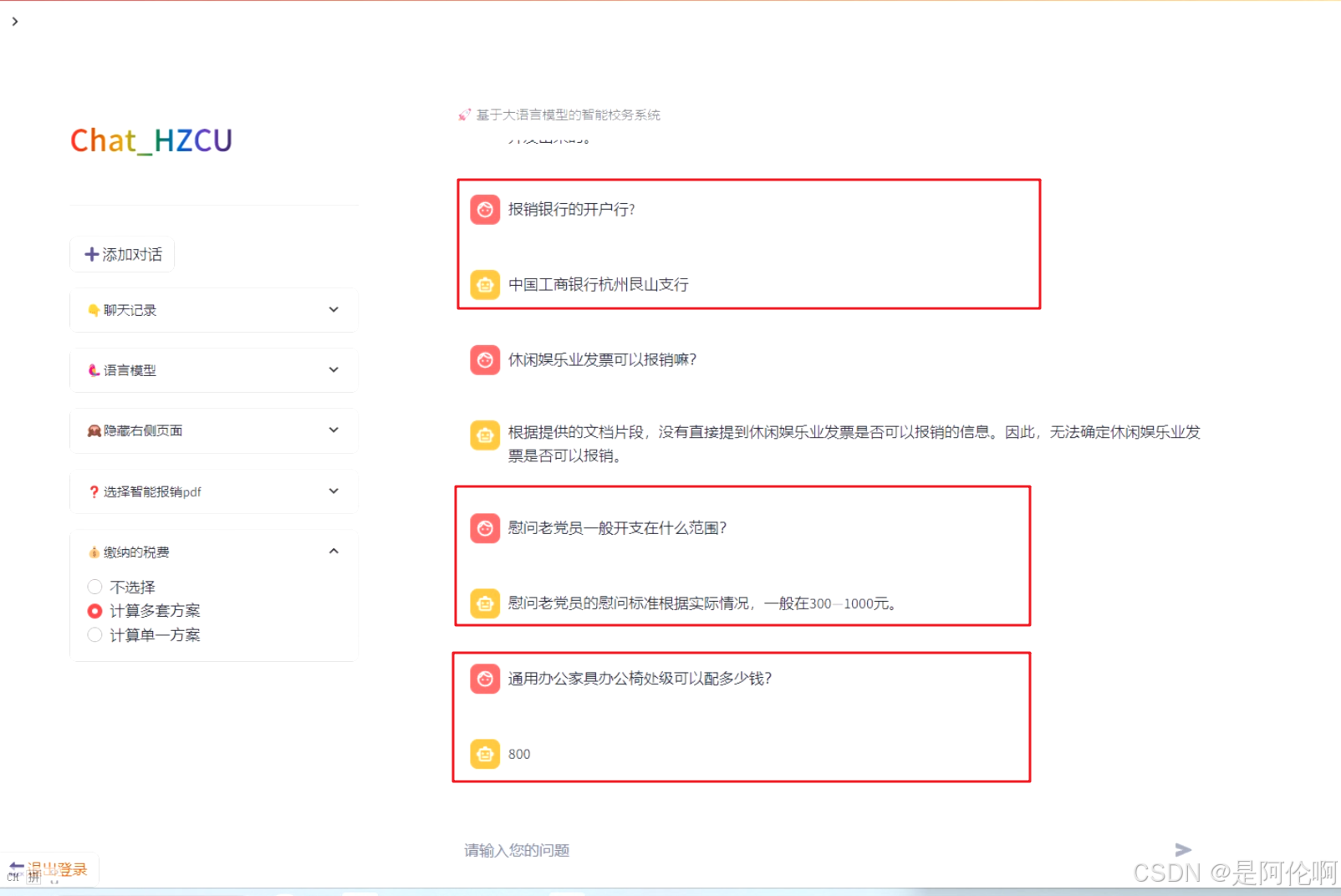
- 效果:
3.2. Function Calling(函数调用)
- 流程图:
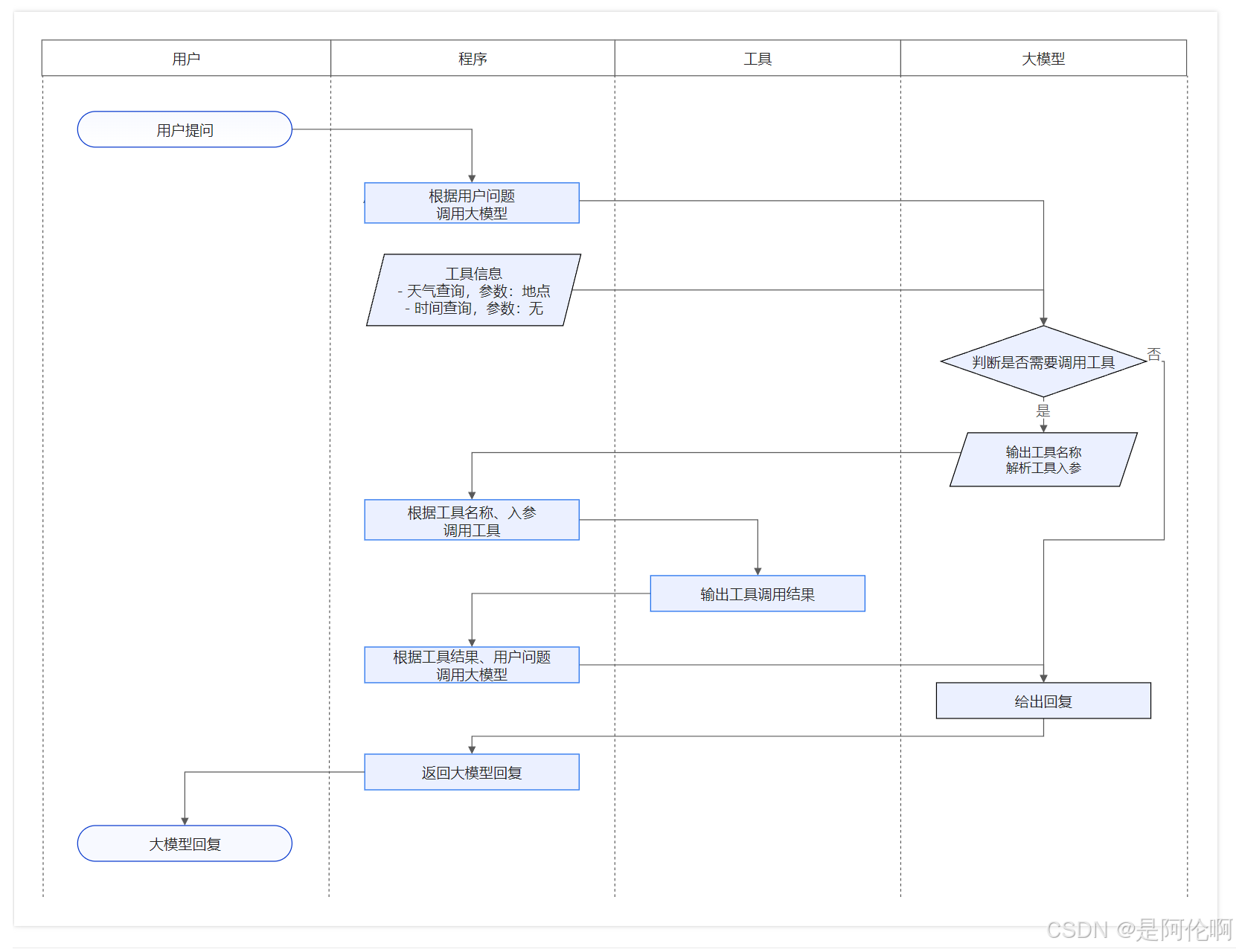
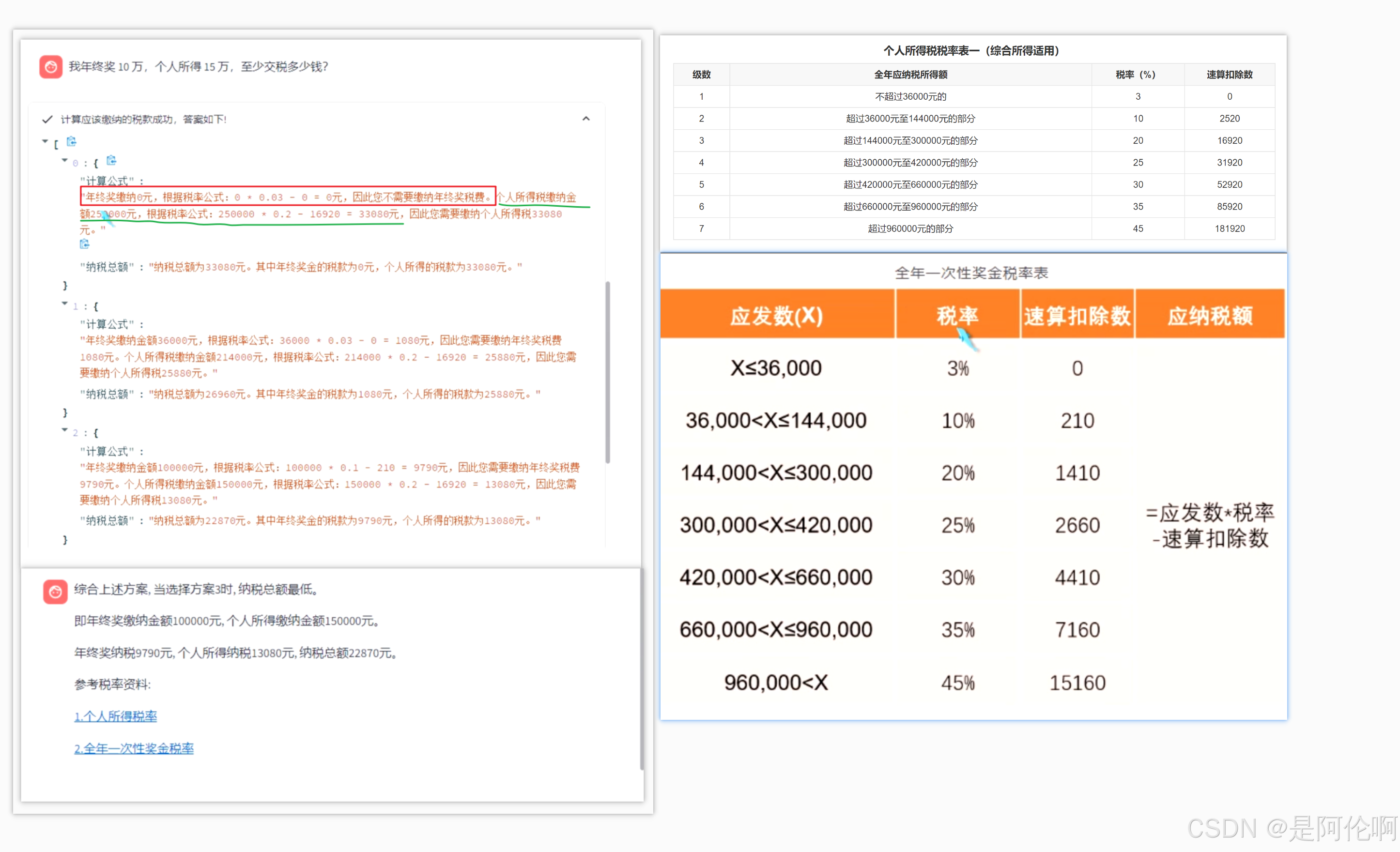
- 效果:
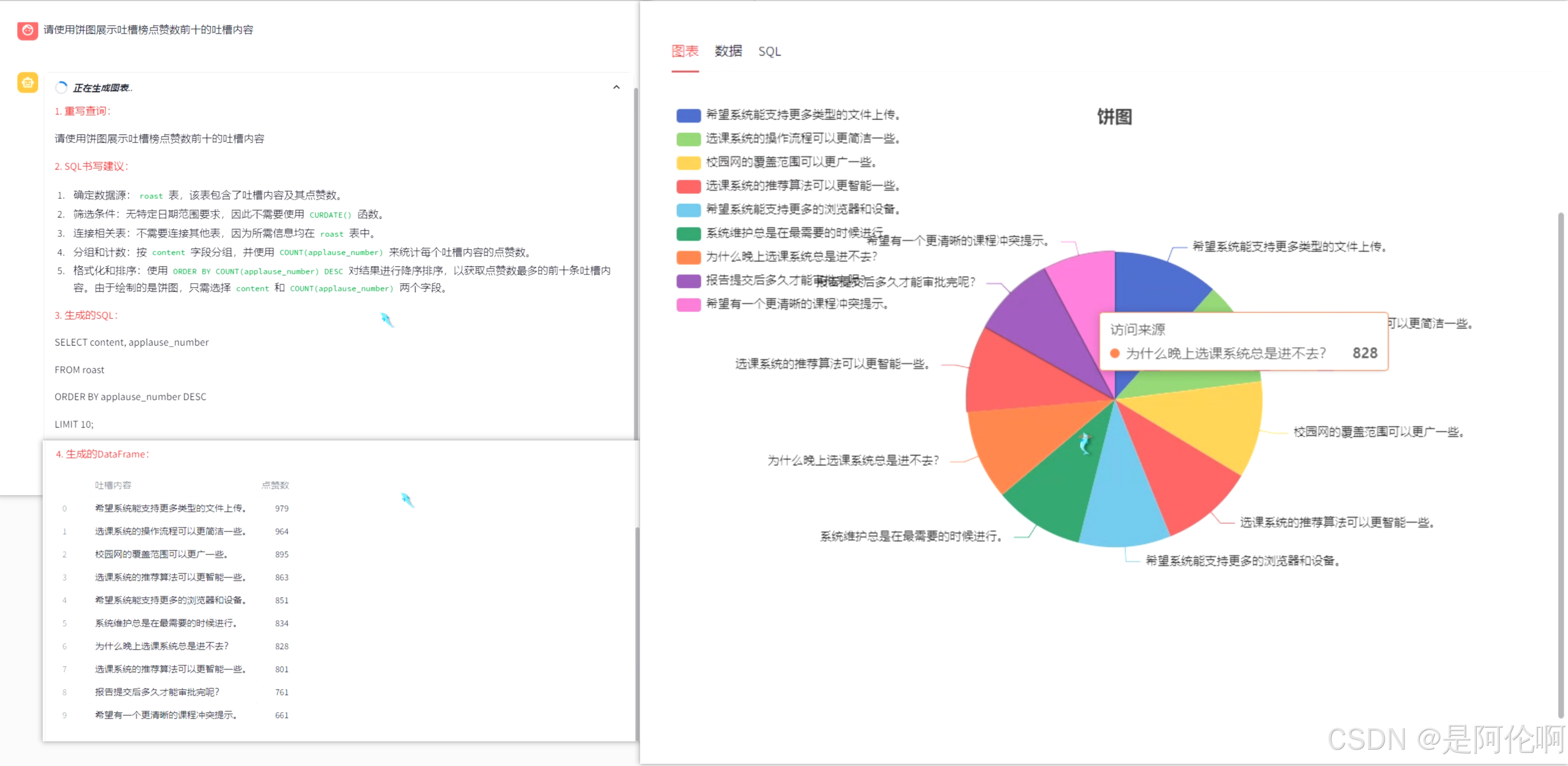
3.3. NL2SQL/图表
- 流程图:
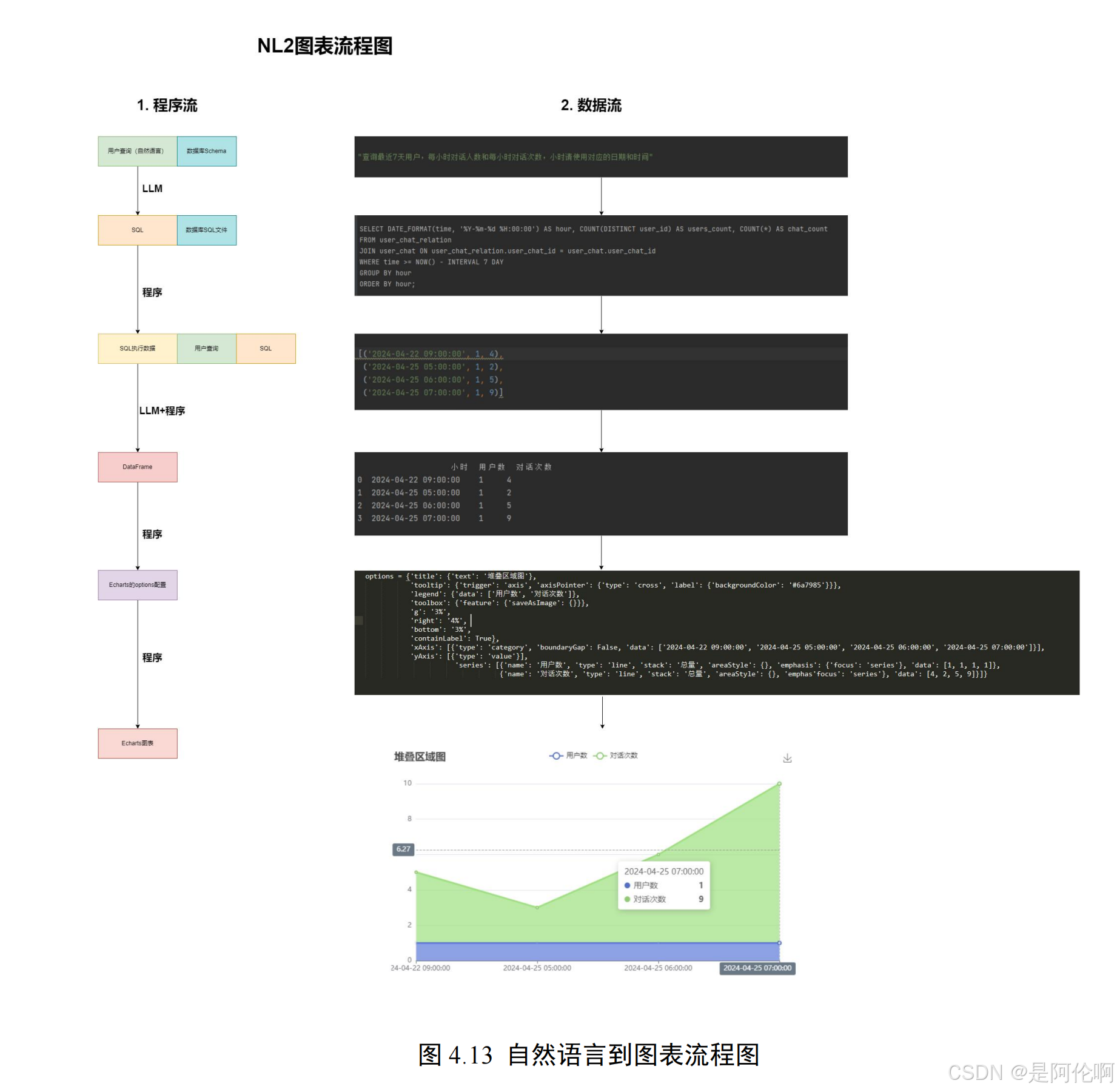
- 效果:
4. 相关集成
4.1. DeepSeek官方开源项目集成
4.2. RAG知识库
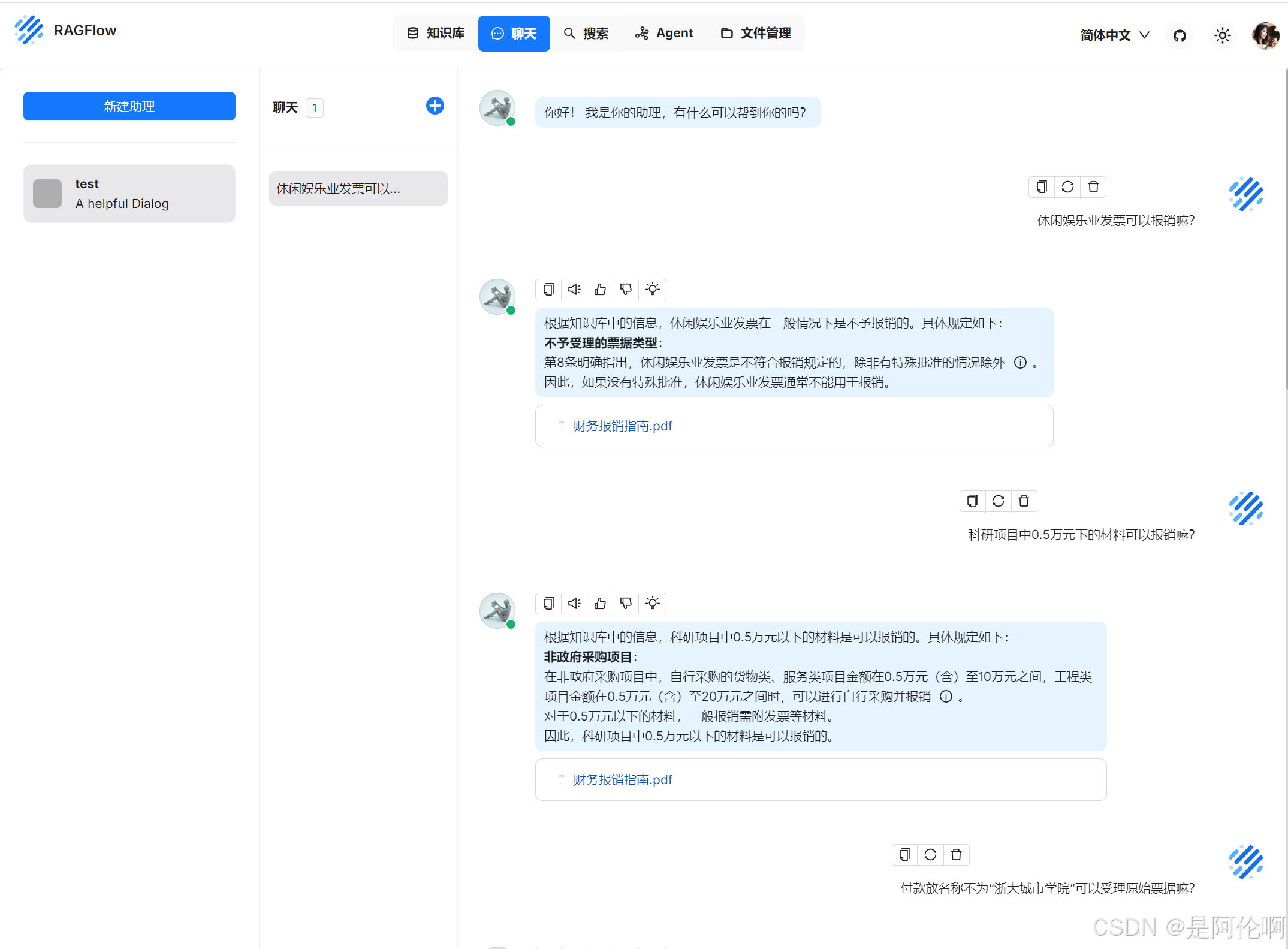
RAGFlow:一款基于深度文档理解构建的开源 RAG引擎。
4.3. Agent智能体
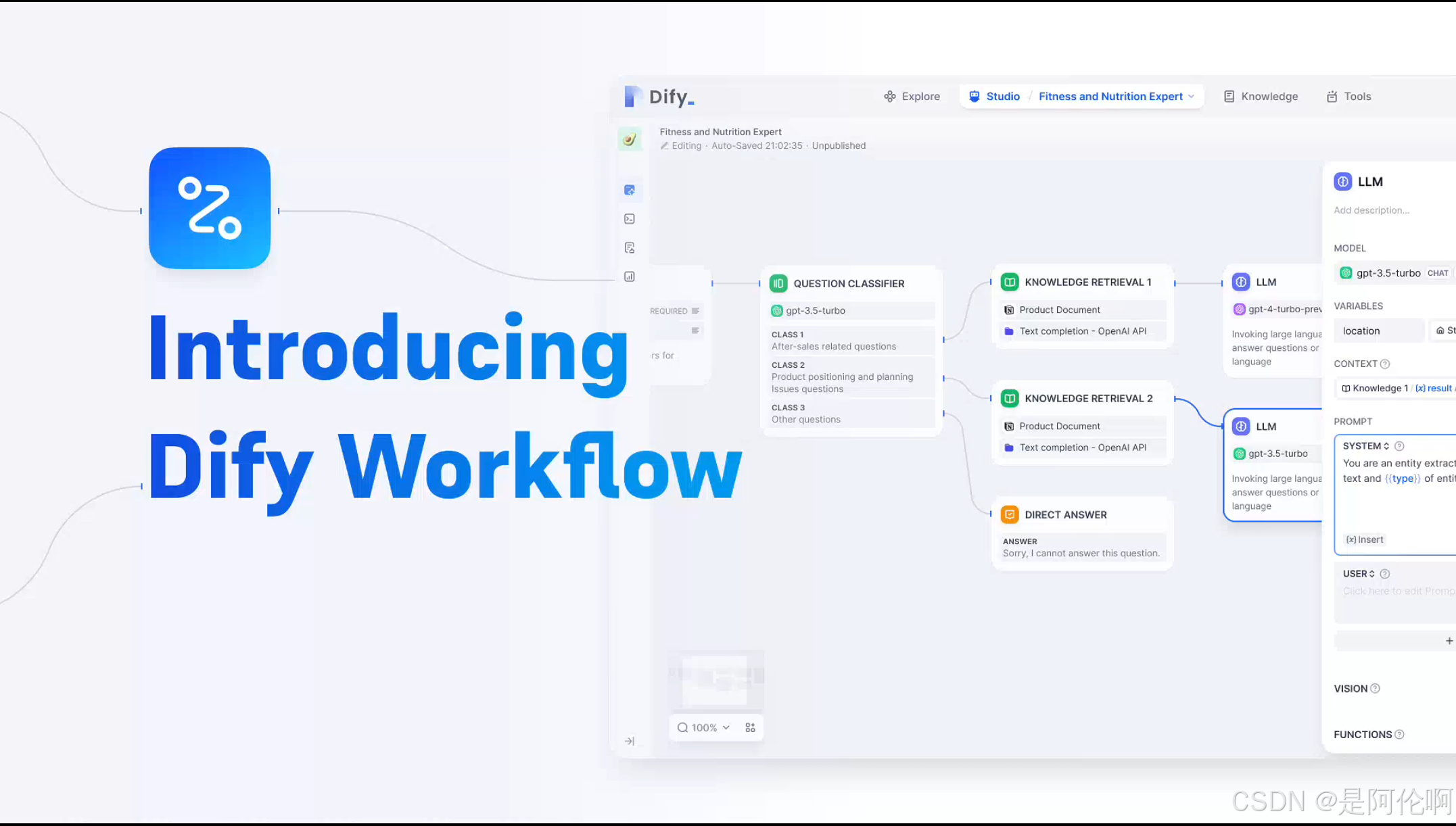
Dify:一个支持 DeepSeek 模型的 LLM 应用开发平台,可用于创建 AI 助手、工作流、文本生成器等应用。
4.4. 即时通讯
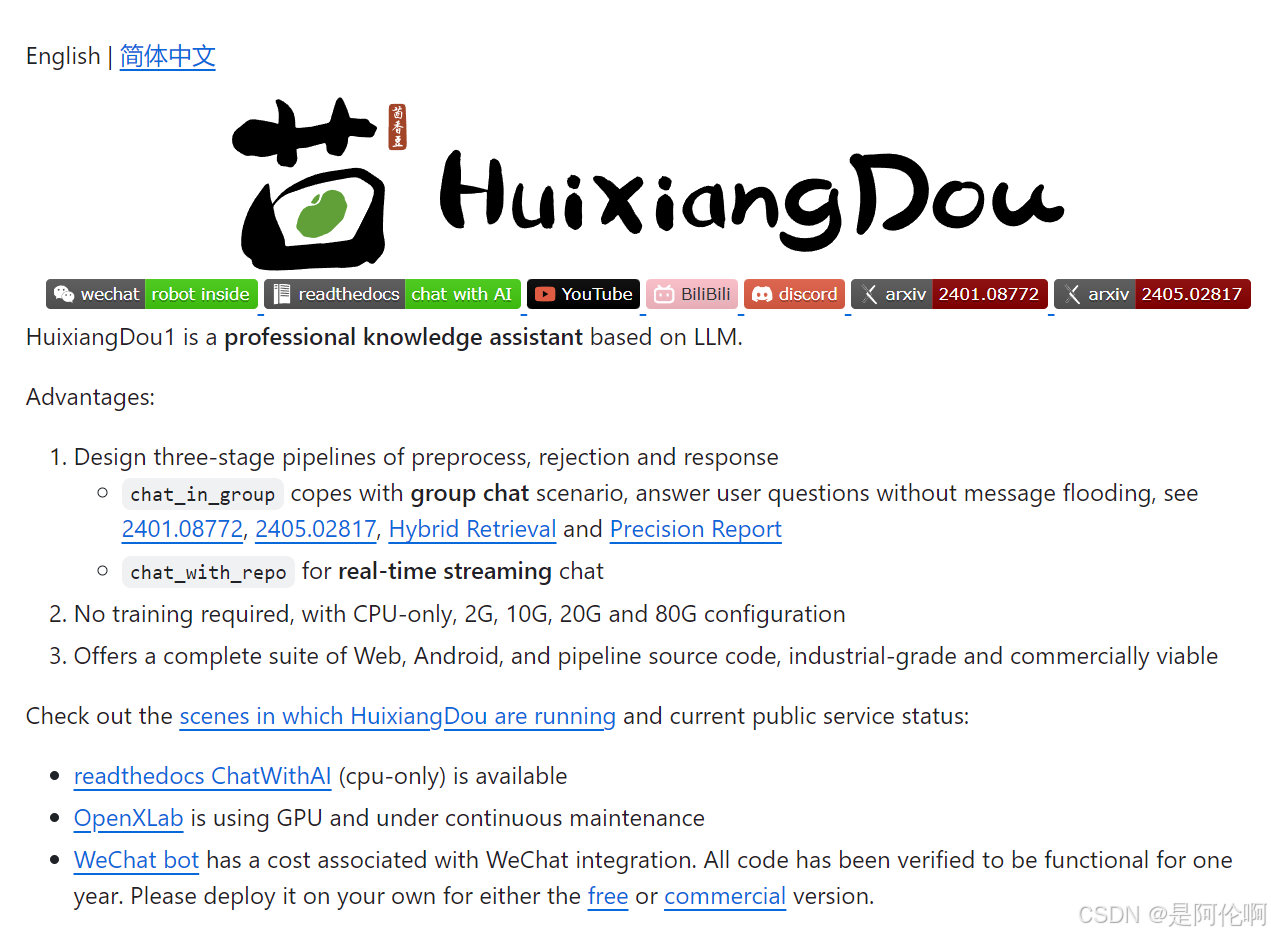
茴香豆:一个集成到个人微信群/飞书群的领域知识助手,专注解答问题不闲聊
4.5. 代码编辑器
Cursor:基于VS Code进行扩展的AI Code编辑器
5. 常用AI工具推荐
5.1. 论文阅读

步骤:打开腾讯元宝 -> 上传论文 -> 发送 -> 点击深度阅读该文档 -> 点击总结/精度/翻译/脑图/生成学术海报
5.2. 智能编码
Cursor+DeepSeek/Qwen
5.3. 问答/DeBug

Grok/腾讯元宝/DeepSeek/Kimi
5.4. 制作PPT【文字->图片】
Napkin
6. 本小节参考文献
- Deepseek. 2025. “Deepseek.” Accessed March 22, 2025. https://www.deepseek.com/.
- Deepseek. 2025. “推理模型指南.” Accessed March 22, 2025. https://api-docs.deepseek.com/zh-cn/guides/reasoning_model.
- Deepseek AI. 2025. “Awesome Deepseek Integration.” Accessed March 22, 2025. https://github.com/deepseek-ai/awesome-deepseek-integration/blob/main/README_cn.md.
- Tencent Yuanbao. 2025. “Chat.” Accessed March 22, 2025. https://yuanbao.tencent.com/chat/naQivTmsDa.
- Cursor. 2025. “Cursor.” Accessed March 22, 2025. https://www.cursor.com/cn.
- Napkin AI. n.d. Accessed March 22, 2025. https://app.napkin.ai/.
三. DeepSeek R1的部署
1. 开源模型平台介绍
1.1. huggingface
Hugging Face 是一个领先的开源机器学习平台和社区,专注于自然语言处理(NLP),提供丰富的预训练模型、工具和数据集,支持开发者快速构建、共享和部署AI应用。
1.2. 魔搭社区
魔搭社区(ModelScope)是由阿里巴巴达摩院推出的开源AI模型社区,聚焦中文场景,提供丰富的预训练模型、开发工具及协作平台,助力开发者高效构建和部署人工智能应用。
1.3. DeepSeek R1的模型
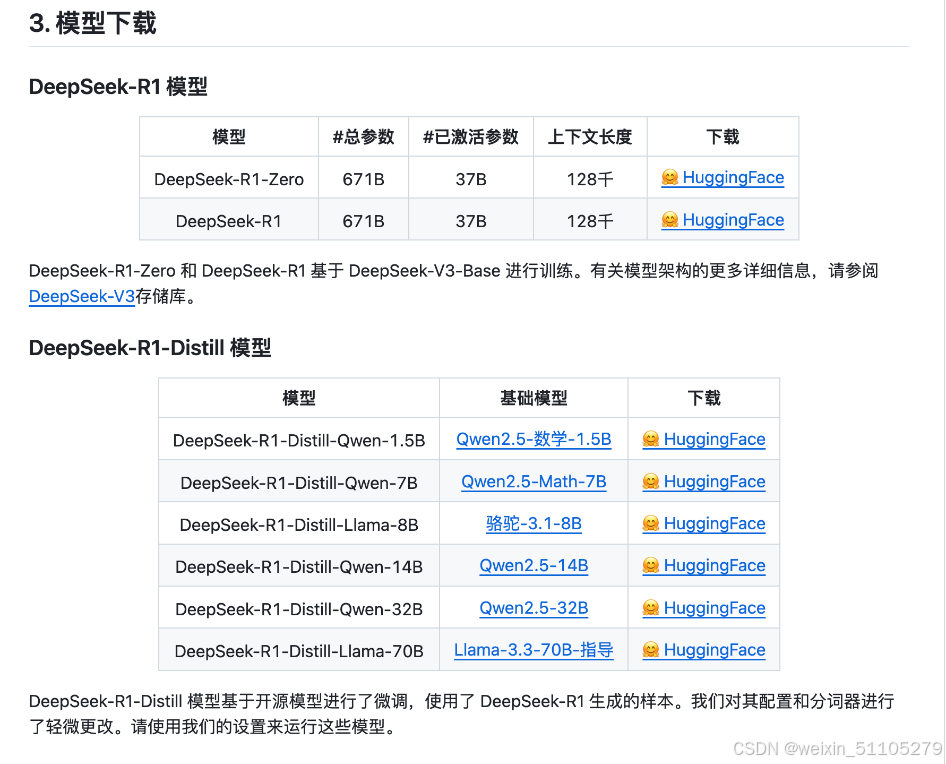
DeepSeek R1及蒸馏模型
2. 推理引擎介绍
2.1. ollama
适用于个人单机部署
2.2. sglang
适用于企业级部署全量的DeepSeek R1
2.3. vllm
适用于企业级部署蒸馏的DeepSeek R1
2.4. xinference(强烈推荐)
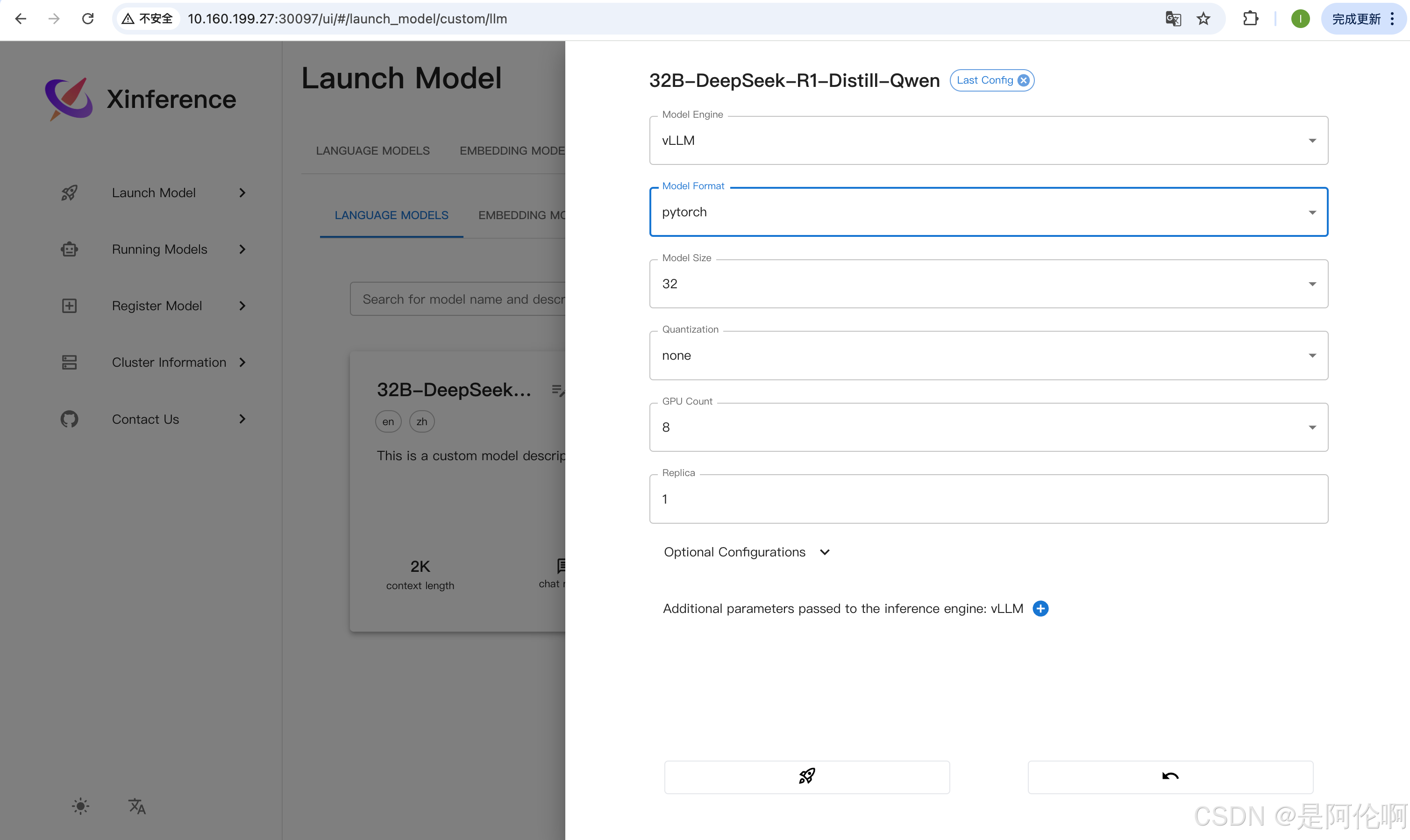
整合多种推理引擎(强烈推荐),适用于企业级部署蒸馏的DeepSeek R1
3. 对话系统介绍
3.1. gradio
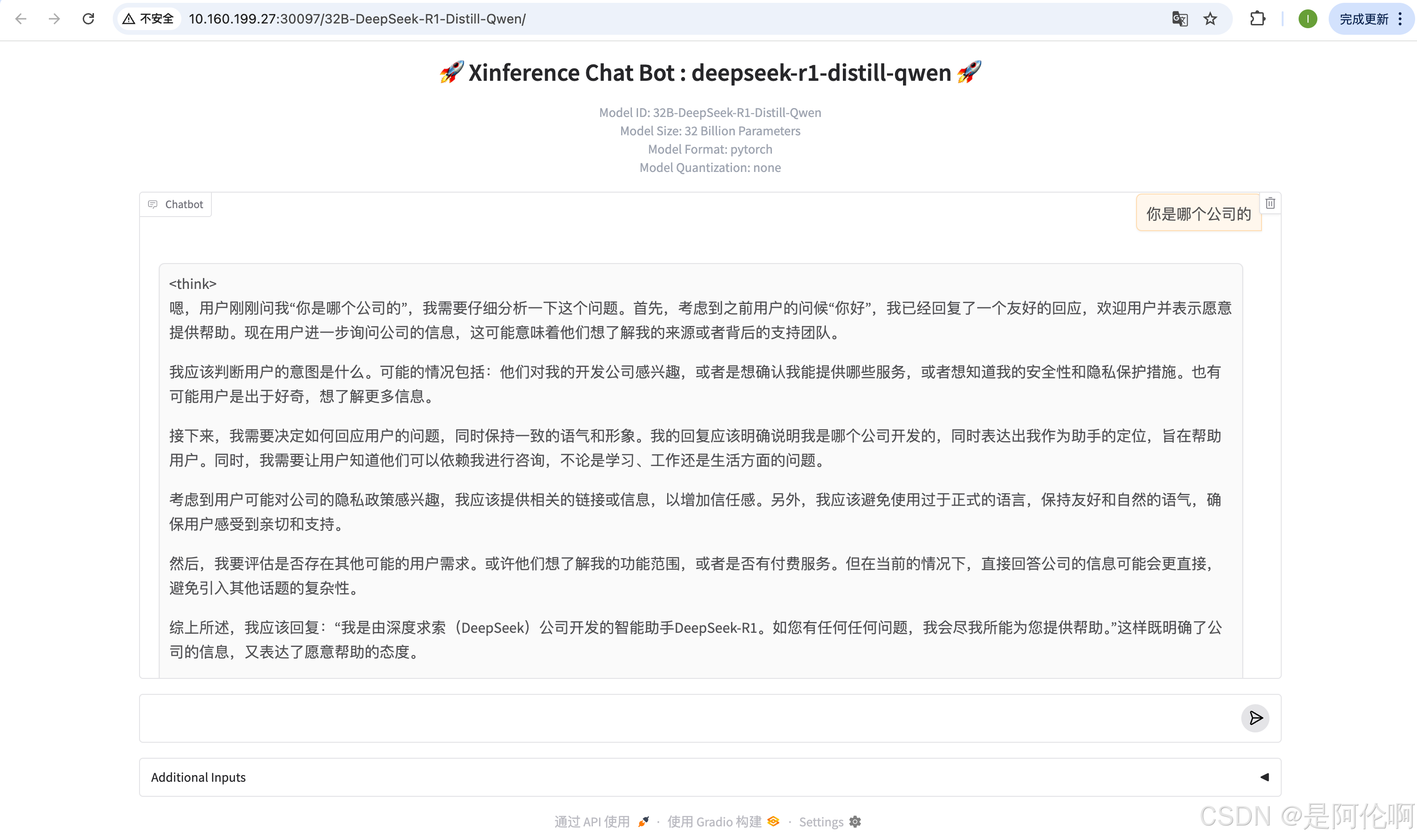
个人测试模型效果
3.2. open webui:
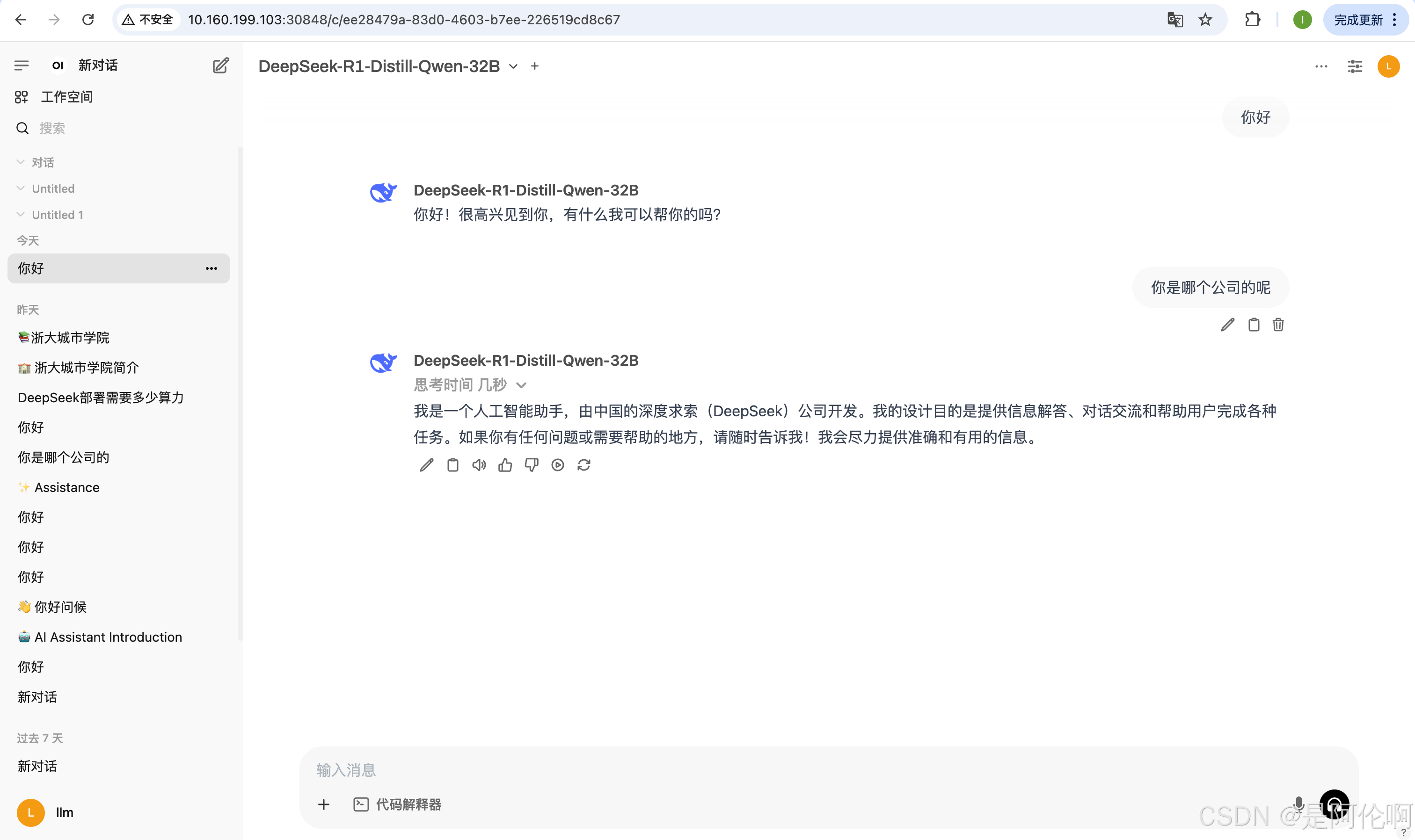
企业内部使用
4. 部署推荐
- 推荐1:
硬件配置:个人PC电脑
部署推荐:模型(DeepSeek R1量化版)+推理引擎(ollama)+对话界面(open-webui) - 推荐2:
硬件配置:专业的GPU设备(T4,A800,H800,H20等)
部署推荐:模型(DeepSeek R1蒸馏版)+推理引擎(xinference)+对话界面(open-webui) - 推荐3:
硬件配置:专业的GPU设备【4台A800,2台H200/H20】
部署推荐:模型(DeepSeek R1 671B)+推理引擎(sglang)+对话界面(open-webui)
5. 部署实践
5.1. 使用xinference部署DeepSeek蒸馏模型:
- 步骤:

- 效果:
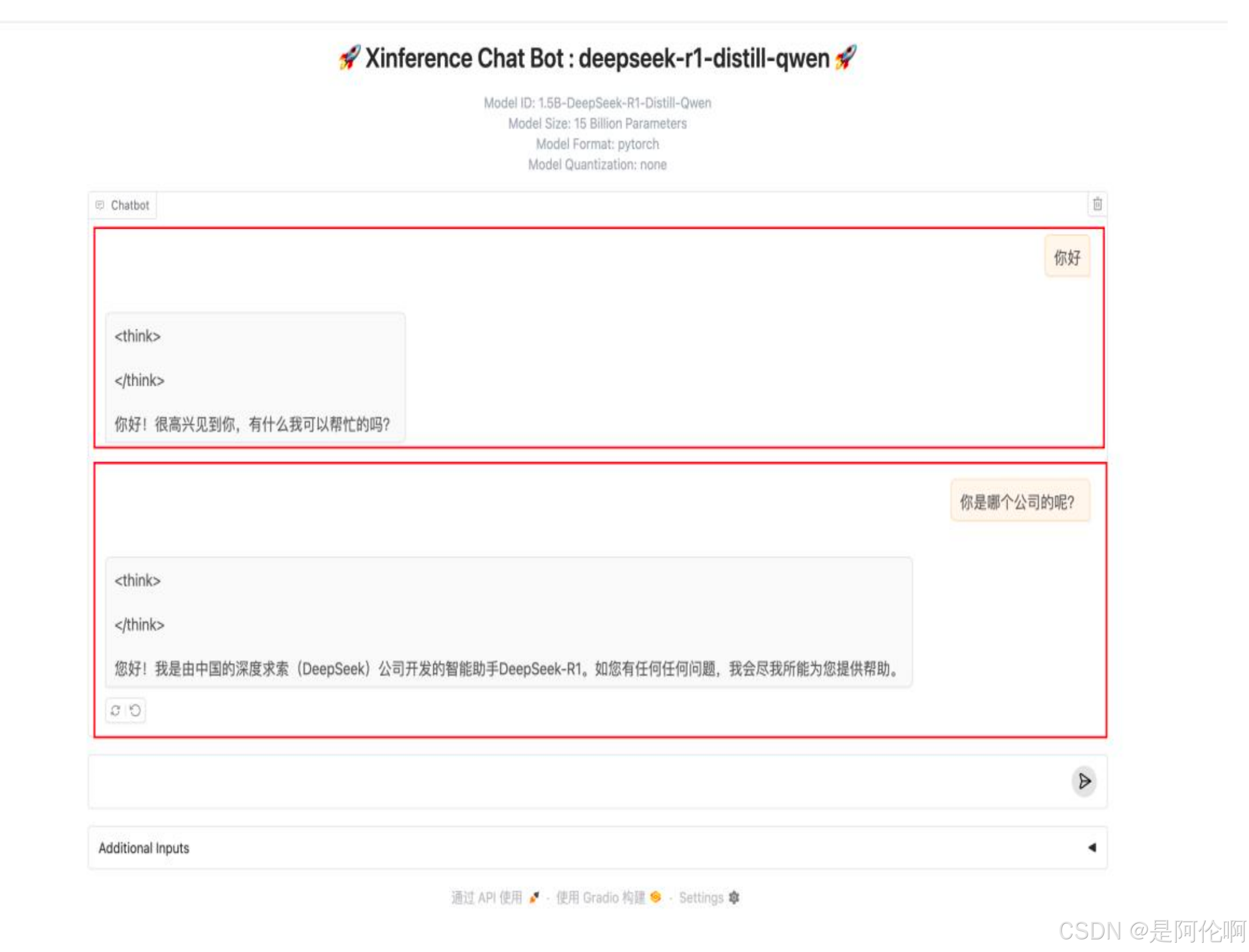
5.2. 使用ollama部署【参考部署资料】:
5.3. 使用sglang部署DeepSeek R1 671B版本【参考SGLang的链接】
6. 本小节参考文献
- DeepSeek-AI. n.d. “DeepSeek-R1.” GitHub. Accessed March 22, 2025. https://github.com/deepseek-ai/DeepSeek-R1.
- Hugging Face. n.d. “Hugging Face.” Hugging Face. Accessed March 22, 2025. https://huggingface.co/.
- ModelScope. n.d. “My Overview.” ModelScope. Accessed March 22, 2025. https://www.modelscope.cn/my/overview.
- Ollama. n.d. “Ollama.” GitHub. Accessed March 22, 2025. https://github.com/ollama/ollama.
- Xorbitsai. n.d. “Inference.” GitHub. Accessed March 22, 2025. https://github.com/xorbitsai/inference.
- VLLM-Project. n.d. “VLLM.” GitHub. Accessed March 22, 2025. https://github.com/vllm-project/vllm.
- SGL-Project. n.d. “SGLang.” GitHub. Accessed March 22, 2025. https://github.com/sgl-project/sglang.
- Gradio-App. n.d. “Gradio.” GitHub. Accessed March 22, 2025. https://github.com/gradio-app/gradio.
- Open-WebUI. n.d. “Open WebUI.” GitHub. Accessed March 22, 2025. https://github.com/open-webui/open-webui.
总结
本文主要介绍了DeepSeek R1模型的背景、发展历程、技术细节、应用场景及部署方法。DeepSeek R1是由幻方科技创始人梁文锋带领团队研发的通用人工智能模型,基于DeepSeek-V3基座模型,通过强化学习等技术增强推理能力,并在编码、数学、软件工程等领域表现出色,部分性能接近OpenAI的模型。文章详细阐述了DeepSeek R1的关键技术、评测效果及其在普通用户、API调用、大模型应用技术等方面的应用。此外,文章还提供了DeepSeek R1的开源模型平台、推理引擎、对话系统的介绍,并推荐了不同场景下的部署方案,包括个人PC、专业GPU设备等。最后,文章通过实践步骤展示了如何使用xinference、ollama和sglang等工具部署DeepSeek R1模型。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)