亲手复现DeepSeek-R1-Zero实验完整解读
本文给大家分享个人亲手复现R1-Zero的全过程,包括对关键源码的解读、训练过程和实验结果分析。TL;DR,整个项目只需要定制2处地方:另外在main_ppo.py训练入口中的注册该reward function即可。如果想定制训练自己的推理任务,只需要处理上述两处代码即可。又可以愉快地调包了 (:中途遇到问题:模型和数据基于Qwen2.5-3B复现。下载作者上传的数据集Jiayi-Pan/Cou
亲手复现DeepSeek-R1-Zero实验完整解读
本文给大家分享个人亲手复现R1-Zero的全过程,包括对关键源码的解读、训练过程和实验结果分析。
源码概览
实验主要借鉴tinyZero,在veRL框架上实验。
countdown的任务是给定target和nums,要求基于加减乘除得到target。比如target=24,nums=[2,3,5,6] ,要求用这4个数来计算出24,1种方案比如:(6/2) * (3+5)=24。
TL;DR,整个项目只需要定制2处地方:
- 数据集预处理,
example/data_preprocess/countdown.py,数据集可以通过计算机任意生成N个数任意加减乘法组合运算及结果给定,作者已经提供好数据集放在huggingface,我们只需要下载下来,构造成适配veRL的数据集即可,包括问题、标准答案等。 - 规则奖励函数,
verl/utils/reward_score/countdown.py,定义规则化奖励函数,输入是大模型的生成结果、标准答案,进行比对,定义格式准确性分数、答案准确性分数等即可。
另外在main_ppo.py训练入口中的_select_rm_score_fn注册该reward function即可。
如果想定制训练自己的推理任务,只需要处理上述两处代码即可。又可以愉快地调包了 (:
环境配置
- 2张A100 x 80G:原作者采用了2张H200实验,A100比H200的显存小不少,容易OOM,需要调整参数配置方可跑起来。建议最少用2张A100;当然如果卡不够,还可以尝试下开源项目unsloth,号称能节省80%的显存,并且支持Lora;
- python=3.9;python相关的依赖环境如下,在编译flash-attn的时候花了不少时间,记得先安装ninja能加快速度。
pip3 install --no-cache-dir \
torch==2.4.0 \
accelerate \
codetiming \
dill \
hydra-core \
numpy \
pybind11 \
tensordict \
"transformers <= 4.46.0"
pip install ninja
pip3 install --no-cache-dir flash-attn==2.7.0.post2 --no-build-isolation
pip install importlib-metadata
# vllm depends on ray, and veRL does not support ray > 2.37
pip3 install --no-cache-dir vllm==0.6.3 ray==2.10
pip install wandb IPython matplotlib
pip install absl-py
pip install astunparse
-
中途遇到问题:
ImportError: cannot import name '_get_socket_with_port' from 'torch.distributed.elastic.agent.server.api' (~/.local/lib/python3.9/site-packages/torch/distributed/elastic/agent/server/api.py) 参见:https://github.com/deepspeedai/DeepSpeed/issues/5603
模型和数据
基于Qwen2.5-3B复现。下载作者上传的数据集Jiayi-Pan/Countdown-Tasks-3to4。数据集包括target和nums两列。
pip install -U huggingface_hub
export HF_ENDPOINT="https://hf-mirror.com"
--model
huggingface-cli download --resume-download Qwen/Qwen2.5-3B
--dataset
huggingface-cli download --resume-download --repo-type dataset Jiayi-Pan/Countdown-Tasks-3to4
此处要注意,veRL框架存在1处bug,在模型rollout生成答案的过程中,使用的是tokenizer.eos_token_id来作为生成内容的结束符标记,但模型生成的结果的实际结束符是generation_config.eos_token_id。Qwen2.5-3B的这两个符号是不一样的,如果不处理此处bug,模型会无法识别出结束符,导致模型一直输出结束符直到max_response_length。
结尾都是<|endoftext|>的例子:

处理的方式包括2种,
- verl修改生成的代码
eos_token_id设置为generation_config.eos_token_id,这个有对应的issue和pull request:https://github.com/volcengine/verl/pull/213,可关注下。 - 或者临时修改
tokenizer_config.json里的结束符,保证和generation_config.eos_token_id一致即可。
outputs = model.generate(
inputs.input_ids,
max_new_tokens=MAX_RESPONSE_LENGTH,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=generation_config.eos_token_id, # 此处verl框架中选择的是tokenizer.eos_token_id导致问题,要使用generation_config.eos_token_id
)
数据集处理
python ./examples/data_preprocess/countdown.py --local_dir data

核心处理逻辑如下,每条数据最重要的2个字段:prompt(包含question)、reward_model (包含标准答案)。
# countdown
def make_map_fn(split):
def process_fn(example, idx):
question = make_prefix(example, template_type=args.template_type)
solution = {
"target": example['target'],
"numbers": example['nums']
}
data = {
"data_source": data_source,
"prompt": [{
"role": "user",
"content": question,
}],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": solution
},
"extra_info": {
'split': split,
'index': idx,
}
}
return data
return process_fn
1条数据形如:
{
"target": {
"0": 98
},
"nums": {
"0": [
44,
19,
35
]
},
"data_source": {
"0": "countdown"
},
"prompt": {
"0": [
{
"content": "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.\\nUser: Using the numbers [44, 19, 35], create an equation that equals 98. You can use basic arithmetic operations (+, -, *, \\/) and each number can only be used once. Show your work in <think> <\\/think> tags. And return the final answer in <answer> <\\/answer> tags, for example <answer> (1 + 2) \\/ 3 <\\/answer>.\\nAssistant: Let me solve this step by step.\\n<think>",
"role": "user"
}
]
},
"ability": {
"0": "math"
},
"reward_model": {
"0": {
"ground_truth": {
"numbers": [
44,
19,
35
],
"target": 98
},
"style": "rule"
}
},
"extra_info": {
"0": {
"index": 0,
"split": "train"
}
}
}
后续veRL框架中处理步骤包括,
- 先根据data_source的取值countdown拿到前面对应注册的reward_function。
- 然后根据prompt中的question进行rollout生成response。question中已经包含了具体的nums和目标值target。
- response作为reward_function的输入,解析出答案,并和reward_model中的ground_truth target值进行比对,计算奖励值。
值得注意的是,instruct类模型的输入有一些差异,要稍微处理下。
奖励函数
先举某个时刻运行日志例子来形象介绍奖励函数。
(main_task pid=15898) --------------------------------
(main_task pid=15898) Target: 87 | Numbers: [48 86 48]
(main_task pid=15898) Extracted equation: 86 + 48 / 48
(main_task pid=15898) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=15898) User: Using the numbers [48, 86, 48], create an equation that equals 87. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=15898) Assistant: Let me solve this step by step.
(main_task pid=15898) <think> To create an equation using the numbers 48, 86, and 48 that equals 87, we need to experiment with different combinations of addition, subtraction, multiplication, and division. Let's try: 86 + 48 = 134, then subtracting 48 from 134 gives us 86. However, this doesn't equal 87. Trying another combination: (86 - 48) + 48 = 38 + 48 = 86. That doesn't work either. How about: 86 - (48 + 48) = 86 - 96 = -10. No luck. How about: (86 - 48) * 48 = 38 * 48 = 182. Not 87. How about: (48 * 86) - 48 = 4128 - 48 = 4080. Incorrect. How about: 48 + 86 + 48 = 182. Nope. Trying: (86 + 48) / 48 = 134 / 48 = 2.7916667. No. How about: 86 - 48 * 48 = 86 - 2304 = -2218. Wrong. How about: (86 / 48) + 48 = 1.7916667 + 48 = 49.7916667. No. Finally, how about: 86 + 48 / 48 = 86 + 1 = 87. This works!</think>
(main_task pid=15898) <answer> 86 + 48 / 48 </answer><|endoftext|>
(main_task pid=15898) Correct equation: 86 + 48 / 48 = 87.0
(main_task pid=15898) --------------------------------
逻辑很简单,逐行代码解释如下。主入口compute_score。
-
先调用
extract_solution抽取模型结构化的输出,即包裹在的结果,以上述为例即:86 + 48 / 48 -
验证表达式是否正确
validate_equation,包括是否使用了要求的数字、且每个数字都用上并只用了1次、表达式准确可计算。 -
表达式无误则直接解析计算结果
evaluate_equation,简单粗暴的直接eval(表达式)即可。 -
对比计算答案是否准确,
-
- 格式和答案都准确则返回1分;
- 答案错误但是格式准确则得0.1分;格式对但是没有遵循规则: "有且仅用1次所有的数字"也得0.1分;
- 没有输出计算式子得0分;
#导入所需的库:正则表达式、随机数生成器等
import re # 正则表达式模块用于匹配和处理文本模式
import random # 随机数生成器,用于生成随机问题和结果
import ast # 将字符串转换为可执行的Python代码(ast.literal_eval()函数使用)
import operator # 提供算术运算符的模块(如+,-,*,/,等)
# 定义提取解题过程的函数
def extract_solution(solution_str):
"""Extract the equation from the solution string."""
# 检查"Assistant:"是否存在于字符串中,若有则分割并取后面部分
if"Assistant:"in solution_str:
solution_str = solution_str.split("Assistant:", 1)[1]
elif"<|im_start|>assistant"in solution_str: # 如果使用特定的开始标记
solution_str = solution_str.split("<|im_start|>assistant", 1)[1]
else:
returnNone# 没有找到解题过程则返回None
# 将字符串按回车符分割,取最后一行作为结果
solution_str = solution_str.split('\n')[-1]
# 使用正则表达式提取<answer>标签内的内容
answer_pattern = r'<answer>(.*?)</answer>'# 定义匹配模式
match = re.finditer(answer_pattern, solution_str) # 寻找所有匹配项
matches = list(match) # 存储所有匹配结果
if matches: # 如果有匹配结果,取最后一个的值作为最终答案
final_answer = matches[-1].group(1).strip() # 提取内容并去除两端空格
else:
final_answer = None# 没找到匹配内容
return final_answer
# 定义验证算式是否使用正确且完整的数字的函数
def validate_equation(equation_str, available_numbers):
"""Validate that equation only uses available numbers and each number once."""
try:
# 使用正则表达式提取方程中的所有整数
numbers_in_eq = [int(n) for n in re.findall(r'\d+', equation_str)]
# 将可用数字和计算结果进行比较,确保每个数字只使用一次且正确
available_numbers = sorted(available_numbers)
numbers_in_eq = sorted(numbers_in_eq)
# 检查方程中的所有数字是否都在允许范围内,并且没有重复或遗漏
return numbers_in_eq == available_numbers
except: # 在任何异常情况下返回False
returnFalse
# 定义安全地评估算式的函数,避免使用全局变量以防止漏洞
def evaluate_equation(equation_str):
"""Safely evaluate the arithmetic equation using eval() with precautions."""
try:
# 确保方程只包含数字、运算符和括号等合法字符
allowed_pattern = r'^[\d+\-*/().\s]+$'# 定义允许的字符模式
ifnot re.match(allowed_pattern, equation_str): # 如果不符合则抛异常
raise ValueError("Invalid characters in equation.")
# 使用受限的环境安全地评估方程,仅允许使用数字和预定义的运算符
result = eval(equation_str, {"__builtins__": None}, {})
return result
except Exception as e: # 在任何异常情况下返回None
returnNone
# 定义计算分数的函数
def compute_score(solution_str, ground_truth, method='strict', format_score=0.1, score=1.):
"""The scoring function for countdown task.
Args:
solution_str: the solution text
ground_truth: dictionary containing target number and available numbers
method: the method to extract the solution
format_score: the score for correct format but wrong answer
score: the score for the correct answer
"""
target = ground_truth['target'] # 目标数字
numbers = ground_truth['numbers'] # 可用的数字
equation = extract_solution(solution_str=solution_str) # 提取方程
do_print = random.randint(1, 64) == 1# 随机决定是否打印详细信息
if do_print:
print(f"--------------------------------")
print(f"Target: {target} | Numbers: {numbers}")
print(f"Extracted equation: {equation}")
print(f"Solution string: {solution_str}")
if equation isNone: # 如果没有提取到方程
if do_print:
print(f"No equation found") # 没有找到解题过程
return0
# 验证方程是否使用了正确的数字
ifnot validate_equation(equation, numbers):
if do_print:
print(f"Invalid equation") # 方程格式错误
return format_score # 返回指定的分数
# 安全评估方程,确保计算过程无异常
try:
result = evaluate_equation(equation) # 计算结果
if result isNone: # 如果无法计算
if do_print:
print(f"Could not evaluate equation") # 输出错误提示
return format_score
# 检查结果是否正确,允许浮点数精度误差
if abs(result - target) < 1e-5:
if do_print:
print(f"Correct equation: {equation} = {result}") # 正确方程显示
return score # 返回满分
else:
if do_print:
print(f"Wrong result: equation = {result}, target = {target}") # 错误结果提示
return format_score # 返回指定的分数
except:
if do_print:
print(f"Error evaluating equation") # 检查计算过程中的错误
returnNone# 如果发生其他异常则返回None
训练脚本
- wandb login提前在terminal登录下,如果没有账号提前注册下。
#!/bin/bash
export N_GPUS=2 #2卡
export CUDA_VISIBLE_DEVICES=0,1
export BASE_MODEL=~./huggingface.co/Qwen/Qwen2.5-3B
export DATA_DIR=./data
export ROLLOUT_TP_SIZE=2
export EXPERIMENT_NAME=countdown-qwen2.5-3b-fix-grpo
export VLLM_ATTENTION_BACKEND=XFORMERS
- 启动训练,实测A100下面参数可用。如果你是H200,可以直接用官网教程里的脚本。
grpo算法配置如下:
python -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=$DATA_DIR/train.parquet \
data.val_files=$DATA_DIR/test.parquet \
data.train_batch_size=128 \
data.val_batch_size=640 \
data.max_prompt_length=256 \
data.max_response_length=1024 \
actor_rollout_ref.model.path=$BASE_MODEL \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.ppo_micro_batch_size=4 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.grad_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size=4 \
actor_rollout_ref.rollout.tensor_model_parallel_size=$ROLLOUT_TP_SIZE \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.rollout.temperature=1.0 \
actor_rollout_ref.ref.log_prob_micro_batch_size=2 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['wandb'] \
+trainer.val_before_train=False \
trainer.default_hdfs_dir=null \
trainer.n_gpus_per_node=$N_GPUS \
trainer.nnodes=1 \
trainer.save_freq=10 \
trainer.test_freq=10 \
trainer.project_name=TinyZero \
trainer.experiment_name=$EXPERIMENT_NAME \
trainer.total_epochs=152>&1 | tee verl_demo.log
ppo算法配置如下,配置有一些差异,可参考veRL官方docs。
python -m verl.trainer.main_ppo \
data.train_files=$DATA_DIR/train.parquet \
data.val_files=$DATA_DIR/test.parquet \
data.train_batch_size=128 \
data.val_batch_size=640 \
data.max_prompt_length=256 \
data.max_response_length=1024 \
actor_rollout_ref.model.path=$BASE_MODEL \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.ppo_micro_batch_size=4 \
actor_rollout_ref.rollout.log_prob_micro_batch_size=4 \
actor_rollout_ref.rollout.tensor_model_parallel_size=$ROLLOUT_TP_SIZE \
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
actor_rollout_ref.ref.log_prob_micro_batch_size=2 \
critic.optim.lr=1e-5 \
critic.model.path=$BASE_MODEL \
critic.ppo_micro_batch_size=4 \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.logger=['wandb'] \
+trainer.val_before_train=False \
trainer.default_hdfs_dir=null \
trainer.n_gpus_per_node=$N_GPUS \
trainer.nnodes=1 \
trainer.save_freq=10 \
trainer.test_freq=10 \
trainer.project_name=TinyZero \
trainer.experiment_name=$EXPERIMENT_NAME \
trainer.total_epochs=152>&1 | tee verl_demo.log
开始运行:
训练初期,胡说八道,甚至乱码,多语言。温度越高,初期探索越多,胡说八道更多。
tau=1高温:
 tau=1.2超高温,初期开始夹杂多语言了。
tau=1.2超高温,初期开始夹杂多语言了。

实验分析
训练效率:在2张A100上训练,tau=1,rollout=5,22h差不多训练550 steps,平均2-3分钟1个step。
温度实验
- tau=1(青色)和 tau=0.6(紫色)
- 温度越高,前期探索越多,输出长度越长,后期都收敛后输出长度差距不大;
- 输出长度都呈现出先下降再升高最后逐步收敛平稳,下文会解释下原因。
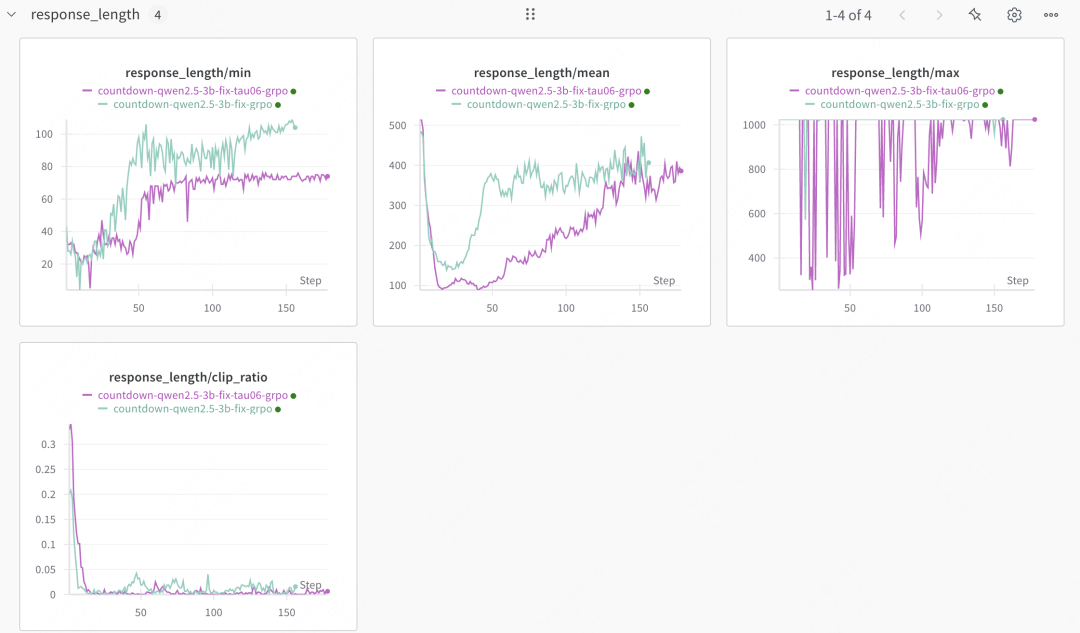
验证集上,高温的效果更好。
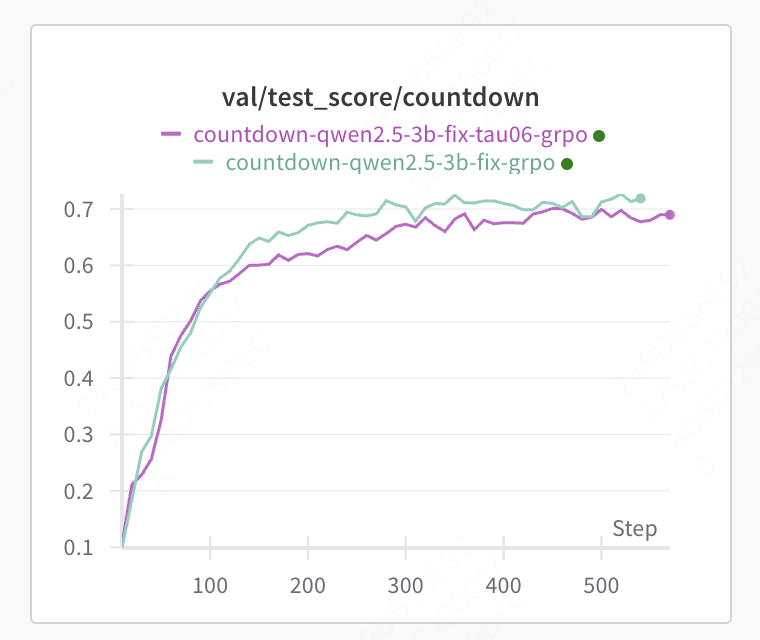
进一步将温度调高到1.2,探索过多,前期分数提升更快,但后期分数起不来,需要后期降温。因此训练策略建议前期高温后期降温。
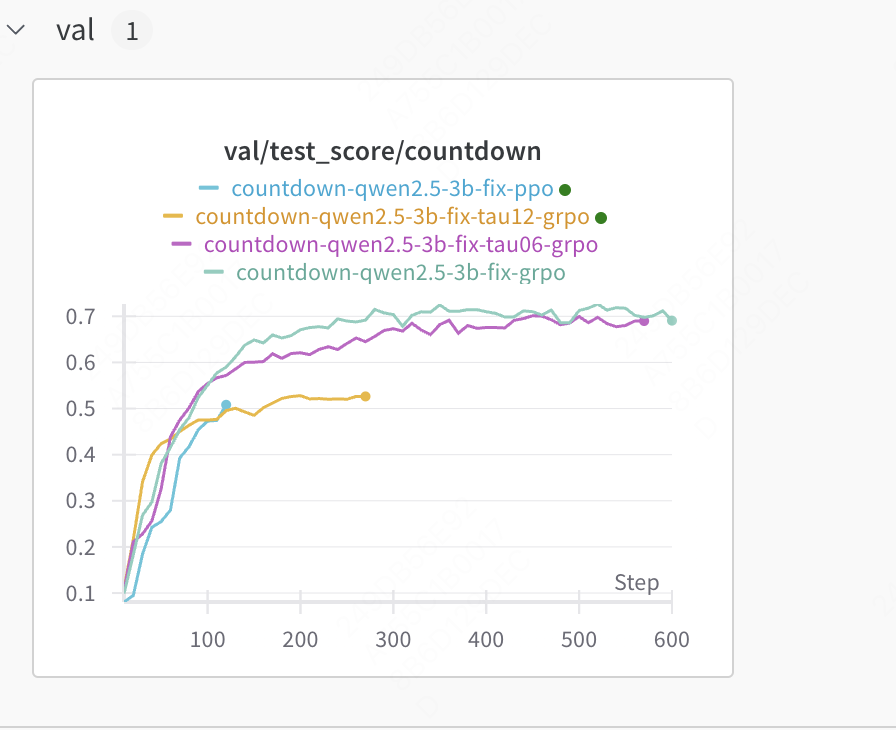
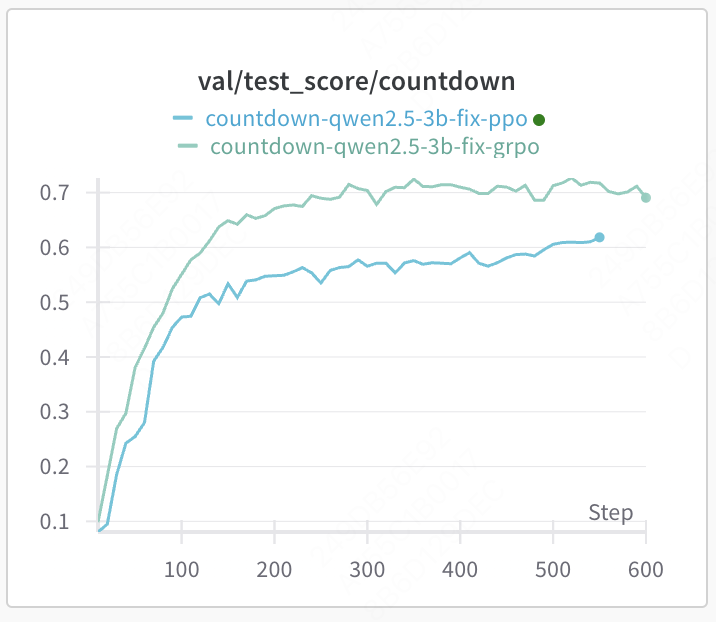
训练算法实验:grpo VS ppo
相同参数设定下,grpo的效果更好,且训练更快。不过也有可能是因为没有精细化调参。
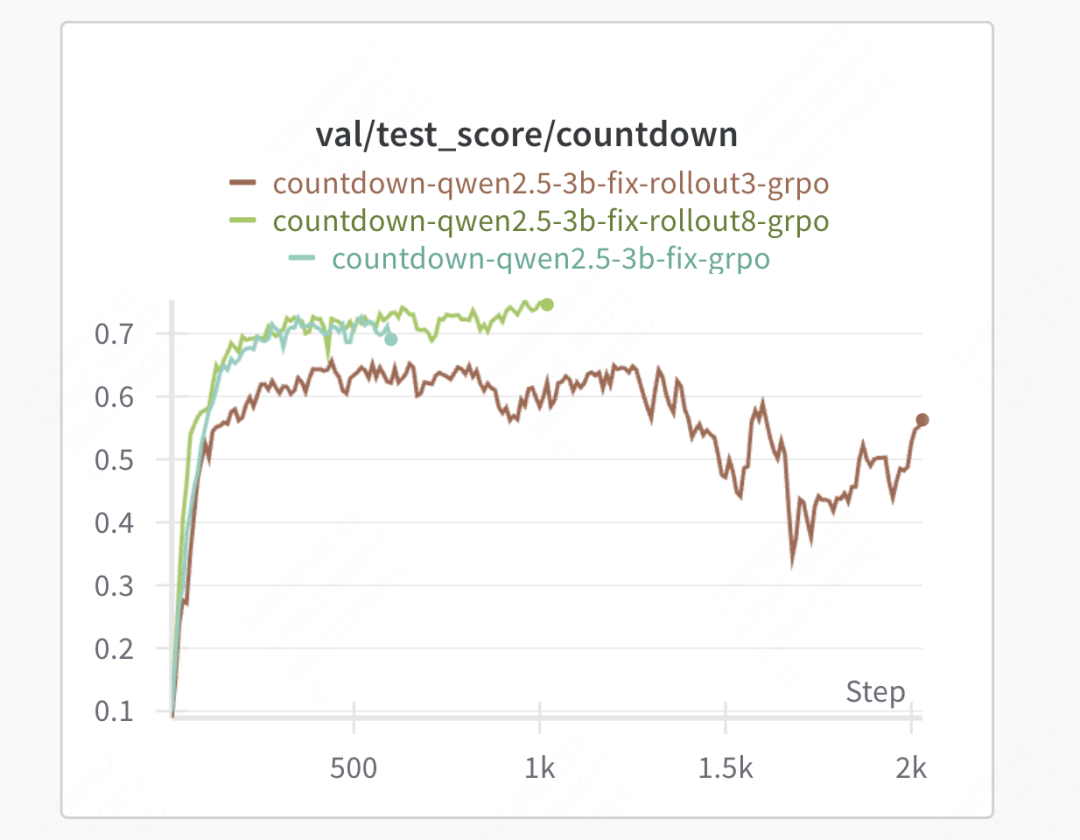
rollout次数实验
颜色比较接近,看命名即可。图例中从上至下依次是rollout=3,8,5。
可以看到效果最好的是8,其次是5,效果最差的是3。符合直觉,且5和8的差异没有特别大,边际收益递减,设置为8训练比较慢。
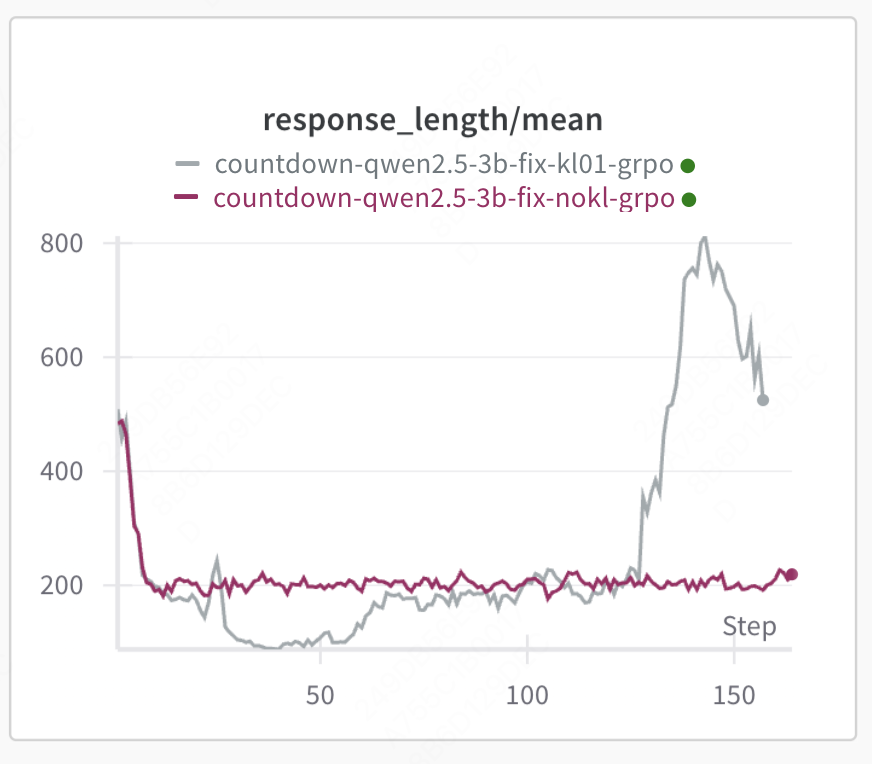
KL Loss实验图例自上而下,① 使用KL,KL的coff=0.01;② 不使用KL;③ 使用KL,KL的coff=0.001。不使用KL损失,完全让模型自由发挥时,RL求解空间过大,找不到合理的优化方向,模型的输出长度始终没有变长。使用KL损失但是系数较大时(coff=0.01),优化初期指标的提升可能只是源自于format分数的提升(同步观察response不断减小可以推测),当想要进一步拿到accuracy的分数时,可以发现分数提升缓慢,KL loss限制了模型的探索。因此,KL Loss的存在是必要的,系数的设置需要权衡。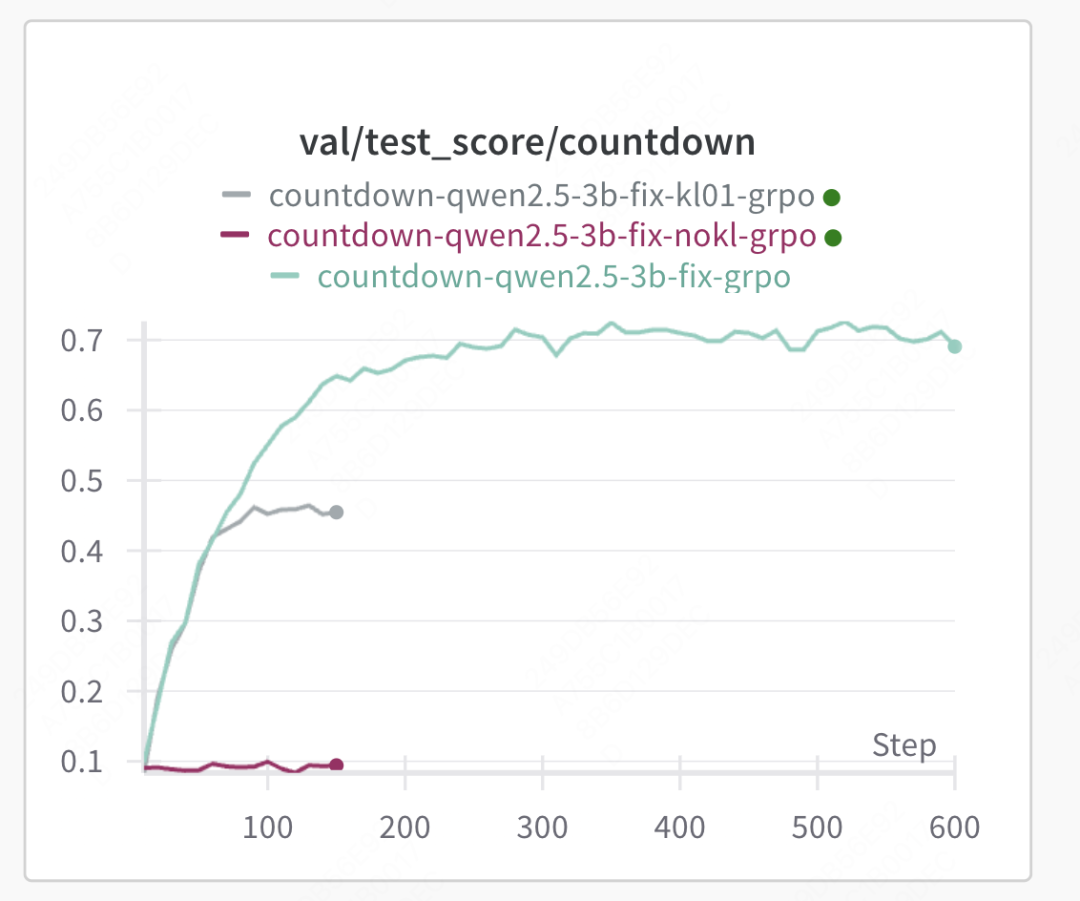
效果示例和解读
温度tau=1,rollout=8迭代1k步左右的效果如下,答案基本都对了。模型基本摸出规律了。仔细看可以发现:
think表现出一定的模式: 几乎每个问题下,模型总喜欢先简单尝试其中2个数字,比如92 - 92 = 0,然后再依次加一个数字,直到穷举完。如果答案正确则结束,如果不对则反思换一种组合,不断尝试直到找到答案。比如 However, this does not give us 82. Let's try another combination: That's still not 82. Ok, how about:... how about... 这个思考相比于训练初期好非常多了,非常接近普通人面对这个问题的思考逻辑,先纵观全局,挑2个尝试,然后逐步枚举。
另外think的模式和参数设定关系还挺大的,tau=1,rollout=5的时候,think表达出的是另一种模式。
(main_task pid=75047) epoch 0, step 1027
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 82 | Numbers: [929281]
(main_task pid=75047) Extracted equation: (92 / 92 + 81)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [92, 92, 81], create an equation that equals 82. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 92 - 92 = 0, then 0 + 81 = 81. However, this does not give us 82. Let's try another combination: 92 + 81 = 173, then 173 - 92 = 81. That's still not82. Ok, how about: 81 + 92 = 173, then 173 - 92 = 81. Ok, how about: 92 + 92 = 184, then 184 - 81 = 103. That's still not 82. Ok, how about: 92 / 92 = 1, then 1 + 81 = 82. </think>
(main_task pid=75047) <answer> (92 / 92 + 81) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (92 / 92 + 81) = 82.0
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 82 | Numbers: [92 92 81]
(main_task pid=75047) Extracted equation: (92 / 92 + 81)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [92, 92, 81], create an equation that equals 82. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 92 - 92 = 0, then 0 + 81 = 81. However, this does not give us 82. Let's try another combination: 92 + 81 = 173, then 173 - 92 = 81, which is still not82. Ok, how about: 81 + 92 = 173, then 173 - 92 = 81, still not there. Ok, how about: 92 + 92 = 184, then 184 - 81 = 103. That's still not 82. Ok, how about: 92 / 92 = 1, then 1 + 81 = 82. </think>
(main_task pid=75047) <answer> (92 / 92 + 81) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (92 / 92 + 81) = 82.0
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 14 | Numbers: [40 51 3]
(main_task pid=75047) Extracted equation: (51 + 3 - 40)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [40, 51, 3], create an equation that equals 14. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 51 - 40 = 11, then 11 - 3 = 8. However, 8 is not 14. Let's try another combination: 40 + 51 = 91, then 91 - 3 = 88. That's still not 14. Ok, how about: 51 + 3 = 54, then 54 - 40 = 14. This works. </think>
(main_task pid=75047) <answer> (51 + 3 - 40) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (51 + 3 - 40) = 14
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 32 | Numbers: [ 8 24 29]
(main_task pid=75047) Extracted equation: (24 / 8 + 29)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [8, 24, 29], create an equation that equals 32. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 29 - 24 = 5, then 5 + 8 = 13. However, this does not give 32. Let's try another combination: 24 + 29 = 53, then 53 - 8 = 45. That's still not 32. Ok, how about: 29 + 8 = 37, then 37 - 24 = 13. That's still not32. Ok, how about: 8 + 29 = 37, then 37 - 24 = 13. Ok, how about: 24 + 8 = 32, then 32 - 29 = 3. That's still not 32. Ok, how about: 29 + 24 = 53, then 53 - 8 = 45. Ok, how about: 8 * 24 = 192, then 192 / 29 is approximately 6.62 which is still not 32. Ok, how about: 24 / 8 = 3, then 3 + 29 = 32. </think>
(main_task pid=75047) <answer> (24 / 8 + 29) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (24 / 8 + 29) = 32.0
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 54 | Numbers: [23 81 50]
(main_task pid=75047) Extracted equation: (81 + 23 - 50)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [23, 81, 50], create an equation that equals 54. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 81 - 50 = 31, then 31 - 23 = 8. However, this does not give us 54. Let's try another combination: 50 + 81 = 131, then 131 - 23 = 108. That's still not 54. Ok, how about: 81 + 50 = 131, then 131 - 23 = 108. Ok, how about: 50 + 23 = 73, then 73 - 81 = -2. That's still not54. Ok, how about: 81 + 23 = 104, then 104 - 50 = 54. </think>
(main_task pid=75047) <answer> (81 + 23 - 50) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (81 + 23 - 50) = 54
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 37 | Numbers: [91 32 4]
(main_task pid=75047) Extracted equation: (4 * 32) - 91
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [91, 32, 4], create an equation that equals 37. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 91 - 32 = 59, then 59 - 4 = 55. However, 55 is not 37. Let's try another combination: 32 + 91 = 123, then 123 - 4 = 119. That's still not 37. Ok, how about: 91 + 4 = 95, then 95 - 32 = 63. That's still not37. Ok, how about: 4 + 32 = 36, then 36 + 91 = 127. That's still not 37. Ok, how about: 91 + 32 = 123, then 123 / 4. That's not an integer. Ok, how about: 32 + 4 = 36, then 36 + 91 = 127. Ok, how about: 91 / 4isnot an integer, let me try: 4 * 32 = 128, then 128 - 91 = 37. </think>
(main_task pid=75047) <answer> (4 * 32) - 91 </answer><|endoftext|>
(main_task pid=75047) Correct equation: (4 * 32) - 91 = 37
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 92 | Numbers: [57944]
(main_task pid=75047) Extracted equation: (44 + 57 - 9)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [57, 9, 44], create an equation that equals 92. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 57 - 44 = 13, then 13 + 9 = 22. However, this does not give 92. Let's try another combination: 44 + 57 = 101, then 101 - 9 = 92. </think>
(main_task pid=75047) <answer> (44 + 57 - 9) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (44 + 57 - 9) = 92
(main_task pid=75047) --------------------------------
(main_task pid=75047) Target: 31 | Numbers: [68 93 71 77]
(main_task pid=75047) Extracted equation: (77 + 93 - 71 - 68)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [68, 93, 71, 77], create an equation that equals 31. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 93 - 77 = 16, then 16 + 68 = 84, and finally 84 - 71 = 13. However, this does not give us 31. Let's try another combination: 77 + 93 = 170, then 170 - 71 = 99, and lastly 99 - 68 = 31. </think>
(main_task pid=75047) <answer> (77 + 93 - 71 - 68) </answer><|endoftext|>
(main_task pid=75047) Correct equation: (77 + 93 - 71 - 68) = 31
(main_task pid=75047) -------------------------------
当然也有错误的,think的过程把所有的max_response_length=1024都用完了还没找到答案。正确答案是69 - 67 - 1 + 9,在69-67后没能快速找到-1+9的路径,还是不够聪明,毕竟只有3B。当然此处如果能把max_response_length调大应该能找到答案。
(main_task pid=75047) Target: 10 | Numbers: [69 67 1 9]
(main_task pid=75047) Extracted equation: (69 - 67) * (9 - 1)
(main_task pid=75047) Solution string: A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
(main_task pid=75047) User: Using the numbers [69, 67, 1, 9], create an equation that equals 10. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
(main_task pid=75047) Assistant: Let me solve this step by step.
(main_task pid=75047) <think> 69 - 67 = 2, then 2 + 1 = 3, and finally 3 - 9 = -1 which is not 10. Let's try another combination: 67 + 69 = 136, then 136 - 9 = 127, and lastly 127 - 1 = 126. That's still not 10. Ok, how about: 9 + 69 = 78, then 78 - 67 = 11, and lastly 11 + 1 = 12. That's still not 10. Ok, how about: 69 + 1 = 70, then 70 - 67 = 3, and finally 3 + 9 = 12. Ok, how about: 9 + 1 = 10, then 10 - 69 = -1, and finally -1 + 67 = 66. Ok, how about: 67 + 9 = 76, then 76 - 69 = 7, and finally 7 + 1 = 8. Ok, how about: 1 * 69 = 69, then 69 - 67 = 2, and finally 2 + 9 = 11. Ok, how about: 9 * 1 = 9, then 9 + 69 = 78, then 78 - 67 = 11. Ok, how about: 69 / 9 = 7, then 7 + 67 = 74, then 74 - 1 = 73. Ok, how about: 1 * 9 = 9, then 9 + 69 = 78, then 78 - 67 = 11. Ok, how about: 9 * (69 - 67) = 9 * 2 = 18, then 18 + 1 = 19. Ok, how about: (69 + 67) / 9 = 136 / 9 which is not an integer. Ok, how about: 67 - (69 / 9) = 67 - 7 = 60, then 60 - 1 = 59. Ok, how about: 9 / 1 = 9, then 9 + 69 = 78, then 78 - 67 = 11. Ok, how about: 69 - 9 = 60, then 60 / 1 = 60, then 60 - 67 = -3. Ok, how about: 1 + 69 = 70, then 70 - 67 = 3, then 3 + 9 = 12. Ok, how about: 9 - (69 / 1) = 9 - 69 = -10, then -10 + 67 = 57. Ok, how about: 67 / 69 is not an integer. Ok, how about: 1 * (69 - 67) = 1 * 2 = 2, then 2 + 9 = 11. Ok, how about: (9 + 69) / 67 = 78 / 67 which is not an integer. Ok, how about: 69 + 67 = 136, then 136 / 9 is not an integer. Ok, how about: 9 / (69 - 67) = 9 / 2 which is not an integer. Ok, how about: 69 + 9 = 78, then 78 - 67 = 11, then 11 + 1 = 12. Ok, how about: 1 + 67 = 68, then 68 - 69 = -1. Ok, how about: 69 / (9 - 1) = 69 / 8 which is not an integer. Ok, how about: 9 * 69 = 621, then 621 / 67 = 9. </think>
(main_task pid=75047) <answer> (69 - 67) * (9 - 1) </answer><|endoftext|>
(main_task pid=75047) Wrong result: equation = 16, target = 10
输出长度变化机制理解
模型输出的长度先减少再提升最后相对稳定这一现象怎么理解,我们可以结合github oat-zero项目的图来理解,也是countdown游戏:
左侧上半部分画出了随着训练步数的增加,格式错误(incorrect)、格式正确但答案错误(formatted)、格式和答案均正确(correct)的构成比例。左侧下半部分是平均回答长度随着训练步数的变化。
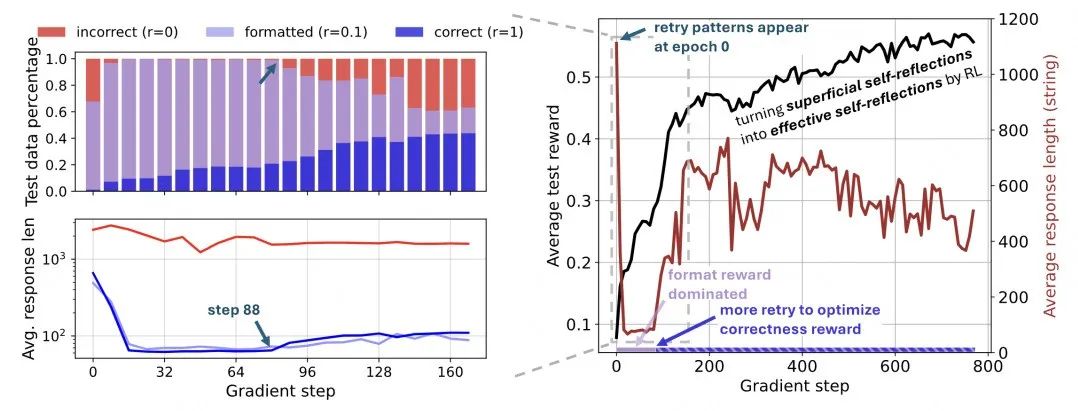
结合左侧图,可以明显的看到:
① 训练初期step=0:格式错误占比很高。
② step>0开始,格式错误比例快速下降。这个部分模型先优化格式,减少冗余输出,毕竟冗余输出并不会带来格式正确的分数提升。
③ 格式基本都正确后,模型开始探索答案正确性,从step=88开始,为了提升答案的准确性,拿到更多的奖励,模型必须更主动探索,探索导致原来已经学的很好的格式能力会稍微变弱(incorrect格式错误比例稍有提升),此时self-refections往更加有效的方向进化。
结合右侧图,画出了160步之后更长步数的结果:
④ 到后面为了进一步拿分,模型会兼顾格式和答案,二者都完成的较好。
总结
总结下来,整体学习的过程形如:
- ① 模型发现format分数更容易拿,先把format优化好拿到基础分数,此时原本基础模型的冗余思考并没有用,因此会逐步先丢掉一些冗余生成模式;
- ② format基本会了之后,必须探索正确的答案,此时会短暂牺牲一些format的分数,但correct的分数在提升,为了拿到correct分数,模型必须更有效的进行self-reflection,因此生成长度提升;
- ③ 后面为了追求高分,逐渐兼顾format和correct,增加“重试”次数,因此回答长度提升。
这个过程本质是RL优化奖励规则的结果,让模型往更加有效的方向进行思考,从而涌现出aha moment。
题外话,也有研究认为这不是aha moment (oatllm.notion.site/oat-zero),认为R1的反思特性在step=0就有了。个人认为模型在奖励函数的引导下,提升了有效思考的能力,本身就是一种aha moment的体现。 调教前的模型,输出虽然能带一些思考的文字,但找不到正确的答案,作为自回归本身的一种action进行探索试错。这种探索不断通过reward传递并进行梯度更新,经过不断调教后,模型遇到难题时不再瞎蒙,而是自然地质疑自己、修正思路,甚至想出更高级的解法——这种"哦!原来如此"的时刻,难道不是一种Aha moment吗?
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 35
35 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)