
京东二面:DeepSeek为何要用FP8而不是INT8?
最近已有不少大厂开启春招宣讲了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键
最近已有不少大厂开启春招宣讲了。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:

随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
本文介绍 DeepSeek 中大量使用的一种数据编码方式——FP8。FP8 是 Float8 的简写,中文可以称之为 8 位浮点数,也就是用 8 位的空间来存储一个浮点数。
本文将从什么是 FP8 的基本结构开始, 举例讲解如何将一个十进制的小数转换为 FP8 的格式。同时,也会演示如何将一个 FP8 的数据转换回一个十进制的数。
接下来,我们会介绍 FP8 的基本计算原理,包括如何进行加减乘除运算。相信通过本文的介绍,读者应该会对 FP8 有一个基本的了解。
01 FP8的基本结构
FP8 是一种 8 位浮点数格式,专为深度学习计算设计。与传统的 32 位浮点数(FP32)相比,它大幅减少了存储空间和计算负担,同时为 AI 任务保留了足够的精度。
FP8 主要有两种常见规格:
-
E4M3:1 位符号位 + 4 位指数位 + 3 位尾数位
-
E5M2:1 位符号位 + 5 位指数位 + 2 位尾数位
02 FP8和十进制如何转换
FP8 遵循 IEEE 浮点数的基本原理,一个 FP8 数的值计算为:
(-1)^符号位 × (1.尾数) × 2^(指数-偏置值)
其中 E4M3 格式的偏置值为 7(2^(4-1)-1)。
实例:十进制转 FP8
以 0.15625 为例,如何转换为 FP8(E4M3)格式?
-
确定符号位:0.15625 为正数,符号位为 0
-
二进制转换:0.15625 = 0.00101(二进制) = 1.01 × 2^(-3)
-
计算指数:实际指数为 -3,加上偏置值 7 得到 E = 4(二进制 0100)
-
提取尾数:尾数为 01,补齐三位为 010
-
组合结果:0|0100|010 = 00100010(二进制)
这样,0.15625 就被编码为 00100010 这个 8 位二进制数。
实例:FP8 转十进制
如果我们看到 FP8 数 01100010,如何转换回十进制?
分解各部分:
-
符号位 S = 0(正数)
-
指数位 E = 1100(二进制) = 12(十进制)
-
尾数位 M = 010
计算实际值:
-
实际指数 = 12 - 7 = 5
-
尾数转换为十进制: 1.010 = 1 * 2^0 + 1*2^(-2) = 1+0.25 = 1.25
-
最终,真实值 = 1 × 1.25 × 2^5
-
= 1 × 1.25 × 32
-
= 40
03 计算原理
高能预警:本节内容存在大量计算,需要读者掌握一些基本的计算机组成原理知识。包括但不限于:进制转换速算、计算机组成原理等。
限于篇幅,无法将所有先验知识一一写明,读者请酌情阅读下列内容。如果写得不清楚的地方,欢迎读者在文章评论区提问,作者会及时回复。
本节用 2 个 FP8 数值为用户举例讲解两个 FP8 的数据如何进行计算。
两个数值的对应信息见下表:
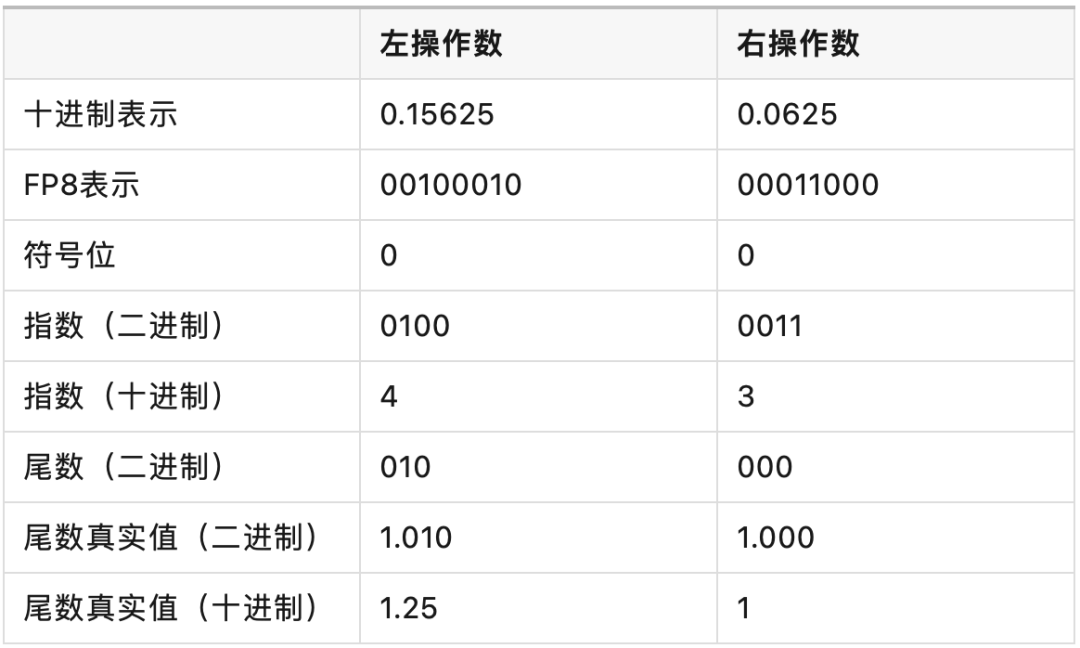
尾数真实值需要补充隐含的 1。
加减
加减的计算规则按照:
-
处理符号位:同号加法结果符号与操作数相同,异号加法结果符号跟随绝对值较大的操作数,用绝对值较大的数减去绝对值较小的数。 减法将第二个操作数的符号取反,然后按加法规则处理。
-
将较小指数的操作数的尾数右移相应位数,将两个操作数的指数变换成相同。
-
对齐后的尾数按照普通二进制的加减规则进行加减(即加法直接相加,减法取补码后相加)
-
将尾数真实值规格化到 [1,2) 之间。如果结果尾数 ≥2,需要右移一位并将指数加 1 。如果结果尾数 <1,需要左移直到尾数 ≥1,并相应减小指数。
举例
第一步: 同号加法,符号位为 0。
第二步: 因为右操作数的指数是 3,而左操作数的指数是 4,所以需要将右操作数的尾数真实值右移一位,使得左右操作数指数一致。即 1.000 >> 1 = 0.100。
第三步: 对齐后的左右操作数的尾数直接按照普通二进制加减法进行加减。即 1.010 + 0.100 =1.110。
第四步: 规格化,因为 1.110 已经在 [1,2) 之间了,所以不需要缩放了。最终结果为符号位 0,指数 0100,尾数 110,最终拼起来就是 00100110。对应的十进制数为 0.21875。
乘除
乘除的计算规则按照:
-
处理符号位:乘除法的结果符号位是两个操作数符号位的异或结果(相同为 0,不同为 1)。
-
指数处理:乘法时,结果的指数等于两个操作数的指数之和再减去偏移量;除法时,结果的指数等于被除数的指数减去除数的指数再加上偏移量。
-
尾数处理:乘法时,将两个操作数的尾数真实值相乘;除法时,将被除数的尾数真实值除以除数的尾数真实值。
-
将尾数真实值规格化到 [1,2) 之间。如果结果尾数 ≥2,需要右移一位并将指数加 1;如果结果尾数 <1,需要左移直到尾数 ≥1,并相应减小指数。
举例
以乘法为例:
第一步:两个操作数符号位都是 0,异或结果为 0,所以结果符号位为 0。
第二步:左操作数指数为 4,右操作数指数为 3,两数相加得 7,再减去偏移量 7,实际指数为 0。
第三步:计算尾数真实值相乘,即 1.010 × 1.000 = 1.010。
第四步:结果尾数 1.010 已在 [1,2) 之间,不需要规格化。
最终结果为符号位 0,指数 0111,尾数 010,拼起来就是 00111010。对应的十进制数为 0.15625 × 0.0625 = 0.009765625。
04 FP8常见问题解答(FAQ)
Q1:FP8 相比 FP32/FP16 会带来多大的精度损失?
A: FP8 相比 FP32 或 FP16 确实会带来一定的精度损失。E4M3 格式的动态范围约为 [-448, 448],精度约为 2^-3≈0.125;而 E5M2 格式的动态范围约为 [-57344, 57344],精度约为 2^-2≈0.25。
相比之下,FP32 的精度约为 2-23≈1.19×10-7,FP16 的精度约为 2-10≈9.77×10-4。
但研究表明,对于大多数深度学习应用场景,特别是大型语言模型,这种精度损失是可接受的,不会显著影响模型性能,同时能带来高达 4 倍的存储空间节约和计算效率提升。
Q2:FP8 的舍入策略有哪些?它们如何影响计算结果?
A: FP8 主要采用的舍入策略包括:
向最近舍入(Round to Nearest Even,RNE):将数值舍入到最近的可表示值,如果处于中间点则舍入到偶数。这是最常用的策略,平均误差最小。
向零舍入(Round toward Zero,RTZ):舍入到绝对值较小的可表示值,简单但容易累积误差。
随机舍入(Stochastic Rounding):基于概率随机舍入,在训练过程中特别有用,可以防止梯度消失。
DeepSeek 模型主要使用 RNE 策略,因为它在统计上偏差最小,适合深度学习训练。
Q3:FP8 和 INT8 有什么区别?为什么不直接用 INT8?
A: 尽管 FP8 和 INT8 都使用 8 位表示数值,但它们的结构和用途完全不同:
-
INT8 是定点数,表示范围固定 [-128, 127],精度均匀。
-
FP8 是浮点数,具有指数位,可表示更大范围的数值,但精度随数值变化。
深度学习模型权重和激活值的分布通常是非均匀的,有极小和极大的值,FP8 更适合捕捉这种分布,而不需要像 INT8 那样复杂的量化校准过程。
Q4:E4M3 和 E5M2 应该在什么场景下选择?
A: 选择取决于具体需求:
E4M3:(4 位指数,3 位尾数)。精度较高但范围较小,适合前向传播和激活值,对数值精确度要求较高的场景。DeepSeek-V3 模型全面采用 E4M3 格式。**
E5M2:(5 位指数,2 位尾数)。范围更大但精度较低,适合梯度计算和反向传播,数值波动较大的场景。
许多框架会在一个模型中混合使用这两种格式:前向传播用 E4M3,反向传播用 E5M2,以平衡精度和范围需求。
Q5:FP8 是否支持 NaN、无穷大等特殊值?
A: 是的,与标准 IEEE 754 浮点数类似,FP8 也支持特殊值:
NaN(非数值):当指数位全为 1 且尾数不为 0 时表示。
无穷大:当指数位全为 1 且尾数为 0 时表示。
零:当指数位和尾数都为 0 时表示。
非规格化数:当指数位为 0 且尾数不为 0 时表示,用于扩展表示范围。
这些特殊值在处理溢出、下溢和错误操作时非常重要。
Q6:在模型中如何平滑过渡到 FP8 格式?
A: 由于 FP8 的精度有限,因此目前还无法做到所有的训练过程都使用 FP8。
因此需要平滑过渡,通常需要以下步骤:
混合精度训练:先用 FP16/FP32 训练模型,然后逐步将部分计算迁移到 FP8。
缩放因子:应用动态缩放因子(scaling factors)来调整 FP8 表示范围,避免溢出和下溢。
梯度累加:在更高精度(如 FP16/FP32)下累加梯度,只在计算密集型操作中使用 FP8。
误差分析:监控并比较 FP8 与更高精度格式之间的误差,确保不会显著影响模型性能。
选择性应用:对精度敏感的层保留较高精度,对不敏感的层应用 FP8。
Q7:FP8 在消费级硬件上是否可用?需要特殊硬件支持吗?
A: 目前只在 H 系列的 GPU 上提供支持。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)