新手福音!Deepseek+ollama 超级简单的本地部署种草方案
目前本地部署的 Deepseek R1 的 1.5B 等小参数模型基本是将推理能力提炼到 Qwen 或 Llama 的蒸馏版本,性能是远远比不上官网的版本的,你可以根据你自身的情况判断是否需要本地部署。
本文档主要是指引 Deepseek 本地部署教程,可以平移到其他的模型也适用。
如:清华的 ChatGLM、阿里的千问以及 Meta 的 llama 等。当前主要演示 window 的版本,其他版本类似。
前言
目前本地部署的 Deepseek R1 的 1.5B 等小参数模型基本是将推理能力提炼到 Qwen 或 Llama 的蒸馏版本,性能是远远比不上官网的版本的,你可以根据你自身的情况判断是否需要本地部署。
1. 什么是本地部署?
DeepSeek 本地部署是指将 DeepSeek 人工智能模型直接安装到用户的本地设备(如电脑或服务器)上运行,非依赖云端服务。
2. 为什么要做本地部署?
-
确保数据隐私和安全
-
减少网络延迟(效果对设备有要求)
-
无网络环境下的离线运行 AI 功能
-
定制化集成(企业内部灵活对接)
-
自有模型训练
3. 安装 ollama
更多功能可查看官方文档:https://ollama.readthedocs.io/quickstart/
3.1 下载 ollama
3.1.1 官网下载
地址:https://ollama.com/
选择对应的版本下载
3.1.2 加速下载(如下载比较慢的情况)
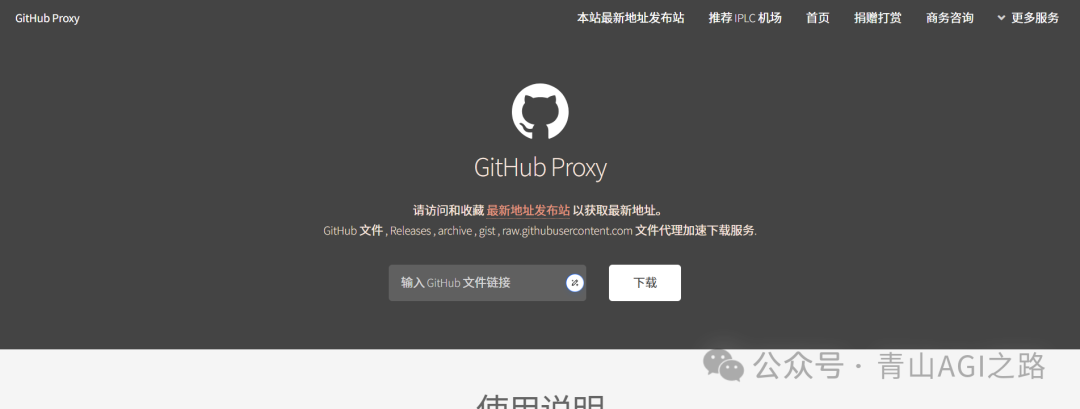
- 用 github 代理加速(https://ghfast.top/ )
- 把 ollama 在 github 的下载链接https://github.com/ollama/ollama/releases/download/v0.5.7/OllamaSetup.exe 输进去
3.1.3 安装:一路 “下一步” 就搞定安装
3.2 设置模型位置(可选)
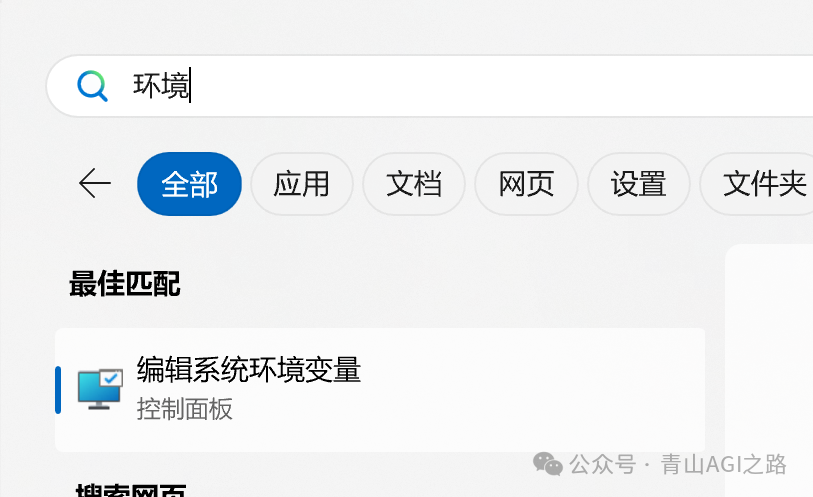
3.2.1 打开环境变量
搜索【环境】点击 编辑系统环境变量
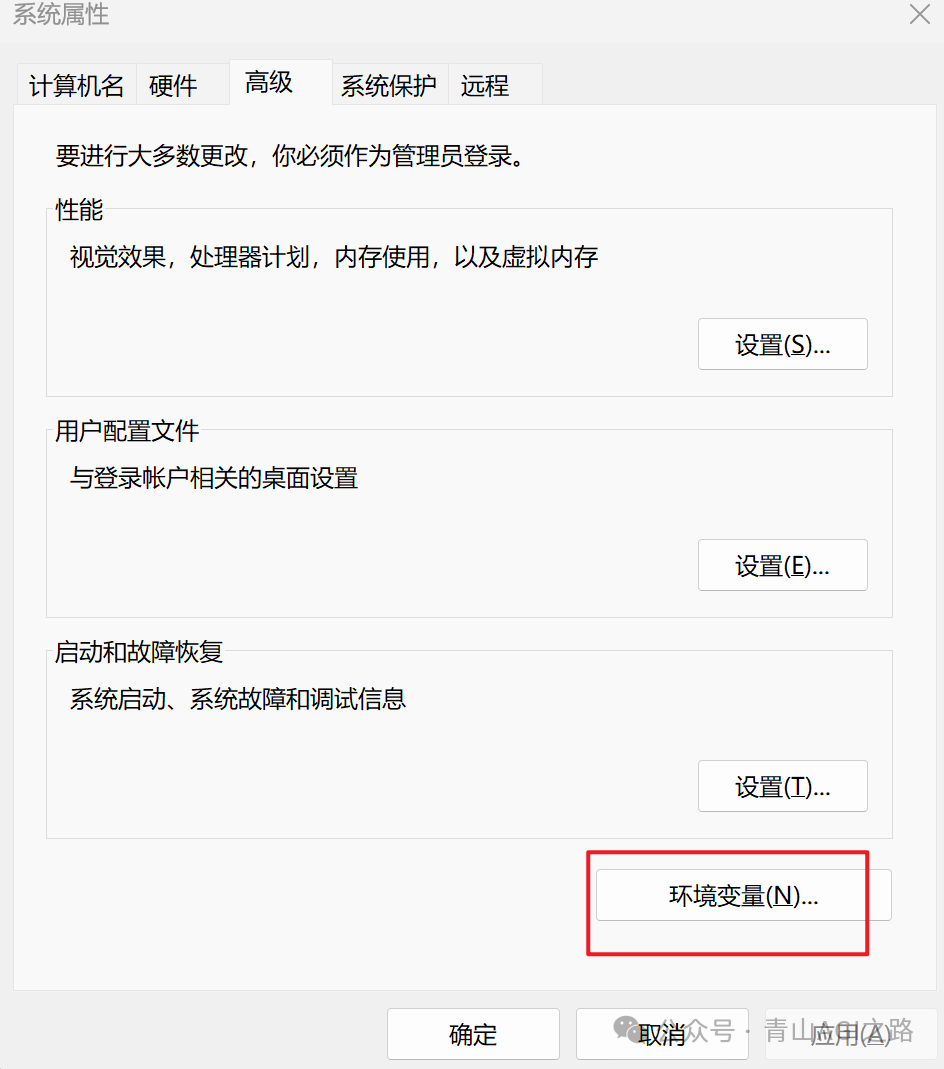
3.2.2 新建 ollama 环境变量
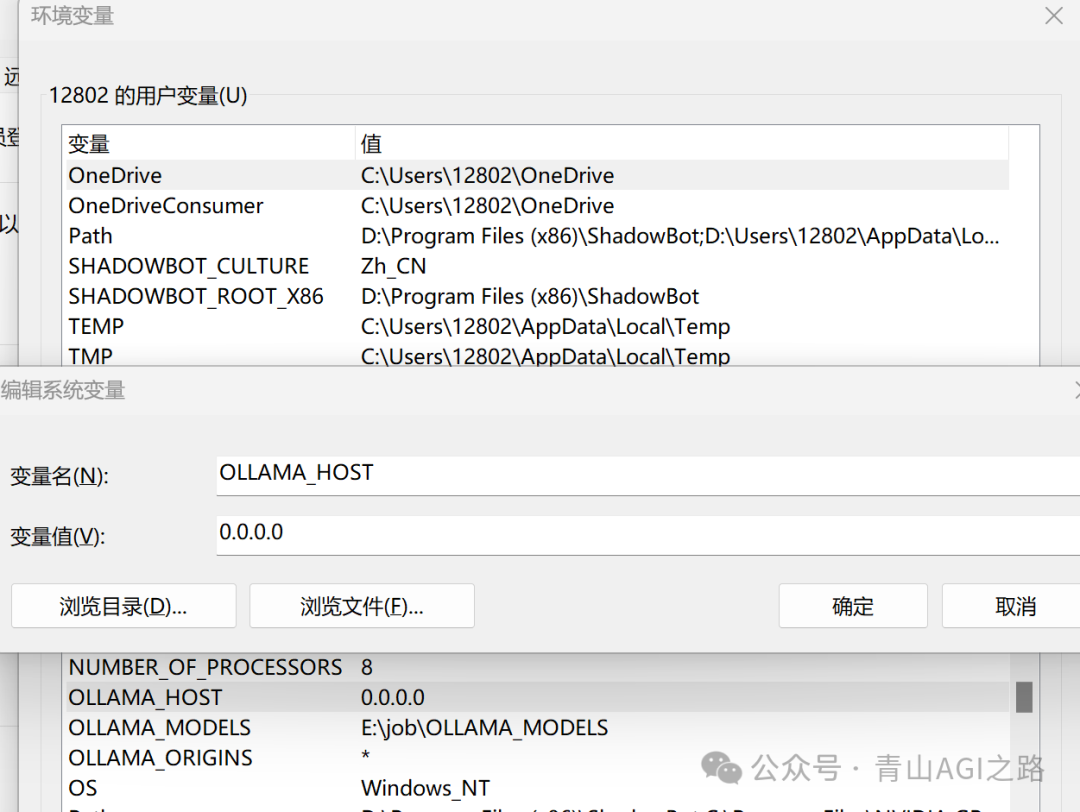
OLLAMA_HOST 配置访问的 ip,方便其他电脑访问
OLLAMA_MODELS 配置模型的下载位置,默认 C 盘,容易爆盘
OLLAMA_ORIGINS 设置跨域
OLLAMA_HOST 0.0.0.0OLLAMA_MODELS E:\job\OLLAMA_MODELSOLLAMA_ORIGINS *
点击【新建】按钮
3.3 终端使用验证
安装成功后,win 搜索 cmd,打开终端应用
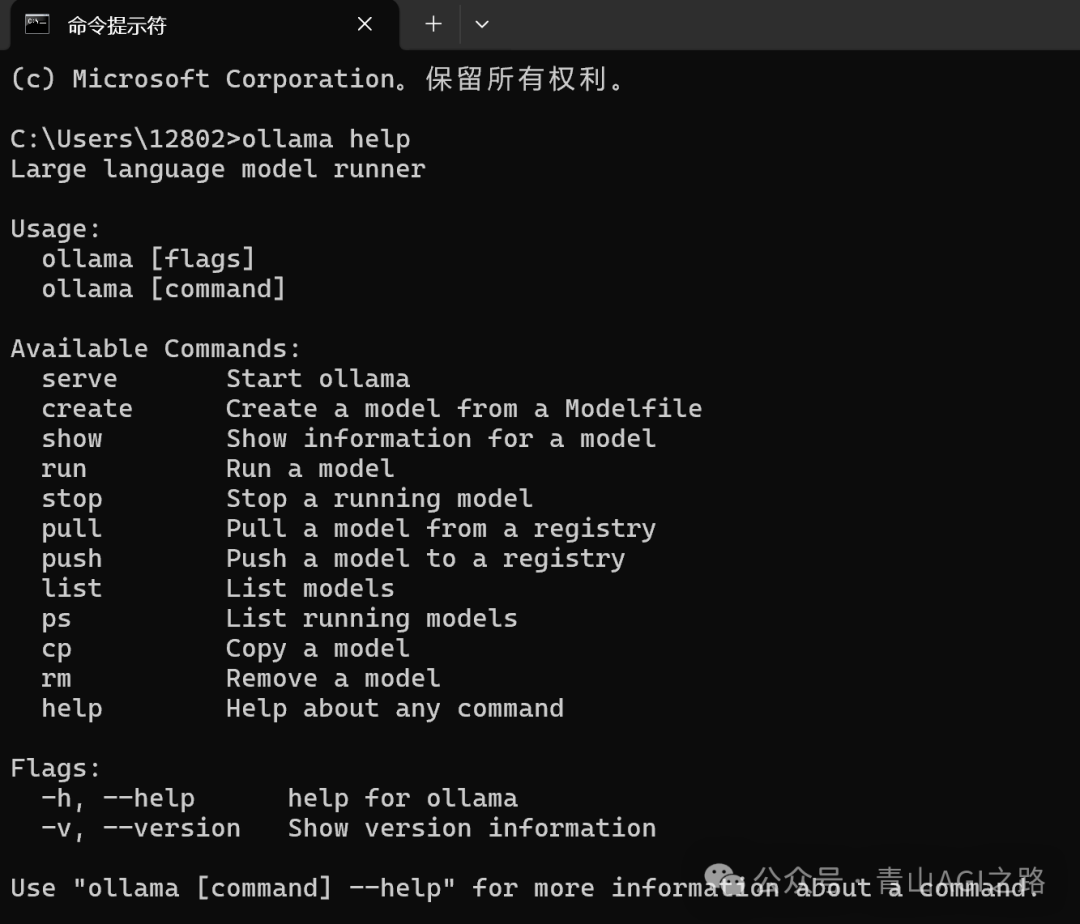
3.3.1 验证是否安装成功
复制到 cmd 中执行
ollama help
如下
3.4 启动
3.4.1 启动 ollama
复制到 cmd 中执行
ollama serve
3.4.2是否启动成功
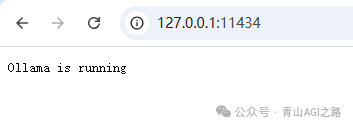
浏览器访问:http://127.0.0.1:11434/
出现如下标志表示运行成功,否则重新启动
4. Deepseek 显卡硬件要求(实操可跳过)
一般需要 GPU,显卡的算力能力
4.1 精准计算
-
确定模型参数规模例如:DeepSeek R1-7B 对应 7B 参数(十亿:7×10^9)。
-
选择计算精度
-
- FP16:每个参数占 2 字节
- 4-bit 量化:每个参数占 0.5 字节(4/8=0.5)
- 8-bit 量化:每个参数占 1 字节
-
场景系数选择
-
- 推理:仅需参数和激活值(约 1.2 倍参数体积)示例:7B 模型 FP16 推理显存 ≈ 7×2×1.2 = 16.8GB
-
**额外开销(KV 缓存)**每 token 的 KV 缓存显存 ≈ 2×层数×隐藏维度×序列长度×批次大小。例如:
-
- 7B 模型(32 层,4096 隐藏维度)在 1024 序列长度下,KV 缓存 ≈ 2×32×4096×1024×1 ≈ 256MB。
-
量化优化4-bit 量化可减少 75%参数体积,但需额外 10%-20%显存用于量化映射表示例:7B 模型 4-bit 推理显存 ≈ 7×0.5×1.2 + 0.3GB ≈ 4.5GB
4.2 简单计算
7B 参数(十亿:7×10^9),以字节为单位。
1G=102410241024 = 1B 参数
需要显存 ≈ 参数每个参数字节数1.5(还有其他缓存类)
例如:DeepSeek R1-7B 对应 7B 参数(十亿:7×10^9)。
显存配置 = 70.5(量化的字节数)*1.5 ≈ 5G
4.3 大概的算力对照表
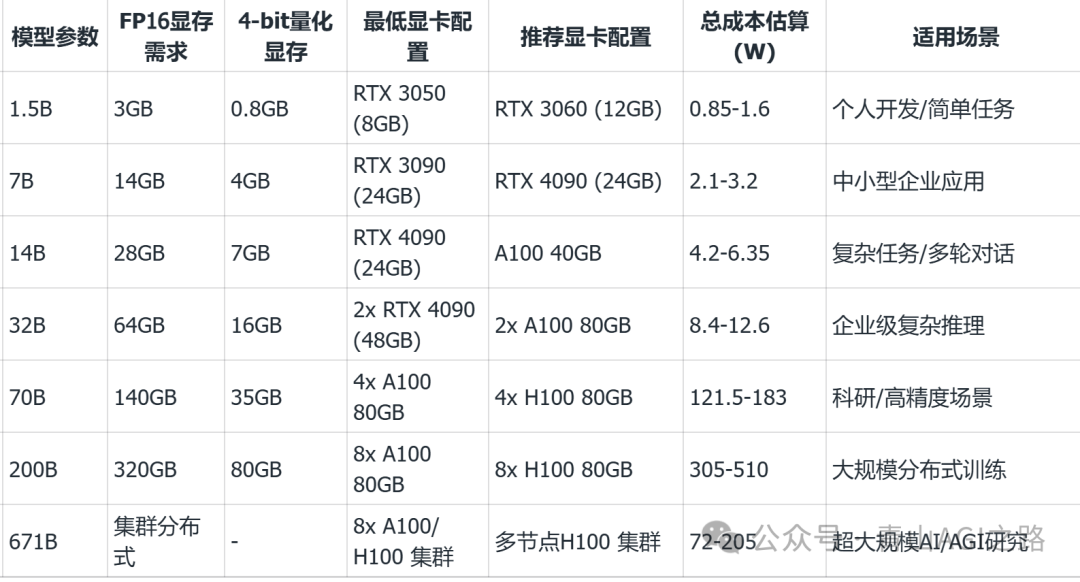
价格差异问题:200B vs 671B:671B 采用 MoE 架构+显存压缩技术(如 Int4 量化),单卡 RTX 4090 即可部署,而 200B 需 8x A100 集群,更详细请查看更多官方资料
说明:
- 量化支持:4-bit 量化可减少约 75%显存占用,但可能损失 5-10%精度
- 分布式训练:200B 以上参数需多显卡并行,建议使用 NVIDIA NVLink 互联
- 推理优化:使用 vLLM 等推理框架可进一步降低显存占用(如 14B 模型 INT8 推理仅需 9GB)
- 硬件兼容性:AMD Radeon 显卡支持部分模型(如 RX 7900XTX 可运行 14B 量化版),但生态支持弱于 NVIDIA
建议根据任务复杂度选择模型,例如日常使用选 7B/14B,科研选 70B+,超大规模任务需集群部署。实际部署前建议测试量化版本,平衡性能与资源消耗。
5. 选择 Deepseek 模型
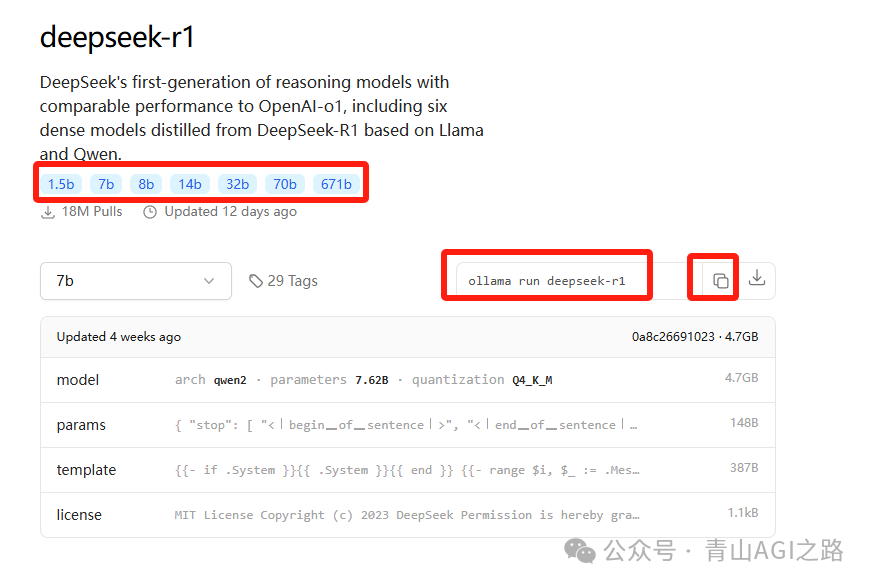
打开 Deepseek 模型:
https://ollama.com/library/deepseek-r1
5.1 模型选择
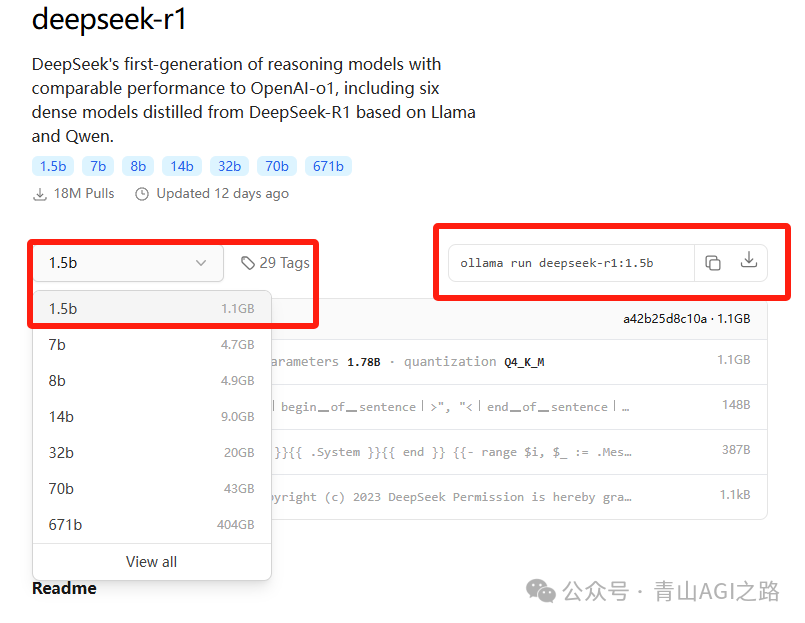
根据电脑的配置,可以选择最小的 1.5b 模型
5.2 拉取模型
复制命令到 cmd 中执行
ollama pull deepseek-r1:1.5b

5.3 运行模型(测试效果)
复制命名到终端运行
如 ollama run deepseek-r1:1.5b
ollama run deepseek-r1:1.5b
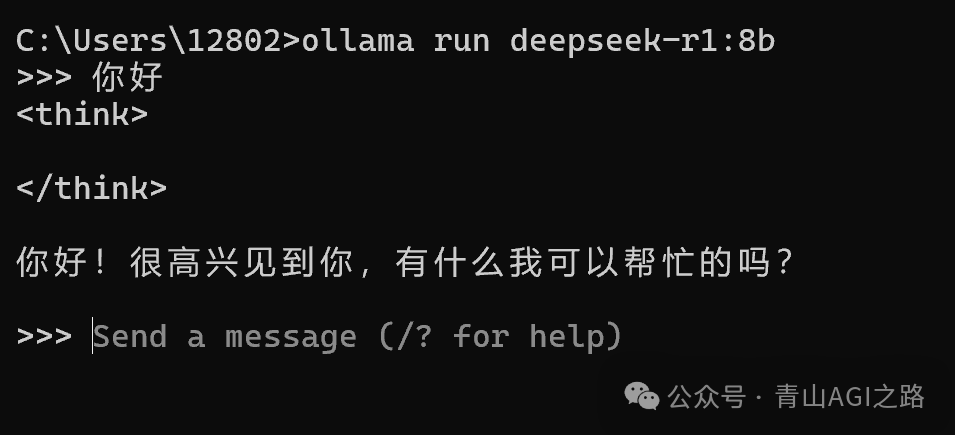
可按住:Ctrl+D 或者输入[/bye]退出
5.4 查看所有模型
复制到 cmd 中执行,可查看刚刚运行的模型
ollama list
效果:表示已经安装了 Deepseek-r1:8b 模型

6. 搭配界面 UI(穿上马甲)
终端操作不是很方便操作,所以我们需要一个界面来承载。
6.1 UI 马甲对比
目前推荐两个,Chatbox 和 Page Assist,可以任意选择一个,比较适合个人实用,更多功能可试试 Cherry Studio 或者 Open WebUI。
几款 UI 对比:
| 对比维度 | Chatbox | Page Assist | Cherry Studio |
|---|---|---|---|
| 核心功能 | 本地化部署,支持Ollama/DeepSeek离线运行 | 浏览器插件,联网搜索与本地模型联动 | 多模型集成(OpenAI/Gemini等)+ RAG功能 |
| 数据隐私 | ✔️ 全本地运行,无数据外传 | ❌ 依赖浏览器网络交互 | ✔️ 支持本地部署(需配置) |
| 模型支持 | 单一本地模型为主 | 本地模型+联网搜索 | ✔️ 多模型API接入(开源+闭源) |
| 部署复杂度 | 中高(需配置本地环境) | 低(即装即用) | 中(需API密钥或私有化部署) |
| 定制化能力 | ❌ 有限 | ❌ 轻量级功能 | ✔️ 企业级扩展(对接CRM/ERP等系统) |
| 联网功能 | ❌ | ✔️ 实时搜索与知识库增强 | ❌(需额外插件或API) |
| 适用场景 | 隐私敏感场景(金融/医疗) | 浏览器端快速问答/信息检索 | 企业级AI应用(多模型协同与数据安全) |
| 成本 | 低(本地资源消耗为主) | 免费开源 | 中高(部分API需付费/企业版授权) |
| 开发者友好度 | ✔️ 适合技术调试 | ❌ 用户友好但开发扩展有限 | ✔️ 开源社区支持+企业级文档 |
6.2 Chatbox
官方入口:https://chatboxai.app/zh
两种安装方式
6.2.1 使用网页版
配置
打开 https://web.chatboxai.app/
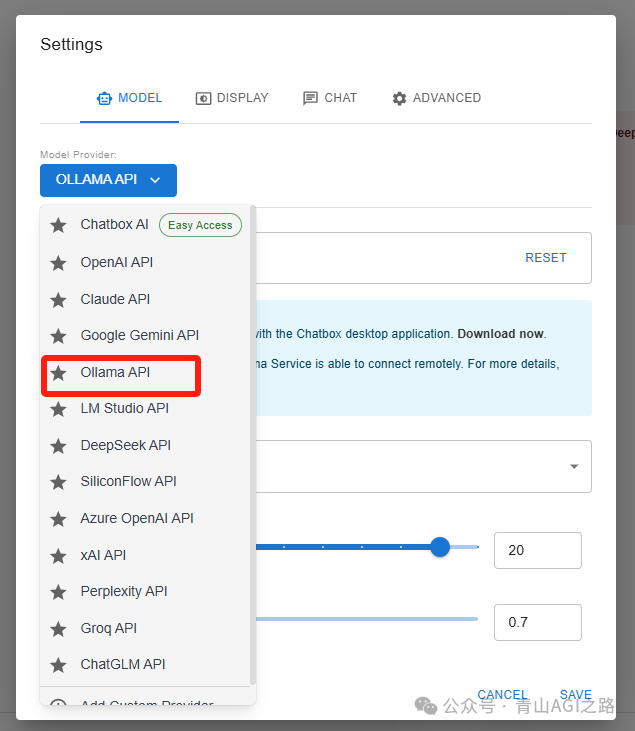
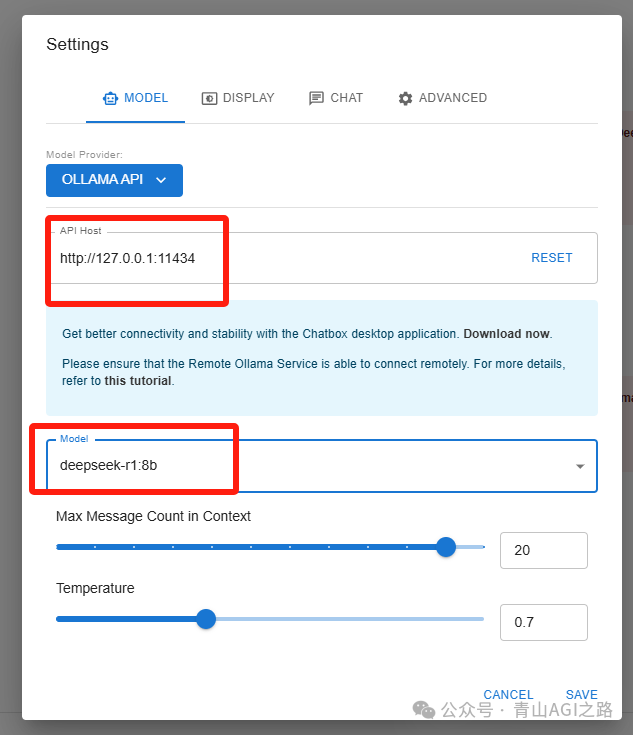
输入地址:http://127.0.0.1:11434/
效果
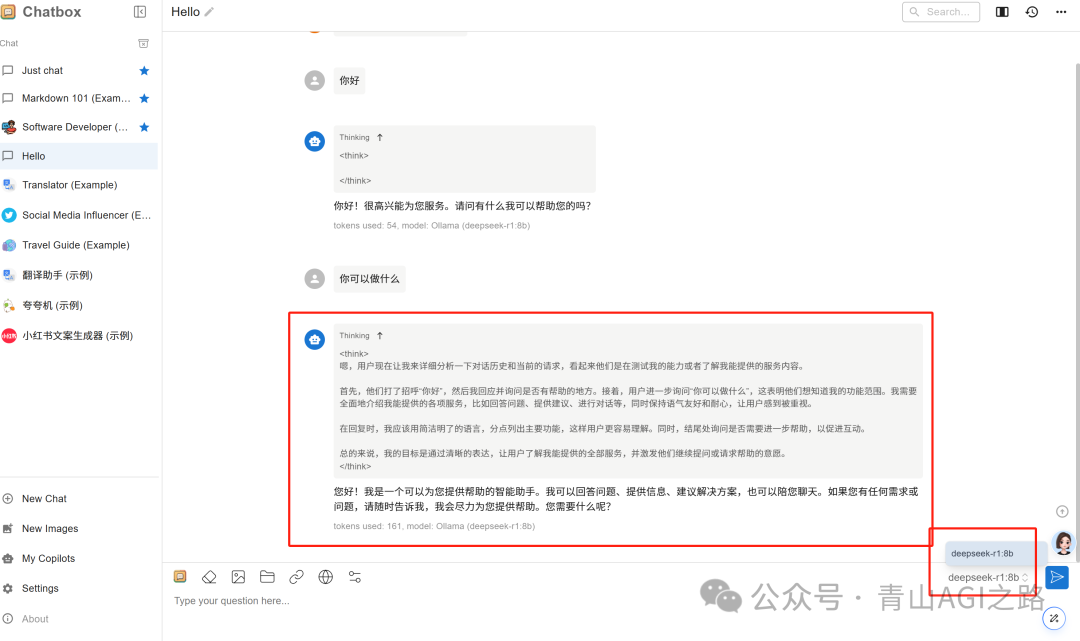
6.2.2 使用桌面版
打开入口:
https://chatboxai.app/zh
下载对应桌面版,配置参考网页版
6.3 Page Assist
Page Assist 作为一款开源的 Chrome 扩展程序,堪称本地 AI 模型交互的得力助手。它为用户打造了直观易用的交互界面,让本地 AI 模型的应用更加便捷。
6.3.1 安装扩展
可选择一种方式,在线或者离线安装
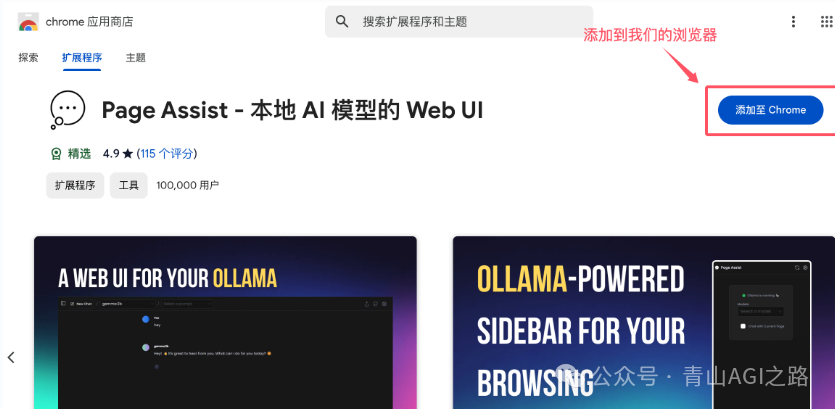
在线安装:谷歌商店
我们可以直接从 Chrome Web Store 或 Firefox Add-ons 商店下载安装,也可以通过手动安装的方式进行。
访问 https://chromewebstore.google.com/search/,搜索 Page Assist:
离线安装
下载方式
-
从 GitHub 下载:访问 Page Assist 的 GitHub 仓库,进入该页面后点击 “Releases” 标签,在里面找到适合你浏览器版本的插件文件进行下载。比如你使用 Chrome 浏览器,可下载对应的 Chrome 版本插件文件。
-
从第三方插件网站下载:可以通过 crxsoso 等第三方插件下载网站进行下载,但要注意选择正规、可靠的网站,避免下载到恶意软件或损坏的文件。
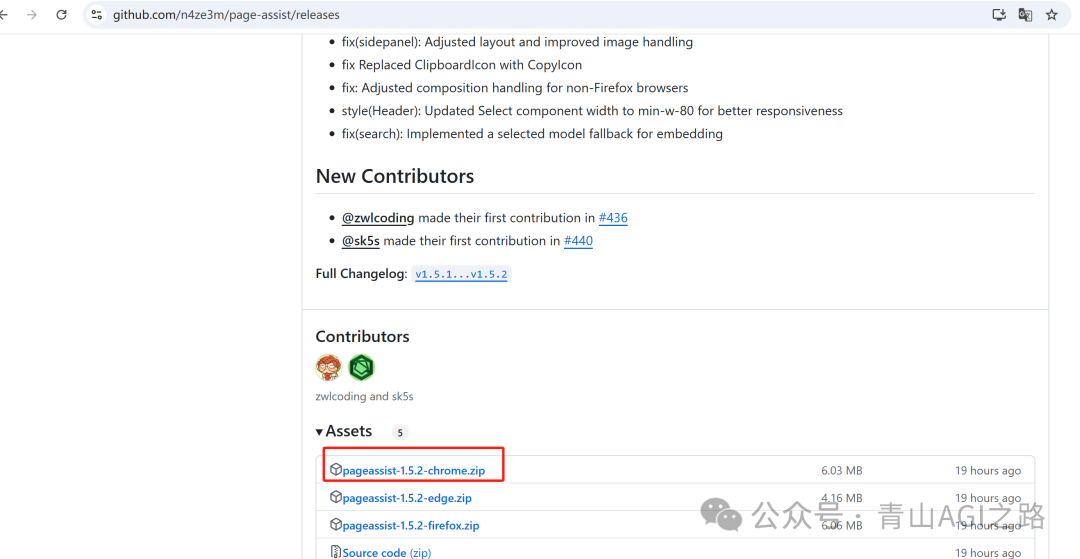
GitHub 下载插件安装
通过 GitHub 下载插件
然后打开浏览器【扩展程序】->【管理扩展程序】
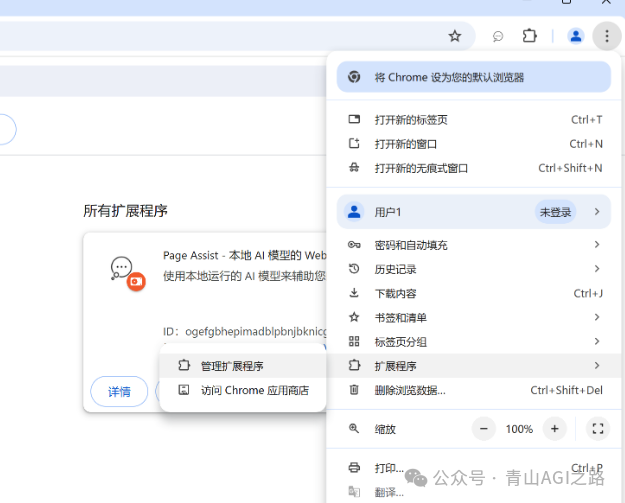
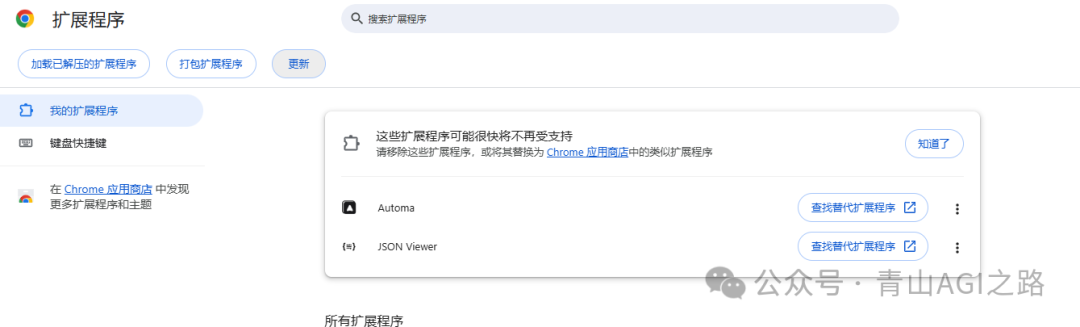
将文件解压后把下载的插件 crx 文件后将文件拖过去安装提示成功就行
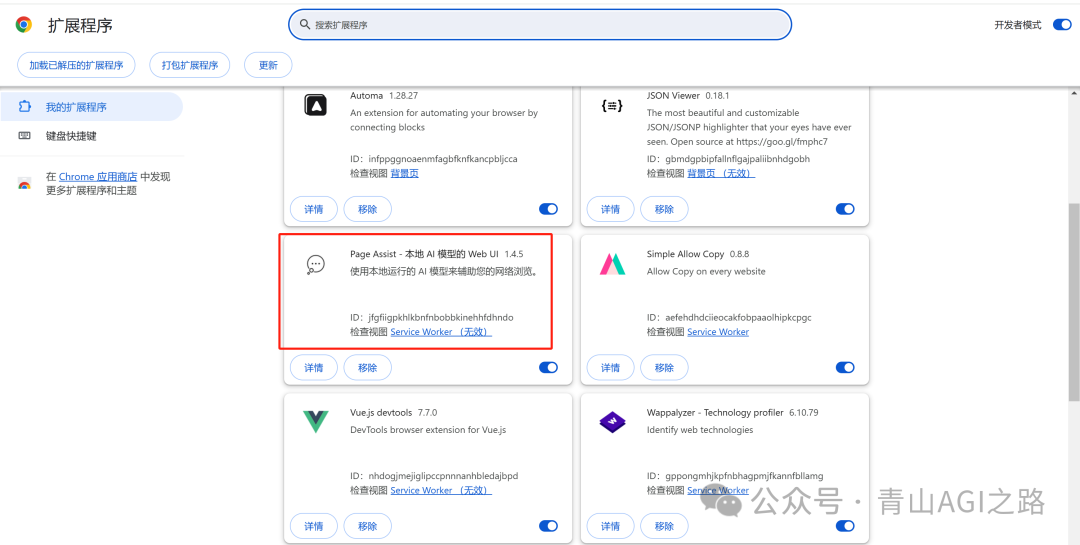
6.3.2 固定窗口
点击插件详情进去
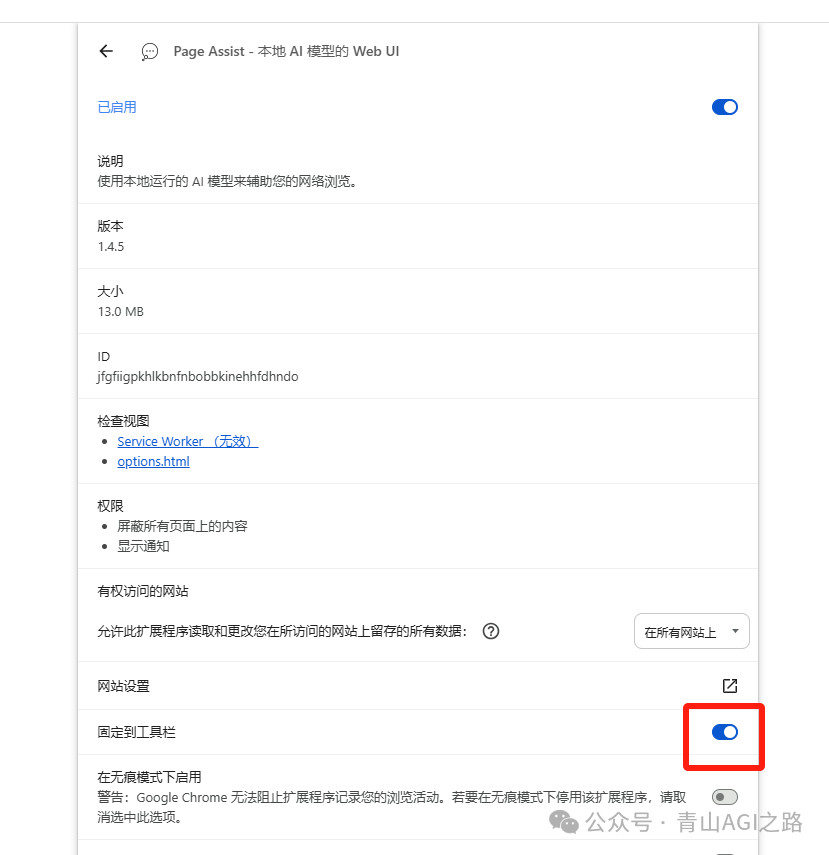
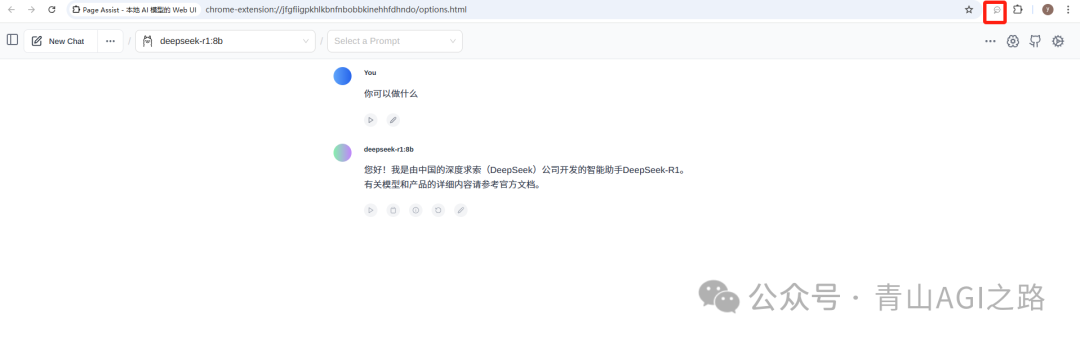
6.3.3 界面效果,会自动识别 ollama
打开:两个入口
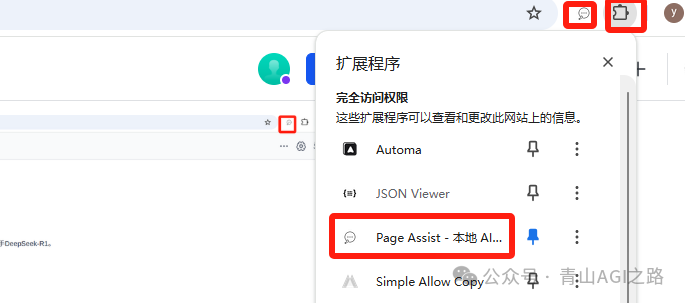
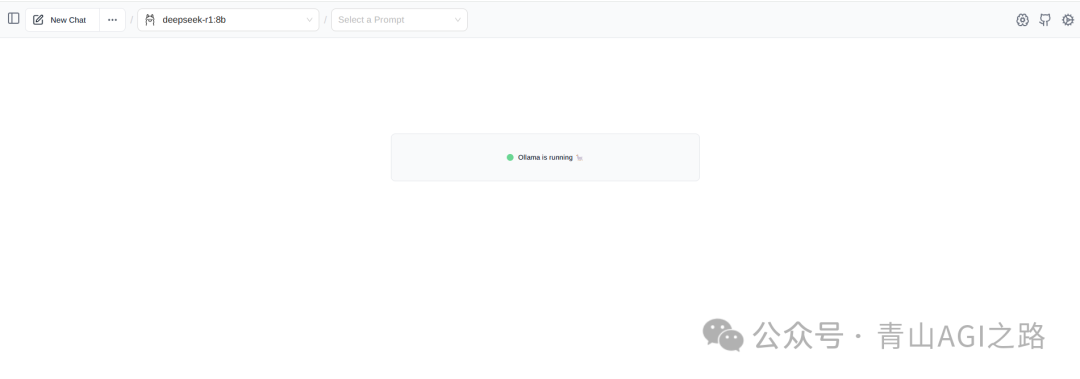
效果
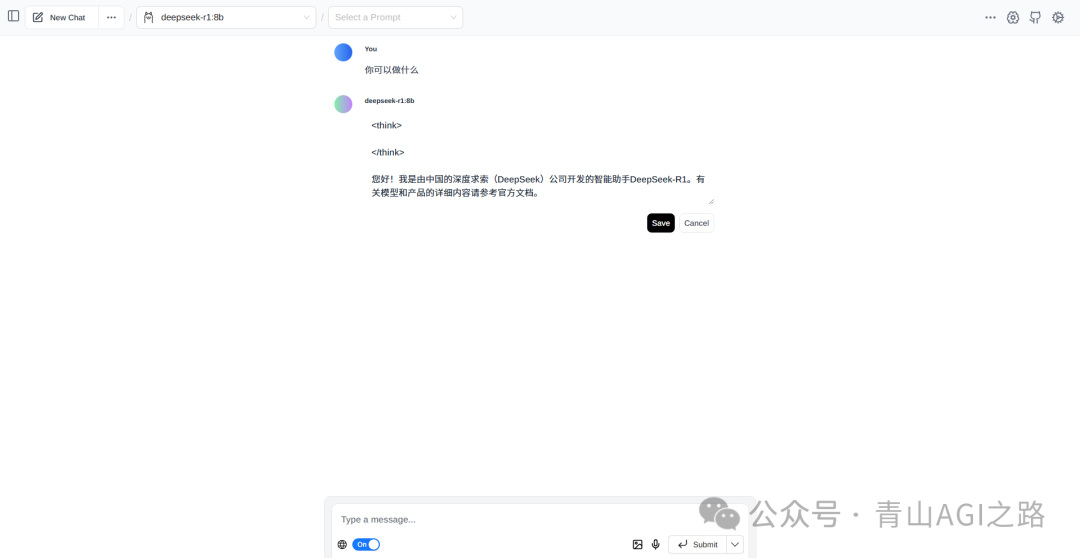
7. 其他
7.1 手机端
Chatbox 可以用网页版或 APP 版
ps:需要云部署把服务放出来才能访问
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
那么应该如何学习大模型
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【
保证100%免费】
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)