Ollama部署deepseek
参考Ollama是一个工具。他不是docker,不是前端或者后端,它就仅仅是一个工具官网我下面以aarch系统为例子做一下deepseek的部署。
参考 RDK X3上——部署deepseek - 嵌入式系统 -电子工程世界-论坛 -手机版
Ollama是一个工具。他不是docker,不是前端或者后端,它就仅仅是一个工具
官网 Ollama

我下面以aarch系统为例子做一下deepseek的部署
目录
1 下载ollama
windows、linux(amd)、mac 直接在官网上下载就行


linux的aarch需要在github的release中

下载 ollama-linux-arm64.tgz


2 安装ollama
把这个包搞到 /opt/ollama 中

然后解压

解压之后这有个bin

进目录之后有个ollama

在bin下执行./ollama serve
- 这里换了个aarch的机器截图,前面的流程都是一样的
- 这里不是卡死了,而是这本身是个服务,它就是一个不终止的终端

这时候就能看一下ollama中已经下载好的镜像了。由于是新的所以这什么都没有

使用ollama服务的时候,会在ollama serve中有响应

为了不每次开关机启动一次服务,你可以让它开机自启。为了不每次到/opt/ollama/bin下执行,你可以搞一个自定义命令
在~/.bashrc中定义一个自定义命令
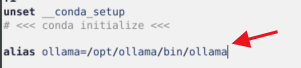
然后在任意位置就能使用ollama了

3 通过ollama使用modelscope中的模型
ollama可以加载modelscope中的gguf模型(gguf模型可以理解为类似deepseek的模型)
- 文档地址 魔搭社区

访问 魔搭社区 之后,点击框架,然后再点击gguf就可以看到modelscope的所有gguf模型

我们在这里可以看到deepseek

点击模型文件,然后你就随便点一个,比如我点第一个

然后就能看到模型了

这里的模型太大了,不适合在小型设备上使用,我们换个小的
我这里找了一下其他的deepseek,发现这个还可以

开启后执行 ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf
它首先会下载(第一次下载完成后第二次不会再次下载),下载好了你就直接问就行了

我随便问个内容

我们回过头来分析一下ollama run这个指令,拆解一下就是 ollama run [红色线的部分]:[绿色线的部分]

ollama不同的系统可能会下载到不同的位置,比如说RDKX3的模型默认会放到 /usr/share/ollama/.ollama/models/

deepseek在这

对于jetsonnx就会放在这

4 通过python请求ollama
4.1 思考过程
我们在上面启动ollama服务的时候我们能看到,实际上ollama就是一个服务

而且它看起来还像是一个http,我们可以用浏览器访问一下,访问一下你发现也能用

知道这个之后我在网上有针对性的找了找,找到了对应的接口
ollama其实有官方的请求方法 GitHub - ollama/ollama-python: Ollama Python library ,但是这个库我没下载下来

4.2 ollama官方接口文档
翻了翻ollama的Readme,后面我们发现它提供了接口文档 ollama/docs/api.md at main · ollama/ollama · GitHub

4.3 python请求
首先需要确保ollama serve开启

之后通过代码请求/api/generate这个接口
import requests
url = 'http://127.0.0.1:11434/api/generate'
question = "hello"
max_word = 20
data = {
"model":"modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf",
"prompt":question,
"stream":False,
"options":{"temperature":0.7,"num_predict":max_word}
}
response = requests.post(url,json=data)
print(response)
print(type(response))
print(response.text)
print(type(response.text))
true = True
ollama_response = eval(response.text).get("response").splitlines()
print(olloma_response)
if len(olloma_response)>=5:
ollama_answer = ollama_response[4:]
ollama_answer = ' '.join(ollama_answer)
elif len(olloma_response)==3:
ollama_answer = "I don't want to talk to you"
else:
ollama_answer = "It's hard to answer you in " + str(max_word) + " words"
print(ollama_answer)我们先看效果

我们说一下我代码中用到的参数
4.3.1 model 用的哪个模型
这个是用到的模型,类型是字符串,写 ollama list 查出来的结果

4.3.2 prompt 提问的问题
向deepseek提问的问题,类型是字符串
4.3.3 stream 是否启用流式回答
是否启用流式回答,流式回答就是一个字一个字往外蹦,但是由于咱们是http请求,它最后的结果最后也是一起出。我们可以简单用一下

它返回的是一堆键值对,画红框的地方是它要回复的文字。如果使用流式回复,后面的处理方式要有变化,我这里没改就报错了

4.3.4 options 其余配置项
代码中用到的是下面两个
- temperature 回答的灵动程度。如果这个值越高,回答的结果就越跳脱。
- num_predict 回答字数限制
我们代码中限制字数是20,字数越少它响应的就越快。这个回答字数限制不是它会在20字以内回答问题,而是它回答问题,回答到20个字之后它就不说了。我们做个例子

我们可以看到画红箭头的实际上是它的回答,这里回答了20个字就砍掉了。我们可以对比上面的回答,上面的回答是有 <think> </think> 这个东西的。但是我们把回答砍断了就没有 </think>
绿色的箭头是做个了容错,告诉你很难在20字以内回答你的问题

还有一种情况它思考完了,它不返回任何东西。这种情况不多,我们也可以做一个容错


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)