利用Deepseek+腾讯云HAI快速创建一个python网页爬虫程序
借助腾讯云HAI和DeepSeek的强大能力,我们可以轻松应对复杂的网页数据爬取任务,我们可以快速搭建一个爬取网站数据信息的代码,不仅提升了开发效率,还确保了数据处理的精准度和智能化。通过云端资源的灵活调配和智能化模型的应用,我们开发者可以更加专注于业务逻辑的优化,而无需担心基础设施的复杂性。随着技术的不断进步,未来的数据爬取和处理将更加高效、智能,为各行各业的数字化转型提供强大的支持和保障。
简介
DeepSeek-R1 在后训练阶段大规模应用了强化学习技术,在标注数据极为稀缺的情况下,显著提升了模型的推理能力。在数学、代码和自然语言推理等任务中,其性能已与 OpenAI O1 正式版相媲美。
腾讯云 HAI 已提供 DeepSeek-R1 模型的预装环境,用户可以在 HAI 平台上快速启动并进行测试,轻松接入到我们的实际业务中。
快速使用
创建 DeepSeek-R1 应用
-
登录 高性能应用服务 HAI 控制台。
-
单击新建,进入高性能应用服务 HAI 购买页面。
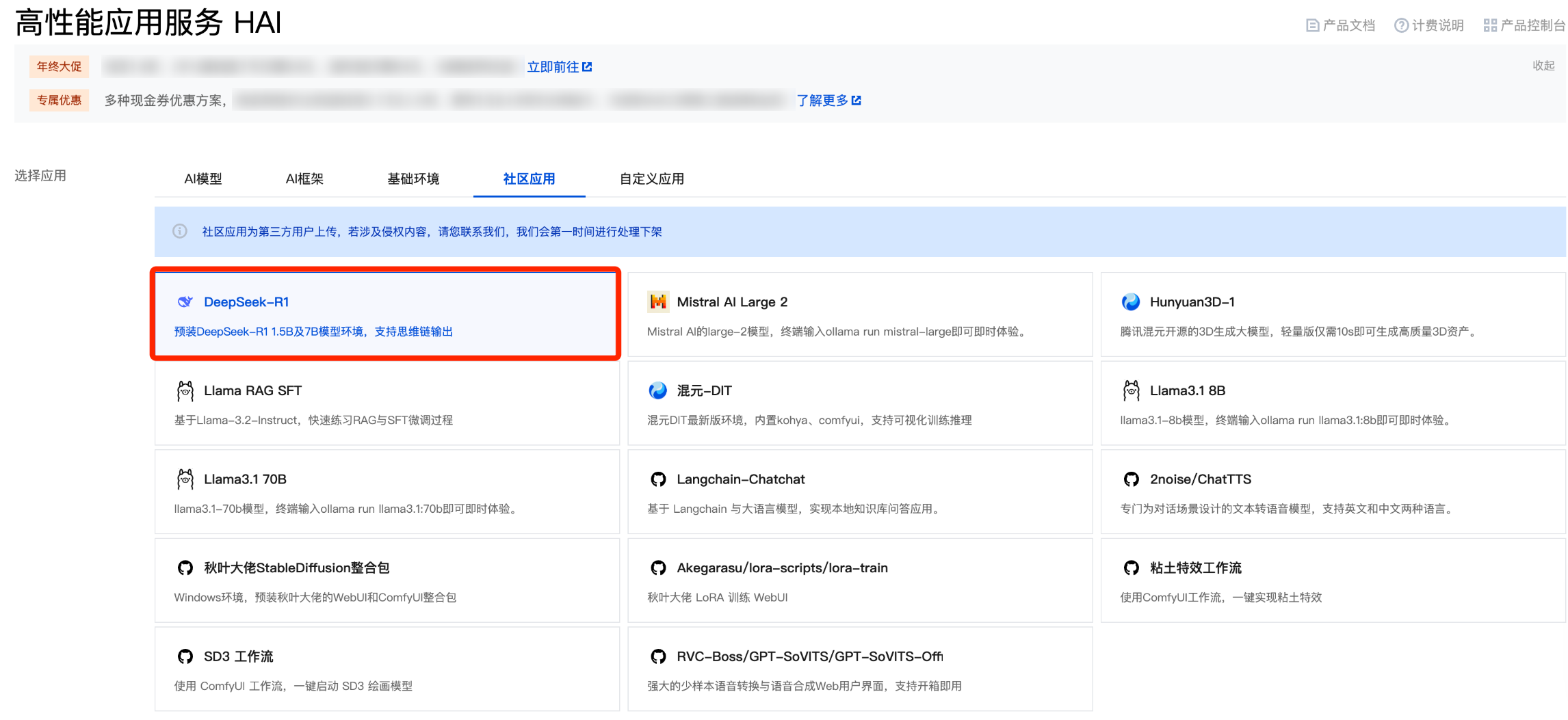
我们选择社区应用,应用选择 DeepSeek-R1。建议选择靠近自己实际地理位置的地域,降低网络延迟、提高您的访问速度。
或者我们可以点击这个一元体验活动

购买我所需要的HAI-CPU体验版(算力方案所支持的CPU算力核数和时长不同)

在单并发访问模型的情况下,建议最低配置如下:
| 模型 | 参数量级 | 推荐算力套餐 |
|---|---|---|
| DeepSeek-R1 | 1.5B/7B/8B/14B | GPU基础型 |
| DeepSeek-R1 | 32B | GPU进阶型 |
具体算力套餐配置及参数可参考 套餐类型。
**实例名称:**自定义实例名称,若不填则默认使用实例 ID 替代。
购买数量:默认1台、 单击立即购买、提交订单,并根据页面提示完成支付。
等待创建完成。单击实例任意位置并进入该实例的详情页面。同时您将在站内信中收到登录密码。此时,可通过可视化界面(GUI)或命令行(Terminal)使用 DeepSeek 模型。
中图网图书畅销榜信息爬取
- 选择这个OpenWebUI可视化界面使用

- 在新窗口中,单击开始使用。

- 之后输入自己的邮箱等信息,设置密码成功登录,进入交互界面:
我们让其写一份python数据爬取——中图网图书畅销榜信息爬取包含一下模块: 导入所需第三方库 打开 CSV 文件并创建写入 发送请求循环抓取每一页的数据 解析每本书的具体信息并清洗 将数据写入 CSV 文件 控制请求间隔 关闭文件

可见它这里给出了详细的完整可运行代码和注释,但是由于具体网址的不同,甚至页面结构的不同,可能会产生报错,这里我们具体情况具体分析,这里我对代码进行了优化和改善,在OpenWebUI可视化界面下我们可直接运行代码,简直是太方便了。
利用DeepSeek的自然语言处理和推理能力,能够准确识别和提取网站中复杂或多样化的内容,减少了传统爬虫可能出现的误抓取或遗漏问题。腾讯云HAI提供了预装环境,用户可以轻松启动并接入DeepSeek模型,无需复杂的配置,降低了开发的技术门槛,适合快速原型开发和上线。

下面是DeepSeek的强大推理能力体现、快速分析和提取网站上的关键信息,b并给出了详细的注释说明。
腾讯云HAI提供了灵活的计算资源,可以根据需求快速调整算力,支持大规模爬虫任务。
导入所需第三方库
比如我们有代码不知它的具体意思,我们可直接询问:
导入requests、parsel、csv、time、和re三个库
requests 库是一个广泛使用的 HTTP 请求库,旨在简化发送 HTTP/HTTPS 请求并处理响应的过程。它将复杂的网络请求细节进行了封装,提供了易于使用的接口,使开发者能够轻松地与 Web 服务进行交互。
parsel 库用于从 HTML 或 XML 文档中提取数据,主要通过 CSS 选择器和 XPath 来进行解析和数据抽取,广泛应用于网页数据抓取和处理场景。
csv 库是用来处理 CSV格式文件的标准库。CSV 是一种非常常见的文本文件格式,用于存储表格数据,每一行代表一条记录,字段之间用逗号(或其他分隔符)分隔。用于读写 CSV 文件,处理数据和进行文件操作。
time 库提供了一些与时间相关的功能。它可以帮助你获取当前时间、暂停程序的执行、进行时间测量等。
re: 用于进行正则表达式操作,这里用来清洗掉价格或折扣中的一些无关符号。
打开文件并创建写入

其逻辑分析能力,清晰明了可见:
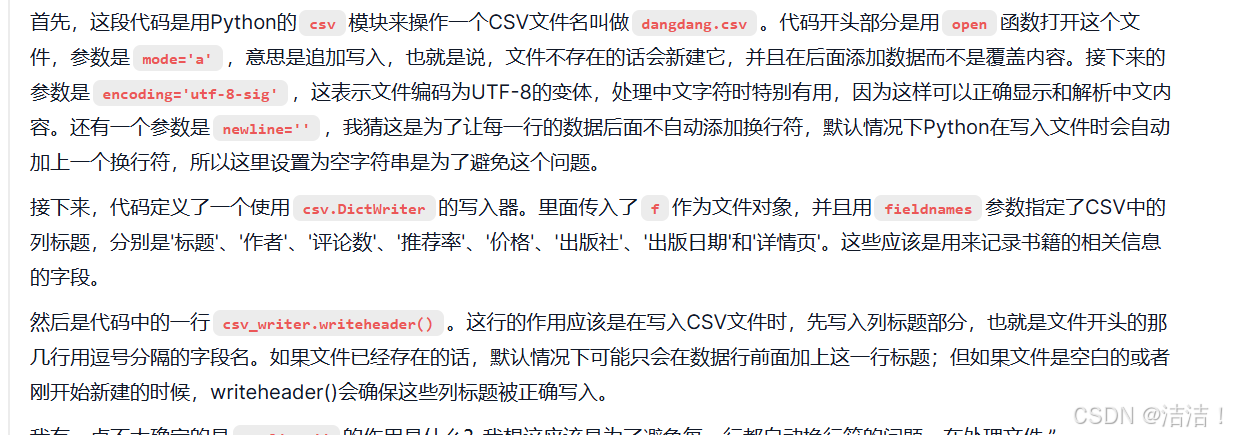
open(‘bookschina.csv’, mode=‘a’, encoding=‘utf-8-sig’, newline=‘’): 打开文件 bookschina.csv 以追加模式写入,如果文件不存在,则会创建该文件,编码为 utf-8-sig,适合存储中文数据并兼容 Excel。
csv.DictWriter(f, fieldnames=[…]): 创建一个 DictWriter 对象,用来写入字典格式的数据。字段名是预定义的,定义了每列数据的名称。
csv_writer.writeheader(): 如果文件为空,这行代码会写入表头(即字段名)。这样每次执行爬虫时,都能确保文件结构一致。
发送请求循环抓取每一页的数据


for page in range(1, 8): 这行代码循环遍历网页的页码。page 变量控制请求的页数。
headers: 定义请求头,模拟浏览器的行为。使用 User-Agent 来告诉服务器请求是来自一个普通浏览器,而不是一个爬虫程序,防止被反爬虫机制拦截。
url = f’https://www.bookschina.com/24hour/1_0_{page}/': 动态生成当前页的 URL。
response = requests.get(url=url, headers=headers): 发送 GET 请求,获取页面内容。
selector = parsel.Selector(response.text): 使用 parsel 库解析返回的 HTML 内容,生成一个 Selector 对象。
lis = selector.css(‘.bookList li’): 使用 CSS 选择器提取页面上所有包含书籍信息的
- 标签。每个
- 标签代表一本书的内容。
-
解析每本书的具体信息并清洗


在这个循环中,我们对每一本书的
- 标签进行解析:《具体分析》
-
number = li.css(‘.num span::text’).get(): 获取书籍的编号。通过 CSS 选择器提取 标签内的文本内容。
title = li.css(‘.cover a::attr(title)’).get(): 获取书籍的标题。通过 CSS 选择器提取 a 标签的 title 属性值。
author = li.css(‘.infor .author a::text’).get(): 获取书籍的作者,提取 标签内的文本内容。
price = li.css(‘.infor .priceWrap .sellPrice::text’).get(): 获取书籍的价格,并清洗掉其中的 ‘¥’ 符号。
discount = li.css(‘.infor .priceWrap .discount::text’).get(): 获取书籍的折扣,并清洗掉括号及折扣符号。
publisher = li.css(‘.infor .publisher a::text’).get(): 获取书籍的出版社。
href = li.css(‘.cover a::attr(href)’).get(): 获取书籍的详情页链接。
将数据写入 CSV 文件

book_info = {…}: 将提取到的书籍信息组织成字典格式。
csv_writer.writerow(book_info): 将字典中的数据写入 CSV 文件的每一行。
print(book_info): 打印当前书籍信息,供调试用,确保爬取的数据是正确的。
控制请求间隔

time.sleep(1): 暂停 1 秒,避免频繁请求导致 IP 被封禁。
关闭文件
f.close(): 确保在数据爬取完成后关闭文件,保存数据。
下面是完整代码:
import requests # 导入requests库,用于发送网络请求 import parsel # 导入parsel库,用于解析HTML页面 import csv # 导入csv库,用于写入CSV文件 import time # 导入time库,用于处理时间间隔 import pandas as pd # 导入pandas库,可用于数据处理 # 打开文件 'dangdang.csv' 用于追加写入,确保文件编码为 utf-8-sig(适用于中文文件) f = open('dangdang.csv', mode='a', encoding='utf-8-sig', newline='') # 设置CSV文件的列标题 csv_writer = csv.DictWriter(f, fieldnames=[ '标题', # 书籍标题 '作者', # 作者 '评论数', # 评论数 '推荐率', # 推荐率 '价格', # 书籍价格 '出版社', # 出版社 '出版日期', # 出版日期 '详情页' # 详情页面链接 ]) # 如果文件为空,写入CSV标题(字段名) csv_writer.writeheader() # 遍历每一页的数据(假设总共有9页) for page in range(1, 10): print(f'正在下载第{page}页数据================================') # 定义请求头,模拟浏览器行为(防止被反爬虫机制阻止) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36' } # 动态拼接URL,'page'变量控制请求的页数 url = f'http://bang.dangdang.com/books/bestsellers/01.56.00.00.00.00-24hours-0-0-1-{page}' # 发送GET请求获取页面内容 response = requests.get(url=url, headers=headers) # 使用parsel库的Selector对象来解析返回的HTML selector = parsel.Selector(response.text) # 获取所有书籍信息所在的<li>标签 lis = selector.css('.bang_list_mode li') # 遍历所有书籍的<li>标签,提取书籍信息 for li in lis: title = li.css('.name a::attr(title)').get() # 获取书名 author = li.css('.publisher_info a::attr(title)').get() # 获取作者 comments = li.css('.star a::text').get() # 获取评论数 recommend = li.css('.tuijian::text').get() # 获取推荐率 price = li.css('.price .price_n::text').get() # 获取价格 publisher = li.css('.publisher_info a::text').get() # 获取出版社 publish_date = li.css('.publisher_info span::text').get() # 获取出版日期 href = li.css('.name a::attr(href)').get() # 获取书籍详情页面链接 # 将提取的数据组织成字典形式 book_info = { '标题': title, '作者': author, '评论数': comments, '推荐率': recommend, '价格': price, '出版社': publisher, '出版日期': publish_date, '详情页': href, } # 打印出当前书籍信息,供调试用 print(book_info) # 将书籍信息写入CSV文件 csv_writer.writerow(book_info) # 模拟请求间隔,避免发送过多请求被封禁(每次请求后暂停1秒) time.sleep(1) # 关闭CSV文件,保存数据 f.close()成功爬取结果如下:

总结
借助腾讯云HAI和DeepSeek的强大能力,我们可以轻松应对复杂的网页数据爬取任务,我们可以快速搭建一个爬取网站数据信息的代码,不仅提升了开发效率,还确保了数据处理的精准度和智能化。
通过云端资源的灵活调配和智能化模型的应用,我们开发者可以更加专注于业务逻辑的优化,而无需担心基础设施的复杂性。随着技术的不断进步,未来的数据爬取和处理将更加高效、智能,为各行各业的数字化转型提供强大的支持和保障。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)