R1/o1/o3等LRM火热背后,微调、推理等LLM后训练方法,看这篇综述够了 |最新
随着DeepSeek-R1、OpenAI的o1和o3等大型推理模型(Large Reasoning Models,LRMs)的出现,我们正在见证一个关键转变:从单纯依赖预训练向精细化后训练(Post-training)技术的飞跃。这些模型不仅在基准测试上取得了突破性成绩,更在复杂推理和实际应用中展现出前所未有的能力。
前言
人们普遍认为,真正的智力既赋予我们推理能力,又使我们能够检验假设,还能为未来可能发生的情况做好准备。 ——让·卡尔法,《何为智力?》(1994年)
后训练时代的大语言模型新格局
随着DeepSeek-R1、OpenAI的o1和o3等大型推理模型(Large Reasoning Models,LRMs)的出现,我们正在见证一个关键转变:从单纯依赖预训练向精细化后训练(Post-training)技术的飞跃。这些模型不仅在基准测试上取得了突破性成绩,更在复杂推理和实际应用中展现出前所未有的能力。
对于正在开发AI产品的工程师而言,理解这些后训练方法不再是可选项,而是必备技能。重要的事情是:如果有可能,建议你认认真真读一遍这篇文章,再去对照论文好好再看一遍论文。这篇文章对于未来几年都很重要。至少你可以看到,过去模型的发展脉络以及未来发展的方向和可能。
本文基于最新发表的《A SURVEY ON POST-TRAINING OF LARGE LANGUAGE MODELS》综述论文,为您揭示后训练技术的核心原理、实现方法和应用场景,帮助您在当前LRM竞争激烈的环境中把握技术趋势和实现路径。

从ChatGPT到DeepSeek-R1的关键里程碑
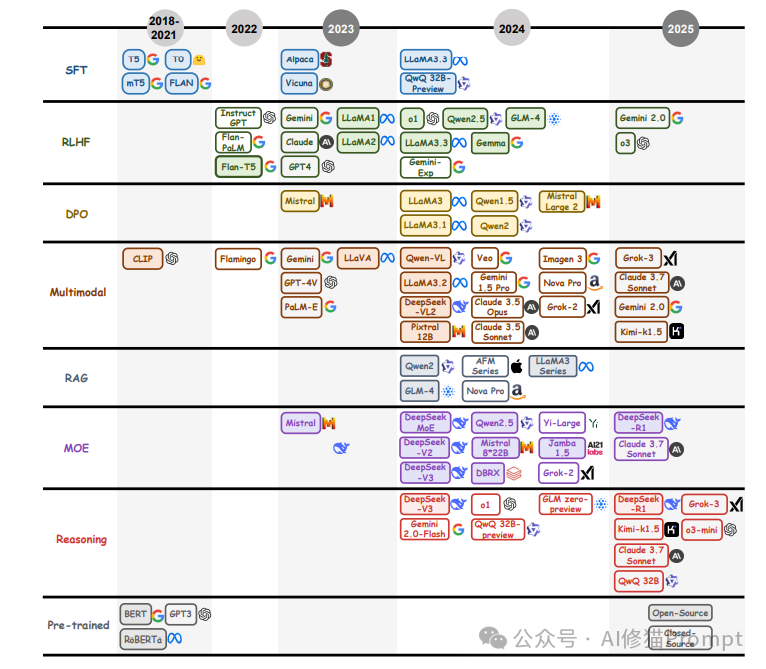 这张时间线图展示了2018年至2025年间大语言模型后训练技术的关键发展节点。图中清晰地划分了SFT(监督微调)、RLHF(人类反馈强化学习)、DPO(直接偏好优化)、多模态、RAG(检索增强生成)、MOE(混合专家模型)和推理等七大技术路线的演进历程。我们可以看到,从2018年BERT和GPT的出现,到2022年ChatGPT的爆发,再到2025年DeepSeek-R1和o3等大型推理模型的兴起,后训练技术经历了从简单微调到复杂推理增强的质变。特别值得注意的是,2024-2025年间,推理能力增强成为技术发展的主要方向,标志着LLM正在从通用模型向专业推理工具转变。
这张时间线图展示了2018年至2025年间大语言模型后训练技术的关键发展节点。图中清晰地划分了SFT(监督微调)、RLHF(人类反馈强化学习)、DPO(直接偏好优化)、多模态、RAG(检索增强生成)、MOE(混合专家模型)和推理等七大技术路线的演进历程。我们可以看到,从2018年BERT和GPT的出现,到2022年ChatGPT的爆发,再到2025年DeepSeek-R1和o3等大型推理模型的兴起,后训练技术经历了从简单微调到复杂推理增强的质变。特别值得注意的是,2024-2025年间,推理能力增强成为技术发展的主要方向,标志着LLM正在从通用模型向专业推理工具转变。
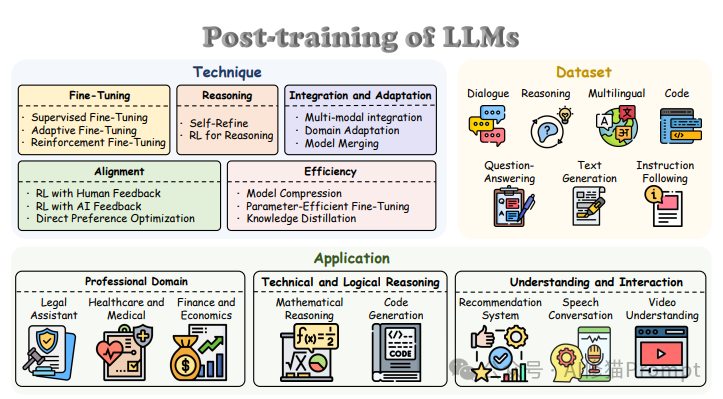 上图全面展示了大语言模型后训练技术的结构框架,分为技术、数据集和应用三大部分。在技术层面,包括微调、推理、集成与适应、对齐和效率五大类;数据集分为对话、推理、多语言、代码、问答、文本生成和指令跟随七种类型;应用场景则涵盖专业领域(法律、医疗、金融)、技术和逻辑推理(数学推理、代码生成)以及理解与交互(推荐系统、对话、视频理解)三大类。这一结构图不仅清晰展示了后训练技术的全貌,还揭示了技术、数据和应用之间的内在联系,为工程师提供了系统性的技术选择和应用指南。
上图全面展示了大语言模型后训练技术的结构框架,分为技术、数据集和应用三大部分。在技术层面,包括微调、推理、集成与适应、对齐和效率五大类;数据集分为对话、推理、多语言、代码、问答、文本生成和指令跟随七种类型;应用场景则涵盖专业领域(法律、医疗、金融)、技术和逻辑推理(数学推理、代码生成)以及理解与交互(推荐系统、对话、视频理解)三大类。这一结构图不仅清晰展示了后训练技术的全貌,还揭示了技术、数据和应用之间的内在联系,为工程师提供了系统性的技术选择和应用指南。
后训练技术的发展历程可追溯至2018年,当时BERT和GPT的出现奠定了"预训练+微调"范式的基础。随着GPT-3的发布,后训练技术迎来了快速发展期,各种方法层出不穷:从针对特定任务的微调,到确保模型与人类偏好一致的对齐策略,再到增强模型推理能力的技术。
2022年,InstructGPT和ChatGPT的出现标志着对齐技术的重大突破,通过人类反馈的强化学习(RLHF)实现了模型与人类意图的高度一致。2023年,Claude和GPT-4等模型进一步推动了对齐技术的发展,引入了更高效的直接偏好优化(DPO)等方法。
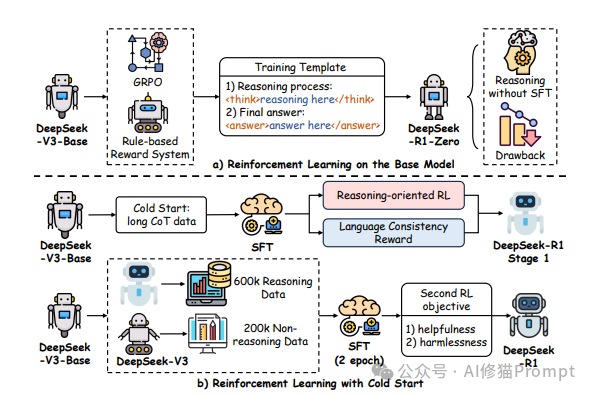
2025年,DeepSeek-R1的出现代表了后训练技术的最新高峰,它突破了传统监督微调(SFT)的限制,通过思维链(CoT)推理和探索性强化学习策略,在复杂推理任务上取得了显著进展。DeepSeek-R1-Zero更是整合了自验证、反思和探索等先进技术,展现了后训练技术的无限潜力。
微调技术:从全参数到参数高效的演进
全参数微调:基础但强大
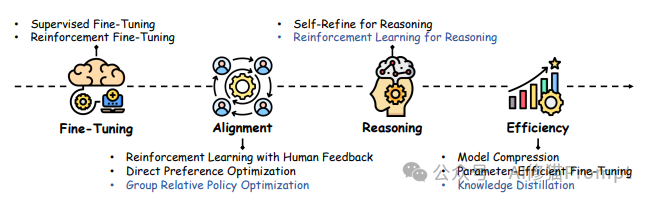
上图展示了大语言模型后训练技术的演进路径,从左至右依次为微调、对齐、推理和效率四大核心技术领域。在微调方面,技术从监督微调(SFT)发展到强化微调(ReFT);对齐技术则从人类反馈的强化学习(RLHF)发展到直接偏好优化(DPO)和群组相对策略优化(GRPO);推理技术从自我优化发展到强化学习推理;效率优化则包括模型压缩、参数高效微调和知识蒸馏。图中蓝色高亮的部分特别标注了DeepSeek模型的技术贡献,展示了其在推理增强方面的创新。这一技术演进图谱不仅揭示了后训练技术的发展脉络,也为工程师提供了清晰的技术选择指南。
全参数微调(Full-parameter Fine-tuning)是最直接的后训练方法,通过在特定任务数据上调整模型的所有参数来优化性能。尽管计算成本高昂,但其效果显著,如GPT-3到InstructGPT的转变就是通过全参数微调实现的。
实现原理:全参数微调通过最小化预测损失来更新模型参数:
L(θ) = -E(x,y)~D[log P(y|x;θ)]
其中,θ表示模型参数,(x,y)表示输入-输出对,D表示微调数据集。
参数高效微调(PEFT):降低资源门槛的关键
随着模型规模的增长,全参数微调的成本变得难以承受,参数高效微调技术应运而生。这些方法仅调整模型的一小部分参数,大幅降低了计算和存储需求,同时保持了接近全参数微调的性能。

主要PEFT方法包括:
-
加性PEFT:在原始模型基础上添加少量可训练参数
• Adapter:在Transformer层之间插入小型神经网络
• LoRA(低秩适应):通过低秩分解矩阵来更新权重,计算公式为:
W = W0 + ∆W = W0 + BA其中,B∈R(d×r),A∈R(r×k),r远小于d和k
-
选择性PEFT:仅更新模型中特定的参数
• BitFit:只微调偏置参数
• Sparse Fine-tuning:仅更新模型中的稀疏参数 -
重参数化PEFT:通过引入新的参数表示来优化模型
• Prompt Tuning:在输入序列中添加可学习的软提示向量
• P-Tuning v2:在Transformer架构中引入层级提示向量
微调技术的最新进展:ReasoningFT和ReFT
最新的微调技术已经从简单的任务适应转向了增强模型的推理能力:
-
• ReasoningFT:通过思维链(CoT)数据增强微调过程,引导模型学习多步推理
-
• ReFT(强化微调):结合强化学习和微调,通过奖励机制优化模型的推理过程
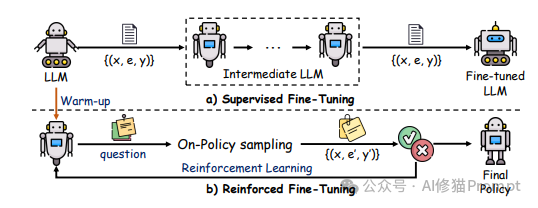
这些技术在数学、科学和逻辑推理等复杂任务上表现出色,是DeepSeek-R1和OpenAI o1等LRM模型的核心训练方法。
对齐技术:确保模型行为符合人类期望
RLHF:人类反馈的强化学习
RLHF是目前最广泛使用的对齐技术,通过人类反馈来指导模型生成符合人类偏好的输出。其工作流程包括:
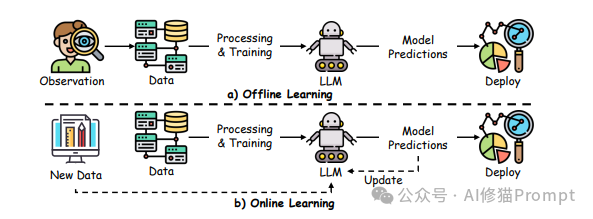
-
奖励模型训练:收集人类对模型输出的偏好数据,训练奖励模型R(x,y)
-
策略更新 :使用强化学习算法(如PPO)优化模型策略,目标函数为:
max_π E[R(x,y) - β * KL(π||π_ref)]其中,π是当前策略,π_ref是参考策略,β是控制KL散度的系数
RLHF的优势在于能够捕捉复杂的人类偏好,但其缺点是需要大量人类标注数据,且训练过程复杂。
DPO:直接偏好优化
DPO通过直接从偏好数据学习策略,绕过了显式的奖励建模步骤,大大简化了对齐过程。给定偏好三元组(x, y_w, y_l),其中y_w是偏好输出,y_l是非偏好输出,DPO的目标函数为:
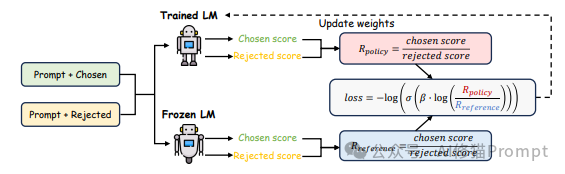
L_DPO(π_θ; π_ref) = -E_{(x,y_w,y_l)}[log σ(β log(π_θ(y_w|x)/π_ref(y_w|x)) - β log(π_θ(y_l|x)/π_ref(y_l|x)))]
DPO的主要优势是训练效率高,无需奖励模型,且更易于实现和扩展。Claude和最新版本的GPT模型都采用了DPO或其变体进行对齐。
对齐技术的最新进展:RLAIF和W2SG
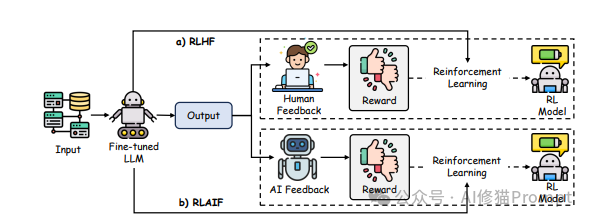
• RLAIF(AI反馈的强化学习):使用AI生成的标签代替人类反馈,大幅提高了对齐过程的可扩展性
• W2SG(弱到强泛化):利用强大模型的知识来指导弱模型的学习,实现知识迁移和能力提升
这些技术正在推动对齐方法向更高效、更可扩展的方向发展,为构建更符合人类价值观的AI系统提供了新途径。
推理增强:LRM模型的核心竞争力
推理增强的基本原理
推理增强技术旨在提高模型的多步推理能力,使其能够处理复杂的逻辑推理、数学问题和科学分析等任务。其核心在于构建适当的状态表示和奖励设计。
状态表示通常包括:
• 问题描述
• 已生成的推理步骤
• 上下文信息和相关知识
奖励设计包括:
• 二元正确性奖励:根据最终答案的正确性给予奖励
• 步骤准确性奖励:根据每个推理步骤的质量给予增量奖励
• 自一致性奖励:根据多条推理路径的一致性给予奖励
主要推理增强方法
- 思维链(CoT)训练:通过显式的推理步骤指导模型学习多步推理过程
- 自我反思:让模型评估和改进自己的推理过程
- 探索性强化学习:通过探索不同的推理路径来优化模型的推理策略
DeepSeek-R1和OpenAI o1/o3等LRM模型正是通过这些技术实现了在复杂推理任务上的突破性进展。例如,DeepSeek-R1-Zero整合了自验证、反思和探索等技术,在数学和科学推理任务上表现出色。
效率优化:让大模型更轻量、更快速
随着模型规模的不断增长,效率优化变得至关重要。主要的效率优化技术包括:
量化技术
量化通过降低参数精度来减少模型大小和计算需求。常见的量化方法包括:
• 后训练量化(PTQ):在训练后将模型参数从高精度(如FP32)转换为低精度(如INT8)
• 量化感知训练(QAT):在训练过程中模拟量化效果,提高量化后的模型性能
量化的数学表示为:
X_L = Round(X_F * (2^b-1) / absmax(X_L))
其中,X_F是浮点参数,X_L是量化后的参数,b是位宽。
剪枝技术
剪枝通过移除模型中不重要的连接或神经元来减小模型规模。主要方法包括:
• 结构化剪枝:移除整个神经元或注意力头
• 非结构化剪枝:移除单个权重连接
知识蒸馏
知识蒸馏通过将大模型(教师模型)的知识转移到小模型(学生模型)中,实现模型压缩。蒸馏损失函数通常为:
L_KD = α * L_CE(y, σ(z_s)) + (1-α) * L_KL(σ(z_s/T), σ(z_t/T))
其中,z_s和z_t分别是学生模型和教师模型的输出logits,T是温度参数,α是平衡系数。
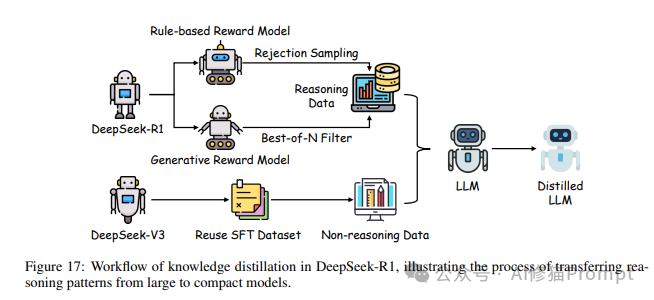
这些效率优化技术使得大型模型能够在资源受限的环境中部署,为AI产品的实际应用提供了可能。
集成与适应:扩展模型能力的关键
多模态集成
多模态集成技术使LLM能够处理和生成图像、音频和视频等多种模态的数据。主要方法包括:
- 视觉编码器集成:通过视觉编码器(如CLIP)将图像转换为LLM可处理的表示
- 音频编码器集成:通过音频编码器将语音和声音信号转换为文本表示
- 多模态对齐:通过对齐不同模态的表示空间,实现跨模态理解和生成
检索增强生成(RAG)
RAG通过从外部知识源检索相关信息来增强模型的生成能力,特别适用于需要最新或专业知识的场景。RAG的工作流程包括:
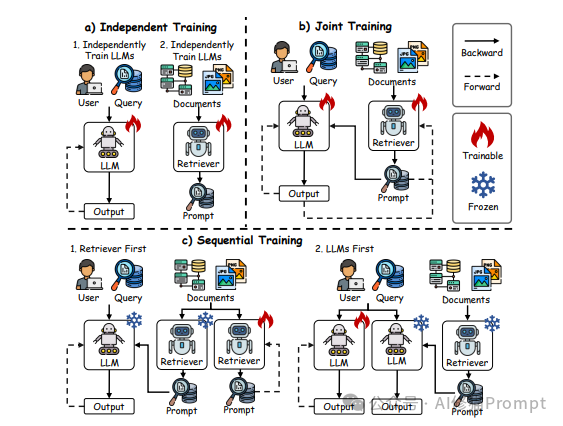
- 查询生成:从用户输入生成检索查询
- 知识检索:从知识库中检索相关文档
- 增强生成:将检索到的知识与原始输入结合,生成最终输出
RAG技术已在问答系统、科学研究和医疗健康等领域取得了显著成功,是扩展LLM知识边界的有效方法。
模型合并
模型合并技术通过组合多个专业模型的知识和能力,创建功能更全面的模型。主要方法包括:
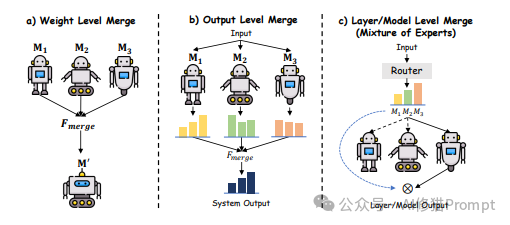
- 权重级合并:直接合并模型权重,如权重平均和权重插值
- 模块级合并:组合不同模型的功能模块
- 模型级合并:在推理时动态选择或组合多个模型的输出
这些集成与适应技术为LLM提供了更广泛的应用可能性,使其能够适应不同领域和任务的需求。
后训练数据集:质量与多样性的平衡
后训练数据集的质量和多样性对模型性能至关重要。主要的数据集类型包括:
人类标注数据集
人类标注数据集具有高准确性和上下文保真度,但成本高昂且规模有限。代表性数据集包括:
• Anthropic的HH-RLHF:包含约16万条人类偏好数据
• OpenAI的WebGPT:包含约2万条人类比较数据
蒸馏数据集
蒸馏数据集通过精炼原始数据集创建,具有更高的信息密度。主要方法包括:
• 自对话生成:如Baize数据集,通过ChatGPT自对话生成65.3万条多轮对话
• 模型交互:如UltraChat数据集,通过模型间交互生成140万条指令-响应对
合成数据集
合成数据集通过自动化方法生成,可以大规模创建特定领域或任务的数据。代表性数据集包括:
• Alpaca:通过GPT-4生成的5.2万条指令-响应对
• WizardMath:专注于数学推理的合成数据集
选择合适的数据集对后训练效果至关重要,工程师应根据具体任务和资源情况进行选择和组合。
应用场景:后训练技术的实际落地
后训练技术已在多个领域展现出强大的应用价值:
专业领域应用
- 法律助手:通过领域微调和对齐,模型能够提供可靠的法律指导,如LawGPT和Lawyer-LLaMA
- 医疗辅助:通过专业知识集成和伦理对齐,模型可以辅助医疗诊断和健康咨询
- 金融分析:通过推理增强和知识集成,模型能够进行复杂的金融分析和风险评估
技术开发辅助
- 代码生成:通过代码特定微调,模型能够生成高质量的代码,如GitHub Copilot
- 技术文档生成:通过RAG技术,模型可以生成准确的技术文档
- 调试辅助:通过推理增强,模型能够帮助开发者诊断和修复代码问题
交互式应用
- 智能助手:通过对齐和多模态集成,模型可以提供自然、有用的交互体验
- 教育辅导:通过推理增强和知识适应,模型能够提供个性化的教育内容
- 创意写作:通过风格微调和内容控制,模型可以辅助创意写作和内容创作
这些应用场景展示了后训练技术的广泛价值,为AI产品开发提供了丰富的可能性。
结论:后训练技术的战略意义
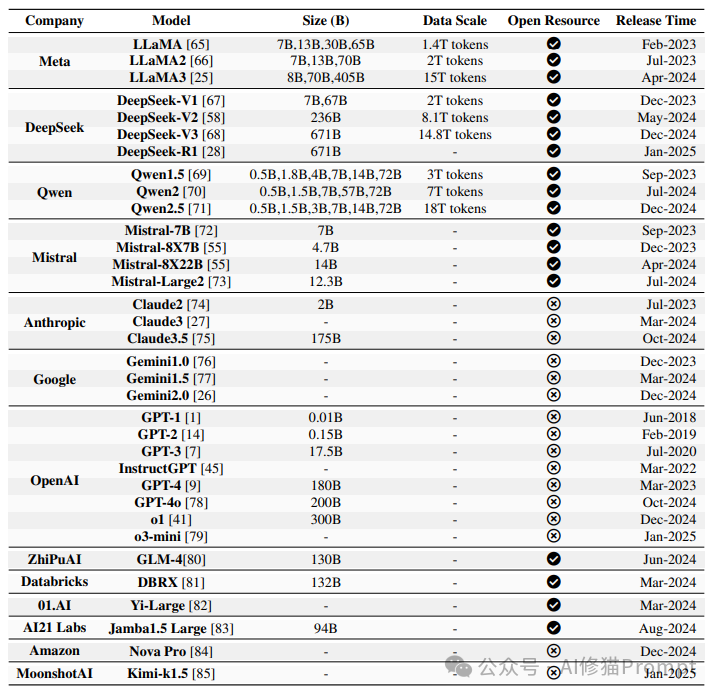
这张表格全面对比了当前主流大语言模型的关键参数和特性,包括公司、模型名称、模型大小、训练数据规模、开源状态和发布时间。从表中我们可以清晰地看到模型规模的增长趋势,从早期GPT-1的0.01B参数到最新o1的300B参数;同时也展示了开源模型(如Meta的LLaMA系列、DeepSeek系列和Qwen系列)与闭源模型(如OpenAI的GPT系列、Anthropic的Claude系列)的并行发展。特别值得注意的是,2024-2025年发布的模型(如DeepSeek-R1、o1和o3-mini)在保持大规模参数的同时,更加注重推理能力的增强,标志着大语言模型正在从通用智能向专业推理工具转变。这一趋势对AI产品开发者具有重要的战略指导意义。
后训练技术已成为LLM发展的关键驱动力,从ChatGPT到DeepSeek-R1的演进清晰地展示了这一点。对于AI产品开发者而言,掌握这些技术不仅能够提升产品性能,还能够降低开发成本、扩展应用场景。
随着R1/o1/o3等LRM模型的出现,我们正在进入一个推理能力成为核心竞争力的新时代。在这个时代,后训练技术将继续发挥关键作用,推动AI系统向更精确、更道德、更多功能的方向发展。
作为AI工程师,了解并应用这些后训练方法,将使您在快速发展的AI领域保持竞争力,创造出更智能、更有价值的产品和服务。无论是微调、对齐、推理增强,还是效率优化和多模态集成,这些技术都将是您工具箱中不可或缺的组成部分。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)