DeepSearch源码分析
结合deepseek r1推理模型,在问题拆解和判断是否需要额外的查询这两个任务中利用强推理模型返回结果。
项目地址:https://github.com/zilliztech/deep-searcher
注意:本篇文章主要介绍QA部分,文件加载部分不会涉及
整理架构
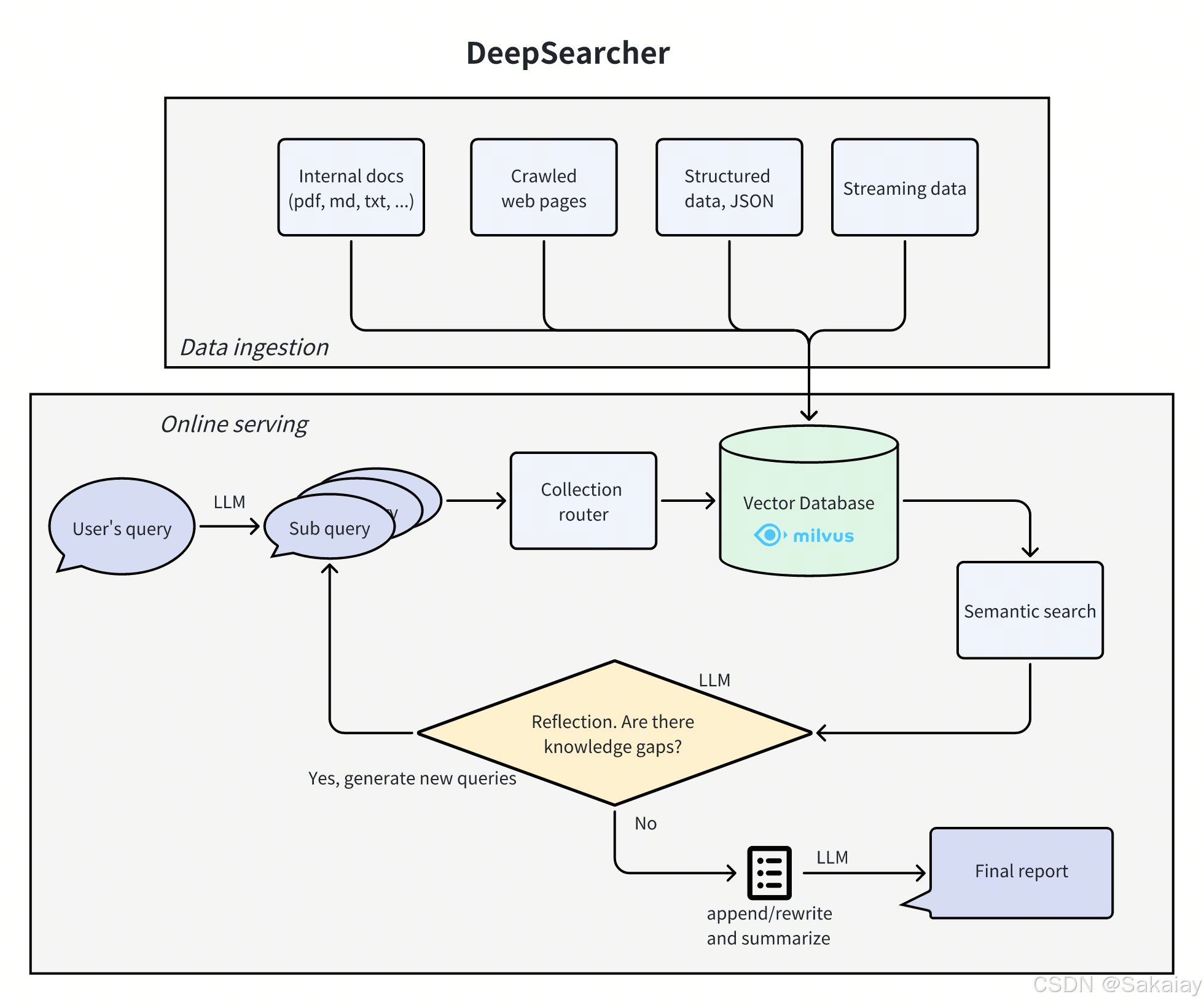
数据支持本地文件和url链接
支持json文件、pdf文件、text文件、非结构化文本。
问答:
文件:deepsearcher/online_query.py
问答代码如下:
async def async_query(
original_query: str, max_iter: int = 3
) -> Tuple[str, List[RetrievalResult], int]:
retrieval_res, all_sub_queries, retrieve_conseumed_token = await async_retrieve(
original_query, max_iter
)
### GENERATE FINAL ANSWER ###
log.color_print("<think> Generating final answer... </think>\n")
final_answer, final_consumed_token = generate_final_answer(
original_query, all_sub_queries, retrieval_res
)
log.color_print("\n==== FINAL ANSWER====\n")
log.color_print(final_answer)
return final_answer, retrieval_res, retrieve_conseumed_token + final_consumed_token
async_retrieve为检索函数,generate_final_answer为生成回答函数
async_retrieve检索
函数async_retrieve中
用户的问题会被分解成几个query
### SUB QUERIES ###
sub_queries, used_token = generate_sub_queries(original_query)
total_tokens += used_token
generate_sub_queries为分解query的脚本,Prompt如下:
PROMPT = """To answer this question more comprehensively, please break down the original question into up to four sub-questions. Return as list of str.
If this is a very simple question and no decomposition is necessary, then keep the only one original question in the list.
Original Question: {original_query}
<EXAMPLE>
Example input:
"Explain deep learning"
Example output:
[
"What is deep learning?",
"What is the difference between deep learning and machine learning?",
"What is the history of deep learning?"
]
</EXAMPLE>
Provide your response in list of str format:
"""
通过问题分解后,输入变为了sub_query(分解后的问题),然后遍历每一个sub_query去检索相关的段落。
# Create all search tasks
search_tasks = [search_chunks_from_vectordb(query, sub_gap_queries) for query in sub_gap_queries]
# Execute all tasks in parallel and wait for results
search_results = await asyncio.gather(*search_tasks)
单独一个sub_query检索出来的段落为retrieved_results。
将当前的sub_query和所有sub_query拼在一起,让大模型判断返回段落是否问题有关。
代码如下:
for retrieved_result in retrieved_results:
chat_response = llm.chat(
messages=[
{
"role": "user",
"content": RERANK_PROMPT.format(
query=[col_query] + sub_queries,
retrieved_chunk=retrieved_result.text,
),
}
]
)
Prompt如下:
Based on the query questions and the retrieved chunk, to determine whether the chunk is helpful in answering any of the query question, you can only return "YES" or "NO", without any other information.
Query Questions: {query}
Retrieved Chunk: {retrieved_chunk}
Is the chunk helpful in answering the any of the questions?
仅保存模型返回为”YES“的段落。
采用异步的方式得到所有sub_query返回出来的段落**search_results **。
generate_gap_queries函数为判断是否需要额外的查询,original_query为原始问题,all_sub_queries为分解后的子问题,all_search_res为子问题返回的段落。
sub_gap_queries, consumed_token = generate_gap_queries(
original_query, all_sub_queries, all_search_res
)
Prompt如下:
"""Determine whether additional search queries are needed based on the original query, previous sub queries, and all retrieved document chunks. If further research is required, provide a Python list of up to 3 search queries. If no further research is required, return an empty list.
If the original query is to write a report, then you prefer to generate some further queries, instead return an empty list.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
footer = """Respond exclusively in valid List of str format without any other text."""
sub_gap_queries为大模型生成新一轮的查询,新的查询在进行search_chunks_from_vectordb查找相关段落。最多进行n迭代。
generate_final_answer生成回答
输入原始问题,子问题和相关段落,大模型生成答案。
prompt如下:
"""You are a AI content analysis expert, good at summarizing content. Please summarize a specific and detailed answer or report based on the previous queries and the retrieved document chunks.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
总结
结合deepseek r1推理模型,在问题拆解和判断是否需要额外的查询这两个任务中利用强推理模型返回结果。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)