deepseek本地化部署,python调用api访问deepseek
本地化部署deepseek,python自动化调用
·
deepseek本地化部署
ollama下载地址: ollama下载
deepseekr1 模型下载: 模型下载
安装的时候下一步就行 不展示安装过程
安装完成后桌面右下角会有图标
打开命令提示符输入 ollama --version
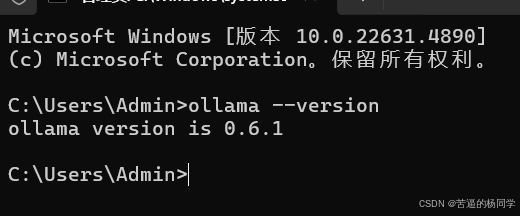
输出版本号就表示安装成功
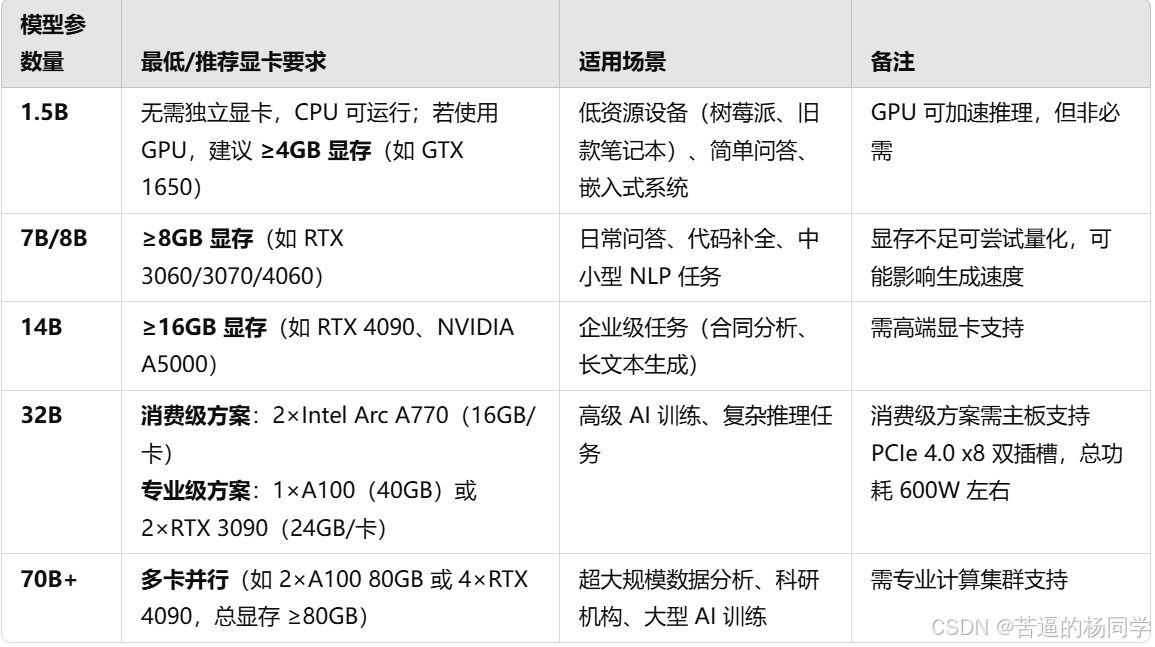
至于模型选择可以按照自己的使用需求和显卡配置来选择合适的,下面列出各种模型所需显卡要求以供大家参考:
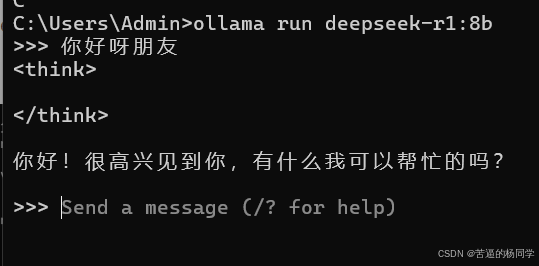
执行代码 ollama run deepseek-r1:7b 即可开始下载模型,如果已经下载过模型,执行该命令则会执行模型,就可以开始使用了。

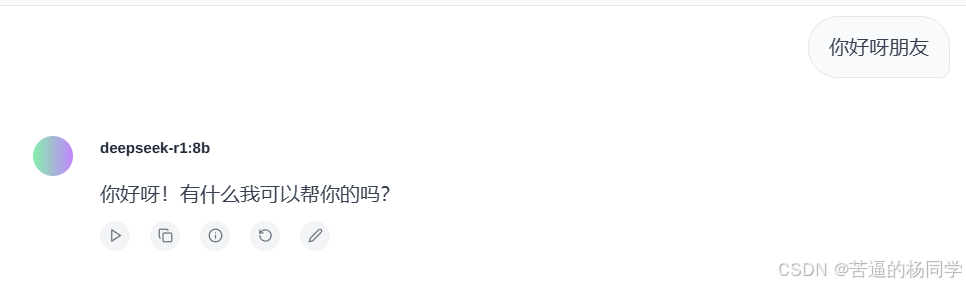
使用界面如下:
谷歌浏览器安装Page Assist
在谷歌商店搜索Page Assist或者通过其他途径安装即可,这里不做展示,安装完成后在扩展程序里打开即可。
在输入框里面输入内容即可开始使用。
使用python代码调用ollama接口使用deepseek
OLLAMA_URL = "http://localhost:11434/api/generate"
# 请求体
def use(word):
payload = {
"model": "deepseek-r1:8b", # 模型名称
"prompt": word, # 输入文本
"stream": True, # 启用流式输出
"max_tokens": 500, # 最大生成长度
"temperature": 0.7, # 温度参数
}
# 发送 POST 请求,启用流式响应
response = requests.post(OLLAMA_URL, json=payload, stream=True)
# 检查响应状态码
if response.status_code == 200:
print("开始生成文本...\n")
# 逐块处理流式响应
for chunk in response.iter_lines():
if chunk:
# 解析 JSON 数据
data = json.loads(chunk.decode("utf-8"))
# 获取生成的文本片段
generated_text = data.get("response", "")
# 实时打印到控制台
print(generated_text, end="", flush=True)
print("\n\n生成完成!")
else:
print("请求失败,状态码:", response.status_code)
print("错误信息:", response.text)
“stream”: True 这里表示是否使用流输出,即是否显示思考模型推理的过程。


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)