
DeepSeek-R1私有化部署——DeepSeek-R1模型微调原理与代码实现
在微调大语言模型(LLM)的过程中,开发者常常会面临一系列技术挑战。显存不足?如果显存资源有限,可以采用 LoRA(低秩适配)技术结合 4-bit 量化,显著降低显存占用,同时保持模型性能。此外,云端训练也是一个不错的选择,借助强大的云服务资源,可以轻松应对大规模模型的训练需求。数据集太小?当数据集规模较小时,模型容易出现过拟合现象,导致无法泛化到新的数据。此时,可以运用数据增强技术,如同义词替换
概述
随着大语言模型(LLM)技术的不断发展,从大型企业到个人开发者都在积极探索如何利用其强大的能力构建各类应用。然而,在实际业务场景中,当面临具有垂直领域和专业知识要求的任务时,预训练的 LLM 往往难以达到预期的性能水平。此时,如何针对性地改善特定场景下 LLM 的表现,成为亟待解决的关键问题。目前,优化 LLM 的重要方案主要有两种:微调(Fine-Tuning)和检索增强生成(Retrieval-Augmented Generation,RAG)。
既然微调和 RAG 都是当前优化 LLM 的重要技术,那么在实际应用中,我们该如何进行选择呢?虽然之前已经探讨过这两种方案的差异,但在结合具体产品需求进行落地时,仍然会遇到一些问题。
微调(Fine-Tuning)
微调是一种通过对预训练模型进行进一步训练以适应特定任务或领域的方法。其核心在于冻结预训练模型的大部分参数,仅对少量参数进行更新,从而在特定领域实现更好的性能。例如,LoRA(Low-Rank Adaptation)是一种高效的微调技术,通过在 Transformer 架构的每一层中注入可训练的低秩分解矩阵,大幅减少了下游任务的可训练参数数量。这种方法在资源有限的情况下尤为有效,因为它可以显著降低计算资源的需求。
微调的优势在于其能够对模型进行深度定制,使其更好地适应特定领域的语言风格和任务需求。然而,微调也存在一些局限性,例如需要大量的标注数据,并且可能会导致模型在其他领域的性能下降。
检索增强生成(RAG)
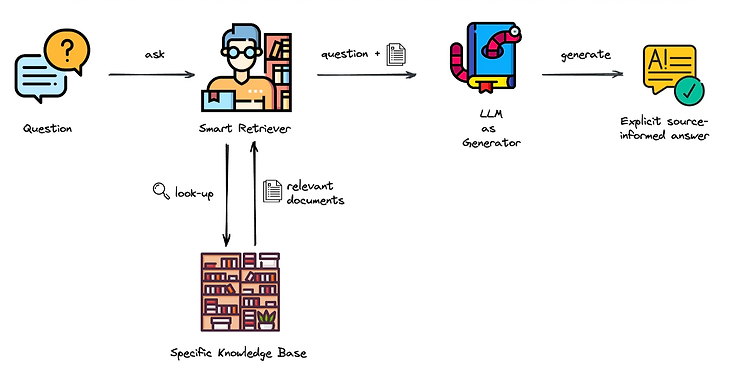
RAG 是一种结合了信息检索技术和语言生成模型的技术。它通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给 LLM,从而增强模型处理知识密集型任务的能力。RAG 的工作流程主要包括以下几个步骤:
- 知识准备:收集并转换知识文档为文本数据,进行预处理和索引。
- 嵌入与索引:使用嵌入模型将文本转换为向量,并存储在向量数据库中。
- 查询检索:将用户查询转换为向量,从数据库中检索相关知识。
- 提示增强:结合检索结果构建增强提示模板。
- 生成回答:LLM 根据增强后的提示生成准确回答。
RAG 的优势在于其能够快速适应新的数据和知识,而无需对整个模型进行重新训练。此外,RAG 还可以有效解决 LLM 的幻觉问题,因为它能够从外部知识库中检索到准确的信息。然而,RAG 也存在一些局限性,例如对知识库的大小和检索效率有较高要求。
选择微调还是 RAG?
在选择微调和 RAG 时,需要根据具体的业务场景和需求进行权衡。以下是一些关键的考虑因素:
- 数据量和资源限制:如果数据量较小且计算资源有限,微调可能是更好的选择,因为它可以显著减少计算资源的需求。然而,如果数据量较大且需要快速适应新的知识,RAG 则可能更适合。
- 任务类型:对于需要深度定制的任务,微调可以提供更好的性能。而对于需要快速检索和生成准确信息的任务,RAG 则更具优势。
- 知识更新频率:如果知识更新频繁,RAG 可以更灵活地适应新的知识。而微调则需要重新训练模型,这可能需要更多的时间和资源。
微调和 RAG 都是优化 LLM 的重要技术,但它们各有优缺点。在实际应用中,需要根据具体的业务场景和需求进行选择。对于资源有限且需要深度定制的任务,微调可能是更好的选择;而对于数据量较大且需要快速适应新知识的任务,RAG 则更具优势。只有结合实际场景来理解这两种技术的差异,才能真正实现 LLM 的优化。
| 特征 | RAG | 微调/长上下文窗口 |
|---|---|---|
| 成本 | 最低,无需训练 | 高,需要广泛的训练和更新 |
| 数据时效性 | 按需检索数据,确保实时性 | 数据可能很快过时 |
| 透明度 | 高,显示检索到的文档 | 低,不清楚数据如何影响结果 |
| 可扩展性 | 高,与各种数据源轻松集成 | 有限,扩展需要大量资源 |
| 性能 | 选择性数据检索提高性能 | 性能可能随着上下文大小的增加而下降 |
| 适应性 | 可根据特定任务进行定制而无需重新训练 | 需要重新训练进行重大调整 |
一、模型微调
1.1 微调重要性
微调是让通用大模型适应特定任务、行业或数据集的关键步骤。以下是微调的重要性:
-
让模型更懂你的行业
预训练模型虽然知识面广,但大多是通识性内容。如果你需要它专精于某个领域,比如医疗、金融或法律,微调就是给它“补专业课”的过程。 -
提升准确率
通用模型可能对某些专业术语或特殊表达方式不够敏感,而微调能让它学会特定领域的语言风格,从而回答得更加准确。 -
让模型更擅长具体任务
大模型虽然功能强大,但默认情况下是“啥都会一点,啥都不精”。如果你想让它更擅长聊天机器人、文档摘要或问答系统等具体任务,微调是必经之路。 -
减少偏见
预训练数据可能带有一些固有的偏见,而通过微调,你可以用更符合需求的数据调整模型,让它的回答更加客观、公正。
总之,微调就像是让模型接受专业训练,使其在特定场景下表现得更聪明、更可靠。对于开发者来说,这不仅能提升模型的实用性,还能让 AI 更符合你的业务需求。
1.2 微调是如何工作
微调的核心是使用特定任务的标注数据来训练模型,使其学会如何更准确地回答问题。以下是微调的主要流程:
1.2.1 主要流程
- 输入(X):模型接收的文本数据,比如一句话、一个问题或一篇文章。
- 目标(Y):根据标注数据给出的正确答案,比如情感分类标签或聊天机器人的回复。
- 损失函数:衡量模型预测结果与正确答案的差距。最常用的损失函数是交叉熵损失(Cross-Entropy Loss),其公式为:
L = − ∑ i y i log ( y ^ i ) \mathcal{L} = -\sum_{i} y_i \log(\hat{y}_i) L=−i∑yilog(y^i)
其中, y i y_i yi 是真实标签, y ^ i \hat{y}_i y^i 是模型预测的概率。
1.2.2 举个例子
假设我们在 IMDB 电影评论数据集上进行微调:
- 输入(X):用户的电影评论,比如“电影的视觉效果很棒,但剧情有点薄弱。”
- 目标(Y):正确的情感分类,比如“负面”。
如果是文本生成任务,比如问答系统,输入可能是一个问题,目标则是模型应该生成的正确答案。
二、数据分配
在资源有限的设备上对 DeepSeek LLM 这样的大模型进行微调时,如果直接使用完整数据集(比如 IMDB 数据集的 25,000 条样本),训练时间会变得非常长,GPU 也可能不堪重负。
为了避免这种情况,我们采取折中方案:
- 挑选一个小部分数据:从 25,000 条中选出 500 条用于训练,100 条用于评估。
- 保证数据的代表性:虽然数据量减少了,但仍然保留了足够的多样性,确保模型能学到核心内容。
这样做的好处是:
- 训练更快,能更快验证效果,避免浪费大量时间和算力。
- 方便实验,让开发者更容易理解和测试微调的概念。
- 如果是生产环境,建议使用更大的数据集,并配备更强的计算资源。
少量数据能让我们快速试验,等模型表现不错后,再上大规模数据正式训练!
四、推荐硬件配置
对 DeepSeek LLM 这样的大语言模型进行微调,对计算资源要求较高。以下是推荐的硬件配置:
| 资源类型 | 推荐配置 |
|---|---|
| GPU | A100 (80GB) 或 4090 (24GB),显存越大越好 |
| CPU | 8 核心以上,多线程跑得快 |
| 内存 | 32GB 以上,大数据集建议 64GB |
| 存储 | 200GB+ SSD,因为大模型需要高速读写 |
如果显存不够怎么办?
- 使用 LoRA(低秩适配):让消费级显卡也能跑微调。
- 用更小的 Batch Size:显存吃紧时,把 Batch Size 设小一点,比如 2 或 4。
- 云端训练:比如 Google Colab Pro+,或者租个 A100 云服务器。
五、准备微调
在微调之前,我们需要先准备好 DeepSeek LLM,让它准备好接受训练。
5.1 安装必要的库
为了让模型顺利运行,先安装几个关键的 Python 依赖:
pip install -U torch transformers datasets accelerate peft bitsandbytes
- torch:深度学习框架 PyTorch,训练模型的核心。
- transformers:Hugging Face 的大模型库,管理 LLM 的神器。
- datasets:加载各类 NLP 数据集,比如 IMDB 影评、金融、医疗等。
- peft:支持 LoRA 微调,让训练更节省资源。
- accelerate:优化大模型训练,提升速度。
- bitsandbytes:8-bit 和 4-bit 量化工具,让大模型更省显存。
安装完成后,环境就搭建好了,可以开始加载模型了。
5.2 用 4-bit 量化加载 DeepSeek LLM
4-bit 量化能让大模型适应显存较小的 GPU,减少内存占用,但仍然保持高性能。其量化公式为:
q
(
x
)
=
round
(
x
−
min
(
x
)
max
(
x
)
−
min
(
x
)
×
(
2
4
−
1
)
)
q(x) = \text{round}\left(\frac{x - \min(x)}{\max(x) - \min(x)} \times (2^4 - 1)\right)
q(x)=round(max(x)−min(x)x−min(x)×(24−1))
其中,
x
x
x 是原始权重,
q
(
x
)
q(x)
q(x) 是量化后的权重。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
import torch
# 选择模型
model_name = "deepseek-ai/deepseek-llm-7b-base"
# 配置 4-bit 量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16 # 用 float16 计算更快
)
# 加载分词器(Tokenizer)和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto" # 自动分配设备
)
# 检查是否成功加载
print("DeepSeek LLM 已成功加载,支持 4-bit 量化!")
5.3 LoRA
LoRA(Low-Rank Adaptation)是一种专门为大语言模型(LLM)设计的微调方法,目标是:
- 减少训练时的显存占用,让大模型在普通显卡上也能跑得动。
- 加速训练,相比传统微调方式,参数量减少了 10 倍以上,但效果基本不变。
- 让微调更灵活,可以随时加载/卸载 LoRA 适配层,不会影响原始模型的能力。
一句话总结:LoRA 可以用小显存训练大模型,而且不会降低效果!
5.4 LoRA 的核心思路
一般来说,微调大模型需要调整模型的大量参数,导致显存占用飙升。而 LoRA 采用了更聪明的方式:
- 冻结原始模型的大部分参数,只训练一小部分。
- 在关键层(比如注意力层 Attention)引入低秩矩阵,用更少的参数来近似建模。其公式为:
W = W 0 + ( A × B ) W = W_0 + (A \times B) W=W0+(A×B)
其中,(W) 是原始权重,(W_0) 是冻结的权重,(A) 和 (B) 是低秩矩阵。 - 只训练 LoRA 适配层,而不动原始模型,这样可以节省大量显存。
举个例子:传统微调 = 重新装修整套房子,又贵又费时。LoRA 微调 = 只换几件家具,成本低,但效果一样好!
5.5 给 DeepSeek LLM 加上 LoRA
# 配置 LoRA 参数
lora_config = LoraConfig(
r=8, # 低秩矩阵的维度,越小越省显存
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 只在注意力层(Attention)里应用 LoRA
lora_dropout=0.05,
bias="none"
)
# 把 LoRA 套在模型上
model = get_peft_model(model, lora_config)
# 检查可训练的参数
model.print_trainable_parameters()
print("LoRA 适配完成,模型已准备好微调!")
5.6 加载 Hugging Face 数据集(IMDB 影评)
如果想训练情感分类模型,IMDB 影评数据集是个不错的选择。
from datasets import load_dataset
# 直接从 Hugging Face 加载数据
dataset = load_dataset("imdb")
print("IMDB 数据集加载完成!")
5.7 预处理数据
模型只能理解数字,所以需要把文本转换成 Token(标记):
def tokenize_function(examples):
inputs = tokenizer(
examples["text"],
truncation=True, # 截断超长文本
padding="max_length", # 统一长度
max_length=512
)
inputs["labels"] = inputs["input_ids"].copy() # 训练目标是输入本身
return inputs
# 批量 Token 化
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 取一小部分数据,避免训练时间过长
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(500))
small_test_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(100))
# 打印一个样本,看看处理后的数据长啥样
print("预处理完成,看看样本:")
print(small_train_dataset[0])
六、微调 DeepSeek
6.1 设置训练参数
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results", # 训练结果保存目录
evaluation_strategy="epoch", # 每个 epoch 评估一次
learning_rate=3e-4, # LoRA 适用的低学习率
per_device_train_batch_size=1, # Batch Size 设小,减少显存占用
gradient_accumulation_steps=8, # 通过梯度累积模拟大 Batch
num_train_epochs=0.5, # 训练 0.5 轮,快速测试
weight_decay=0.01,
save_strategy="epoch", # 每个 epoch 保存一次
logging_dir="./logs",
logging_steps=50,
fp16=True, # 使用混合精度(FP16),提高训练效率
)
6.2 初始化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_test_dataset,
)
print("Trainer 已初始化!")
6.3 开始微调
print("开始微调 DeepSeek LLM...")
trainer.train()
6.4 保存微调后的模型
trainer.save_model("./fine_tuned_deepseek")
tokenizer.save_pretrained("./fine_tuned_deepseek")
print("微调完成,模型已保存!")
七、微调大模型的常见挑战及应对方法
微调大语言模型(LLM)并非易事,过程中会遇到不少挑战。以下是常见的 5 个挑战及应对方法:
7.1 计算资源有限
挑战:
- 训练大模型需要高端 GPU,显存和内存占用都很高。
- 普通消费级显卡很难支撑完整的微调过程。
解决方案:
- 使用 LoRA 和 4-bit 量化,减少计算负担,让 RTX 4090 或 Colab 也能跑微调。
- 云端训练:如果本地显卡不够,可以使用 Google Colab Pro+、AWS、TPU 等云服务。
- 将部分计算任务 Offload 到 CPU,减少 GPU 负载。
7.2 过拟合
挑战:
- 训练数据太少,导致模型死记硬背,无法泛化到新数据。
- 微调后,模型可能只能应对特定场景,而无法适应类似任务。
解决方案:
- 数据增强(Data Augmentation):增加数据的多样性,比如换个说法、同义词替换、添加噪声等。
- 正则化方法(Regularization):使用 Dropout、Early Stopping,防止模型过度拟合。Dropout 的公式为:
Dropout ( x ) = { 0 with probability p x 1 − p with probability 1 − p \text{Dropout}(x) = \begin{cases} 0 & \text{with probability } p \\ \frac{x}{1 - p} & \text{with probability } 1 - p \end{cases} Dropout(x)={01−pxwith probability pwith probability 1−p - 使用更多通用数据,混合特定领域数据和通用数据,让模型保持泛化能力。
7.3 训练时间太长
挑战:
- 训练动辄几天甚至几周,算力消耗巨大。
- 每次改超参数都要重新训练,调优过程太慢。
解决方案:
- 使用 Gradient Checkpointing,减少显存占用,让更大的模型跑得动。
- LoRA 低秩微调,比完整微调快 5-10 倍,但效果接近。
- 减少 Epoch 数,先用少量 Epoch 进行快速测试,确保方向正确再长时间训练。
7.4 灾难性遗忘(Catastrophic Forgetting)
挑战:
- 微调后,模型可能忘记之前学过的通用知识,导致整体能力下降。
- 例如,一个本来会讲笑话的 AI,微调成医疗助手后就不会聊天了。
解决方案:
- 混合训练数据:在微调时,加入一部分原始预训练数据,保持模型的通用能力。
- Continual Learning(持续学习):分阶段微调,而不是一次性全部调整。
- 使用 Adapter(适配器)方法,让模型可以切换不同的任务,而不影响原始模型。
7.5 微调后的模型可能存在偏见
挑战:
- 微调过程中,模型可能继承数据集中的偏见,导致输出结果不公平、不客观。
- 例如,使用偏向某一性别或地域的数据,可能会让 AI 产生偏颇的回答。
解决方案:
- 数据去偏(Debiasing):确保训练数据多样化,避免单一视角的数据。
- 公平性评估(Fairness Metrics):用公平性测试工具检查模型的输出,发现偏见。
- 对抗性训练(Adversarial Training):让模型学会识别并修正潜在偏见。
八、总结
在微调大语言模型(LLM)的过程中,开发者常常会面临一系列技术挑战。以下是一些常见问题及其针对性的解决方案:
-
显存不足?
如果显存资源有限,可以采用 LoRA(低秩适配)技术结合 4-bit 量化,显著降低显存占用,同时保持模型性能。此外,云端训练也是一个不错的选择,借助强大的云服务资源,可以轻松应对大规模模型的训练需求。 -
数据集太小?
当数据集规模较小时,模型容易出现过拟合现象,导致无法泛化到新的数据。此时,可以运用数据增强技术,如同义词替换、句子重组等,增加数据的多样性。同时,引入正则化方法(如 Dropout)能够有效避免模型死记硬背,提升其泛化能力。 -
训练时间太长?
长时间的训练不仅消耗大量计算资源,还会拖慢开发进度。采用 Gradient Checkpointing 技术可以减少显存占用,从而支持更大的模型和更长的训练时间。结合 LoRA 微调,进一步加速训练过程,使模型在短时间内达到较好的性能。 -
模型忘记通用知识?
在微调过程中,模型可能会遗忘一些预训练阶段学到的通用知识,影响其在其他任务上的表现。通过混合训练数据,将特定领域的数据与通用数据相结合,可以让模型在学习特定知识的同时,保持对通用知识的记忆。 -
微调后模型带偏见?
如果微调后的模型存在偏见,可能会导致不公平或不客观的结果。在训练数据阶段进行去偏处理,确保数据来源的多样性和平衡性。同时,运用公平性评估工具对模型输出进行检测,及时发现并修正潜在的偏见。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)