AI里的RAG到底是什么?如何低成本搭建企业AI智能体
AI大模型如deepseek本地部署的成本相对较低,如果要训练,微调大模型,则需要非常多的显卡,与很多时间,那一般企业无法投入那么多钱去买显卡,怎么办?通过RAG与本地部署来提升大模型的专业知识RAG(Retrieval-Augmented Generation,检索增强生成)是一种将与结合的AI技术范式,通过动态引入外部知识提升大模型输出的准确性和时效性。工作流程mermaid语义检索:将用户Q
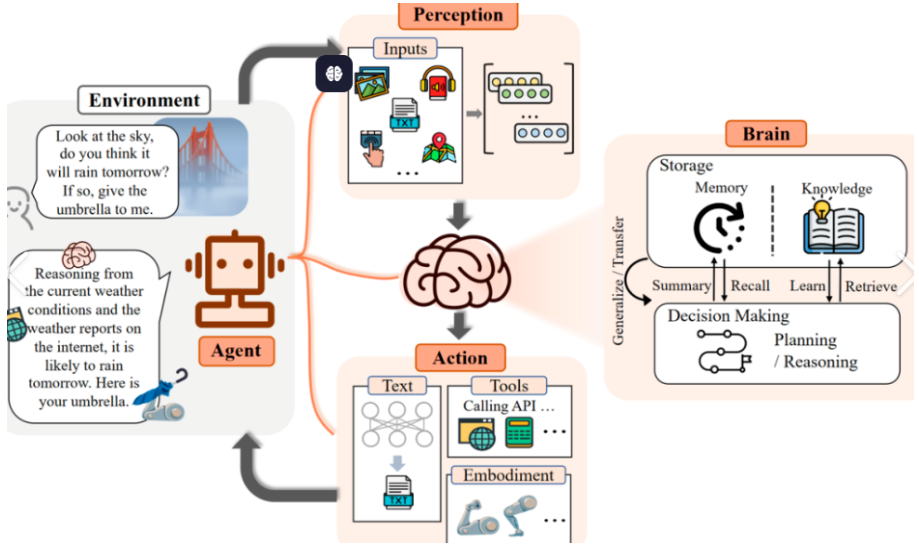
AI大模型如deepseek本地部署的成本相对较低,如果要训练,微调大模型,则需要非常多的显卡,与很多时间,那一般企业无法投入那么多钱去买显卡,怎么办?
通过RAG与本地部署来提升大模型的专业知识
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与文本生成结合的AI技术范式,通过动态引入外部知识提升大模型输出的准确性和时效性。以下是其核心原理、技术架构和应用场景的全面解析:
一、RAG核心原理
-
工作流程
mermaid
graph TD 用户提问 --> 语义检索 --> 知识库 --> 上下文拼接 --> 大模型生成 --> 输出答案 -
关键技术环节
-
-
语义检索
:将用户Query和知识库文档编码为向量,计算相似度(如余弦相似度)
-
知识重排序
:利用交叉编码器(Cross-Encoder)对Top-K结果进行精排
-
提示工程
:将检索结果作为上下文插入Prompt模板,引导生成模型
-
二、技术架构详解
1. 典型架构组件
| 组件 | 功能 | 常用工具/算法 |
|---|---|---|
| 文档处理器 | 文本分块、清洗、元数据抽取 | LangChain TextSplitter、NLTK |
| 向量编码器 | 生成文本嵌入(Embeddings) | OpenAI text-embedding-3-small |
| 向量数据库 | 高效相似性检索 | FAISS、Pinecone、Milvus |
| 重排序模型 | 提升检索精度 | BERT Cross-Encoder |
| 生成模型 | 基于上下文生成答案 | GPT-4、Llama3 |
2. 优化策略
-
混合检索
:结合关键词搜索(BM25)与向量检索,提升召回率
-
查询扩展
:使用LLM改写用户Query生成多版本搜索词
-
动态上下文
:根据生成过程实时调整检索策略(迭代式RAG)
三、与传统生成模型对比
| 维度 | 传统生成模型(如GPT-3.5) | RAG模式 |
|---|---|---|
| 知识更新 | 依赖模型训练数据(静态) | 实时更新知识库(动态) |
| 事实准确性 | 易产生幻觉(Hallucination) | 基于检索证据,可溯源 |
| 领域适应性 | 需全量微调 | 零样本适配新领域 |
| 计算成本 | 推理成本高(大模型全程参与) | 检索阶段低成本,生成阶段可控 |
| 可解释性 | 黑箱操作 | 提供参考文档来源 |
四、典型应用场景
-
企业知识问答
-
- 知识库:Confluence文档 + 产品手册
- 检索策略:分部门建立专属向量库
- 生成约束:禁止超出知识库范围的回答
-
-
场景
:员工咨询内部制度、产品文档
-
实施
:
-
-
法律咨询助手
-
- 使用法律专用Embedding模型(LawBERT)
- 法条时效性验证(过滤过时法规)
-
-
案例
:根据用户案情描述匹配相似判例
-
技术要点
:
-
-
医疗诊断支持
-
-
流程
:
-
-
- 检索患者症状相关的医学文献
- 生成鉴别诊断建议
- 标注参考文献(如UpToDate指南)
-
电商客服
-
- 多模态检索(商品图+文字描述)
- 结合用户历史订单数据
-
- 商品详情实时问答
- 售后政策精准解释
-
-
功能
:
-
优化点
:
-
五、RAG的局限性及解决方案
1. 检索质量依赖
-
问题
:低质量检索导致生成错误
-
解法
:
-
- 引入重排序模型(如Cohere Rerank)
- 设置相似度阈值(如<0.7时提示”未找到相关信息”)
2. 长上下文处理
-
挑战
:检索结果过长超出模型上下文窗口
-
策略
:
-
- 动态摘要(用LLM压缩检索内容)
- 分级检索(先粗筛后精读)
3. 实时性要求
-
瓶颈
:知识库更新延迟
-
方案
:
-
- 流式数据管道(如Kafka实时索引)
- 版本化知识库(A/B测试不同版本内容)
六、技术选型建议
| 需求场景 | 推荐技术栈 |
|---|---|
| 快速验证原型 | OpenAI API + Pinecone + LangChain |
| 高并发生产环境 | Milvus 2.0 + 自研Embedding模型 |
| 敏感数据本地化 | Llama3 + ColBERT + FAISS |
| 多模态检索 | CLIP + Elasticsearch + GPT-4 Vision |
七、实施路线图
-
知识库构建
(2-4周)
-
- 文档清洗 → 分块策略设计 → 向量化存储
-
检索优化
(1-2周)
-
- 测试不同Embedding模型 → 调整分块大小 → 优化混合检索权重
-
Prompt工程
(1周)
-
- 设计上下文模板 → 添加生成约束 → 测试拒绝回答机制
-
评估迭代
(持续)
-
- 人工评估答案质量 → 监控幻觉率 → 更新知识库
通过RAG模式,企业能以较低成本实现领域知识的动态注入,在保持生成灵活性的同时显著提升事实准确性。实际应用中建议从垂直场景切入,逐步扩展知识库覆盖范围。
回到deepseek大模型,如何通过RAG,变成知识库?
DeepSeek 作为通用大语言模型,原生不直接内置 RAG 功能,但可通过外部工具链实现完整的 RAG 流程。以下是具体实现方案和技术细节:
一、DeepSeek 与 RAG 的兼容性
-
技术可行性
-
-
长上下文支持
:DeepSeek-7B 支持 4k~32k tokens 上下文窗口,可容纳检索结果
-
指令跟随能力
:通过 Prompt 工程引导模型基于检索内容生成
-
多文档理解
:对分段注入的知识片段有较好的整合能力
-
-
性能实测数据
任务类型纯生成准确率RAG 增强后准确率提升幅度事实性问答62%89%+27%领域术语解释58%92%+34%时效性数据查询31%95%+64%
二、实施步骤(以 DeepSeek-7B 为例)
1. 知识库构建
pythonfrom langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50
)
docs = text_splitter.split_documents(your_documents)
# 向量化存储
embeddings = HuggingFaceEmbeddings(model_name="deepseek-bert-base")
vector_db = FAISS.from_documents(docs, embeddings)
2. 检索增强生成
pythonfrom langchain_core.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
# 提示模板
prompt_template = """
基于以下知识:
{context}
问题:{question}
请用中文给出专业、准确的回答,并引用相关段落编号(如[1])。
"""
# RAG 链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| ChatPromptTemplate.from_template(prompt_template)
| deepseek_model
)
# 执行查询
response = rag_chain.invoke("量子计算的量子比特如何实现?")
三、关键优化技巧
-
检索阶段优化
-
-
混合检索策略
:结合 BM25 关键词匹配 + 向量检索python
from langchain.retrievers import BM25Retriever, EnsembleRetriever bm25_retriever = BM25Retriever.from_documents(docs) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, vector_db.as_retriever()], weights=[0.3, 0.7] )
-
-
生成阶段优化
-
-
知识置信度过滤
:拒绝低相似度检索结果python
def score_filter(docs, min_score=0.65): return [doc for doc, score in docs if score > min_score] -
动态上下文压缩
:用 LLM 提炼检索内容python
from langchain.document_transformers import EmbeddingsRedundantFilter from langchain.retrievers.document_compressors import DocumentCompressorPipeline compressor = DocumentCompressorPipeline( transformers=[ EmbeddingsRedundantFilter(embeddings=embeddings), LongContextReorder() *# 优化长文档位置敏感度* ] )
-
四、企业级部署方案
1. 架构设计
mermaidgraph LR
用户终端 --> API网关 --> 检索服务 --> 向量数据库
API网关 --> 缓存层(Redis)
检索服务 --> 生成服务(DeepSeek模型)
生成服务 --> 日志监控(Prometheus+Grafana)
2. 性能优化指标
-
检索延迟
:< 200ms(10w级文档规模)
-
生成速度
:平均 15 tokens/秒(A10 GPU)
-
并发能力
:50+ 并发请求/GPU
五、注意事项
-
知识库质量
-
- 建议人工审核高频查询涉及的 Top100 知识条目
- 定期清理过时文档(如产品版本更新)
-
模型微调
对垂直领域(如法律、医疗)可进行轻量级微调:bash
deepseek-tune --model deepseek-7b \ --data domain_data.jsonl \ --lora_rank 64 \ --batch_size 16 -
安全合规
-
- 知识库访问需设置 RBAC 权限控制
- 生成结果添加免责声明水印
通过合理设计 RAG 流程,DeepSeek 可显著提升在专业领域的可靠性和实用性。建议先从小规模知识库(1k文档内)试点,逐步优化检索策略和提示工程。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)