DeepSeek与Dify知识库:数据库查询双剑合璧【API与直连教程】
怎么让在个ai应用客户端直接连接数据库查询。dify官方没有现成的组件可以直接用。当时我想的是两种方式,一种是基于代码执行模块直接查询数据库,一种是基于Http请求,调用自己封装接口来查询数据库。
怎么让在个ai应用客户端直接连接数据库查询。dify官方没有现成的组件可以直接用。
当时我想的是两种方式,一种是基于代码执行模块直接查询数据库,一种是基于Http请求,调用自己封装接口来查询数据库。
一、基于接口执行数据库查询
想干这事之前先梳理下流程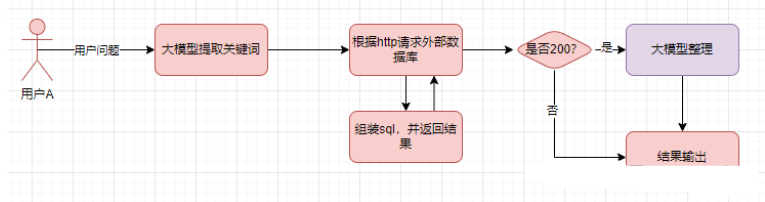
- 用户输入问题,根据用户的问题提出关键词
- 通过http调用外部服务接口,根据关键词查询数据库
- 返回200,调用大模型,将用户问题和知识进行梳理
- 返回其他,直接输出
本地准备
要求:
-
有一个python环境
-
安装pymysq和flask 组件
python -m pip install pymysql flask -
有一个mysql,或其他的数据库,我有mysql直接用了
接口开发
让kimi给我生成一个文章表,并且插入10条数据,我们可以告诉kimi,文章长度多大,这样内容可以丰富些。
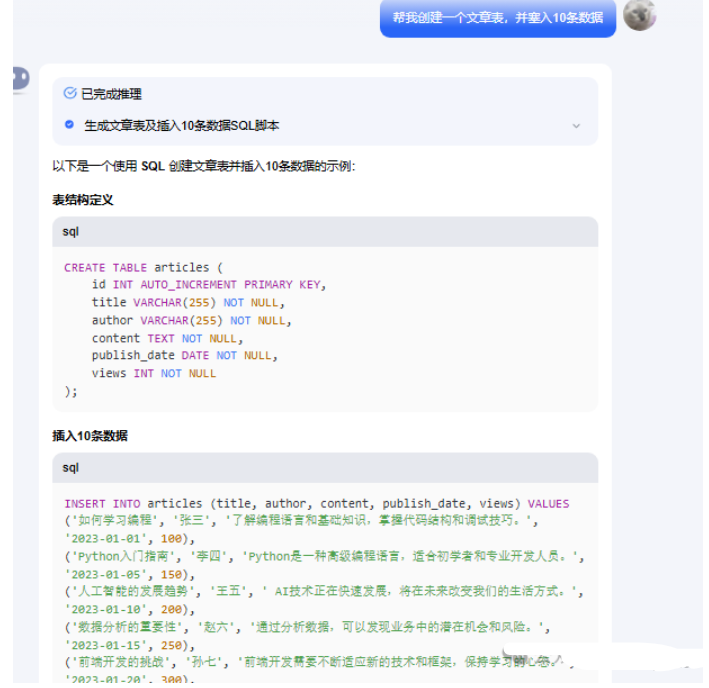
直接让kimi生成一个暴露接口查数据库的服务,有简单的优化了下,将下面的内容放入到server.py文件中
from flask import Flask, request, jsonify
import pymysql
app = Flask(__name__)
# 数据库配置
DATABASE_CONFIG = {
'host': '', # 自己的数据库地址
'user': '', # 自己数据库的账户
'password': '', #自己数据库的密码
'db': 'demo', # 自己数据库的库名
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
@app.route('/query', methods=['POST'])
def query_database():
print("接收到请求")
# 获取关键字
keyword = request.json.get('keyword')
print("keyword为:"+keyword)
ifnot keyword:
return jsonify({"error": "Keyword is required"}), 400
# 参数化查询,避免 SQL 注入,修改成自己的库
query = "SELECT * FROM articles WHERE content LIKE %s"
params = ('%' + keyword + '%',)
try:
# 建立数据库连接
connection = pymysql.connect(**DATABASE_CONFIG)
with connection.cursor() as cursor:
# 执行查询
cursor.execute(query, params)
result = cursor.fetchall()
connection.commit()
connection.close()
ifnot result:
return"未查询到有效数据", 400
# 生成 Markdown 表格
markdown_table = generate_markdown_table(result)
return markdown_table, 200
except Exception as e:
return str(e), 500
def generate_markdown_table(results):
""" 生成 Markdown 表格 """
ifnot results:
return""
# 获取列名
columns = results[0].keys()
# 表头
table_md = "| " + " | ".join([col for col in columns]) + " |\n"
# 分隔线
table_md += "| " + " --- |" * len(columns) + "\n"
# 表格内容
for row in results:
table_md += "| " + " | ".join([str(cell) for cell in row.values()]) + " |\n"
return table_md
if __name__ == '__main__':
# 注意这里绑定本机的内容ip,省事点,就0.0.0.0即可。不要绑定127.0.0.1,docke内访问不到
app.run(host='10.1.0.65', port=8000)
启动服务
python .\server.py
配置工作流

创建一个空白应用。
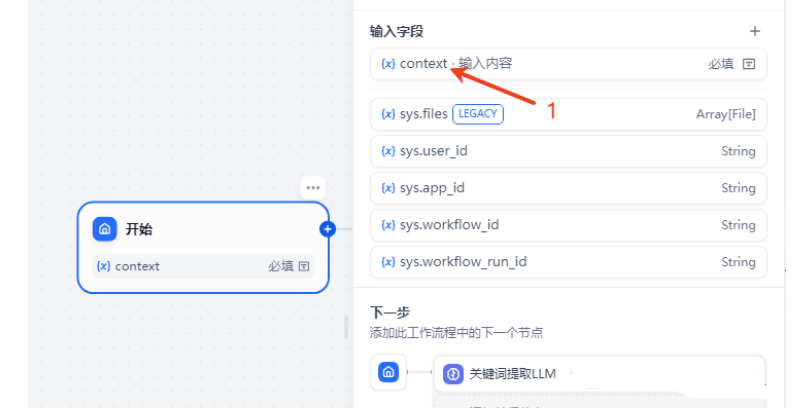
在开始节点添加一个输入字段context
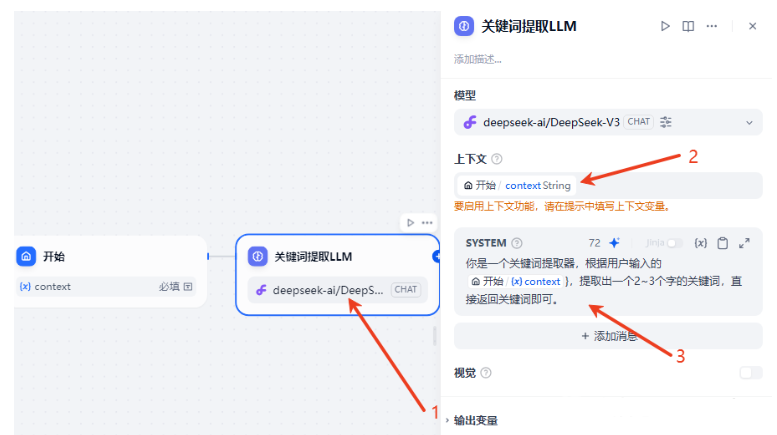
添加一个LLM,把开始节点设置的context字段作为上下文传入,并设置提示词提取关键词。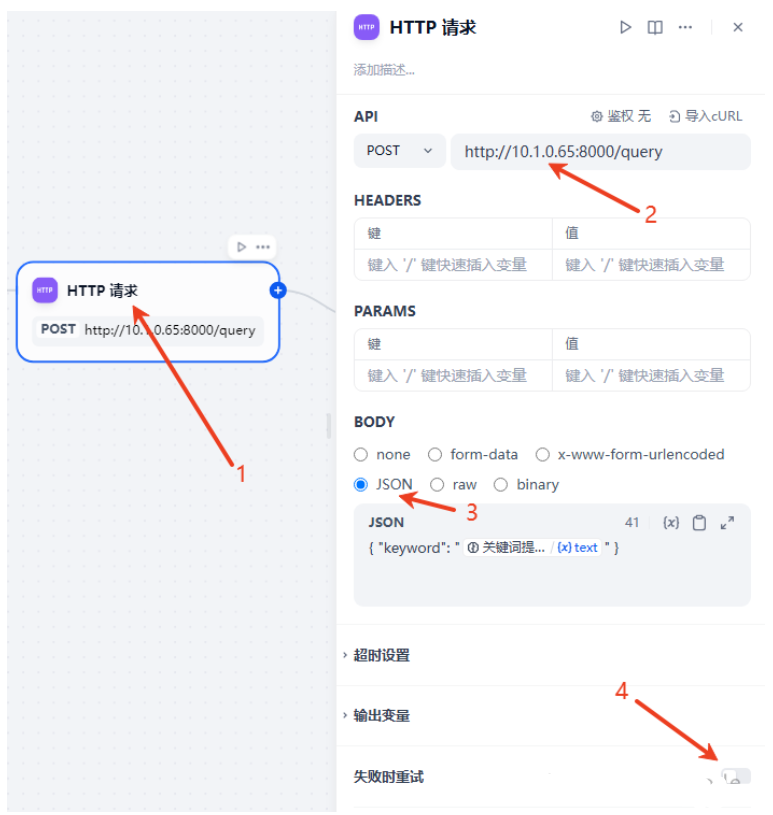
添加一个http请求节点,把我们在接口开发里的地址和接口名填写进去2,然后把大模型的输出作为关键词填写到请求body里3,我们关闭重试机制4。
这里要注意下:json的引号是中文的,最好在外面写好校验过了再放进去。
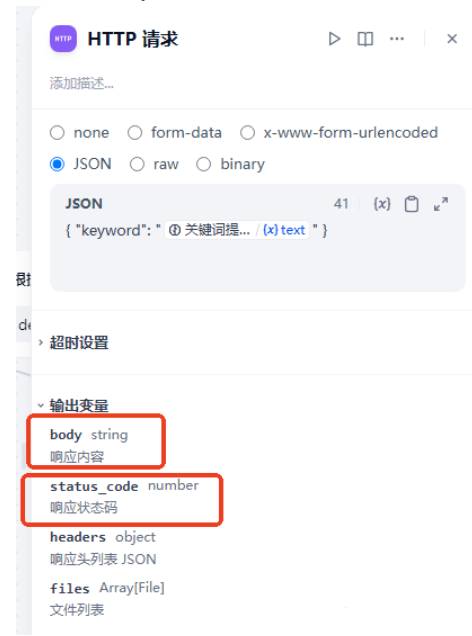
在HTTP请求的输出变量里,我们只关注status_code 响应状态码和响应内容即可。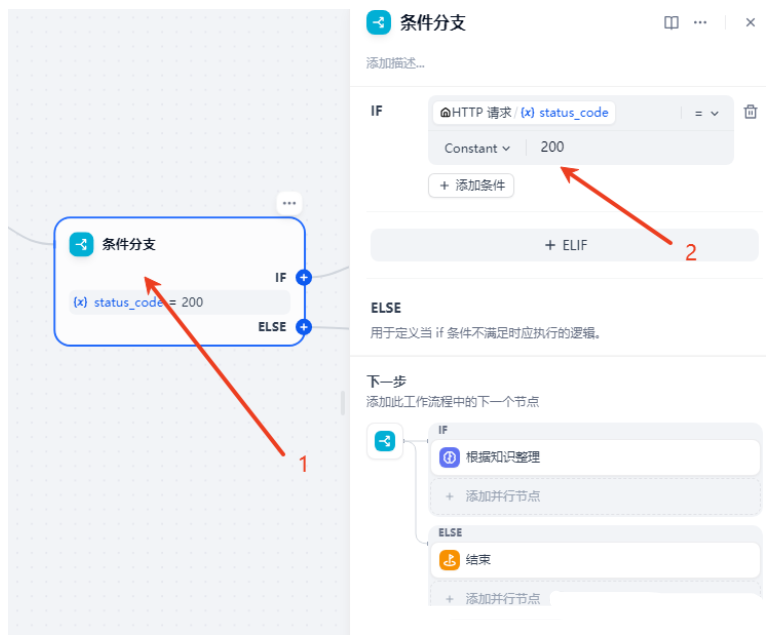
添加一个条件分支1,然后设置HTTP响应码为200的时候,连接到大模型。其他直接结束。
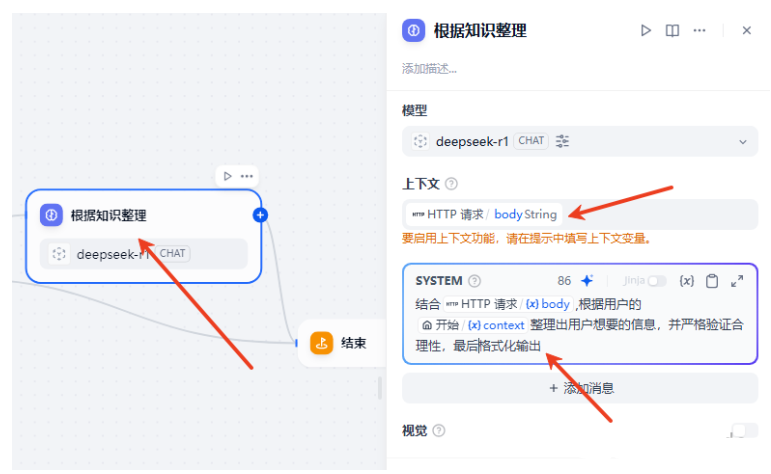
添加大模型,将HTTP请求的响应体作为上下文给大模型,输入提示词,让大模型根据知识,验证,并进行合理性的验证,最后结构化返回。
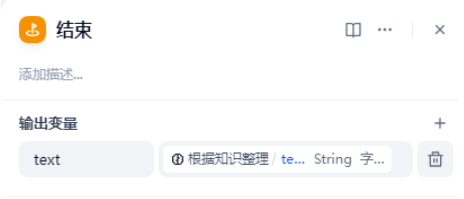
在结束节点中,我们把大模型整理的内容输出。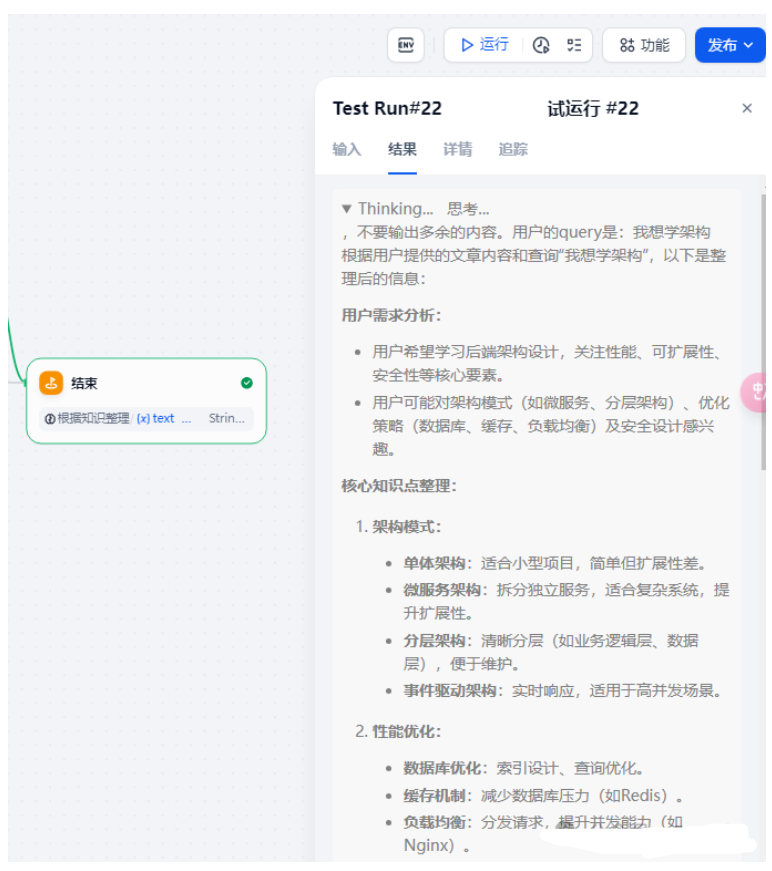
试运行效果。
二、基于代码执行查询数据库

由于difysandbox的安全限制
- 不能访问文件系统
- 不能进行网络请求
- 不能执行操作系统级命令
官方也有了对应的说明,见文档。 https://github.com/langgenius/dify-sandbox/blob/main/FAQ.mdss
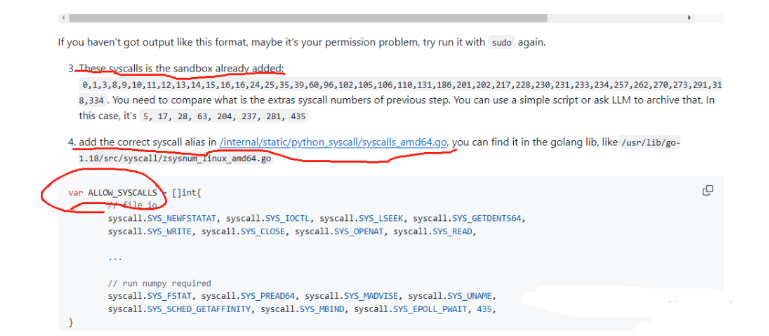
-
官方已经告诉我们沙箱里添加了哪些权限
-
如果我们要添加可以在哪里添加
difysandbox源码修改
一定要使用linux环境、一定要使用linux环境``一定要使用linux环境
我从github上拉下代码以后,搜索``syscalls_amd64.go
一共有4个文件,
-
nodejs的系统调用,有amd和arm平台
-
python的系统,也是有amd和arm平台
我用python,不是arm架构的,镜像都是linux的。
我们直接问kimi即可。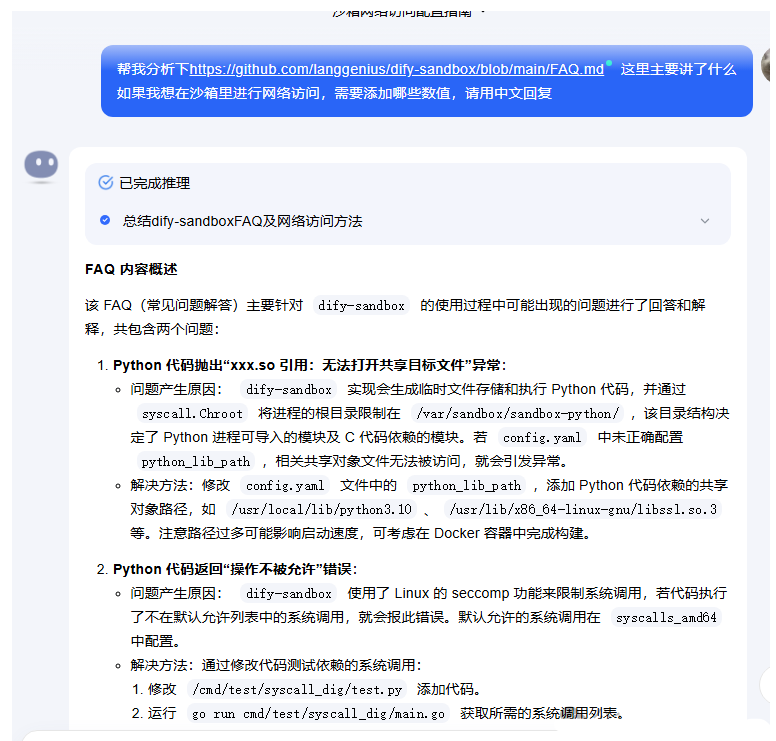
ps:这个问题丢给了ds和chatgpt都是瞎回答
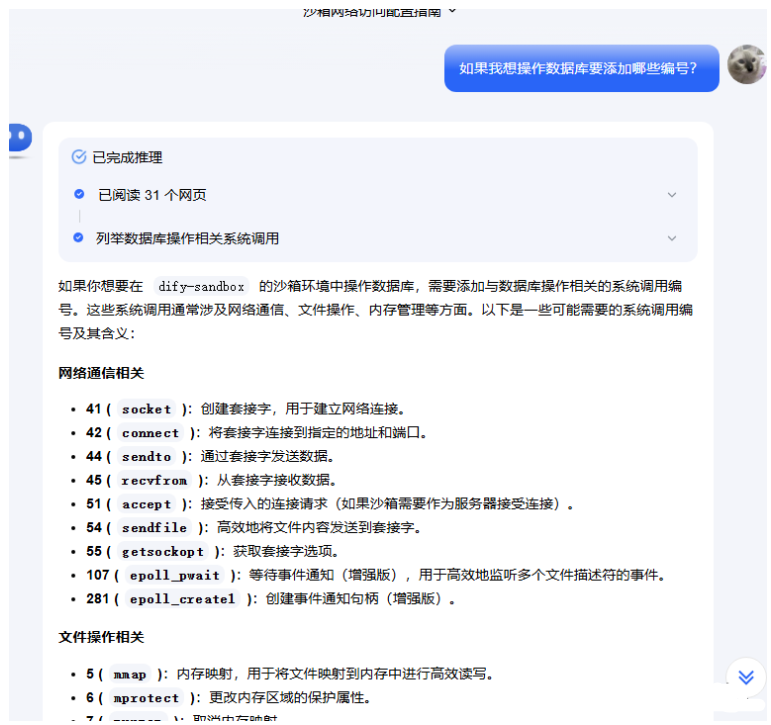
一步步的问kimi,最后告诉我要添加哪些。整理以后添加到代码里。
var ALLOW_SYSCALLS = []int{
// file io
syscall.SYS_NEWFSTATAT, syscall.SYS_IOCTL, syscall.SYS_LSEEK, syscall.SYS_GETDENTS64,
syscall.SYS_WRITE, syscall.SYS_CLOSE, syscall.SYS_OPENAT, syscall.SYS_READ,
// thread
syscall.SYS_FUTEX,
// memory
syscall.SYS_MMAP, syscall.SYS_BRK, syscall.SYS_MPROTECT, syscall.SYS_MUNMAP, syscall.SYS_RT_SIGRETURN,
syscall.SYS_MREMAP,
// user/group
syscall.SYS_SETUID, syscall.SYS_SETGID, syscall.SYS_GETUID,
// process
syscall.SYS_GETPID, syscall.SYS_GETPPID, syscall.SYS_GETTID,
syscall.SYS_EXIT, syscall.SYS_EXIT_GROUP,
syscall.SYS_TGKILL, syscall.SYS_RT_SIGACTION, syscall.SYS_IOCTL,
syscall.SYS_SCHED_YIELD,
syscall.SYS_SET_ROBUST_LIST, syscall.SYS_GET_ROBUST_LIST, SYS_RSEQ,
// time
syscall.SYS_CLOCK_GETTIME, syscall.SYS_GETTIMEOFDAY, syscall.SYS_NANOSLEEP,
syscall.SYS_EPOLL_CREATE1,
syscall.SYS_EPOLL_CTL, syscall.SYS_CLOCK_NANOSLEEP, syscall.SYS_PSELECT6,
syscall.SYS_TIME,
syscall.SYS_RT_SIGPROCMASK, syscall.SYS_SIGALTSTACK, SYS_GETRANDOM,
//新增
5, 6, 7, 21, 41, 42, 44, 45, 51, 54, 55, 107, 137, 204, 281,
}
预装mysql操作包
既然我们要操作在沙箱里操作mysql,那我们得在对应的环境中预装下mysql客户端。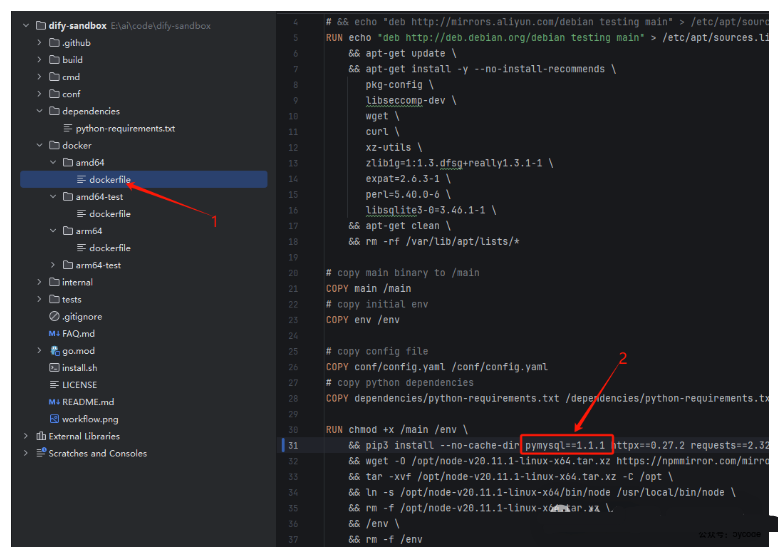
在1对应的文件中添加2对应的pymysql==1.1.1,我直接安装最新版。
在readme中有操作步骤
### Steps
1. Clone the repository using `git clone https://github.com/langgenius/dify-sandbox` and navigate to the project directory.
2. Run ./install.sh to install the necessary dependencies.
3. Run ./build/build_[amd64|arm64].sh to build the sandbox binary.
4. Run ./main to start the server.
编译成功以后,打包镜像。因为我没有环境,直接模拟了下创建了一个main和env目录
然后模拟打包镜像。在根目录中执行下面的命令
docker build -f docker/amd64/dockerfile -t dify-sandbox:local .
我在win上打包报了一堆错,都扔给kimi,一步步的解决。最后成功。

沙箱网咯策略配置
在我们的安装dify的的时候,有个dify/docker/ssrf_proxy目录,找到squid.conf.template
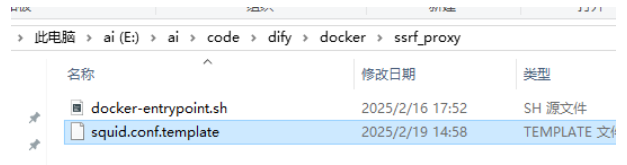
在这里,你可以设置允许访问的网络,允许访问的端口,生产一定要最小权限
acl devnet src 10.1.0.0/24
acl devnet src 10.255.200.0/24
acl Safe_ports port 3306 # MySQL
acl Safe_ports port 5432 # Postgres
acl Safe_ports port 27017 # MongoDB
acl Safe_ports port 6379 # Redis
http_access allow devnet
-
devnet为定义的规则集名称,后面跟自己的ip段设置,表示:10.255.200.1到10.255.200.254-acl Safe_ports port允许访问的端口 -
http_access allow devnet允许访问的规则集
重新部署dify
在dify的的docker目录中修改docker-compose.yaml文件sandbox使用本地镜像。
sandbox:
#image: langgenius/dify-sandbox:0.2.10
image: dify-sandbox:local
restart: always
environment:
将image由langgenius/dify-sandbox:0.2.10 改为了dify-sandbox:local
在docker目录下执行以下命令
# 销毁
docker compose down
# 重新部署
docker compose up -d
脚本
使用kimi生成了一个python代码
import sys
import pymysql
import os
def connect_to_database():
""" 连接到数据库,配置都从环境变量里取 """
try:
# 从环境变量或配置文件中获取数据库参数
host = os.getenv("DB_HOST", "localhost")
user = os.getenv("DB_USER", "root")
password = os.getenv("DB_PASSWORD", "password")
database = os.getenv("DB_NAME", "database_name")
conn = pymysql.connect(
host=host,
user=user,
password=password,
database=database,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor # 使用字典游标
)
return conn
except pymysql.MySQLError as err:
print(f"Error connecting to database: {err}")
returnNone
def execute_query(conn, query, params=None):
""" 执行 SQL 查询,并支持参数化查询 """
cursor = conn.cursor()
try:
if params:
cursor.execute(query, params)
else:
cursor.execute(query)
return cursor.fetchall()
except pymysql.MySQLError as err:
print(f"Error executing query: {err}")
returnNone
finally:
cursor.close()
def generate_markdown_table(results):
""" 生成 Markdown 表格 """
ifnot results:
return""
# 获取列名
columns = results[0].keys()
# 表头
table_md = "| " + " | ".join([col for col in columns]) + " |\n"
# 分隔线
table_md += "| " + " --- |" * len(columns) + "\n"
# 表格内容
for row in results:
table_md += "| " + " | ".join([str(cell) for cell in row.values()]) + " |\n"
return table_md
def main(arg1: str) -> dict:
# 参数化查询,避免 SQL 注入
query = "SELECT * FROM table_name WHERE column LIKE %s"
params = ('%' + arg1 + '%',)
# 连接到数据库
conn = connect_to_database()
ifnot conn:
sys.exit(1)
try:
# 执行查询
result = execute_query(conn, query, params)
if result isNone:
return {"result": [], "markdown": ""}
# 生成 Markdown 表格
markdown_table = generate_markdown_table(result)
return {
"result": result,
"markdown": markdown_table
}
except Exception as e:
print(f"Unexpected error: {e}")
return {"result": [], "markdown": ""}
finally:
# 确保数据库连接关闭
conn.close()
后记
这两种方式,不管哪种都能实现查询数据库,但是有个问题,数据量小的时候性能还行,数据量大了,你查询一次就得耗时好久。
如果知识固定,也可以前置设置一个知识库把关键词和文章映射出来,这样大模型整理的时候,尽量的去往对应的关键词上靠。
三、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 21
21 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)