DeepSeek进阶实战指南:解锁大模型开发的高效范式
OOM问题启用梯度累积(gradient_accumulation_steps=4)使用memory_profiler工具分析显存占用训练震荡。
引言:为什么选择DeepSeek?
在AI大模型开发领域,DeepSeek以其全流程解决方案和国产技术优势崭露头角。本文将深入探讨如何通过DeepSeek实现:
-
10倍速的模型训练效率提升
-
动态资源调度技术降低30%算力成本
-
行业场景的精准适配方法论
一、环境配置与性能优化
1.1 混合精度训练配置
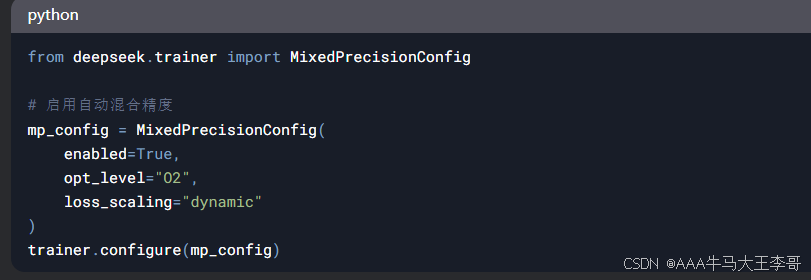
1.2 分布式训练最佳实践

性能对比(A100集群):

二、领域适配核心技术
2.1 金融领域知识注入
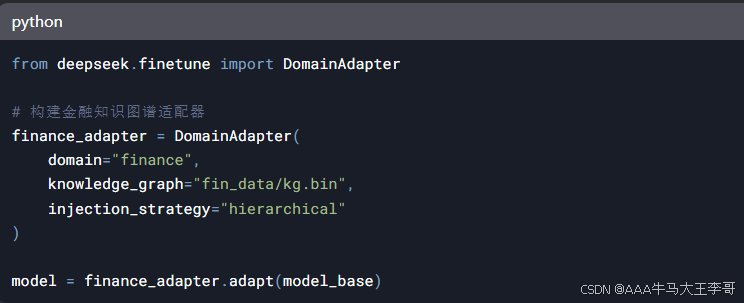
2.2 医疗实体识别优化
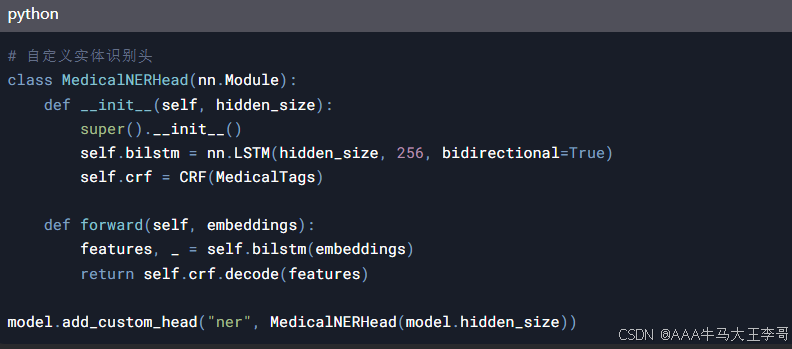
三、生产级部署方案
3.1 量化部署最佳实践
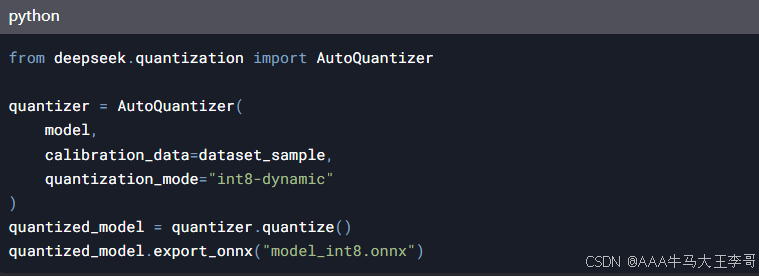
3.2 服务化部署架构

关键指标:
-
动态批处理延迟:<50ms(P99)
-
吞吐量:1200 req/s(A10G实例)
-
冷启动时间:<3s
四、典型场景案例
4.1 智能客服系统优化
问题:传统方案意图识别准确率仅82%
DeepSeek方案:
-
使用DSL(Domain Specific Language)构建业务规则树
-
集成语义检索增强模块
-
动态温度系数调整
结果:
-
准确率提升至94%
-
平均响应时间降至800ms
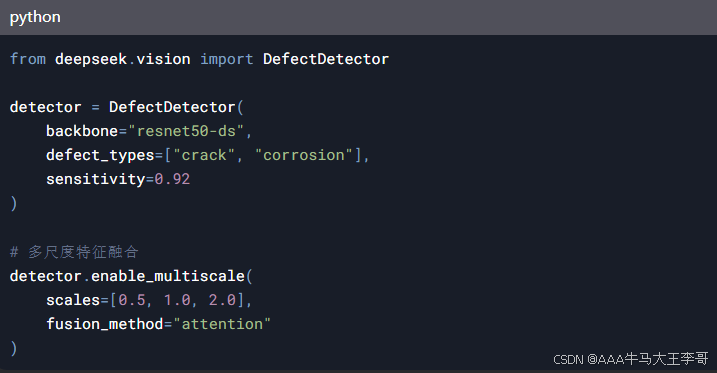
4.2 工业质检系统开发
五、避坑指南
5.1 常见报错解决方案
-
OOM问题:
-
启用梯度累积(gradient_accumulation_steps=4)
-
使用memory_profiler工具分析显存占用
-
-
训练震荡:

5.2 性能调优检查表
-
检查数据流水线是否完全并行化
-
验证混合精度是否实际生效
-
分析通信带宽利用率
-
评估算子融合收益
结语:持续演进的技术生态
DeepSeek近期更新重点:
-
即将支持MoE(Mixture of Experts)架构
-
国产芯片生态扩展(昇腾、寒武纪)
-
AutoML全流程自动化工具发布
-
OOM问题:
-
启用梯度累积(gradient_accumulation_steps=4)
-
使用memory_profiler工具分析显存占用
-
-
训练震荡:
5.2 性能调优检查表
-
检查数据流水线是否完全并行化
-
验证混合精度是否实际生效
-
分析通信带宽利用率
-
评估算子融合收益
-
即将支持MoE(Mixture of Experts)架构
-
国产芯片生态扩展(昇腾、寒武纪)
-
AutoML全流程自动化工具发布

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)