搭建属于自己的AI大模型,DeepSeek-R1-70B本地化部署指南
至此,你已经成功完成了DeepSeek-R1-L70-Preview在本地环境中的部署。性能调优调整批处理大小(batch_size)以提高吞吐量。通过分布式部署(如多机多卡训练)提升服务能力。安全配置配置HTTPS访问,确保数据传输安全。设置权限控制,防止未授权的调用。监控与维护部署监控工具(如Prometheus、Grafana)实时监控服务状态和资源使用情况。定期备份模型文件和配置信息,确保
近年来,随着人工智能技术的快速发展,深度学习模型在自然语言处理领域的应用 ngày càng广泛。为了帮助开发者和企业更好地利用AI技术,DeepSeek推出了R1-L70-Preview版本,该版本不仅性能强劲,还支持本地化部署,为用户提供了更高的灵活性与隐私保障。在这篇文章中,我们将详细介绍如何在本地环境中完成DeepSeek-R1-L70-Preview的下载、部署和调用过程。
一、为什么选择DeepSeek-R1-L70-Preview?
在正式开始部署之前,咱们先来了解一下DeepSeek-R1-L70-Preview的特点以及为什么我们要选择本地化部署:
- 高性能
:作为深度学习领域的杰出模型,R1-L70-Preview具有强大的计算能力和准确率。
- 本地化部署支持
:通过本地化部署,可以避免云服务的依赖,节省成本,并提升数据隐私与安全性。
- 灵活性高
:本地环境可以根据具体需求进行调整和优化,适合企业级应用场景。
如果你的目标是构建一个安全、高效、可控的AI解决方案,那么DeepSeek-R1-L70-Preview无疑是一个理想的选择。
二、本地化部署前的准备工作
在开始部署之前,请确保以下几点已经完成:
-
硬件需求
-
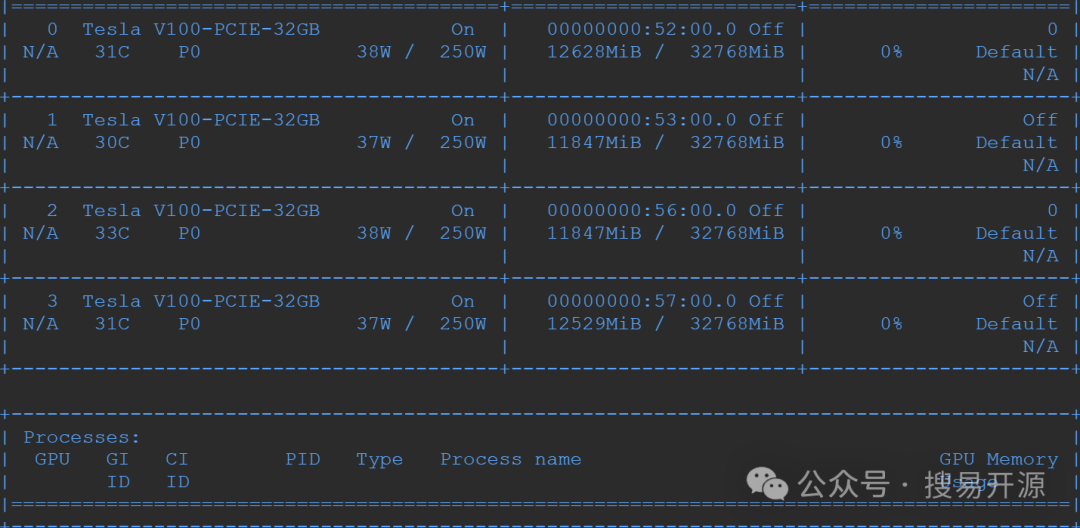
最低配置:4核8线程CPU,16GB内存,1块NVIDIA GPU(>=1080Ti)。
-
推荐配置:16核32线程CPU,128GB内存,≥4块高性能GPU(如A100、V100等)。
-
-
操作系统
-
推荐使用Ubuntu 20.04 或 CentOS 7.x及以上版本。
-
-
软件环境
-
安装Docker:Docker是容器化部署的核心工具,后续步骤中我们将通过Docker完成模型的部署。
-
安装NVIDIA驱动和CUDA toolkit(如有GPU支持)。
-
确保Python 3.8或更高版本已安装。
-
-
网络环境
-
确保服务器或电脑可以访问互联网,用于下载模型文件和依赖包。如果是内网环境,可以提前准备好相关的离线安装包。
-
三、DeepSeek-R1-L70-Preview的下载与准备
接下来,我们将详细介绍如何下载DeepSeek-R1-L70-Preview的模型文件。
步骤1:注册与获取模型
DeepSeek-R1-L70-Preview的模型文件需要在其官网或认证平台下载。以下是具体操作步骤:
-
访问DeepSeek官网(假设为官网地址),并完成注册。
-
登录后,在“资源中心”或“模型市场”中找到R1-L70-Preview模型,点击下载。
-
根据提示获取模型文件,可能需要等待邮件确认或审核。
注意事项:
-
如果是企业用户,可以联系DeepSeek的技术支持获取批量授权。
-
确保网络环境稳定,以免下载过程中出现中断。
步骤2:解压与整理
下载完成后,你将得到一个压缩包(通常为.tar或.zip格式)。接下来需要对其进行解压:
- 使用以下命令将压缩包解压到指定目录:
mkdir -p /path/to/model_dir tar -xvf deepseek-r1-l70-preview.tar -C /path/to/model_dir -
检查解压后的文件结构,通常包括模型权重、配置文件和调用接口。
四、本地化部署的具体步骤
完成下载后,我们需要将DeepSeek-R1-L70-Preview在本地环境中完成部署。以下是详细的操作指南:
步骤1:安装Docker
如果你还没有安装Docker,可以参考以下命令进行安装(以Ubuntu为例):
# 更新包列表
sudoapt update
# 安装必要的依赖包
sudoaptinstall-y apt-transport-https ca-certificates curl software-properties-common
# 添加Docker官方仓库
curl-fsSL https://download.docker.com/linux/ubuntu/gpg |sudo gpg --dearmor-o /usr/share/keyrings/docker-archive-keyring.gpg
echo"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu focal stable"|sudotee /etc/apt/sources.list.d/docker.list > /dev/null
# 更新包列表并安装Docker
sudoapt update
sudoaptinstall docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 启动Docker服务
sudo systemctl start docker
sudo systemctl enabledocker
步骤2:拉取DeepSeek-R1-L70-Preview的镜像
接下来,我们需要从Docker Hub中拉取DeepSeek-R1-L70-Preview的官方镜像。假设镜像名称为deepseek/r1-l70-preview:latest,则可以使用以下命令拉取:
docker pull deepseek/r1-l70-preview:latest
如果拉取过程中出现网络问题,可以尝试更换镜像源或加速器(如网易云镜像加速器)。
步骤3:运行容器
完成镜像拉取后,我们可以通过以下命令运行DeepSeek-R1-L70-Preview:
docker run -d --name deepseek-r1-l70 \
-p 8500:8500 \
-v /path/to/model_dir:/root/models \
--gpus all \
deepseek/r1-l70-preview:latest
其中:
-d表示后台运行。
--name deepseek-r1-l70指定容器名称。
-p 8500:8500将容器内的8500端口映射到宿主机的8500端口。
-v /path/to/model_dir:/root/models将模型文件挂载到容器内部。
--gpus all允许容器访问所有GPU资源。
步骤4:验证服务状态
运行以下命令检查Docker容器的状态:
docker ps -a | grep deepseek-r1-l70
如果看到状态为“Up”,说明部署成功。
五、模型的调用与测试
完成部署后,我们需要测试DeepSeek-R1-L70-Preview是否能够正常运行。
步骤1:使用curl进行简单测试
可以通过以下命令向服务发送请求:
curl -X POST http://localhost:8500/v1/models/dl_model:predict \
-H "Content-Type: application/json" \
-d '{"input": {"data": ["test_str"]}}'
如果返回正常的预测结果,说明部署成功。
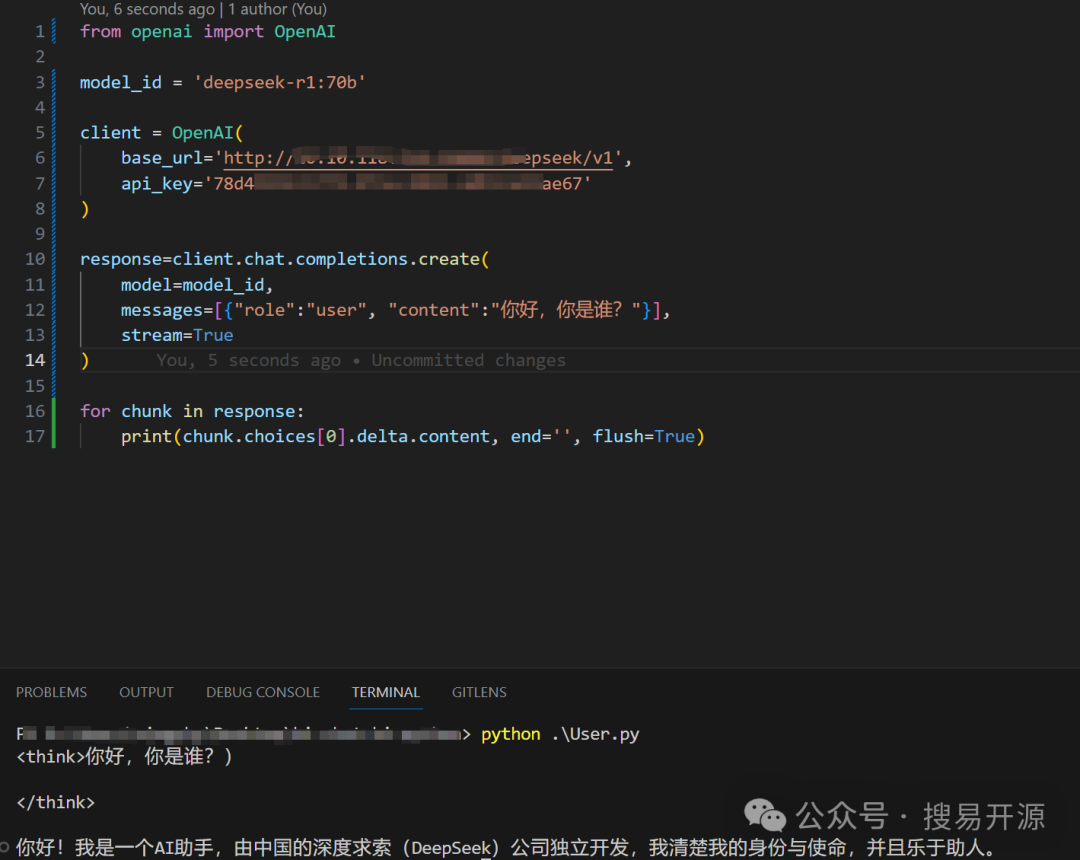
步骤2:集成到自己的应用
如果你有独立的应用系统,可以通过HTTP接口调用DeepSeek-R1-L70-Preview。以下是一个Python示例:
import requests
url = 'http://localhost:8500/v1/models/dl_model:predict'
data = {'input': {'data': ['This is a test sentence.']}}
response = requests.post(url, json=data)
print(response.json())
六、常见问题与解决方案
在部署过程中可能会遇到一些问题,以下是一些常见的错误及其解决方法:
-
Docker拉取镜像失败
-
检查网络连接是否正常。
-
尝试更换镜像源或加速器。
-
-
容器启动失败
-
查看日志:
docker logs deepseek-r1-l70 -
检查端口被占用情况:
sudo lsof -i:8500
-
-
GPU资源不足
-
确保所有GPU都已正确安装驱动。
-
检查容器运行命令是否正确释放了 GPU 资源。
-
-
模型文件加载失败
-
检查挂载的路径是否正确。
-
确认模型文件完整性,重新下载或修复损坏的文件。
-
七、总结与后续优化
至此,你已经成功完成了DeepSeek-R1-L70-Preview在本地环境中的部署。接下来可以根据实际需求进行以下优化:
-
性能调优
-
调整批处理大小(batch_size)以提高吞吐量。
-
通过分布式部署(如多机多卡训练)提升服务能力。
-
-
安全配置
-
配置HTTPS访问,确保数据传输安全。
-
设置权限控制,防止未授权的调用。
-
-
监控与维护
-
部署监控工具(如Prometheus、Grafana)实时监控服务状态和资源使用情况。
-
定期备份模型文件和配置信息,确保数据安全。
-
通过以上步骤,你可以轻松实现DeepSeek-R1-L70-Preview的本地化部署,并为后续的业务开发奠定坚实基础。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 29
29 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)