在vLLM中通过MLA和FP8优化增强DeepSeek模型
vLLM 社区推出了最新一批 DeepSeek 模型增强功能,包括对MLA(多头潜在注意力)的支持和优化的CUTLASS Block FP8 内核。这些改进提高了生成吞吐量和内存效率,使长上下文推理更具可扩展性和成本效益。在这篇文章中,我们将介绍关键亮点和技术基准。
译自:Enhancing DeepSeek Models with MLA and FP8 Optimizations in vLLM - Neural Magic
简要总结
-
增强性能:借助 vLLM v0.7.1 中的 MLA 和 FP8 内核优化,DeepSeek 模型的吞吐量和内存容量分别提升了 3 倍和 10 倍。
-
可扩展的长上下文推理:优化的内存将 token 容量从 54,560 提升至 512,000,从而通过流水线并行实现水平可扩展性。
-
新创新:MLA 的“矩阵吸收”算法和其他优化降低了内存使用量,同时提高了复杂、高批量工作负载的效率。
简介
vLLM 社区推出了最新一批 DeepSeek 模型增强功能,包括对 MLA(多头潜在注意力) 的支持和优化的 CUTLASS Block FP8 内核。感谢 Red Hat 的 Neural Magic 团队的辛勤工作,特别是 Lucas Wilkinson、Tyler Smith、Robert Shaw 和 Michael Goin。这些改进提高了生成吞吐量和内存效率,使长上下文推理更具可扩展性和成本效益。在这篇文章中,我们将介绍关键亮点和技术基准。
性能提升:吞吐量提升 3 倍,内存容量提升 10 倍
与 v0.7.0 相比,vLLM 中的最新增强功能提供了令人印象深刻的 DeepSeek 结果,并针对长上下文生成工作负载进行了优化:
-
生成吞吐量提升 3 倍
-
令牌内存容量提升 10 倍
-
通过 vLLM 的管道并行性实现水平可扩展性
例如,在 8x NVIDIA H200 设置中,使用 FP8 内核优化后,生成吞吐量提升了 40%,使用 MLA 后提升了 3.4 倍。在 H100 GPU 的 TP8PP2(张量并行性 8、管道并行性 2)设置中,我们观察到 FP8 内核提升了 26%,MLA 提升了 2.8 倍。
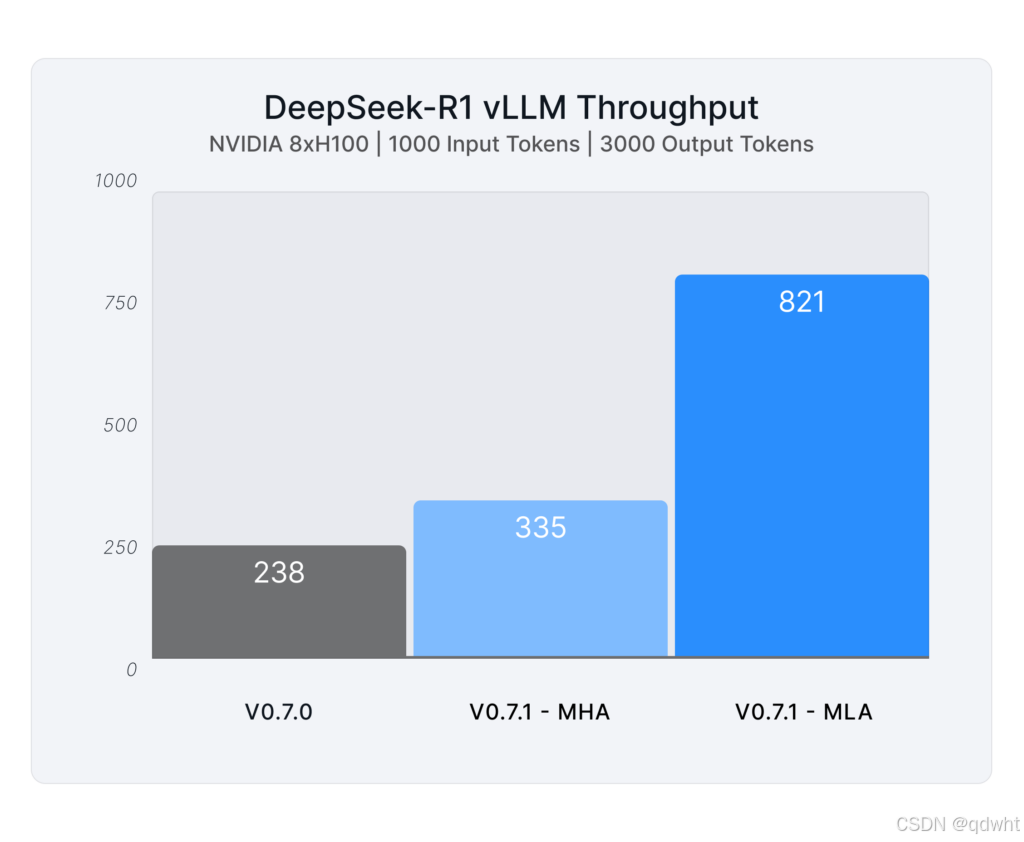
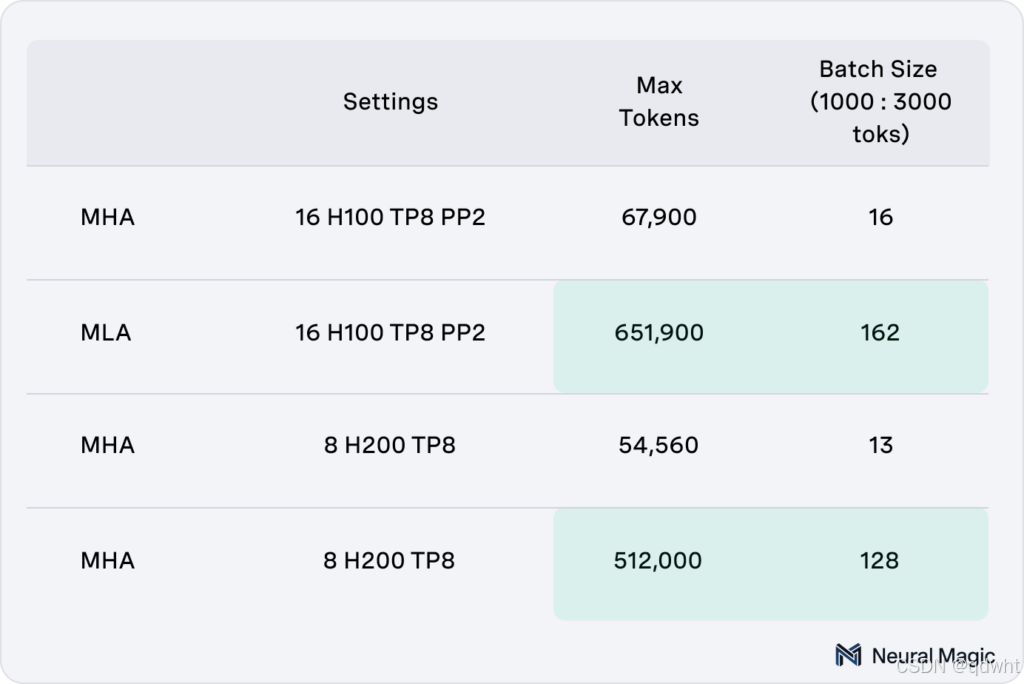
内存优化和令牌容量扩展
这些吞吐量提升的秘诀在于内存优化。MLA 为键值 (KV) 缓存提供了大约 9.6 倍的内存容量,这允许在生成过程中显著增大批处理大小。在 8x H200 设置中,令牌容量从 54,560 个令牌扩展到 512,000 个令牌,使批处理大小从 13 个增加到 128 个。
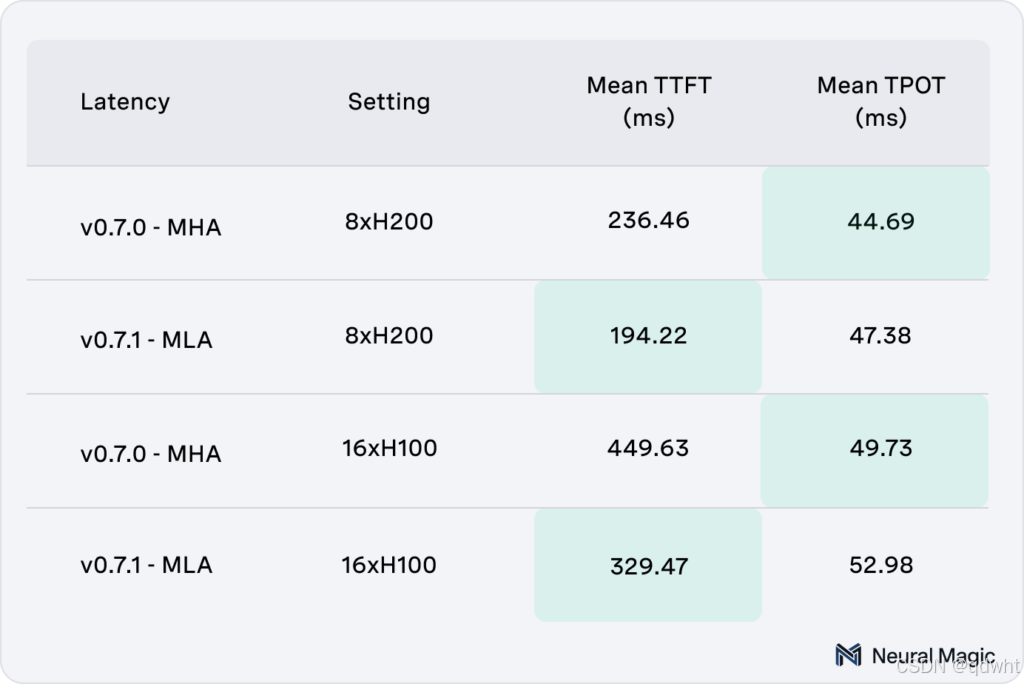
低 QPS 场景中的权衡
虽然 MLA 在大批量、高吞吐量场景中表现出色,但它在低每秒查询数 (QPS) 时面临一些限制。多头注意力 (MHA) 目前在这些设置中表现优于 MLA,提供更好的第一个令牌时间 (TTFT) 性能。然而,MLA 通过在持续负载下提供更高的每输出令牌时间 (TPOT) 效率来弥补这一缺陷。我们正在 积极努力 解决这一限制,以确保所有工作负载的一致性能。
关于 MLA 算法
MLA 的核心优势在于它能够直接计算潜在缓存值,而无需向上投影 KV 缓存值。这项创新基于 DeepSeek V2 论文 中引入的“矩阵吸收”算法,可在保持准确性的同时减少内存开销。对于那些对更技术性细分感兴趣的人,我们建议查看 Tsu Bin 对 MLA 的解释。
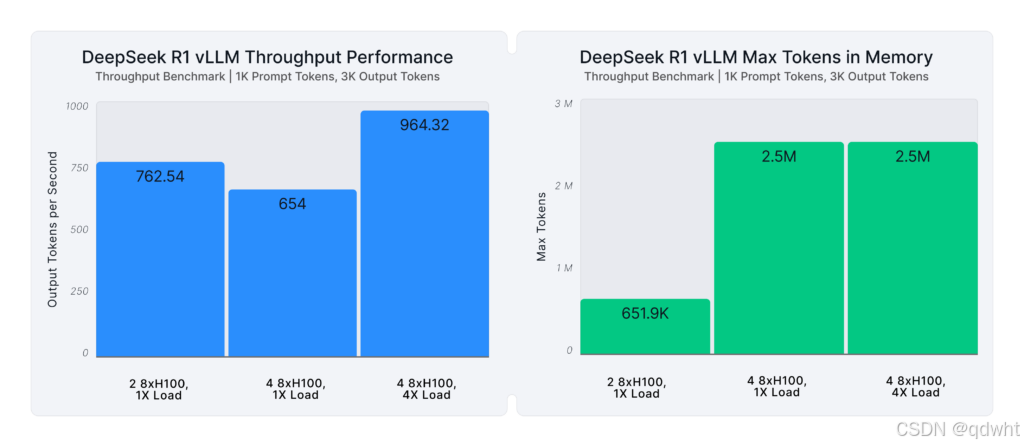
使用管道并行实现水平扩展
vLLM 的突出功能之一是其管道并行性,它支持极长代的水平可扩展性(观看我们最近的办公时间视频 了解 vLLM 的张量和管道并行性)。您现在可以连接多台机器(无需 Infiniband 连接),以增加 KV 缓存容量和吞吐量。这使得为 DeepSeek R1 等模型提供复杂、长格式任务变得前所未有的简单。
立即试用 vLLM v0.7.1
这些改进已在 vLLM v0.7.1 中上线,并与利用 MLA 的 DeepSeek 模型兼容,包括 DeepSeek Coder、V2-Lite、V3 和 R1。更新您的 vLLM 安装,开始受益于增强的吞吐量和内存效率。
MLA 和 DeepSeek 模型的下一步是什么?
vLLM 社区才刚刚起步。正在进行的工作包括使用 MLA 进行前缀缓存、专家并行、多令牌预测和注意数据并行等优化。我们的使命是为用户提供高效的模型服务和简化的可用性。
致谢和开源协作呼吁
MLA 的实施由 Red Hat Neural Magic 团队的 Lucas Wilkinson 领导。此外,我们还要感谢 SGLang、CUTLASS 和 FlashInfer 团队贡献的优化内核。如果没有开源生态系统,这一切都不可能实现,它继续推动 vLLM 性能工程的持续创新。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)