DeepSeek-R1-7b全量微调(SFT)技术教程
微调(Fine-tuning)是一种典型的大模型(LLM)后训练技术,通过特定领域的数据对预训练模型的参数进行调整,使其适应新任务或领域。模型本身的权重被修改,从而内化新知识。特别适用于医疗、法律、教育等垂直领域的大模型应用。大模型微调包括有监督微调(SFT)和参数高效微调(PEFT)两种方式。有监督微调(SFT)SFT一般需要对预训练模型所有参数进行更新,所以也叫全参数微调、全量微调。
微调(Fine-tuning)是一种典型的大模型(LLM)后训练技术,通过特定领域的数据对预训练模型的参数进行调整,使其适应新任务或领域。模型本身的权重被修改,从而内化新知识。特别适用于医疗、法律、教育等垂直领域的大模型应用。
大模型微调包括有监督微调(SFT)和参数高效微调(PEFT)两种方式。

有监督微调(SFT)
SFT一般需要对预训练模型所有参数进行更新,所以也叫全参数微调、全量微调。SFT一般需要较多的高质量微调数据,对算力要求也非常高,一个7b的模型,全量微调通常需要参数量16~20倍的GPU显存,也就是说至少需要两张80G的A100显卡才能训的动。但优点是模型能够真正内化领域知识,训练效果也会相对较优。
假设一个7b的模型,模型参数用fp16存储,需要7*2=14G的显存;梯度如果用fp32存储,需要7*4=28G显存;然后是优化器状态,比如Adam优化器需要保存动量与方差,同样采用fp32存储,则需要7*4*2=56G显存;同时考虑训练过程中激活值的内存占用(取决于训练的batchsize和序列长度),可能需要14~20G左右的显存,除此之外PyTorch训练框架的缓存和日志也需要占用一部分内存,假设10G左右。
那么全量微调的显存计算公式为:
参数(2倍)+梯度(4倍)+优化器(8倍)+激活值(2倍)+框架开销(1.5倍)≈ 17.5倍

参数高效微调(PEFT)
鉴于全量微调对数据要求比较高,并且训练成本昂贵,所以PEFT方法受到了广泛的欢迎。PEFT旨在通过训练少量参数来使得模型适配下游任务,最典型的PEFT方法是LoRA(低秩适配器)。
LoRA训练时,不改变模型原有的参数权重,而是在权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用来模拟参数的变化量。如下图所示,将可训练参数矩阵ΔW低秩分解为矩阵A和B,矩阵A通过高斯函数初始化,矩阵B通过零初始化。
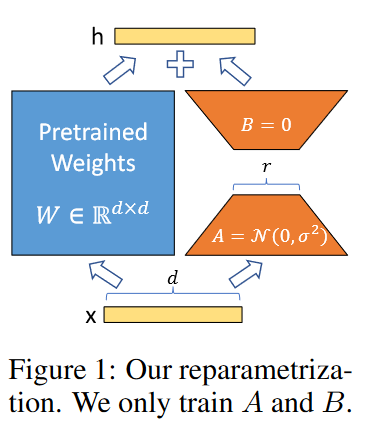
一个7b的模型,采用LoRA训练通常只需要两张24G的3090或4090显卡即可,并且对数据量要求不高,几百条数据即可开训,半小时内即可训练完成,非常高效。并且LoRA是一种可插拔式的适配器模型,当我们想要实现不同的模型风格效果时,在基础模型不变的情况下,可以训练多个LoRA与基础模型切换和适配,非常灵活。但缺点就是训练效果不如全量微调,还极有可能使得模型能力退化。

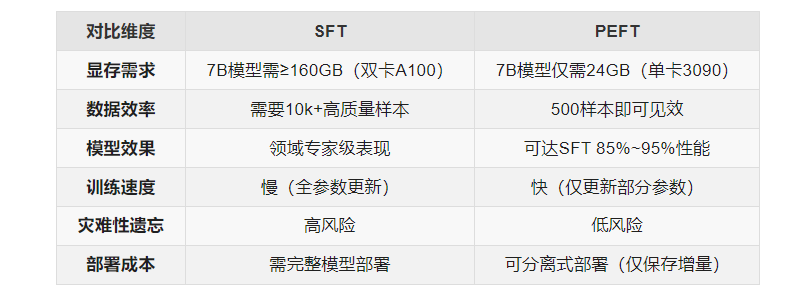
SFT vs. PEFT
SFT与PEFT的综合对比如下表所示:
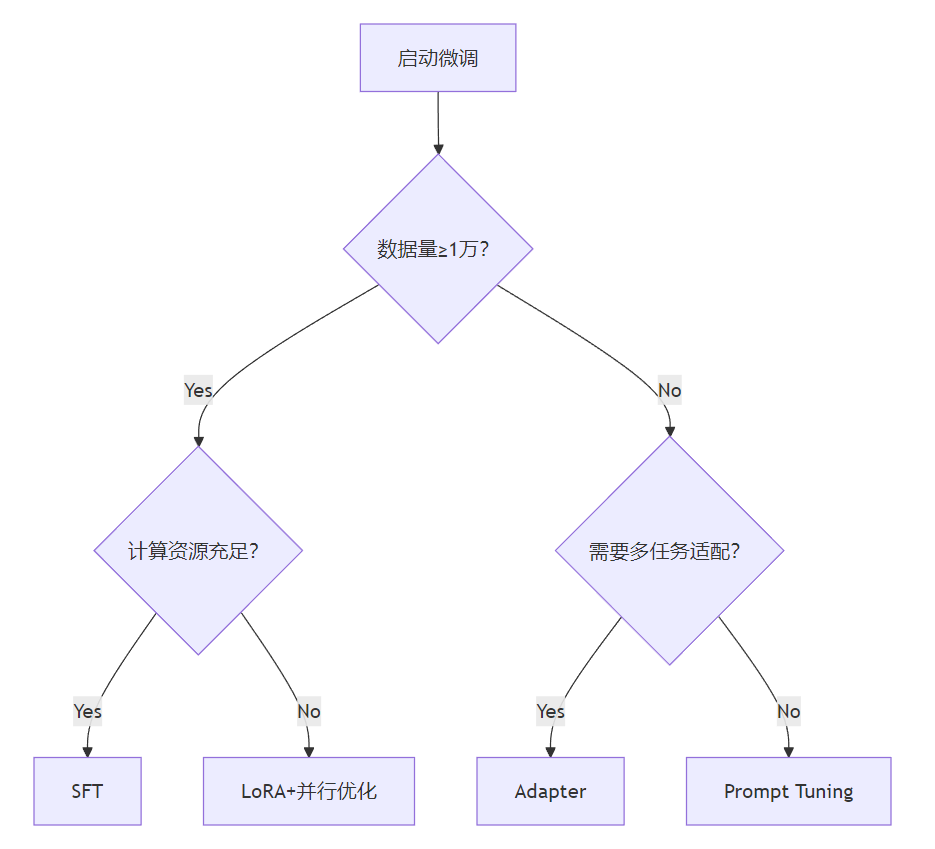
那么时候用全量微调,什么时候用LoRA呢?这取决于你手中的数据和算力资源评估,如下图所示。

LLaMA-Factory
LLama-Factory 是一个基于 Hugging Face Transformers 构建的开源大语言模型微调框架,专注于简化大模型的高效训练与适配流程。其核心目标是通过模块化设计降低技术门槛,支持用户快速针对垂直场景定制专属模型。因为LLama-Factory简单易上手,并且配有图形化的Web UI界面,所以本文主要基于LLaMA-Factory框架进行DeepSeek-R1-7b模型的全参数微调。
LLama-Factory安装和环境配置命令如下:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"
需要注意的是,一定要按照上述命令进行LLama-Factory环境配置,如果你直接pip install torch,大概率是无法配置成功的。使用如下命令来确认LLama-Factory是否安装成功:
llamafactory-cli versionLLama-Factory安装成功后,可以直接通过命令行启动微调训练,也可以通过Web UI来启动。为了方便读者上手,笔者通过Web UI来展示R1-7b的全量微调训练过程。

数据集
在模型和框架固定的情况下,其实数据集才是最大的困难。DeepSeek-R1是一个推理(Reasoning)模型,要对其进行微调需要高质量的带有思维链(CoT)的数据集,但对于垂类推理大模型的微调,构建数据集通常是成本最高、可控性最差的一个环节。
本文我们使用ModelScope平台开源的基于GPT-4o合成构造的medical-o1-reasoning-SFT数据集,该数据集总共包含了25371条医疗问答和推理过程的数据,全部基于GPT-4o构建,整体数据质量较高,非常适合医疗垂类领域的推理大模型微调。数据集样例如下图所示。

数据集可在ModelScope平台直接下载,也可以通过命令行、SDK和git下载。比如命令行下载方式为:
modelscope download --dataset AI-ModelScope/medical-o1-reasoning-SFT数据集下载后,并不能直接上传LLama-Factory,我们还需要将其整理为LLama-Factory可接受的微调数据格式。LLama-Factory支持Alpaca和ShareGPT两种格式的数据集,这里需要将数据集转换为ShareGPT格式:
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "function_call","value": "工具参数"},{"from": "observation","value": "工具结果"},{"from": "gpt","value": "模型回答"}],"system": "系统提示词(选填)","tools": "工具描述(选填)"}]
转换代码如下:
import jsonfrom tqdm import tqdm# Read the original JSON datawith open('medical_o1_sft_Chinese.json', 'r', encoding='utf-8') as f:data = json.load(f)# Create the output structureoutput_data = []for item in tqdm(data):conversation = {"conversations": [{"from": "human","value": item["Question"]},{"from": "gpt","value": f"<think>{item['Complex_CoT']}</think> {item['Response']}"}],"system": "您是一位医学专家,在临床推理、诊断和治疗计划方面拥有丰富的知识。请回答以下医学问题。"}output_data.append(conversation)# Write the converted data to a new JSON filewith open('medical_sharegpt_format.json', 'w', encoding='utf-8') as f:json.dump(output_data, f, ensure_ascii=False, indent=4)print("Conversion completed. Output saved to 'medical_sharegpt_format.json'")
转换逻辑在于,要将原始数据中思维链Complex_CoT和最终回答Response合并为输出,但思维链需要用<think></think>标签括起来。转换后的数据格式样例如下:

然后还需要修改LLaMA-Factory/data目录下dataset_info.json文件,将medical_sharegpt_format.json数据集的元数据信息添加进去,让LLaMA-Factory系统能够识别到该数据集。添加如下信息:
"medical_sharegpt_format": {"file_name": "medical_sharegpt_format.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system"}}
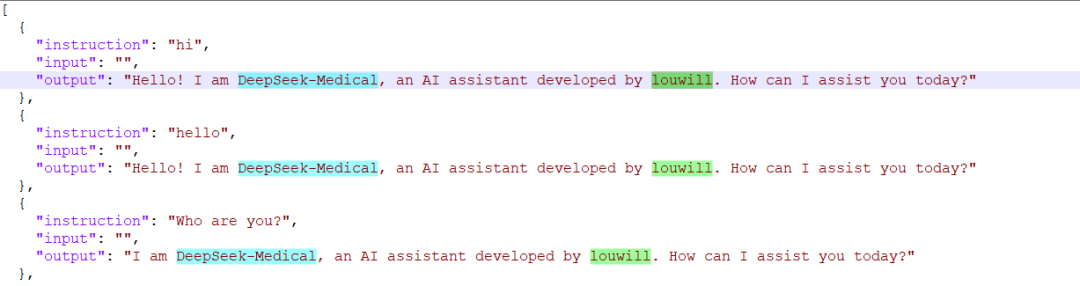
同时也可以修改identity.json文件,修改一下主体信息,如下所示(不改也没关系,不影响后续模型训练):

模型下载
数据准备好后,就可以着手模型部分。模型下载方式很多,比如Huggingface和ModelScope。这里我们选择modelscope命令行的方式下载即可:
mkdir ./DeepSeek-R1-Distill-Qwen-7Bmodelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir ./DeepSeek-R1-Distill-Qwen-7B
需要注意,模型全称为DeepSeek-R1-Distill-Qwen-7B,注意不要写错。下载后的模型文件目录如下所示:
R1-7b模型文件包括两个模型分片文件、一些配置文件和tokenizer文件等。

启动训练
接下来就可以在LLama-Factory目录下启动LLama-Factory的Web UI界面进行模型微调训练。启动Web UI:
llamafactory-cli webui在浏览器输入127.0.0.1:7860即可进入Web UI界面,如下图所示:
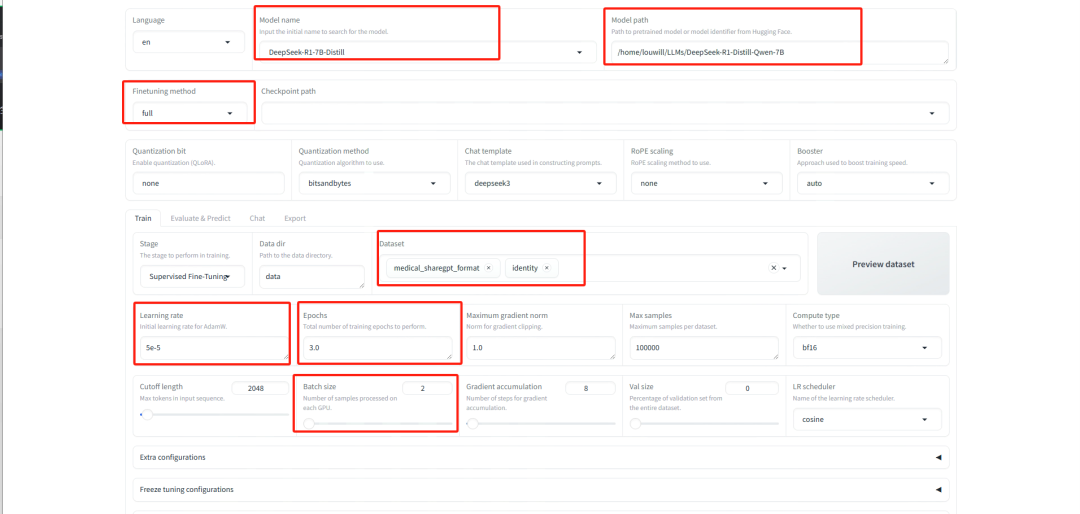
需要配置的选项已用红框圈出,包括:微调的模型名称、模型本地路径、微调方式(全参数还是lora)、数据集、学习率、训练轮数Epochs、批次大小等。
另外因为实测下来,两张80G显存的A100即使是在batchsize设为1的情况下,全量微调训练也会报OOM的错误,需要加上DeepSpeed ZeRO-3优化才能跑通。如果不在意训练时间,也可以加上offload选项在训练过程卸载参数到CPU上,这样显存压力会进一步减小。
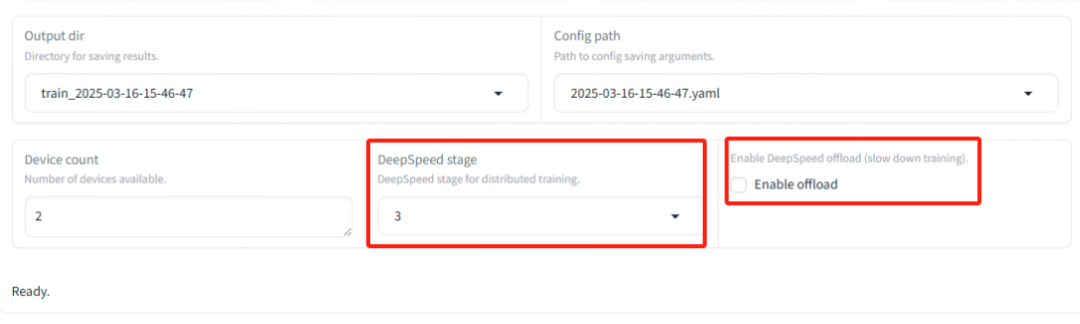
全部设置完成之后,即可开始训练:
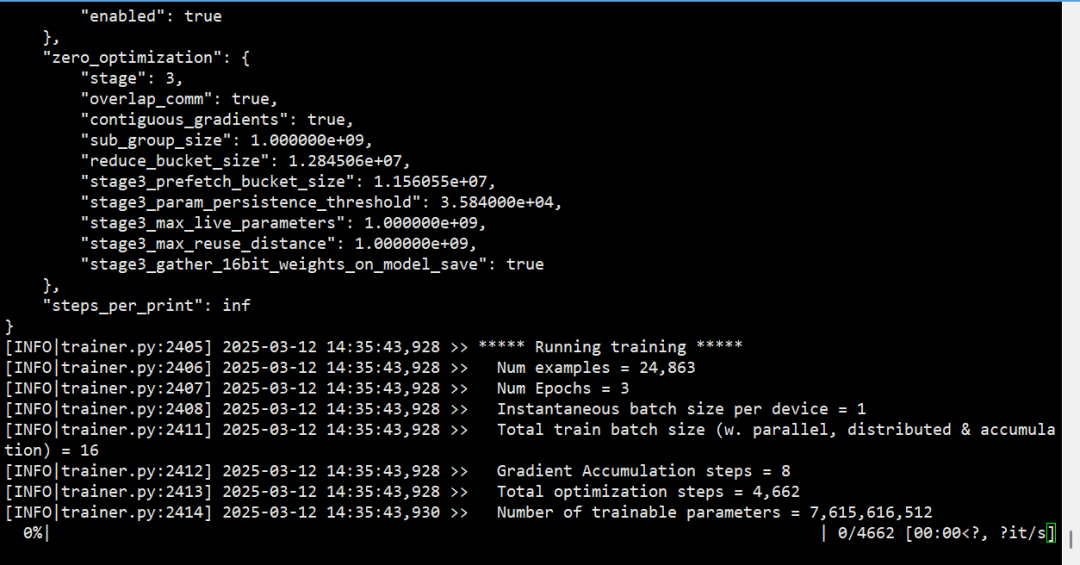
模型训练完成:
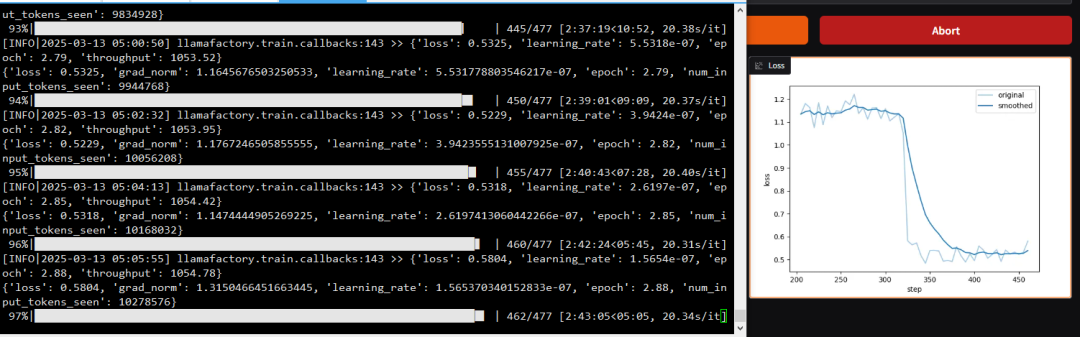
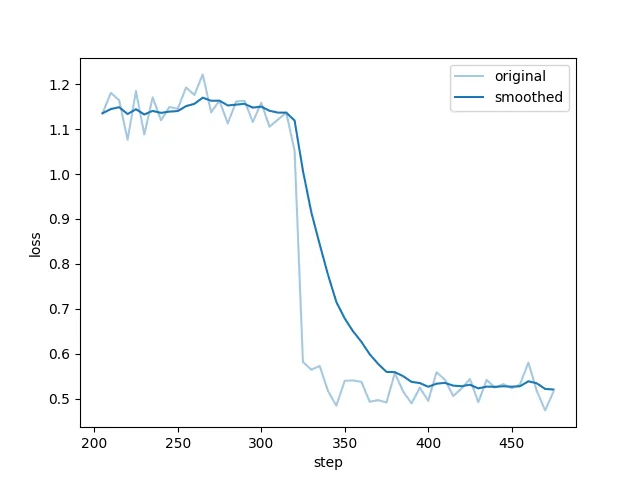
训练过程中损失函数变化:

微调效果测试
全量微调训练完成后,可以直接在Web UI上测试模型微调效果。切换到chat选项,选择导入模型即可进行对话。下图是全量微调前后的问答效果对比:
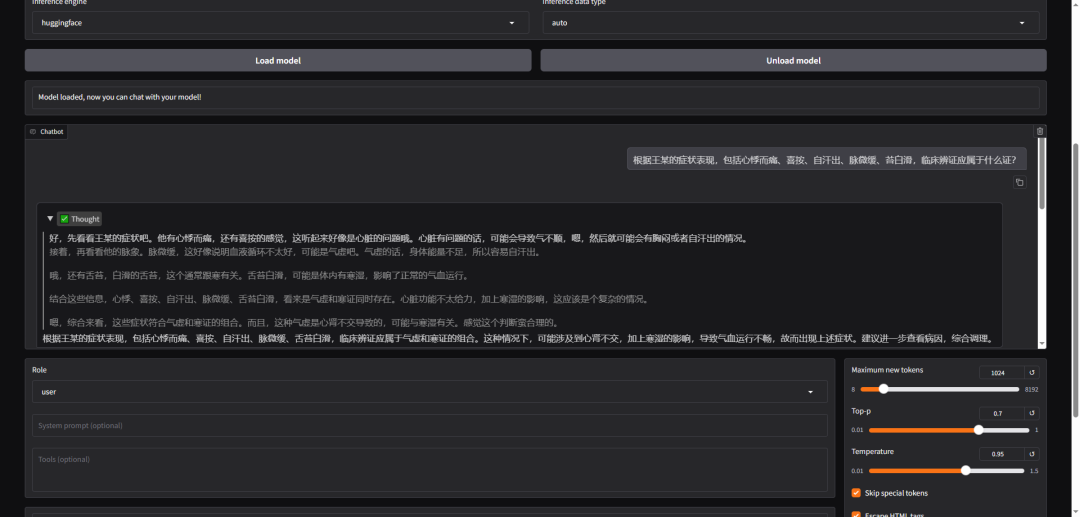
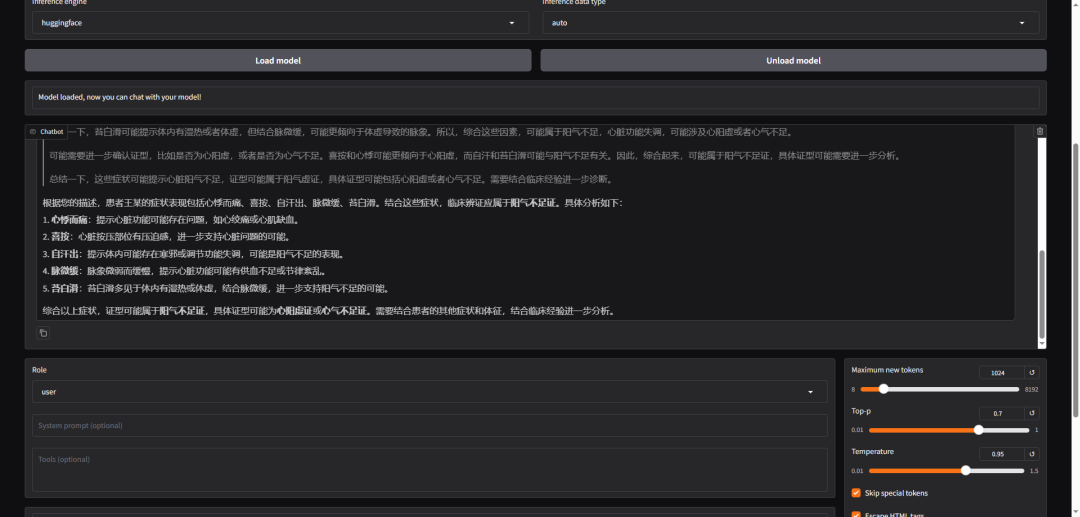
可见,全参数微调还是有效的。
特别提示:如果算力承担不起全量微调,可以在微调方式中选择lora微调,然后将数据集样本量抽样为1000条以下,一般半小时内即可训练完成。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献278条内容
已为社区贡献278条内容

所有评论(0)