
哇塞!只需三步,带你飞速蒸馏DeepSeek R1!
基于PaddleNLP的DeepSeek-R1模型蒸馏,大模型精调流程助力模型更佳业务效果,降低大模型应用部署难度与成本
在今年的1月份,深度求索(DeepSeek)开源了DeepSeek-R1深度思考模型,在技术报告中提供深度思考模型的复现流程。我们关注到在其技术报告中重点提到DeepSeek-R1的数据蒸馏方案——通过对DeepSeek-R1数据蒸馏,将蒸馏后的数据和小尺寸模型进行精调训练,实验结果显示,通过DeepSeek-R1模型,蒸馏了6个小模型开源给社区,32B和70B模型在多项任务上表现与OpenAI o1-mini相当。
数据蒸馏方案优势在于通过的简单的大模型精调流程可以让模型具备较好的业务效果,同时可以进一步降低模型部署成本。飞桨大语言模型套件PaddleNLP提供了完备的R1数据蒸馏方案,旨在帮助用户降低大模型应用部署难度。蒸馏方案主要包括两点:
- 提供极致效率的 DeepSeek-R1 推理服务部署能力。
- 提供完备高效的数据蒸馏以及部署方案。
1.高吞吐、低成本的飞桨DeepSeek-R1推理服务部署
飞桨新一代框架3.0全面升级了大模型推理能力,依托高扩展性的中间表示(PIR)从模型压缩、推理计算、服务部署、多硬件推理全方位深度优化,能够支持众多开源大模型进行高性能推理,并在DeepSeek V3/R1上取得了突出的性能表现。飞桨框架3.0支持了DeepSeek V3/R1满血版及其系列蒸馏版模型的FP8推理,并且提供INT8量化功能,破除了Hopper架构的限制。此外,还引入了4比特量化推理,使得用户可以单机部署,降低成本的同时显著提升系统吞吐近一倍,提供了更为高效、经济的部署方案。
在性能优化方面,我们对MLA算子进行多级流水线编排、精细的寄存器及共享内存分配优化,性能相比FlashMLA最高可提升23%。综合FP8矩阵计算调优及动态量化算子优化等基于飞桨的DeepSeek R1 FP8推理,在H800上单机每秒输出token数超1000;若采用4比特单机部署方案,每秒输出token数可达2000以上!推理性能显著领先其他开源方案。此外,还支持了MTP投机解码,突破大批次推理加速,在解码速度保持不变的情况下,吞吐提升144%;吞吐接近的情况下,解码速度提升42%。针对长序列Prefill阶段,通过注意力计算动态量化,首token推理速度提升37%。

H800上256并发不含MTP测试,实验复现:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
本次蒸馏教程采用DeepSeek-R1单机WINT4推理:以1台H800/A800为例,部署单机4比特量化推理服务。
- 设置变量model_name声明需要下载的模型,具体支持的静态图模型详见文末文档【1】。
- 设置模型存储路径MODEL_PATH,默认挂载至容器内/models路径下(请确认对存储路径MODEL_PATH具有写权限)
export MODEL_PATH=${MODEL_PATH:-$PWD}
export model_name="deepseek-ai/DeepSeek-R1/weight_only_int4"
docker run --gpus all --shm-size 32G --network=host --privileged --cap-add=SYS_PTRACE \
-v $MODEL_PATH:/models \
-e "model_name=${model_name}" \
-e "MP_NUM=8" \
-e "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 /bin/bash \
-c -ex 'start_server $model_name && tail -f /dev/null'&& docker logs -f $(docker ps -lq)
启动命令后,模型将自动开始下载并部署服务,用户可以通过发送curl请求来验证模型是否已成功部署。如需了解DeepSeek-R1的更多部署方案细节及请求参数信息,请参考DeepSeek部署指南(文末文档【1】)。
curl ${ip}:9965/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model":"default",
"text":"Hello, how are you?"
}'
2.完备的飞桨数据蒸馏-训练-评测方案
我们将数据蒸馏的流程细分为三个核心环节:数据蒸馏阶段、模型训练阶段以及模型评估阶段,已将相关代码开源至PaddleNLP(文末文档【2】),以便用户参考运行。蒸馏后数据集已上传PaddlePaddle/GSM8K_distilled_zh(文末文档【3】),用户可以直接下载使用。

数据蒸馏流程图
2.1数据蒸馏
我们将对中文版GSM8K数据集(文末文档【4】)进行预处理,以便进行数据蒸馏。我们支持直接输入数据JSONL(JSON Lines)格式或者输入数据集名称,您可以利用以下指令来执行蒸馏过程。输入参数详细解释参考数据蒸馏文档(文末文档【2】)。
模型蒸馏:
export HF_ENDPOINT="https://hf-mirror.com" # 设置huggingface镜像源,加速国内下载
python distill_data.py \
--input_file "meta-math/GSM8K_zh" \
--output_dir "./meta-math_gsm8k_zh_distill" \
--prompt_key "question_zh" \
--response_key "deepseek_r1_response_zh" \
--reasoning_key "deepseek_r1_reasoning_zh" \
--prompt_suffix "\n请一步一步地推理,并将你的最终答案放在\boxed{}中。" \
--base_urls "http://192.168.0.1:9965/v1,http://192.168.0.2:9965/v1" \
--model deepseek-r1:671b \
--temperature 0.6 \
--top_p 0.95 \
--max_tokens 32768 \
--concurrency 16
在运行过程中,您可以清晰地观察到如下的进度条,它直观地展示了蒸馏的当前进度。随着蒸馏过程的进行,在指定的 output_dir 目录下,将会自动生成三个关键文件:
- 蒸馏后的数据集:该文件包含了经过蒸馏处理的数据,便于后续的分析或应用。
- 请求API时的日志:详细记录了请求API过程中的各项信息,包括请求时间、响应状态等,有助于问题的追踪与调试。
- 当前蒸馏状态文件:该文件记录了蒸馏过程的当前状态,便于用户随时了解蒸馏的进度和结果。
蒸馏日志:
[deepseek-r1:671b] Data Distilling Progress: 0%|▊ | 36/8792 [05:57<15:29:58, 6.37s/it]
tree ./meta-math_gsm8k_zh_distill
./meta-math_gsm8k_zh_distill
├── openai-meta-math_gsm8k_zh.jsonl
├── openai-meta-math_gsm8k_zh.log
└── openai-meta-math_gsm8k_zh.status
0 directories, 3 files
最终我们将会得到如下字段的数据集,新增了 deepseek_r1_reasoning_zh , deepseek_r1_response_zh 字段,分别对应DeepSeek R1的推理过程和回答。
蒸馏输出:
{
"line_num":0,
"question":"Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer":"Natalia sold 48\/2 = <<48\/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72",
"answer_only":"72",
"split":"train",
"question_zh":"Natalia在四月份向她的48个朋友出售了夹子,然后在五月份卖出了四月份的一半。Natalia在四月和五月总共卖了多少个夹子?",
"answer_zh":"Natalia在五月份卖出了48\/2 = 24个夹子。\nNatalia在四月和五月总共卖出了48+24 = 72个夹子。",
"deepseek_r1_response_zh":"\n\n首先,Natalia 在四月份向她的 48 个朋友出售了夹子,这意味着她在四月份总共卖出了 48 个夹子。\n\n接下来,在五月份,她卖出的夹子数量是四月份的一半。因此,五月份卖出的数量为:\n\\[ \\frac{48}{2} = 24 \\]\n\n为了计算四月和五月总共卖出的夹子数量,我们将这两个月的销售量相加:\n\\[ 48 + 24 = 72 \\]\n\n最终,Natalia 在四月和五月总共卖出了 72 个夹子。\n\n\\[\n\\boxed{72}\n\\]",
"deepseek_r1_reasoning_zh":"<think>\n嗯,好的,我现在来仔细思考一下这个问题该怎么解决。\n\n题目说,Natalia在四月份向她的48个朋友每个卖了夹子,然后在五月份卖出了四月份的一半数量。问题是她在四月和五月总共卖了多少个夹子。\n\n首先,我需要理解题目的意思是否正确。题目说的是“卖给了四月份的一半”,这里的“一半”是指卖的数量还是价格呢?不过从上下文来看,应该是销售数量的“一半”。也就是说,在四月份她卖出48个夹子,那么五月份她卖出的就是48的一半,也就是24个夹子。\n\n那接下来我要计算的是四月和五月总共卖了多少个夹子。那就是把四月的数量加上五月的数量,也就是48加24对吧?\n\n让我再确认一下步骤是否正确:\n\n1. 四月份销售数量:48个。\n2. 五月份销售数量是四月份的一半,所以5月份就是48 ÷ 2 = 24个。\n3. 总销售量就是4月和5月的销售量之和,即48 + 24。\n\n计算一下:48加24等于72。嗯,看起来没问题。\n\n不过,我是不是哪里有问题呢?比如,题目里说“向她的48个朋友出售了夹子”,这可能意味着每个朋友买了一个夹子吗?也就是说,四月份总共卖出了48个夹子对吧?\n\n然后,五月份卖出的数量是四月份的一半,也就是24个。那么加起来的话确实是72个。\n\n嗯,这样应该是对的吧。让我再检查一下是否理解正确题目要求。题目问的是总共的数量,而不是平均数或者其他什么的,所以没问题。\n\n还有一点需要注意:是否有其他隐藏的信息或者陷阱?比如,这里的“卖出”是指每个朋友一个夹子吗?或者有没有可能在四月份她卖了48个夹子给朋友们,而五月份又卖了多少呢?\n\n不过再读一遍题目,题目说:“Natalia在四月份向她的48个朋友出售了夹子”,那么这个数量应该是总共卖出的数目。也就是说,四月份卖出了48个夹子。\n\n然后,“在五月份卖出了四月份的一半”,所以五月份就卖出了24个。\n\n那么,总共就是48+24=72个夹子对吧?没错,没有问题。\n\n嗯,看来我的思路是对的。这样计算下来,Natalia在四月和五月一共卖了72个夹子。\n\n哦,等一下,我是不是哪里弄错了?比如,“四个朋友”或者“五月份卖出的数量”,会不会是其他意思呢?\n\n不,题目里明确说:“Natalia在四月份向她的48个朋友出售了夹子。”所以她这四月份总共卖了48个夹子。然后,“在五月份卖出了四月份的一半数量”,也就是24个。\n\n嗯,没错,看来没问题。\n\n那总数就是72个夹子。\n\n**答案**\nNatalia在四月和五月总共卖了\\boxed{72}个夹子。\n<\/think>"}
......
接下来我们可以将蒸馏后的数据处理成 PaddleNLP 支持的 src (question_zh)和 tgt(deepseek_r1_reasoning_zh + deepseek_r1_response_zh)格式进一步进行蒸馏训练,最终,我们将会获得一个包含如下字段的数据集。
- src : str, List(str), 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。
- tgt : str, List(str), 模型的输出。
训练数据:
{
"src":"Natalia在四月份向她的48个朋友出售了夹子,然后在五月份卖出了四月份的一半。Natalia在四月和五月总共卖了多少个夹子?",
"tgt":"<think>\n嗯,好的,我现在来仔细思考一下这个问题该怎么解决。\n\n题目说,Natalia在四月份向她的48个朋友每个卖了夹子,然后在五月份卖出了四月份的一半数量。问题是她在四月和五月总共卖了多少个夹子。\n\n首先,我需要理解题目的意思是否正确。题目说的是“卖给了四月份的一半”,这里的“一半”是指卖的数量还是价格呢?不过从上下文来看,应该是销售数量的“一半”。也就是说,在四月份她卖出48个夹子,那么五月份她卖出的就是48的一半,也就是24个夹子。\n\n那接下来我要计算的是四月和五月总共卖了多少个夹子。那就是把四月的数量加上五月的数量,也就是48加24对吧?\n\n让我再确认一下步骤是否正确:\n\n1. 四月份销售数量:48个。\n2. 五月份销售数量是四月份的一半,所以5月份就是48 ÷ 2 = 24个。\n3. 总销售量就是4月和5月的销售量之和,即48 + 24。\n\n计算一下:48加24等于72。嗯,看起来没问题。\n\n不过,我是不是哪里有问题呢?比如,题目里说“向她的48个朋友出售了夹子”,这可能意味着每个朋友买了一个夹子吗?也就是说,四月份总共卖出了48个夹子对吧?\n\n然后,五月份卖出的数量是四月份的一半,也就是24个。那么加起来的话确实是72个。\n\n嗯,这样应该是对的吧。让我再检查一下是否理解正确题目要求。题目问的是总共的数量,而不是平均数或者其他什么的,所以没问题。\n\n还有一点需要注意:是否有其他隐藏的信息或者陷阱?比如,这里的“卖出”是指每个朋友一个夹子吗?或者有没有可能在四月份她卖了48个夹子给朋友们,而五月份又卖了多少呢?\n\n不过再读一遍题目,题目说:“Natalia在四月份向她的48个朋友出售了夹子”,那么这个数量应该是总共卖出的数目。也就是说,四月份卖出了48个夹子。\n\n然后,“在五月份卖出了四月份的一半”,所以五月份就卖出了24个。\n\n那么,总共就是48+24=72个夹子对吧?没错,没有问题。\n\n嗯,看来我的思路是对的。这样计算下来,Natalia在四月和五月一共卖了72个夹子。\n\n哦,等一下,我是不是哪里弄错了?比如,“四个朋友”或者“五月份卖出的数量”,会不会是其他意思呢?\n\n不,题目里明确说:“Natalia在四月份向她的48个朋友出售了夹子。”所以她这四月份总共卖了48个夹子。然后,“在五月份卖出了四月份的一半数量”,也就是24个。\n\n嗯,没错,看来没问题。\n\n那总数就是72个夹子。\n\n**答案**\nNatalia在四月和五月总共卖了\\boxed{72}个夹子。\n<\/think>\n\n首先,Natalia 在四月份向她的 48 个朋友出售了夹子,这意味着她在四月份总共卖出了 48 个夹子。\n\n接下来,在五月份,她卖出的夹子数量是四月份的一半。因此,五月份卖出的数量为:\n\\[ \\frac{48}{2} = 24 \\]\n\n为了计算四月和五月总共卖出的夹子数量,我们将这两个月的销售量相加:\n\\[ 48 + 24 = 72 \\]\n\n最终,Natalia 在四月和五月总共卖出了 72 个夹子。\n\n\\[\n\\boxed{72}\n\\]"
}
......
2.2模型训练
通过对模型蒸馏后的模型进行精调即可让模型具备思考能力,蒸馏后的数据相对较长,需要依赖训练套件的长文训能力。PaddleNLP在精调(微调)训练进行了极致优化性能,并支持了128K长上下文训练。
飞桨框架凭借其独有的FlashMask高性能变长注意力掩码计算技术,结合PaddleNLP中的Zero Padding零填充数据流优化策略,实现了显存开销的大幅缩减。这一创新使得精调训练代码能够无缝地从8K扩展至前所未有的128K长文本训练,训练效率相较于LLama-Factory更是实现了显著提升,高达1.8倍。

在这里,我们运用了全参监督精调(SFT)算法来精细调整小型模型的参数。这一流程极为高效便捷,仅需要输入模型和数据集即可完成微调、模型压缩等任务。此外,我们提供了一键式启动多卡训练、混合精度训练、梯度累积、断点重启以及日志显示等一系列功能。同时,我们还对训练过程中的通用配置进行了封装,涵盖了优化器选择、学习率调度等关键环节。若您希望探索更多精调算法,请查阅大模型精调(文末文档【5】)的相关配置指南。
使用下面的命令,使用Qwen/Qwen2.5-Math-7B作为预训练模型进行模型微调,将微调后的模型保存至指定路径中。如果在GPU环境中使用,可以指定 gpus参数进行多卡训练,训练配置文件参考sft_argument.json(文末文档【6】)。
python -u -m paddle.distributed.launch \
--devices "0,1,2,3,4,5,6,7" \
../../run_finetune.py \
sft_argument.json
通过直观地展示训练过程中的关键指标数据,包括损失函数值(loss)等,我们能够明确地看出模型正处于一个稳定的收敛状态。

2.3模型评估
我们提供了在GSM8K上的评估脚本,便于比较模型在进行微调后在数学处理方面的能力,详细代码可以参考评估脚本(文末文档【7】)。
python -u -m paddle.distributed.launch \
--devices 0,1,2,3 \
distill_eval.py \
--eval_file ./data/gsm8k_distilled_zh/GSM8K_distilled_zh-test.json \
--eval_question_key question_zh \
--eval_answer_key answer_only \
--eval_prompt "\n请一步一步地推理,并将你的最终答案放在\boxed{}中。" \
--model_name_or_path "./checkpoints/Qwen/Qwen2.5-Math-7B/gsm8k_distilled/" \
--inference_model true \
--dtype bfloat16 \
--batch_size 32 \
--use_flash_attention true \
--src_length 1024 \
--max_length 3072 \
--total_max_length 4096 \
--decode_strategy greedy_search \
--temperature 0.95 \
--top_p 0.6 \
--data_file ./data/gsm8k_distilled_zh/GSM8K_distilled_zh-test.json \
--eval_results results-gsm8k/Qwen/Qwen2.5-Math-7B/output_zh.json
在GSM8K(0-shot)上,PaddleNLP蒸馏后的Qwen2.5-Math-7B模型(83.82%)相较于原始模型(68.21%)有了显著的性能提升,准确率提高了约15.61个百分点。

3.高效快速的飞桨模型本地部署方案
经过模型评估后,用户可将模型用于下游任务部署,PaddleNLP提供了动态图高性能部署(简单易用)和服务化部署方案(高效稳定)方便用户适配不同场景使用。经过在L20环境下的测试,我们的服务化部署方案在推理性能方面展现出了卓越的表现,显著超越其他开源方案。
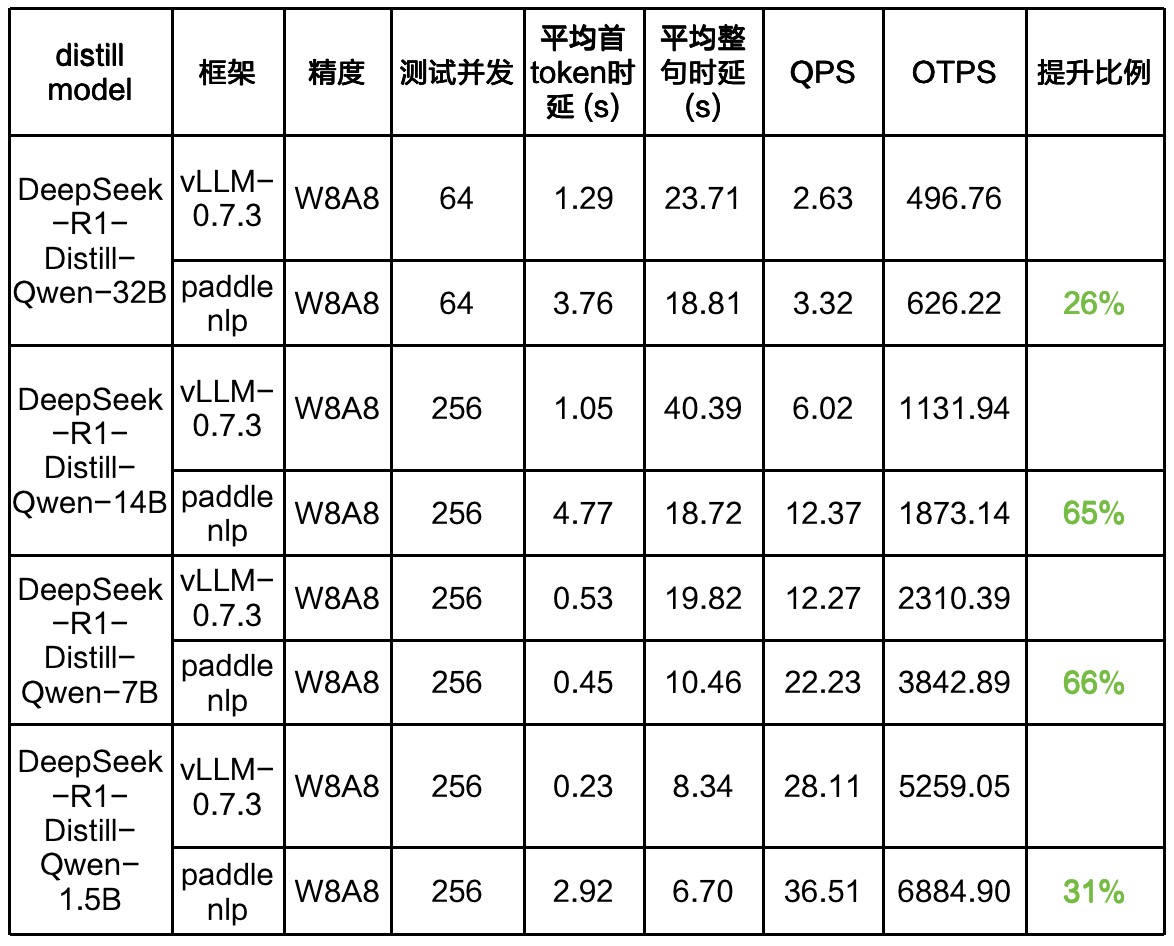
3.1 Flask & Gradio UI 服务化部署
我们提供了一套基于动态图推理的简单易用UI服务化部署方法,用户可以快速部署服务化推理,并支持gradio图形化界面快速开启对话,配置参数请参见推理文档(文末文档【8】)。
# 单卡,可以使用 paddle.distributed.launch 启动多卡推理
python ./predict/flask_server.py \
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
--port 8010 \
--flask_port 9965 \
--dtype "float16"
3.2大模型服务化部署工具
该部署工具基于Triton Inference Server开发,支持gRPC、HTTP协议的服务接口,以及流式Token输出能力。底层推理引擎支持连续批处理、weight only int8、后训练量化(PTQ)等加速优化策略,为用户带来易用且高性能的部署体验。
基于预编译镜像部署,本节以DeepSeek-R1-Distill-Qwen-7B为例,用户训练后模型需要动转静后进行部署服务,更详细的模型动转静教程可以参考大模型动转静教程(文末文档【8】)。
export MODEL_PATH=${MODEL_PATH:-$PWD}
export model_name=${model_name:-"deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/weight_only_int8"}
docker run -i --rm --gpus all --shm-size 32G --network=host --privileged --cap-add=SYS_PTRACE \
-v $MODEL_PATH:/models -e "model_name=${model_name}" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 /bin/bash \
-c -ex 'start_server $model_name && tail -f /dev/null'
以上两种方式任意一种成功部署后,用户可以API形式访问,直接使用 curl 调用开始对话,
curl 127.0.0.1:9965/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"message": [{"role": "user", "content": " 珍妮特的鸭子每天下16个蛋。她每天早上吃三个作为早餐,还用四个给朋友们烤松饼。她每天将剩余的鸭蛋以每个2美元的价格在农贸市场上出售。她每天在农贸市场上赚多少美元?"}]}'
或者使用OpenAI格式调用:
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:9965/v1/",
)
# Completion API
stream = True
completion = client.chat.completions.create(
model="default",
messages=[
{"role": "user", "content": " 珍妮特的鸭子每天下16个蛋。她每天早上吃三个作为早餐,还用四个给朋友们烤松饼。她每天将剩余的鸭蛋以每个2美元的价格在农贸市场上出售。她每天在农贸市场上赚多少美元?"}
],
max_tokens=1024,
stream=stream,
)
if stream:
for c in completion:
print(c.choices[0].delta.content, end="")
else:
print(completion.choices[0].message.content)
PaddleNLP 链接:https://github.com/PaddlePaddle/PaddleNLP
精彩课程预告
为了帮助您迅速且深入地了解DeepSeek-R1全流程蒸馏方案,百度研发工程师将于 3月25日(周二)19:00 为您深度解析。此外,我们还将开设针对DeepSeek-R1全流程蒸馏的PaddleNLP实战营,手把手带您体验从数据蒸馏、模型训练、模型评估到模型部署的完整开发流程。机会难得,立即点击链接报名:https://www.wjx.top/vm/hdJ80Xf.aspx?udsid=330931

文档【1】:
https://paddlenlp.readthedocs.io/zh/latest/llm/docs/predict/deepseek.html
文档【2】:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/application/distill
文档【3】:
https://huggingface.co/datasets/PaddlePaddle/GSM8K_distilled_zh
文档【4】:
https://huggingface.co/datasets/meta-math/GSM8K_zh
文档【5】:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/finetune.md
文档【6】:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/application/distill/sft_argument.json
文档【7】:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/application/distill/distill_eval.py
文档【8】:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/predict/inference.md

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)