DeepSeek在transformer中做了哪些优化?-多头潜在注意力
在自注意力机制中,输入序列的每个元素首先被映射到三个向量:查询(Q)、键(K)和值(V)。在自注意力中,每个元素都会有一个对应的键向量,它与查询向量一起决定了注意力分数。在自注意力(Self-Attention)机制中,查询(Query,简称Q)、键(Key,简称K)和值(Value,简称V)是三个核心的概念,它们共同参与计算以生成序列的加权表示。在自注意力机制中,每个元素都会生成一个对应的查询向
自注意力机制:通过计算序列中每个元素之间的关系,动态调整每个元素的表示,使其能够捕获整个输入序列的上下文信息。
*注意力机制详解
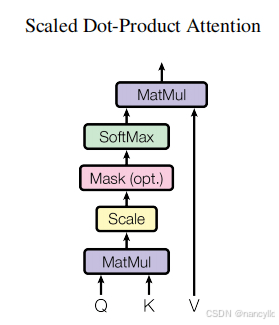
自注意力机制的计算过程可以被分解为几个关键步骤。
- 输入序列被映射到查询(Query)、键(Key)和值(Value)三个向量。
- 通过计算查询向量与所有键向量之间的点积来获得注意力得分。这些得分随后被缩放并经过Softmax函数进行归一化,以获得每个元素的注意力权重。
- 这些权重被用来对值向量进行加权求和,生成最终的输出序列。
Q、K、V的生成
在自注意力(Self-Attention)机制中,查询(Query,简称Q)、键(Key,简称K)和值(Value,简称V)是三个核心的概念,它们共同参与计算以生成序列的加权表示。
查询(Query,Q)
查询向量Q代表了当前元素在序列中的作用,它用于“询问”序列中的其他元素以获取相关信息。在自注意力机制中,每个元素都会生成一个对应的查询向量,该向量用于与序列中的所有键向量进行比较,以确定每个元素的重要性或相关性。
键(Key,K)
键向量K包含了序列中每个元素的特征信息,这些信息将用于与查询向量进行匹配。键向量的主要作用是提供一种机制,使得模型能够识别和比较序列中不同元素之间的关系。在自注意力中,每个元素都会有一个对应的键向量,它与查询向量一起决定了注意力分数。
值(Value,V)
值向量V包含了序列中每个元素的实际信息或特征,这些信息将根据注意力分数被加权求和,以生成最终的输出。值向量代表了序列中每个元素的具体内容,它们是模型最终用于生成输出的原始数据。
![]()
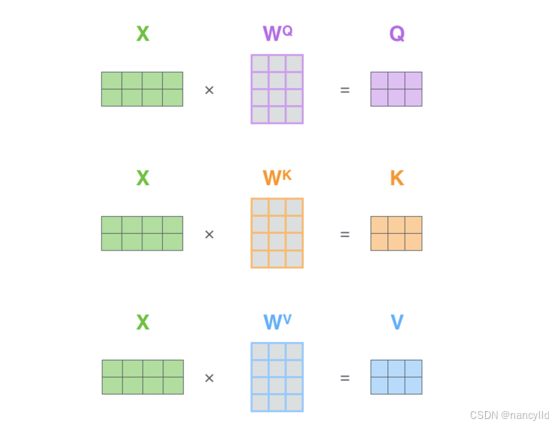
在自注意力机制中,输入序列的每个元素首先被映射到三个向量:查询(Q)、键(K)和值(V)。这一过程通常通过与三个权重矩阵的线性变换实现。具体来说,输入序列X与权重矩阵W^Q、W^K和W^V相乘,得到Q、K和V:
其中,X是输入序列,W^Q、W^K和W^V是可学习的权重矩阵。这些矩阵的维度通常是(序列长度,特征维度)乘以(特征维度,Q/K/V维度)。Q、K和V的维度是(序列长度,Q/K/V维度)。
这三个变换可以看作是对原始输入的一种重新编码,目的是从不同角度提取信息,以便后续计算注意力分数时能够更有效地捕捉到元素间的相关性。
缩放点积计算注意力得分
自注意力机制中,查询向量Q与所有键向量K之间的点积被用来计算注意力得分。为了避免点积结果过大导致梯度问题,引入了一个缩放因子1/√dk,其中dk是键向量的维度。缩放后的注意力得分计算如下:


这个操作生成了一个注意力得分矩阵,其中每个元素代表对应元素对之间的相似度。
加权求和生成输出
最后,归一化的注意力权重被用来对值向量V进行加权求和,生成最终的输出序列。输出序列的每个元素是所有值向量的一个加权和,权重由对应的注意力权重决定:

这一步骤有效地整合了序列内部的信息,使得每个元素的输出表示包含了整个序列的上下文信息。
deepseek在注意力机制中的优化
Multi-Head机制是在Self-Attention基础上的扩展,用于提升模型的表达能力。它通过多个“头”并行计算不同维度的注意力信息,使模型可以从多种角度理解序列。
(1)单个注意力头的局限性:如果只有一个头,模型只能关注序列中某一特定方面的关系,可能忽略其他重要信息。
(2)多头的优势:多个注意力头可以在不同的子空间中独立学习,这样即使是同一个输入序列,不同的头也能捕捉到不同层次的特征。最终,这些特征会被整合到一起,形成更全面的表示。
例如,在处理一句话时,一个头可能关注语法关系,另一个头可能关注语义,第三个头可能关注全局上下文。通过多头机制,模型能够同时捕获多种不同层次的信息,提高对输入序列的理解能力。
(2)无辅助损失的负载均衡策略:针对大型模型训练中常见的资源分配不均问题, DeepSeek-V3通过创新的策略确保计算资源在编码和解码阶段都能被充分利用。
(3)多Token预测目标:解码器可以一次性预测多个目标Token,提高生成速度,并在长序列生成任务中展现出明显的性能优势。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)