山东大学 软件学院 创新实训 deepseek论文分析(一)
DeepSeek是一家专注于人工智能和大型语言模型(LLMs)的中国公司,由梁文锋于2023年创立,并得到了High-Flyer对冲基金的资助。DeepSeek致力于实现通用人工智能(AGI),并以开放、高效和可访问的方式开发AI技术。DeepSeek开源了其生成式人工智能算法、模型和训练细节,允许其代码被免费使用、修改、浏览和构建。这使得全球的研究人员可以合作,创造创新的解决方案。,允许商业用途
deepseek介绍、原理、参数等学习
deepseek简介
DeepSeek是一家专注于人工智能和大型语言模型(LLMs)的中国公司,由梁文锋于2023年创立,并得到了High-Flyer对冲基金的资助。DeepSeek致力于实现通用人工智能(AGI),并以开放、高效和可访问的方式开发AI技术。
DeepSeek开源了其生成式人工智能算法、模型和训练细节,允许其代码被免费使用、修改、浏览和构建。这使得全球的研究人员可以合作,创造创新的解决方案。
-
开源许可:MIT 许可证,允许商业用途与二次开发。
DeepSeek-R1 是其核心模型,于 2025 年 1 月发布,拥有 6710 亿参数,采用混合专家(MoE)架构,仅激活部分参数进行推理,从而提高效率。研究显示,其性能在数学、编码和推理任务上可与 OpenAI 的 o1 模型相媲美,且训练成本仅约 600 万美元,远低于 OpenAI 的 GPT-4(2023 年约 1 亿美元)。
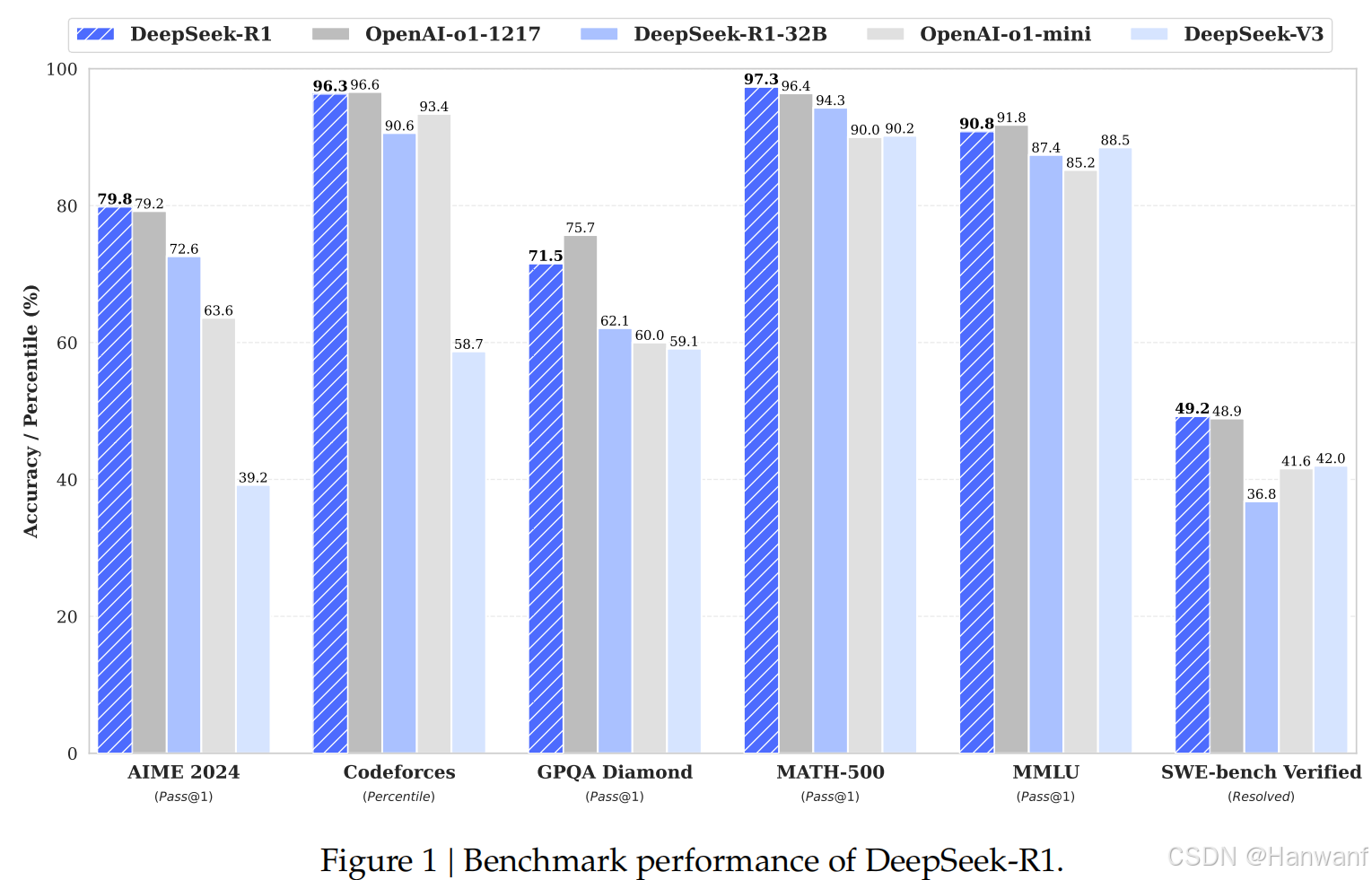
DeepSeek 的创新在于高效的 MoE 架构、RL 驱动的推理能力和开源策略,以下是关键技术对比表:
| 模型 | 参数数量 | 训练成本 | 训练方法 | 开源状态 |
|---|---|---|---|---|
| DeepSeek-R1 | 6710 亿 | ~600 万美元 | RL + 少量 SFT | MIT 许可 |
| OpenAI GPT-4 | 未知 | ~1 亿美元 | SFT + RLHF | 闭源 |
| Meta Llama 3.1 | 未知 | 高(约 10 倍计算资源) | SFT + 其他方法 | 部分开源 |
技术原理
训练原理
DeepSeek 的模型训练依赖强化学习(RL),特别是 Group Relative Policy Optimization(GRPO)方法,允许模型通过比较新旧响应来优化策略,无需单独的价值模型,从而降低计算成本。DeepSeek-R1-Zero 完全使用纯 RL 训练,展现出无需监督微调即可发展推理能力,但存在可读性和语言一致性问题。为此,DeepSeek-R1 引入了少量监督数据(冷启动阶段)来改善这些问题。
DeepSeek-R1 是一个更成熟、更实用的版本,而 DeepSeek-R1-Zero 是一个探索性的“纯强化学习”模型。DeepSeek-R1-Zero 完全依靠强化学习(RL)进行训练,没有经过监督微调(SFT)。
DeepSeek 的模型训练核心在于强化学习(RL),特别是 Group Relative Policy Optimization(GRPO)方法。GRPO 是一种无需价值模型(Critic)的 RL 算法,通过组内比较优化策略,降低内存和计算开销。根据 Medium 文章,RL 在 LLM 上下文中用于对齐模型输出,如事实准确性、逻辑一致性和类人推理,特别适用于数学、编码和逻辑推理任务。
- 奖励系统:DeepSeek 使用基于规则的奖励系统,特别是在可验证任务(如数学和编码)中,奖励基于最终答案的正确性,而非中间步骤。 Techtarget 文章,这种方法优于常见的神经奖励模型,允许模型探索更高效的推理策略,而无需大量标记数据。
- 多阶段训练:DeepSeek-R1 采用多阶段训练,先通过少量监督数据(冷启动)改善可读性和语言一致性,然后应用 RL 进一步优化。冷启动数据包括数千个精心挑选的链式思维(CoT)示例,覆盖常识问答、基础数学和标准指令任务, Vellum AI 博客。
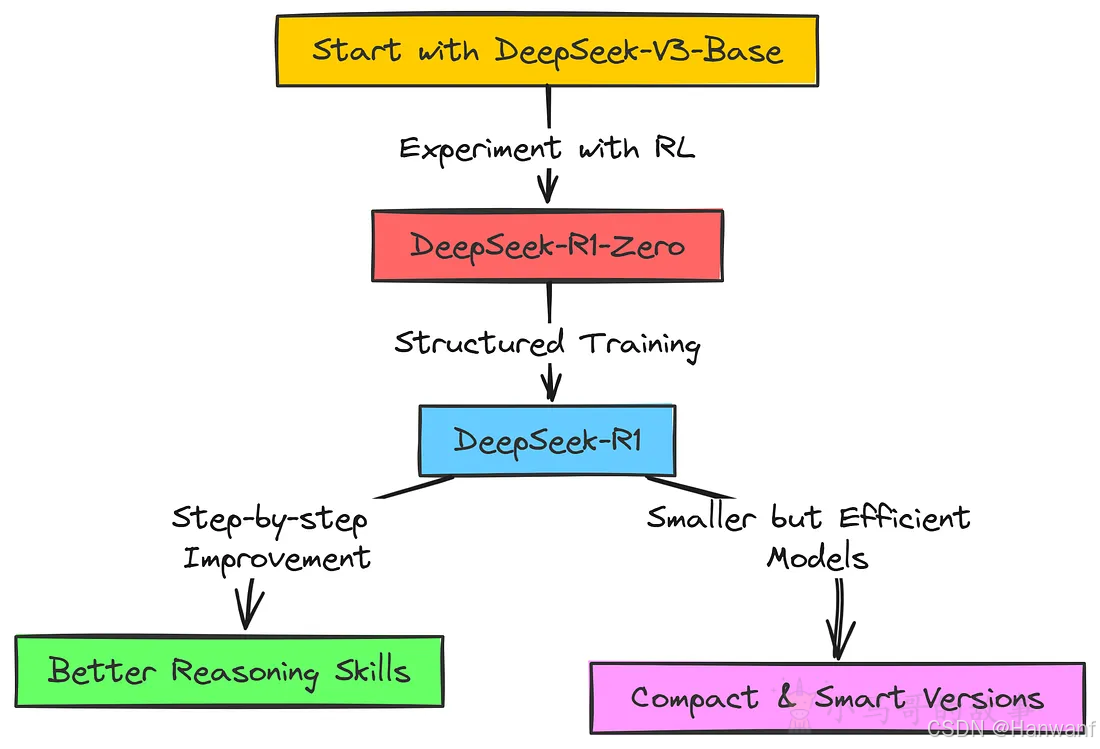
整体训练流程:
基座模型:DeepSeek v3
DeepSeek v3主要特点是采用MoE架构,通过稀疏激活降低推理成本,同时保持大规模参数优势。
| 维度 | DeepSeek-V3 | R1-Zero | DeepSeek-R1 |
|---|---|---|---|
| 定位 | 通用基座模型 | 纯 RL 训练的推理实验模型 | 多阶段优化的商用推理模型 |
| 训练方法 | 预训练 + SFT | 纯强化学习(GRPO 算法) | SFT → RL → SFT → RL与SFT混合训练 |
| 数据依赖 | 通用语料 + 标注数据 | 数学/代码数据(无需标注) | RL 生成数据 + 人类偏好数据 |
| 推理能力 | 基础问答 | 强推理但语言混杂 | 强推理 + 语言规范 |
| 可用性 | 通用场景 | 实验性(不可直接商用) | 全场景适配(客服、编程等) |
| 开源状态 | 开源 | 未开源 | 开源 |
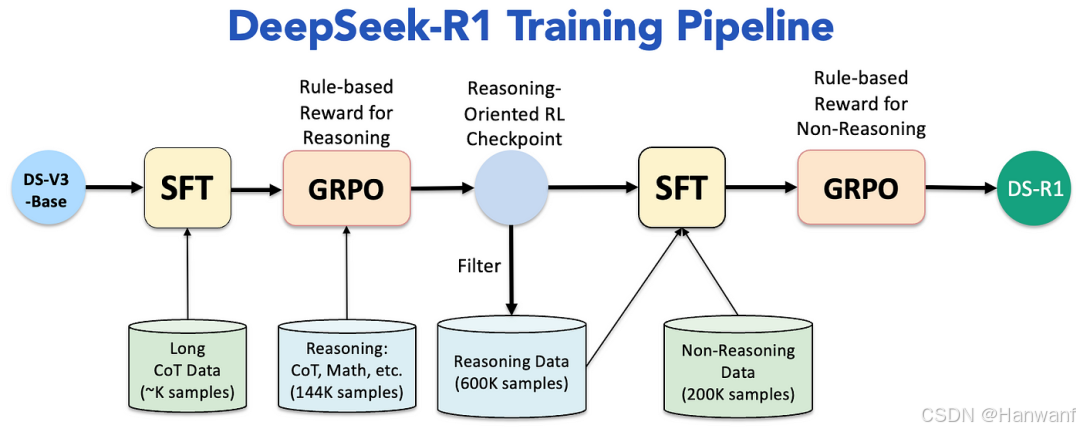
1. 监督微调(SFT)阶段
冷启动监督微调(Supervised Fine-Tuning, SFT)是深度学习,特别是在大语言模型(LLM)训练中的一个重要阶段。这里的“冷启动”指的是在模型训练的初始阶段,使用少量精心设计的高质量数据来启动训练过程,而不是直接从随机初始化的状态开始训练。冷启动 SFT 通过提供高质量的、结构化的数据(如思维链数据),帮助模型快速获得一个有效的推理框架,稳定初始训练过程。
- 目的:解决强化学习冷启动问题,提升模型输出连贯性。
- 数据来源:包含 10k Token 的长链式推理(CoT)数据,由 R1-Zero 模型生成和人工标注样本组成。
- 关键技术:通过链式思维标注优化模型对数学、编程问题的分步推理能力,并提升生成内容的可读性。
2. 推理任务强化学习阶段
- 方法:应用群体相对策略优化(GRPO),专注于数学与编程推理任务。
- GRPO 的核心思想是通过比较一组样本的奖励来估计优势函数,而不是像传统方法那样依赖于一个绝对的奖励值。这种比较的方式使得算法对奖励模型的噪声和偏差更具鲁棒性。
- 它会计算一个样本的奖励与批次中其他所有样本奖励的平均值之间的差。
- 奖励设计:
- 准确性奖励:评估答案正确性(如 LeetCode 问题是否通过编译)。
- 格式奖励:确保推理过程以标准化标记(如
<reasoning>)呈现。
- 效果:在 AIME 2024 测试集上,Pass@1 得分从 15.6% 提升至 71.0%。
3. 拒绝采样与合成数据生成
- 技术手段:使用第二阶段模型生成合成数据集,覆盖写作、角色扮演等通用任务。
- 数据量:生成约 60 万条推理相关数据及 20 万条通用任务数据,结合原有 SFT 数据集进行优化。
拒绝采样用于从模型生成的多个候选响应中选择最佳响应。具体步骤如下:
-
给定一个提示,模型会生成多个候选响应。
-
使用一个奖励模型对每个候选响应进行评分。
-
根据奖励分数和一定的规则(如拒绝阈值),选择一个最佳响应作为最终输出。这可以看作是拒绝采样的一种变体,其中奖励模型起到了评估样本质量的作用。
4. 最终强化学习优化
- 目标:结合规则与结果奖励模型,提升模型的有用性和安全性。
- 创新点:通过 GRPO 直接优化 KL 散度项,避免传统 PPO 的奖励信号干扰,显著降低内存消耗。
参数
推理时可以调整的参数:
可调推理参数
- Temperature(温度)
- 作用:控制输出的随机性。较低的值(如 0.1)使模型生成更确定性、更保守的输出;较高的值(如 1.0 或以上)增加输出的多样性和创造性。
- 推荐范围:DeepSeek 官方建议将 Temperature 设置在 0.5-0.7 之间(推荐 0.6),以避免无尽重复或不连贯的输出(见 NVIDIA NIM 文档)。
- 应用场景:对于需要严格推理的任务(如数学题),建议使用较低值;对于开放性任务(如创意写作),可适当提高。
- Top-p(核采样)
- 作用:通过核采样(nucleus sampling)控制输出分布,只从累积概率达到 p 的最小词集采样。值越小(如 0.1),输出越集中;值越大(如 0.9),输出更随机。
- 默认情况:部分推理平台可能不支持此参数(如 DeepSeek 官方 API),但在本地部署(如 Hugging Face Transformers)时可调整。
- 建议:通常设为 0.7-0.9,以平衡连贯性和多样性。
- Top-k(Top-k 采样)
- 作用:从概率最高的前 k 个词中采样。值越小,输出越确定;值越大,输出越多样。
- 可调性:在支持的框架中(如 Ollama 或 Transformers)可以调整,但 DeepSeek API 可能不支持。
- 建议:常见设置为 40-50,适用于需要控制输出范围的场景。
- Max Tokens(最大生成长度)
- 作用:限制模型生成的最大 token 数量,影响输出的长度和推理深度。
- 范围:DeepSeek-R1 支持最大上下文长度为 64K(API 版本),但具体生成长度可自由设置。
- 应用场景:对于复杂推理任务,可增加此值以允许更长的链式思维(CoT);对于简单任务,可减少以提高速度。
- 注意:过高的值可能增加推理时间和成本(见 Together AI 文档)。
- Context Window(上下文窗口大小)
- 作用:决定模型一次处理的输入 token 数量上限。
- 范围:API 版本支持 64K,本地部署可能因硬件限制需调整(如 Ollama 的 num_ctx)。
- 调整方法:在本地运行时,可根据显存大小设置(如 2048、4096),过大可能导致内存溢出(OOM)。
- Presence Penalty(存在惩罚)
- 作用:减少模型重复使用已出现词的可能性。值越高,重复越少。
- 可调性:部分平台支持(如 Hugging Face),但 DeepSeek 官方 API 可能不支持。
- 建议:通常设为 0.1-0.5,避免过度惩罚导致输出不自然。
- Frequency Penalty(频率惩罚)
- 作用:根据词出现频率施加惩罚,降低高频词的重复率。
- 可调性:同 Presence Penalty,可能受平台限制。
- 建议:与 Presence Penalty 配合使用,设为 0.1-0.5。
- Thinking Tokens(推理 token 控制)
- 作用:DeepSeek-R1 擅长链式思维(CoT),可通过强制输出 <think> 标签控制推理过程的显式性。
- 调整方法:在提示中添加指令(如 “以 <think> 开始”),或通过 API 参数强制启用(见 Hugging Face 模型卡建议)。
- 效果:增加此参数可提升复杂任务的准确性,但会延长输出时间。
- Batch Size(批处理大小)
- 作用:控制并行处理的请求数量,影响吞吐量。
- 适用场景:主要用于服务器端推理(如 SGLang 或 Fireworks AI),单用户本地运行通常为 1。
- 范围:根据硬件支持可设为 1-128(如 AMD MI300X 测试中提到)。
- Quantization(量化级别)
- 作用:调整模型推理时的精度(如 FP8、4-bit、1.58-bit),影响速度和显存占用。
- 选项:
- FP8:原始精度,需高端 GPU(如 H200)。
- 4-bit(如 Q4_K_M):占用 404GB,速度较慢(2-4 token/s)。
- 1.58-bit(如 UD-IQ1_S):占用 131GB,速度较快(7-8 token/s)。
- 调整方法:在本地部署时选择量化版本(如 Unsloth 或 Ollama)。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)