DeepSeek-V3 技术报告 (Introduction)
其对话版本也超越了其他开源模型,并在一系列标准和开放式基准测试中达到了与领先闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当的性能。在工程相关任务中,虽然DeepSeek-V3的表现略低于Claude-Sonnet-3.5,但仍以显著优势超越所有其他模型,展示了其在多样化技术基准测试中的竞争力。最后,总结了这项工作,讨论了DeepSeek-V3的现有局限性,并提出了未来研究

Abstract
We present DeepSeek-V3 , a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token . To achieve efficient inference and cost-effective training , DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures , which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens , followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3 .
推出了 DeepSeek-V3 ,一个强大的混合专家(MoE)语言模型,具有 6710亿总参数 ,其中每个Token激活 370亿参数 。为了实现高效的推理和经济高效的训练,DeepSeek-V3 采用了 多头潜在注意力(MLA) 和 DeepSeekMoE 架构 ,这些架构在 DeepSeek-V2 中得到了充分验证。此外,DeepSeek-V3 首次提出了一种 无辅助损失的负载均衡策略 ,并设置了 多Token预测训练目标 以提升性能。在 14.8万亿高质量多样化的Token 上对 DeepSeek-V3 进行预训练,并通过监督微调(SFT)和强化学习(RL)阶段充分释放其潜力。综合评估表明,DeepSeek-V3 在性能上超越了其他开源模型 ,并达到了与领先的闭源模型相当的水平。尽管性能卓越,DeepSeek-V3 的完整训练仅需 278.8万H800 GPU小时 。此外,其训练过程非常稳定,在整个训练过程中未出现不可恢复的损失峰值或回滚操作。
Introduction
In recent years, Large Language Models (LLMs) have been undergoing rapid iteration and evolution (Anthropic, 2024; Google, 2024; OpenAI, 2024a), progressively diminishing the gap towards Artificial General Intelligence (AGI) . Beyond closed-source models, open-source models, including DeepSeek series (DeepSeek-AI, 2024a,b,c; Guo et al., 2024), LLaMA series (AI@Meta, 2024a,b; Touvron et al., 2023a,b), Qwen series (Qwen, 2023, 2024a,b), and Mistral series (Jiang et al., 2023; Mistral, 2024), are also making significant strides, endeavoring to close the gap with their closed-source counterparts. To further push the boundaries of open-source model capabilities, we scale up our models and introduce DeepSeek-V3 , a large Mixture-of-Experts (MoE) model with 671B parameters , of which 37B are activated for each token.
With a forward-looking perspective, we consistently strive for strong model performance and economical costs . Therefore, in terms of architecture, DeepSeek-V3 still adopts Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for efficient inference and DeepSeekMoE (Dai et al., 2024) for cost-effective training. These two architectures have been validated in DeepSeek-V2 (DeepSeek-AI, 2024c), demonstrating their capability to maintain robust model performance while achieving efficient training and inference. Beyond the basic architecture, we implement two additional strategies to further enhance the model capabilities. Firstly, DeepSeek-V3 pioneers an auxiliary-loss-free strategy (Wang et al., 2024a) for load balancing, with the aim of minimizing the adverse impact on model performance that arises from the effort to encourage load balancing. Secondly, DeepSeek-V3 employs a multi-token prediction training objective , which we have observed to enhance the overall performance on evaluation benchmarks.
近年来,大型语言模型(LLMs)经历了快速迭代和演进(Anthropic, 2024; Google, 2024; OpenAI, 2024a),逐步缩小与 通用人工智能(AGI) 的差距。除了闭源模型外,开源模型也取得了显著进展,包括 DeepSeek 系列 (DeepSeek-AI, 2024a,b,c; Guo et al., 2024)、LLaMA 系列 (AI@Meta, 2024a,b; Touvron et al., 2023a,b)、Qwen 系列 (Qwen, 2023, 2024a,b)和 Mistral 系列 (Jiang et al., 2023; Mistral, 2024),努力缩小与闭源模型之间的差距。为了进一步突破开源模型的能力边界,扩展了模型规模并推出了 DeepSeek-V3 ,一个拥有 6710亿参数 的大规模混合专家(MoE)模型,其中 每个Token激活370亿参数 。
以前瞻性视角,始终追求 强大的模型性能和经济成本 。因此,在架构设计上,DeepSeek-V3 继续采用 多头潜在注意力(MLA) (DeepSeek-AI, 2024c)以实现高效推理,并采用 DeepSeekMoE (Dai et al., 2024)以降低训练成本。这两种架构在 DeepSeek-V2 中得到了验证,展示了它们在保持模型性能的同时实现高效训练和推理的能力。除此之外,还实施了两项额外策略以进一步增强模型能力。首先,DeepSeek-V3 首次提出了一种 无辅助损失的负载均衡策略 (Wang et al., 2024a),旨在最小化因鼓励负载均衡而对模型性能产生的负面影响。其次,DeepSeek-V3 引入了 多Token预测训练目标 ,观察到它显著提升了在评估基准上的整体性能。
In order to achieve efficient training , we support the FP8 mixed precision training and implement comprehensive optimizations for the training framework. Low-precision training has emerged as a promising solution for efficient training (Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b), its evolution being closely tied to advancements in hardware capabilities (Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a). In this work, we introduce an FP8 mixed precision training framework and, for the first time, validate its effectiveness on an extremely large-scale model. Through the support for FP8 computation and storage, we achieve both accelerated training and reduced GPU memory usage . As for the training framework, we design the DualPipe algorithm for efficient pipeline parallelism, which has fewer pipeline bubbles and hides most of the communication during training through computation-communication overlap. This overlap ensures that, as the model further scales up, as long as we maintain a constant computation-to-communication ratio, we can still employ fine-grained experts across nodes while achieving a near-zero all-to-all communication overhead. In addition, we also develop efficient cross-node all-to-all communication kernels to fully utilize InfiniBand (IB) and NVLink bandwidths . Furthermore, we meticulously optimize the memory footprint, making it possible to train DeepSeek-V3 without using costly tensor parallelism. Combining these efforts, we achieve high training efficiency.
During pre-training, we train DeepSeek-V3 on 14.8T high-quality and diverse tokens . The pre-training process is remarkably stable. Throughout the entire training process, we did not encounter any irrecoverable loss spikes or have to roll back. Next, we conduct a two-stage context length extension for DeepSeek-V3 . In the first stage, the maximum context length is extended to 32K , and in the second stage, it is further extended to 128K . Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3 , to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length .
We evaluate DeepSeek-V3 on a comprehensive array of benchmarks. Despite its economical training costs, comprehensive evaluations reveal that DeepSeek-V3-Base has emerged as the strongest open-source base model currently available , especially in code and math . Its chat version also outperforms other open-source models and achieves performance comparable to leading closed-source models, including GPT-4o and Claude-3.5-Sonnet , on a series of standard and open-ended benchmarks.
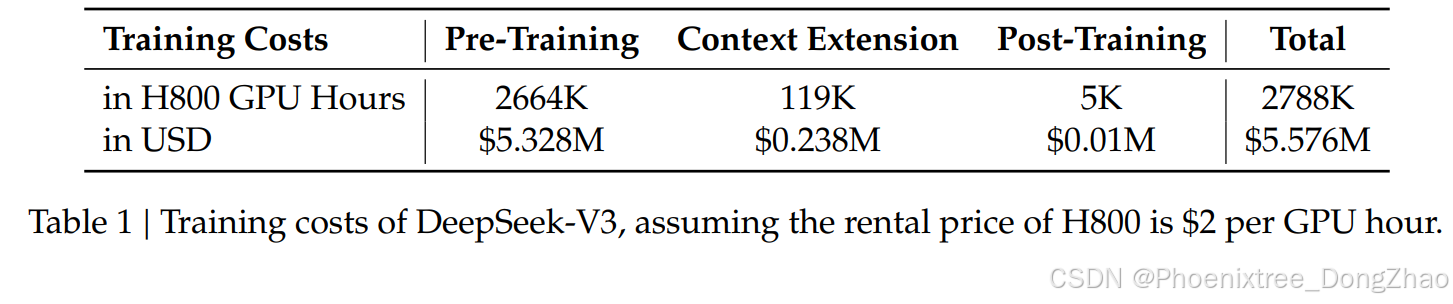
Lastly, we emphasize again the economical training costs of DeepSeek-V3 , summarized in Table 1, achieved through our optimized co-design of algorithms, frameworks, and hardware. During the pre-training stage, training DeepSeek-V3 on each trillion tokens requires only 180K H800 GPU hours , i.e., 3.7 days on our cluster with 2048 H800 GPUs . Consequently, our pre-training stage is completed in less than two months and costs 2664K GPU hours . Combined with 119K GPU hours for the context length extension and 5K GPU hours for post-training, DeepSeek-V3 costs only 2.788M GPU hours for its full training. Assuming the rental price of the H800 GPU is $2 per GPU hour , our total training costs amount to only $5.576M . Note that the aforementioned costs include only the official training of DeepSeek-V3 , excluding the costs associated with prior research and ablation experiments on architectures, algorithms, or ata.
为了实现高效训练,支持 FP8混合精度训练 并对训练框架进行了全面优化。低精度训练已成为高效训练的有前景解决方案(Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b),其发展与硬件能力的进步密切相关(Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a)。在本研究中,引入了 FP8 混合精度训练框架,并首次验证了其在超大规模模型上的有效性。通过支持 FP8 计算和存储,实现了 加速训练并减少了GPU内存使用 。在训练框架方面,设计了 DualPipe 算法 以实现高效的流水线并行,减少了流水线气泡并通过计算-通信重叠隐藏了大部分训练中的通信开销。这种重叠确保了即使模型进一步扩展,只要保持恒定的计算-通信比率,仍能在节点间使用细粒度专家,同时实现接近零的全互连通信开销。此外,还开发了高效的跨节点全互连通信内核,以充分利用 InfiniBand(IB) 和 NVLink 带宽 。最后,精心优化了内存占用,使得无需昂贵的张量并行即可训练 DeepSeek-V3。通过这些努力,实现了 高训练效率 。
在预训练阶段,在 14.8万亿高质量多样化Token 上对 DeepSeek-V3 进行训练。预训练过程非常稳定,整个训练过程中未出现不可恢复的损失峰值或需要回滚的情况。接下来,对 DeepSeek-V3 实施了两阶段上下文长度扩展。第一阶段将最大上下文长度扩展至 32K ,第二阶段进一步扩展至 128K 。随后,进行后训练,包括对 DeepSeek-V3 基础模型的 监督微调(SFT) 和 强化学习(RL) ,以使其符合人类偏好并进一步释放潜力。在后训练阶段,从 DeepSeek-R1 系列模型中蒸馏推理能力,同时谨慎地平衡模型准确性和生成长度。
对 DeepSeek-V3 在一系列综合基准测试中进行了评估。尽管其训练成本经济实惠,但综合评估显示,DeepSeek-V3-Base 已成为目前最强的开源基础模型 ,特别是在代码和数学领域表现尤为突出。其对话版本也超越了其他开源模型,并在一系列标准和开放式基准测试中达到了与领先闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当的性能。
最后,再次强调 DeepSeek-V3 的经济训练成本 ,详见表1,这是通过算法、框架和硬件的协同优化实现的。在预训练阶段,每万亿Token的训练仅需 18万H800 GPU小时 ,即在配备2048个H800 GPU的集群上耗时 3.7天 。因此,预训练阶段在不到两个月内完成,总计消耗 266.4万GPU小时 。加上上下文长度扩展所需的 11.9万GPU小时 和后训练所需的 5千GPU小时 ,DeepSeek-V3 的完整训练仅需 278.8万GPU小时 。假设 H800 GPU 的租赁价格为每小时2美元,总训练成本仅为 557.6万美元 。需要注意的是,上述成本仅包括 DeepSeek-V3 的正式训练,不包括与架构、算法或数据相关的前期研究和消融实验的成本。
Main contribution
Architecture: Innovative Load Balancing Strategy and Training Objective
- On top of the efficient architecture of DeepSeek-V2, we pioneer an auxiliary-loss-free strategy for load balancing , which minimizes the performance degradation that arises from encouraging load balancing.
- We investigate a Multi-Token Prediction (MTP) objective and prove it beneficial to model performance. It can also be used for speculative decoding for inference acceleration.
Pre-Training: Towards Ultimate Training Efficiency
- We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 training on an extremely large-scale model.
- Through the co-design of algorithms, frameworks, and hardware , we overcome the communication bottleneck in cross-node MoE training, achieving near-full computation-communication overlap. This significantly enhances our training efficiency and reduces the training costs, enabling us to further scale up the model size without additional overhead.
- At an economical cost of only 2.664M H800 GPU hours , we complete the pre-training of DeepSeek-V3 on 14.8T tokens, producing the currently strongest open-source base model. The subsequent training stages after pre-training require only 0.1M GPU hours.
Post-Training: Knowledge Distillation from DeepSeek-R1
- We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model , specifically from one of the DeepSeek R1 series models, into standard LLMs, particularly DeepSeek-V3. Our pipeline elegantly incorporates the verification and reflection patterns of R1 into DeepSeek-V3 and notably improves its reasoning performance. Meanwhile, we also maintain control over the output style and length of DeepSeek-V3.
主要贡献
架构:创新的负载均衡策略与训练目标
- 在DeepSeek-V2高效架构的基础上,开创了一种无辅助损失的负载均衡策略 ,最大限度地减少了因鼓励负载均衡而带来的性能下降。
- 研究了多Token预测(MTP)目标,并证明其对模型性能有益 。它还可用于推测性解码以加速推理。
预训练:实现极致的训练效率
- 设计了一个FP8混合精度训练框架,并首次验证了FP8训练在超大规模模型上的可行性和有效性 。
- 通过算法、框架和硬件的协同设计 ,克服了跨节点MoE训练中的通信瓶颈,实现了接近完全的计算-通信重叠。这显著提高了训练效率并降低了训练成本,使能够在不增加额外开销的情况下进一步扩展模型规模。
- 仅以266.4万H800 GPU小时的经济成本 ,在14.8万亿Token上完成了DeepSeek-V3的预训练,生成了目前最强的开源基础模型。预训练后的后续训练阶段仅需0.1万GPU小时。
后训练:从DeepSeek-R1进行知识蒸馏
- 引入了一种创新方法,将长链思维(CoT)模型的推理能力蒸馏到标准LLM中 ,特别是从DeepSeek R1系列模型之一蒸馏到DeepSeek-V3。流程优雅地将R1的验证和反思模式整合到DeepSeek-V3中,显著提升了其推理性能。同时,还保持了对DeepSeek-V3输出风格和长度的控制。
Summary of Core Evaluation Results
-
Knowledge:
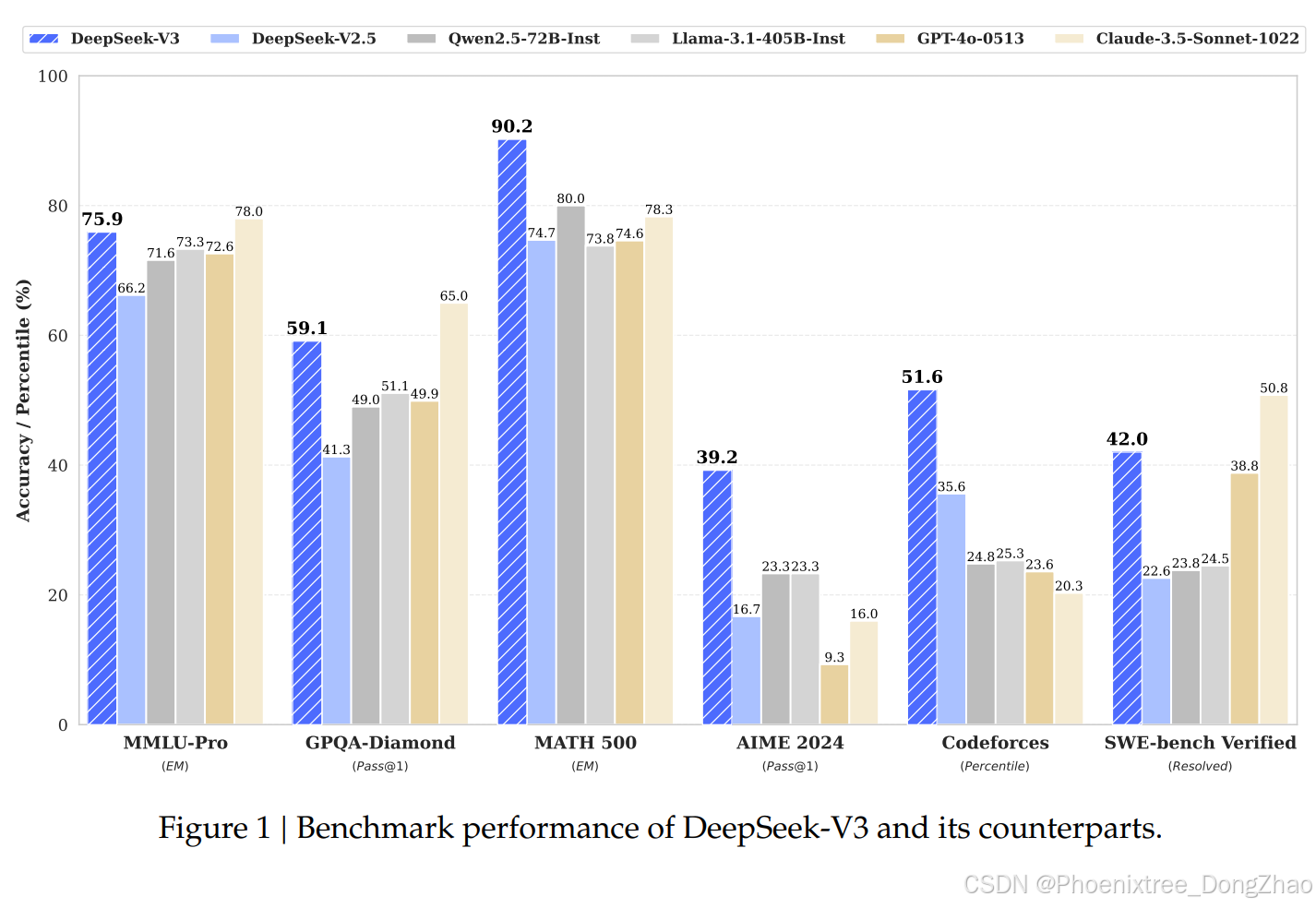
- (1) On educational benchmarks such as MMLU, MMLU-Pro, and GPQA, DeepSeek-V3 outperforms all other open-source models , achieving 88.5 on MMLU , 75.9 on MMLU-Pro , and 59.1 on GPQA . Its performance is comparable to leading closed-source models like GPT-4o and Claude-Sonnet-3.5, narrowing the gap between open-source and closed-source models in this domain.
- (2) For factuality benchmarks, DeepSeek-V3 demonstrates superior performance among open-source models on both SimpleQA and Chinese SimpleQA . While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual knowledge (SimpleQA), it surpasses these models in Chinese factual knowledge (Chinese SimpleQA) , highlighting its strength in Chinese factual knowledge.
-
Code, Math, and Reasoning:
- (1) DeepSeek-V3 achieves state-of-the-art performance on math-related benchmarks among all non-long-CoT open-source and closed-source models. Notably, it even outperforms o1-preview on specific benchmarks, such as MATH-500 , demonstrating its robust mathematical reasoning capabilities.
- (2) On coding-related tasks, DeepSeek-V3 emerges as the top-performing model for coding competition benchmarks , such as LiveCodeBench, solidifying its position as the leading model in this domain. For engineering-related tasks, while DeepSeek-V3 performs slightly below Claude-Sonnet-3.5, it still outpaces all other models by a significant margin , demonstrating its competitiveness across diverse technical benchmarks.
核心评估结果总结
知识:
(1) 在教育类基准测试(如MMLU、MMLU-Pro和GPQA)中,DeepSeek-V3超越了所有其他开源模型 ,在MMLU上达到88.5分,在MMLU-Pro上达到75.9分,在GPQA上达到59.1分。其性能与领先的闭源模型(如GPT-4o和Claude-Sonnet-3.5)相当,缩小了开源模型与闭源模型在此领域的差距。
(2) 在事实性基准测试中,DeepSeek-V3在SimpleQA和Chinese SimpleQA上表现出色 。尽管在英语事实知识(SimpleQA)上落后于GPT-4o和Claude-Sonnet-3.5,但在中文事实知识(Chinese SimpleQA)上超越了这些模型 ,突显了其在中文事实知识方面的优势。
代码、数学和推理:
(1) DeepSeek-V3在数学相关基准测试中,在所有非长链思维的开源和闭源模型中取得了最先进的性能 。特别是在某些基准测试(如MATH-500)上,甚至超越了o1-preview,展示了其强大的数学推理能力。
(2) 在编码相关任务中,DeepSeek-V3在编程竞赛基准测试(如LiveCodeBench)中表现最佳 ,巩固了其在此领域的领先地位。在工程相关任务中,虽然DeepSeek-V3的表现略低于Claude-Sonnet-3.5,但仍以显著优势超越所有其他模型,展示了其在多样化技术基准测试中的竞争力。
In the remainder of this paper , we first present a detailed exposition of our DeepSeek-V3 model architecture (Section 2) . Subsequently, we introduce our infrastructures, encompassing our compute clusters, the training framework, the support for FP8 training, the inference deployment strategy, and our suggestions on future hardware design. Next, we describe our pre-training process , including the construction of training data, hyper-parameter settings, long-context extension techniques, the associated evaluations, as well as some discussions (Section 4 ). Thereafter, we discuss our efforts on post-training , which include Supervised Fine-Tuning (SFT), Reinforcement Learning (RL), the corresponding evaluations, and discussions (Section 5 ). Lastly, we conclude this work, discuss existing limitations of DeepSeek-V3, and propose potential directions for future research (Section 6 ).
论文其余部分结构
在本文的其余部分,首先详细介绍了DeepSeek-V3模型架构(第2节) 。随后,介绍了基础设施,包括计算集群、训练框架、FP8训练支持、推理部署策略以及对未来硬件设计的建议。接下来,描述了预训练过程(第4节) ,包括训练数据的构建、超参数设置、长上下文扩展技术、相关评估以及一些讨论。之后,讨论了后训练工作(第5节) ,包括监督微调(SFT)、强化学习(RL)、相应的评估和讨论。最后,总结了这项工作,讨论了DeepSeek-V3的现有局限性,并提出了未来研究的潜在方向(第6节)。
Architecture
基本架构(Basic Architecture)
多头潜在注意力(MLA)的优化
- 核心目标 :在保持性能的同时减少推理时的内存占用。
- 实现细节 :
- 潜在上下文向量通过 分块矩阵乘法(TMA) 和 低精度计算(FP8) 加速,确保高效推理。
- 通过 动态缓存管理 支持长上下文扩展(如128K),避免传统注意力机制的二次复杂度问题。
DeepSeekMoE的无辅助损失负载均衡策略
- 传统问题 :MoE模型中辅助损失(auxiliary loss)可能导致性能下降。
- 创新设计 :
- 无辅助损失(Auxiliary-Loss-Free) :通过门控机制直接优化专家负载均衡,无需额外辅助损失函数。
- 专家分割与路由 :
- 每个FFN被分割为 更细粒度的专家 (如将单专家分解为 m 个小专家),激活参数量保持为 37B/Token ,总参数量扩展至 671B 。
- 引入 共享专家 固定激活,避免冗余参数;路由专家动态选择,提升专业化。
- 负载均衡效果 :
- 通过 门控权重归一化 (如Sigmoid函数)和 Top-K路由策略 ,确保专家负载分布更均衡。
- 实验证明,无辅助损失策略在 专家专业化模式 上显著优于传统方法。
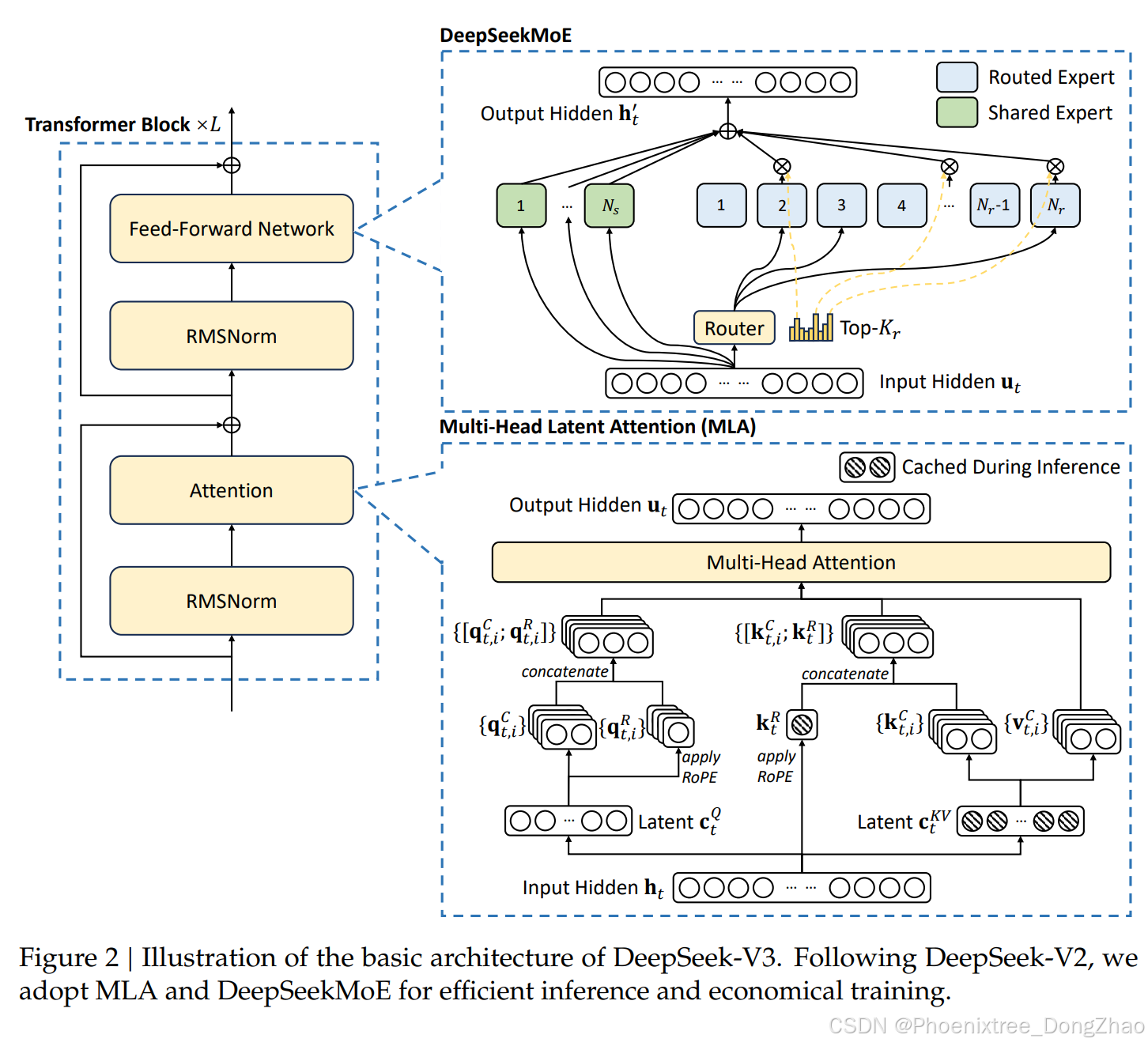
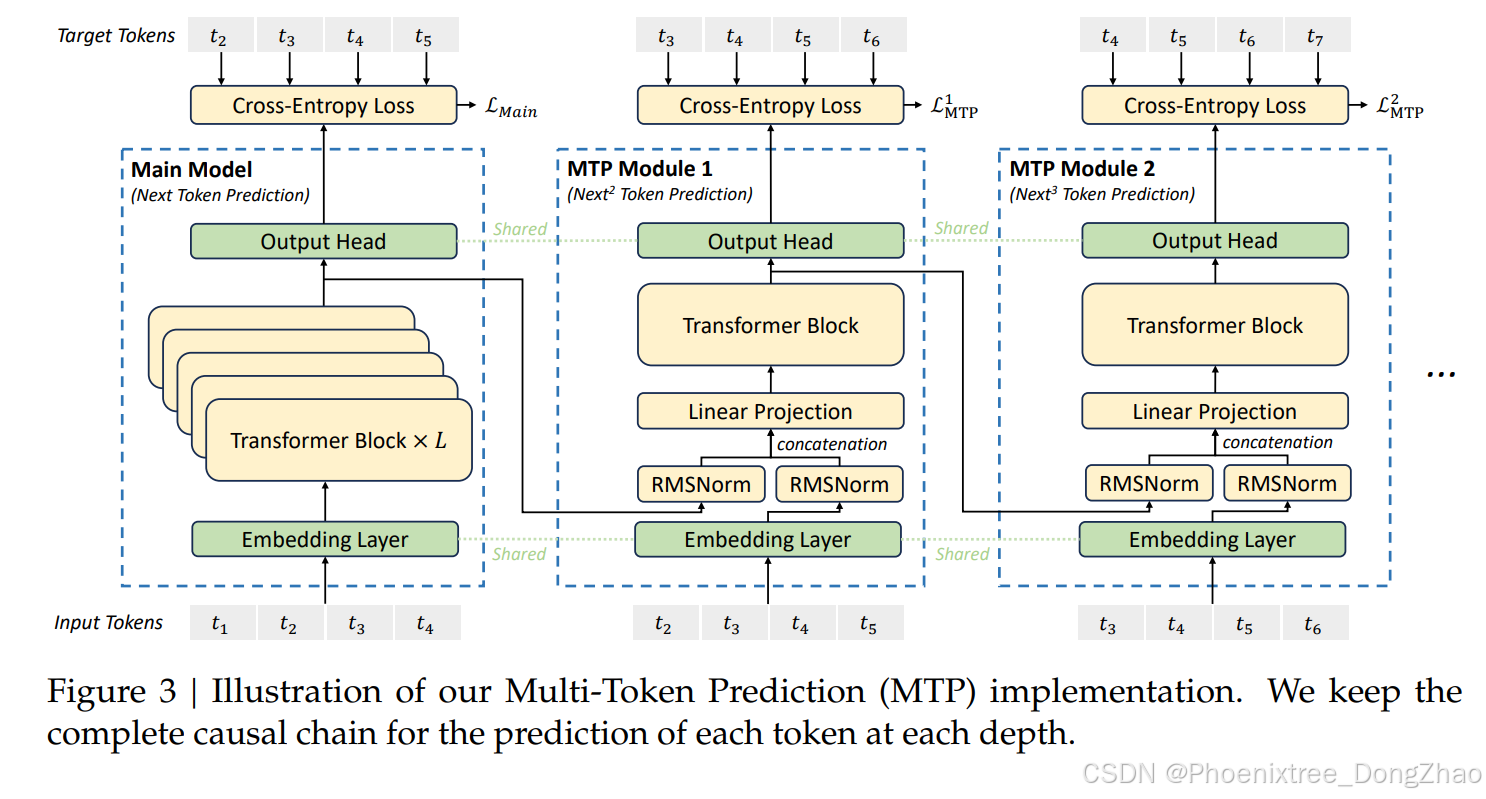
多Token预测目标(Multi-Token Prediction, MTP)
- 核心思想 :在训练中同时预测多个Token,增强模型对上下文依赖的建模能力。
- 实现方式 :
- 在基础模型中添加 1层深度的MTP模块 ,通过并行生成多个Token的预测结果。
- 支持 推测性解码(speculative decoding) ,加速推理过程。
- 效果验证 :
- 在小规模(15.7B参数)和大规模(228.7B参数)模型中均观察到性能提升,尤其在数学和代码任务中表现突出。
- MTP 训练目标:
- 对于每个预测深度,计算交叉熵损失
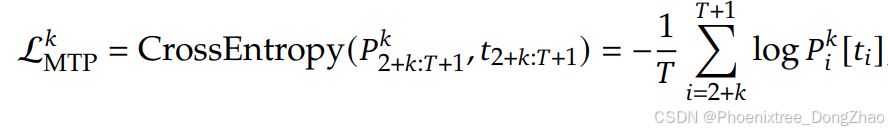
- 推理中的MTP:
- MTP策略主要是为了提高主模型的性能,所以在推理过程中,可以直接丢弃MTP模块,主模型可以独立正常工作。此外,还可以将这些MTP模块重新用于推测解码,以进一步改善生成延迟。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)