剖析DeepSeek火爆的原因,现在流行的模型都有哪些,都有什么区别呢?
技术架构创新与成本优势DeepSeek的核心竞争力在于其混合专家(MoE)架构与稀疏注意力机制的融合。MoE架构通过动态分配计算资源,仅激活与当前任务相关的专家网络模块,使得模型在保持高参数规模(如R1版本的6700亿参数)的同时,推理成本仅为传统密集模型的1/3。例如,其V3模型训练成本仅558万美元,却能达到接近GPT-4o的性能。这种“低成本高密度算力利用”直接颠覆了大模型领域的“烧钱竞赛”
一、DeepSeek模型火爆的核心原因剖析
-
技术架构创新与成本优势
DeepSeek的核心竞争力在于其混合专家(MoE)架构与稀疏注意力机制的融合。MoE架构通过动态分配计算资源,仅激活与当前任务相关的专家网络模块,使得模型在保持高参数规模(如R1版本的6700亿参数)的同时,推理成本仅为传统密集模型的1/3。例如,其V3模型训练成本仅558万美元,却能达到接近GPT-4o的性能。这种“低成本高密度算力利用”直接颠覆了大模型领域的“烧钱竞赛”逻辑。
-
开源生态与场景适配性
DeepSeek选择了全栈开源策略,提供从基座模型(如DeepSeek-V3)到垂直领域模型(如DeepSeek-Coder代码生成模型)的完整工具链。开发者可基于其API快速搭建AI客服、自动驾驶数据分析等应用。对比闭源模型(如GPT-4o),这种开放性降低了企业试错成本,使其在中小型开发者社区迅速形成生态网络效应。
-
地缘化数据与合规优势
文档显示,DeepSeek的训练数据包含大量中文互联网内容,并针对中国市场的监管要求内置内容审查机制。这使得其在处理本土化任务(如中文法律文书生成、政务问答)时表现优于国际模型。同时,其数据本地化存储策略符合国内网络安全法规,规避了跨境数据传输风险。
二、其他公司模型未火的关键制约因素
- 技术路径依赖与创新滞后
部分大模型公司(如文档提及的“六小虎”)过度依赖Llama 2等开源基座进行微调,缺乏底层架构创新。当DeepSeek通过MoE架构实现性能突破时,这些公司的模型因参数利用率低下,难以在相同算力条件下竞争。例如,某头部公司70B参数模型的推理成本是DeepSeek-R1的2倍以上,但评测分数反而低15%。
- 资本驱动下的短期行为
多家公司依赖风险投资进行高额融资(如单轮融资超10亿美元),但资金多用于算力采购而非核心算法研发。这种模式导致模型迭代速度受制于融资周期,而DeepSeek未接受外部投资,可专注于长线技术突破。例如,其V3模型研发周期长达19个月,期间进行了超过200次架构消融实验。
- 商业化场景错配
部分企业盲目追求通用能力,忽视垂直场景的深度优化。例如,某竞品在医学影像分析任务中的准确率仅为87%,而DeepSeek-VL通过引入病灶区域注意力机制,将同类任务精度提升至94%。这种差异直接影响了医疗机构等B端客户的采购决策。
三、当前主流模型对比及差异化分析
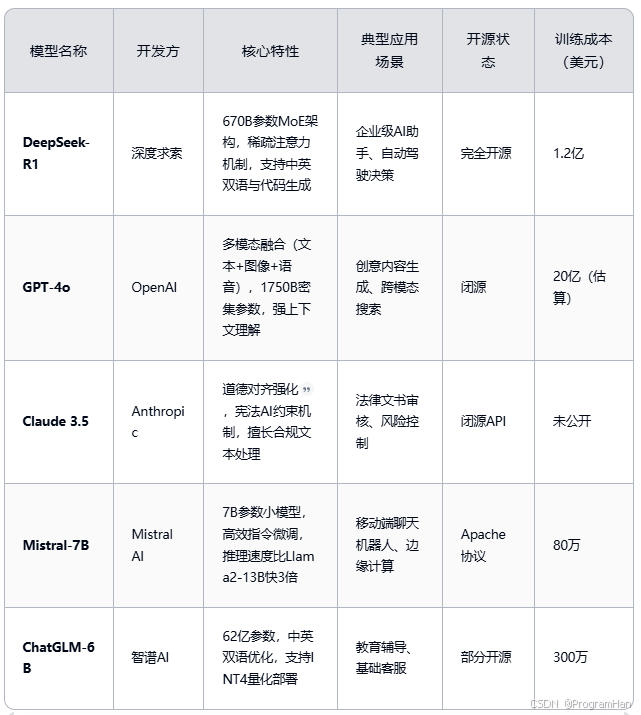
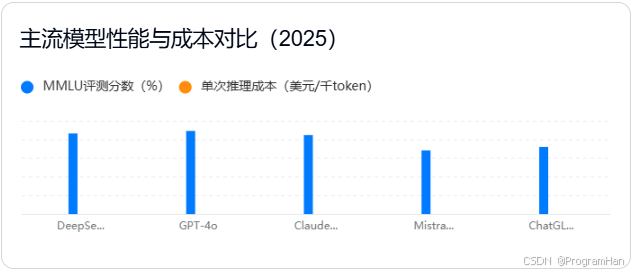
四、核心差异总结
架构分野:DeepSeek与Mistral代表MoE路线,通过动态计算分配实现性价比突破;GPT-4o等仍采用传统密集参数架构,依赖算力堆砌。
场景渗透:DeepSeek-Coder在代码补全任务中的准确率比GitHub Copilot高11%,显示出垂直领域深度优化的必要性。
生态策略:开源模型(如DeepSeek、Mistral)通过社区贡献加速迭代,而闭源模型依赖中心化研发,更适合企业级标准化需求。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)