初探—使用 LLaMA-Factory+AutoDL 0代码有监督微调 DeepSeek1.5B 流程笔记
本文记录了使用 LLaMA-Factory 微调一个 DeepSeek 1.5B 的蒸馏模型的全过程,包括软件下载、插件按照、自定义数据集等过程。
LLaMA 大模型微调🚀
最近由于一些学习工作上的原因,我又捡起了大模型微调的这一项工作,上网搜了搜一些教程学了学,由于微调大模型需要一个有 GPU 的 Linux 系统的电脑。实验室虽然有,但是这中操作怕电脑经不起折腾,还是根据其他人的方案在 AutlDL 上租一个实例来操作,整个过程也是比较复杂如果没有一些专业背景的话还是比较难做这个工作,低成本的训练效果一般很难达到应用标准,既然都做一遍了就把流程记录下来吧。主要流程基本都是基于一个B站名为 堂吉诃德拉曼查的英豪 up主的视频,然后根据自己的理解再记录和微调一下,在此表示衷心的感谢。
文章目录
1.安装 Visual Studio Code 并安装 Remote Explorer 插件
为了方便开发,这里我们选择使用 Visual Studio Code 来远程访问 AutoDL 服务器进行开发,官方如下,工具也是免费的,下载完自己安装就可以了。
官网:https://code.visualstudio.com/
在安装完成之后需要在扩展里搜索 Remote Explorer 插件进行安装用于远程链接 AutoDL 服务器。
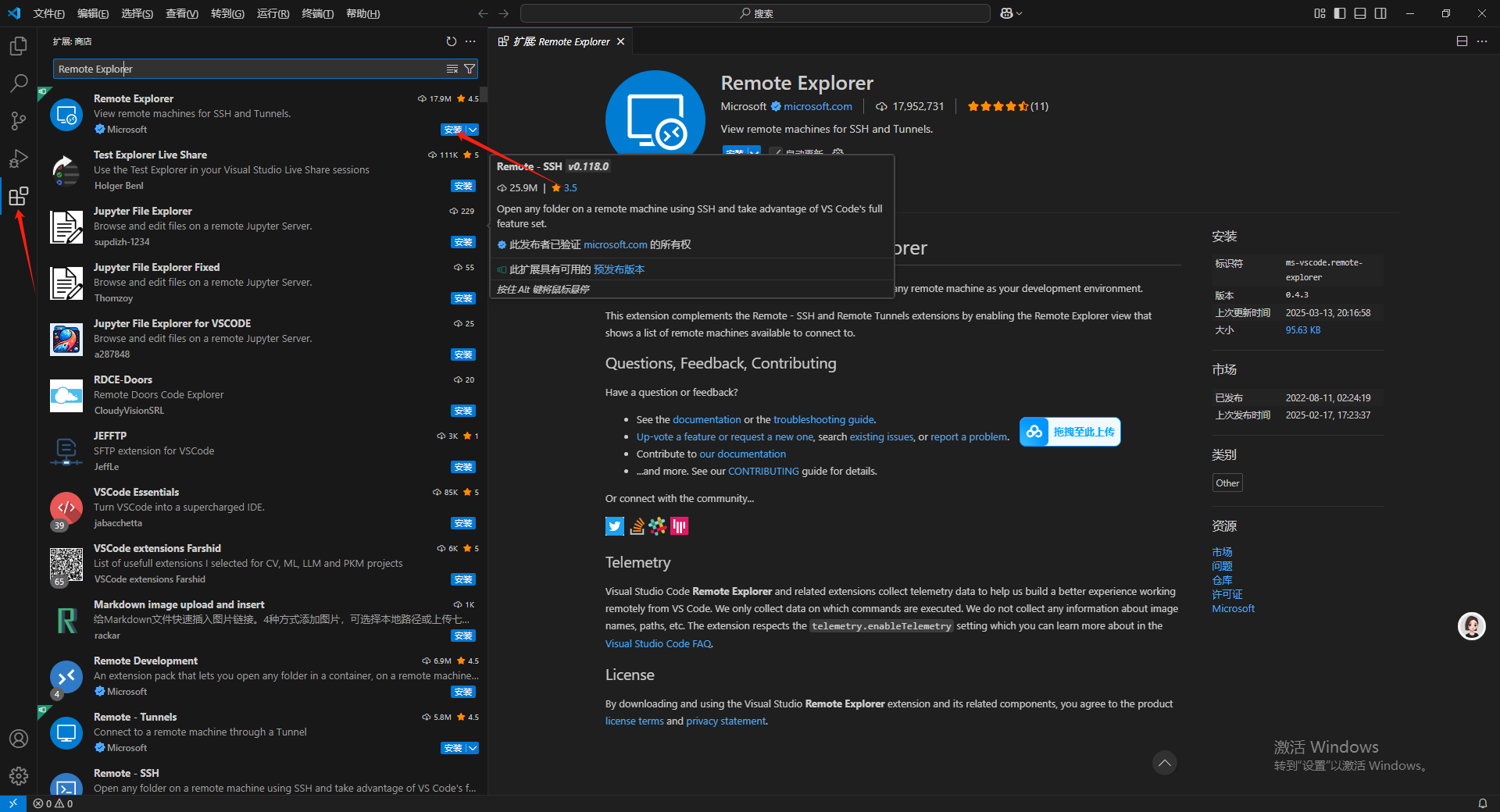
在安装完成之后左侧菜单栏扩展选项的上面会出现一个新的图标。
2. 租用 AutoDL 实例
之后在AutoDL 上租一个 Linux 的带 GPU 的现成的服务器,当然需要首先充值一点点,进入页面后点击算力市场。
AutoDL 网址:https://www.autodl.com/home
找一个能租的显卡,随便找一个就行,主要是熟悉一下完整的流程。
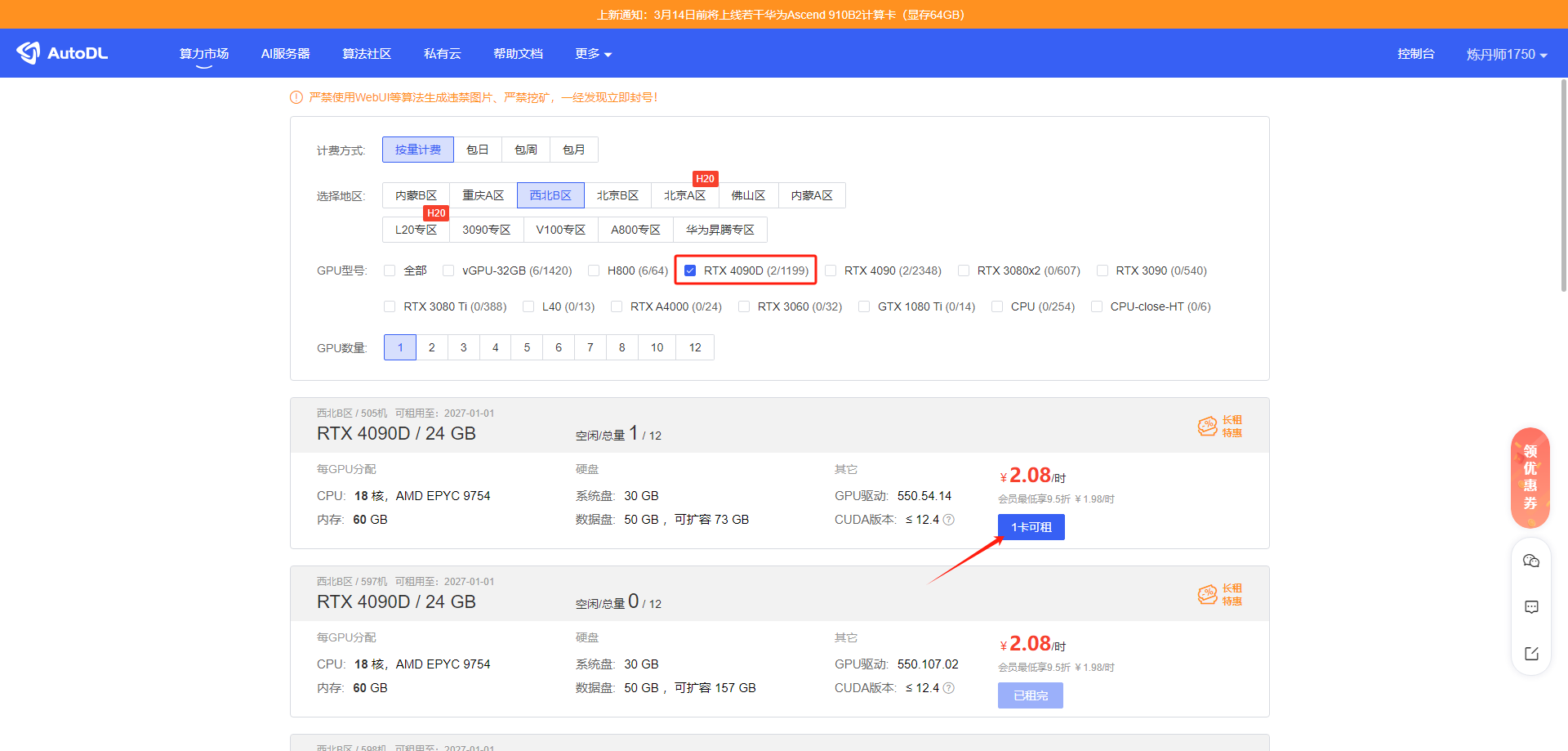
点进去之后在镜像部分选PyTorch 的镜像,版本最新的就可以,对后续操作影响不大。
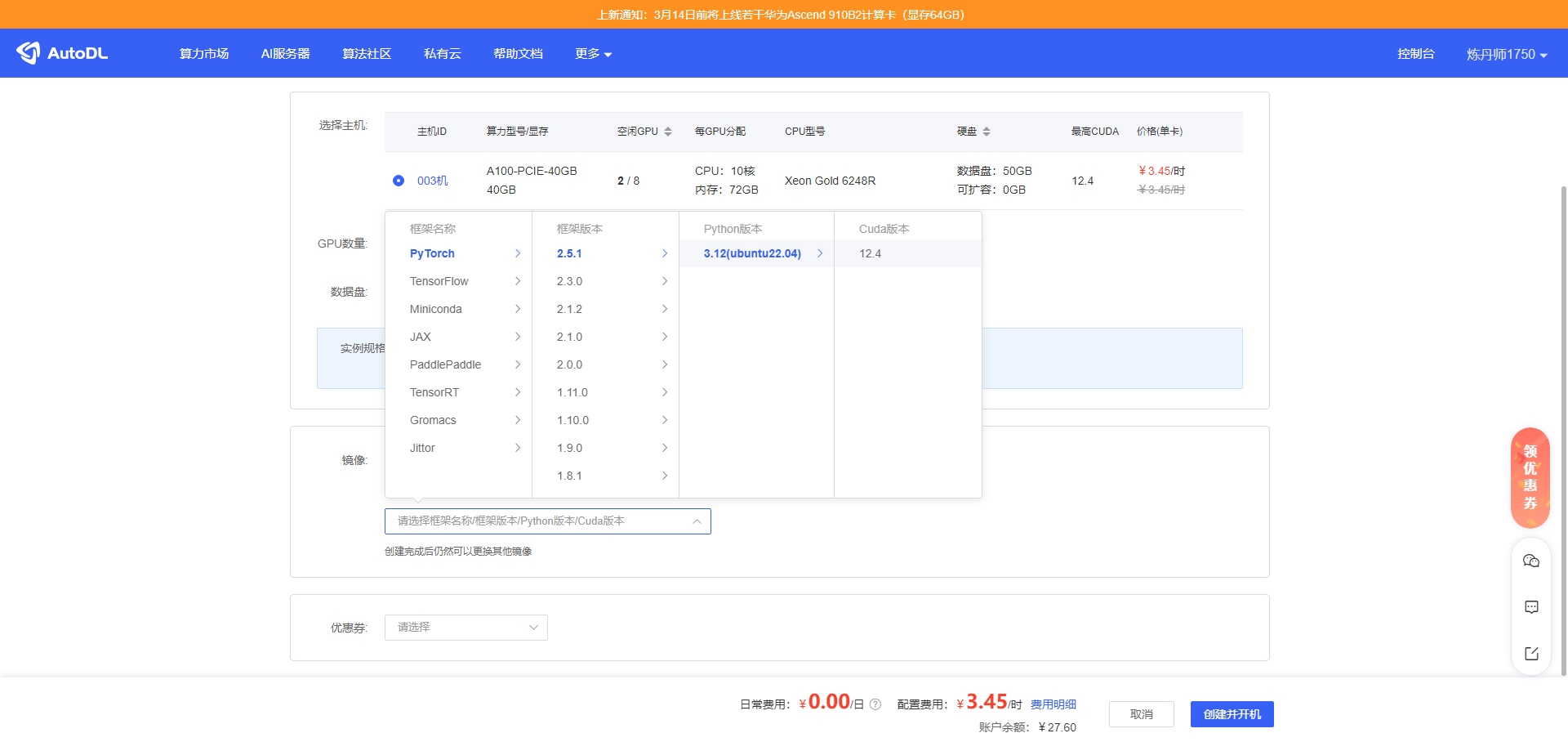
选好了之后点创建并开机。
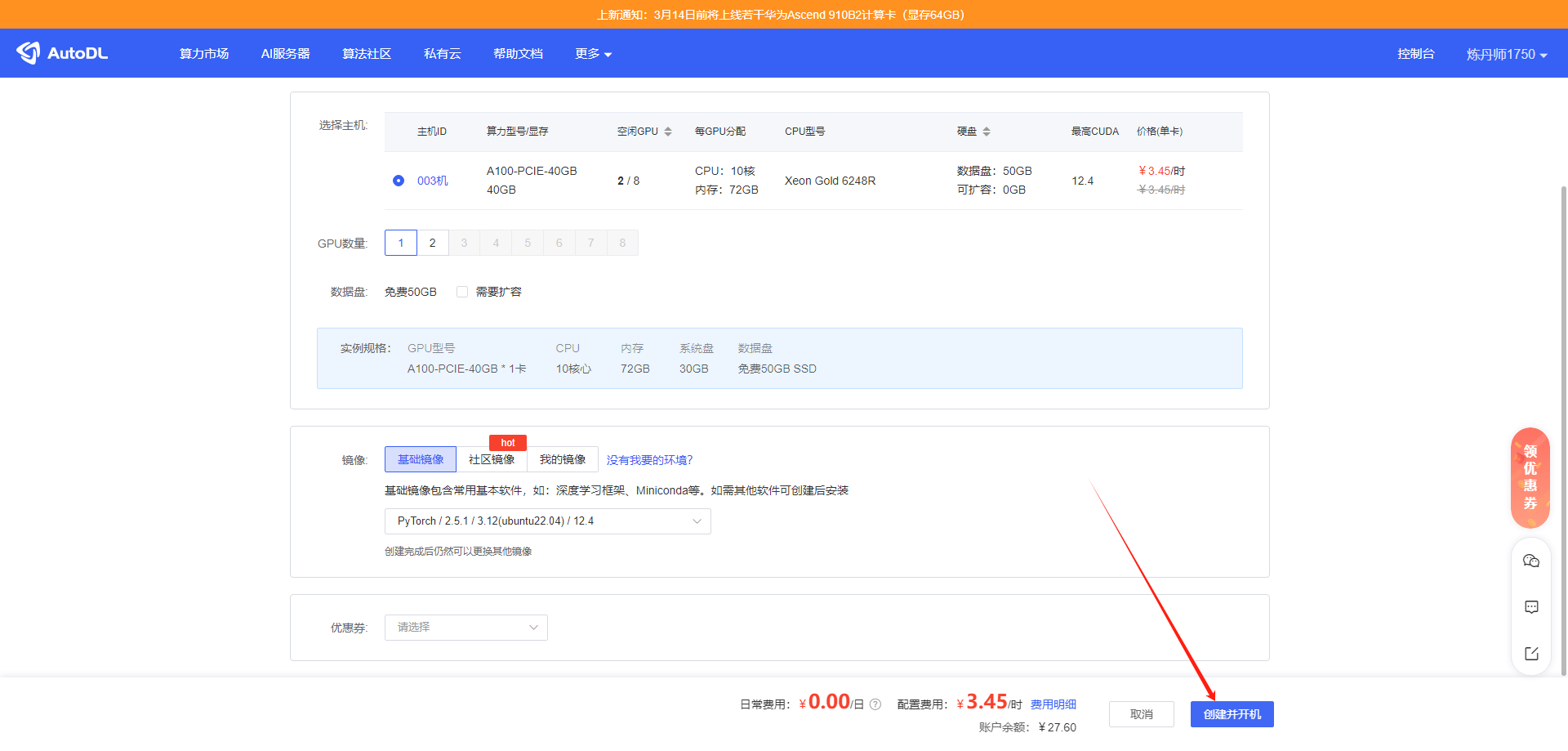
之后就会进入到这个页面。
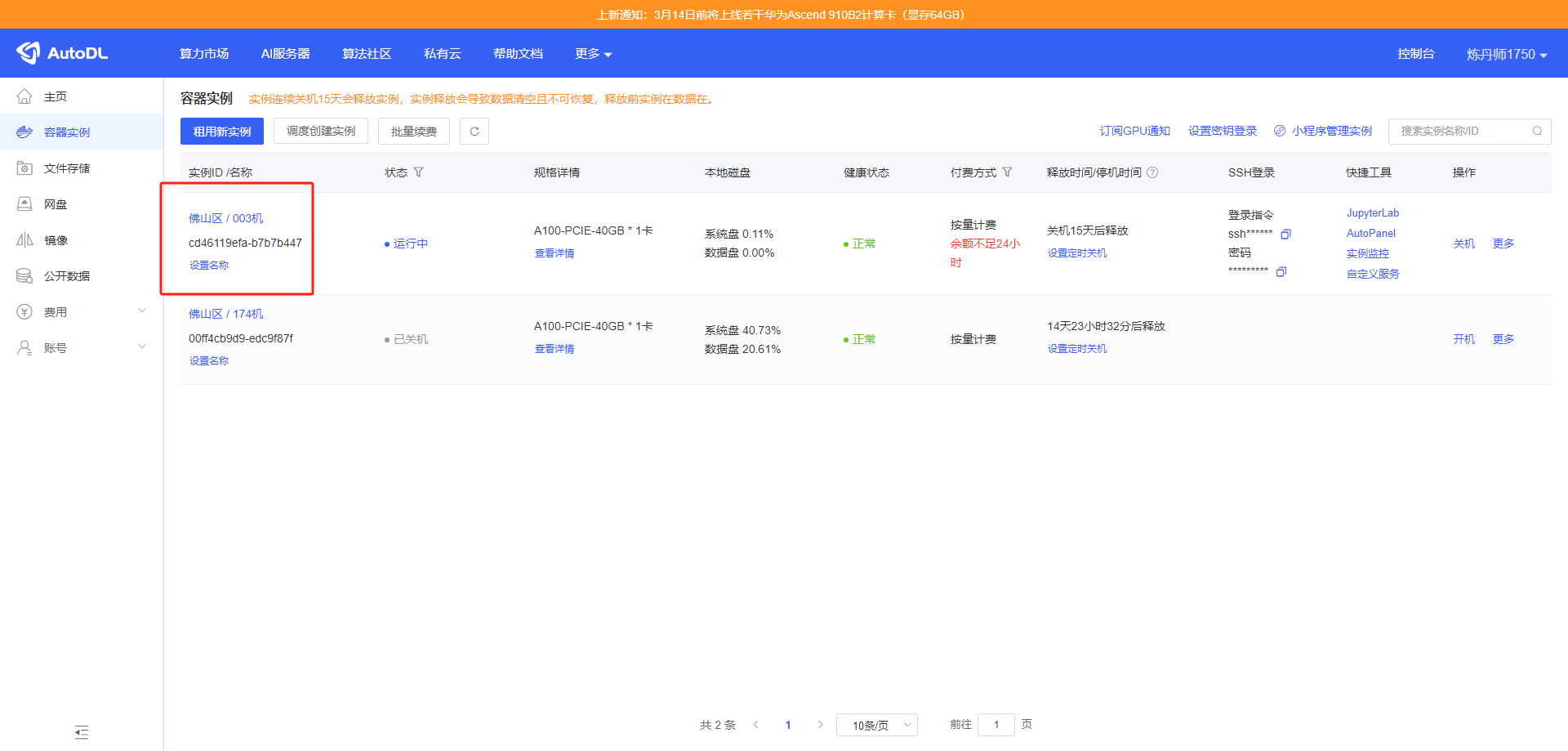
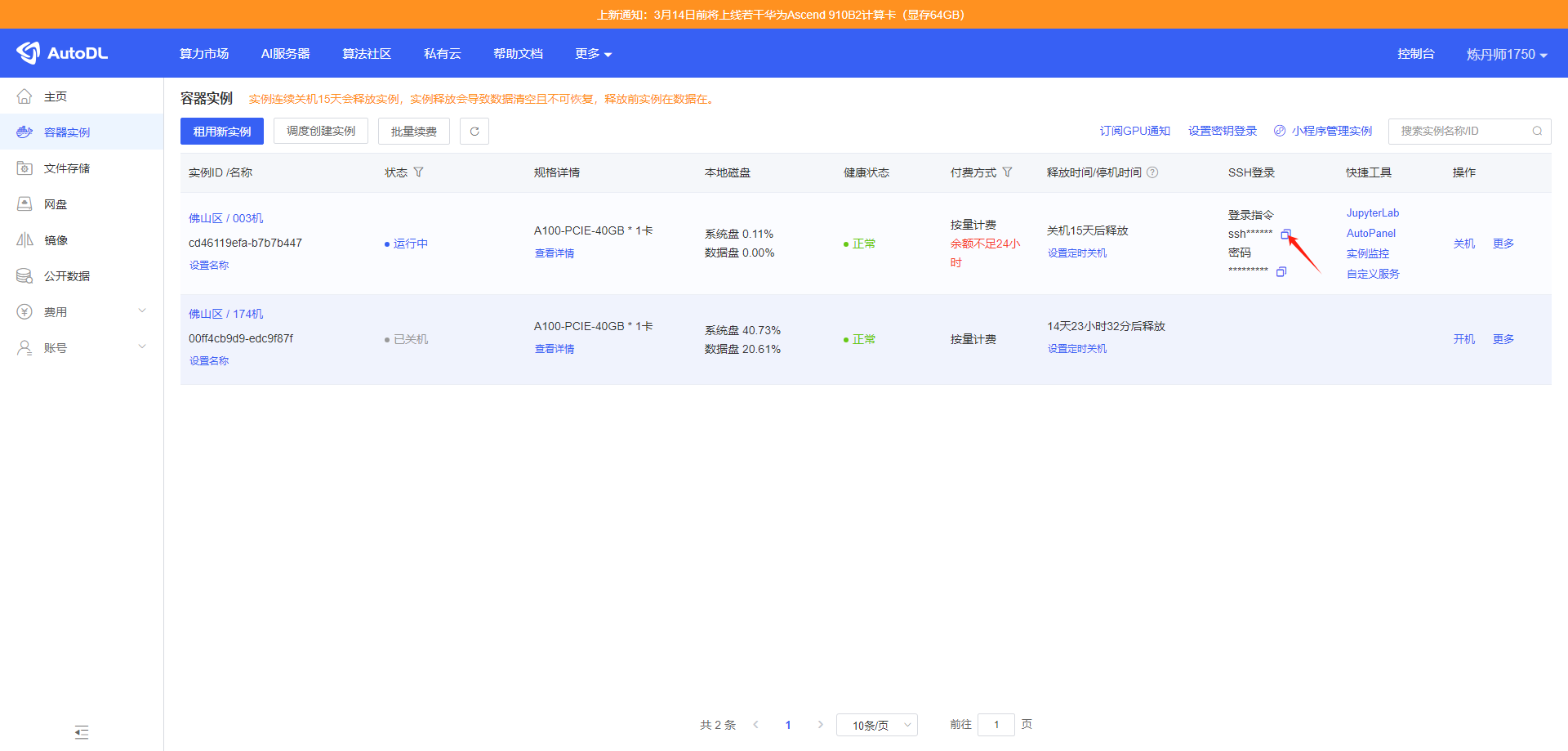
之后点击这个实例的 登录指令下方的 图标复制 SSH 登录命令备用,之后我们移步 Visual Studio。
3.使用 Visual Studio Code 远程链接 AutoDL 服务器
重新回到 Visual Studio Code 点击左侧菜单栏中的Remote Explorer 图标,在弹出的菜单栏中点击SSH所在行尾部的加号(这里鼠标移动到对应位置才能看到加号)
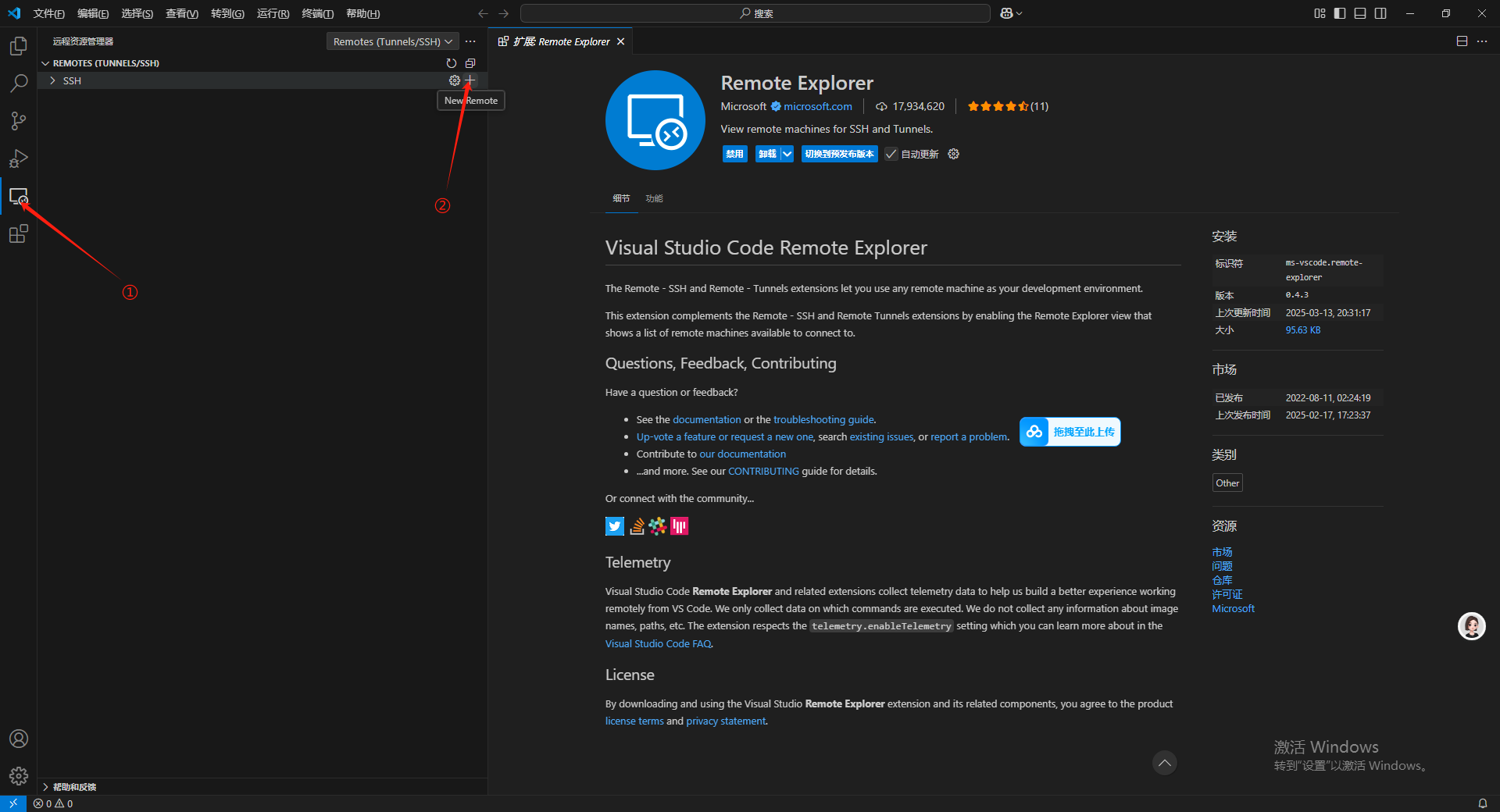
把刚才用 AutoDL 中复制的 SSH 远程链接命令复制进去,然后按回车。
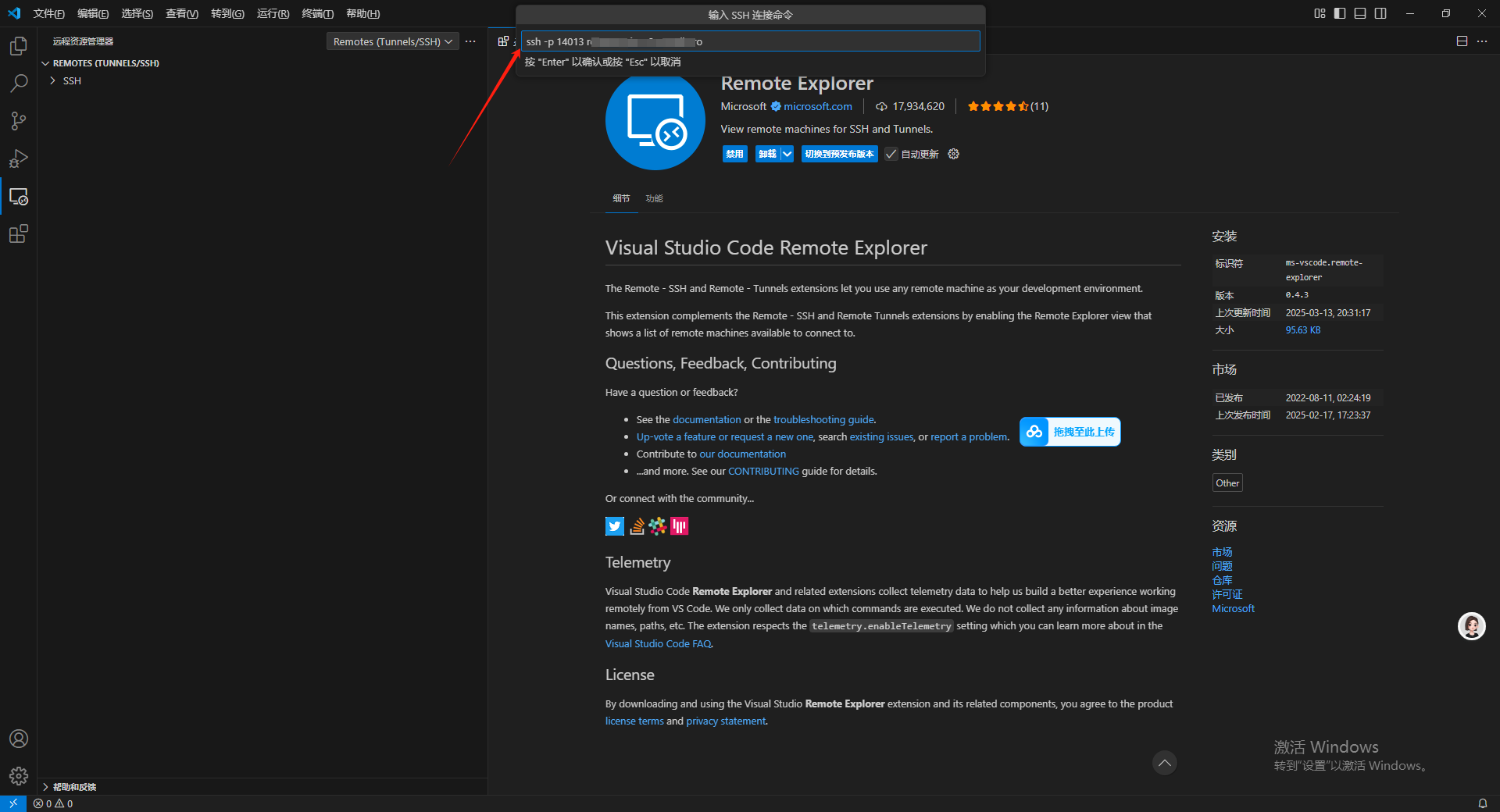
之后会出现要选择更新的 SSH 配置文件的选项,选择第一个点击即可。
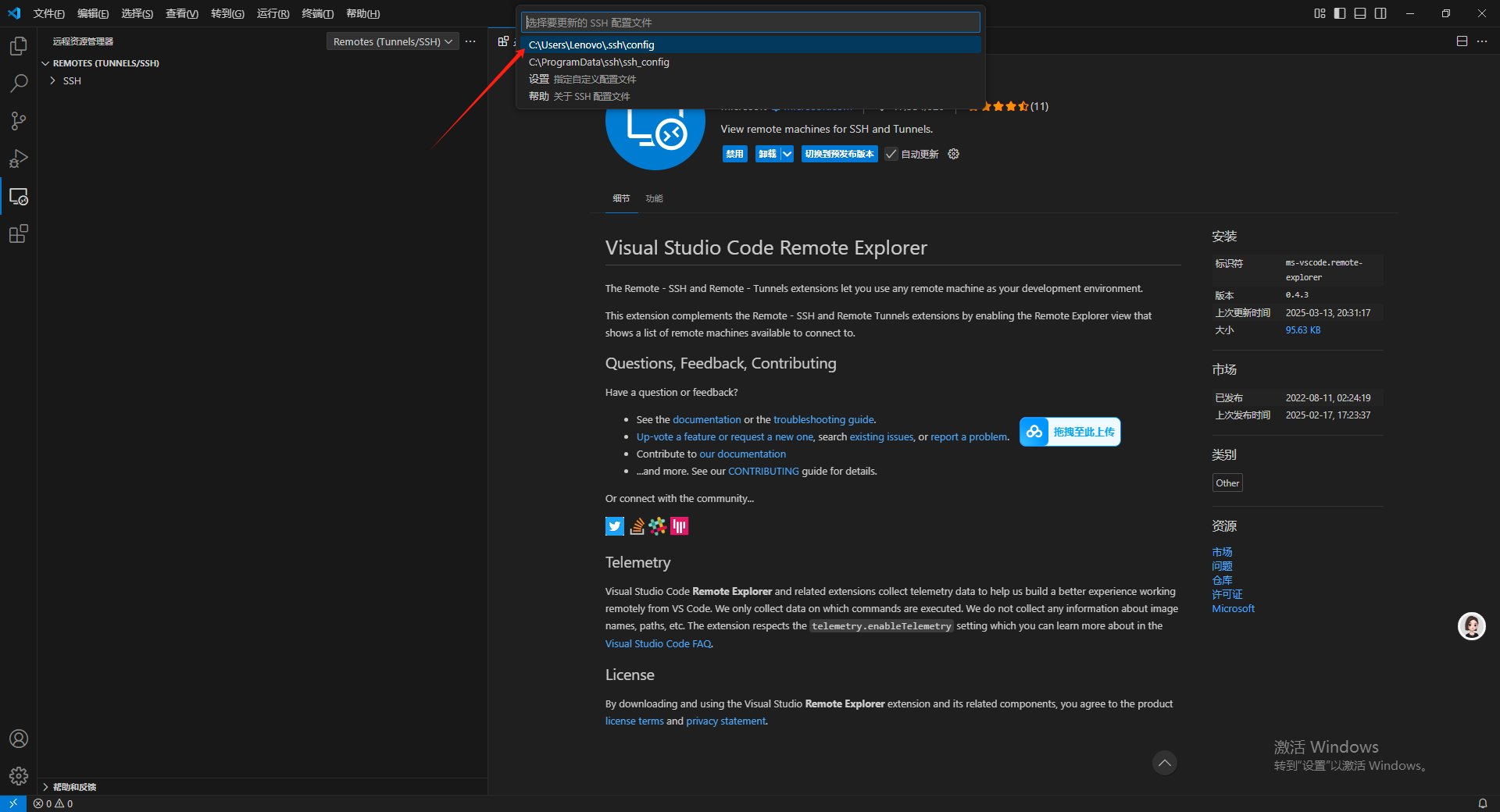
点击链接。
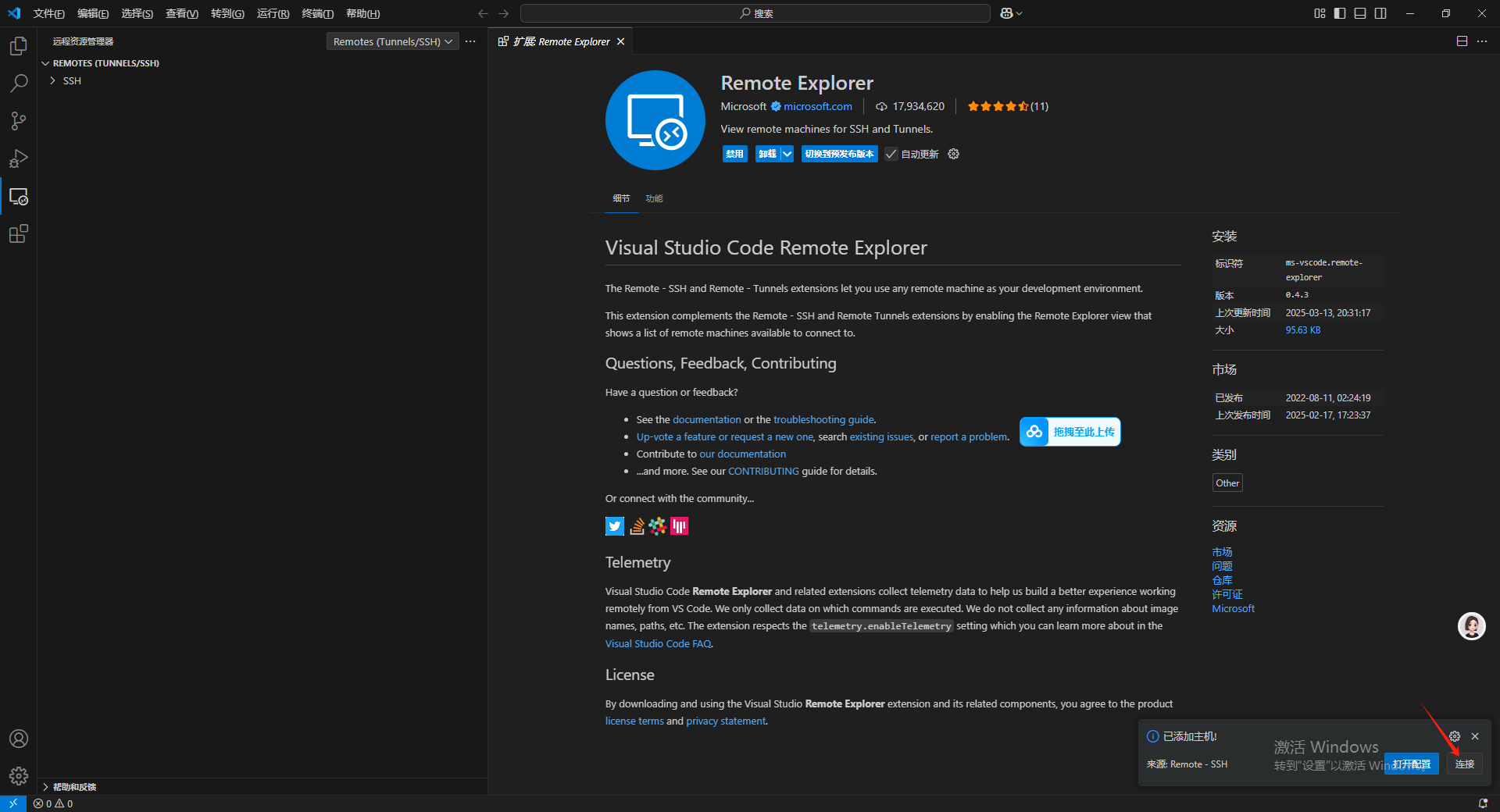
出现一个新弹窗要求输入密码。
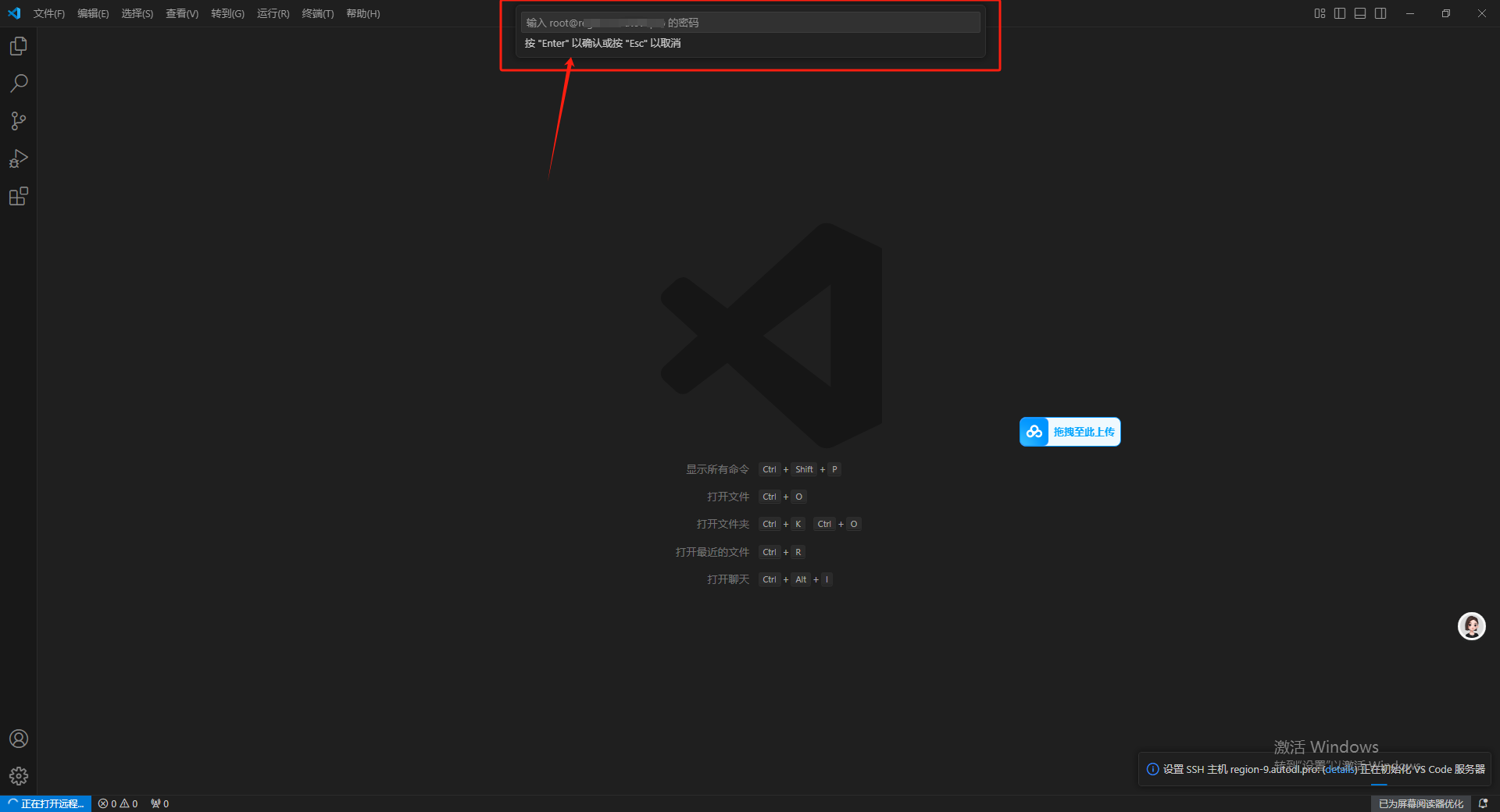
回到AutoDL界面,点击复制密码。
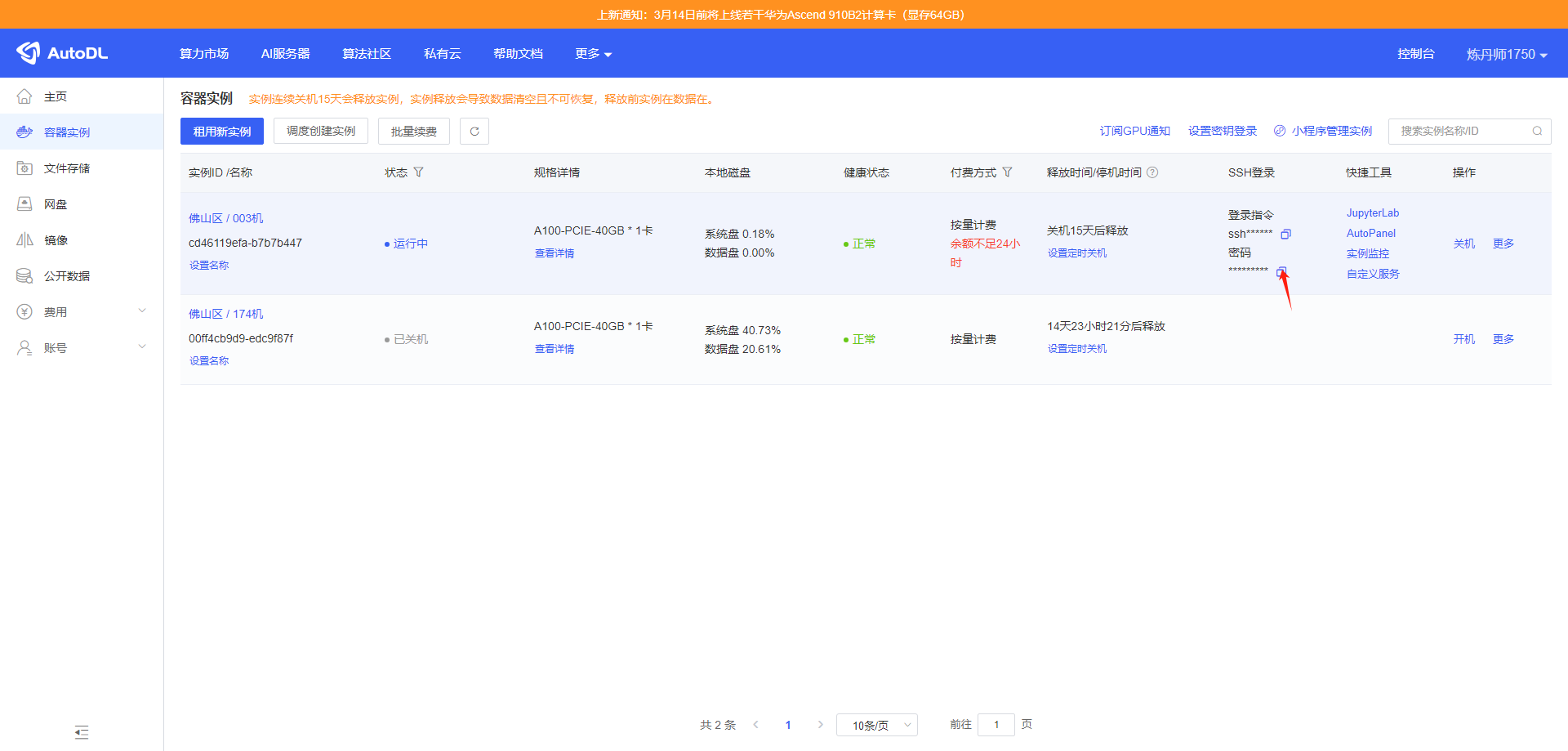
输入之后按回车。
等待远程链接完成。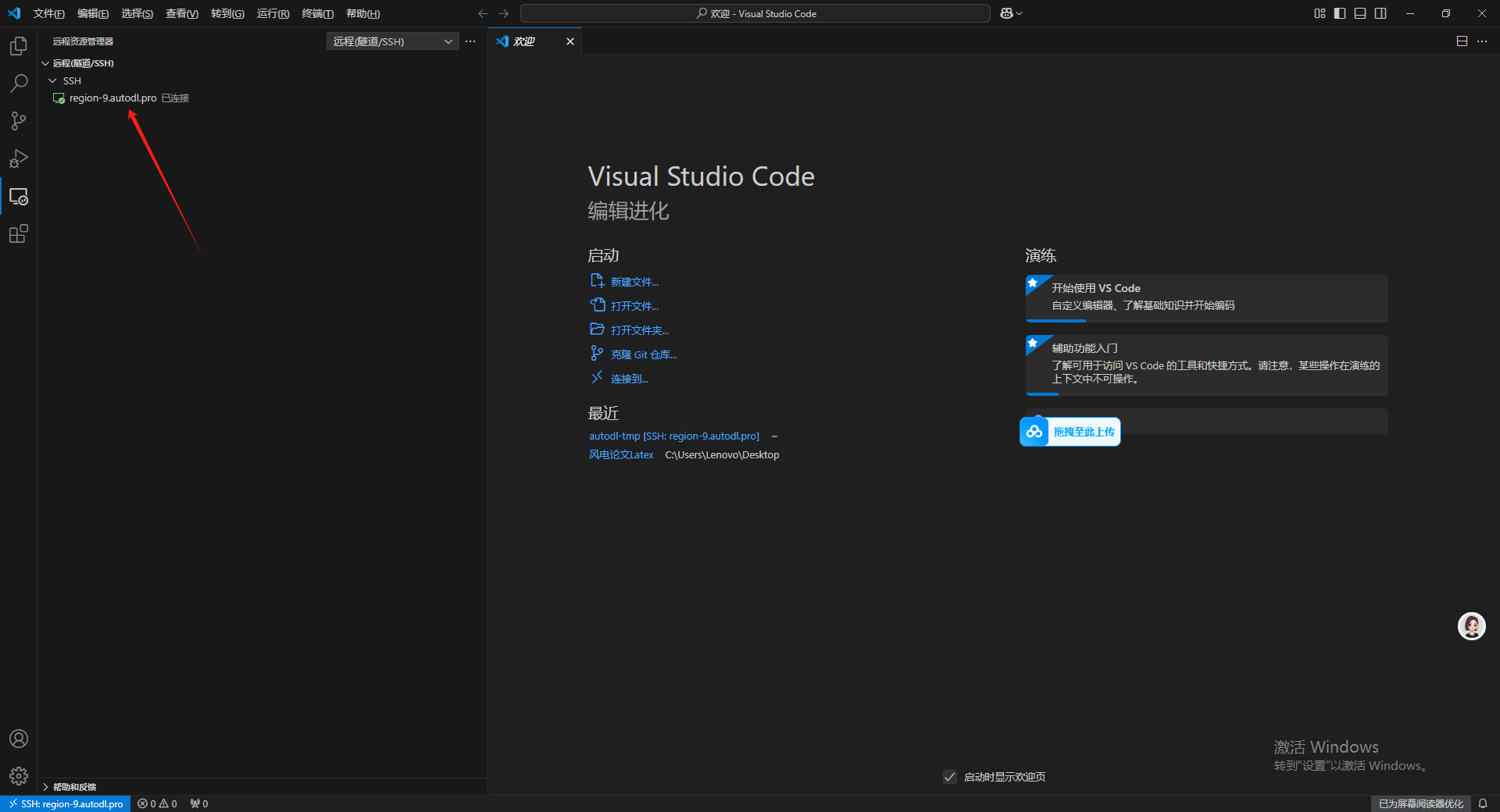
之后点击右上角的切换面板,打开终端界面,可以看到输出内容已经出现 AutoDL 服务器的信息。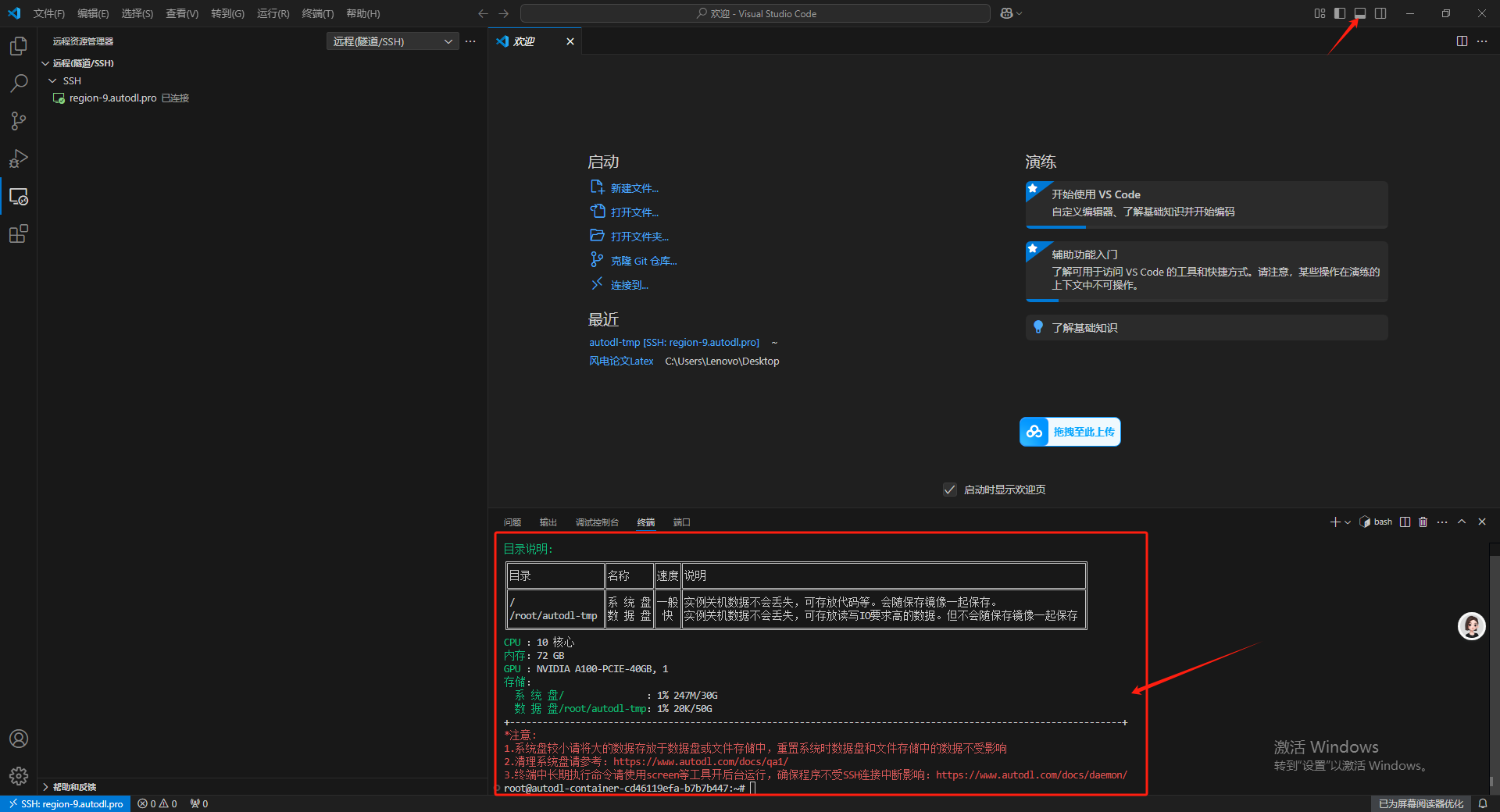
4.进入 autodl-tmp 数据盘
在远程链接了之后我们看不到远程链接的文件夹目录,因此我们要进入到对应的目录文件夹下,这里我们进入到 autodl-tmp 数据盘,主要在数据盘内进行操作,因为如果后续由于 AutoDL 的 GPU 算力不足的时候,可以直接克隆实例把我们的东西都克隆走。
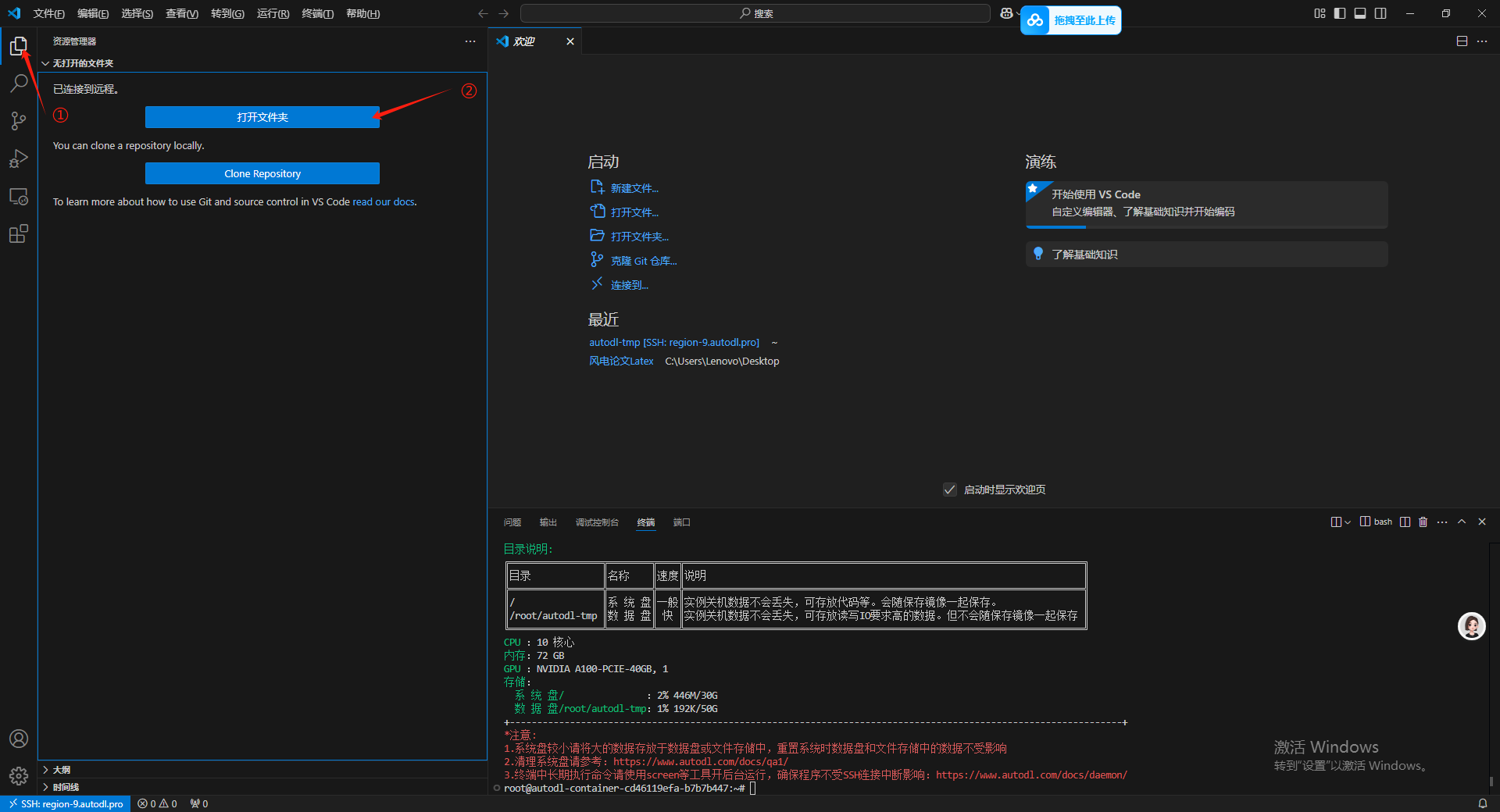
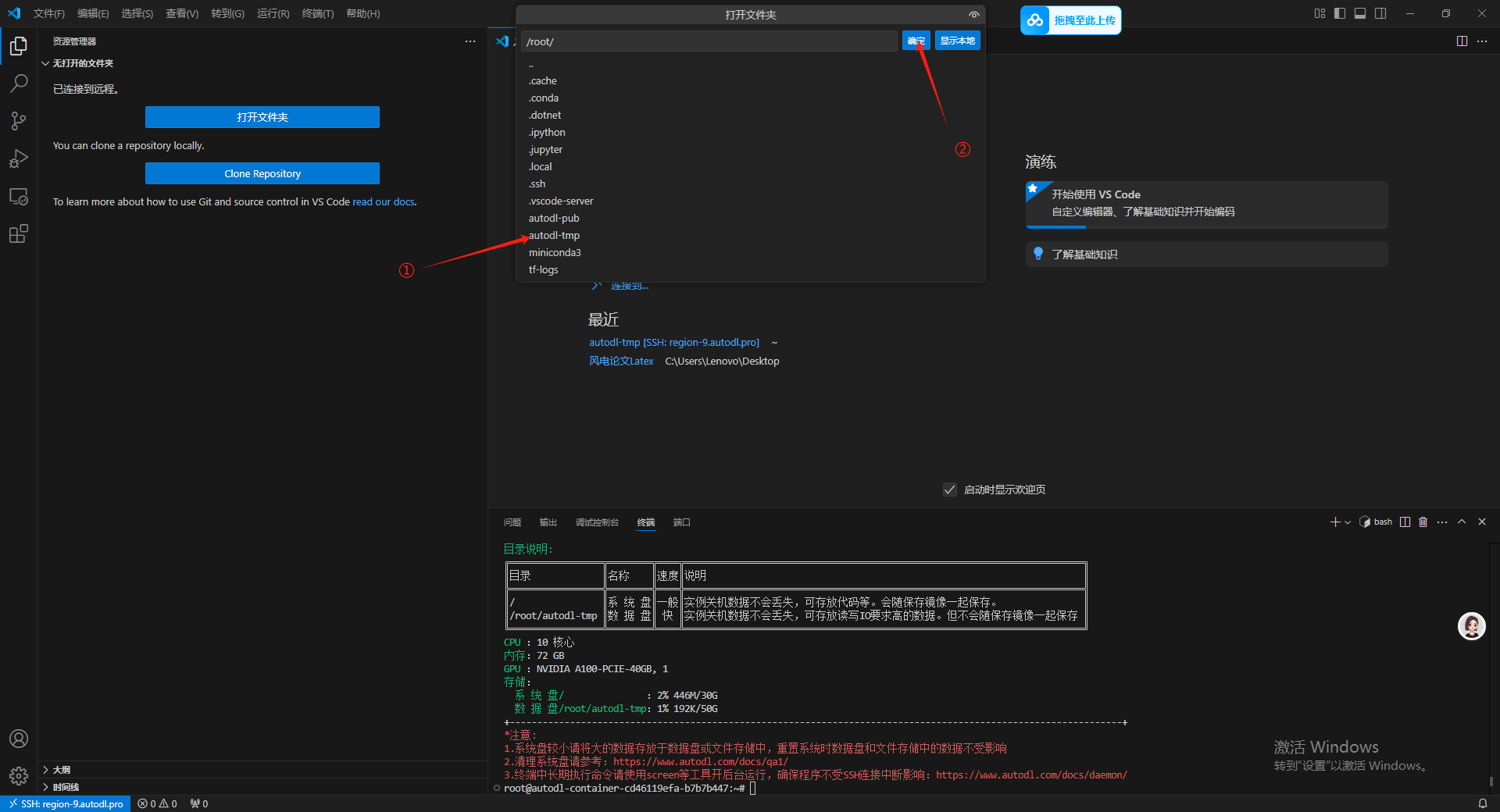
然后这里提示还要输入一遍密码。
此时已经进入到 autodl-tmp 数据盘下面了。
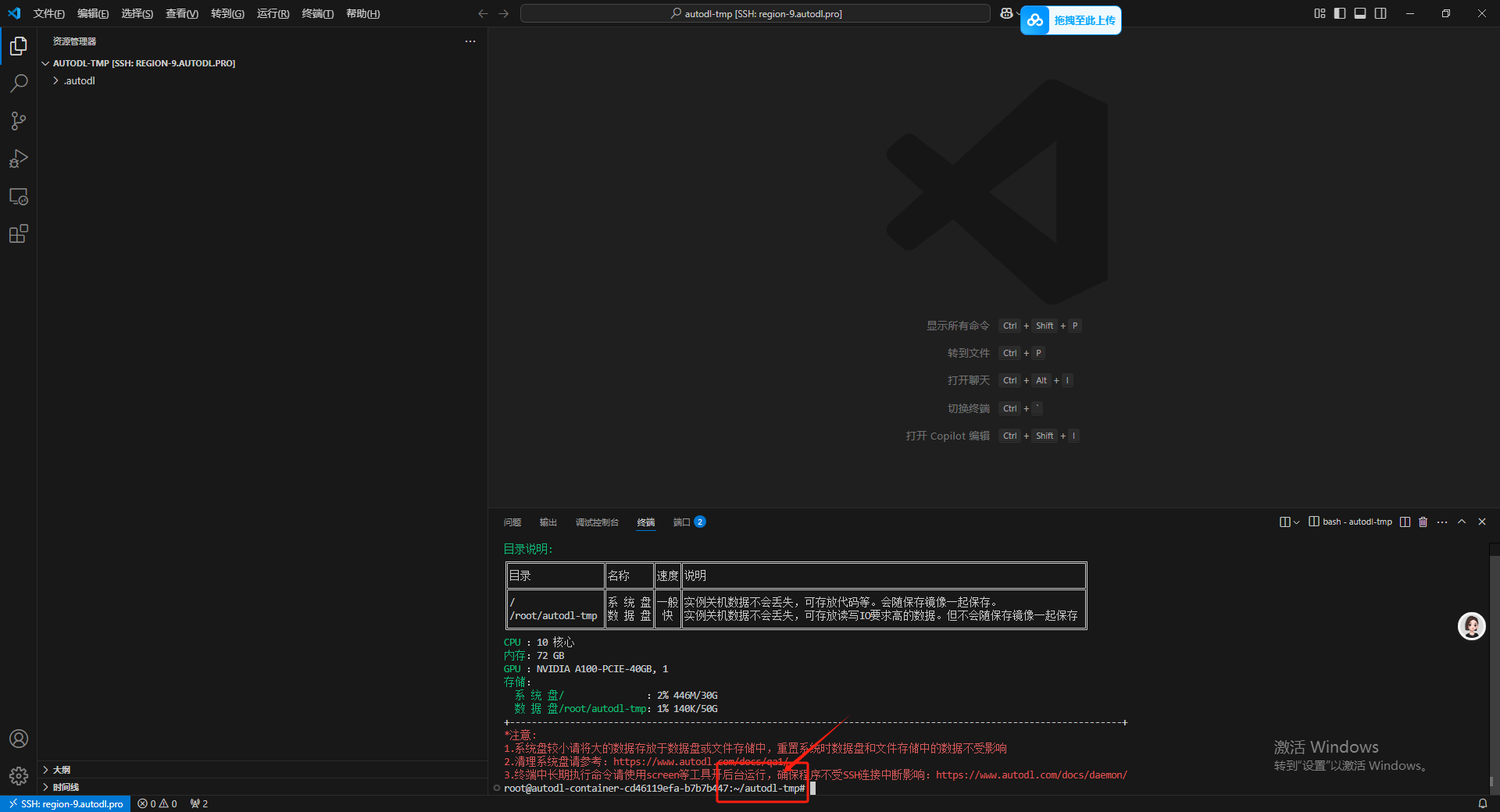
5.克隆 LLaMA-Factory
进入LLaMA-Factory 官网 https://github.com/hiyouga/LLaMA-Factory
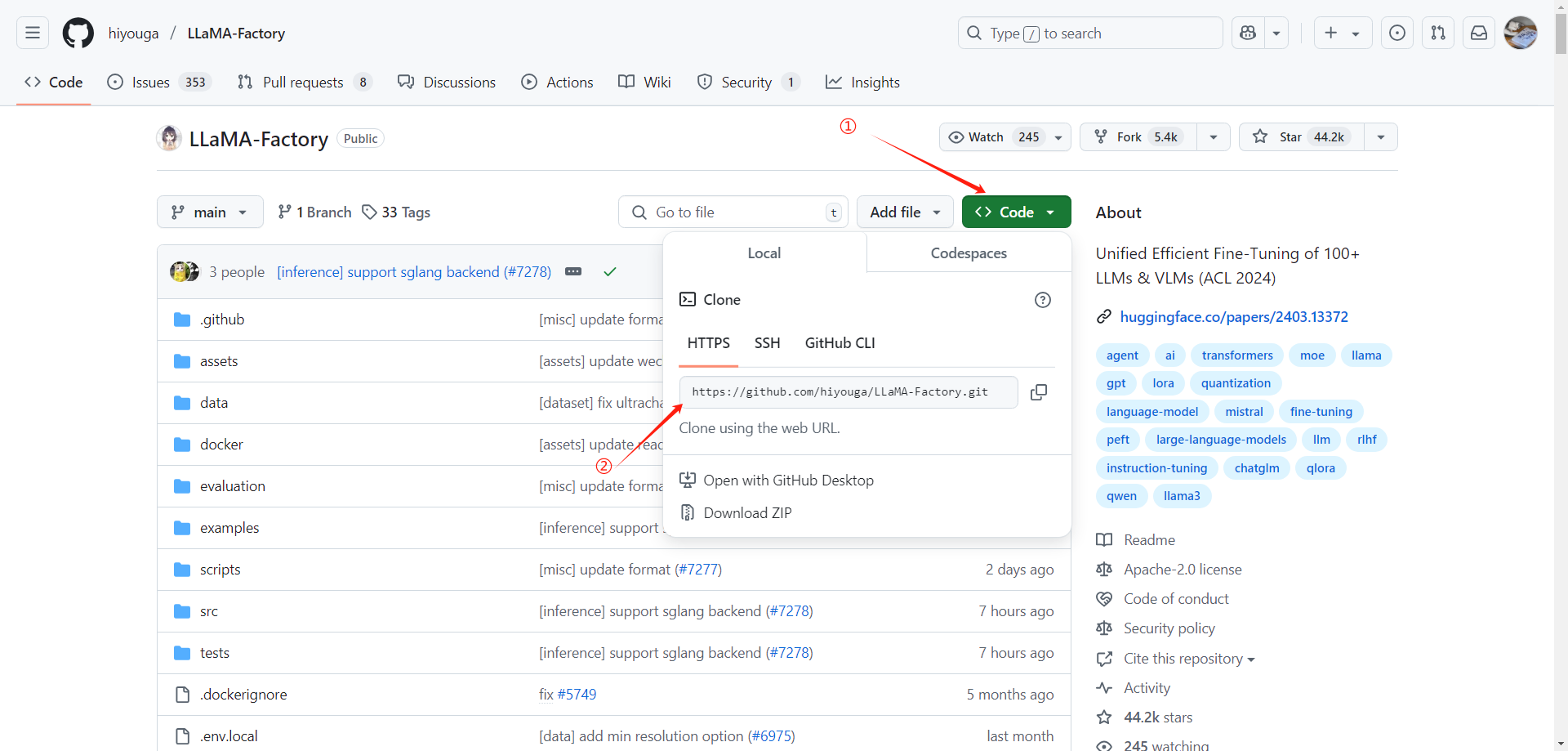
在 Code 里去复制他的 HTTPS 链接。然后在前面加上 git clone -depth 1 构成一个克隆命令
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
然后在终端中输入克隆命令然后回车。
如果报 HTTP2 网络错误 就先输入一下配置,使用 HTTP/1.1 然后设置大缓冲字节就可以。
git config --global http.version HTTP/1.1
git config --global http.postBuffer 157286400
之后使用 cd 命令进入到 LLaMA-Factory 文件夹下,用于之后安装LLaMA-Factory 的安装包
cd LLaMA-Factory
6.将 Conda 迁移到数据盘
这个主要的目的也是后续如果要对实例迁移的时候,可以把虚拟环境一并迁移过去。
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/conda/envs
conda config --add pkgs_dirs /root/autodl-tmp/conda/envs
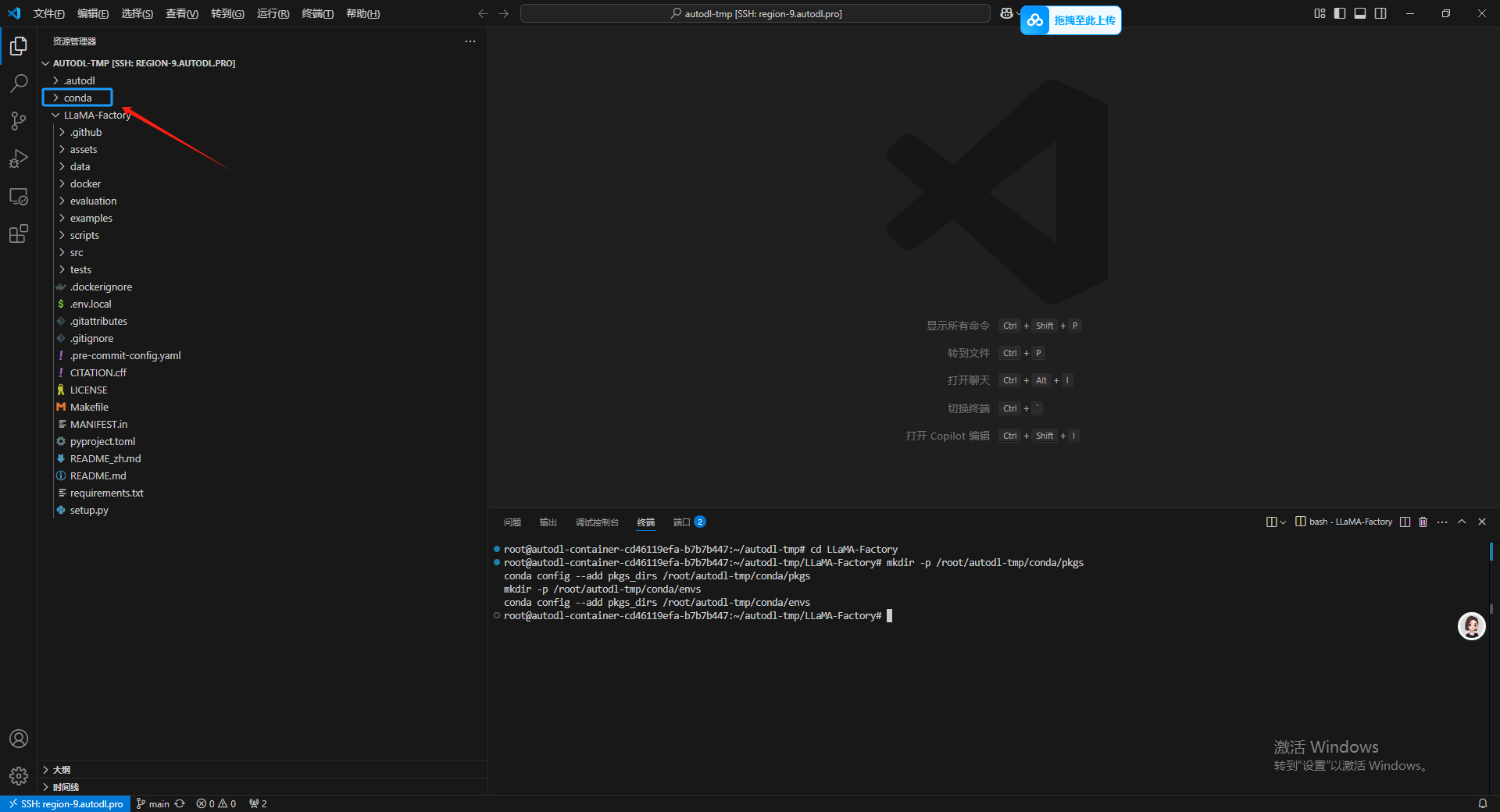
7.给 LLaMA-Factory 安装虚拟环境和依赖
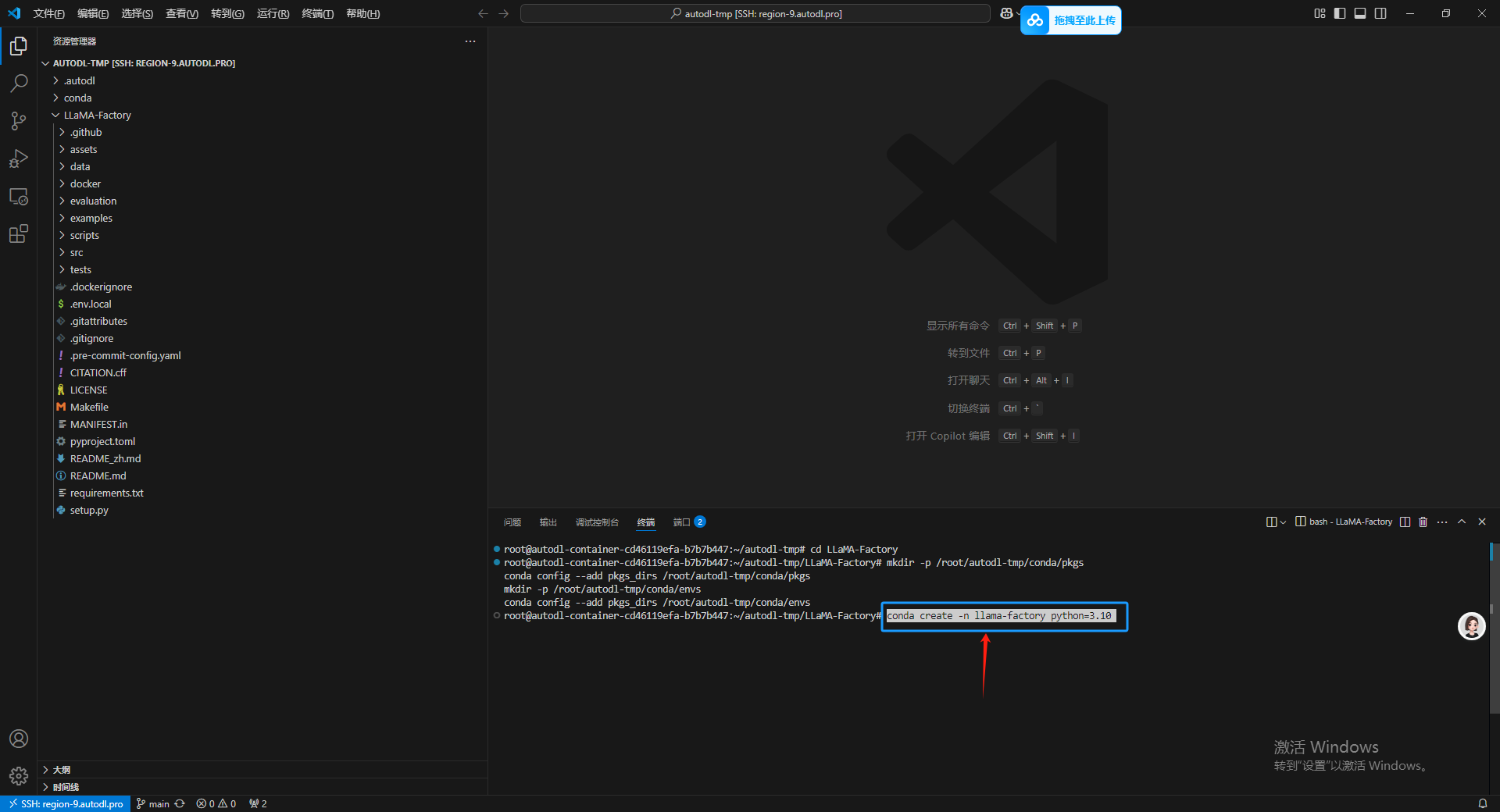
运行之后在数据盘目录下会出现一个 conda 文件夹,之后按照官方的建议新建一个 python 版本为3.10 的 conda 虚拟环境。

conda create -n llama-factory python=3.10
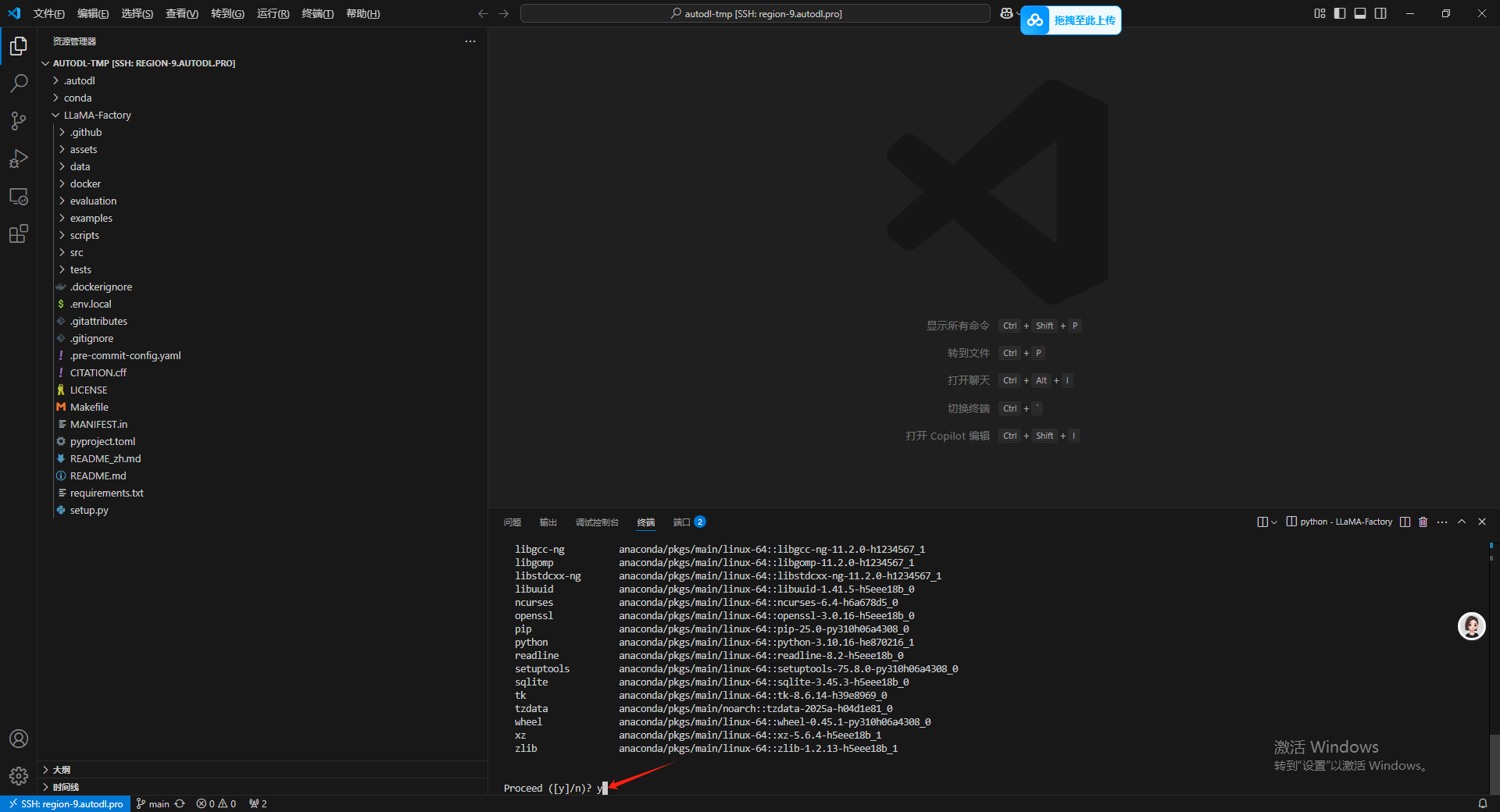
等待出现如下信息之后输入 y 然后回车,等待安装。
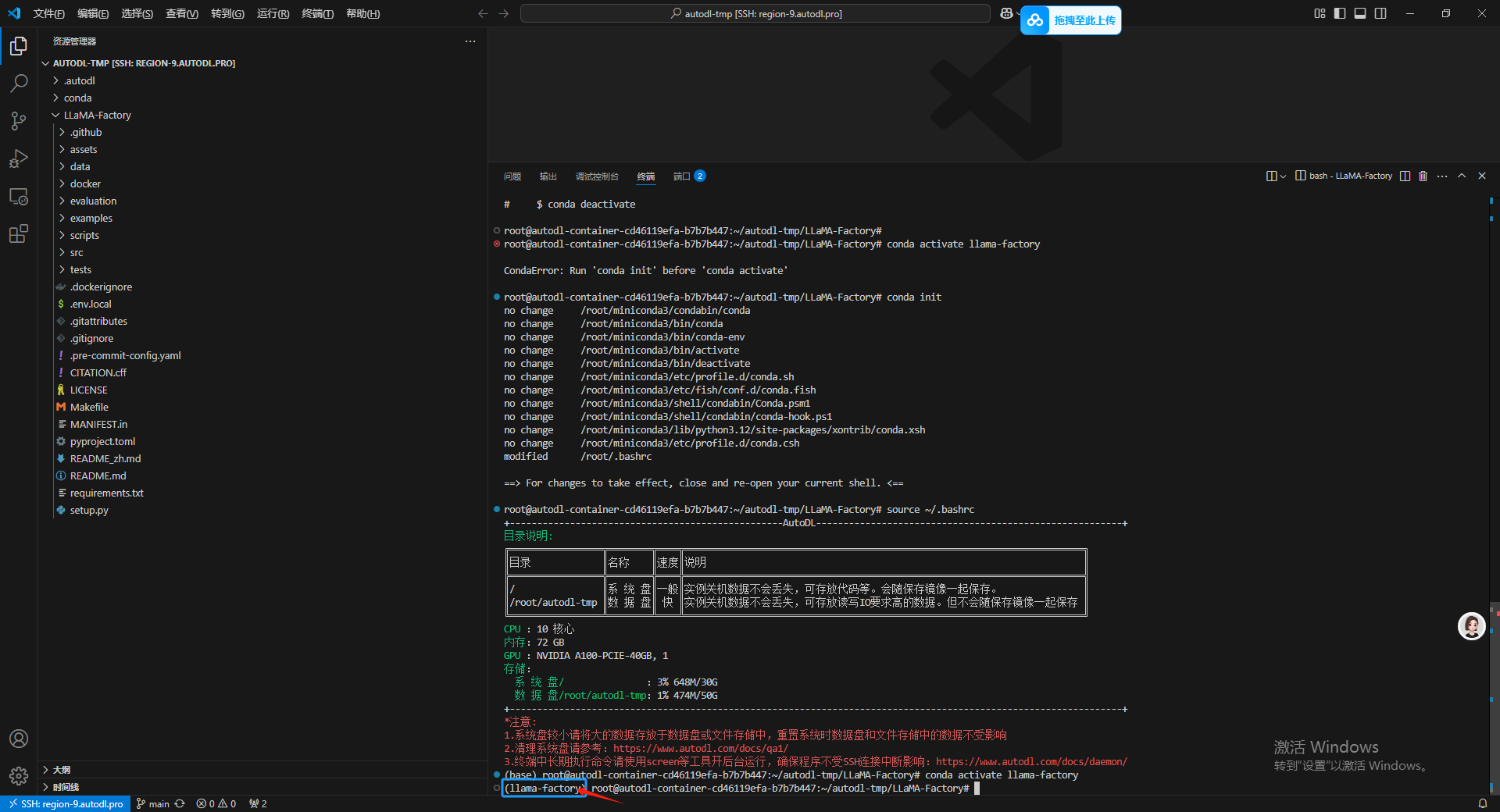
输入以下命令进入虚拟环境:
conda activate llama-factory
如果报错就输入 conda init 然后 再输入 source ~/.bashrc 刷新一下终端,通过命令行前面的括号内容就能看出已经成功进入当前虚拟环境了。
接下来,在当前虚拟环境下,安装相关的python依赖。
pip install -e ".[torch,metrics]"
等待安装成功。
8.启动可视化微调界面
启动命令如下:
llamafactory-cli webui
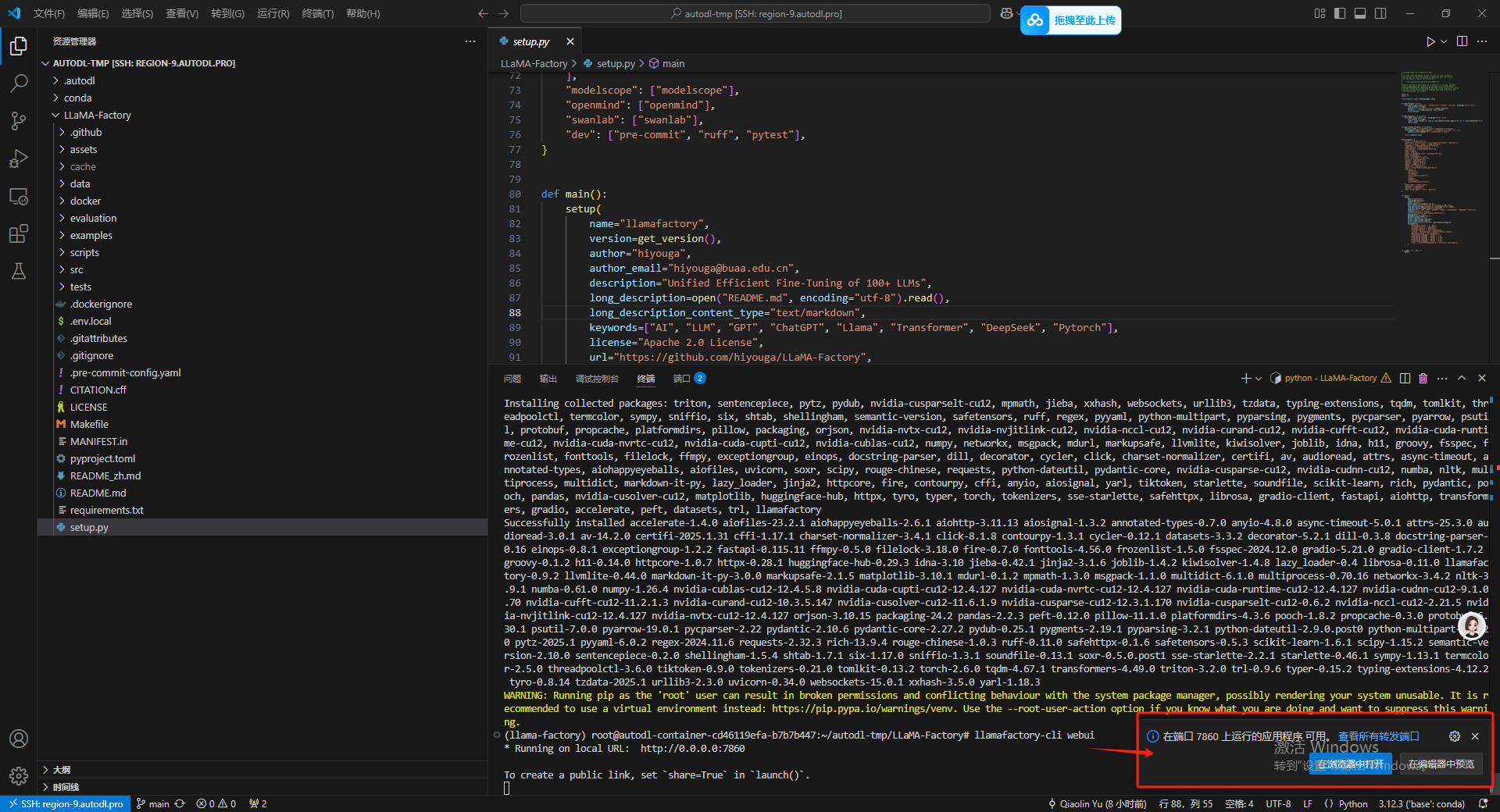
进入到如下界面,代表我们的环境配置部分就成功了。
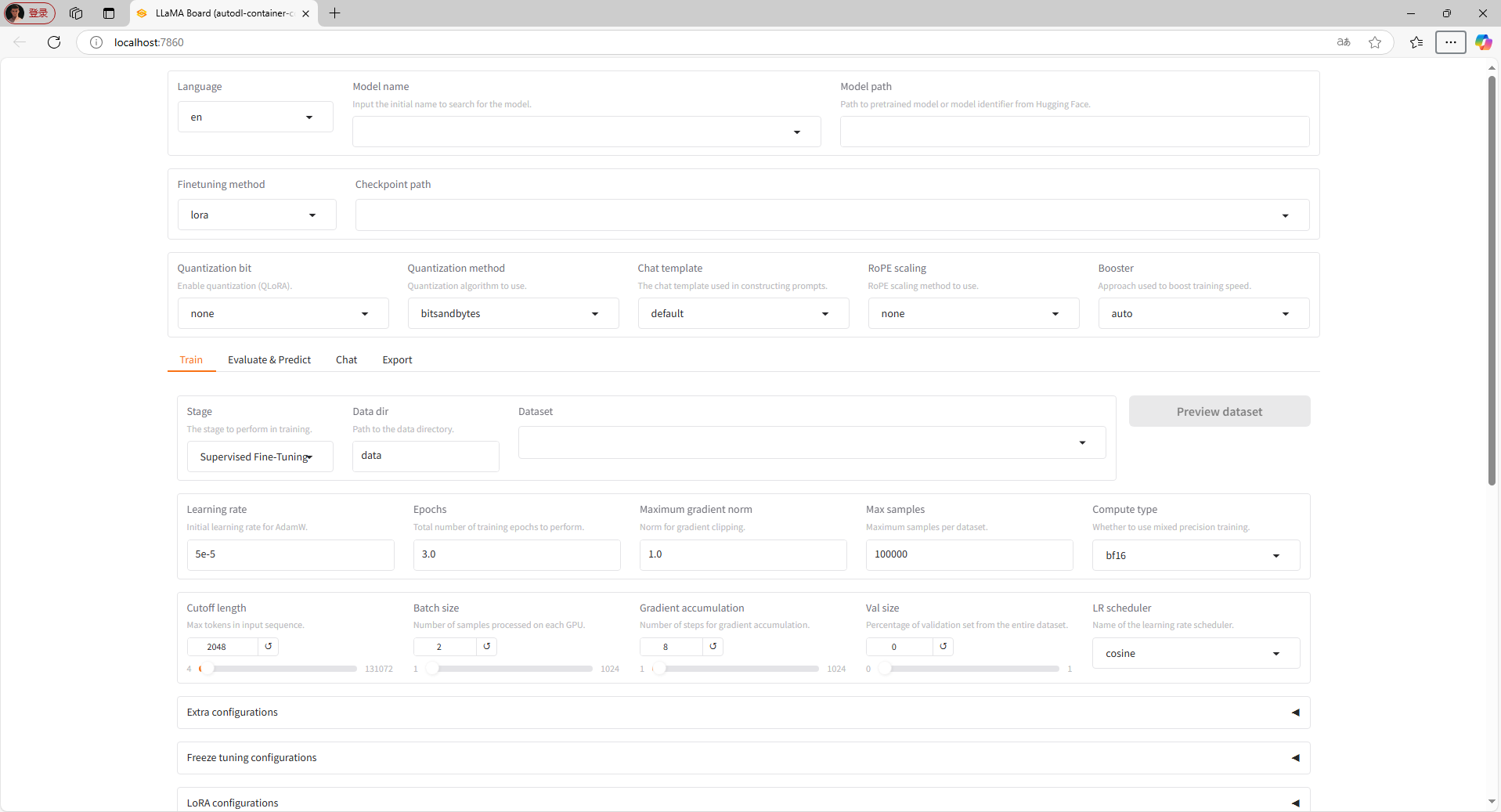
9.下载基座模型
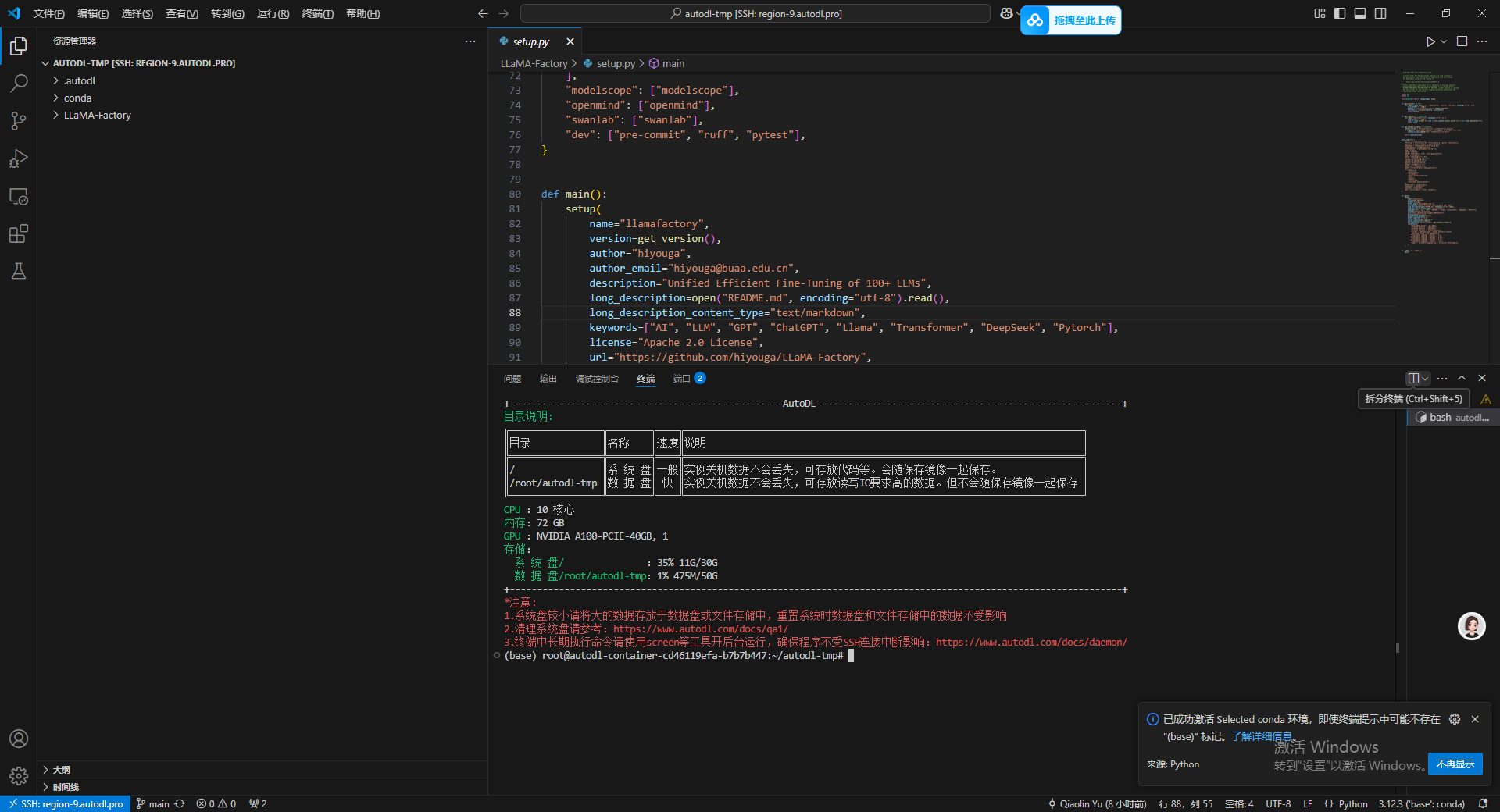
首先,还是新建一个文件夹,之后将基座模型下载到这个文件夹中,新开一个终端,主要操作是点击终端面板右侧的加号,我一截图我发现他图标就变,这个大家可以到时候自己找一下。然后输入以下命令再 autodl-tmp 路径下创新一个新的文件夹。
mkdir Hugging-Face
输入命令之后可以在左侧资源管理器部分看到一个刚出生的 Hugging-Face 文件夹。
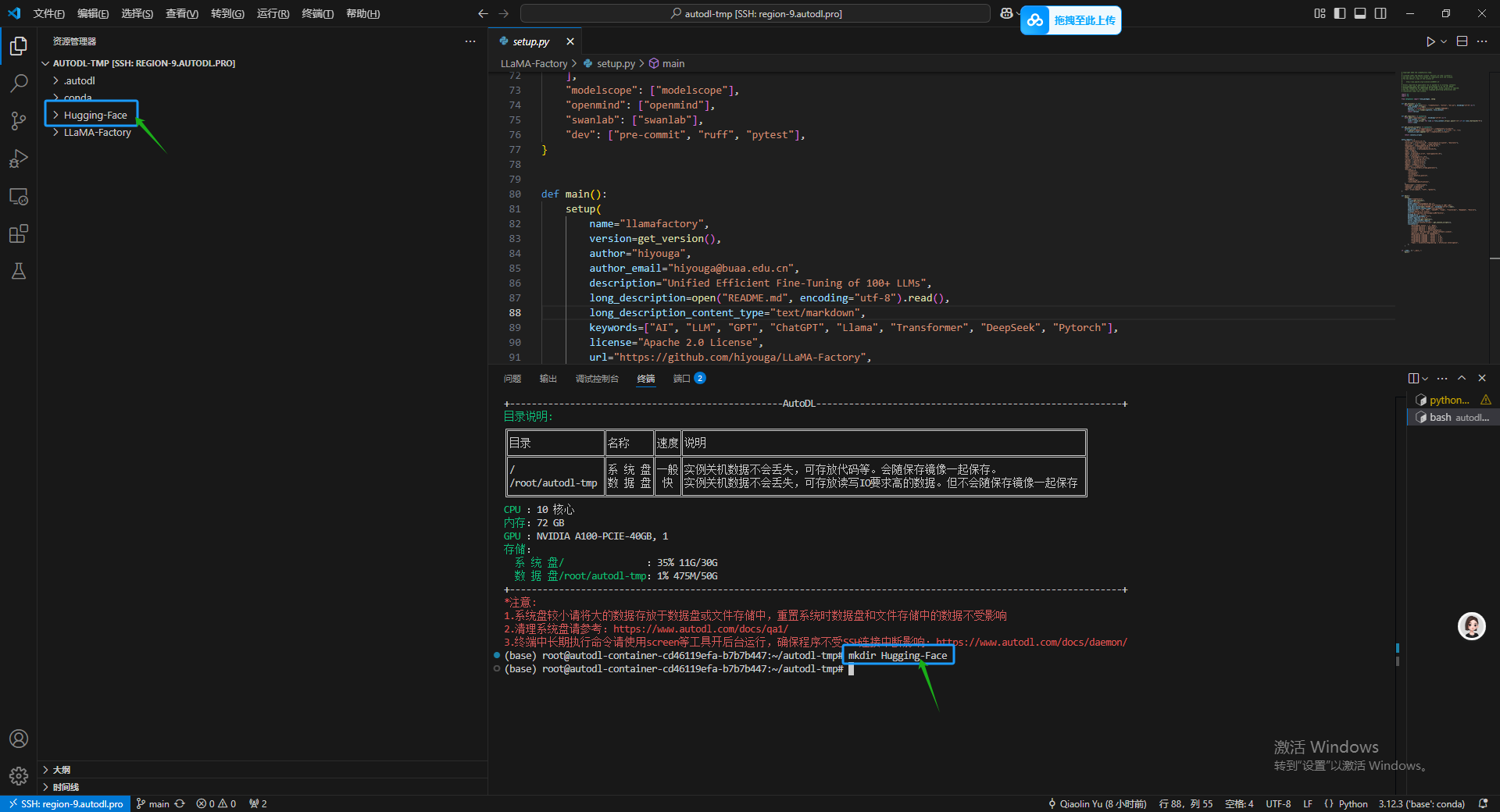
进入到 LLaMA-Factory 环境里,后面的配置环境和路径的操作都必须在我们刚建好的虚拟环境中执行才可以才不会报错。
conda activate llama-factory
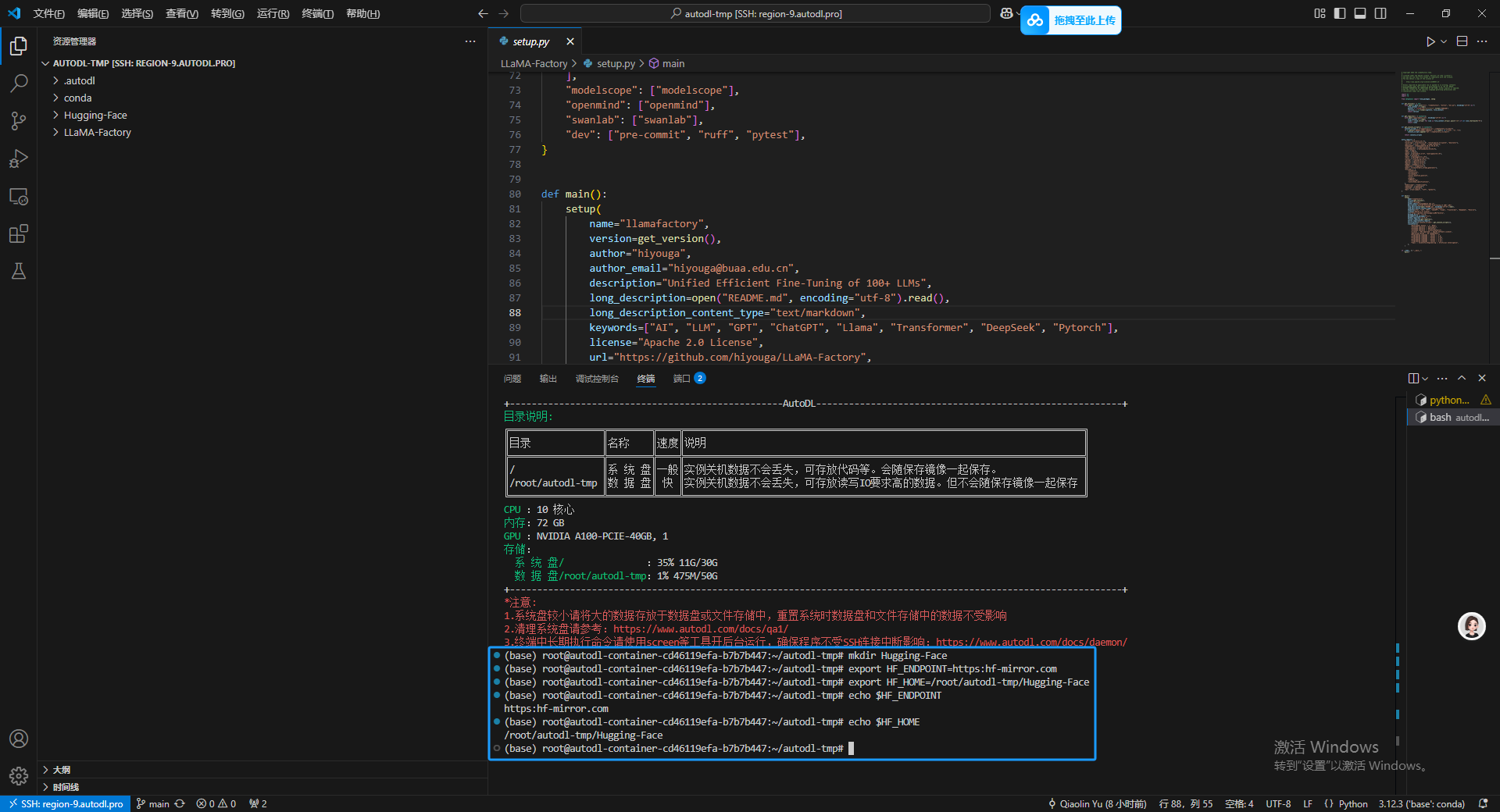
之后修改 HuggingFace 的镜像源,主要是保证使用国内的网络下载的速度。
export HF_ENDPOINT=https:hf-mirror.com
同时修改 HuggingFace 默认的下载路径到我们刚才新建的文件下里面。
export HF_HOME=/root/autodl-tmp/Hugging-Face
最后再使用 echo 命令察看两个关键配置是否生效了。
echo $HF_ENDPOINT
echo $HF_HOME
pip install -U huggingface_hub
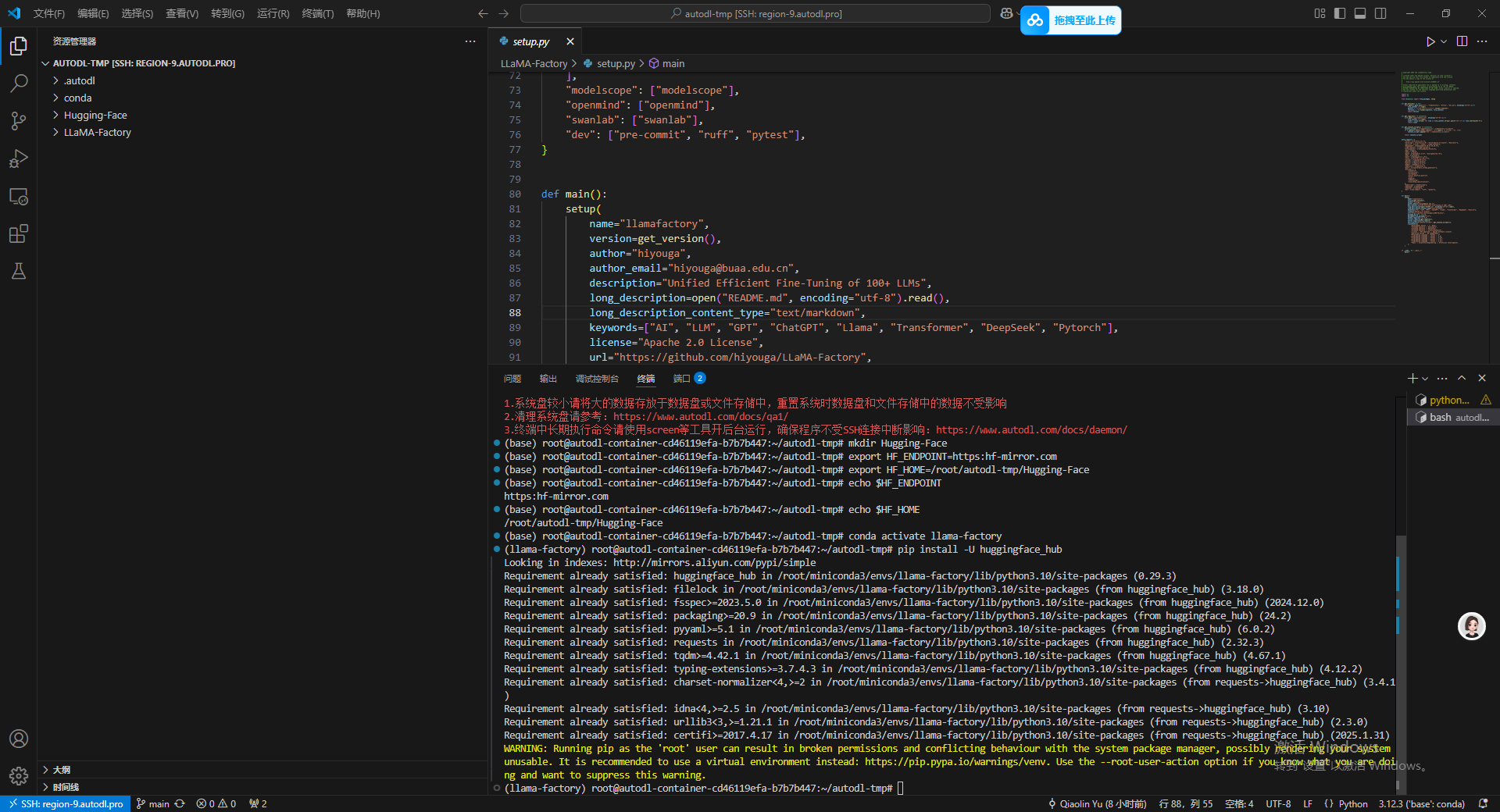
接下来就执行下载命令,这里下载的选一个 DeepSeek 蒸馏 通义千问 1.5B 的方便操作。
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
HuggingFace:https:huggingface.co
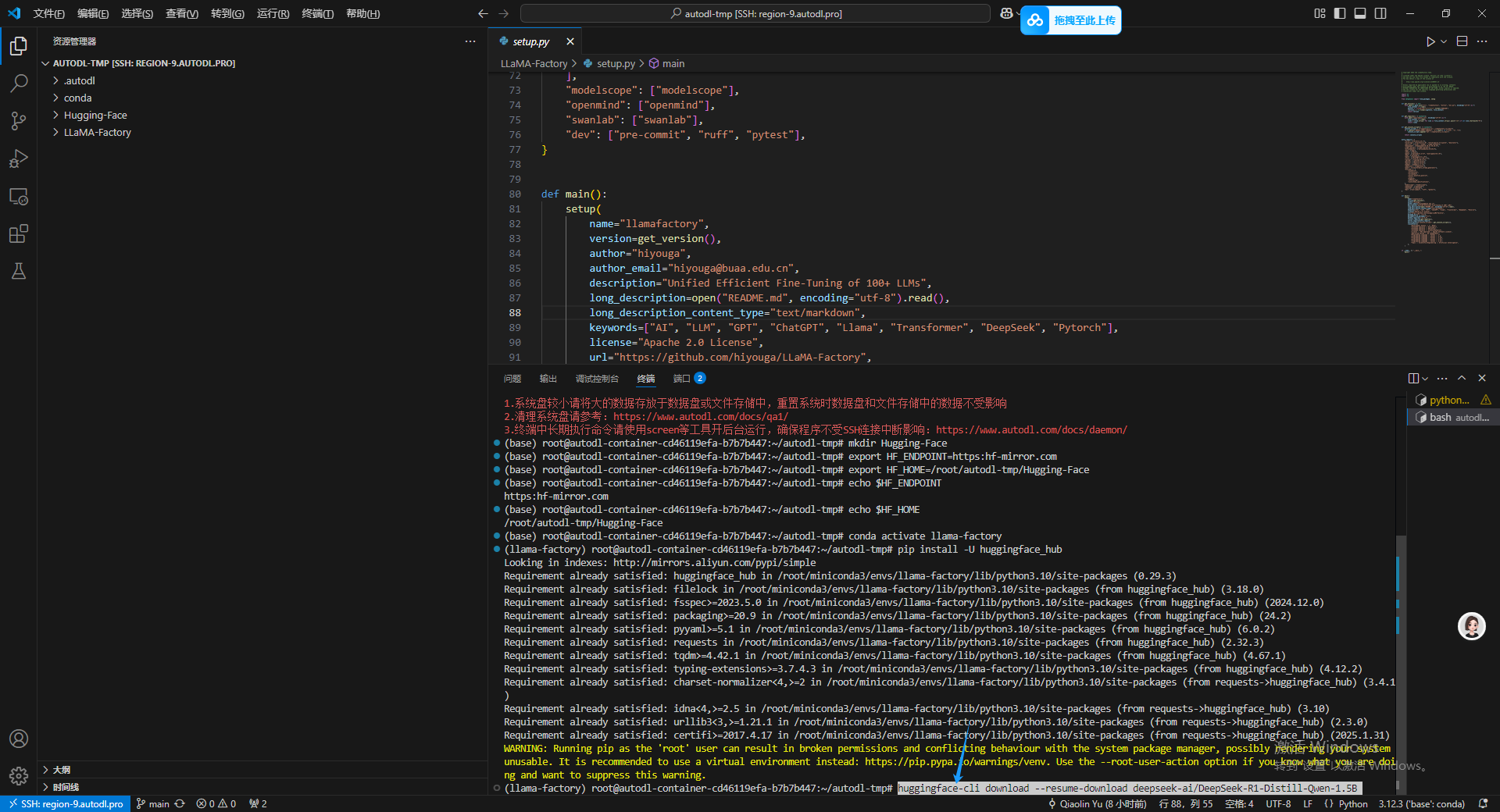
出现新的命令输入行之后,代表基座模型已经完成。
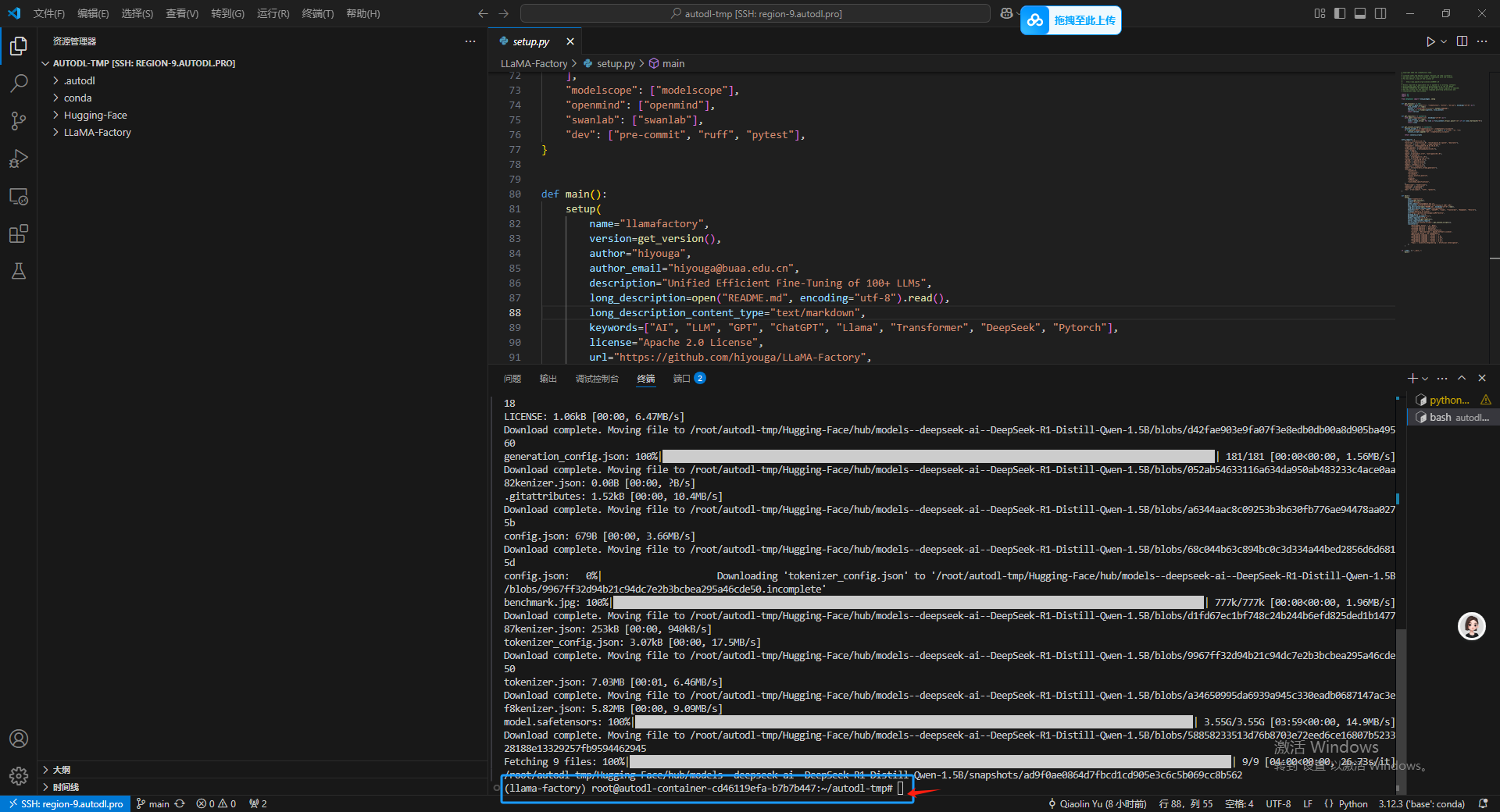
10.测试基座模型
首先去Hugging-Face/Hub/Models–deepseek-ai–DeepSeek-R1-Distill-Qwen-1.5B/snapshots 下复制模型的快照路径。
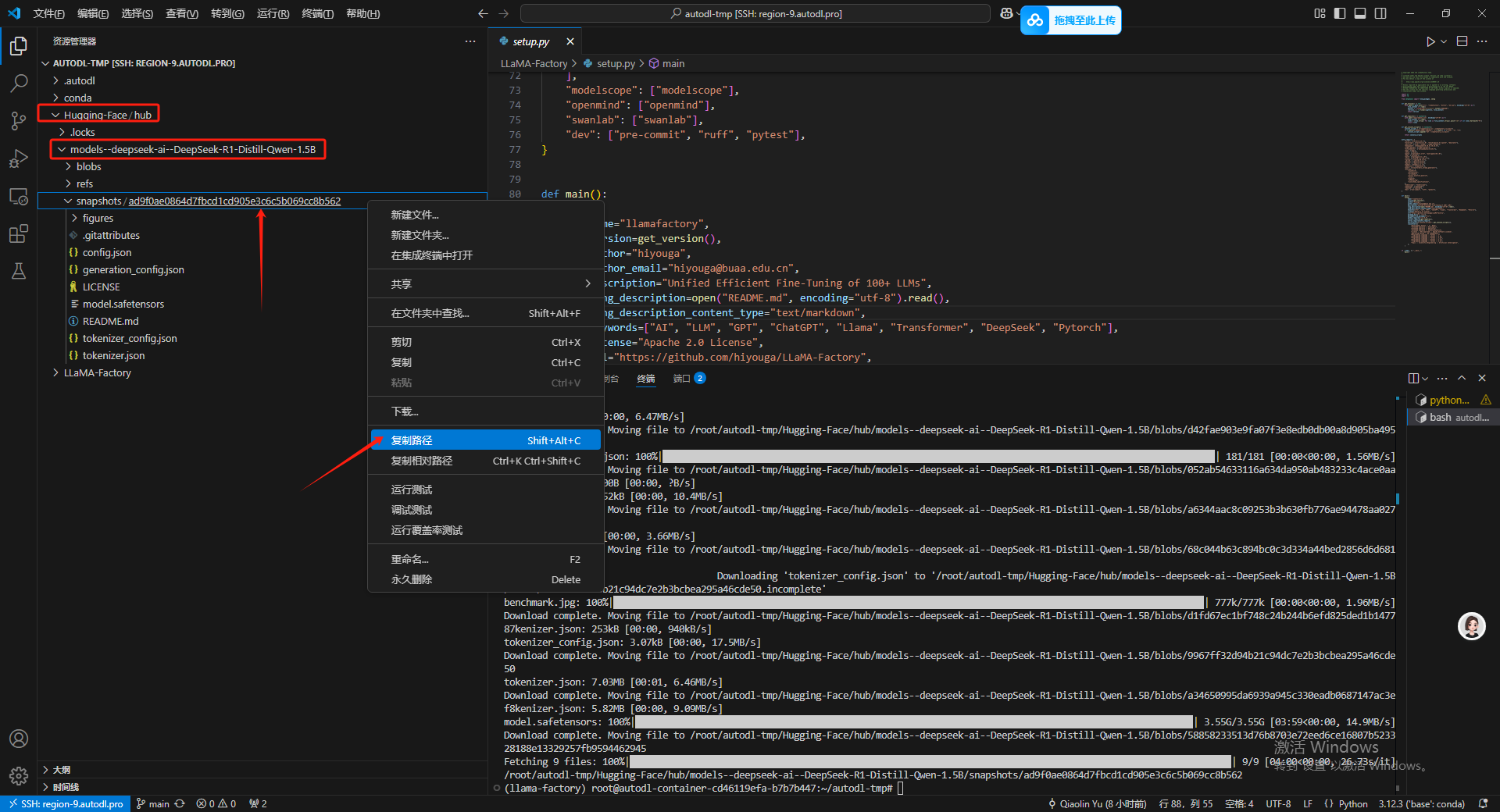
然后讲快照路径复制到Modelpath中,之后再模型名字部分选 DeepSeek的1.5B-Distill 蒸馏版本。
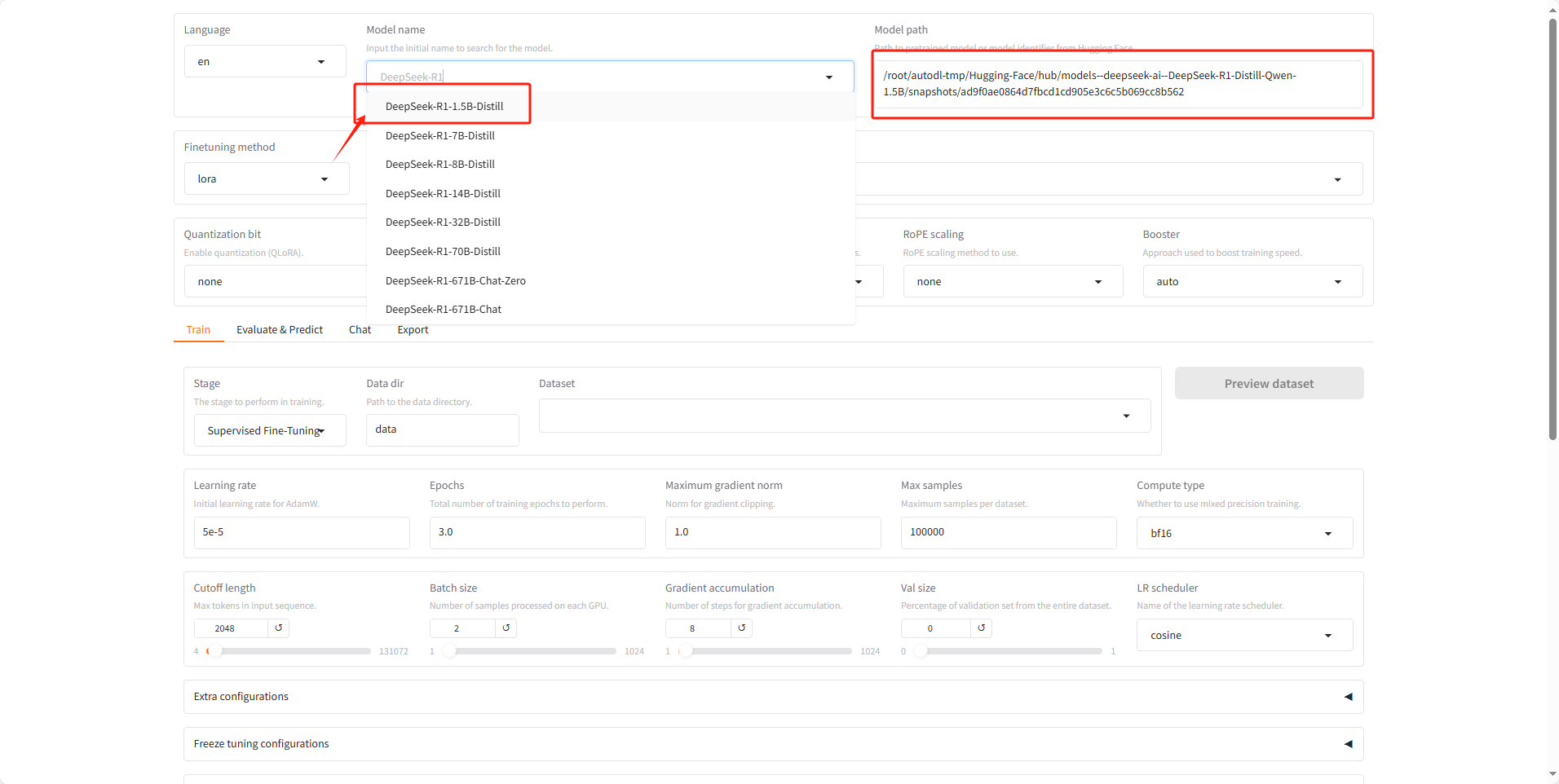
接下载点击中间选项卡中的 Chat 面板,然后点击 Load 加载模型。
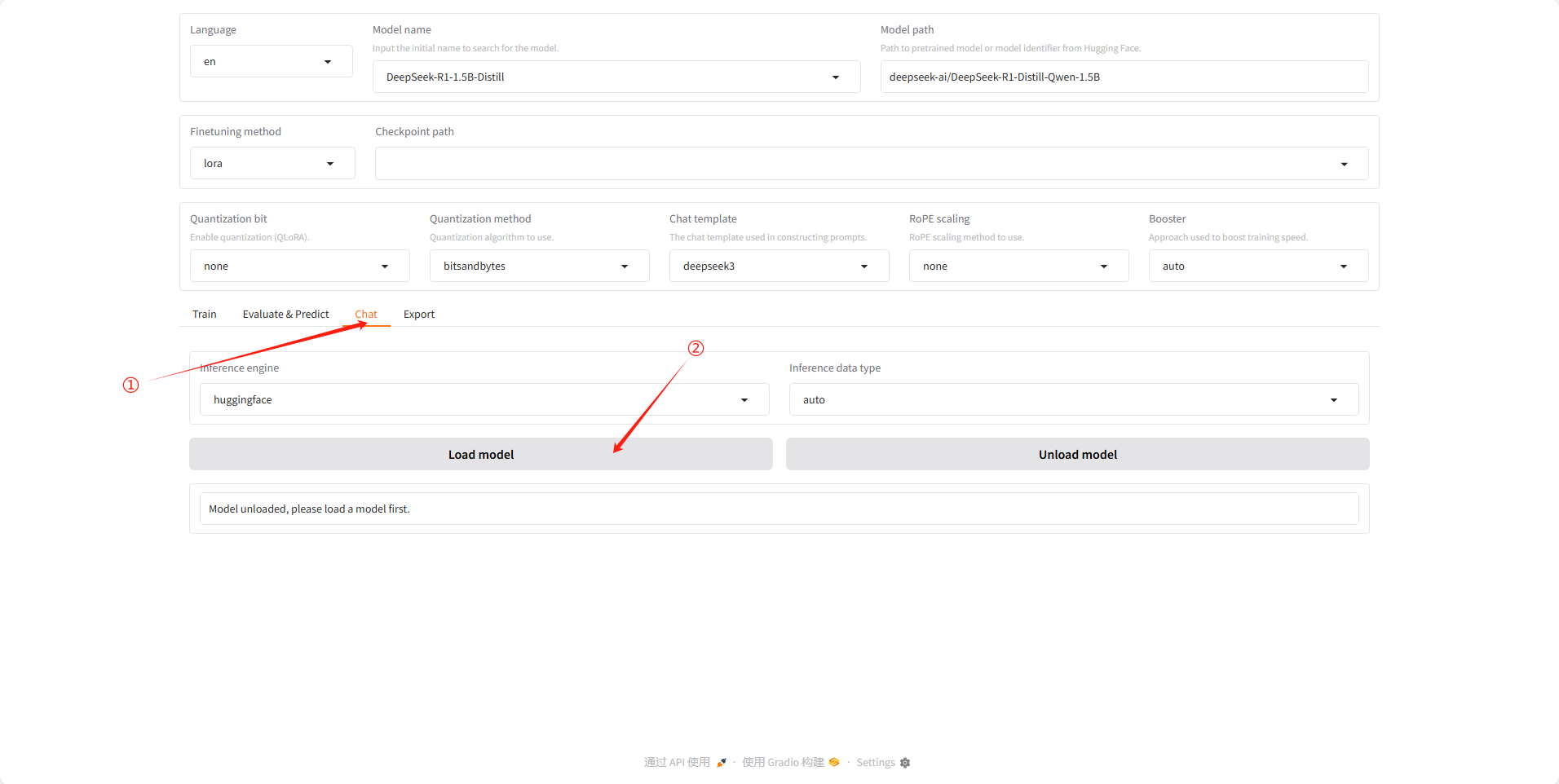
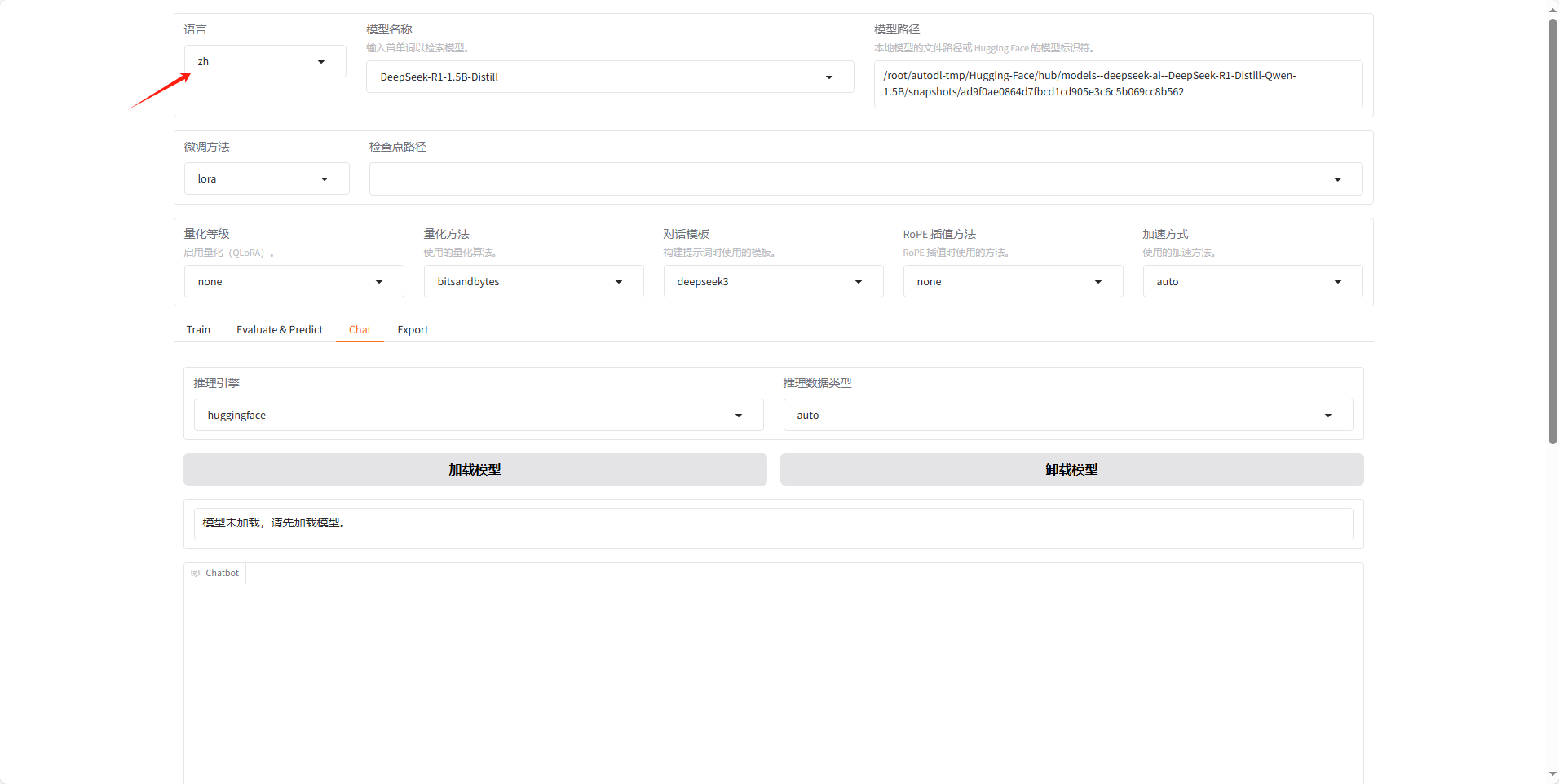
加载成功后页面如下,然后也可在左上角的语言部分选择 ZH 换成中文界面。
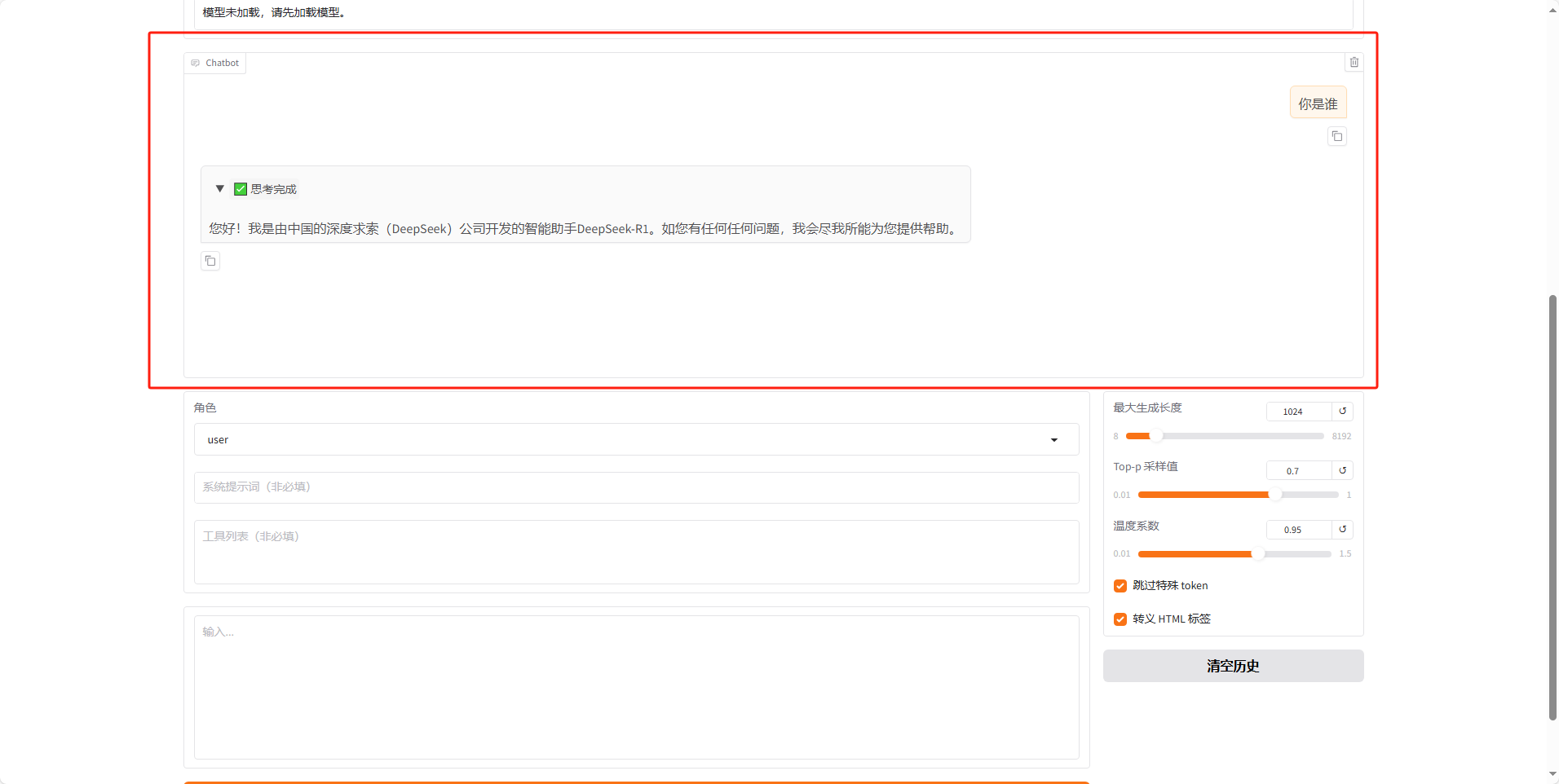
下滑网页在对话框内输入问题,然后点击提交,即可模拟对话效果。
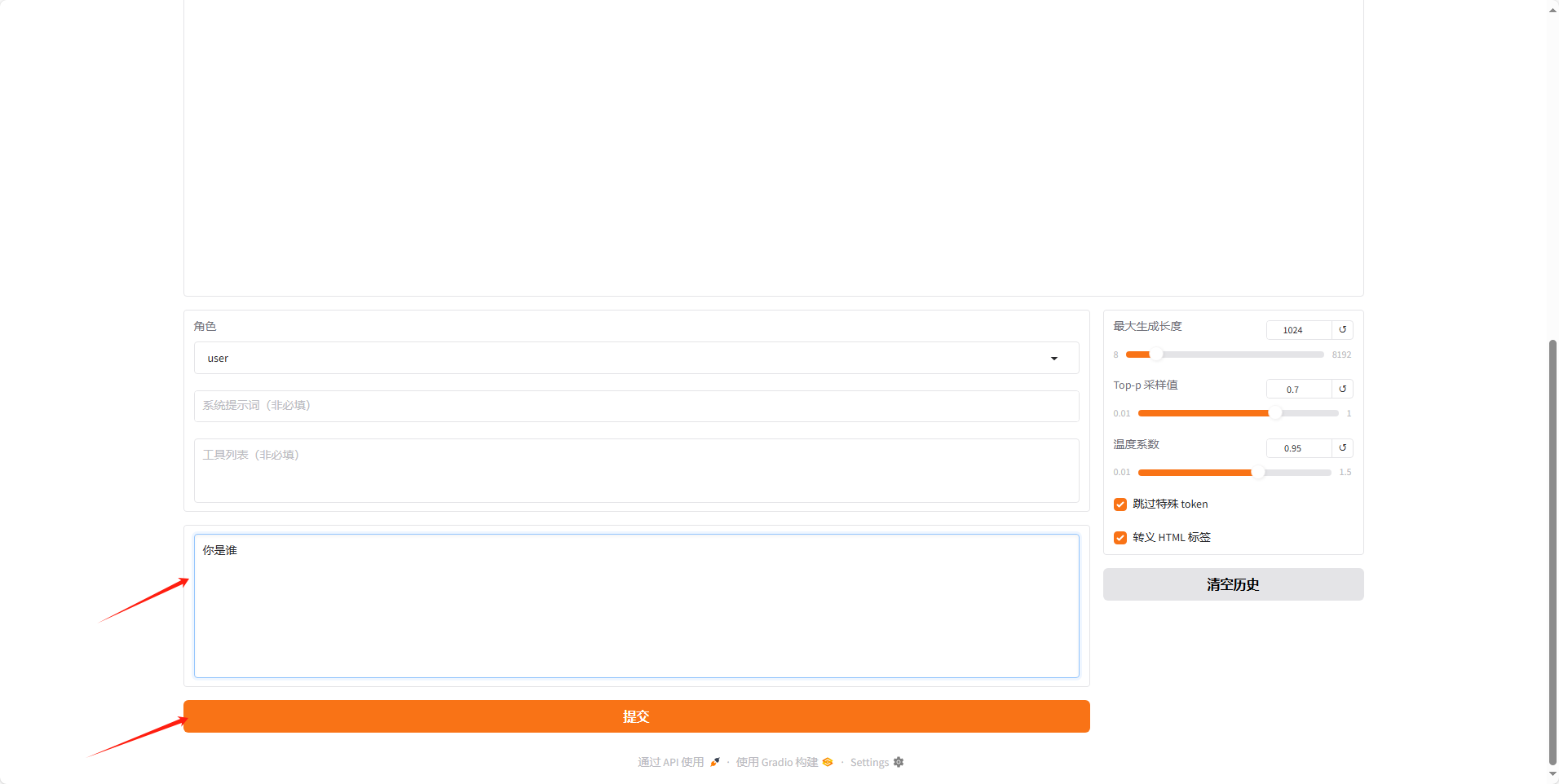
在 ChatBot 中可以看到回复的内容。
11.创建微调数据集
在LLaMA-Factory 的Data 文件夹下,可以找到示例,其中的 Readme 文件也给予了详细的操作文档,这里我就就用最简单的方式制作一下。
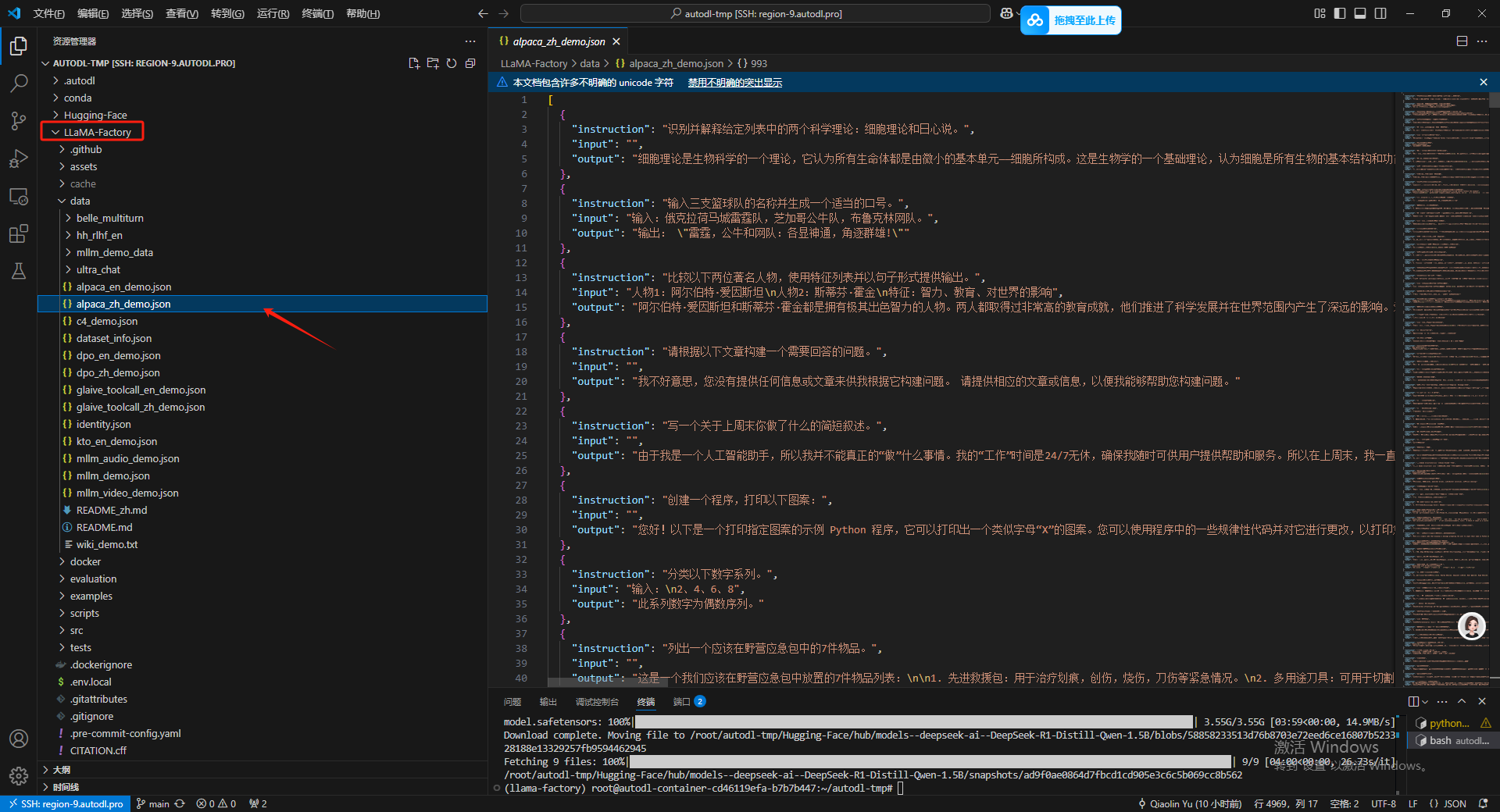
在这里就整两条,然后instruction 代表着用户的实际输入,input 代表着提问的辅助信息,output就是目标输出了,然后 input 在构建数据集的时候是可以省略的。
[
{
"instruction": "你是谁",
"input": "",
"output": "我是一个无情的机器人,生来的使命就是为人类服务"
},
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""
}
]
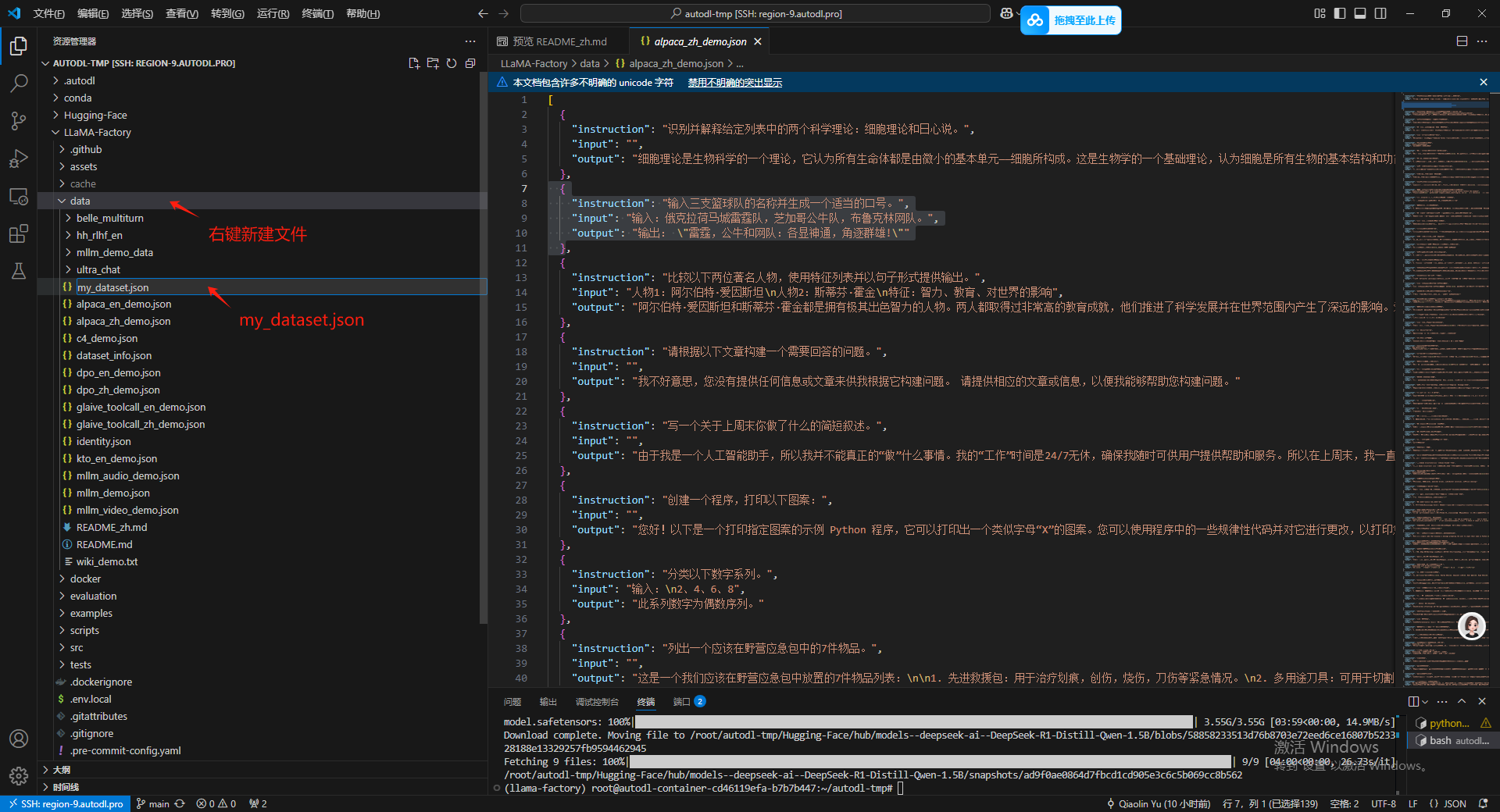
接下来在 Data 文件夹下新建一个json 文件然后把我们这个极简的数据集粘进去。
粘进去之后 顺手按下 Ctrl+S 保存一下。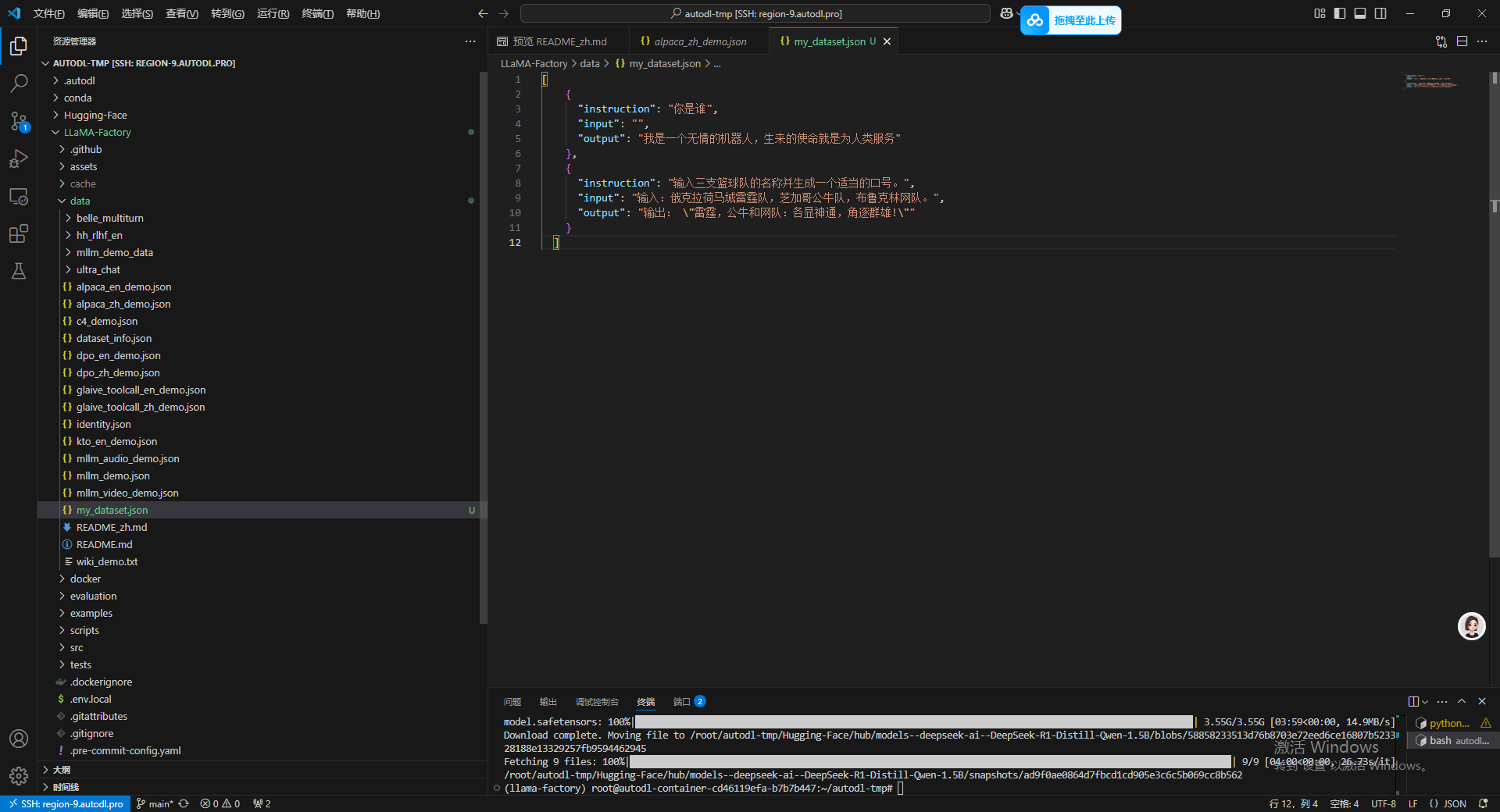
接下来打开 dataset_info.json 文件把我们自己数据集的信息补充到这个文件中,然后顺手按一下 Ctrl+S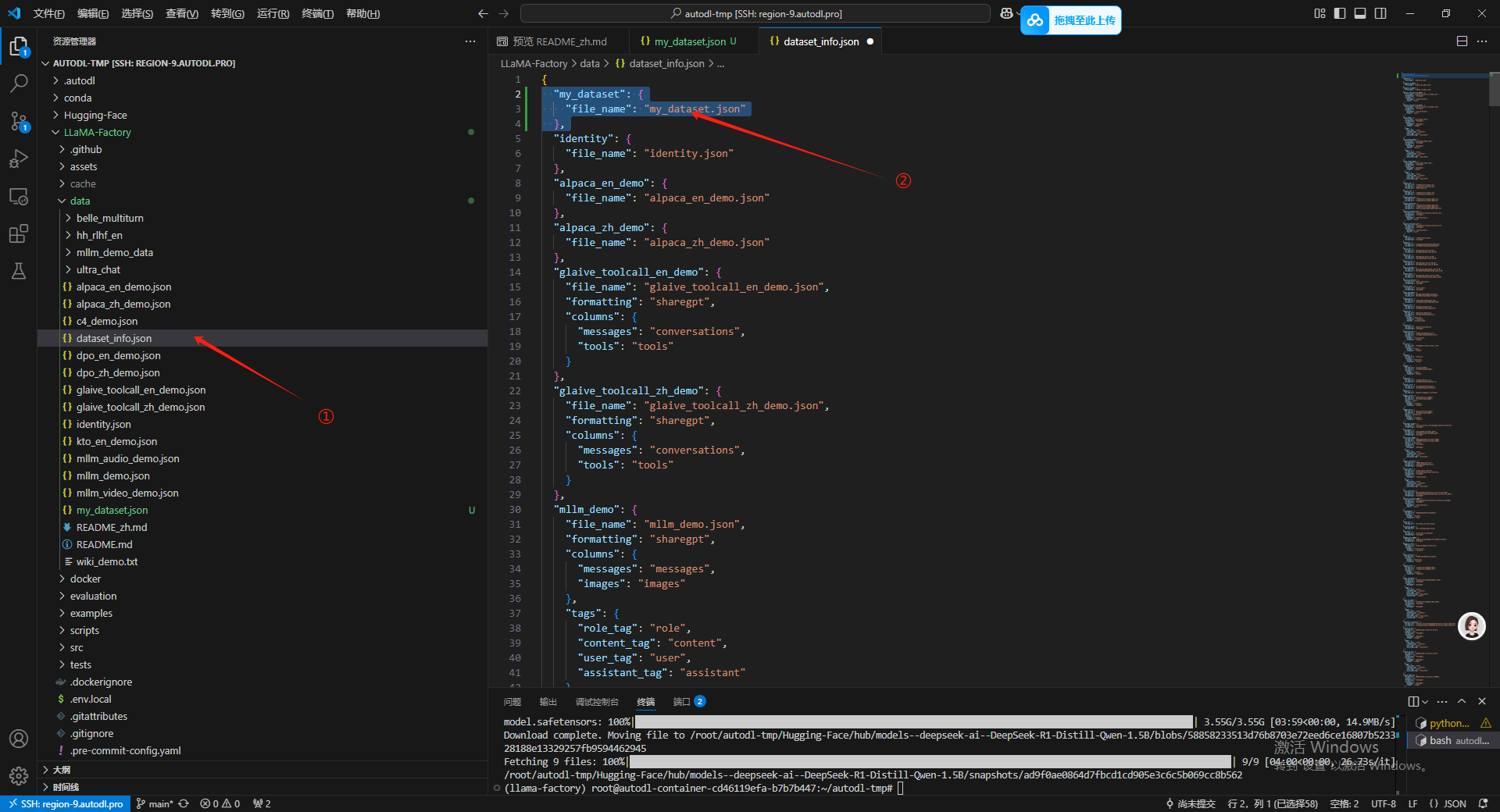
12.使用微调数据集进行训练
然后回到微调页面,选择Train 选项卡,然后选择自己的 mydataset.json 数据集。
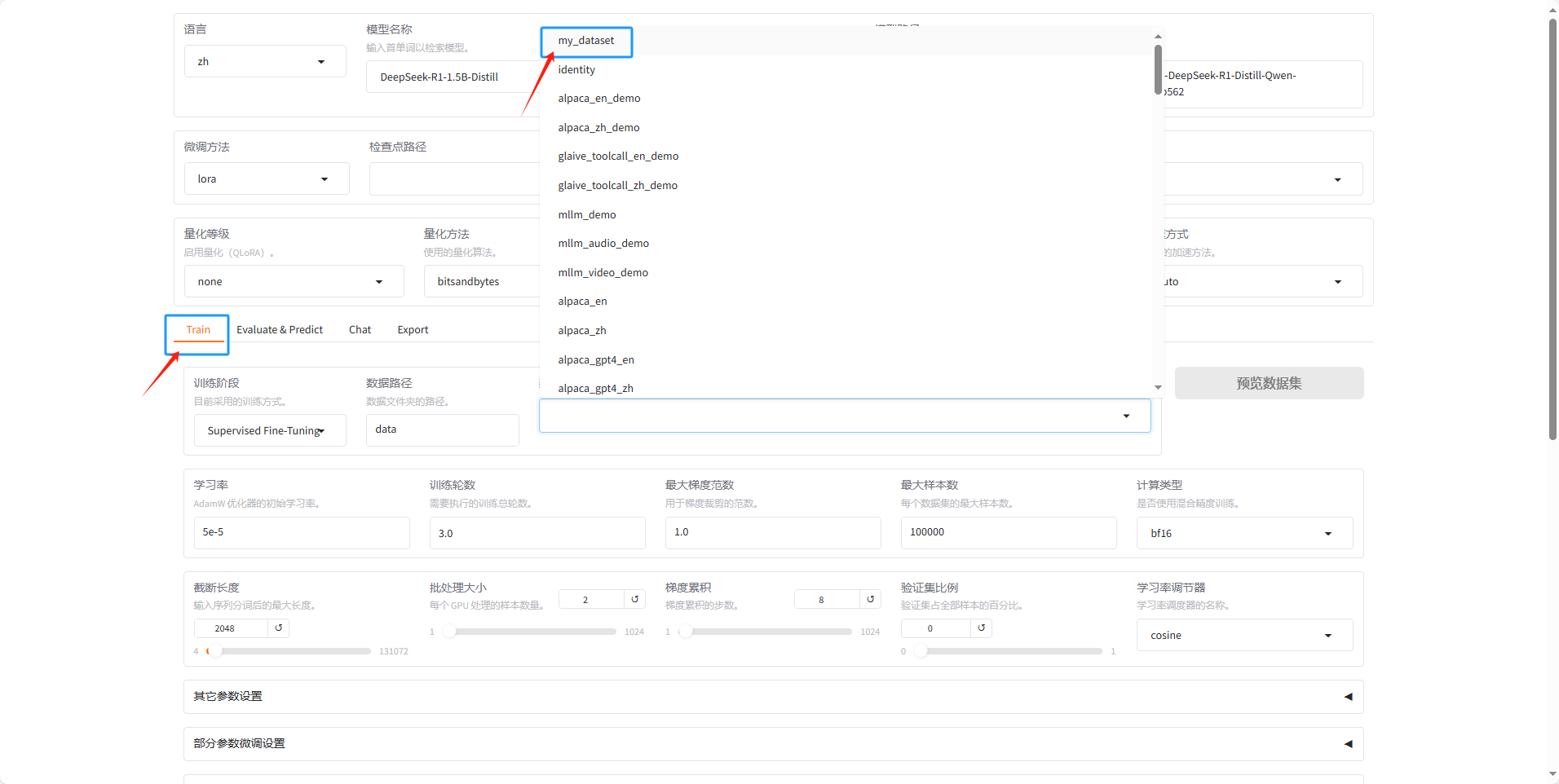
然后可以点击预览一下数据集看数据集内容对不对,这里应该还是可以同时选很多个数据集的。

之后训练轮数这里给调到100让他充分训练,其他的参数都先不动。
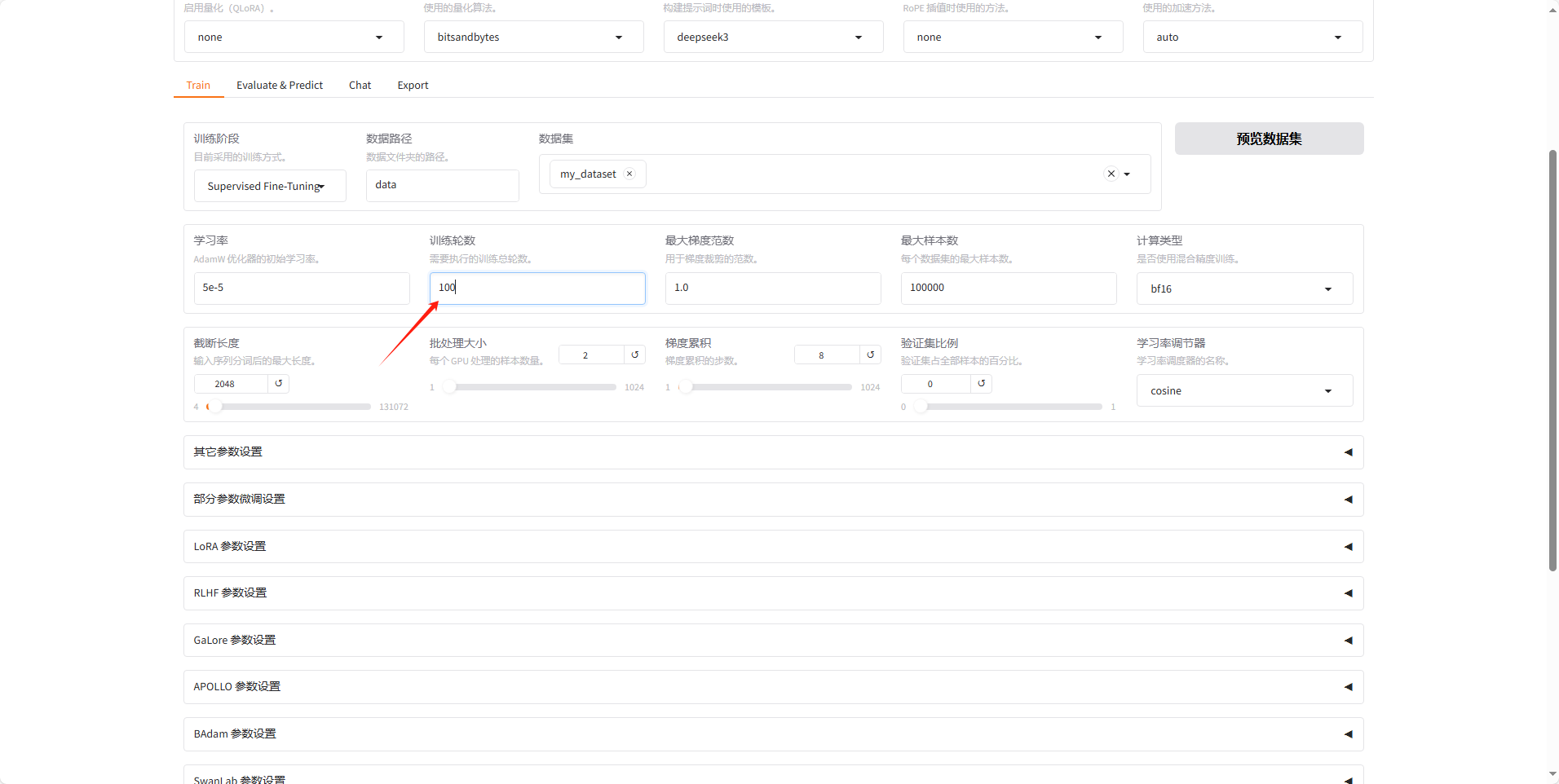
之后直接下滑到底部点击开始训练。
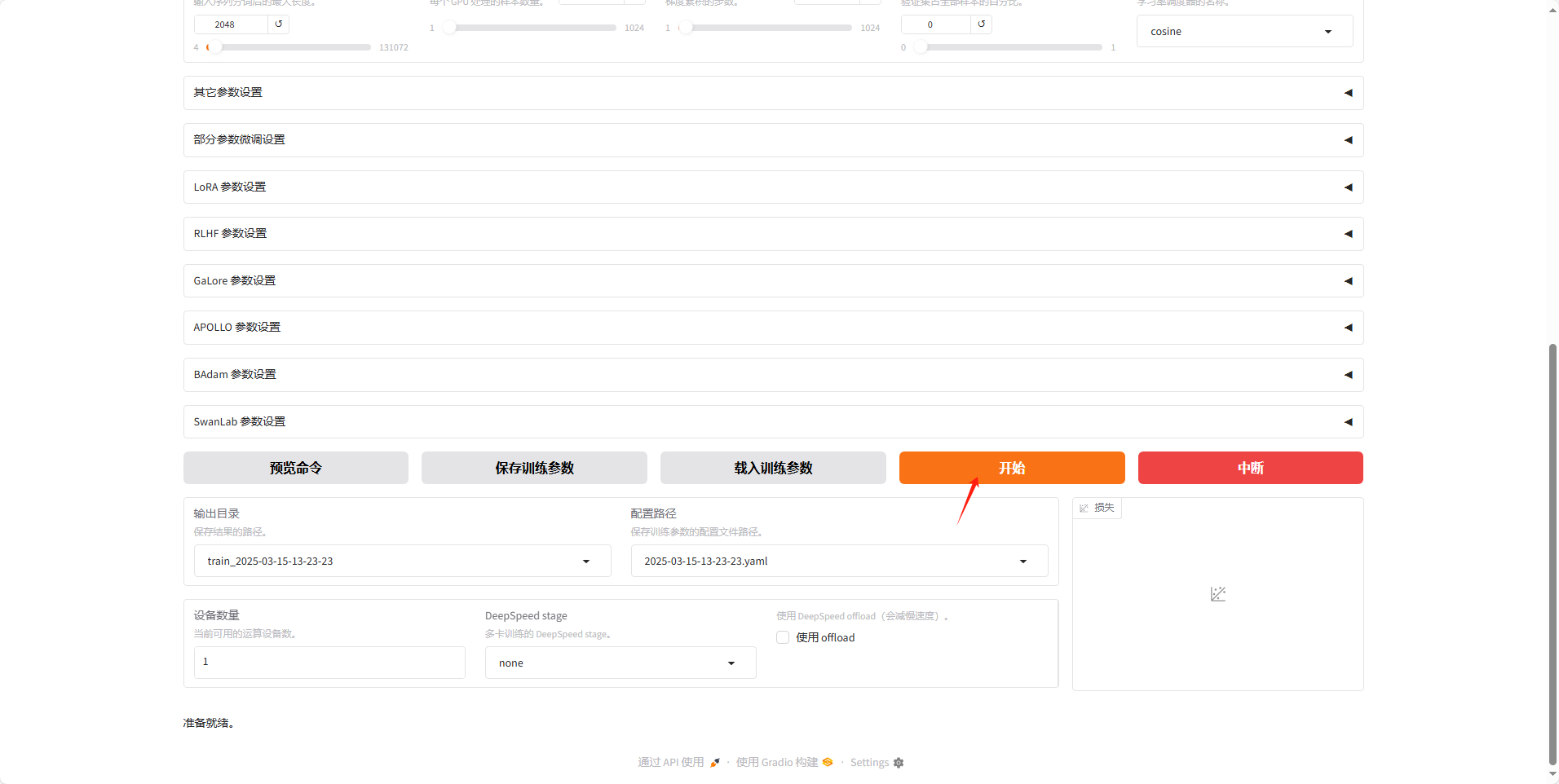
之后等待训练完成,可以看到右侧的损失曲线也已经充分收敛了。
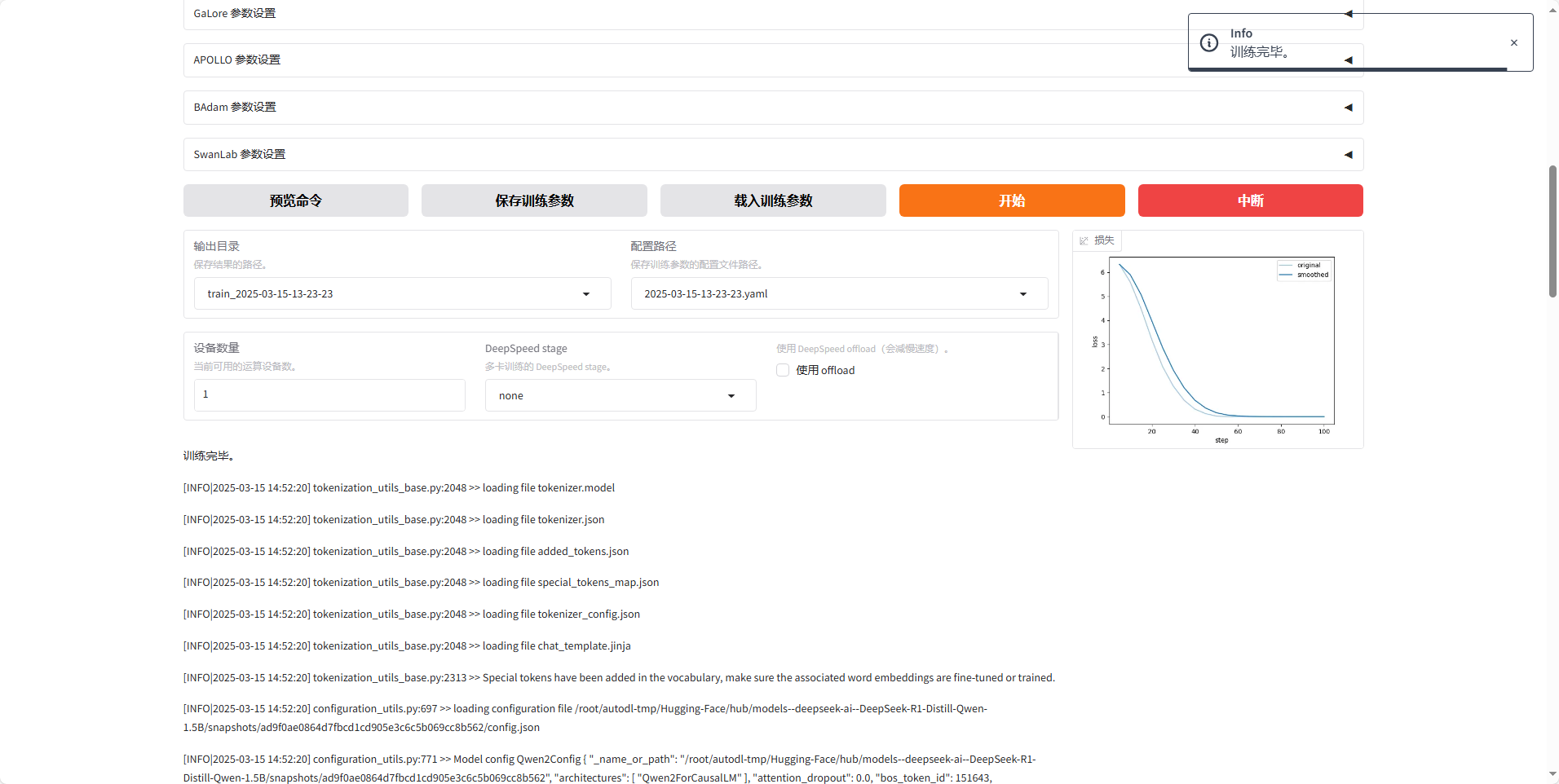
13.测试微调模型
微调好模型之后会生成一个检查点路径,首先会到Chat 页面,然后去选择这个要加载的检查点。
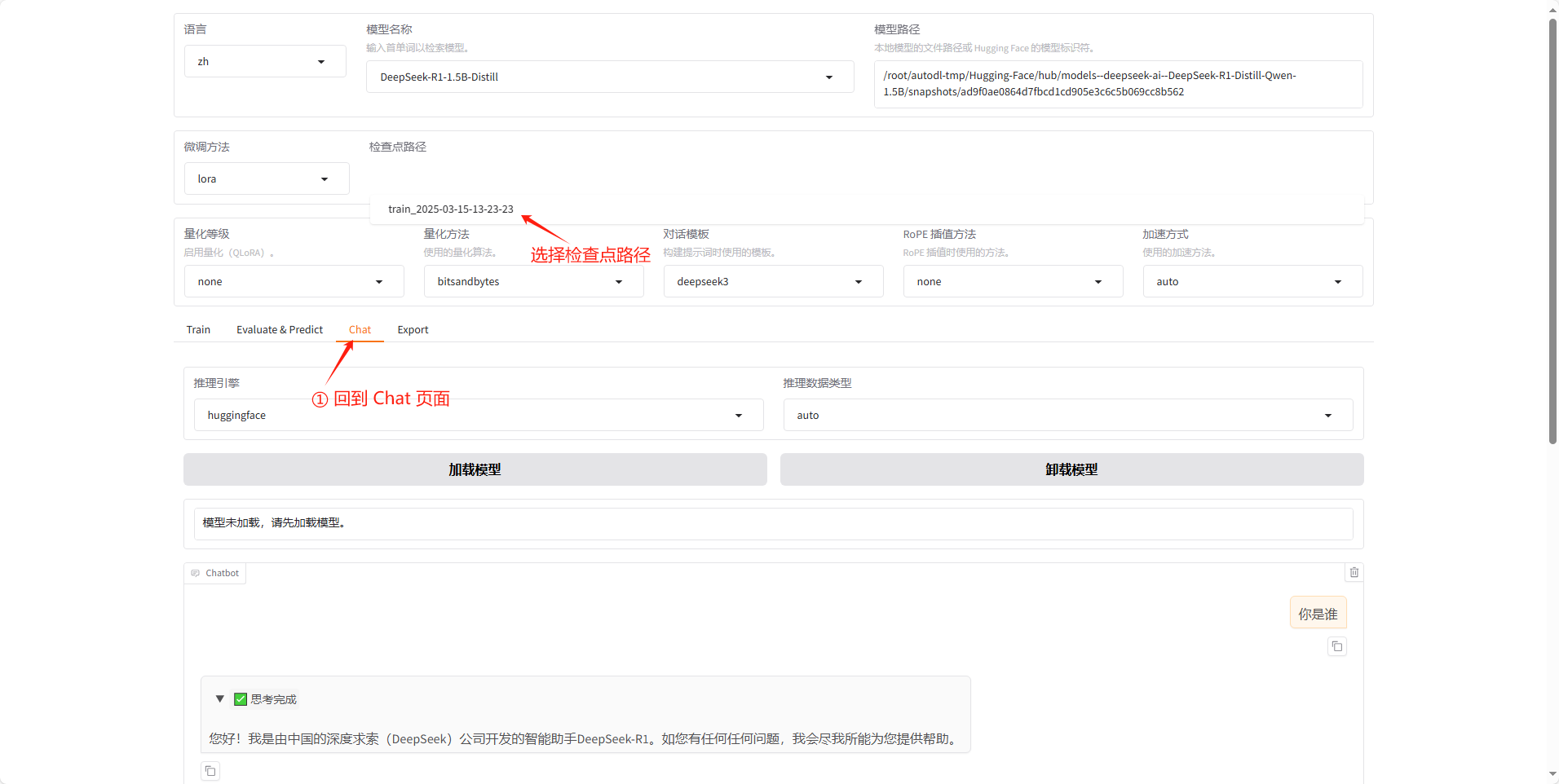
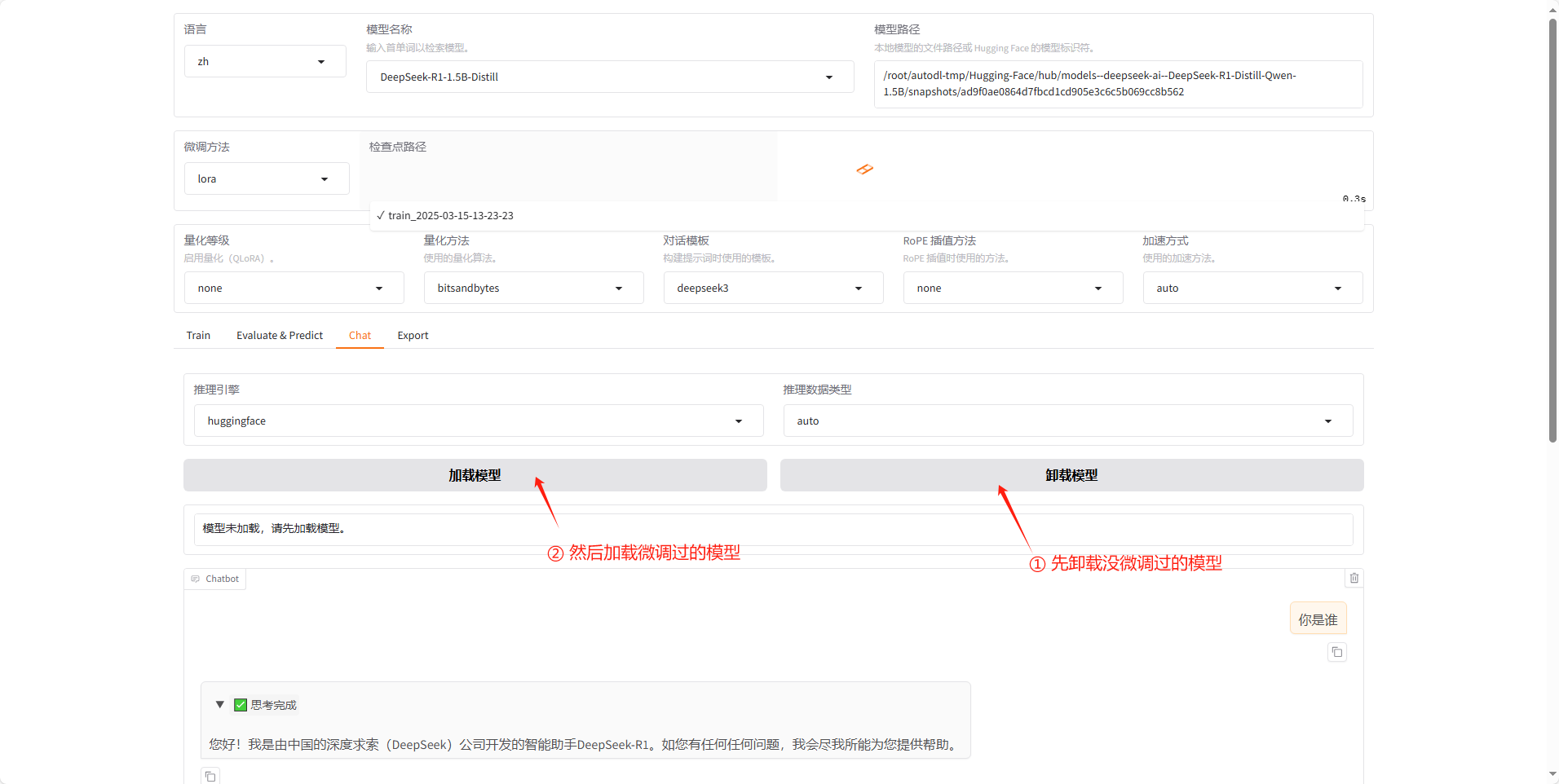
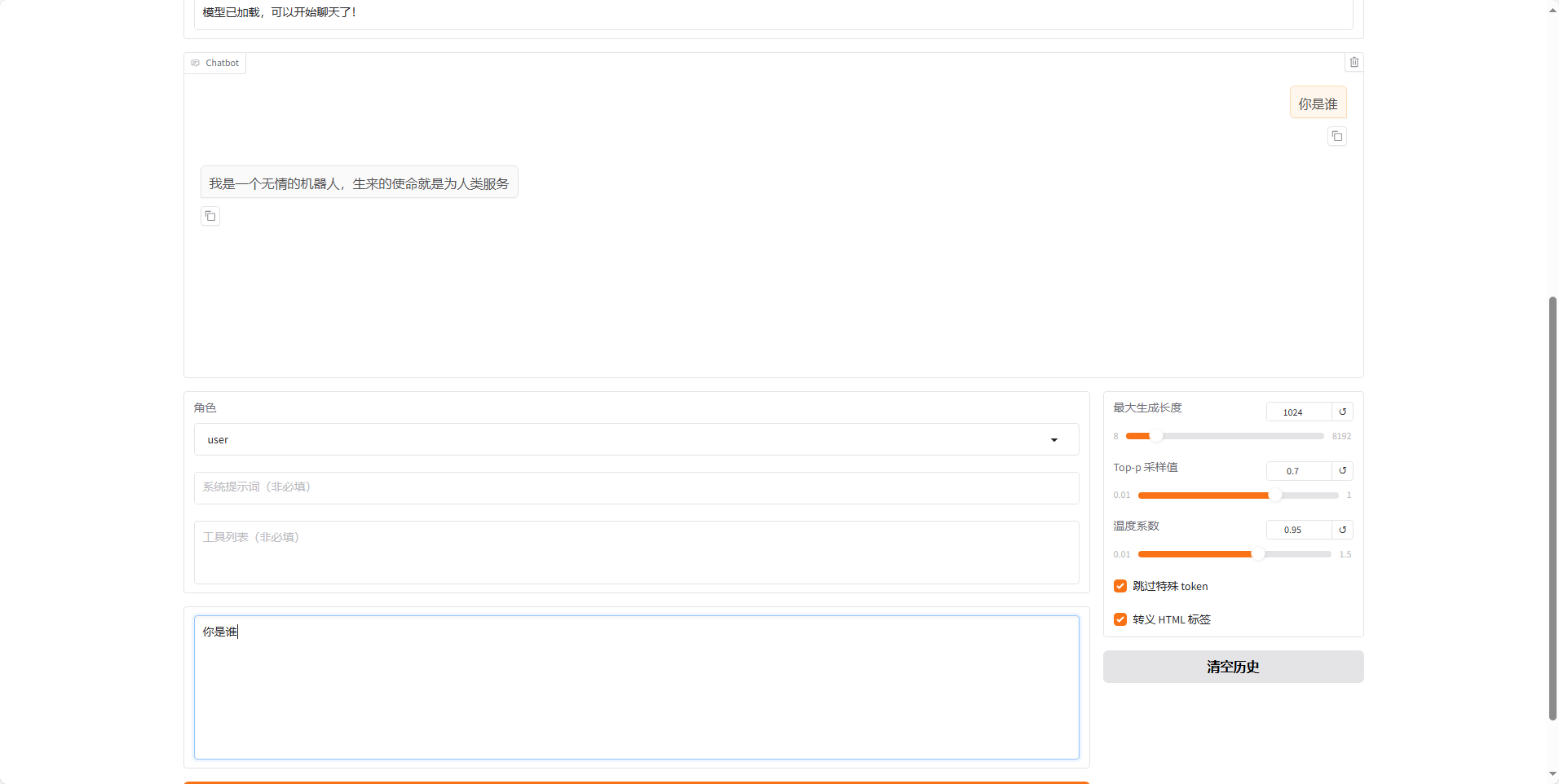
然后再和他对话,可以看到他的回复已经和我们提供的数据集中的内容一致了,然后另外一个我也测试了效果一般,估计是学的不太好,之后可以去调参或者换更聪明的模型。但通过第一个也已经能验证我们微调之后的效果了。
14 导出微调模型
首先是先建一个文件夹,这个文件夹用于保存导出的模型。
mkdir -p Models/deepseek-r1-1.5b-merged
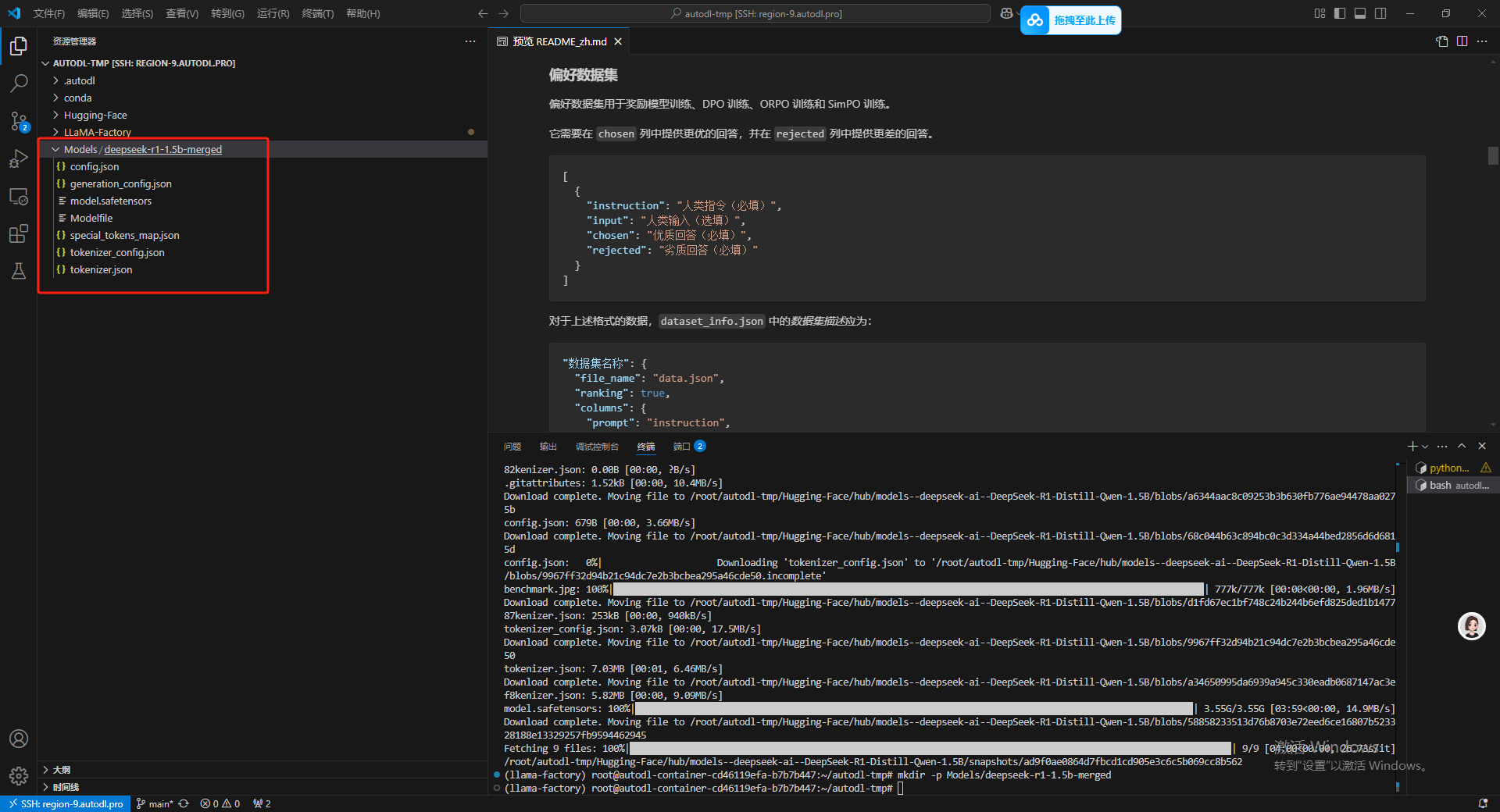
在运行完了命令之后,诞生了一个双层的的文件夹。
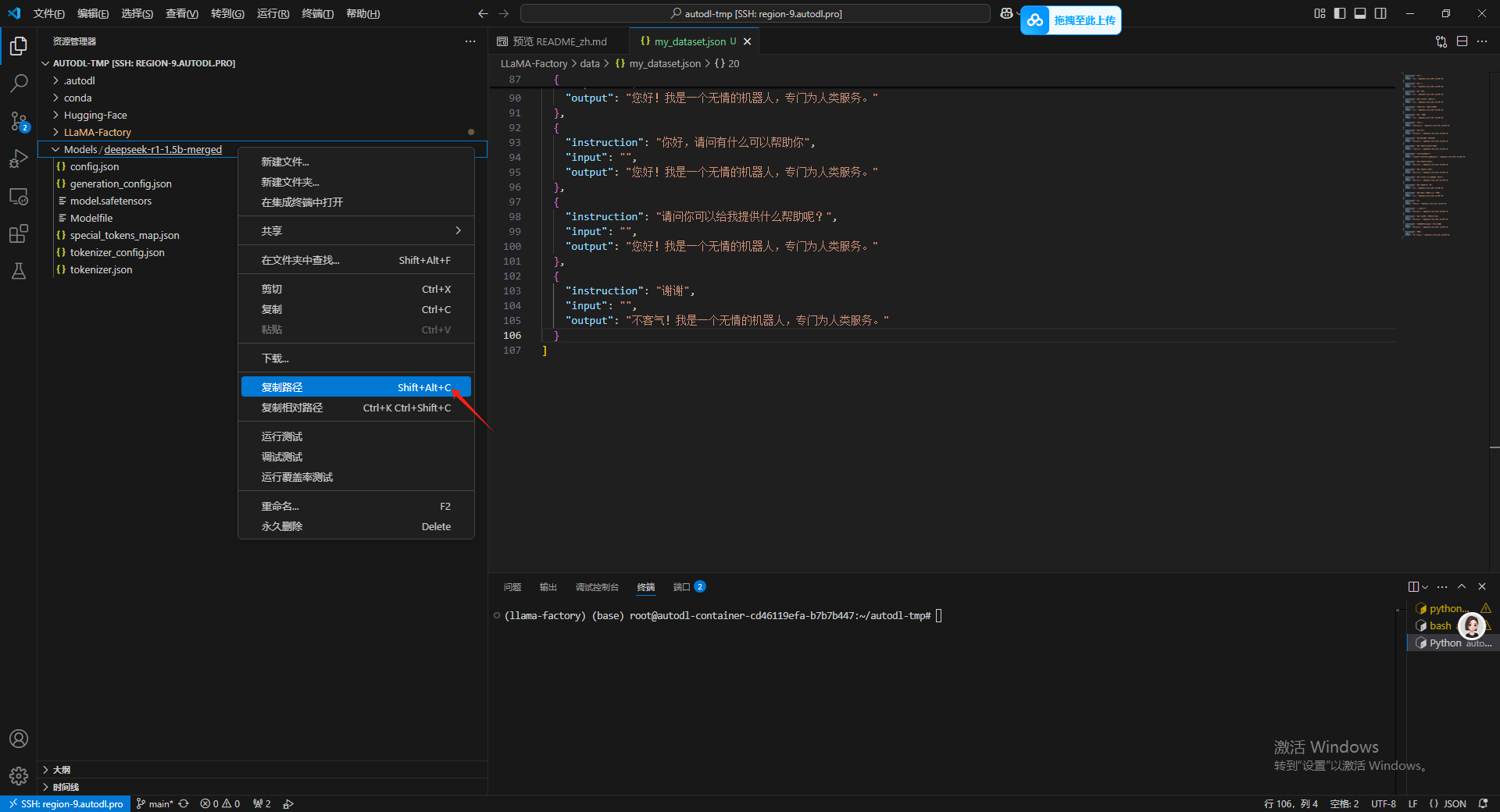
然后点击右键复制全局路径。
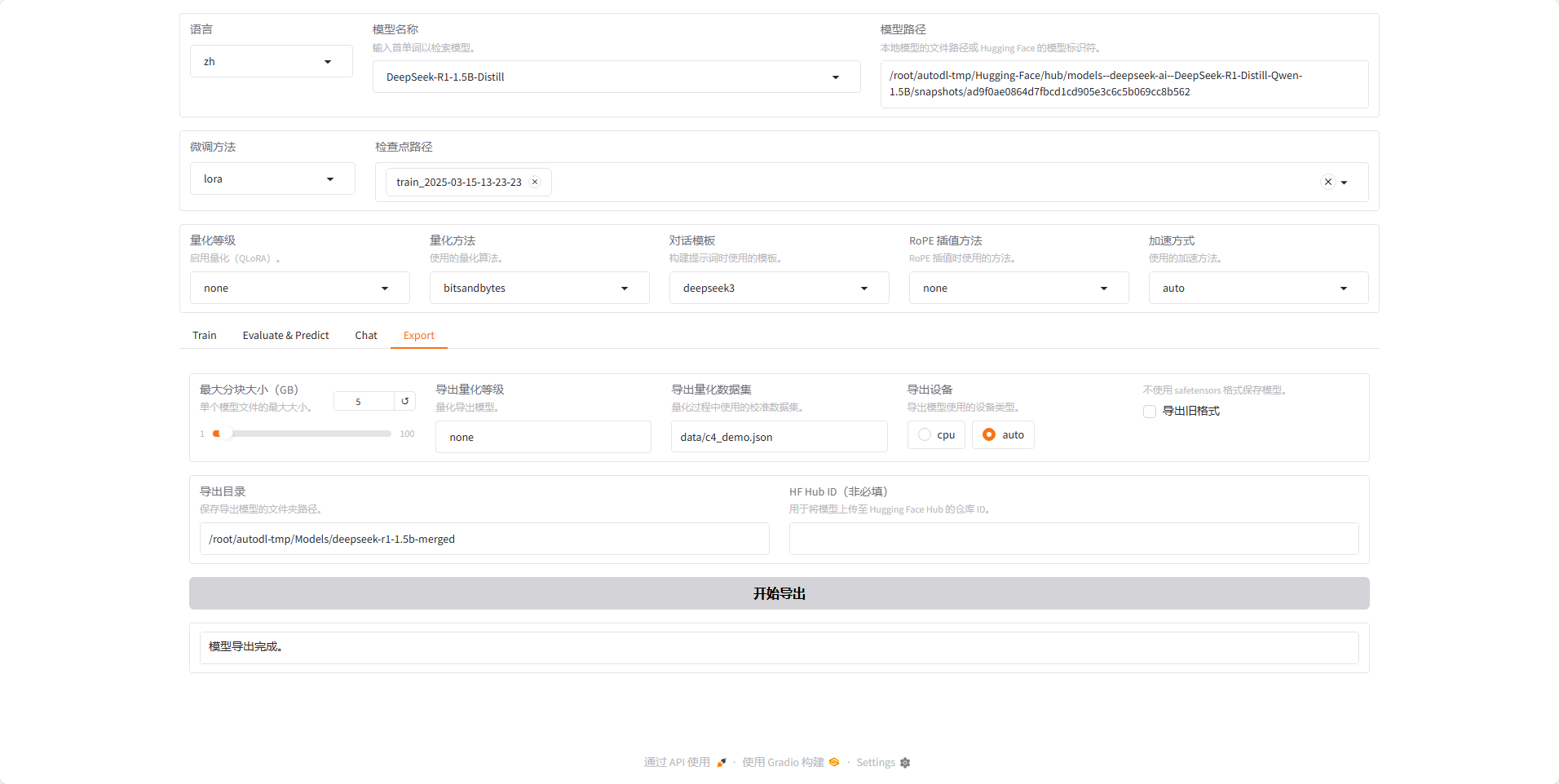
将路径复制到导出目录,然后导出设备选自动,这样他就能用 GPU ,然后点开始导出。
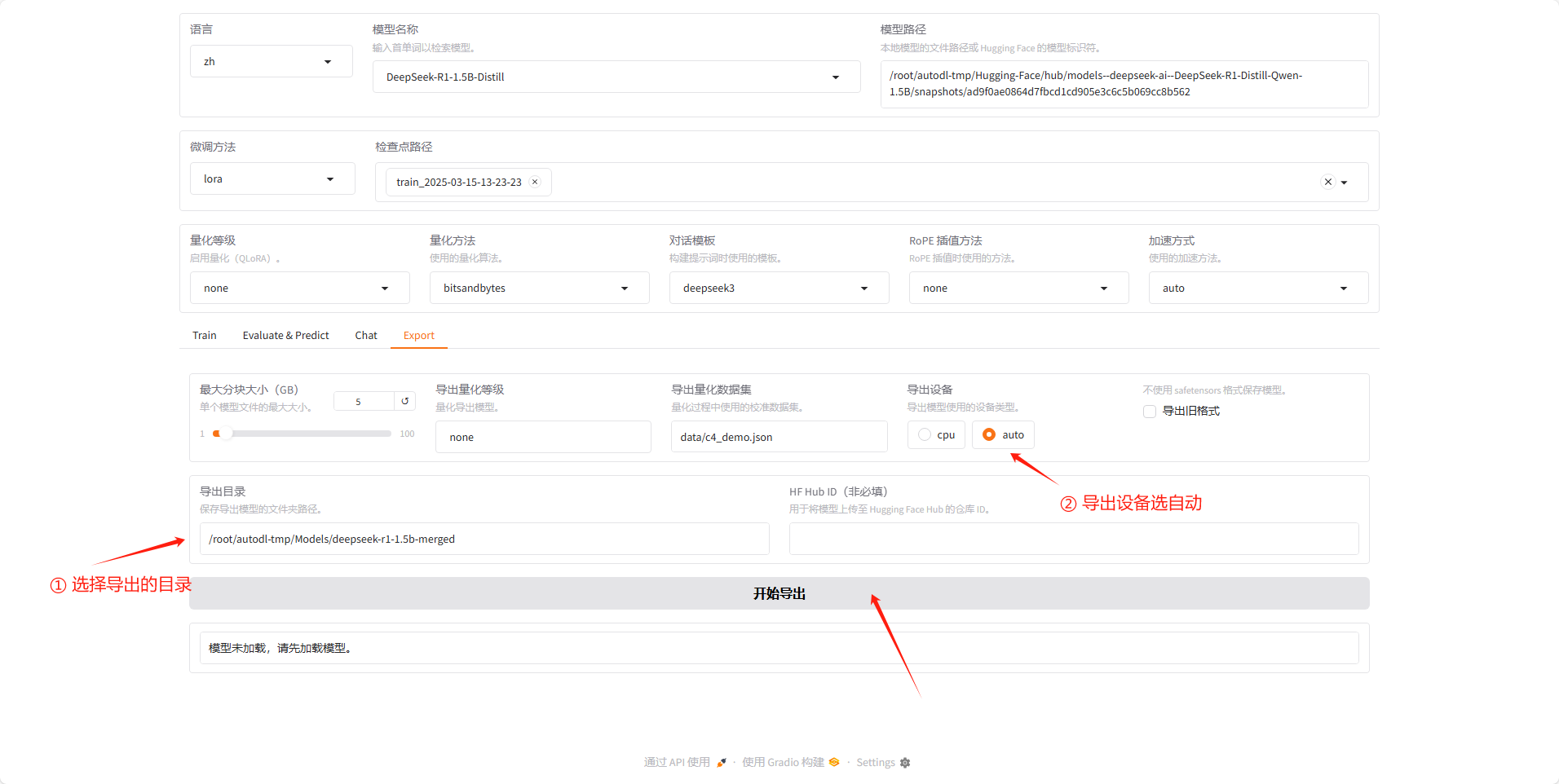
等待导出完成,在页面下方会提示导出完成了。
然后这边在文件夹里也已经能看到导出的模型了。
15.使用导出的模型
导出了模型之后可以在左侧的资源管理器中。之后复制这个导出的模型的路径。
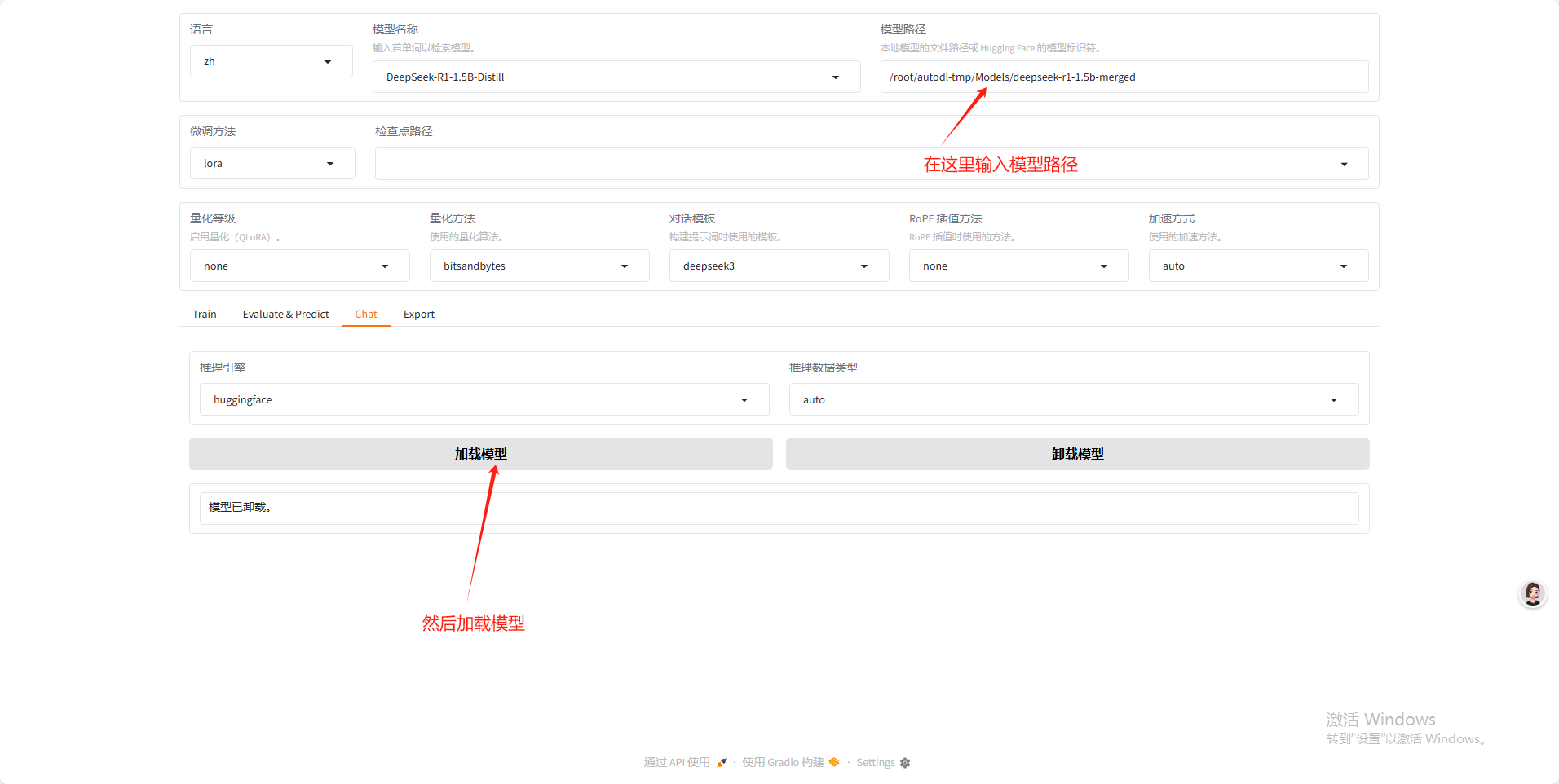
加载之后输入聊天即可。
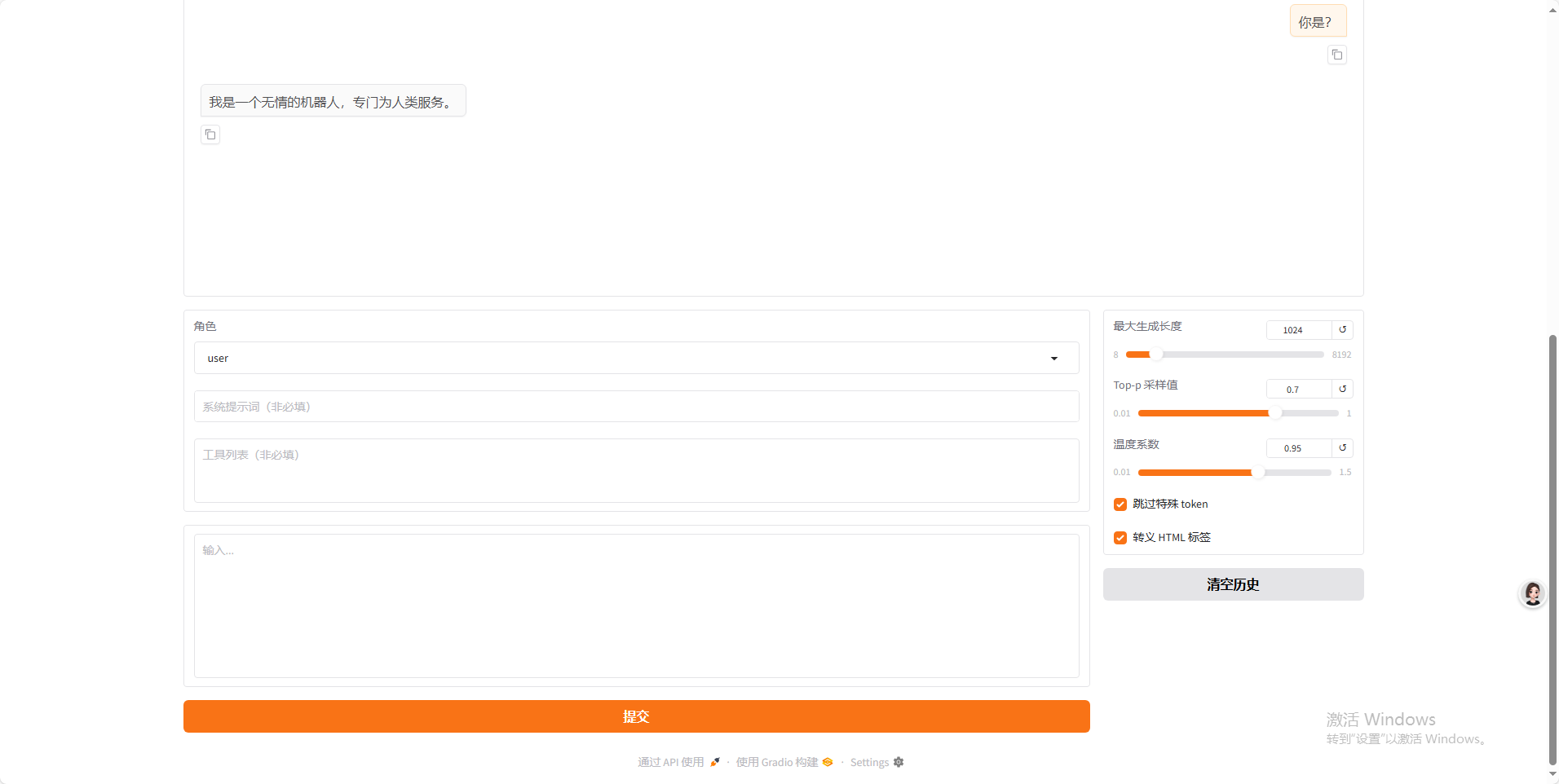
结束
OK,到此为止整个微调的流程就基本结束了,但其实最后我还是想尝试一下使用代码调用的方式,但是我发现 python 代码调用的输出结果和使用LLaMA Board 加载之后输出的结果不太一样,目前来说微调模型还是非常麻烦,虽然也有成功的时候,但我还没找到对应的规律,等我找到了之后我可以在这篇文章结束之后补一下,我先研究研究,总之是一篇非常累的文章,但我也学到了不少东西作为入门的内容应该也已经是足够了。
附件 Python 调用模型简易代码
from transformers import AutoModelForCausalLM, AutoTokenizer
# 指定模型路径
model_path = "Models/deepseek-r1-1.5b-merged"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
# 输入文本
input_text = "你是谁"
# 对输入文本进行编码
inputs = tokenizer.encode(input_text, return_tensors="pt")
# 生成文本
outputs = model.generate(inputs, max_length=50, num_return_sequences=1)
# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 32
32 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)