DeepSeek发布的Janus系列解读
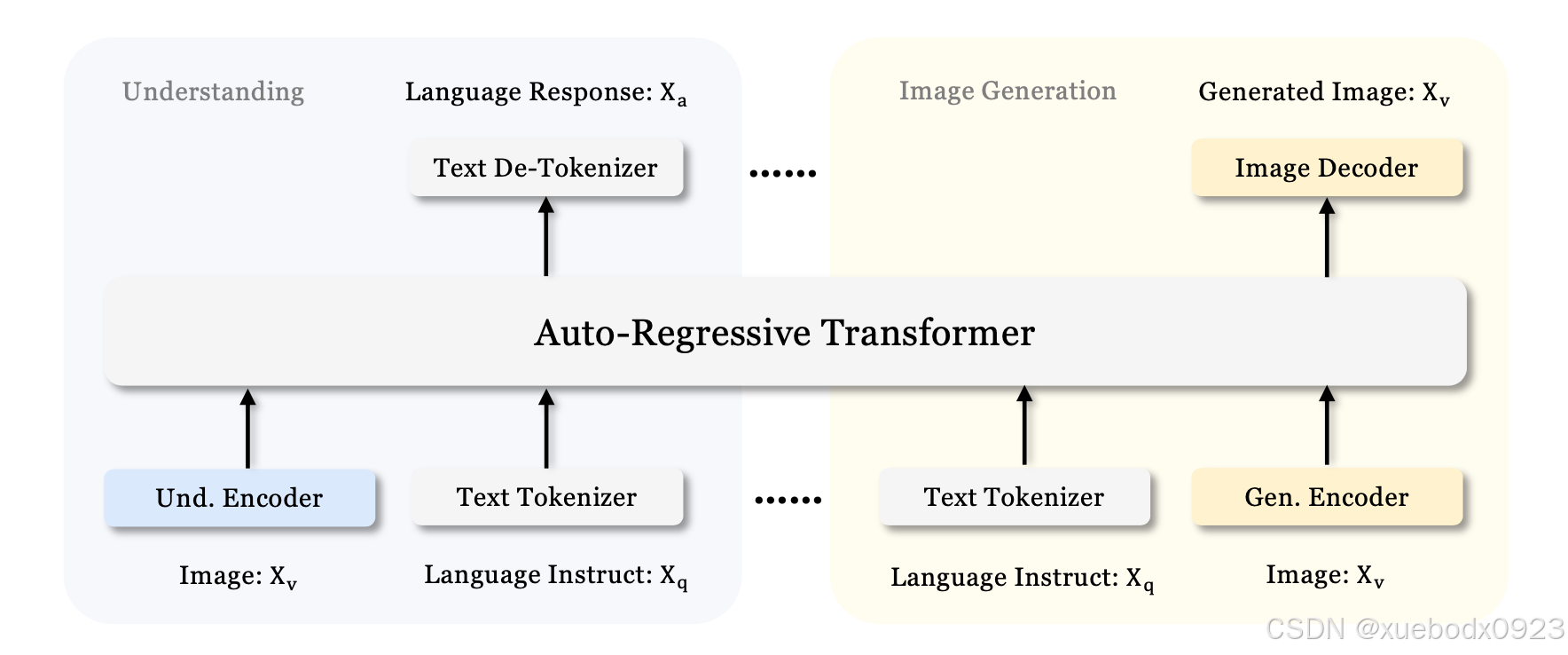
Janus一共有三个系列,分布是Janus,Janus-Pro,JanusFlow。他们统一了多模态的理解和生成。之前的研究通常依赖单一的视觉编码器来同时完成这两项任务,现在Janus 将视觉编码过程解耦,分别为视觉理解和视觉生成提供独立的编码器。支持4k的上下文长度。我们在两个基准测试 GenEval 和 DPG-Bench 上评估性能。总体而言,Janus-Pro 超越了之前的统一多模态模型以
1. 摘要
Janus一共有三个系列,分布是Janus,Janus-Pro,JanusFlow。他们统一了多模态的理解和生成。之前的研究通常依赖单一的视觉编码器来同时完成这两项任务,现在Janus 将视觉编码过程解耦,分别为视觉理解和视觉生成提供独立的编码器。支持4k的上下文长度。我们在两个基准测试 GenEval 和 DPG-Bench 上评估性能。总体而言,Janus-Pro 超越了之前的统一多模态模型以及一些特定任务的模型。
2. Janus-1.3B
Janus将视觉编码解耦,以实现多模态理解和生成。Janus 基于 DeepSeek-LLM-1.3b-base 构建,该库在大约 500B 个文本标记的语料库上进行训练。支持 384 x 384 图像输入。
Janus 采用了一个三阶段训练过程。第一阶段专注于训练适配器和图像头部。第二阶段处理统一预训练,在此期间,除了理解编码器和生成编码器之外的所有组件都会更新其参数。第三阶段是监督微调,在第二阶段的基础上,进一步在训练过程中解锁理解编码器的参数。
3. Janus-Pro(1B,7B)
3.1 介绍
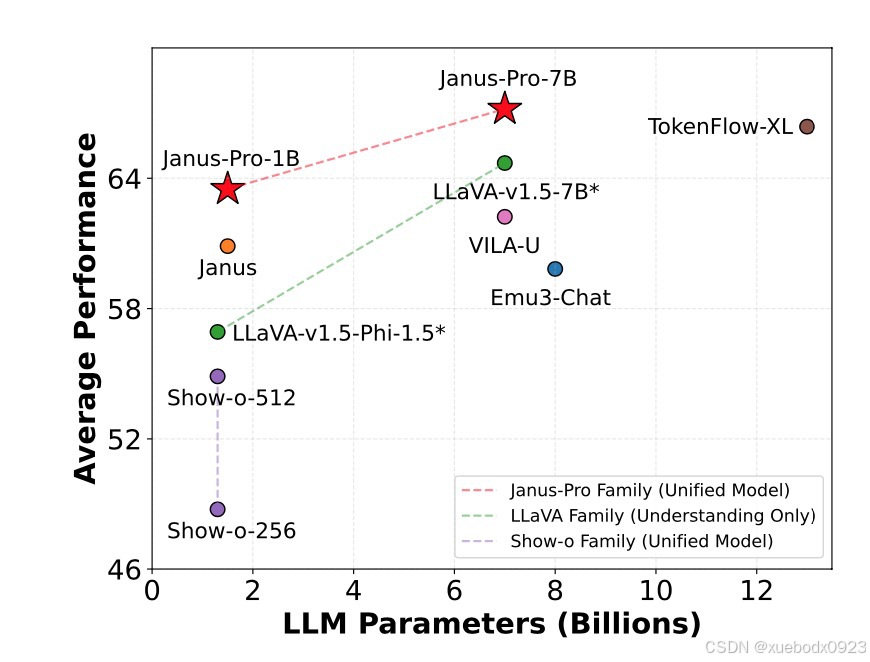
Janus-Pro是Janus的升级版本,Janus-Pro在多模态理解和文本到图像生成方面进行了显著改进。Janus-Pro系列包括两种模型规模:1B和7B。
Janus-Pro 与 Janus 在文本到图像生成之间的比较。Janus-Pro 在短提示词下能够提供更稳定的输出,提高了视觉质量,丰富了细节,并能够生成简单的文本。图像分辨率为384×384。

3.2 Janus-Pro在以下三个方面进行了关键改进
3.2.1 优化训练策略
第一阶段的更长训练:我们增加了第一阶段的训练步骤,以便在 ImageNet 数据集上进行充分的训练。
第二阶段的专注训练:在第二阶段,我们放弃了 ImageNet 数据,直接使用正常的文本到图像数据来训练模型,使其能够根据密集描述生成图像。这种重新设计的方法使得第二阶段能够更高效地利用文本到图像数据,从而提高了训练效率和整体性能。
在第三阶段的监督微调中,调整了不同类型数据的比例,将多模态数据、纯文本数据和文本到图像数据的比例调整为5:1:4。进一步平衡了多模态理解和生成任务的训练。
3.2.2 扩展训练数据
多模态理解:对于第二阶段预训练数据,我们参考了DeepSeekVL2,并增加了大约9000万个样本。这些包括图像字幕数据集(例如 YFCC),以及用于表格、图表和文档理解的数据(例如 Docmatix)。对于第三阶段监督微调数据,我们也纳入了 DeepSeek-VL2 的额外数据集,如 MEME 理解、中文对话数据以及旨在增强对话体验的数据集。这些新增内容显著扩展了模型的能力,丰富了其处理多样化任务的能力,同时改善了整体对话体验。
视觉生成:我们发现前一个版本的 Janus 所使用的现实世界数据质量欠佳且包含大量噪声,这常常导致文本到图像生成不稳定,产生审美质量较差的输出。在 Janus-Pro 中,我们纳入了大约 7200 万个合成审美数据样本,在统一预训练阶段使真实数据与合成数据的比例达到 1:1。实验表明,模型在合成数据上训练时收敛速度更快,生成的文本到图像输出不仅更加稳定,而且在审美质量上也有显著提升。
3.2.3 扩大模型规模
Janus-Pro将模型规模从1.5B 扩展到7B,显著提高了模型的表达能力和收敛速度。实验表明,更大的模型在多模态理解和视觉生成任务上都表现出了更好的性能。
3.3 架构配置以及超参数设置
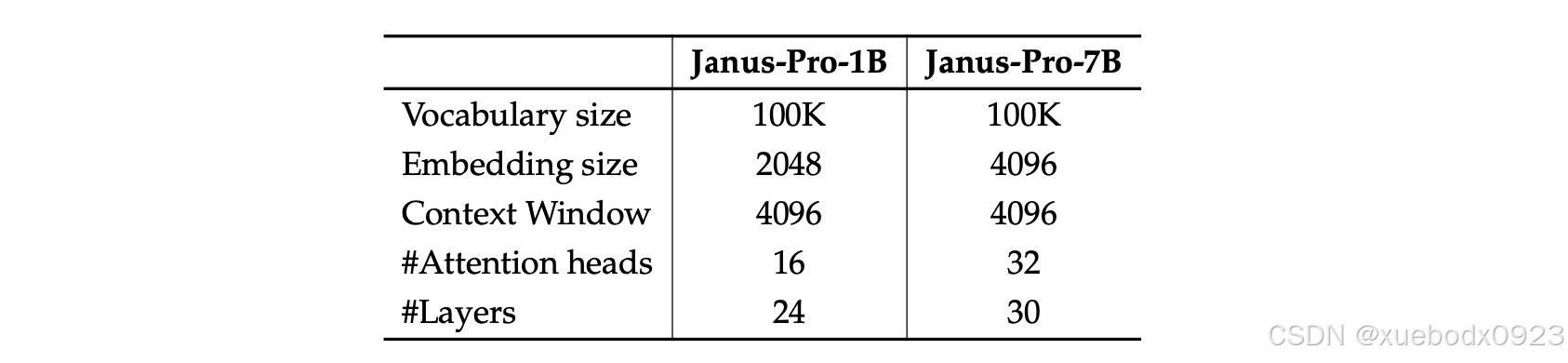
Janus-Pro 的架构配置。我们列出了架构的超参数。
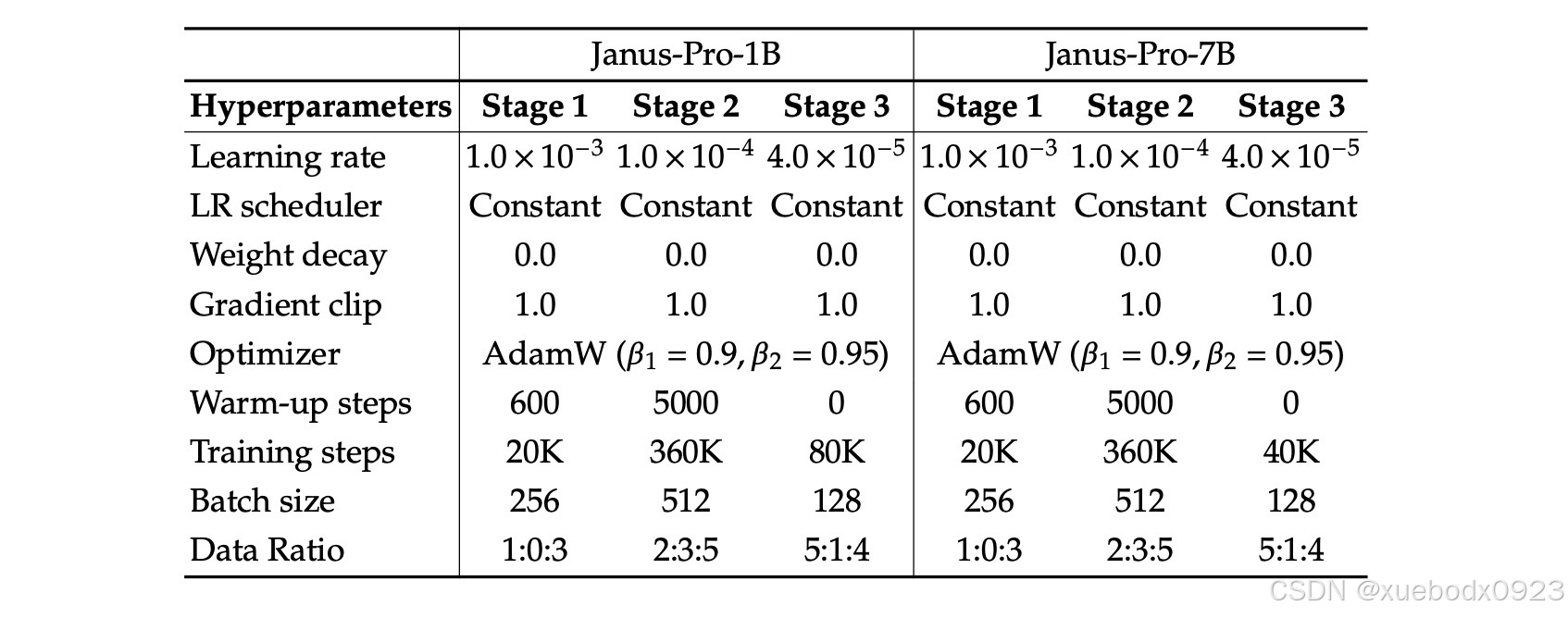
Janus-Pro训练的详细超参数。数据比例是指多模态理解数据、纯文本数据和视觉生成数据的比例。
3.3 和其他模型的对比
“Und.”和“Gen.”分别表示“理解”和“生成”。

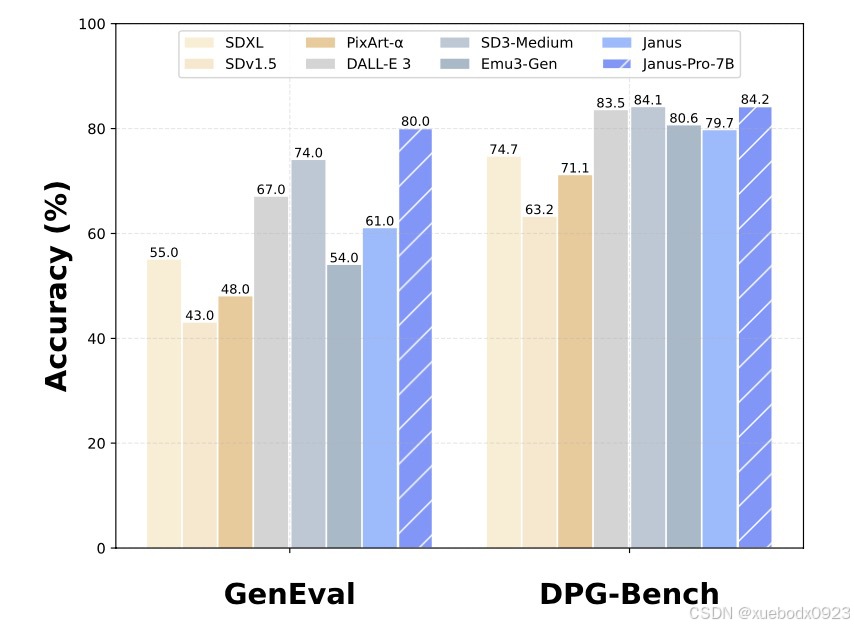
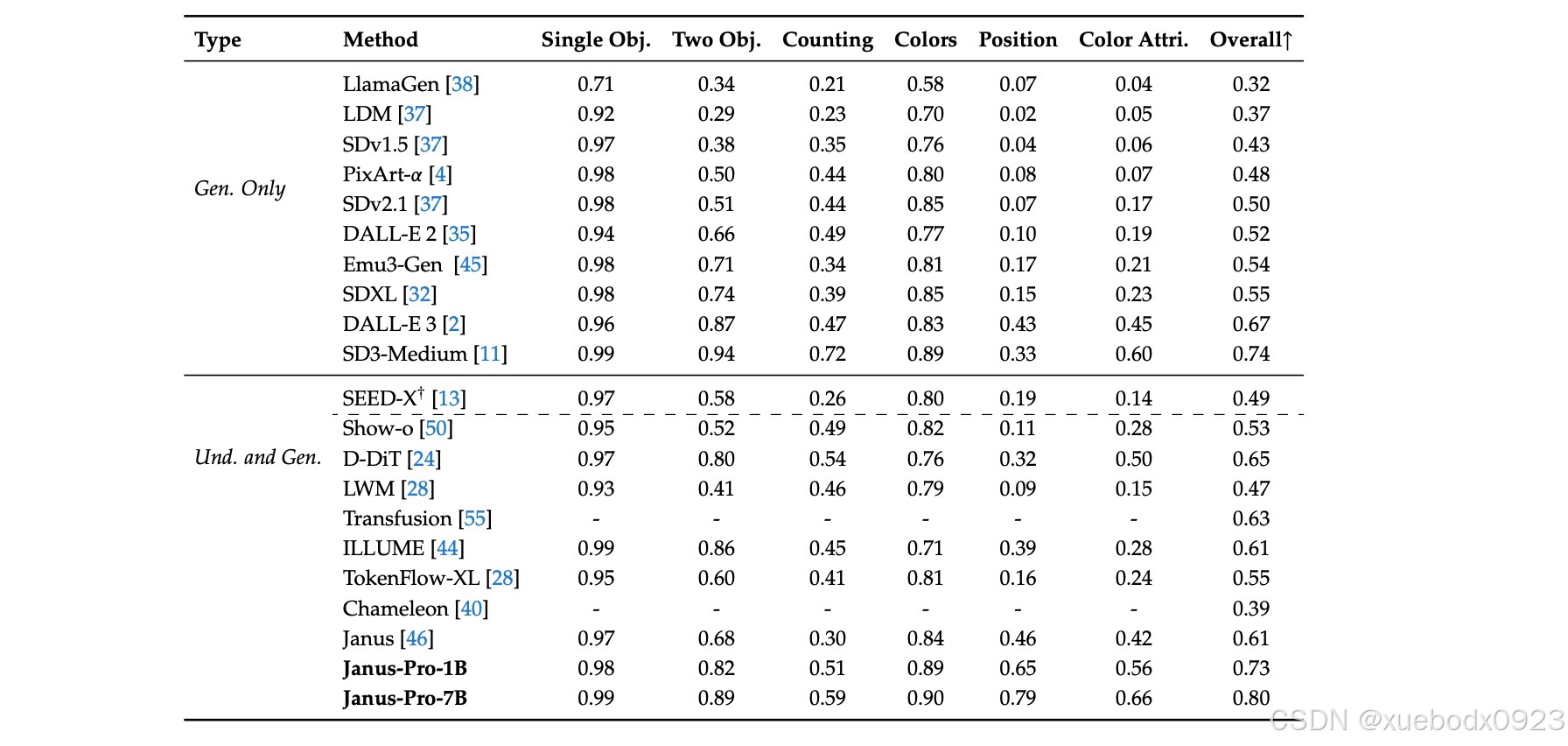
在 GenEval 基准测试中对文本到图像生成能力的评估:
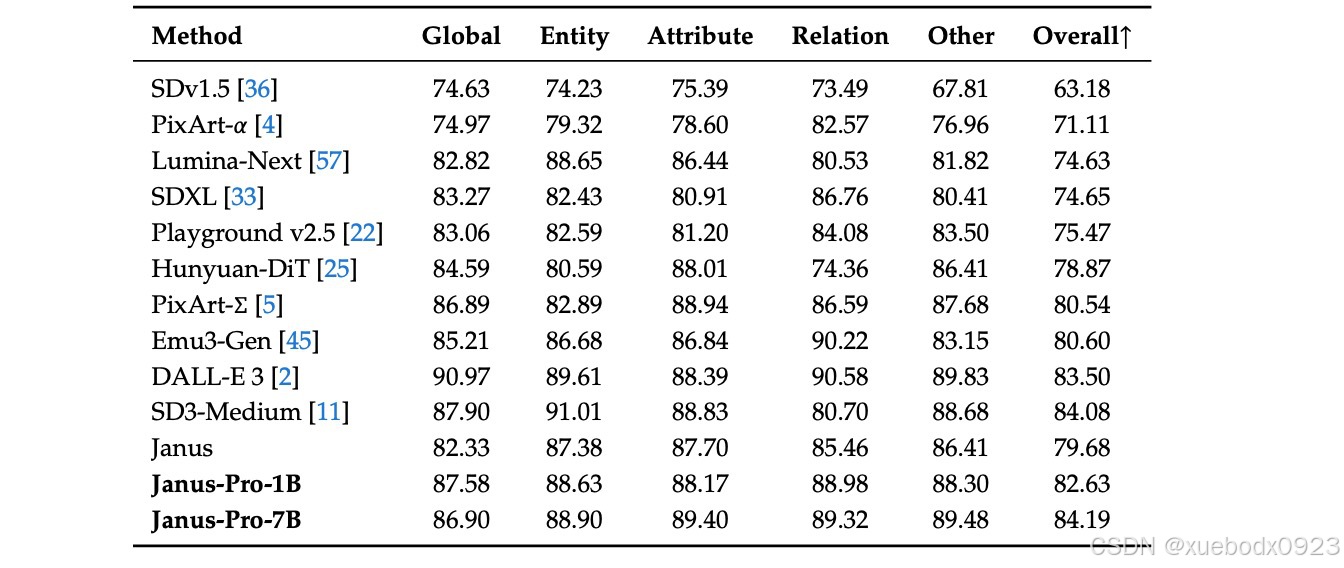
在DPG-Bench 上的性能。下表中的方法均为仅生成模型,除了Janus和Janus-Pro:
4. JanusFlow-1.3B
4.1 介绍
JanusFlow是一个强大的框架,能够在单一模型中统一图像理解与生成任务。JanusFlow将基于视觉编码器和LLM的理解框架与基于Rectified Flow的生成框架直接融合,实现了两者在单一LLM中的端到端训练。
其核心设计包括:(1)采用解耦的视觉编码器分别优化理解与生成能力;(2)利用理解端编码器对生成端特征进行表征对齐,显著提升RF的训练效率。基于1.3B规模的LLM,JanusFlow在视觉理解和生成任务上均超过此前同规模的统一多模态模型。
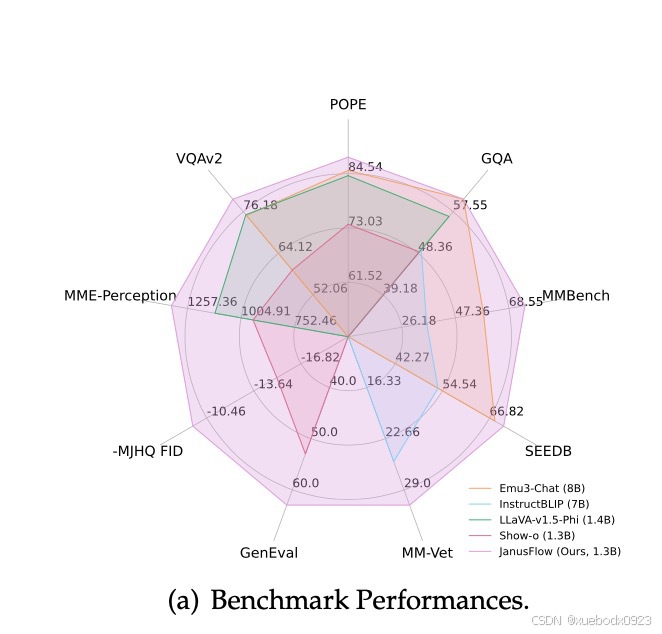
4.2 架构图及训练步骤
4.2.1 架构图
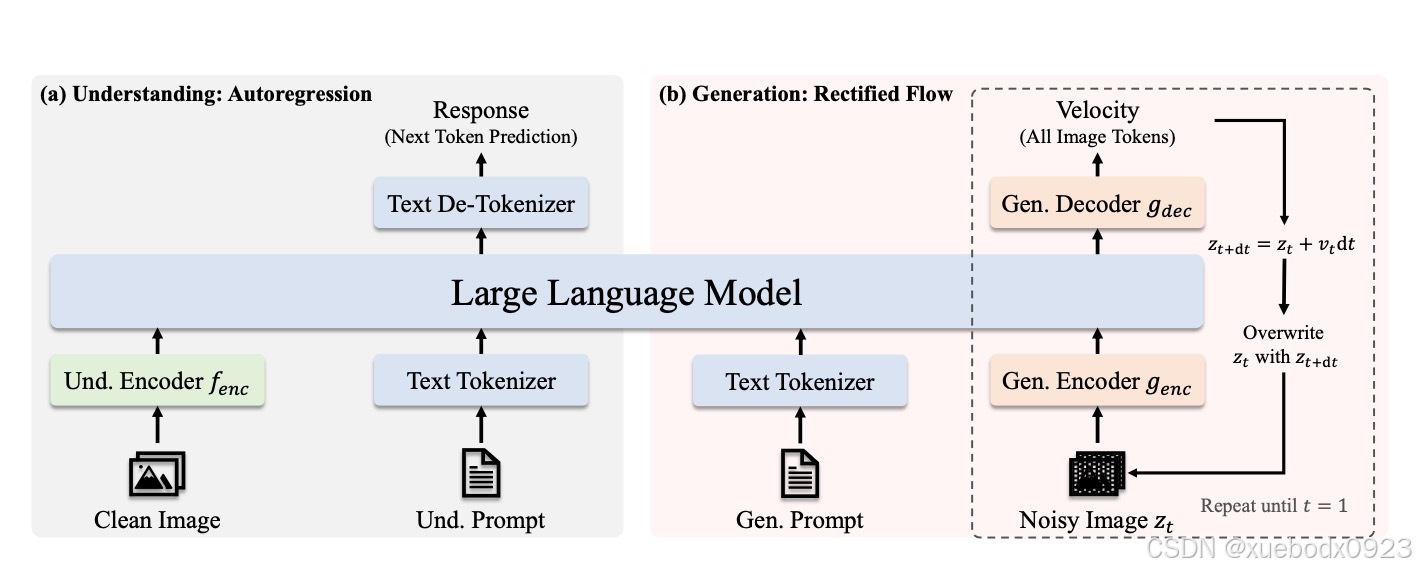
4.2.2 训练策略
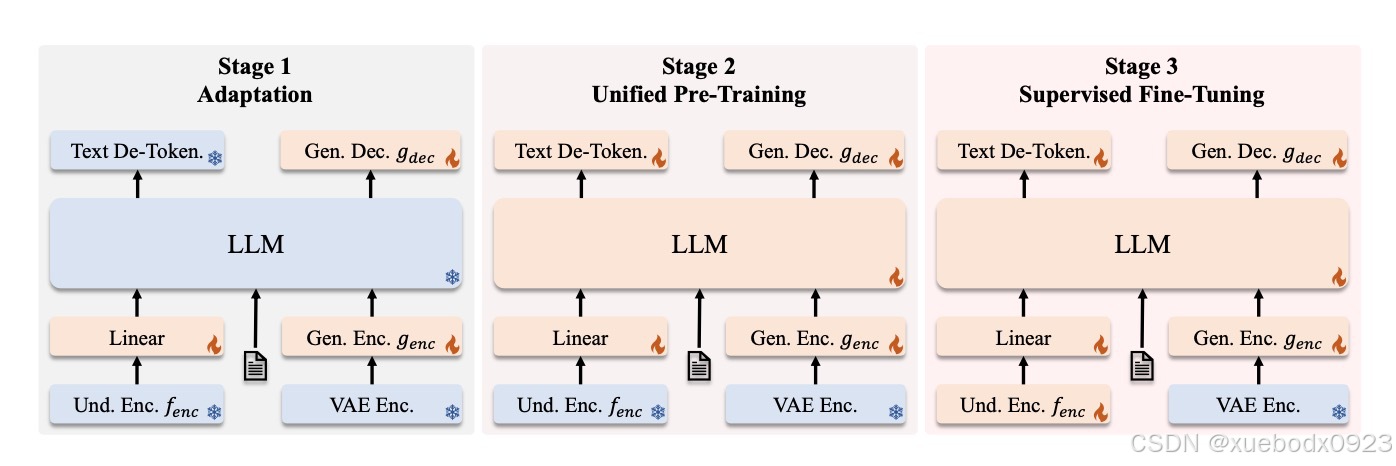
第一阶段:随机初始化组件的适配
在阅读这部分内容时,我了解到第一阶段的重点是训练随机初始化的组件,包括线性层、生成编码器和生成解码器。这一阶段旨在使这些新模块能够与预训练的大语言模型(LLM)和SigLIP编码器有效协作,主要起到为新引入组件初始化的作用。
第二阶段:统一预训练
适配阶段完成后,作者开始对整个模型进行训练,视觉编码器除外,这与之前的方法一致。在这一阶段,训练数据包括三种类型:多模态理解数据、图像生成数据和纯文本数据。训练初期会分配更多的多模态理解数据,以建立模型的理解能力。随后逐步增加图像生成数据的比例,以满足基于扩散模型的收敛需求。
第三阶段:监督微调(SFT)
在最后阶段,作者通过指令调优数据对预训练模型进行微调。这些数据包括对话、特定任务的交互以及高质量的文本条件图像生成示例。在此阶段,SigLIP编码器的参数也被解冻。这一微调过程让我看到,模型能够在多模态理解和图像生成任务中,有效地响应用户的指令。
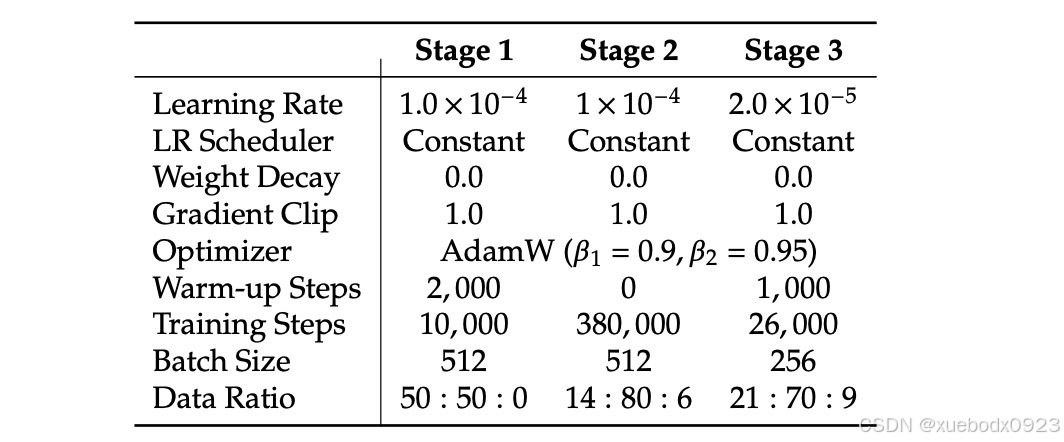
4.2.3 训练超参数设置
4.3 和其他模型的对比
“Und.”和“Gen.”分别表示“理解”和“生成”。
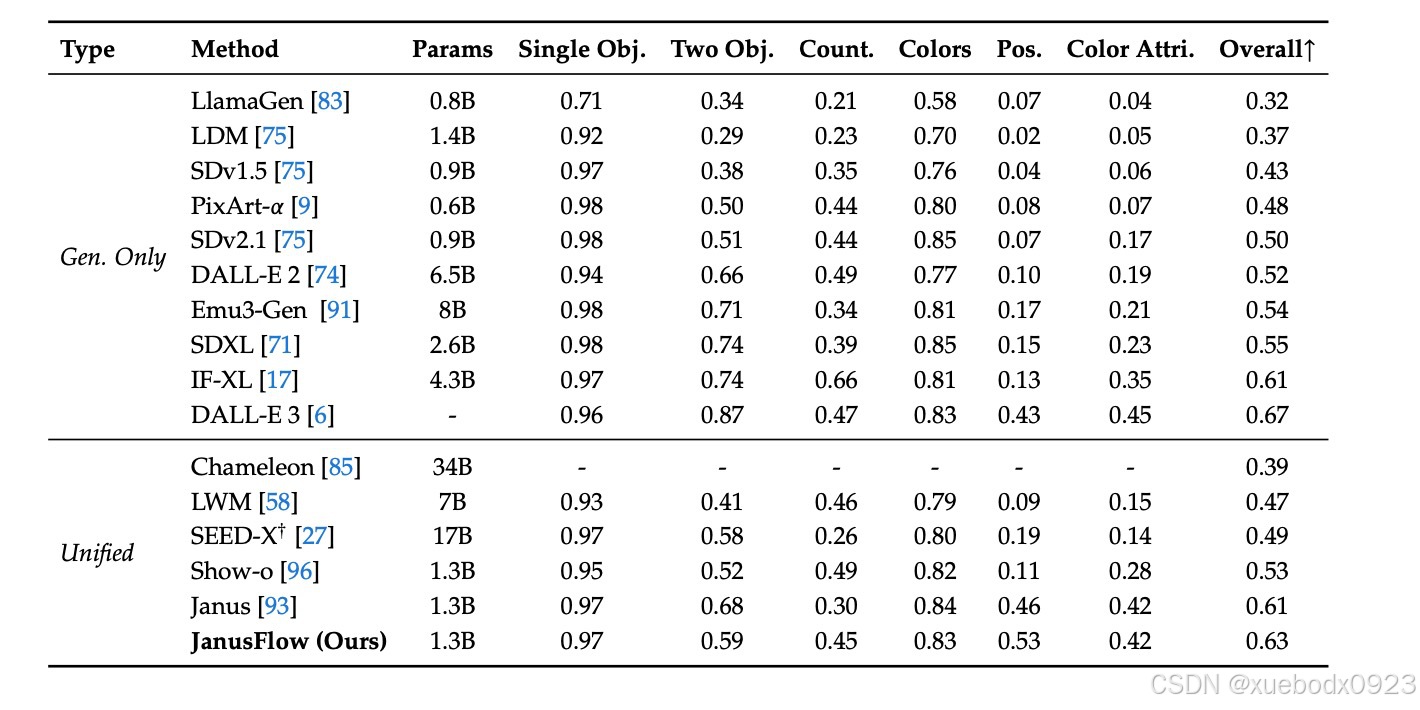
在 GenEval 基准测试中对文本到图像生成能力的评估:
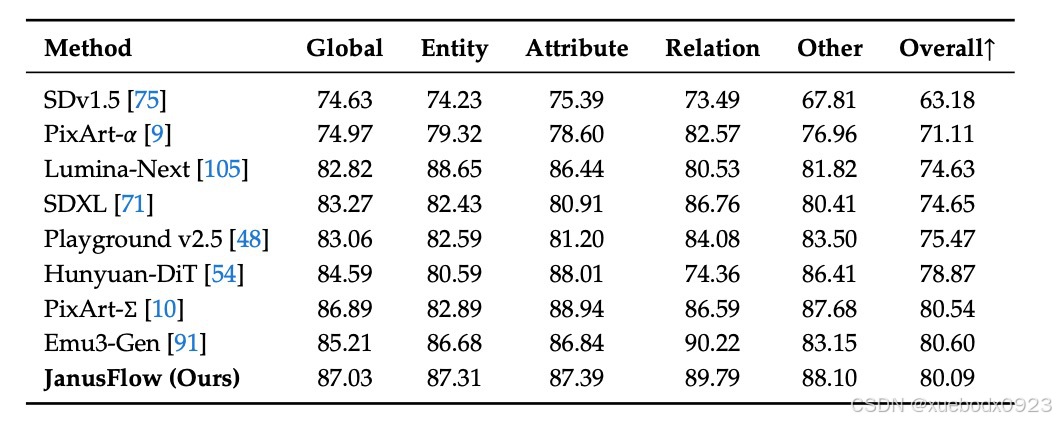
在DPG-Bench上的性能。下表中的方法均为仅生成模型,除了JanusFlow:
5. 本地部署
由于代码太长下面只写Gradio Demo,更详细的请参考:GitHub - deepseek-ai/Janus: Janus-Series: Unified Multimodal Understanding and Generation Models

5.1 程序下载
git clone git@github.com:deepseek-ai/Janus.git
5.2 Janus
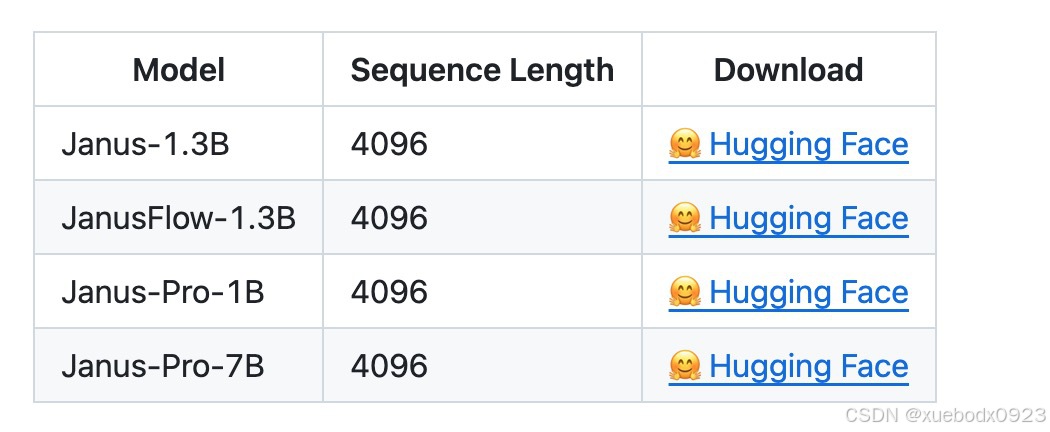
5.2.1 模型下载
https://huggingface.co/deepseek-ai/Janus-1.3B/tree/main
5.2.2 安装
pip install -e .
5.2.3 本地Gradio Demo
pip install -e .[gradio]
python demo/app.py
5.3 Janus-Pro
5.3.1 模型下载
https://huggingface.co/deepseek-ai/Janus-Pro-1B/tree/main
https://huggingface.co/deepseek-ai/Janus-Pro-7B/tree/main
5.3.2 安装
pip install -e .
5.3.3 本地Gradio Demo
pip install -e .[gradio]
python demo/app_januspro.py
5.4 Janus-Flow
5.4.1 模型下载
https://huggingface.co/deepseek-ai/JanusFlow-1.3B/tree/main
5.4.2 安装
pip install -e .
pip install diffusers[torch]
5.4.3 本地Gradio Demo
pip install -e .[gradio]
python demo/app_janusflow.py

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)