DeepSeek-Coder-V2解读
DeepSeek-Coder-V2是一种开源的混合专家(MoE)代码语言模型,在特定代码任务中实现了与GPT4 Turbo相当的性能。发布了参数量分别为16B和236B的两个版本。DeepSeek-Coder-V2是从DeepSeek-V2进一步预训练来的。通过这种持续的预训练,DeepSeek-Coder-V2大大提高了DeepSeek-V2的编码和数学推理能力。DeepSeek-Coder-V
1. 摘要
DeepSeek-Coder-V2是一种开源的混合专家(MoE)代码语言模型,在特定代码任务中实现了与GPT4 Turbo相当的性能。发布了参数量分别为16B和236B的两个版本。DeepSeek-Coder-V2是从DeepSeek-V2进一步预训练来的。通过这种持续的预训练,DeepSeek-Coder-V2大大提高了DeepSeek-V2的编码和数学推理能力。DeepSeek-Coder-V2将其对编程语言的支持从86扩展到338,同时将上下文长度从16K扩展到128K。在标准基准测试评估中,DeepSeek-Coder-V2在编码和数学基准测试方面比GPT4 Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型具有更优的性能。
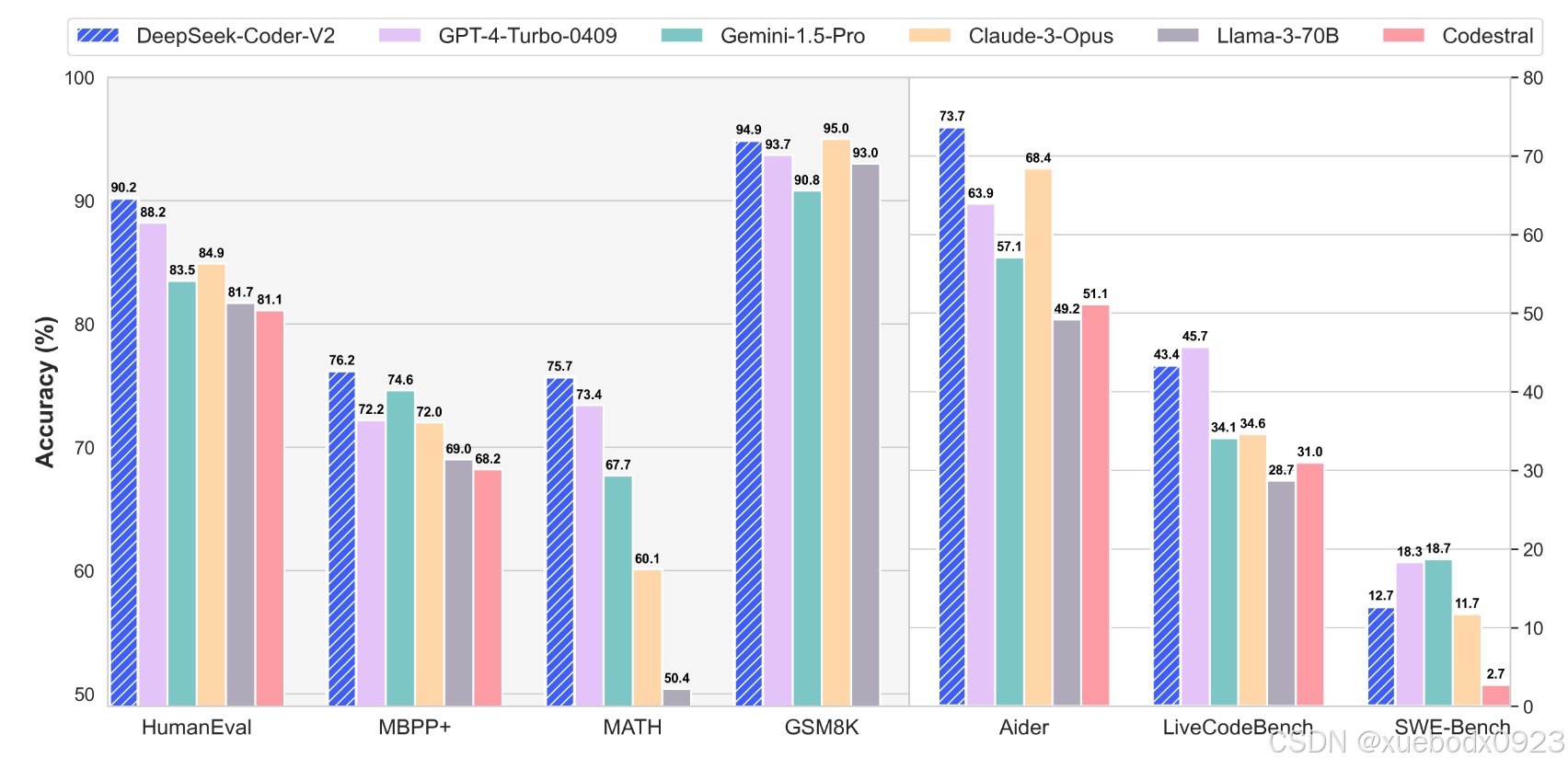
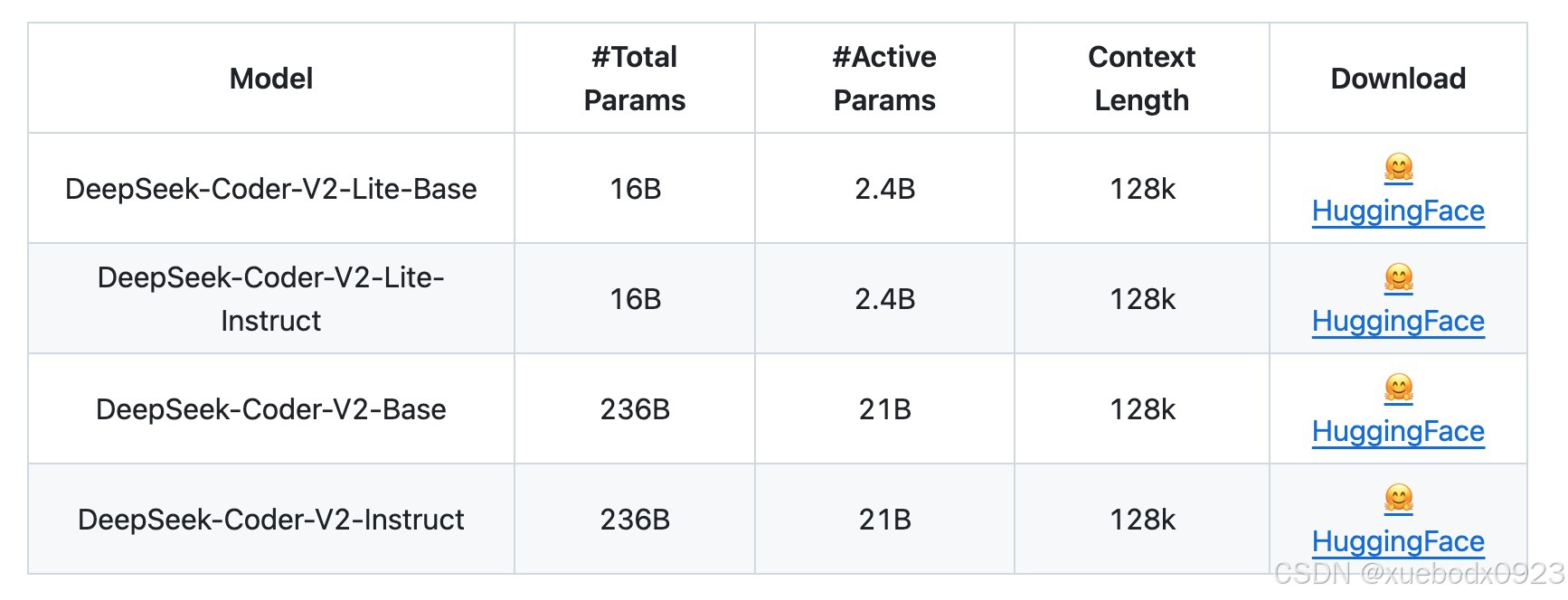
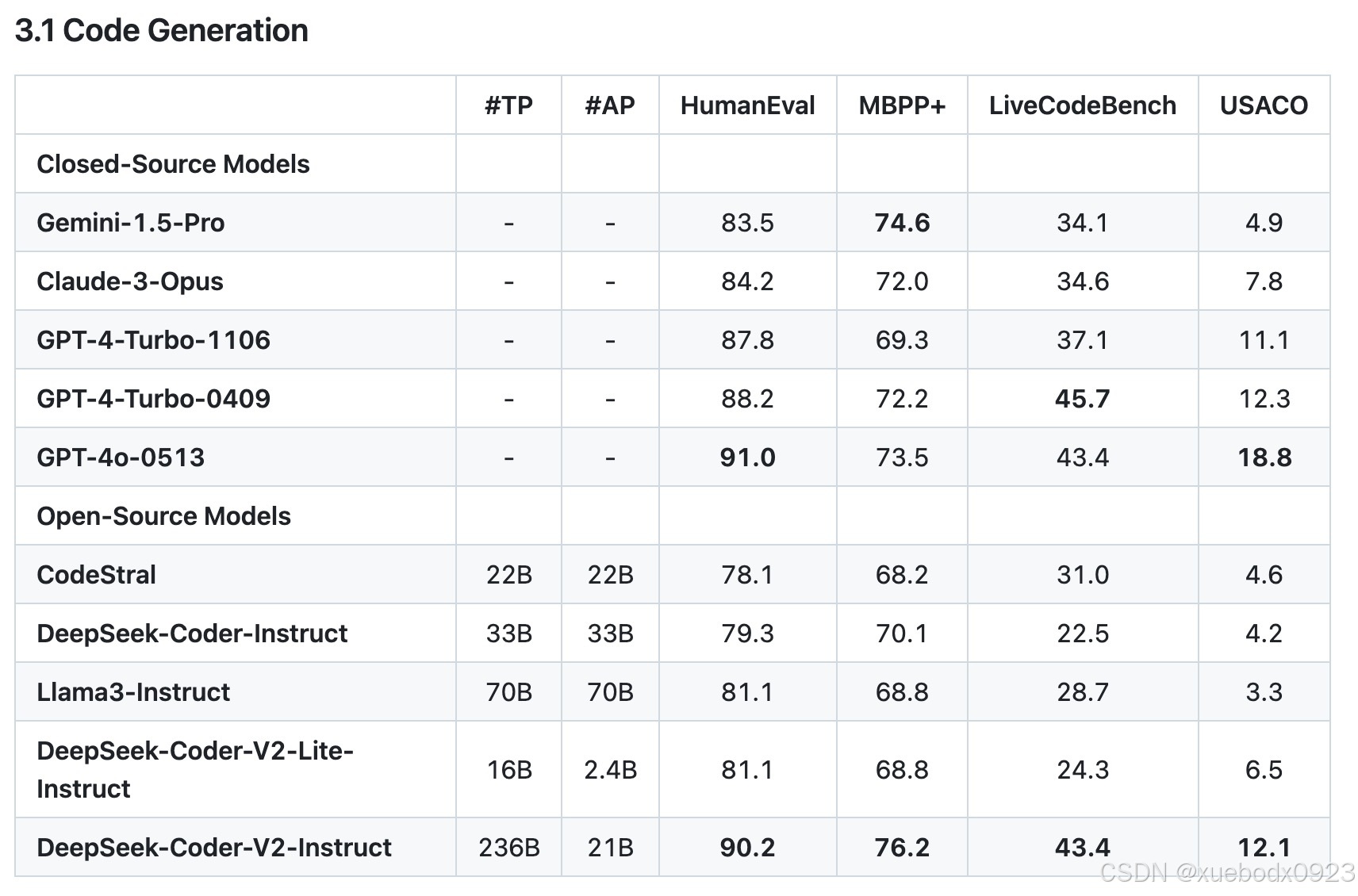
2. 训练
2.1 预训练
2.1.1 训练数据
DeepSeek-Coder-V2的预训练数据主要由60%的源代码、10%的数学语料库和30%的自然语言语料库组成。源代码收集了2023年11月之前在GitHub上创建的公共仓库,对相似,低质量和重复的源代码进行删除,获得了821B代码,涵盖338种编程语言,以及185B与代码相关的文本,如markdown和问题。数学语料库是从网页中收集了70B与代码相关的token和221B与数学相关的token。自然语言语料库直接从DeepSeek-V2的训练数据集中采样。
2.1.2 训练策略
DeepSeek-Coder-V2 16B使用了两种训练目标:Next-Token-Prediction和Fill-In-Middle(FIM补全)。对于DeepSeek-Coder-V2 236B,我们仅使用Next-Token-Prediction目标。FIM训练策略将内容重建结构化为序列:前缀,后缀和中间。
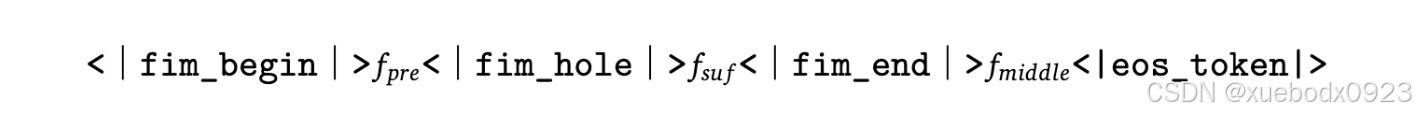
使用AdamW优化器,配置为𝛽1 = 0.9, 𝛽2 = 0.95,并使用0.1的权重衰减。批量大小和学习率根据DeepSeek-V2的规格进行调整。对于学习率调度,我们采用余弦衰减策略,从2000个预热步骤开始,逐渐将学习率降低到初始值的10%。
DeepSeek-Coder-V2和DeepSeek-Coder-V2-Lite都使用相同的方法进行训练。为了保持DeepSeek-Coder-V2在自然语言理解方面的稳健能力,我们从DeepSeek-V2的中间检查点继续预训练过程。最初的中间检查点是在4.2T个token上训练的。因此,在预训练阶段,DeepSeek-Coder-V2总共接触了10.2T个高质量token。
预训练后的模型名称为DeepSeek-Coder-V2-Lite-Base和DeepSeek-Coder-V2-Base。
2.2 对齐
2.2.1 监督微调
DeepSeek构建了一个包含代码和数学数据的指令训练数据集。首先收集了20k与代码相关的指令数据和30k与数学相关的数据,这些数据来自DeepSeek-Coder和DeepSeek-Math。为了保持通用能力,还从DeepSeek-V2的指令数据中采样了一些数据。最后,使用了总共300M个token的指令数据集。在训练中,使用了余弦相似度,预热步骤为100,初始学习率为5e−6。我们还使用了1M个token的批量大小,总共1B个token。
2.2.2 强化学习
prompt:收集了40k的关于代码和数学相关训练数据。
奖励建模:在数学偏好数据方面,使用真实标签作为奖励。在代码偏好数据方面,使用代码编译器提供的0-1反馈作为奖励。最后使用编译器提供的数据训练一个奖励模型,并在RL训练中使用奖励模型来提供信号。
强化学习算法:采用Group Relative Policy Optimization (GRPO)算法作为RL算法。
对齐后的模型名称为DeepSeek-Coder-V2-Lite-Instruct和DeepSeek-Coder-V2-Instruct。
3. 本地部署模型
使用BF16精度在本地部署DeepSeek-Coder-V2-Instruct 236B的模型进行推理,需要80GB*8 GPUs。
3.1 模型下载
https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Instruct/tree/main
3.2 使用 Huggingface 的 Transformers 进行推理
3.2.1 Code Completion
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
3.2.2 Code Insertion
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
3.2.3 Chat Completion
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|end▁of▁sentence|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
3.3 使用 vLLM 进行推理(推荐)
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 1
model_name = "deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "write a quick sort algorithm in python."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)