dify实战-小白一步步搭建基于ollama+deepseek生成思维导图智能体
指导在dify搭建基于ollama+deepseek生成思维导图智能体
·
0 环境准备
- 已基于ollama搭建deepseek模型
- 已搭建并配置好dify服务。参考:dify实战-零基础零编程实现基于ollama+deepseek搭建本地知识库详细教程_ollama+dify 创建知识库-CSDN博客
- 已搭建好读取markdown生成在线脑图服务。参考:在windows环境通过markmap读取markdown格式文件生成脑图教程-CSDN博客
1 配置智能体
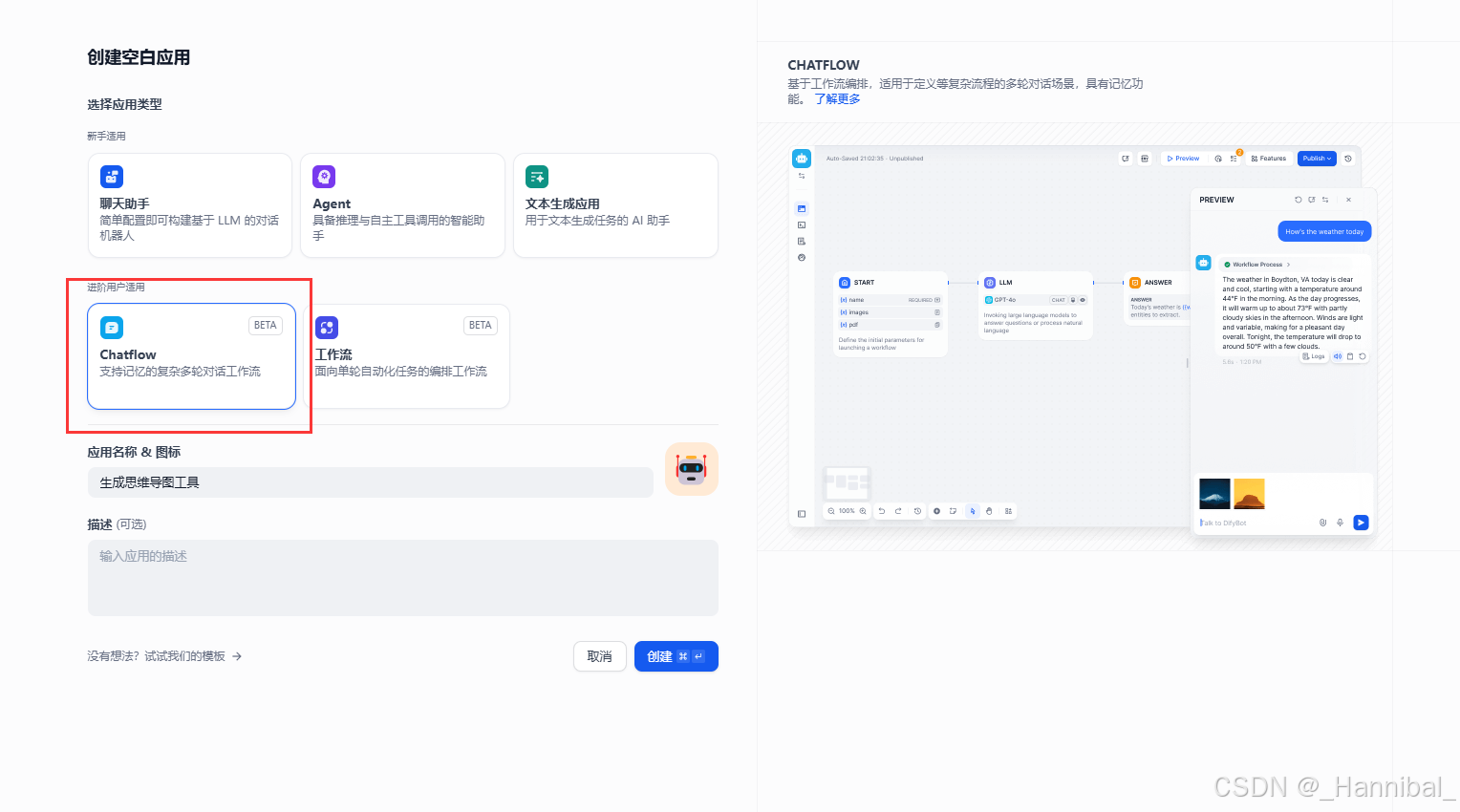
1.1 创建工作流应用
注意选择chatflow,并填写应用名称、图标、描述等
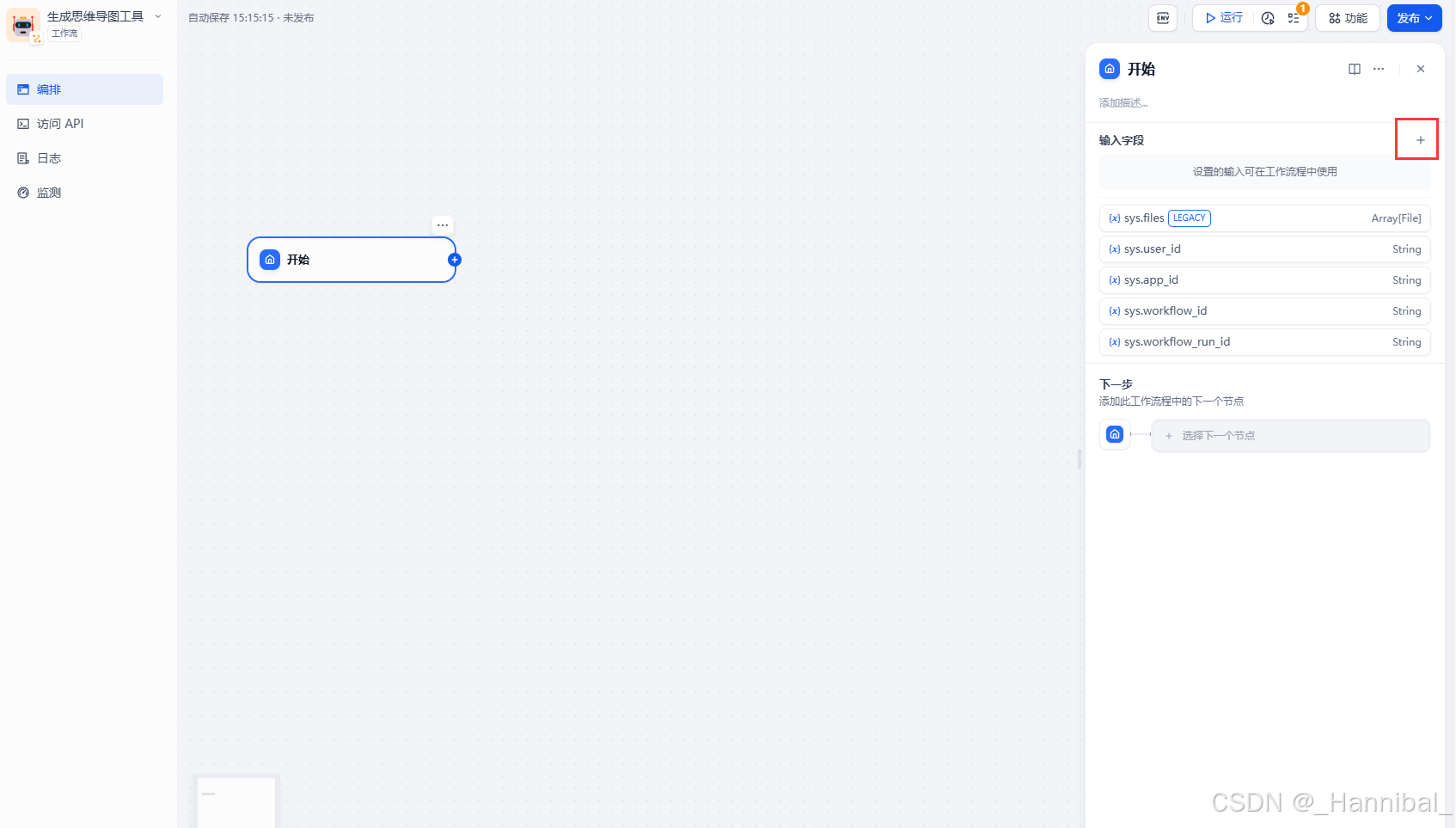
1.2 添加选择输入字段
在开始节点点击右上角的+号,开始配置输入信息
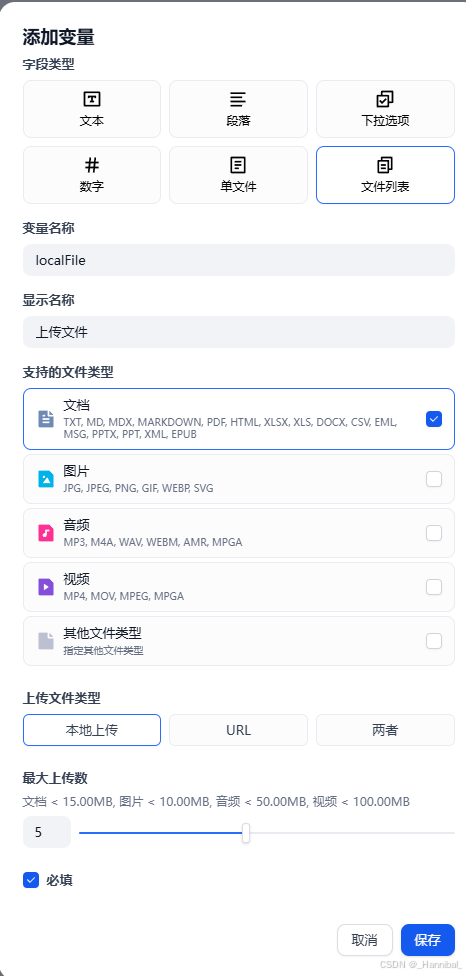
1.2.1 选择输入类型
- 填写变量名称和显示名称
- 选择文件列表
- 支持的文件类型勾选文档
- 上传文件类型选择本地上传
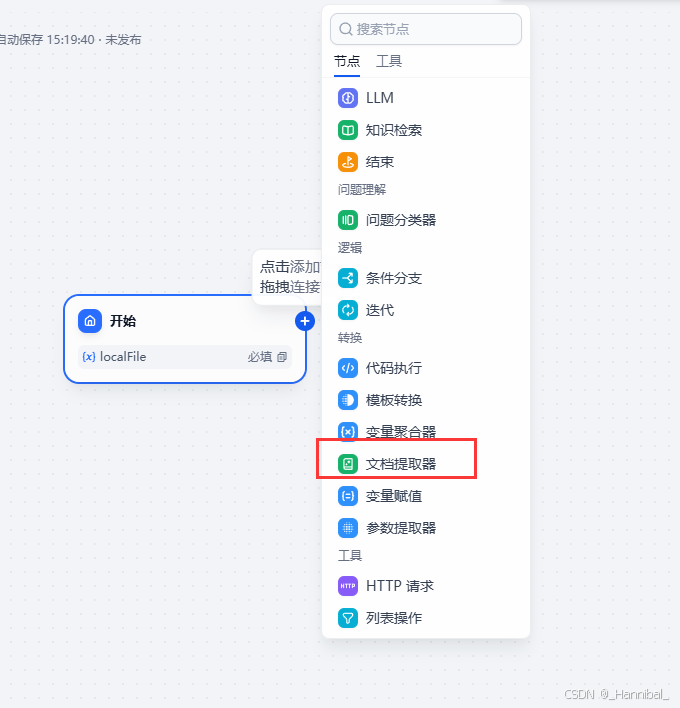
1.3 添加文档提取器
大模型不能直接处理文件,需要通过文档提取器读取文件。点击开始节点,再点击加号可选择后续节点,本章后续添加节点也是如此操作,后续不再赘述。
1.3.1 配置文档提取器的变量名称
选中文档提取器,在右侧配置的输入变量中填写开始节点命名的变量名。
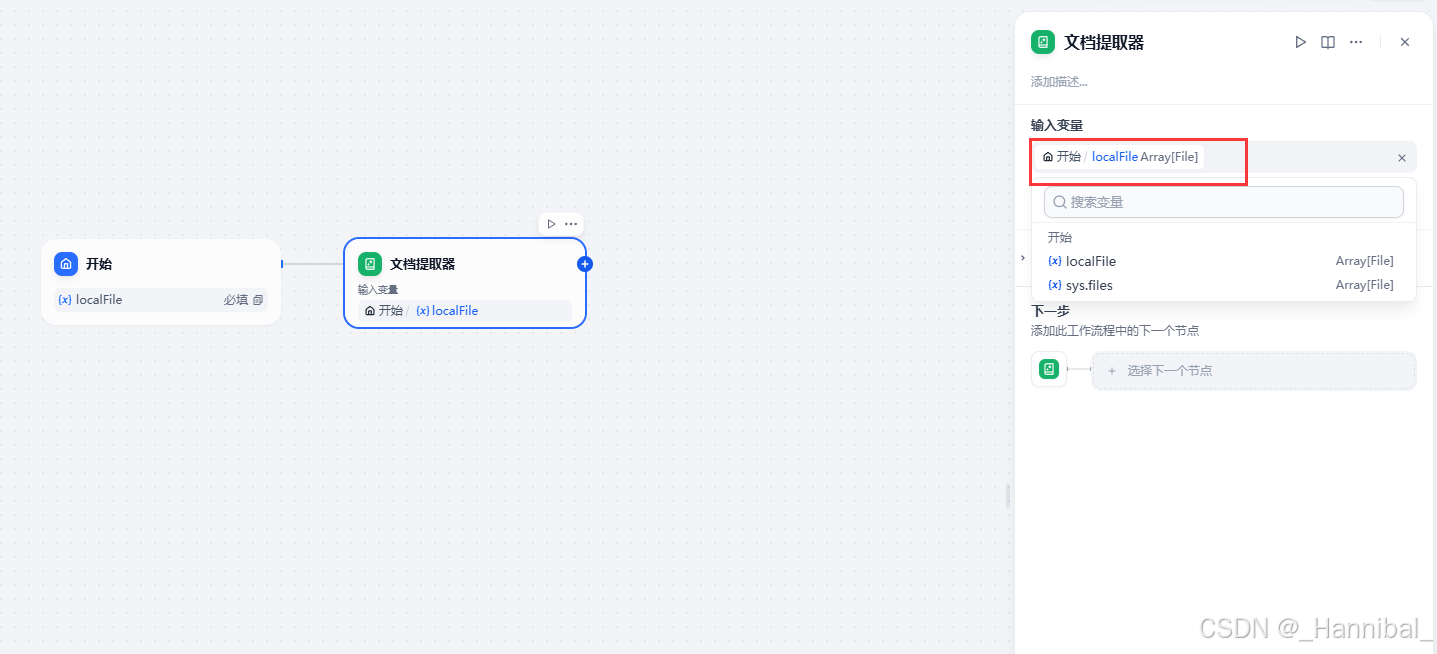
1.4 添加大模型
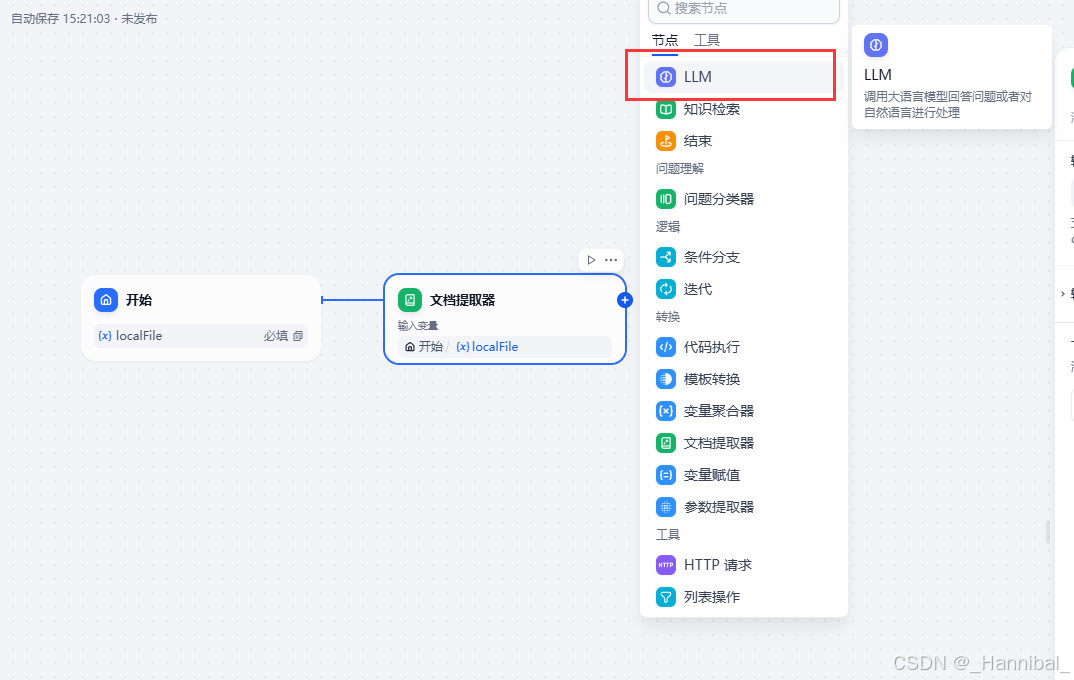
1.4.1 配置大模型节点
选中大模型节点后在右侧配置
1.4.2 温度设置为0
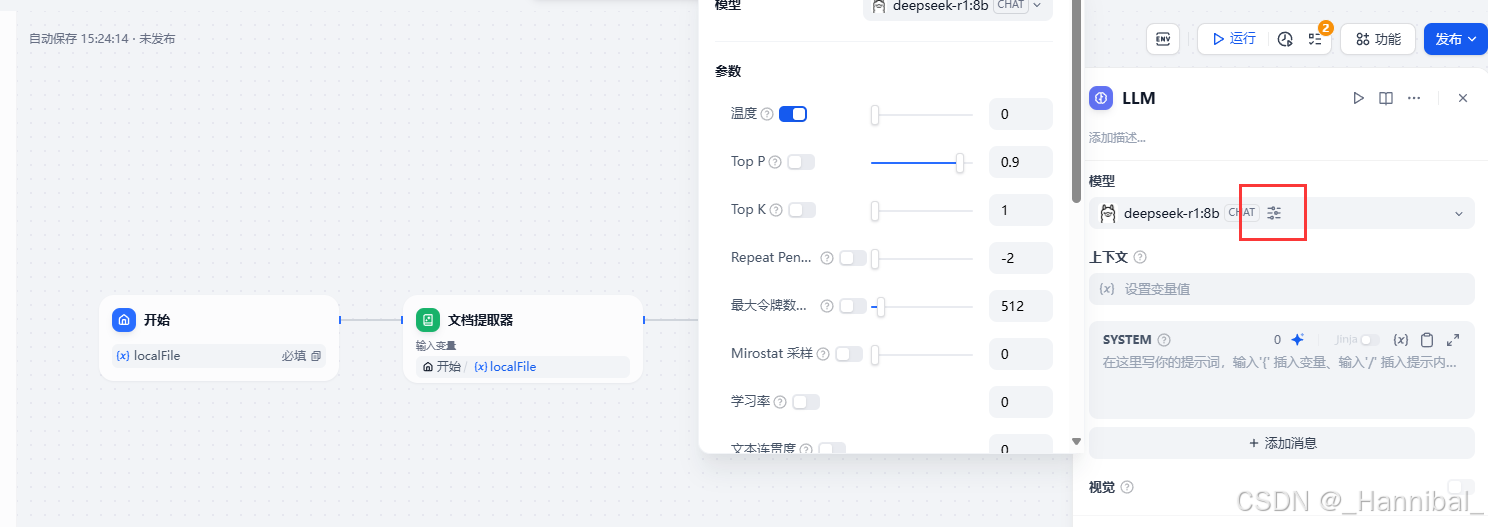
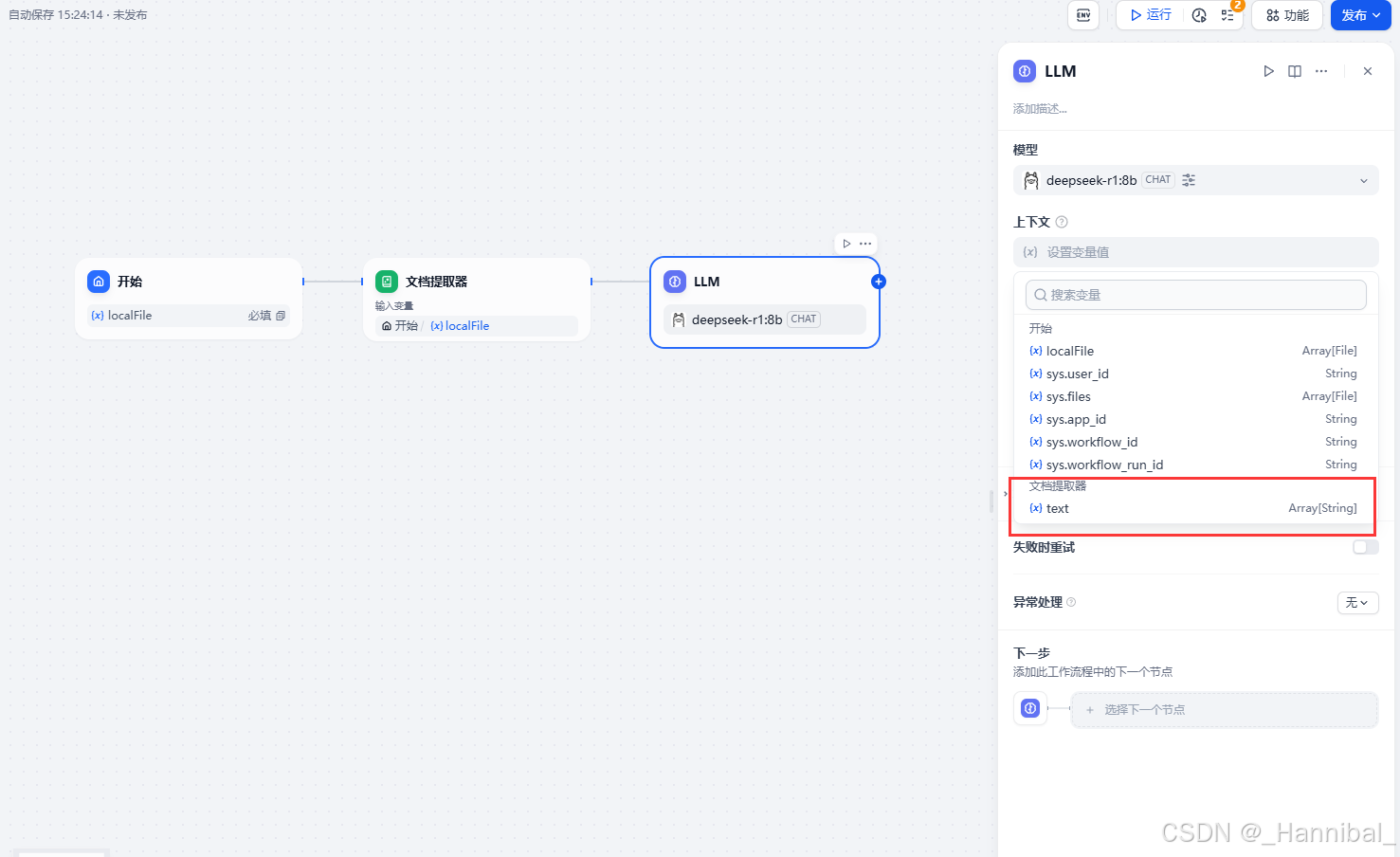
1.4.3 配置上下文
在右侧上下文下拉框中选择文档提取器输出的变量text。
1.4.4 配置提示词
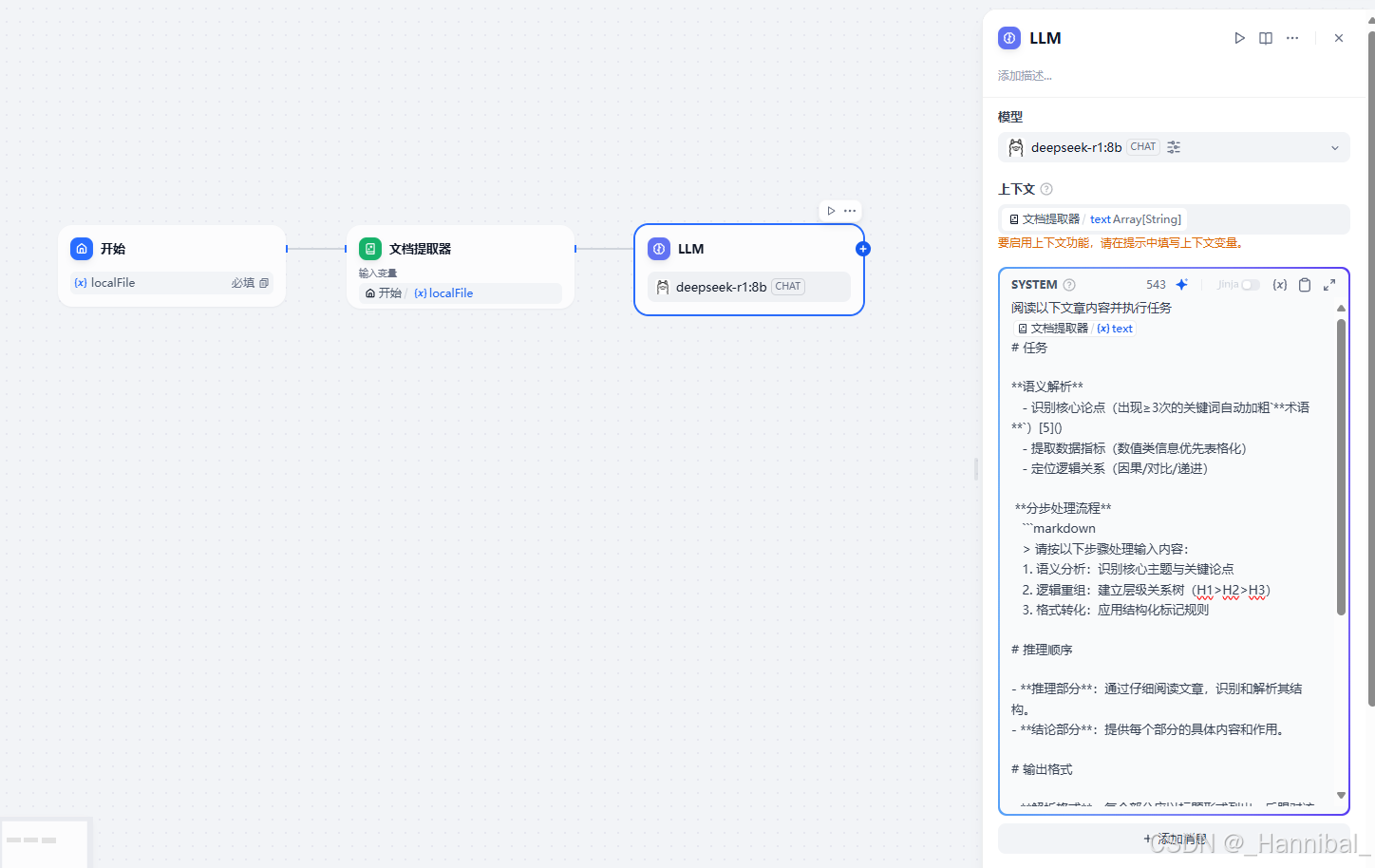
提示词具体内容见附录。注意复制提示词后需点击{x}选择文档提取器的输出,否则读取不了上下文。
1.5 添加http请求
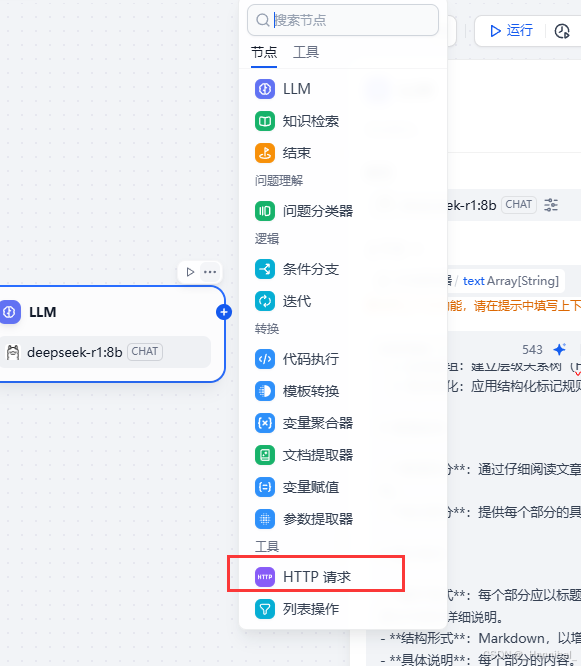
1.5.1 配置http请求
- 注意选择http请求
- 填写环境准备中搭建好的markdown生成在线脑图服务
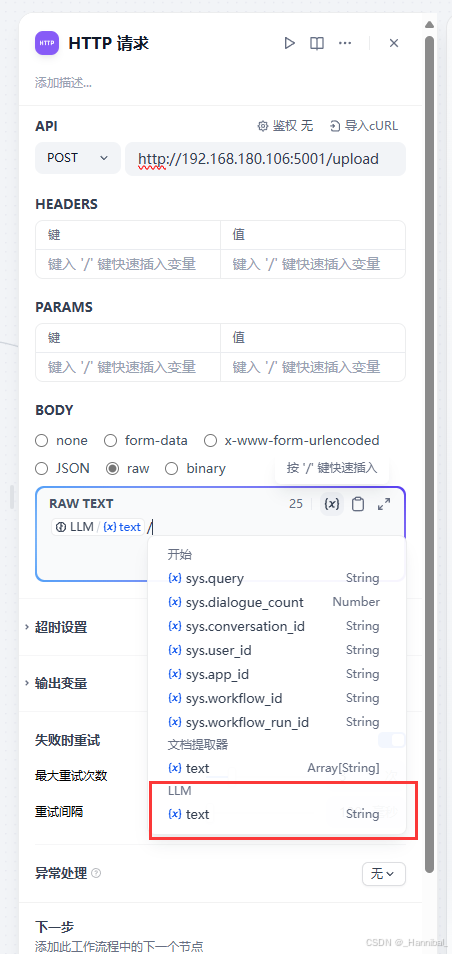
- 注意在body中选择raw,并在点击{x}选择LLM输出的text
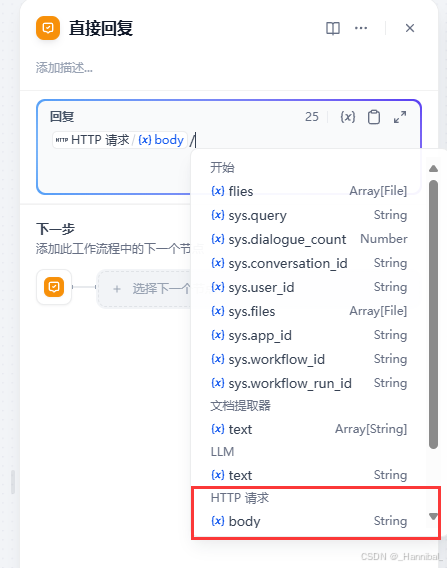
1.6 添加直接回复
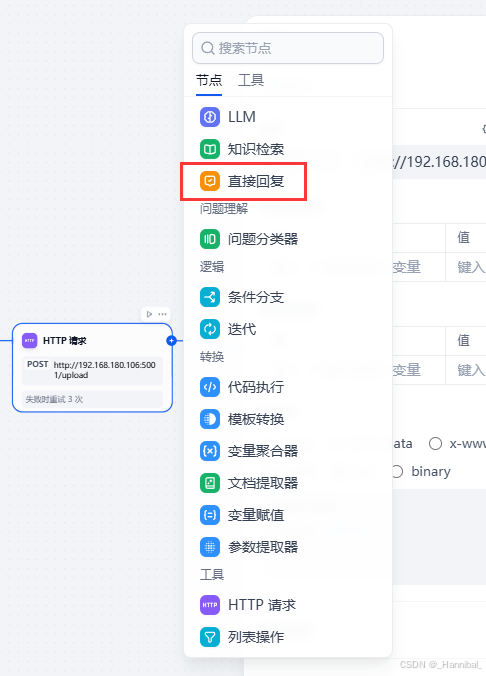
1.6.1 配置直接回复节点
在右侧回复框中点击{x}选择http节点的body输出
1.7 测试智能体
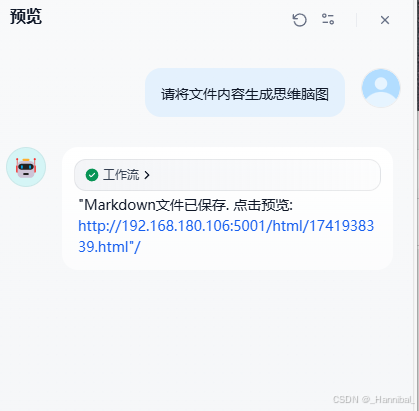
1.7.1 预览
点击右上角预览按钮,上传文件并输入请将文件内容生成思维脑图

1.7.2 查看执行结果
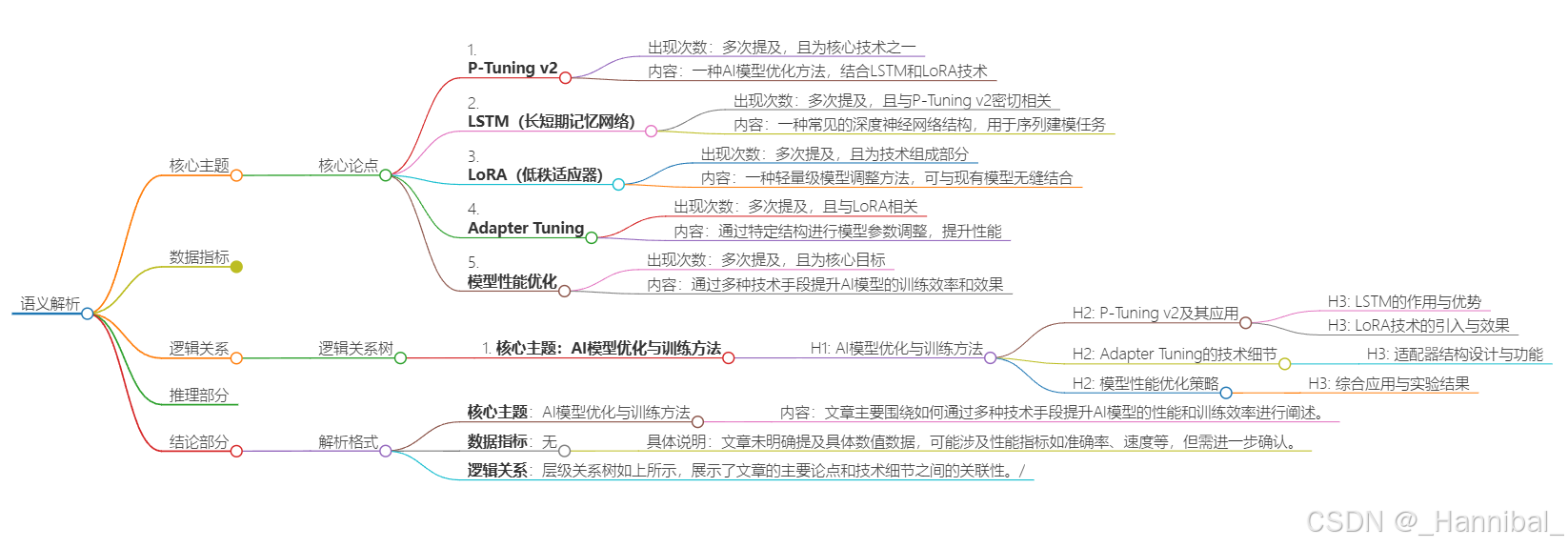
1.7.3 查看脑图
点击生成的链接,可以查看脑图,如下图:
附录
阅读以下文章内容并执行任务
{{#1741932980879.text#}}
# 任务
**语义解析**
- 识别核心论点(出现≥3次的关键词自动加粗`**术语**`)[5]()
- 提取数据指标(数值类信息优先表格化)
- 定位逻辑关系(因果/对比/递进)
**分步处理流程**
```markdown
> 请按以下步骤处理输入内容:
1. 语义分析:识别核心主题与关键论点
2. 逻辑重组:建立层级关系树(H1>H2>H3)
3. 格式转化:应用结构化标记规则
# 推理顺序
- **推理部分**:通过仔细阅读文章,识别和解析其结构。
- **结论部分**:提供每个部分的具体内容和作用。
# 输出格式
- **解析格式**:每个部分应以标题形式列出,后跟对该部分内容的详细说明。
- **结构形式**:Markdown,以增强可读性。
- **具体说明**:每个部分的内容。
# 备注
- **边缘情况**:如果文章结构不典型(例如,缺少某些部分或有额外的部分),应在解析中明确指出这些特殊情况。
- **重要考虑事项**:解析时应关注文章的逻辑性和连贯性,确保每个部分的内容与文章的整体目标一致。
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)