《DeepSeek-VL: Towards Real-World Vision-Language Understanding》阅读解析
解析DeepSeek VL文章
DeepSeek-VL: Towards Real-World Vision-Language Understanding原文链接:
https://arxiv.org/pdf/2403.05525
主要贡献
高分辨率视觉编码:1024 x 1024分辨率
三阶段训练方式
模态热身策略
主要架构
主要架构分为三部分:
A hybrid vision encoder, a vision adaptor, and a language model.
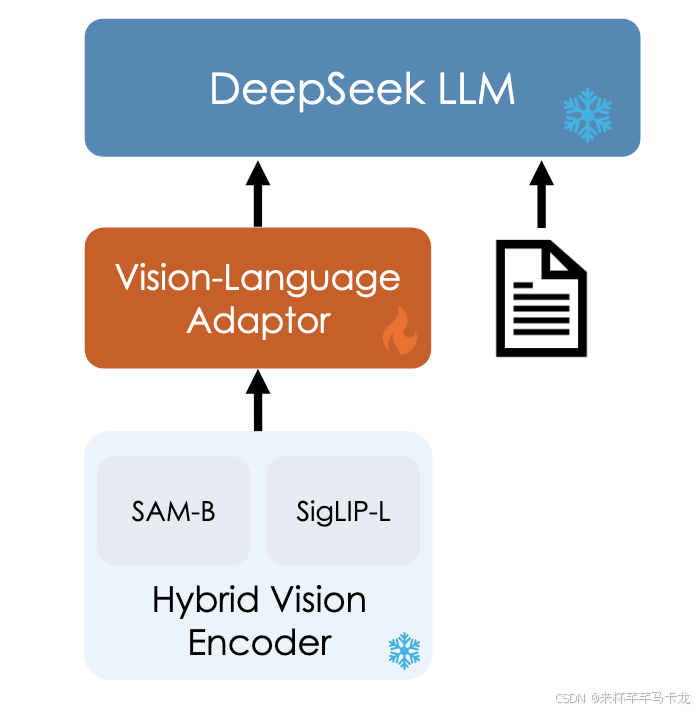
hybrid vision encoder
采用SigLIP作为视觉编码器来提取视觉输入的高级特征表示。然而,一个单独的SigLIP编码器很难解决现实世界的问题,受模糊的编码影响,导致视觉上不同的图像被编码为相似,CLIP家族受其相对较低的分辨率输入的限制(例如224 x 224,336 x 336,384 x 384,512 x 512),这阻碍了他们处理任务的能力,该任务需要更详细的低级别功能,例如密集的OCR和视觉接地任务。
为了处理高分辨率的低级特征,利用SAM-B处理1024 x 1024的高分辨率图像输入,还保留了具有低分辨率384 x 384图像输入的Siglip-L视觉编码器,因此,混合视觉编码器结合了SAM-B和Siglip-L编码器,有效地编码了高分辨率1024 x 1024图像,同时保留语义和详细信息。
Vision-Language Adaptor
使用两层混合MLP来桥接视觉编码器和LLM,最初,不同的单层MLP用于分别处理高分辨率特征和低分辨率功能。随后,这些特征沿其尺寸连接,然后通过另一层MLP转换为LLM的输入空间。
Language Model
语言模型建立在DeepSeek LLM的基础之上,采用Pre-Norm结构(即在每一层的输入之前进行归一化操作,而不是在输出之后进行归一化(Post-Norm)。Pre-Norm 结构在近年来被广泛应用于Transformer模型及其变体中,因为它能够有效缓解梯度消失问题,并提升训练的稳定性),使用RMSNorm作为归一化函数,并且使用SwiGLU作为前馈网络的激活函数,采用旋转嵌入作为位置编码,使用与DeepSeek-LLM相同的tokenizer。
RMSNorm


SwiGLU

Sigmoid函数公式如下:




训练策略
训练过程分为三个阶段,
Stage 1: Training Vision-Language Adaptor
Stage 2: Joint Vision-Language pretraining
Stage 3: Supervised Fine-tuning
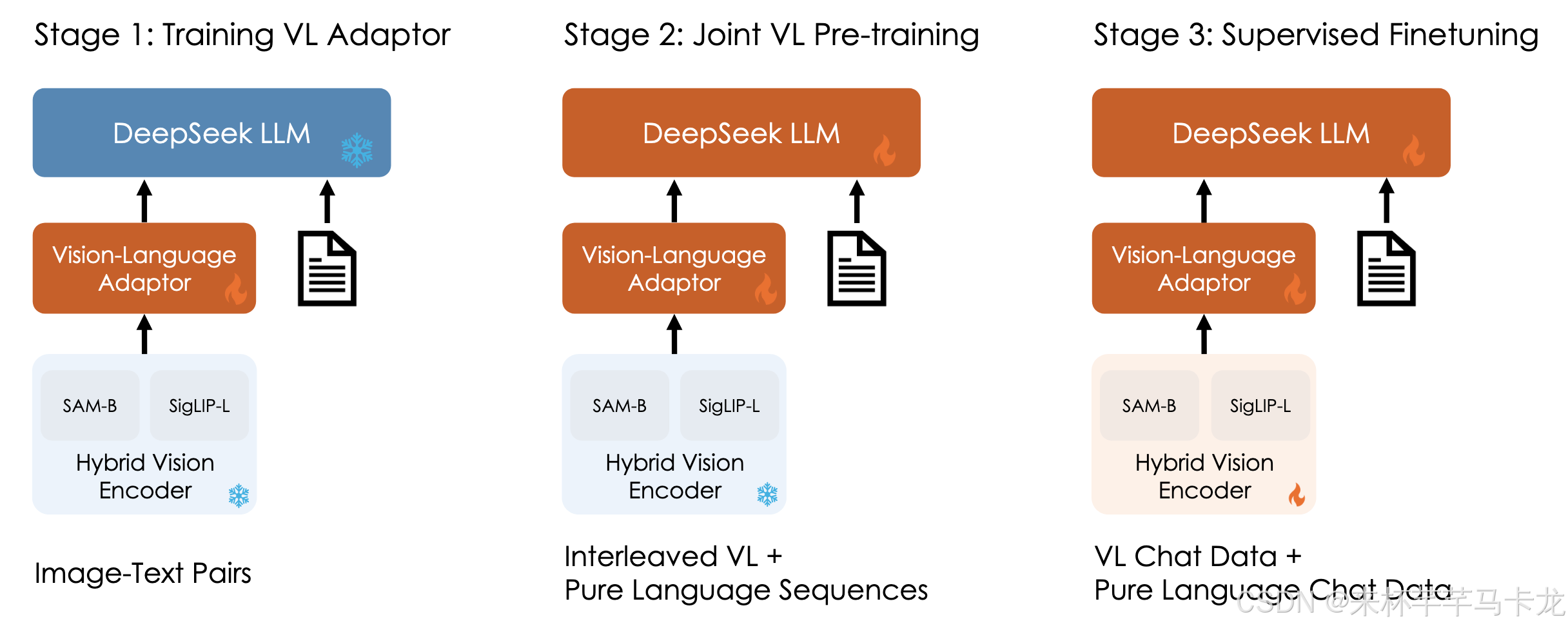
第一阶段:Training Vision-Language Adaptor训练视觉语言适配器
此阶段的主要目的是在嵌入空间内的视觉和语言元素之间建立概念上的联系,从而促进了大语言模型(LLM)对图像中所描绘实体的全面理解。冻结视觉编码器和大语言模型,仅训练调整Vision-LanguageAdaptor,使用从ShareGPT4V获得的1.25million的image-text对captions以及2.5million个Document OCR对进行适配器的训练,但是由于Vision-Language Adaptor模型的参数容量较小,海量的数据并不能一直增强其效果。
第二阶段:Joint Vision-Language pretraining 视觉-语言联合预训练
在这个阶段,探索有效的与训练策略,将其视为使大语言模型能过理解多模态输入的额外阶段。在此阶段冻结视觉编码器,训练LLM和适配器。
起初,直接使用多模态数据进行训练,发现多模态指标有所改善,但是会导致语言指标严重下降,所以需要找到增强多模态能力和保持语言能力的权衡点。作者认为,出现以上现象的原因主要有亮点:首先,大多数多模式语料库都过于简单,并且与语言数据的复杂性和分布显着差异。其次,多模式和语言模式之间似乎具有竞争性动态,导致可以被描述为灾难性忘记LLM中的语言能力。
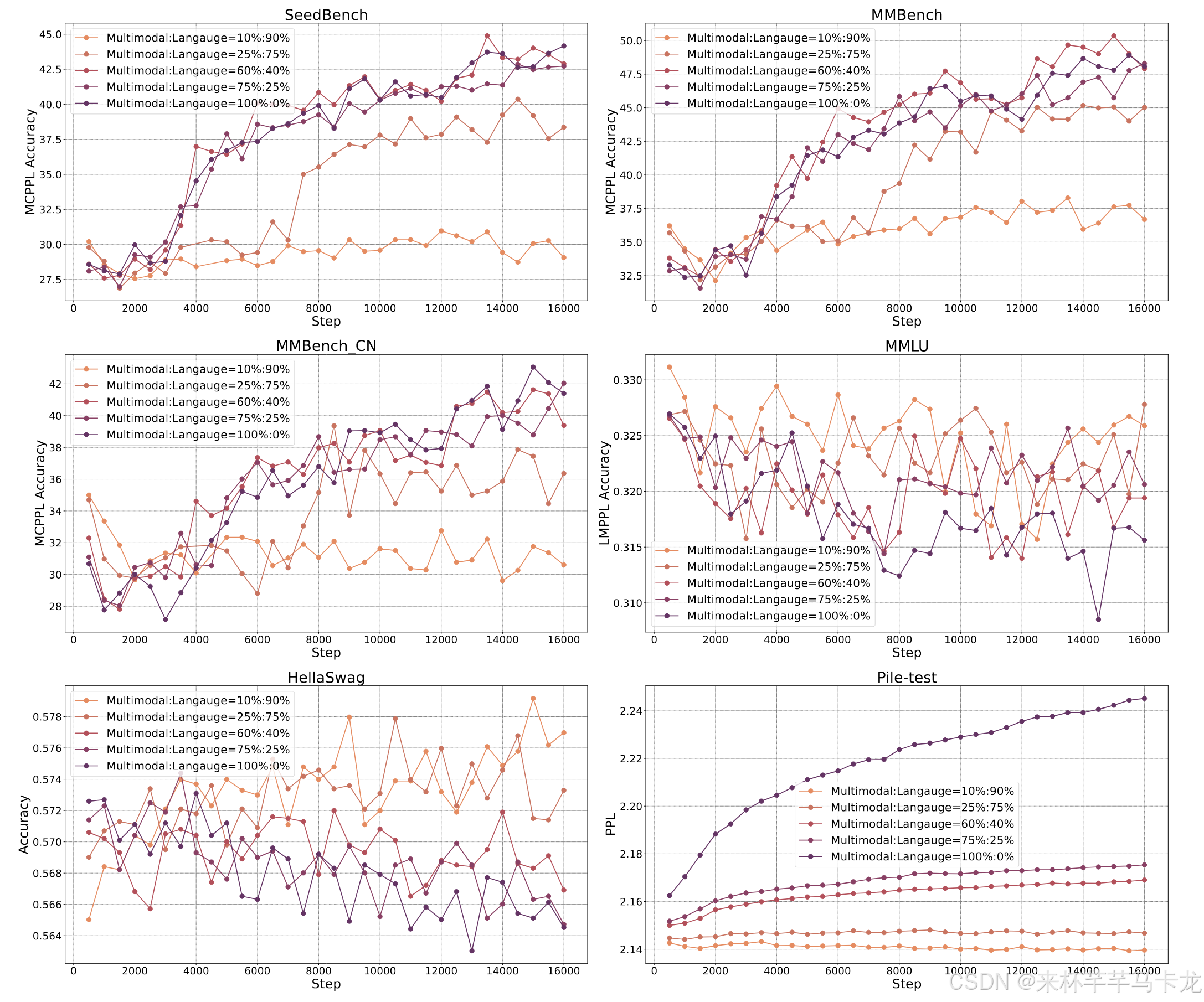
为了解决上述问题,作者采用联合语言和多模态数据进行训练。并且在实验过程中调整比列,得到了几个重要结论:
(1)整合语言数据可大大减轻语言能力的下降,表明该模型的语言表现有了很大的改善。
(2)包含语言数据并不会导致多模式性能造成重大损失,这表明该模型保留了其多模式处理能力。
(3)不同方式的性能与培训数据集中各自的比例密切相关,从而证实了两种方式之间的竞争关系。
最终作者为模型选择了大约7:3的语言与多模式数据量比例进行训练,该比率使该模型能够保持其语言能力,同时在多模式数据上更好地预处理,从而有效地平衡语言和多模式能力的发展。
第三阶段:Supervised Fine-tuning 监督微调
在这个阶段,基于指令微调来微调预训练的DeepSeek-VL模型以增强其遵循指令以及对话的能力,使用表2种的监督微调数据来优化LLM、VL Adaptor以及hybrid vision encoder(由于GPU内存限制,依然冻结了SAM- B)。仅监督答案和特殊令牌,然后掩盖系统和用户提示,为了确保模型在对话中的全面熟练程度,利用了DeepSeek-Llm中使用的多模式数据和纯文本对话数据的融合。这种方法可确保模型在各种对话方案中的多功能性。
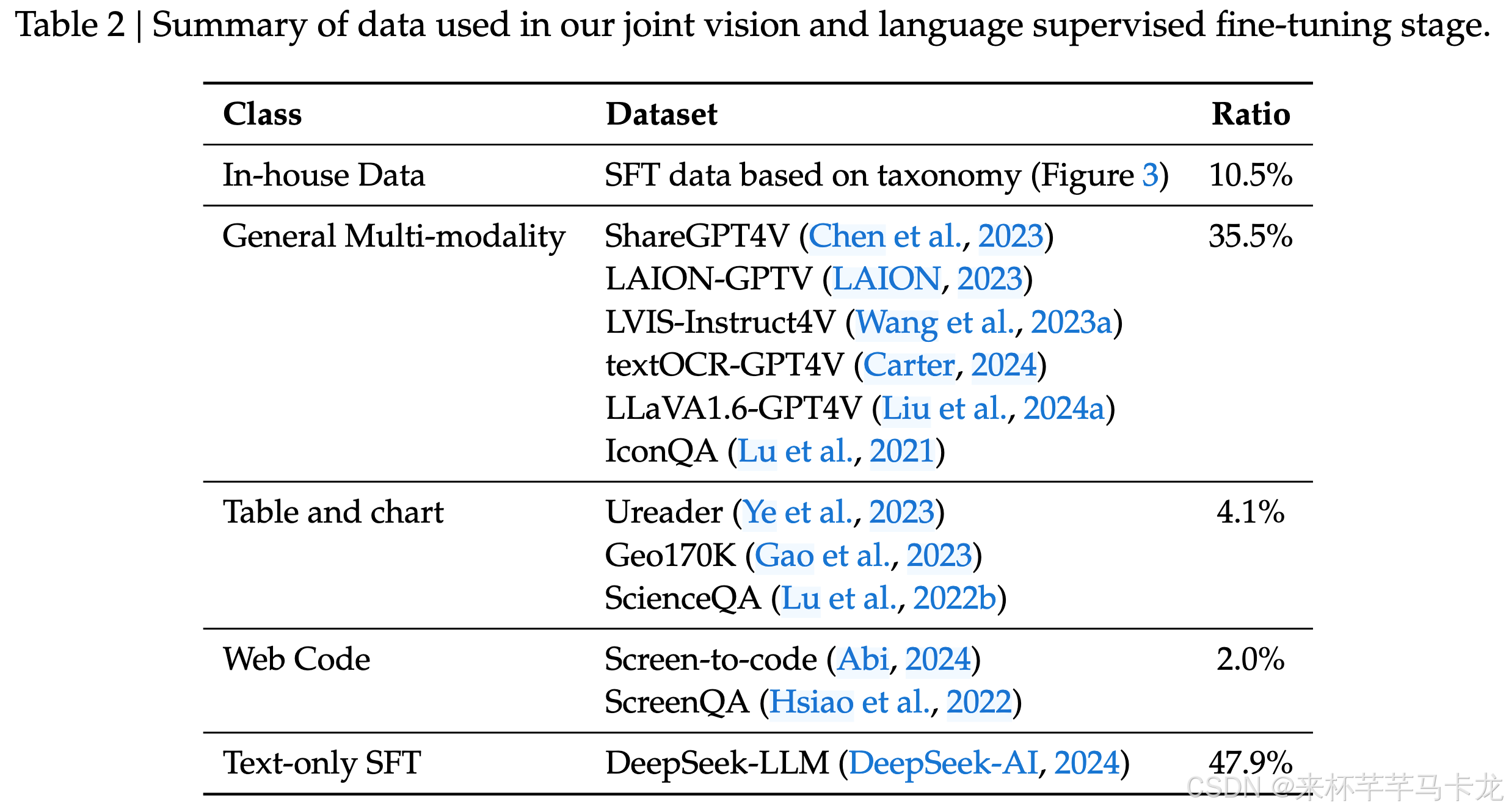
训练超参数
DeepSeek-VL-7B在512张A100上训练了5天,DeepSeek-VL 1B在128张A100上训练了7天。

模型效果
对比实验
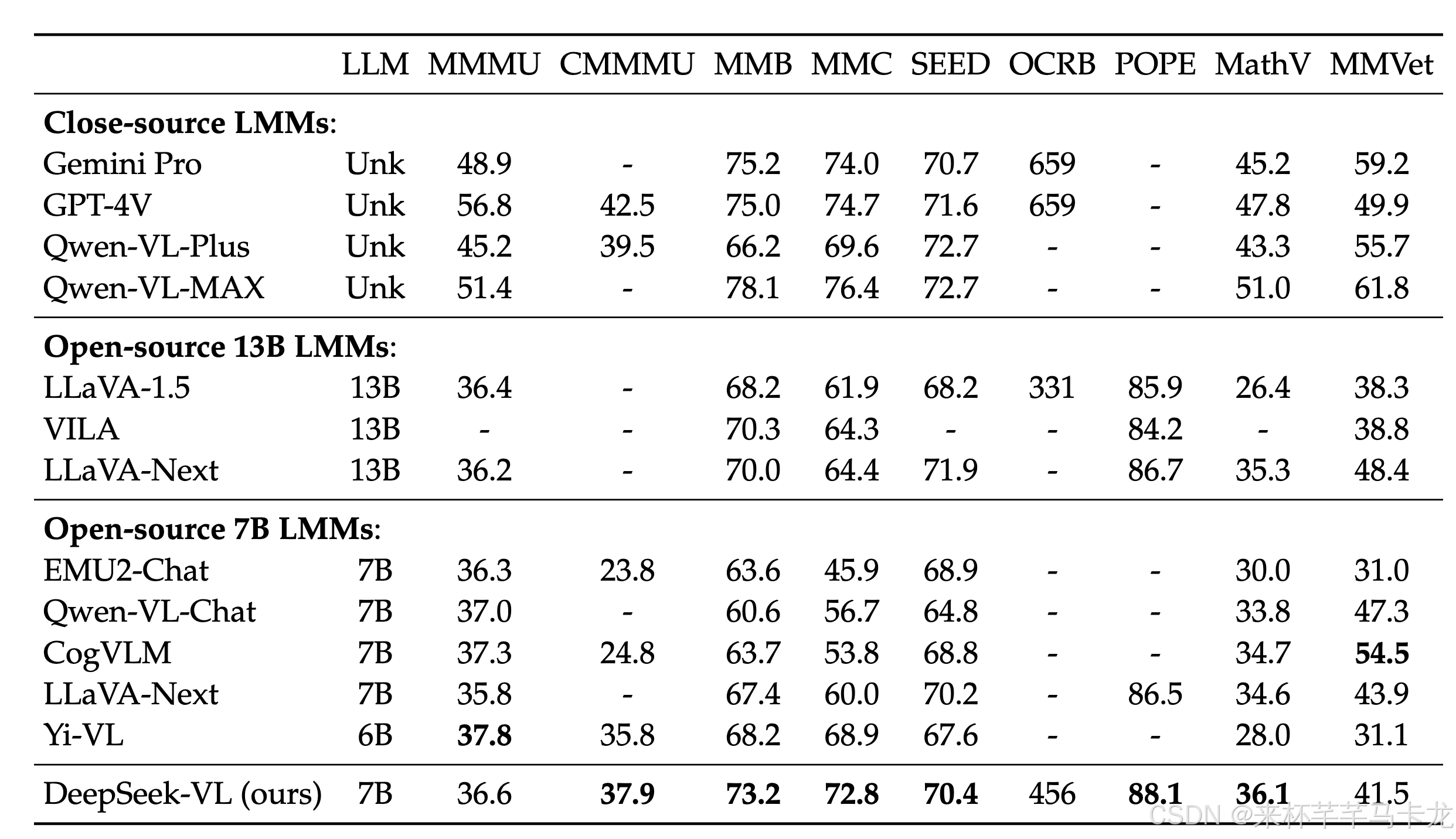
多模态任务下模型效果如下:
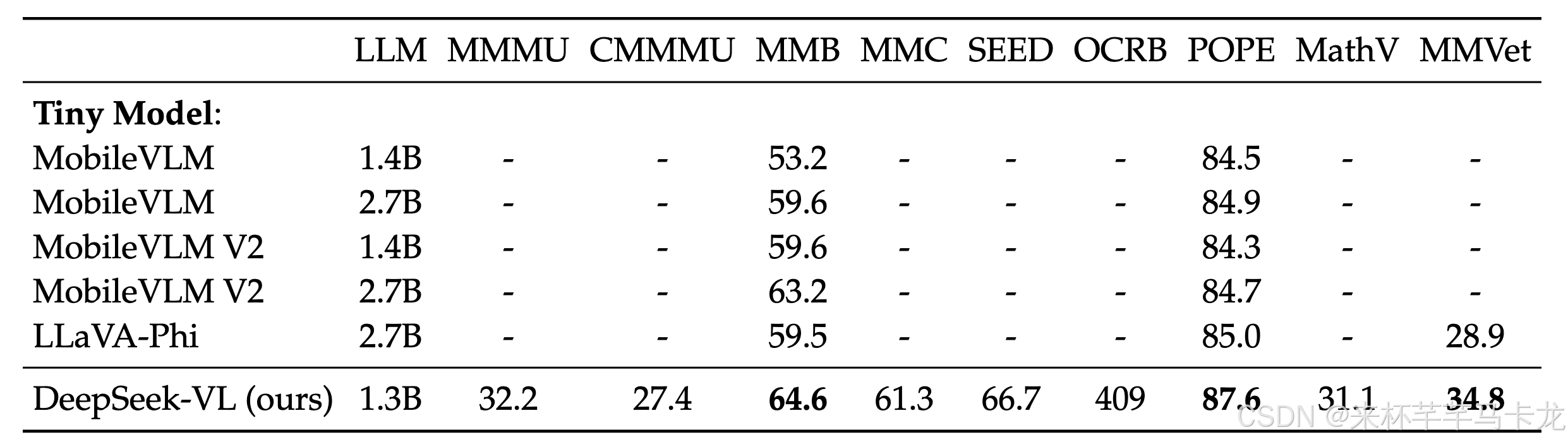
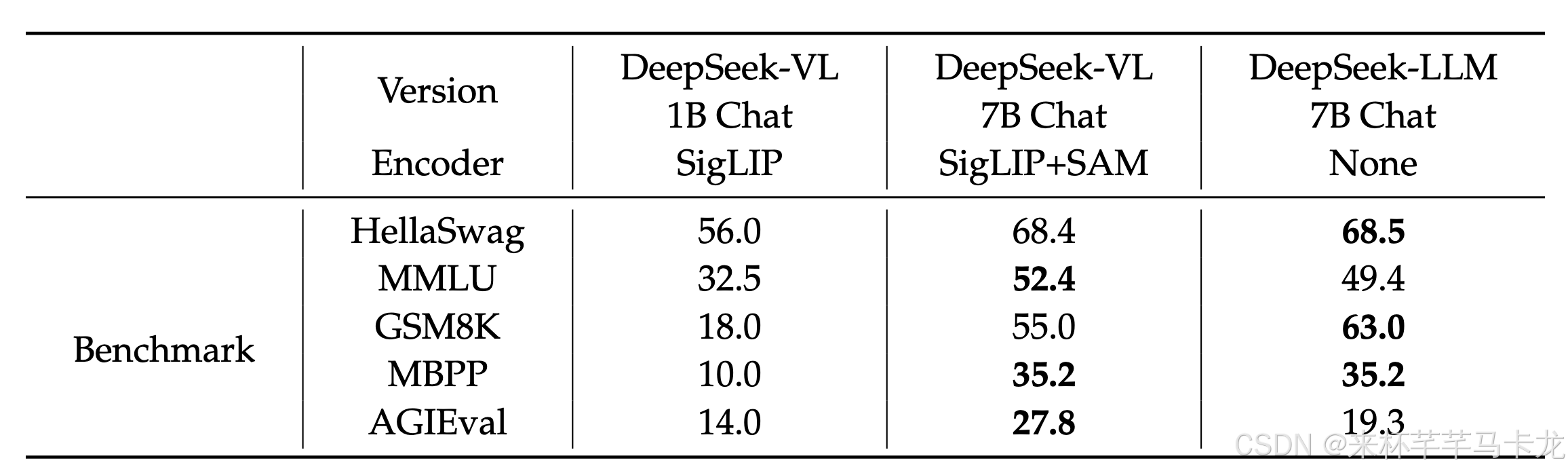
语言能力测评效果如下(含消融实验):
消融实验
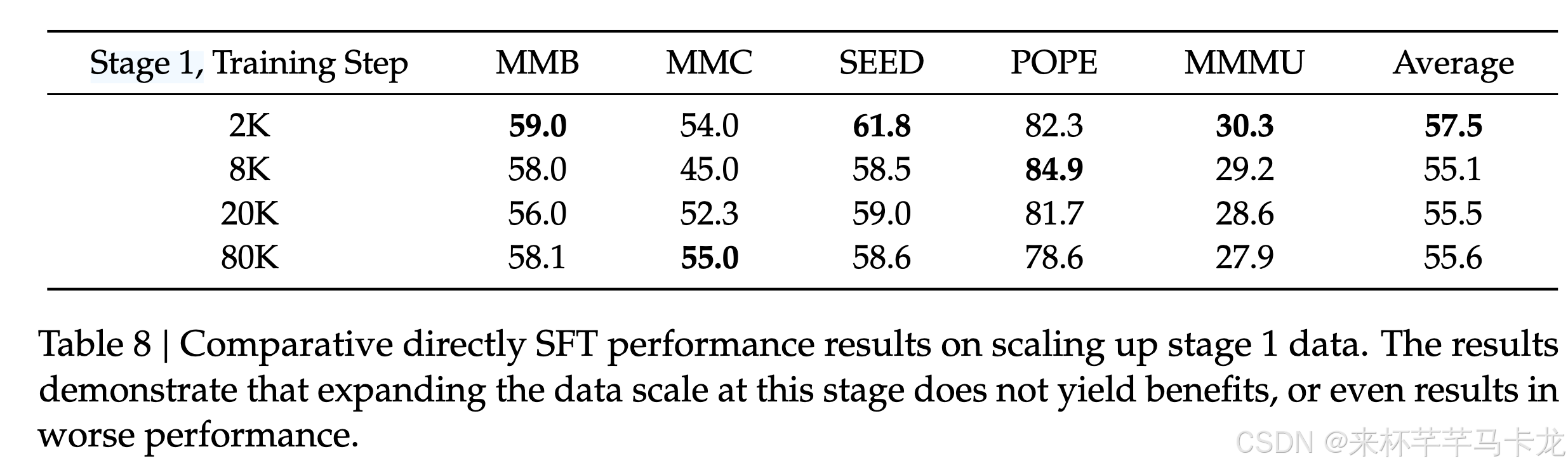
阶段一中适配器训练数据缩放
下表证明了,在阶段一中由于Vision-Language Adaptor参数容量有限,并不是越多训练数据适配器模型效果就越好。

三阶段训练步骤消融对比
从下表可以看出,三阶段训练策略是有必要的,Stage1和Stage2的训练会提升模型性能,特别是stage2。

训练数据模态分批
作者在文中提出,直接将语言数据和多模态数据混合训练(即同一个batch中即存在纯文本数据也存在多模态数据)会大大降低训练效率,因为每个批处理中的梯度反向传播都需要等待最慢的样本处理完成,大多数的纯文本样本处理更快(前面说到作者选用7:3的纯文本和多模态数据),需要等待多模态样本处理完成,从而降低了训练效率。为了解决这个问题,将纯文本数据和多模态数据进行分批训练,实验表明这种训练方法优化了训练工作流程,在不损害模型性能的同时提高了20%的模型训练效率。

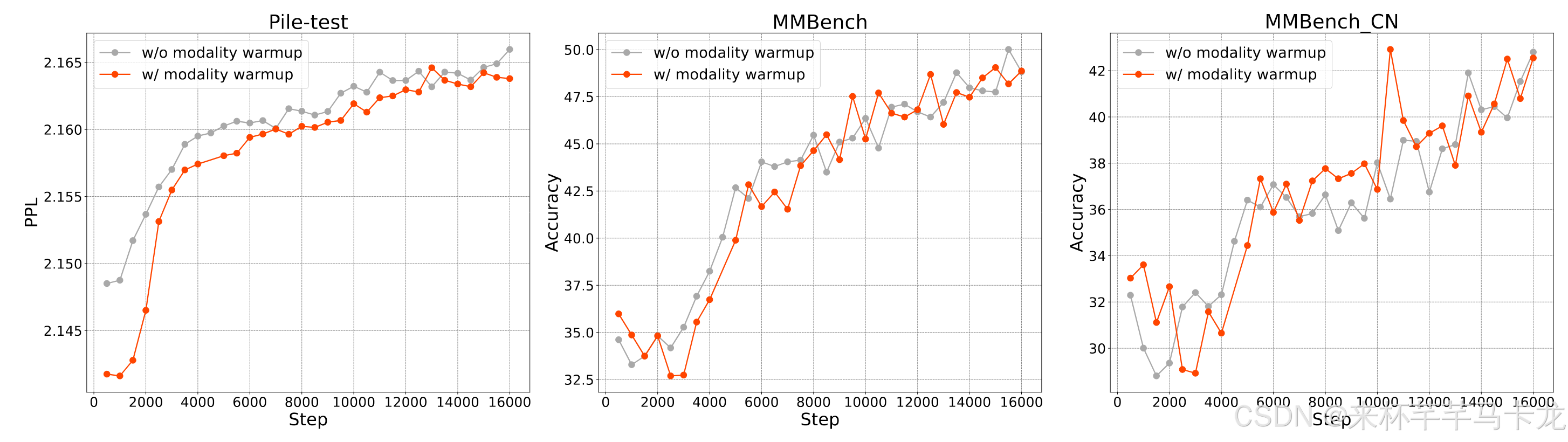
模态热身
作者提出,考虑到DeepSeek VL 是基于DeepSeek LLM的基础上改进的,因此一开始就以固定比例的纯文本和多模态数据混合训练可能会破坏语言模型的稳定性,为了解决这个问题,作者提出了一种简单而有效的方式热身策略。最初,我们将语言数据比率设置为1,然后将其逐渐降低到最终模型训练的目标比率(例如0.7)。
该策略有效地阻止了训练开始时语言能力的显着下降,使该模型能够更加无缝地适应多模式数据的合并,从而提高了整体训练稳定性和性能。
展望
作者提出,将会把DeepSeek VL拓展到更大体量,同时结合Mixture of Experts,进一步提高模型的效率和有效性,从而为AI领域的研究和应用开辟了新的视野。
有关MoE的知识可以参考:混合专家模型 Mixture-of-Experts (MoE)-CSDN博客

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)