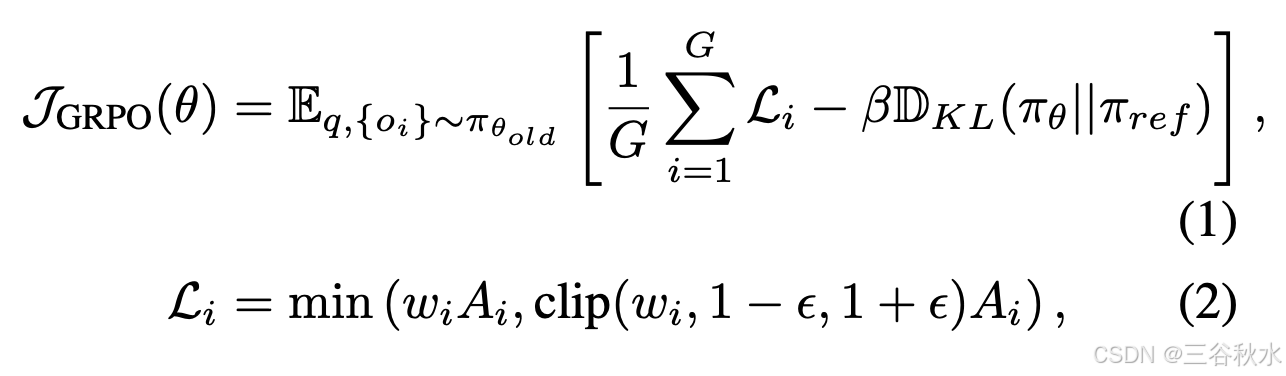
AlphaDrive:通过强化学习和推理释放自动驾驶中 VLM 的力量
25年3月来自华中科技大学和地平线的论文“AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning”。OpenAI o1 和 DeepSeek R1 在数学和科学等复杂领域达到甚至超越人类专家级表现,其中强化学习 (RL) 和推理发挥着至关重要的作用
25年3月来自华中科技大学和地平线的论文“AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning”。
OpenAI o1 和 DeepSeek R1 在数学和科学等复杂领域达到甚至超越人类专家级表现,其中强化学习 (RL) 和推理发挥着至关重要的作用。在自动驾驶中,最近的端到端模型已经大大提高规划性能,但由于常识和推理能力有限,仍然难以解决长尾问题。一些研究将视觉语言模型 (VLM) 融入自动驾驶,但它们通常依赖于对驾驶数据进行简单监督微调 (SFT) 的预训练模型,而没有进一步探索专门针对规划的训练策略或优化。本文提出 AlphaDrive,一个用于自动驾驶中 VLM 的 RL 和推理框架。AlphaDrive 引入四种基于 GRPO 针对规划定制的 RL 奖励,并采用将 SFT 与 RL 相结合的两阶段规划推理训练策略。因此,与仅使用 SFT 或不使用推理相比,AlphaDrive 显著提高规划性能和训练效率。此外,经过 RL 训练后,AlphaDrive 表现出一些新兴的多模态规划能力,这对于提高驾驶安全性和效率至关重要。
近年来,自动驾驶技术发展迅速,端到端自动驾驶成为最具代表性的模型之一 [8, 16, 17, 22, 29]。端到端自动驾驶以传感器数据为输入,利用可学习的神经网络规划车辆未来轨迹。得益于大规模的驾驶演示,端到端模型通过扩充训练数据、增加模型参数等方式不断提升规划能力。
然而,由于端到端模型的黑箱特性和缺乏常识性,在处理复杂、长尾驾驶场景时仍面临重大挑战。例如,考虑前方车辆在行驶时携带交通锥的情况。端到端模型可能无法理解前车与交通锥之间的关系,错误地认为前方的道路正在施工,因此无法通行,从而导致错误的刹车决定。因此,仅依靠端到端模型实现高水平自动驾驶仍然具有挑战性。
随着 GPT [6] 的成功,大语言模型 (LLM) 表现出卓越的理解和推理能力 [38, 48]。此外,它们的能力已经从单模态文本理解发展到多模态视觉语言处理。[3, 10, 24]。VLM 的常识和推理能力在缓解端到端模型的局限性方面具有巨大潜力。
最近,结合推理技术的 OpenAI o1 [25] 在编程等领域实现与人类专家相当甚至超越人类专家的性能。此外,利用强化学习的 DeepSeek R1 [14] 不仅展示“涌现能力”并实现顶级性能,而且与其他模型相比,所需的训练成本也显着降低。这些进步凸显推理技术和强化学习在大模型开发中的巨大潜力。
自回归学习 [39] 是目前 LLM 的主流预训练策略。此外,强化学习和推理技术进一步增强大型模型的能力 [26, 31–33, 43]。例如,GPT [1] 采用带人类反馈的强化学习 (RLHF) [26],将人类反馈纳入训练过程。通过整合人类意图和行为偏好,RLHF 使 LLM 能够生成更符合人类习惯和偏好的输出。直接偏好优化 (DPO) [31] 通过直接优化偏好反馈来提高模型的性能。在此基础上,组相对策略优化 (GRPO) [33] 引入一种组相对优化策略,它考虑多个输出组之间的相对优劣,进一步提高训练过程的稳定性和有效性。
最近的 DeepSeek R1 [14] 在基于 GRPO 的训练过程中经历“顿悟时刻”,在没有任何明确指导的情况下,模型自主地将更多思考分配给问题并重新评估其初始方法。这凸显 RL 在使大模型从单纯的模仿发展到新兴智能方面的潜力。在推理方面,思维链 [43] 通过逐步分解和推理,在解决复杂问题方面表现出色。基于思维链的 OpenAI o1 [25] 引入推理-时间规模化。通过增加推理过程中的计算成本并结合蒙特卡洛树搜索 (MCTS) [35] 和 波束搜索(Beam Search) [46] 等策略,在需要复杂推理的科学和编程等领域取得显着的进步。这也表明,除扩展模型参数和训练数据之外,扩展推理-时间计算也是一个有希望的探索方向。
现有的将 VLM 应用于自动驾驶的研究大致可分为两个方向。第一个方向侧重于利用 VLM 理解驾驶场景 [34, 49]。第二个方向探讨 VLM 在规划中的应用,一些研究将 VLM 视为端到端系统,处理驾驶图像和其他输入以直接预测轨迹 [7, 47]。然而,与专门为轨迹规划设计的端到端模型不同,VLM 在语言空间中运行,并不天生适合精确的数值预测 [12, 15]。因此,直接使用 VLM 进行轨迹规划可能会导致性能不佳,甚至带来安全风险。
一些研究利用 VLM 进行高级规划,用自然语言表达自车的未来行动,例如“减速并右转” [18]。虽然此方法规避上述缺点,但现有研究仍然缺乏对训练方法的进一步探索,大多数研究主要依赖于 SFT,而忽略不同训练策略对规划性能的影响以及相关的训练成本。
为了解决上述挑战,AlphaDrive,一个基于 VLM 的强化学习和推理框架,专门用于自动驾驶规划。具体来说,AlphaDrive 采用基于组相对策略优化 (GRPO) [33] 的 RL 策略。与近端策略优化 (PPO) [32] 和直接偏好优化 (DPO) [31] 相比,GRPO 表现出更好的训练稳定性和性能。
AlphaDrive 是一款专为自动驾驶规划而设计的 VLM。与以前仅依赖 SFT 的方法不同,其探索将 RL 和推理技术结合起来,以更好地适应驾驶规划的独特特征:(1)不同驾驶行为的重要性各不相同;(2)存在多个可行解决方案;(3)规划决策所需的现成推理数据稀缺。
本文提出四种基于 GRPO 的 RL 奖励,专门用于规划,以及一种将 SFT 与 RL 相结合的两阶段规划推理训练策略。与单独使用 SFT 或不使用推理进行训练相比,AlphaDrive 在规划性能和训练效率方面都实现显着提升。
目前常用的 RL 算法包括 PPO [32]、DPO [31] 和 GRPO [33]。给定一个查询 q,GRPO 从旧策略 π_θ_old 中采样一组输出 {o_1, o_2, · · · , o_G},并通过最大化以下内容优化新策略 π_θ:
本文选择 GRPO 作为 AlphaDrive 的强化学习算法,主要有两个原因:(1)DeepSeek R1 [14] 已经证明 GRPO 在一般领域的有效性。与其他算法相比,GRPO 提供更高的训练稳定性和效率;(2)此外,GRPO 引入的组相对优化策略特别适合规划,因为规划通常涉及多个有效解决方案,因此跨多个解决方案的相对优化是自然而然的选择。实验结果进一步证实,使用 GRPO 训练的模型表现出强大的规划能力。
规划准确度奖励。在数学或编程等领域,GRPO 中的奖励可以根据最终答案是否正确直观地确定。然而,规划更为复杂,因为它涉及横向(方向)和纵向(速度)分量。此外,可能的操作集受到限制。因此,用 F1 分数分别评估横向和纵向决策的准确性,并相应地分配奖励。
最初,检查模型的预测是否与基本事实完全匹配来评估准确性。然而,由于模型在早期训练阶段的格式不完善,例如区分大小写的差异或存在无关输出,这种方法导致训练早期阶段的稳定性较差。然后,从预测中提取所有单词,并检查基本事实是否包含在单词中。这引入一个新问题,即模型有时会学习捷径解决方案,例如输出所有可能的操作,这会导致模式崩溃。最终,用 F1 分数进行评估,因为它不仅可以防止模型学习捷径解决方案(输出所有决策可能导致高召回率但低准确率),还可以提高早期训练阶段的稳定性。
动作加权奖励。如上所述,不同行为在规划中的重要性各不相同。例如,减速和停止对安全比保持速度更重要。因此,我们为各种动作分配不同的重要性权重,将它们作为加权成分纳入最终奖励。
规划多样性奖励。由于规划本质上是多模态的,因此在基于 GRPO 的 RL 训练期间,模型会为组相对优化生成多个解决方案。在训练的后期阶段,我们观察到模型的输出趋向于收敛到同一个解决方案。我们的目标是鼓励模型生成各种可行的解决方案,而不仅仅是与训练数据中的真实动作保持一致。为了实现这一点,我们提出了规划多样性奖励。当模型的输出不同时,我们会分配更高的奖励;否则,我们会降低奖励。
规划格式奖励。最后一个奖励用于规范输出,使提取推理过程和最终答案变得更容易。这种方法的灵感来自 R1。推理过程封装在 标签中,而规划结果则包含在 标签中。如果最终输出不符合此格式,则格式奖励将设置为 0。
规划准确度奖励、动作加权奖励和规划多样性奖励相乘以计算规划质量奖励。分别计算速度规划和方向规划的规划质量奖励。最后利用规划质量奖励和规划格式奖励计算GRPO损失,更新模型参数。规划奖励建模详见如下算法1:

其中 extrat_ans 将从给定的字符串中提取与指定模式匹配的子字符串,cal_f1_score 将根据预测和基本事实计算 F1 分数,check_format 将根据正则表达式匹配检查给定的字符串是否与提供的模式匹配。
如图所示 AlphaDrive 的总训练框架:
与数学或科学等领域拥有大量高质量的推理数据可供训练不同,自动驾驶中的规划过程难以记录,人工标注成本高昂,目前尚无大规模、随时可用的规划推理数据集。初步尝试将推理步骤直接纳入强化学习的训练过程,但最终结果并不理想,主要原因包括:(1)对交通信号灯等关键要素感知不足;(2)推理过程混乱,因果关系薄弱;(3)推理输出过于冗长、低效。
因此,采用功能更强大的云端大模型,如 GPT-4o,从一小组驾驶片段中生成高质量的规划推理数据。具体而言,为模型提供包括特定场景下的真实驾驶行为、车辆当前状态和导航信息等提示,促使模型生成简明的决策过程。生成的推理过程质量不错,经过人工质检,过滤掉有明显错误的样本后,得到一批高质量的规划推理数据,随后,模型可以基于这些数据通过知识蒸馏提升规划推理能力。
RL依赖于稀疏的奖励信号,而SFT基于密集监督,更适合进行知识提炼。另外,单纯依靠RL会导致训练初期不稳定,因此先基于SFT用少量数据进行热身,然后再使用全数据集进行RL训练,发现这种方式提升训练初期的稳定性,提升模型的规划推理性能,最终提升整体的规划能力。
采用 MetaAD(一个大规模真实驾驶数据集)作为训练和评估基准。该数据集总共包含 120k 个驾驶剪辑,每个剪辑持续三秒。MetaAD 是一个高质量的数据集,专为规划而设计,支持多传感器数据和感知注释。此外,它在各种驾驶环境和规划操作中保持良好的平衡分布。数据集分为 110k 个剪辑用于训练和 10k 个剪辑用于验证。至于推理,从训练数据集中抽取 30k 个数据来生成规划推理过程。所有报告的结果都是通过在训练集上进行训练并在验证集上进行评估获得的。
用 Qwen2VL-2B [41] 作为基础模型。 Qwen2VL 是目前性能最好的开源模型之一,它提供更小的 2B 版本,可以更好地满足自动驾驶的延迟要求。此外,Qwen2VL 对 RL 提供更好的支持。该模型的输入包括前视图图像和规划提示,其中包含车辆的当前速度和导航信息。与真实驾驶一致的导航数据是通过 AMap(类似谷歌地图)从稀疏导航点获取的,并转换为文本形式包含在提示中,例如“直行 100 米,然后右转”。使用 16 个 NVIDIA A800 GPU 进行训练。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)